📄 本篇文章主要讲解跳表(Skiplist)这一数据结构,如果需要原论文,可以在作者主页资源中找到。
✈️ 跳表由于其实现简单、查找效率高等特点,已经逐渐成为现在某些工具的数据结构,比如 Redis 中的 ZSet 数据类型。
目录
[1 跳表的基本概念](#1 跳表的基本概念)
[1.1 什么是跳表](#1.1 什么是跳表)
[1.2 Skiplist 的层数随机化算法](#1.2 Skiplist 的层数随机化算法)
[1.3 跳表的查找时间复杂度](#1.3 跳表的查找时间复杂度)
[2 跳表的实现](#2 跳表的实现)
[2.1 跳表的节点结构](#2.1 跳表的节点结构)
[2.2 跳表的构造函数](#2.2 跳表的构造函数)
[2.3 跳表的查找](#2.3 跳表的查找)
[2.4 跳表的插入](#2.4 跳表的插入)
[2.5 跳表的删除](#2.5 跳表的删除)
[2.6 跳表实现代码](#2.6 跳表实现代码)
[3 跳表与其他查找结构的对比](#3 跳表与其他查找结构的对比)
1 跳表的基本概念
1.1 什么是跳表
跳表的英文名称为 Skiplist ,最早是由William Pugh 在 1990 于论文 《Skip Lists: A Probabilistic Alternative to Balanced Trees》中提出。
Skiplist 是在有序链表 list 基础上演化而来,list 我们本身也可以看作是一种查找结构,由于 list 没法使用二分等查找方法,只能遍历链表,所以其查找时间复杂度为 O(n)。

那么有没有什么办法可以提高一下有序链表的查找速度呢?其实我们可以每相邻两个节点,就将节点升高一层:

这样所有升高的节点,也就是新产生的指针构成了一个新的链表,这个链表节点个数大概只有原来的一半,增加了查找的效率。那如果我们再将节点升高一层:

这样新增的指针就又可以构成一个新的链表,第三层的节点个数进一步减少,那么这样为什么可以提高查找效率呢?我们以上面的三层链表举例,假设查找数字 27,在以前的单链表中,我们只能逐个节点向后遍历查找,但是在三层链表中,由于 27 比 9 大,所以可以通过第三层指针直接跳到 9,跳过了 3、6、7 这三个节点,然后 27 又比 24 大,9 可以直接跳到 24,然后再找到 27。以前的单链表需要查找 7 次,但是三层链表只需要查找 3 次就可以找到,所以如果在节点数很多的情况下,使用跳表就可以跳过中间很多节点,从而大大提高了查找效率。
但是上面的多层链表还不是真正的跳表,虽然多层链表查找效率近似于多分查找,比如二层链表查找效率近似于二分查找,效率为 O(logn),但是上下两层节点之间有严格的 2:1 对应关系,为了保持 O(logn) 的查找效率,就必须保持这种严格的对应关系,以至于插入或者删除节点之后,就需要对后面的节点进行调整,所以插入和删除节点的效率会退化为 O(n),这显然不是我们想看到的。所以 William Pugh 在多层链表的思想上进行了改进,从而提出了跳表这一数据结构。
既然多层链表需要保持严格的对应关系,那么只要让每个节点的层数独立,不影响到其他节点,是不是就可以不用保持这种严格的对应关系了呢?所以每个节点的层数并不是固定的,而是随机出一个层数,这样,每一个节点的层数就都是独立的,插入和删除时也不需要考虑其他节点,这样插入和删除效率就会大大提高:
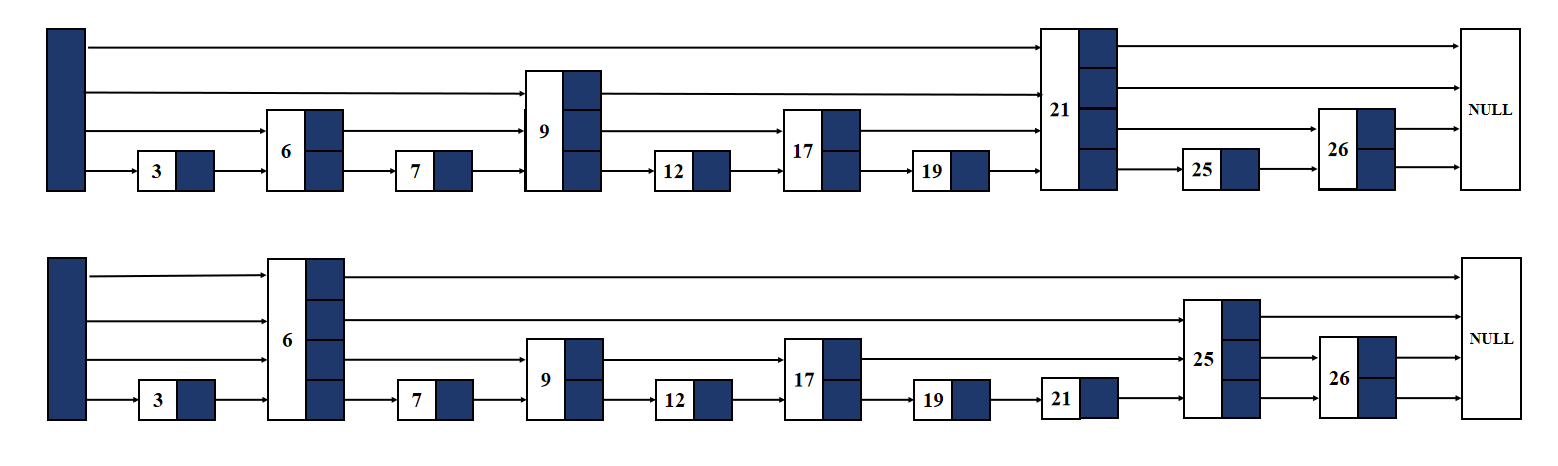
所以什么是跳表呢,其实就是一个可以跳跃查找的有序链表,每个节点随机得到一个节点层数,然后与每一层的前后节点进行连接。这种结构使得在查找时,可以跳过一些节点,大大提高了查找效率。
1.2 Skiplist 的层数随机化算法
跳表中每个节点的层数是随机的,层数的随机化算法我们可以遵循其论文中的伪代码:

William Pugh 在论文中提到了一个概率的概念,在伪代码中,random() 函数会随机返回一个 [0, 1) 之间的数字,如果 random() 产生的数字小于概率 p,那么新节点就增加一层,直到 random() >= p 或者 newLevel >= MaxLevel。
伪代码中的 p 其实就是每个节点层数的概率,这个 p 衡量了每个新节点上升一层所需的概率。因为最开始节点至少为 1 层,而晋升一层的概率是 p,所以节点恰好为 1 层的概率就是 1-p,那么节点恰好为 2 层的概率就是恰好为 1 层的概率 * 晋升一层的概率,也就是 (1-p)*p,那么恰好为第 k 层的概率就是恰好为 1 层的概率 * 晋升 k-1 层的概率,也就是 (1-p)*p^(k-1)。
假设这里的 p = 0.5,那么节点恰好为 1 层的概率就是 (1 - 0.5) = 0.5,恰好为 2 层的概率就是 0.25,恰好为 3 层的概率就是 0.125,恰好为 4 层的概率就是 0.0625;按照节点数来算,假设一共有 1000 个节点,那么一层的节点就是 500 个,两层的节点就是 250 个,三层的节点就是 125 个,四层的节点就是63 个,以此类推,所以我们就可以通过概率 p 来控制每层的节点个数。
1.3 跳表的查找时间复杂度
跳表的查找平均时间复杂度为 O(logn),极端情况下为 O(n),接下来我们就来推导一下。
跳表的查找次数 = 跳表的层数 * 每层的比较次数。所以我们分两部分来计算跳表的查找时间复杂度。
- 跳表的层数:我们假设节点晋升一层的概率为 p,第一层所有节点个数为 n,注意这里不是恰好为第一层的节点个数,就是第一层用指针连接起来的节点,由于所有节点至少为 1 层,所以这里 n 就是所有节点的个数。那么第二层的节点个数就是 np,第三层的节点个数就是 np^2,第 h 层的节点个数就是 np^(h-1),假设第 h 层就是最高层而且节点个数为 1,则

- 每层的平均比较次数:跳表在查找时,如果当前层的下一个节点值比要查找的值大,那就会向下走,如果当前层的下一个节点值比要查找的值要小,那就会向右走,跳过下一个节点(跳表的实现中会有更加详细的讲解)。所以每层的要比较的节点个数其实就是当前层的上一层两个相邻节点之间的节点个数。比如在下图的跳表中,查找 24,第一层的平均比较节点个数其实就是 19 和 21,因为在第二层中会先找到 17,然后 17 的下一个节点 25 比 24 更大,会向下来到第一层,然后第一层查找的节点就只有 19 和 21 了,也就是第二层中相邻两个节点之间的节点个数。

- 所以每一层查找的节点个数就转化为了每一层中晋升节点之间相邻的节点个数有多少个。假设晋升的概率为 p,那么查找的节点个数就会变为以下几种情况:
(1)两个晋升节点之间有 0 个不晋升节点:概率就是 p,查找节点个数为 0
(2)两个晋升节点之间有 1 个不晋升节点:概率为 (1-p)*p,查找节点个数为 1
(3)两个晋升节点之间有 2 个不晋升节点:概率为 (1-p)^2 * p,查找节点个数为 2
(4)......
(5)两个晋升节点之间有 k 个不晋升节点:概率为 (1-p)^k * p,查找节点个数为 p
- 设 X 表示两个相邻晋升节点之间的未晋升节点数量,X = k 的概率为 P(X = k) = (1-p)^k * p,所以 X 的数学期望 E(X) = 0*p + (1-p)*p + 2*(1-p)\^2\*p + ... + k*(1-p)\^k\*p + ... =
,这个几何分布为 E(X) = (1-p)/p,但是由于比较次数会比最终查找节点个数多 1(因为最终还要跟后一个晋升节点比较一次),所以每层的平均比较次数为 E(X) + 1 = 1/p。
- 故最终的查找次数 = 跳表的层数 * 平均每层的比较次数 =
2 跳表的实现
我们借助 leetcode 的一道题目来完成这里跳表的实现。
leetcode 链接:1206. 设计跳表 - 力扣(LeetCode)
这道题目就是让我们实现跳表的核心接口,包括跳表的构造、查找、插入和删除:
cpp
class Skiplist {
public:
Skiplist() {
}
bool search(int target) {
}
void add(int num) {
}
bool erase(int num) {
}
};所以我们就借助这个题目来讲解如何实现跳表。
2.1 跳表的节点结构
跳表也是一个单链表,节点之间用指针连接起来,所以在实现跳表之前,我们需要先有一个节点结构。我们可以借鉴以前单链表的节点结构:
cpp
struct SListNode
{
int _val;
SListNode* _next;
};跳表的节点结构也是一样的,有一个存储数据的数据域,以及指向下一个节点的指针域,但是跳表中的节点可能是多层的,也就是会具有多个指向下一个节点的指针,但是这个层数又不确定,使用一个固定大小的数组可能会浪费空间,所以这里我们可以使用 vector 来存储指向每一层下一个节点的指针:
cpp
struct SkiplistNode
{
int _val;
vector<SkiplistNode*> _nextV;
};这样 _nextVi 就代表每个节点中第 i+1 层指向下一个节点的指针 ,而且 vector 可以通过 resize 动态改变大小,也不会浪费空间。
2.2 跳表的构造函数
有了跳表节点的结构,跳表的构造函数就很简单了。跳表本质上是一个带头单向不循环有序链表,所以跳表的结构只要有一个哨兵位的头节点,在构造函数中我们只需要初始化这个头节点就可以了,而且为了方便我们以后节点的创建,我们在 SkiplistNode 中添加一个 val 和 level(节点层数)作为参数的构造函数。但是跳表中 new 每个节点时,需要使用随机化算法来得到一个节点层数,所以我们在跳表中还需要两个成员,一个是 _Maxlevel 代表最大层数,一个是 _p,代表每增加一层的概率:
cpp
struct SkiplistNode
{
int _val;
vector<SkiplistNode*> _nextV;
SkiplistNode(int val, int level)
: _val(val)
, _nextV(level, nullptr)
{}
};
class Skiplist
{
using Node = SkiplistNode;
public:
Skiplist()
{
//头节点先给 1 层
_head = new Node(-1, 1);
}
private:
Node* _head;
int _Maxlevel = 32;
double _p = 0.25;
};2.3 跳表的查找
在跳表中,查找一个值的逻辑如图所示:
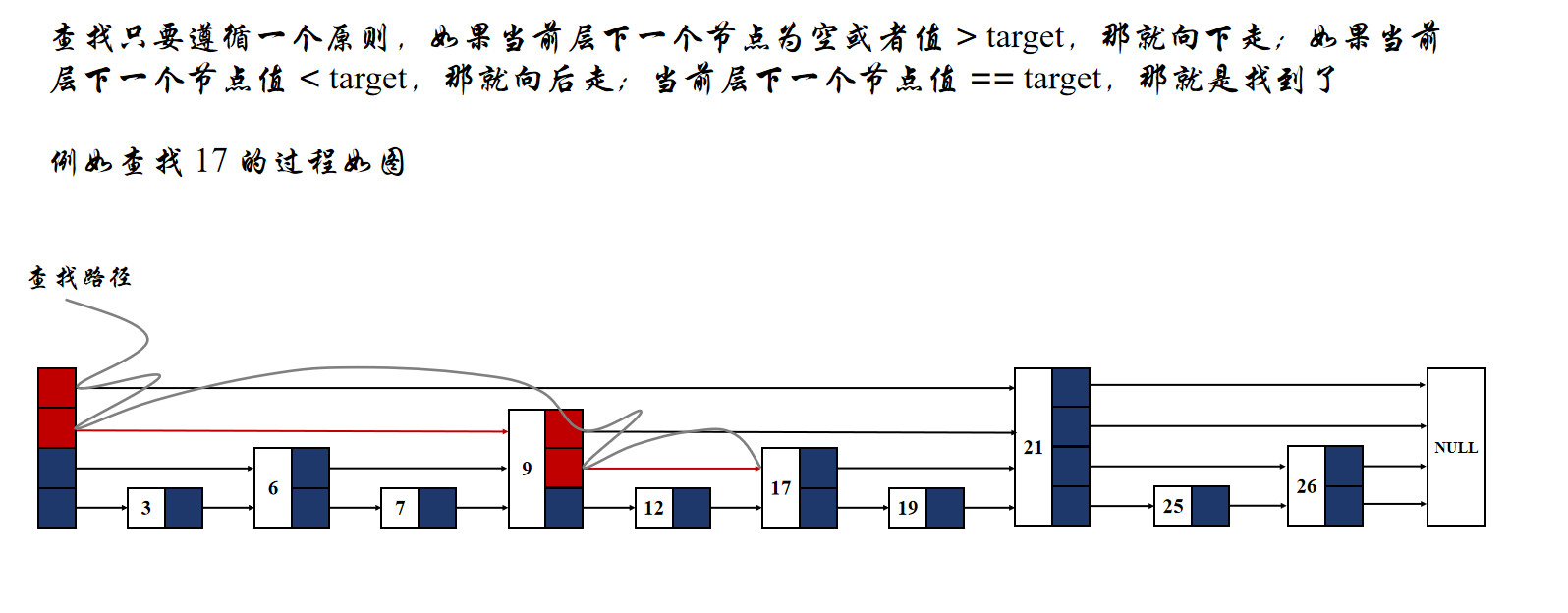
我们在进行查找时,只要遵循一个大原则,那就是如果当前层的下一个节点的值小于我们要查找的值,由于跳表是有序的,所以查找的值必然在下一个节点后面,我们就可以直接跳到下一个节点,越过中间的那些节点;那么如果当前层的下一个节点大于我们要查找的值,那么我们必须降低一层,继续查找。
但是可能遇到一些特殊情况。比如上面的跳表查找 26,首先我们会从头节点跳到 21 这个节点,但是 21 的当前层下一个节点为空了,但是 26 是有的,只不过比 21 节点低两层。所以在跳表查找过程中,如果当前层下一个指针为空,我们也需要降低一层才可以,因为要查找的值可能位于比当前节点更低的层处。
那么什么情况下我们会判定一个值没有在跳表中呢?因为跳表中的所有节点都会在第一层连接起来,所以如果当前查找层数已经小于第一层但是还没有找到,我们就可以判定当前值并不在跳表中。
cpp
bool search(int target)
{
//从头节点最顶层开始查找
int level = _head->_nextV.size() - 1;
Node* cur = _head;
//最坏就是找到最后一层
while (level >= 0)
{
// 如果 cur 当前层的下一个节点不为空并且值比 target 小,那就向后走
if (cur->_nextV[level] && cur->_nextV[level]->_val < target)
{
cur = cur->_nextV[level];
}
//如果 cur 当前层的下一个节点为空或者比 target 大,那就向下走
else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val > target)
{
--level;
}
else
{
return true;
}
}
return false;
}2.4 跳表的插入
跳表的插入其实与单链表插入的本质都是一样的,就是找到要插入的位置,然后改变链表的指向就可以了。所以插入最核心的就是找到要插入节点的前节点。但是在跳表中,每个节点有多层,所以找到前一个节点也就变成了找到每一层的前一个节点,这就是跳表插入甚至是删除方法的核心。
在跳表中查找每一层前一个节点的过程如图所示:
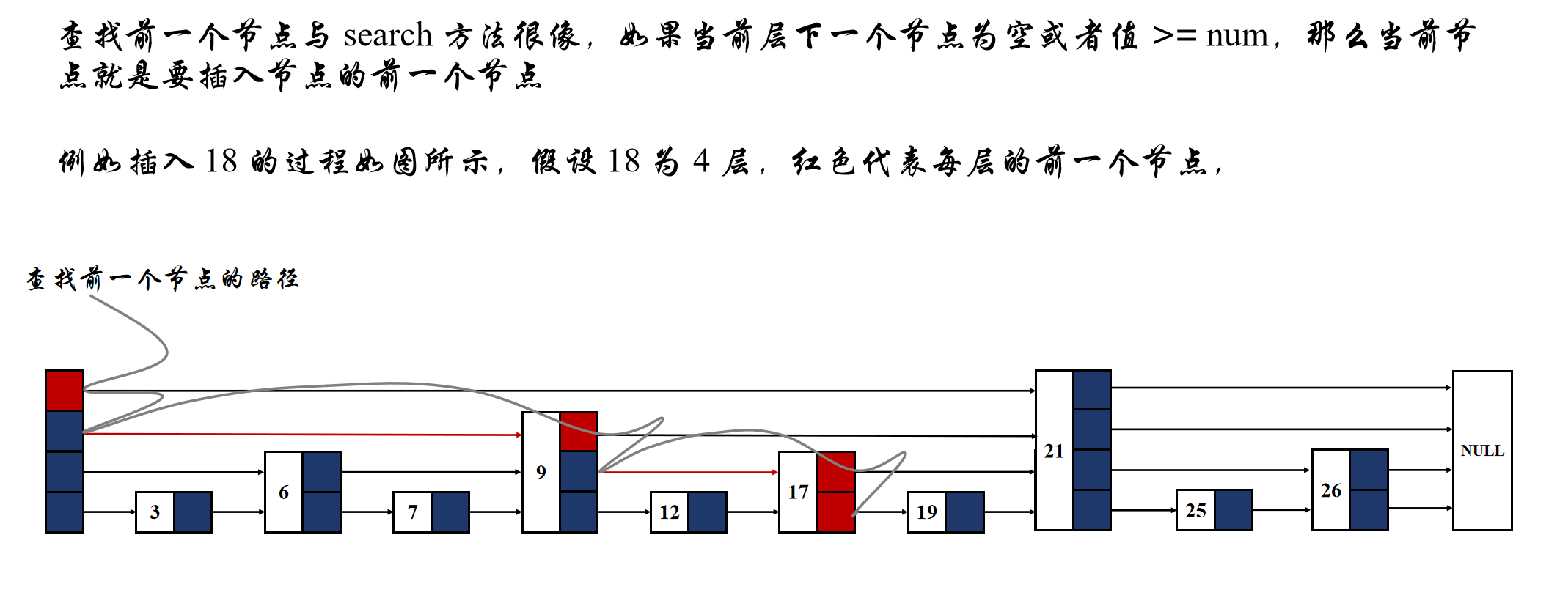
如果以 cur 代表每一层的当前节点,cur 最开始为第四层的头节点,如果 cur 的后一个节点的值要比插入的值小,由于跳表是有序的,那么 cur 绝对不可能是当前层插入节点的前一个节点,至少下一个节点才是;但是如果 cur 的当前层下一个节点为空或者下一个节点的值比要插入的值大,那么 cur 就是当前层的前一个节点。按照这样的搜索方法,我们就可以找到所有层的前一个节点。
找到所有层的前节点之后,我们就可以像单链表中一样,改变每一层的连接关系就可以了。但是插入这里还有一个需要实现的算法,那就是层数的随机化算法。
随机化算法有一个难点,那么如何实现层数增长的概率呢?这里我们选择使用库中的 rand 函数来实现,我们再来看一下 rand 函数:

rand 函数并不是随机返回无限大的值,返回的最大值为 RAND_MAX,所以我们就可以使用 RAND_MAX * _p 来使用概率来控制层数:
cpp
int RandomLevel()
{
int level = 1;
while (rand() < RAND_MAX * _p && level < _Maxlevel)
{
++level;
}
return level;
}其中 rand() < RAND_MAX * _p 可以转化为 (rand() / RAND_MAX) < _p。如果 RAND_MAX 为 100,_p = 0.25,那么这样写不就是只有 0 ~ 24 可以通过吗,对于 0 ~ 100 来说,几乎就是 1/4 的概率,所以就可以通过这个函数来随机化得到一个层数。不过使用了 rand() 函数别忘记在构造时设置一个随机数种子哦。
cpp
int RandomLevel()
{
int level = 1;
while (rand() < RAND_MAX * _p && level < _Maxlevel)
{
++level;
}
return level;
}
//得到插入或者删除节点前所有层的前节点数组的函数
vector<Node*> FindPrev(int num)
{
int level = _head->_nextV.size() - 1;
//插入的核心就在于找到当前插入节点所有层的前一个节点,然后改变指针指向即可
vector<Node*> prevV(level + 1, _head);
Node* cur = _head;
//找到所有层的前节点
while (level >= 0)
{
if (cur->_nextV[level] && cur->_nextV[level]->_val < num)
{
cur = cur->_nextV[level];
}
else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val >= num)
{
prevV[level] = cur;
--level;
}
}
return prevV;
}
void add(int num)
{
vector<Node*> prevV = FindPrev(num);
int n = RandomLevel();
if (n > _head->_nextV.size())
{
_head->_nextV.resize(n, nullptr);
prevV.resize(n, _head);
}
//改变链接关系
Node* newnode = new Node(num, n);
for (size_t i = 0; i < n; i++)
{
newnode->_nextV[i] = prevV[i]->_nextV[i];
prevV[i]->_nextV[i] = newnode;
}
}另外这里提一嘴,可以看到在 FindPrev 函数中,我们返回的直接就是传值返回,在 C++98 之前这里就是拷贝构造,但是在 C++11 及之后这里就可以移动构造了,大大提高了效率。
2.5 跳表的删除
跳表的删除与单链表的删除本质上也没什么区别,就是找到要删除的节点,然后改变前后的连接关系。所以跳表删除节点的核心与插入是类似的,就是找到要删除的节点以及删除节点每一层前的所有节点。
但是这两点可以转化为一个问题,就是找到删除节点每一层的前节点。因为要删除节点第 1 层的前节点的 _nextV0 指向的其实就是要删除的节点;如果要删除的节点不存在,这个 _nextV0 也为空或者 _nextV0->_val > num。所以我们只要找到要删除节点每一层的前节点,就可以解决删除节点的问题。
cpp
bool erase(int num)
{
//也需要找到删除节点的所有前置节点
vector<Node*> prevV = FindPrev(num);
if (prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_val > num)
{
//没找到
return false;
}
Node* del = prevV[0]->_nextV[0];
//改变链接关系
int level = del->_nextV.size();
for (size_t i = 0; i < level; i++)
{
prevV[i]->_nextV[i] = del->_nextV[i];
}
delete del;
//改变头节点层数
int j = _head->_nextV.size() - 1;
while (j >= 0)
{
if (_head->_nextV[j])
break;
else
{
--j;
}
}
_head->_nextV.resize(j + 1);
if (_head->_nextV.size() == 0)
_head->_nextV.resize(1, nullptr);
return true;
}2.6 跳表实现代码
cpp
struct SkiplistNode
{
int _val;
vector<SkiplistNode*> _nextV;
SkiplistNode(int val, int level)
: _val(val)
, _nextV(level, nullptr)
{}
};
class Skiplist
{
using Node = SkiplistNode;
public:
Skiplist()
{
srand(time(nullptr));
//头节点先给 1 层
_head = new Node(-1, 1);
}
bool search(int target)
{
//从头节点最顶层开始查找
int level = _head->_nextV.size() - 1;
Node* cur = _head;
//最坏就是找到最后一层
while (level >= 0)
{
// 如果 cur 当前层的下一个节点不为空并且值比 target 小,那就向后走
if (cur->_nextV[level] && cur->_nextV[level]->_val < target)
{
cur = cur->_nextV[level];
}
//如果 cur 当前层的下一个节点为空或者比 target 大,那就向下走
else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val > target)
{
--level;
}
else
{
return true;
}
}
return false;
}
int RandomLevel()
{
int level = 1;
while (rand() < RAND_MAX * _p && level < _Maxlevel)
{
++level;
}
return level;
}
//得到插入或者删除节点前所有层的前节点数组的函数
vector<Node*> FindPrev(int num)
{
int level = _head->_nextV.size() - 1;
//插入的核心就在于找到当前插入节点所有层的前一个节点,然后改变指针指向即可
vector<Node*> prevV(level + 1, _head);
Node* cur = _head;
//找到所有层的前节点
while (level >= 0)
{
if (cur->_nextV[level] && cur->_nextV[level]->_val < num)
{
cur = cur->_nextV[level];
}
else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val >= num)
{
prevV[level] = cur;
--level;
}
}
return prevV;
}
void add(int num)
{
vector<Node*> prevV = FindPrev(num);
int n = RandomLevel();
if (n > _head->_nextV.size())
{
_head->_nextV.resize(n, nullptr);
prevV.resize(n, _head);
}
//改变链接关系
Node* newnode = new Node(num, n);
for (size_t i = 0; i < n; i++)
{
newnode->_nextV[i] = prevV[i]->_nextV[i];
prevV[i]->_nextV[i] = newnode;
}
}
bool erase(int num)
{
//也需要找到删除节点的所有前置节点
vector<Node*> prevV = FindPrev(num);
if (prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_val > num)
{
//没找到
return false;
}
Node* del = prevV[0]->_nextV[0];
//改变链接关系
int level = del->_nextV.size();
for (size_t i = 0; i < level; i++)
{
prevV[i]->_nextV[i] = del->_nextV[i];
}
delete del;
//改变头节点层数
int j = _head->_nextV.size() - 1;
while (j >= 0)
{
if (_head->_nextV[j])
break;
else
{
--j;
}
}
_head->_nextV.resize(j + 1);
if (_head->_nextV.size() == 0)
_head->_nextV.resize(1, nullptr);
return true;
}
private:
Node* _head;
int _Maxlevel = 32;
double _p = 0.25;
};3 跳表与其他查找结构的对比
高效率的查找结构其实很多,包括二叉平衡树(AVL树、红黑树)、哈希表、B 树系列以及本篇文章讲解的跳表。但是他们各有优劣:
| | 查找效率 | 优势 | 劣势 | 应用场景 |
| 二叉平衡树 | O(logn) | 有序、结构稳定 | 结构与实现复杂、空间消耗相比跳表更大 | map 与 set |
| B 树系列 | O(logn),但是高度很低 | 多路平衡、高度更低 | 实现复杂、空间消耗大 | MySQL 索引 |
| 哈希表 | O(1),最坏 O(n) | 查找极快、插入删除快 | 无序、极端哈希冲突下效率退化 | unordered_map 与 unordered_set |
| 跳表 | 平均 O(logn) | 结构与实现简单、有序 | 概率控制、极端情况下效率退化 | Redis 中的 ZSet 数据类型 |
|---|---|---|---|---|
| [查找数据结构对比] |
总之,跳表相比其他查找数据结构,其优势就是实现简单,并且空间消耗更少 ,这种优势使得其可以成为 Redis 内存数据库 ZSet 数据类型底层实现的首选。