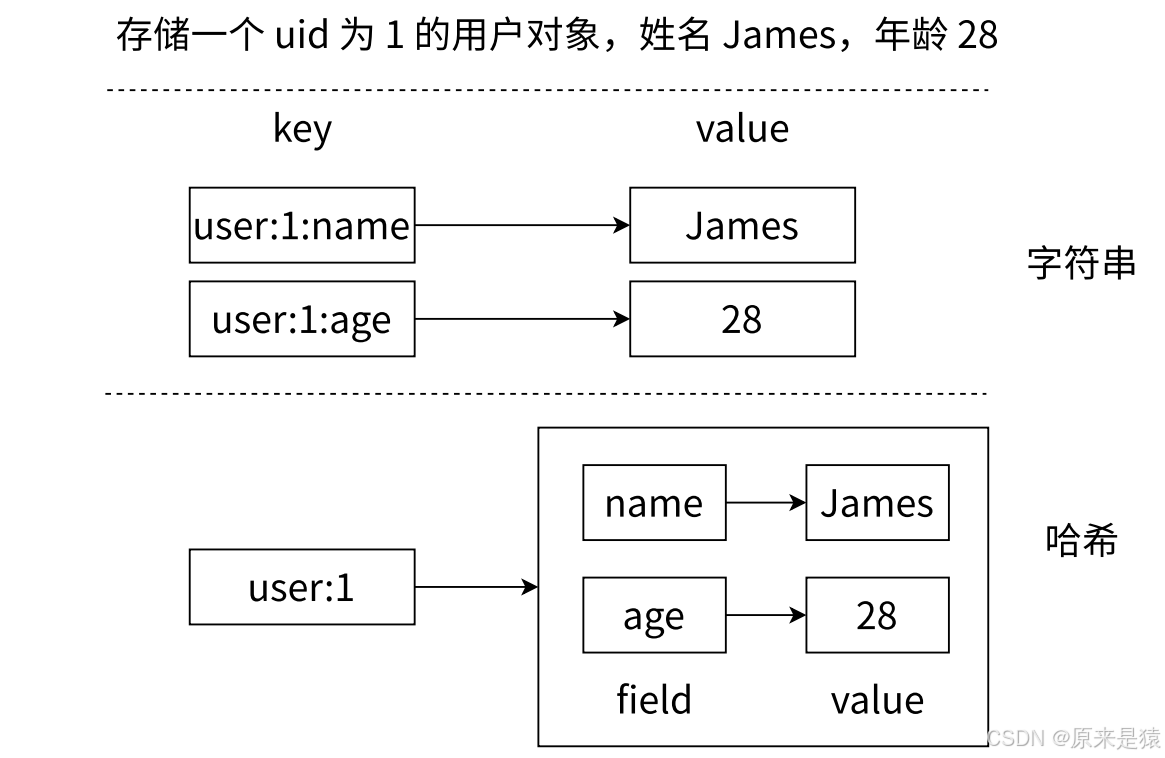
几乎所有的主流编程语言都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组、映射。在redis中,哈希类型是指值本身又是一个键值对结构,形如 key = "key" , value = {{filed1,value1},....,{filedN,valueN}},Redis键值对和哈希类型二者的关系可以用下图来表示。
1. 为什么需要 Hash?
在 Redis 中,String 类型虽然万能,但如果你要存储一个"用户对象",比如:
{
"id": 1001,
"name": "张三",
"age": 28,
"city": "北京"
}用 String 存,要么序列化成 JSON 字符串(整体存取,更新某个字段不方便),要么拆成多个独立的 key(比如 user:1001:name、user:1001:age......这样 key 太多,管理麻烦)。
这时 Hash 类型就派上了用场。
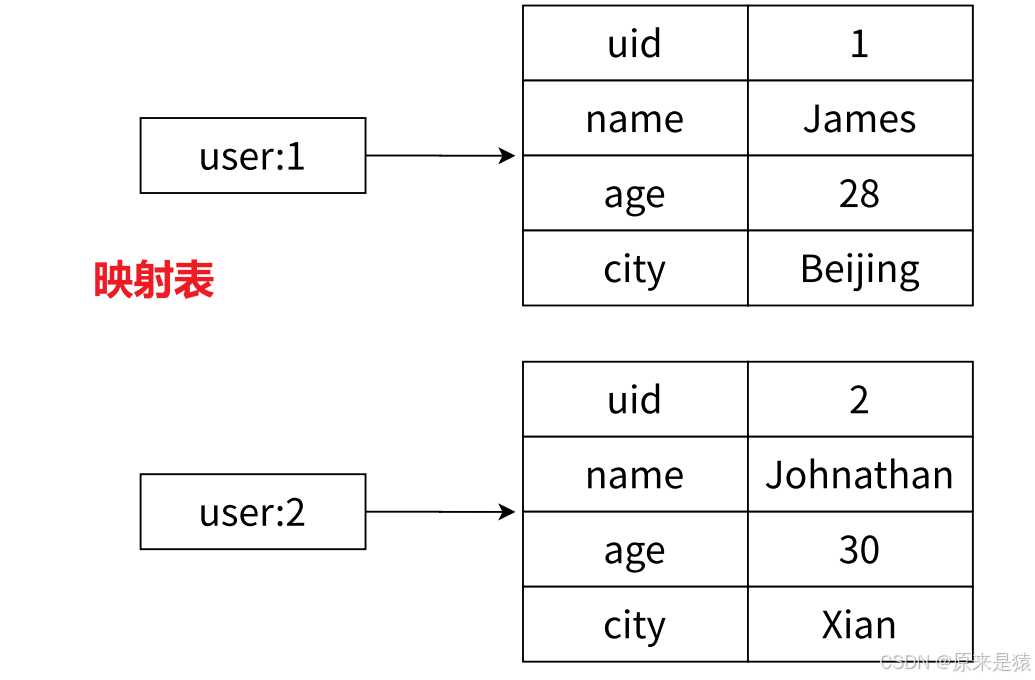
Hash 相当于一个 String 类型的 field-value 映射表,你可以把它理解为一个"对象",每个 field 是属性名,value 是属性值。
在 Redis 中,一个 Hash 的 key 对应一个整体,而这个整体内部又包含多个
field-value对。
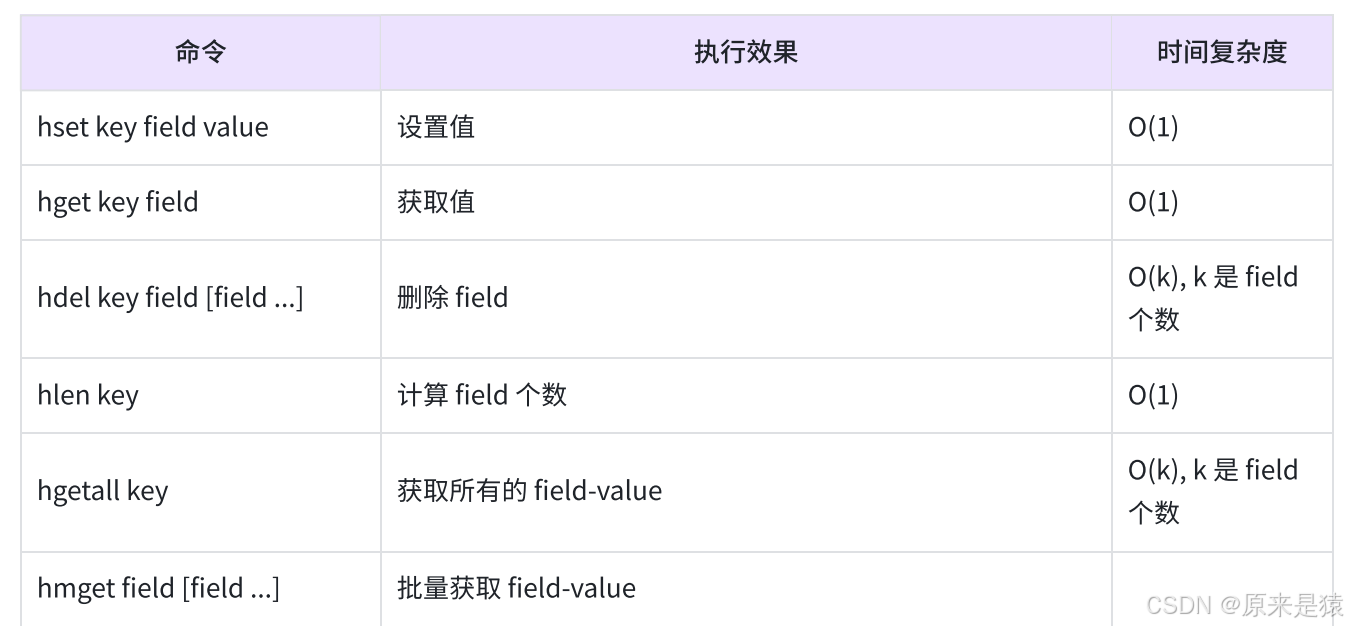
2. Hash 的基本命令
我们从最常用的命令开始,逐步深入。
2.1 HSET -- 设置字段值
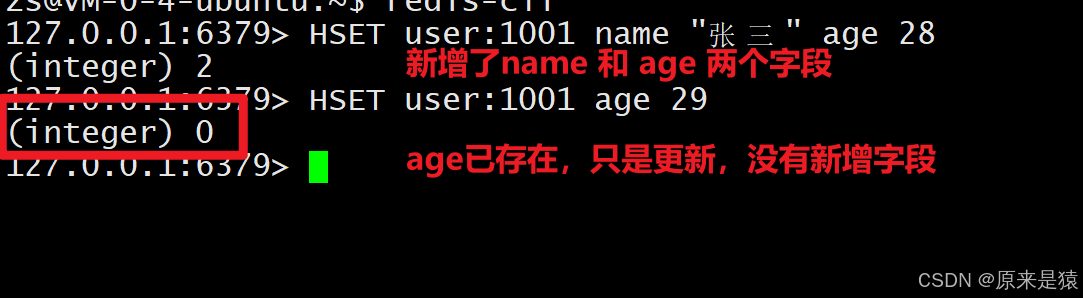
HSET key field value [field value ...]-
作用:给指定的 Hash 设置一个或多个字段的值。
-
如果字段已存在,会覆盖旧值。
-
返回:本次新增的字段个数(不包含更新)。
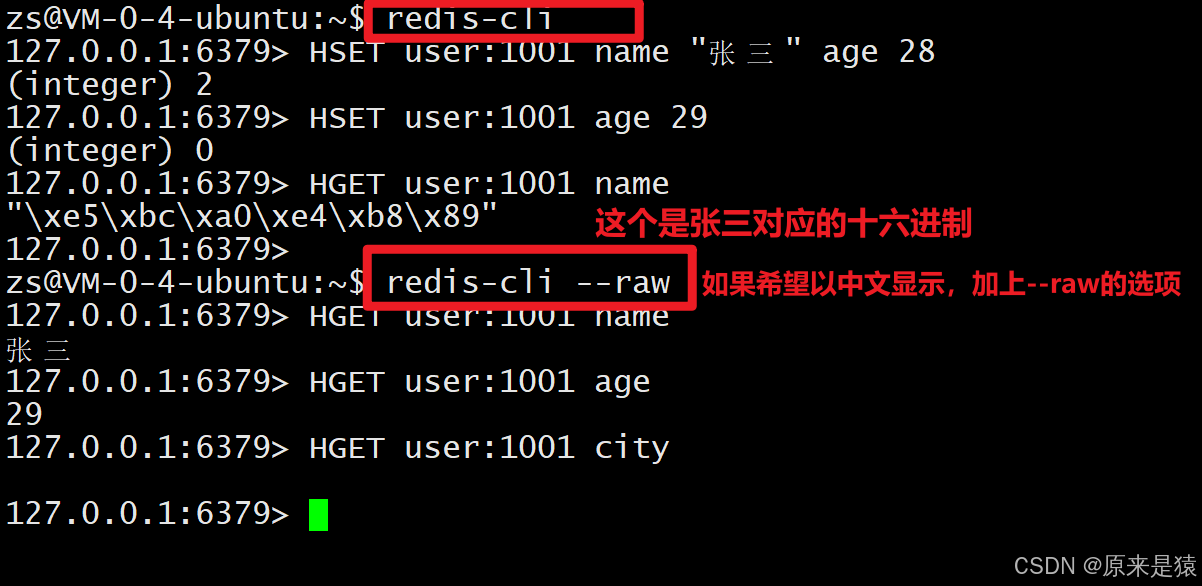
2.2 HGET -- 获取单个字段值
HGET key field- 返回 field 对应的 value,如果 field 不存在返回
nil。
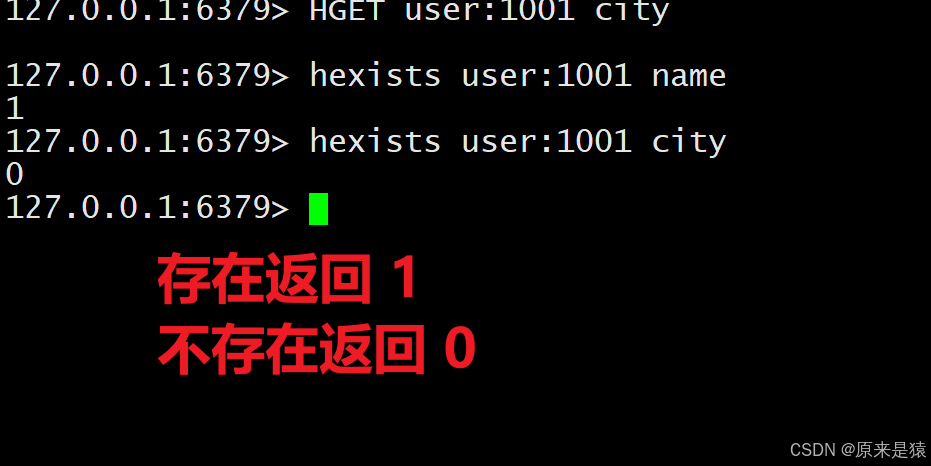
2.3 HEXISTS -- 判断字段是否存在
HEXISTS key field- 返回 1 表示存在,0 表示不存在。
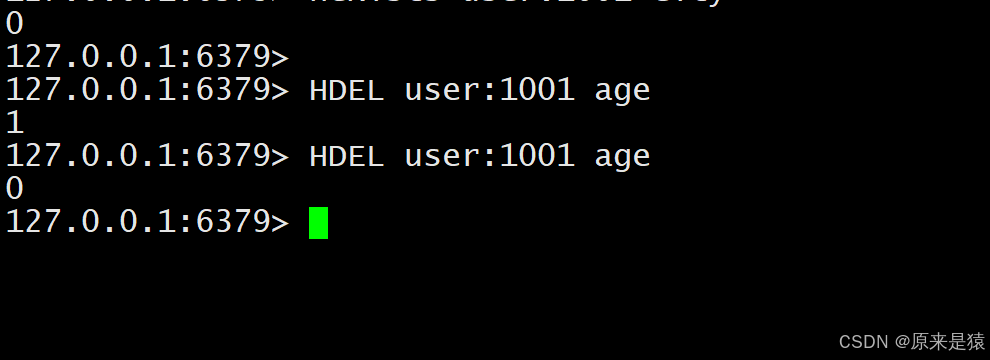
2.4 HDEL -- 删除一个或多个字段
HDEL key field [field ...]- 删除指定字段**,返回成功删除的个数。**
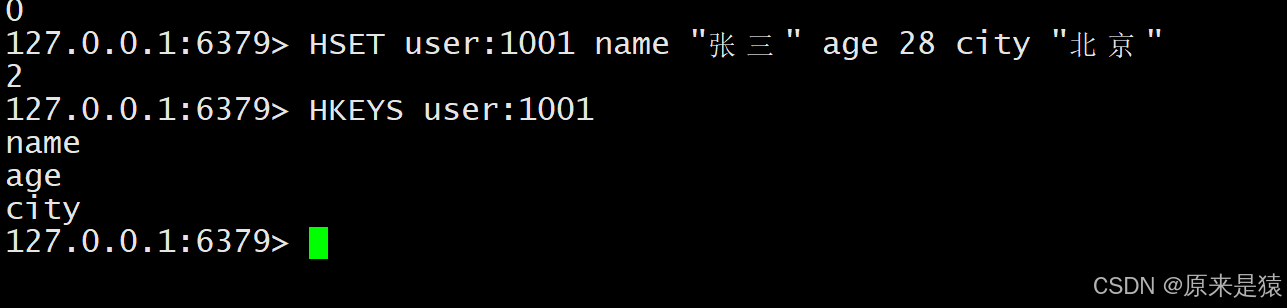
2.5 HKEYS -- 获取所有字段名
HKEYS key- 返回 Hash 中所有 field 的列表(顺序不保证)。
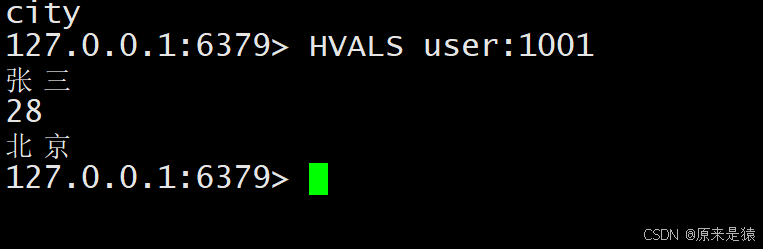
2.6 HVALS -- 获取所有字段值
HVALS key- 返回 Hash 中所有 value 的列表,顺序与
HKEYS对应。
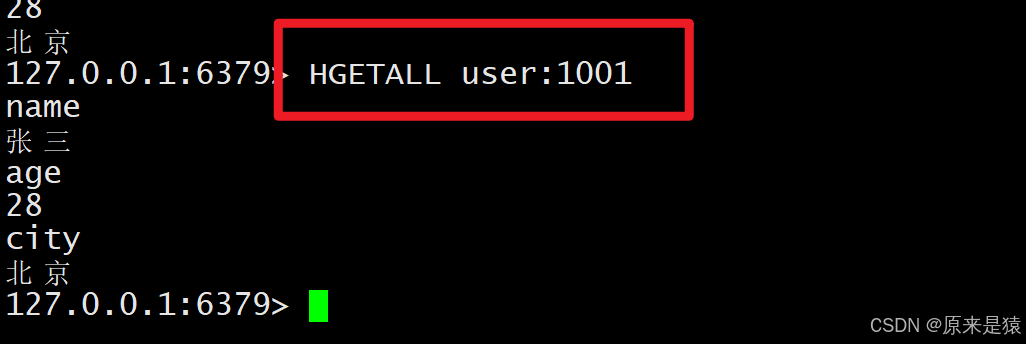
2.7 HGETALL -- 获取所有字段和值
HGETALL key- 返回 field 和 value 交替排列的列表**(奇数位是 field,偶数位是 value)。**
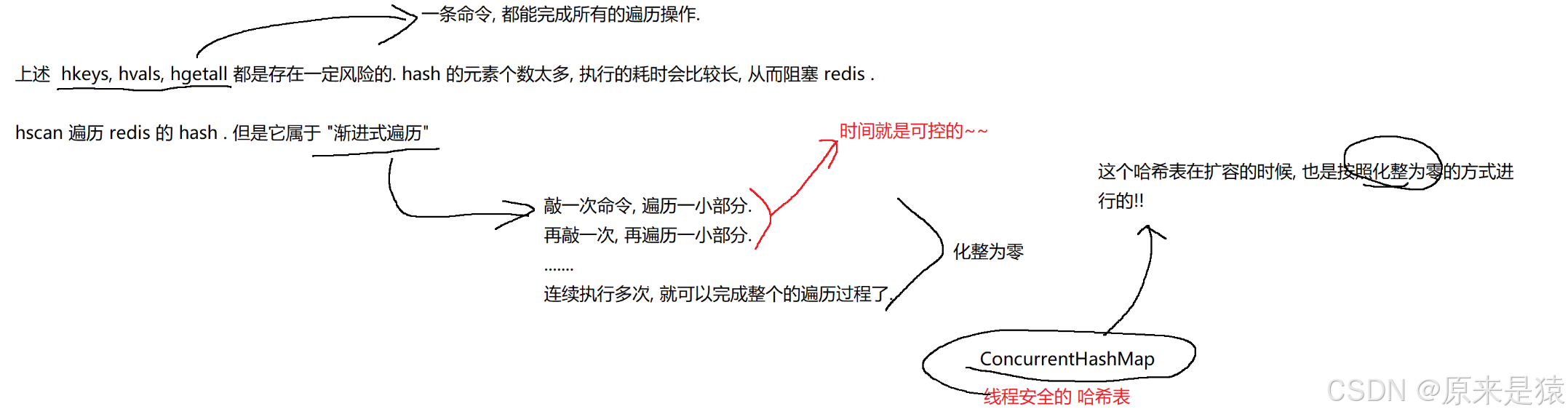
⚠️ 注意 :如果 Hash 中字段非常多(比如成千上万),使用 HGETALL 可能会阻塞 Redis(因为它是 O(N) 的)。建议只在字段数较少时使用,或使用 HSCAN 渐进式遍历。
2.8 HMGET -- 批量获取多个字段
HMGET key field [field ...]- 返回指定字段的值列表,不存在的字段返回 nil。
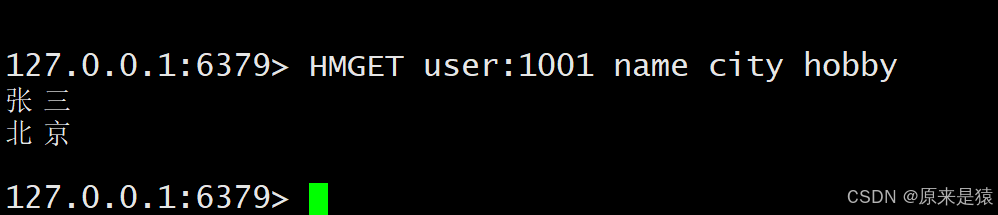
相比多次HGET,HMGET能一次取多个值,减少网络往返
2.9 HLEN -- 获取字段个数
HLEN key- 返回 Hash 中field 的总数。

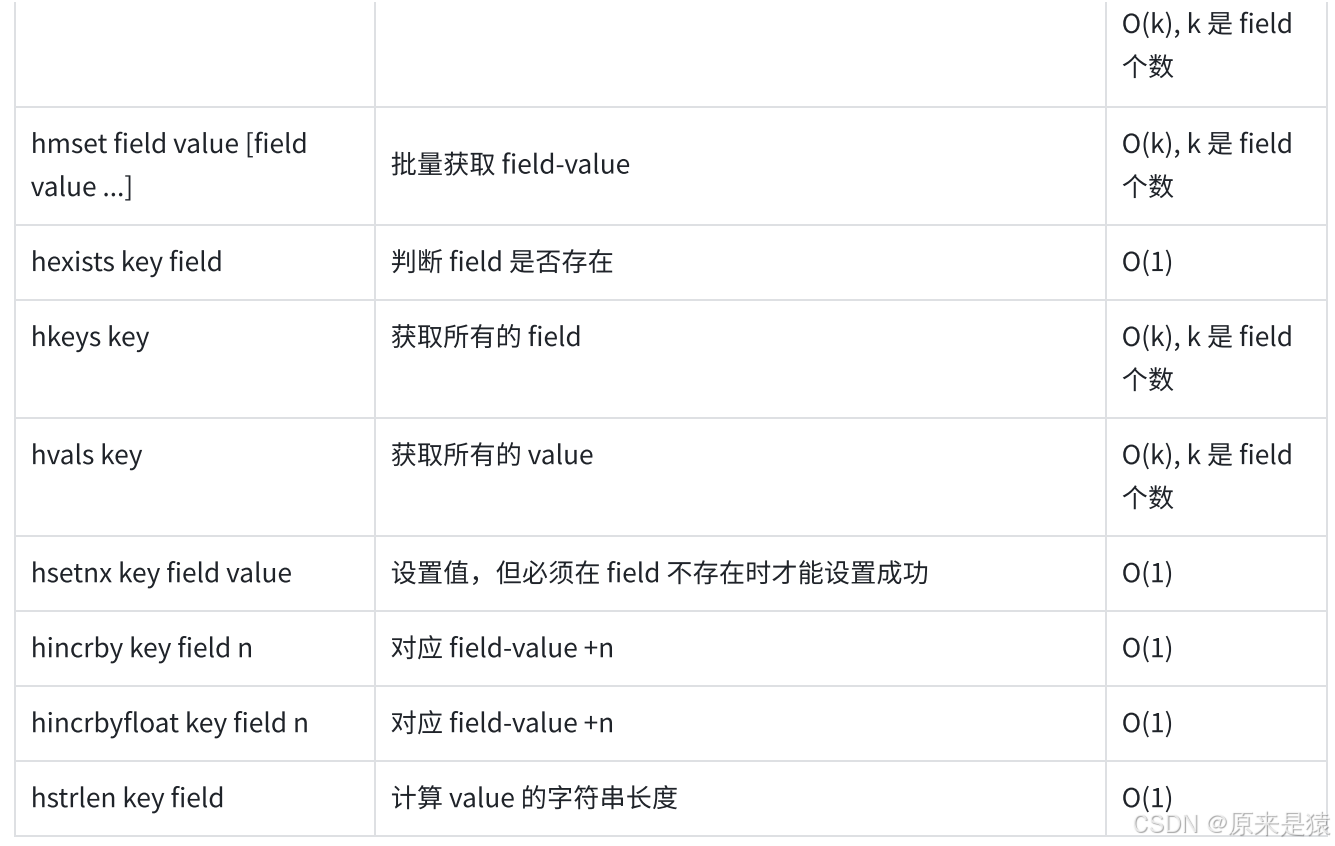
2.10 HSETNX -- 字段不存在时设置
HSETNX key field value-
只在 field 不存在时才设置,若 field 已存在则什么都不做。
-
返回 1 表示设置成功,0 表示失败。
127.0.0.1:6379> HSETNX user:1001 email "zhangsan@qq.com"
(integer) 1 # 设置成功127.0.0.1:6379> HSETNX user:1001 email "new@qq.com"
(integer) 0 # 已存在,未修改127.0.0.1:6379> HGET user:1001 email
"zhangsan@qq.com"
2.11 HINCRBY -- 整数自增/自减
HINCRBY key field increment-
将 Hash 中某个字段**(必须是整数)增**加
increment(可以为负数)。 -
若字段不存在,会先初始化为 0,再执行操作。
-
返回操作后的新值。
127.0.0.1:6379> HSET user:1001 score 100
(integer) 1127.0.0.1:6379> HINCRBY user:1001 score 10
(integer) 110127.0.0.1:6379> HINCRBY user:1001 score -20
(integer) 90127.0.0.1:6379> HINCRBY user:1001 views 1 # views 不存在,先初始化为0
(integer) 1
非常适用于计数器(比如博客阅读量、商品浏览量)的场景。
2.12 HINCRBYFLOAT -- 浮点数自增/自减
HINCRBYFLOAT key field increment-
与
HINCRBY类似,但支持浮点数。127.0.0.1:6379> HSET user:1001 balance 100.5
(integer) 1127.0.0.1:6379> HINCRBYFLOAT user:1001 balance 0.3
"100.8"127.0.0.1:6379> HINCRBYFLOAT user:1001 balance -5.2
"95.6"
3. 内部编码(了解就好)
Redis 内部对 Hash 有两种编码方式:
-
ziplist(压缩列表):当字段数较少(默认 < 512)且所有值长度较短(默认 < 64 字节)时使用,节省内存。
-
hashtable(哈希表):当字段数较多或值较大时使用,读写效率高(O(1))。
你可以用 OBJECT ENCODING key 查看当前编码:

这种内部实现对你来说是无感知的,但了解它能帮助你理解为什么 Hash 在小对象时很省内存。
4. 实战场景
4.1 缓存用户信息(最经典)
正如开头的例子,用 Hash 存储用户对象,每个用户一个 key,字段对应属性。
优点:
-
直观,易于理解。
-
可以单独更新某个属性(比如修改年龄),不需要整体覆盖。
-
批量获取(
HMGET)也很方便。
4.2 购物车
每个用户一个购物车 key,字段是商品 ID,值是购买数量。
HSET cart:1001 item_123 2
HSET cart:1001 item_456 1
HINCRBY cart:1001 item_123 1 # 增加一件
HLEN cart:1001 # 购物车商品种类数
HDEL cart:1001 item_456 # 删除某商品4.3 计数器分组
比如统计每种文章的每日阅读量,可以用 article:2025-03-21 作为 key,字段是文章 ID,值是阅读数。用 HINCRBY 轻松实现自增。
5. 注意事项
-
不要滥用
HGETALL:如果 Hash 很大(成千上万字段),HGETALL会一次性返回所有数据,可能导致 Redis 阻塞。建议使用HSCAN渐进式遍历,或只获取部分字段(HMGET)。 -
字段名和值尽量短 :短字段名和短值可以触发
ziplist编码,节省内存。但也不必过度优化,可读性更重要。 -
Hash 不适合存储太大的对象:单个 Hash 最多可存储 2^32-1 个字段,但若单个 value 过大(比如几 MB),建议用 String 序列化存储,因为 Hash 对大 value 的编码效率不高。
-
更新频繁的单个字段用
HSET或HINCRBY,避免整体读写。