前言:从"万能银弹"到"底层组件"的范式转变
打开 2026 年各大 AI 技术社区、技术沙龙,一个非常直观的变化正在发生:曾经霸占 AI 落地赛道、人人张口必谈的 RAG(检索增强生成,Retrieval-Augmented Generation),行业热度肉眼可见地快速回落。
回溯 2023--2024 年,RAG 是解决大模型幻觉、突破上下文限制、落地企业私有知识库的 "万能银弹",几乎所有 ToB AI 项目都会优先搭建向量检索 + 文档增强链路。但时至今日,技术圈讨论重心彻底转移,Agent(智能体) 、Skill(技能封装) 、MCP(Model Context Protocol,模型上下文协议) 成为新的高频关键词,大量新项目不再优先落地传统 RAG,不少存量 RAG 系统也在向 Agent 架构重构迭代。
随之而来行业出现一种片面论调:RAG 过气了,会被 Agent 彻底淘汰?
本文给出核心结论:RAG 从未消亡,只是随着 AI 技术范式迭代,褪去了全能光环,回归到它最适配的细分定位。 热度消退的底层逻辑,是被动检索的单点 RAG 架构,正在被主动执行、多能力协同的 Agent 生态系统性升级。下文从技术演进脉络逐层拆解,兼顾底层原理与工程落地视角。
一、复盘:RAG 诞生之初,到底解决了哪些核心痛点?
想要客观看待 RAG 降温,必须先理清它崛起的时代背景。大模型早期原生存在两大致命短板,RAG 作为轻量外挂方案,精准补齐缺陷,才成为 AI 落地标配。
1.1 突破上下文窗口枷锁,低成本接入私有/时效性知识
初代大模型上下文容量极其有限,早期 GPT-3 仅 2048 token,开源底座大多卡在 4k 以内,无法加载企业海量合同、行业手册、内部业务文档。模型知识固化在训练数据集,无法适配企业专属数据、实时更新的业务资料。
RAG 通过 「文档切片→向量化入库→相似度检索→上下文注入 Prompt」 的架构,无需改动模型权重,推理时动态调取外部私有知识,完美解决模型知识滞后、私有化落地难的问题。
传统方案 vs RAG 方案对比:
传统微调方案:
训练数据收集 → 数据标注 → GPU 算力投入 → 模型微调 → 部署上线
周期:数周至数月 | 成本:数十万至数百万
RAG 方案:
文档解析 → 向量化 → 存入向量库 → 检索增强推理
周期:数小时至数天 | 成本:数千至数万1.2 强力抑制大模型幻觉,输出内容可溯源
原生大模型基于概率分布生成文本,极易凭空捏造数据、编造政策条款、混淆专业参数,幻觉问题是严肃 ToB 场景(金融、法律、政务)落地最大阻碍。
RAG 的核心约束在于:模型生成内容全部基于检索返回的真实文档片段,每一段输出都能绑定原文来源,大幅降低事实错误概率,让 AI 回答具备业务可信性。
python
# RAG 典型响应格式示例
{
"answer": "外网连接内网怎么操作。",
"sources": [
{
"document": "连接内网操作手册.pdf",
"page": 12
}
]
}1.3 替代高成本微调,降低中小团队落地门槛
在 RAG 普及前,想要让模型掌握行业知识,唯一路径是有监督微调:需要标注数据集、高额 GPU 算力、反复调参规避过拟合,迭代成本极高。RAG 属于零训练、即插即用方案:更新知识库仅需新增文档、增量构建向量索引,不用重新训练模型,中小企业零门槛即可搭建私有问答系统。
依靠以上三点优势,RAG 在两年内席卷全行业,成为知识库问答、智能客服、文档解析、行业咨询的标准技术方案。
二、深度拆解:传统 RAG 与生俱来的架构瓶颈
RAG 的火爆是技术过渡期的必然选择,但它的底层架构设计存在先天性短板。随着大模型能力迭代、业务需求从「简单单轮问答」升级为「多步骤复杂业务闭环」,RAG 的缺陷被持续放大,这也是热度下滑的根本原因。
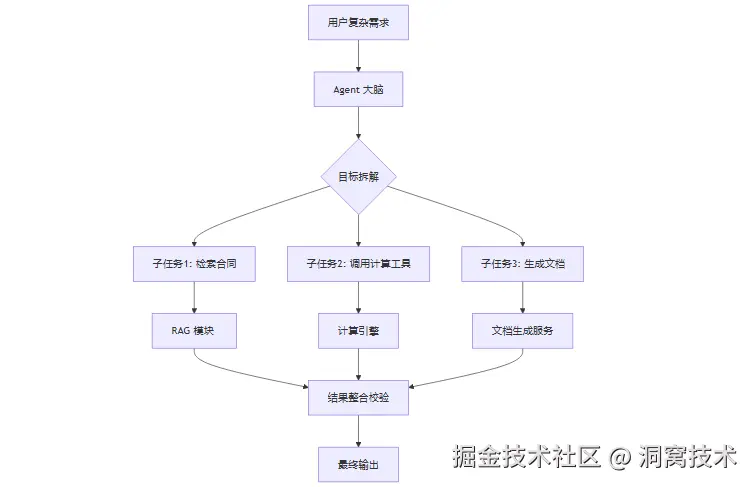
2.1 纯被动检索链路,无自主推理与任务编排能力
传统 RAG 标准流程如下:

整条链路是单点、线性、被动响应,不存在自主思考、目标拆解、多轮迭代、异常重试逻辑。它只能做「信息检索 + 文本整合」,面对需要分步执行的复杂需求(如 "查合同条款→计算违约金→生成整改通知")无能为力,只能输出碎片化信息,无法完成端到端业务闭环。
对比 Agent 架构:
2.2 检索精度存在天然天花板,上下文污染难以根治
RAG 效果高度依赖文档切分策略、向量模型、重排算法、阈值调优,工程落地普遍存在大量痛点:
| 问题类型 | 具体表现 | 影响程度 |
|---|---|---|
| 切片粒度失衡 | 过长片段冗余噪声多,过短丢失上下文语义 | 高 |
| 相似度匹配偏差 | 语义相近但无关文档被召回,挤占有效 Token | 高 |
| 无自主过滤机制 | 检索到垃圾数据后,模型会被误导,反而加重幻觉 | 中 |
| 跨段落信息割裂 | 关键信息分散在多个片段,单独检索无法完整获取 | 高 |
| 多跳推理缺失 | 需要关联多个文档才能得出的结论,RAG 无法实现 | 高 |
一旦检索链路出现偏差,整套系统输出全部失真,且 RAG 无法自主校验、修正检索错误,容错率极低。
2.3 运维链路冗长,动态数据适配能力薄弱
一套企业级完整 RAG 系统包含以下七大模块:
-
文档解析器:处理 PDF、Word、Excel、PPT 等多种格式
-
文本分块:制定切分策略,平衡粒度与语义完整性
-
向量化服务:调用 Embedding 模型生成向量
-
向量数据库:存储和检索向量索引
-
召回重排:对初步召回结果进行精排序
-
增量更新:处理文档变更时的索引同步
-
来源溯源:记录每段内容的原始出处
开发与运维成本居高不下。业务文档、实时业务数据变更时,需要重新切片、入库、重建索引,很难做到毫秒级实时同步;同时 RAG 仅支持非结构化纯文本,无法直接对接数据库、业务 API、第三方工具,场景边界极其狭窄。
2.4 大模型原生能力进化,压缩 RAG 基础使用场景
近两年主流底座上下文窗口实现跨越式提升:
| 模型 | 上下文窗口 | 发布时间 |
|---|---|---|
| GPT-3 | 2,048 tokens | 2020 |
| GPT-4 Turbo | 128,000 tokens | 2023 |
| Claude 3 | 200,000 tokens | 2024 |
| Gemini 1.5 Pro | 2,000,000+ tokens | 2024 |
| GLM-5 | 1,000,000+ tokens | 2025 |
GLM-5、Llama 4、Gemini 全系支持百万级上下文,可直接加载整本行业手册、批量业务文档,无需切片检索;同时大模型原生事实校验、长文本理解能力大幅优化,基础幻觉问题显著缓解。大量简单问答场景,直接把完整文档塞入 Prompt 的效果,已经优于传统粗粒度 RAG,RAG 基础使用场景被持续挤压。
三、范式跃迁:Agent + Skill + MCP 为何能替代大部分传统 RAG 场景?
大模型原生能力升级只是外因,Agent+Skill+MCP 三位一体的新架构,才是重构 AI 应用范式的核心内因。这套组合从底层解决了 RAG 所有先天缺陷,实现从「被动查资料」到「主动完成任务」的技术升级。
3.1 Agent:赋予大模型自主规划、迭代执行的智能主体
和 RAG 单次线性调用不同,AI Agent 的核心是思维链拆解、工具决策、多轮迭代、结果自校验。面对复杂需求时,Agent 会自主完成:
-
目标拆解:把复杂任务拆分为多个可执行子步骤
-
能力判断:识别当前需要调用检索、工具、数据库还是业务接口
-
循环执行:分步调用对应能力,处理报错、重试异常
-
结果整合校验:汇总多渠道信息,自查逻辑与事实错误后输出
简单对比:
| 维度 | RAG | Agent |
|---|---|---|
| 执行模式 | 单次线性检索 | 多轮迭代规划 |
| 任务范围 | 静态问答 | 复杂业务闭环 |
| 错误处理 | 无自主修正能力 | 可重试、可回退 |
| 工具调用 | 仅向量检索 | 可调用任意 API/工具 |
| 输出形式 | 文本答案 | 结构化数据/操作结果 |
企业自动化流程、多环节业务办理、复杂数据分析等场景,天然适配 Agent 架构,传统 RAG 完全无法覆盖。
3.2 Skill:标准化结构化能力,替代规则类文档检索
Skill 是 Agent 封装的标准化原子能力,对应固定业务逻辑、规则、流程、参数。对于企业大量可标准化内容(考勤制度、审批流程、产品参数、固定计算公式),完全不需要通过 RAG 检索碎片化文档:直接封装成 Skill,Agent 调用即可精准返回结果。
对比 RAG 检索文档的模式:
| 维度 | Skill | RAG |
|---|---|---|
| 响应速度 | 毫秒级 | 秒级(含检索耗时) |
| 结果稳定性 | 确定性输出 | 受检索质量影响 |
| 版本管控 | 易于管理 | 难以追踪变更 |
| 适用场景 | 结构化规则 | 非结构化文档 |
由此形成清晰技术分界:结构化、规则稳定的业务场景,由 Skill 承接;海量碎片化、无固定规则的非结构化资料,才交由 RAG 处理。
3.3 MCP(Model Context Protocol):统一资源调度底座,打通 RAG 孤立检索壁垒
MCP 模型上下文协议是当前 Agent 生态的核心基础设施,作用是统一模型、工具、数据库、知识库、外部服务的交互标准。
传统 RAG 是一条孤立的静态文本检索链路,只能读取离线文档,无法联动业务系统;基于 MCP 协议,Agent 可以一站式调度:
-
Skill 工具
-
关系型数据库
-
实时接口
-
向量知识库
-
第三方插件
实现 「语义检索 + 逻辑计算 + 业务操作 + 实时数据查询」 全链路协同。
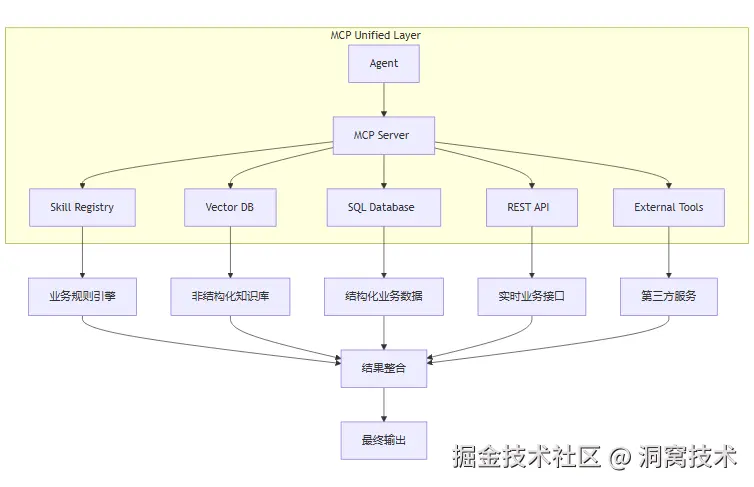
MCP 彻底解决 RAG 只能读取静态文档、无法联动业务系统、无法处理动态实时数据的致命短板,是企业级复杂 AI 系统的必备底座。
四、客观定论:RAG 没有死亡,只是回归了它本该有的定位
行业讨论热度下降 ≠ 技术被淘汰。恰恰相反,热度降温是 AI 工程体系走向成熟的标志。RAG 褪去 "万能方案" 的泡沫,成为 Agent 架构里不可或缺的底层配套组件,而非独立完整业务系统。
4.1 在 Agent 生态中,RAG 依然拥有不可替代的三大核心价值
价值一:海量非结构化历史数据唯一检索方案
企业沉淀的百万级合同、历史邮件、行业白皮书、零散资讯无法标准化封装为 Skill,只能依靠向量 RAG 做语义召回,为 Agent 提供原始上下文素材。
价值二:Agent 动态知识更新的底层底座
Skill 适配固定不变的业务规则,而实时新闻、新增文档、动态业务资料需要依靠 RAG 增量更新,弥补结构化 Skill 无法灵活扩容知识的短板。
价值三:高合规场景溯源的最优解
金融、法律、政务等强监管场景,要求 AI 输出每一句话都绑定原文出处。RAG 天然携带文档来源链路,是满足合规审计、事实溯源需求的最低成本方案,无可替代。
4.2 未来分层落地架构(行业通用标准)
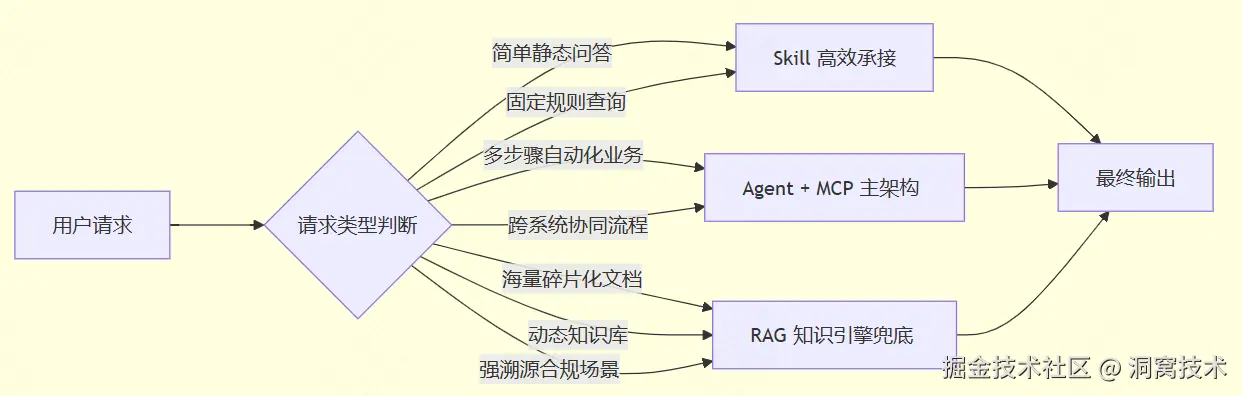
技术演进的核心逻辑不是 "新方案淘汰旧方案",而是分层适配、互补协同。
| 组件 | 角色定位 | 核心价值 |
|---|---|---|
| Agent | 系统大脑 | 自主规划、任务编排、多轮迭代 |
| Skill | 标准化手脚 | 快速响应、确定性输出、易维护 |
| MCP | 统一调度总线 | 资源整合、协议标准化、扩展性强 |
| RAG | 非结构化知识库入口 | 语义检索、动态更新、合规溯源 |
四者共同构成完整 AI 应用体系。
五、行业案例:从 RAG 到 Agent 架构的迁移实践
5.1 某金融机构智能投顾系统重构
背景: 该机构早期采用纯 RAG 架构搭建智能投顾系统,用于回答客户关于理财产品、市场资讯、政策解读等问题。
遇到的问题:
-
客户询问 "帮我分析这只基金的风险并推荐替代产品" 时,RAG 只能返回相关文档片段,无法完成分析和推荐
-
市场数据实时变化,RAG 索引更新延迟导致推荐过时
-
合规要求每次推荐必须引用最新监管文件,RAG 检索准确率不稳定
重构方案:
-
引入 Agent 作为核心控制器,拆解用户需求为:风险评测→产品检索→合规校验→生成报告
-
将固定的风险评估模型封装为 Skill
-
通过 MCP 对接实时行情 API 和监管文件向量库
-
RAG 仅负责非结构化研报和监管文档的语义检索
效果:
-
复杂需求完成率从 35% 提升至 92%
-
响应时间从平均 8 秒降至 3 秒(Skill 承担大部分简单查询)
-
合规审计通过率从 78% 提升至 99.5%
5.2 某制造企业智能客服系统升级
背景: 该企业使用 RAG 搭建产品售后客服系统,涵盖产品手册、故障排查指南、维修记录等知识库。
遇到的问题:
-
用户描述故障现象后,RAG 只能返回相关文档,无法引导用户逐步排查
-
需要结合用户购买记录、保修状态等业务数据时,RAG 无法对接
-
常见问题重复检索,浪费资源
重构方案:
-
将常见故障排查流程封装为 Skill(如 "打印机卡纸处理流程")
-
Agent 根据用户描述自主决定:调用 Skill → 查询业务系统 → RAG 检索罕见案例
-
MCP 统一对接 CRM 系统和产品知识库
效果:
-
首次解决率从 45% 提升至 82%
-
人工转接率下降 60%
-
系统运维成本降低 40%
六、给开发者的落地建议
基于上述分析,给出一套可操作的落地建议:
6.1 摒弃 "RAG 万能" 的老旧思维
不要所有场景一刀切搭建向量库。先梳理业务需求类型:
markdown
需求分类决策树:
你的需求是什么类型?
├── 固定规则查询(如:请假政策、产品价格)
│ └── → 使用 Skill
├── 多步骤业务流程(如:订单退款、审批流转)
│ └── → 使用 Agent + MCP
├── 非结构化文档检索(如:历史合同、行业报告)
│ └── → 使用 RAG
└── 混合场景
└── → Agent orchestrate Skill + RAG + MCP6.2 优先梳理业务规则,稳定标准化流程封装为 Skill
降低检索噪声,提升响应速度和结果稳定性。例如:
python
# Skill 示例:年假计算
class AnnualLeaveSkill:
def execute(self, employee_id: str, request_days: int) -> dict:
# 查询员工入职日期
hire_date = hr_system.get_hire_date(employee_id)
# 计算工龄
years_of_service = calculate_years(hire_date)
# 根据公司政策计算可用年假
if years_of_service < 1:
available_days = 0
elif years_of_service < 5:
available_days = 5
elif years_of_service < 10:
available_days = 10
else:
available_days = 15
# 返回结果
return {
"available_days": available_days,
"requested_days": request_days,
"approved": request_days <= available_days
}6.3 复杂业务以 Agent 为核心,MCP 统一调度各类资源
设计 Agent 的任务规划逻辑,确保其能够正确拆解目标、选择工具、处理异常。
6.4 仅在特定场景引入 RAG 作为底层支撑
-
海量非结构化文档检索
-
动态知识库增量更新
-
合规溯源场景
七、总结与展望
RAG 热度回落的本质,是 AI 行业完成了一次完整技术代际跃迁:从单点检索增强生成的工具时代,迈入智能体自主执行的系统时代。
过去行业疯狂堆砌 RAG,是因为大模型原生能力不足,只能靠外挂检索弥补短板,属于技术过渡期的折中方案;如今 Agent+Skill+MCP 生态成熟,AI 应用从 "问答工具" 升级为 "自动化业务系统",架构更立体、更贴合真实企业复杂需求。
褪去流量喧嚣的 RAG,不再是社区热议的网红技术,却沉淀为 AI 系统不可或缺的底层知识底座。 一项技术褪去泡沫、找准自身边界,恰恰是行业走向成熟最有力的证明。
展望未来,我们可以预见:
-
RAG 将更加精细化:从粗粒度文档检索进化为细粒度知识单元检索,结合图数据库实现多跳推理
-
Agent 将更加专业化:垂直领域 Agent 将涌现,针对特定行业深度优化
-
MCP 将成为行业标准:类似 HTTP 之于 Web,MCP 可能成为 AI 应用互联的基础协议
-
Skill 生态将更加丰富:开源 Skill 市场将出现,开发者可以共享和复用标准化能力
在这个新的技术格局下,RAG 不会消失,而是以更精准、更高效的方式,继续服务于 AI 应用的底层知识需求。