让 Agent 真正"自动干活":Python 脚本化的三根支柱
摘要:Agent 能"看懂"数据、"听懂"需求之后,还差最后一口气------自动干活。每天盯着开源项目有没有发新版、日志里有没有冒出异常,这些重复、有规律的事,正是脚本化的主场。支撑这套自动化的,是三根支柱:批量处理(循环+连接复用)、自动化逻辑(if-else+try-except)、定时执行(schedule→cron)。本文用真实代码把它们一块块拼成完整的"开源情报 Agent"。
目录
- 第一根:批量处理------一次办妥,而不是一个个来
- 第二根:自动化逻辑------会判断、会兜底
- 第三根:定时执行------到点自己动
- [三根支柱搭起来:一个开源情报 Agent](#三根支柱搭起来:一个开源情报 Agent)
- 两件小事,决定脚本是"玩具"还是"工具"
Agent 能"看懂"数据、"听懂"需求之后,还差最后一口气------自动干活。每天盯着几个开源项目有没有发新版、日志里有没有冒出异常、关注的信息源有没有更新,这些重复、有规律、需要定时或批量跑的事,正是脚本化编程的主场,也和 Agent 的执行能力天然契合。
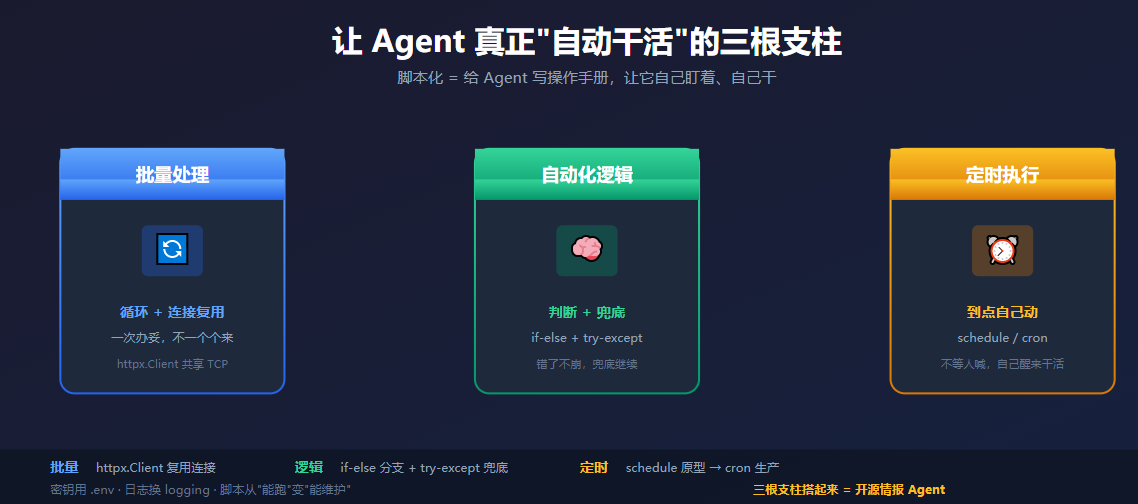
说白了,脚本化就是给 Agent 写一份"操作手册":什么时候做、做什么、怎么做,写清楚,剩下交给它自己跑。支撑这套自动化的,是三根支柱。
第一根:批量处理------一次办妥,而不是一个个来
Agent 经常要同时处理多个对象:多个数据源、多个文件、多个接口。批量处理的核心是**"循环 + 连接复用"**。
一个原创场景:你关注了一批开源项目,想一次性知道它们最近有没有发新版。逐个手动查太蠢,写个脚本批量拉取 GitHub Release 信息,几行就搞定。
python
import httpx
import os
repos = ["python/cpython", "pallets/flask", "psf/requests", "encode/httpx"]
token = os.getenv("GITHUB_TOKEN")
def batch_check_releases(repos: list) -> list:
updates = []
# 关键:用 httpx.Client 复用连接,同一会话内多次请求共享 TCP 连接,
# 省掉重复握手开销,这是批量调用的核心优化
with httpx.Client(timeout=10) as client:
for repo in repos:
try:
resp = client.get(
f"https://api.github.com/repos/{repo}/releases/latest",
headers={"Authorization": f"Bearer {token}"}
)
resp.raise_for_status()
data = resp.json()
updates.append({
"repo": repo,
"tag": data["tag_name"],
"published": data["published_at"][:10]
})
except Exception as e:
updates.append({"repo": repo, "error": str(e)})
return updates打个比方:批量处理就像工厂的流水线 ------不是一个个零件搬来搬去,而是一条传送带依次过,效率天差地别。httpx.Client 就是那条传送带,多次请求共享同一个 TCP 连接,省掉了反复握手的开销。
顺带说一句列表推导式。它通常比 for 循环加 append 更快,因为 CPython 会预分配内存、省掉方法调用开销,但幅度视操作复杂度而定,一般在 20% 到 50% 之间,不是固定数字。逻辑简单时用它又快又优雅,逻辑复杂到要写多行表达式时,老老实实用循环,可读性更重要。
第二根:自动化逻辑------会判断、会兜底
脚本不能"一根筋"。真实世界里文件可能不存在、接口可能超时、数据可能缺字段,只会一条路走到底的脚本跑两次就崩了。if-else 处理不同情况,try-except 接住异常,这和 Agent "根据决策执行、遇错重试或降级"的逻辑是一回事。
换一个原创场景:扫描服务日志,命中关键词就收集起来触发告警。
python
from datetime import datetime
KEYWORDS = ["ERROR", "Traceback", "FATAL"]
def scan_logs(log_file: str) -> list:
try:
alerts = []
with open(log_file, encoding="utf-8") as f:
for lineno, line in enumerate(f, 1):
for kw in KEYWORDS:
if kw in line:
alerts.append({
"line": lineno,
"keyword": kw,
"text": line.strip()
})
if alerts:
print(f"[{datetime.now():%F %T}] 发现 {len(alerts)} 条告警,准备通知...")
# 这里接通知逻辑:发邮件、推 webhook、写数据库都行
else:
print(f"[{datetime.now():%F %T}] 日志干净,无异常")
return alerts
except FileNotFoundError:
print(f"日志文件不存在:{log_file}")
return []
except Exception as e:
print(f"扫描异常:{e}")
return []自动化逻辑就像流水线上的质检员------正常的放行,有问题的拦下来归类,质检员自己生病了也不至于把整条流水线搞停。条件判断让脚本有了"脑子"------知道什么该管、什么该跳过;异常处理让脚本有了"韧性"------错了不崩,兜底继续。这两样加起来,脚本才算从"能跑"变成"可靠地跑"。
第三根:定时执行------到点自己动
很多任务不需要人触发,到点就该跑。最轻量的选择是 schedule 库(pip install schedule,稳定版 1.2.x),语法直白:
python
import schedule
import time
from datetime import datetime
def daily_report():
print(f"[{datetime.now():%F %T}] 开始生成每日情报...")
schedule.every().day.at("09:00").do(daily_report)
while True:
schedule.run_pending()
time.sleep(60)定时执行就是给脚本装了个闹钟------不等人喊,到点自己醒来干活。
但心里要有数:schedule 是单线程串行的,一个任务跑得久会堵住后面的。原型和小脚本用它没问题;真要上生产,任务多、需要并发或要持久化重试时,换 APScheduler,或者干脆用系统级的 cron、systemd timer------进程崩了系统帮你拉起,比常驻一个 Python 进程省心得多。这就像从手机闹钟升级成工厂的自动排班系统,一个管一个人,一个管一整条产线。
三根支柱搭起来:一个开源情报 Agent
把上面三块拼到一起,就是一个完整的"开源情报 Agent":每天到点,批量检查关注的项目有没有新版本,顺带扫一眼服务日志有没有异常,最后汇总成一条通知发给你。
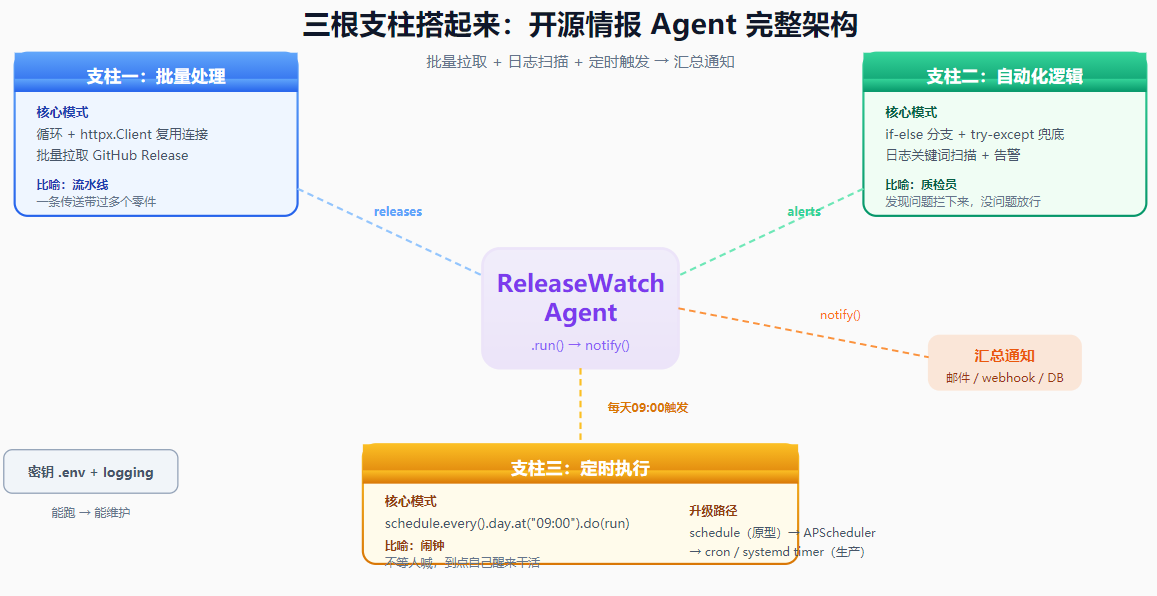
核心结构大概是这样:
python
class ReleaseWatchAgent:
def __init__(self, repos, log_file):
self.repos = repos
self.log_file = log_file
def run(self):
# 批量拉取 + 自动化逻辑(异常处理在函数内部)
releases = batch_check_releases(self.repos)
alerts = scan_logs(self.log_file)
# 汇总成通知
self.notify(releases, alerts)
def start(self):
schedule.every().day.at("09:00").do(self.run)
while True:
schedule.run_pending()
time.sleep(60)批量处理一次性消化多个项目和日志,自动化逻辑过滤出真正值得关心的信息,定时执行让它每天自己醒来干活。Agent 就从"你喊一声它动一下"变成了"自己盯着、自己干"------这才是"自动干活"该有的样子。
两件小事,决定脚本是"玩具"还是"工具"
第一,密钥别写死在代码里 。用 python-dotenv 从 .env 读环境变量,既能保护敏感信息,也方便开发生产环境切换。密钥硬编码就像把家门钥匙贴在门框上------方便了自己也方便了别人。
第二,日志别只用 print ,换标准库 logging,能落文件、能分级过滤,长跑脚本出问题时这是你唯一的排查线索。print 是口头交代,logging 是白纸黑字留档------口头交代转身就忘,留档的东西随时能翻。
这两件小事,是脚本从"能跑"到"能维护"的分水岭。