PyTorch计算机视觉(2)------神经网络模型训练与PyTorch基础
0. 前言
本节将介绍计算机视觉项目的 Python/PyTorch 平台,重点阐述机器学习中用于模型训练的梯度下降算法,以及涉及数据集、数据加载器、激活函数、GPU 使用和模型训练/保存的 Python/PyTorch 库(工具)。
1. 使用梯度下降算法进行线性回归
在本小节中,我们将通过梯度下降算法完成一个线性回归项目,这是编写机器学习代码的标准方式。在本小节实验中,我们需要找出华氏温度与摄氏温度之间的线性关系:给定摄氏温度数组 C = [-20, -15, -10, -5, 0, 5, 10, 15, 20],以及通过公式 F = 32 + 9C/5 生成的华氏温度数组 F = [-4, 5, 14, 23, 32, 41, 50, 59, 68]。
通常机器学习模型包含多个神经层,这些数字神经元不同于人脑中的生物神经元。在计算机视觉模型中,神经层是一组处理输入数据的人工神经元,可视为连续提取并优化信息的一系列滤波器。数字神经元本质是数学运算符,每个神经层都有可学习参数,这些在模型训练中自动更新的参数称为模型参数。例如通过完成温度数组的回归实验,我们将获得线性函数的斜率 1.8 和截距 32.0,这就是该线性模型的两个参数。
为通过训练获取模型参数,需要建立评估模型性能的标准------即机器学习中的损失函数。在每次训练迭代中,我们使用梯度下降算法降低损失函数值。需要手动设置学习率和训练轮数等超参数(区别于模型参数)。训练过程可能持续数秒、数小时甚至数周,其耗时取决于数据规模、代码效率和计算机硬件。使用图形处理器 (graphics processing unit, GPU) 能显著缩短训练时间,因为 GPU 专为并行处理设计,可同步执行大量计算任务。
通过令导数 y ′ = 0 y' = 0 y′=0 来求函数 y = f ( x ) y = f(x) y=f(x) 的极值点非常简单。例如对于函数 y = x 2 + 2 x + 3 y = x^2 + 2x + 3 y=x2+2x+3,令其梯度 y ′ = 2 x + 2 = 0 y' = 2x + 2 = 0 y′=2x+2=0 即可求得函数在 x = − 1 x = -1 x=−1 处取得最小值。然而在机器学习模型中,通常有数百、数千甚至数十亿个参数分布在众多神经层中,这些参数大多以数组或矩阵形式存在而非标量。要为这些数组显式写出损失函数的梯度表达式非常困难。
(1) 首先,导入所需库,并加载 C2F.csv 文件:
python
import numpy as np
import matplotlib.pyplot as plt
n_epochs = 20000
lr = 5e-3
CF = np.loadtxt('C2F.csv', skiprows=1, delimiter=',')NumPy 函数 np.loadtxt 用于加载硬盘上的 CSV 文件,并将数据以 9×2 数组的形式存储到内存中,命名为 CF。由于模型训练不需要列名,在函数中设置参数 skiprows=1,由于文件中数据用逗号分隔,因此设置另一个参数 delimiter=','。
(2) 将 9×2 的 NumPy 数组拆分为一维数组 C 和 F:
python
C = CF[:, 0]
F = CF[:, 1]
print('C =', C)
print('F =', F)
X = np.vstack((C, np.ones(len(C)))).T
print('X=', '\n', X)
Y= F.reshape(-1,1)
print('Y=', '\n', Y)通过过 NumPy 函数 np.len(C) 获取数组 C 的长度。根据该长度,使用另一个 NumPy 函数 np.ones(len(C)) 创建一维全 1 数组 ONES,其中每个元素均为 1.0。随后将数组 C 与 ONES 数组垂直堆叠为 2×9 数组,再转置为如以下公式所示的 9×2 数组 X。Python 函数 reshape(-1,1) 将数组F的形状从一维转换为 9×1。通过设置 reshape 函数中的 -1 参数,计算机将自动计算行或列的数量。
X = x 0 , 0 1 x 1 , 0 1 . . . . . . x 8 , 0 1 = − 20 1 − 15 1 . . . . . . 20 1 , Y = y 0 y 1 . . . y 8 = − 4 5 . . . 68 , y ^ = x 0 , 0 1 x 1 , 0 1 . . . . . . x 8 , 0 1 ⋅ w 0 w 1 (2.1) X=\begin{bmatrix}x_{0,0}&1\\x_{1,0}&1\\...&...\\x_{8,0}&1\end{bmatrix}=\begin{bmatrix}-20&1\\-15&1\\...&...\\20&1\end{bmatrix},\ \ Y=\begin{bmatrix}y_0\\y_1\\...\\y_8\end{bmatrix}=\begin{bmatrix}-4\\5\\...\\68\end{bmatrix},\ \ \hat y=\begin{bmatrix}x_{0,0}&1\\x_{1,0}&1\\...&...\\x_{8,0}&1\end{bmatrix}\cdot\begin{bmatrix}w_0\\w_1\end{bmatrix}\tag{2.1} X= x0,0x1,0...x8,011...1 = −20−15...2011...1 , Y= y0y1...y8 = −45...68 , y^= x0,0x1,0...x8,011...1 ⋅w0w1(2.1)
(3) 为了建立两个一维数组之间的线性关系 ( F = k C + b F = kC + b F=kC+b),我们需要两个参数:斜率 k k k 和截距 b b b。为便于数学处理,我们将它们打包成一个权重数组 W = w 0 , w 1 T = k , b T W = w_0, w_1^T = k, b^T W=w0,w1T=k,bT (数组的上标 T T T 表示转置操作,因此该权重数组具有两行一列)。
本节模型定义为 y ^ = X @ W \hat{y} = X@W y^=X@W,其中 X X X 是一个 9 × 2 的数组(如以上公式所示)。数组 X 的第一列由数组 C 的数值构成,第二列每个元素均为 1.0。X 与 W 的 @ 运算将生成一个 9×1 的 y_hat 数组,其中每个元素代表模型的预测值。
数组 W 的每个参数初始化为零。通过这些设置,当训练 epoch=0 时,我们得到的初始预测数组 y_hat 所有九个元素均为零。在模型训练过程中,我们需要通过均方误差(或损失函数)使模型的预测值 y_hat 尽可能接近目标值 Y。
损失函数的公式及其对权重的梯度公式分别如以下公式所示(其中 n=9。该 MSE 损失函数构建了一个具有最低点(即最小值零)的三维数字山谷。权重矩阵随后沿着损失函数梯度的反方向进行更新: w i + 1 = w i − l r ⋅ ∇ L w_{i+1} = w_i - lr · ∇L wi+1=wi−lr⋅∇L,其中 lr 代表学习率(一个较小的数值)。通过这种方式,模型在每个训练 epoch 都能以 lr 为步长向最低点逼近------这种训练模型的优化算法称为"梯度下降算法"。
L ( X , w ) = 1 ( n + 1 ) ∑ i = 0 n ( y i ^ − y i ) 2 ∇ L = ∂ L ∂ w 0 ∂ L ∂ w 1 = 2 n + 1 \begin{align} L(X,w)=\frac 1{(n+1)}\sum_{i=0}^n(\hat {y_i}-y_i)^2\tag{2.2}\\ \nabla L=\begin{bmatrix}\frac{\partial L}{\partial w_0}\\\frac {\partial L}{\partial w_1}\end{bmatrix}=\frac 2{n+1}\tag{2.3} \end{align} L(X,w)=(n+1)1i=0∑n(yi^−yi)2∇L=∂w0∂L∂w1∂L=n+12(2.2)(2.3)
根据以上公式定义了三个函数:模型函数、MSE 损失函数和梯度函数。需注意损失函数中的平方数组运算并非线性代数中的常规数学运算。NumPy 和 PyTorch 库包含大量此类非代数运算,它们通过逐元素操作避免了循环语句,从而显著加速计算过程。
python
def model(X, W):
return X@W
def criterion(y_hat, Y):
return ((y_hat-Y)**2).mean()
def gradient(X, Y, y_hat):
return 2*(X.T@(y_hat-Y))/X.shape[0]学习率超参数需在模型训练前设定:若学习率过小,模型训练将需要更多周期才能达到最小值;若学习率过大,损失值可能会在最小值附近震荡,导致训练无法收敛。采用合适的学习率时,训练损失在初始阶段会快速下降,随后逐渐趋缓。后续学习中,我们将使用 PyTorch 提供的学习率调度器来实现动态学习率调整。
(4) 定义线性回归项目的拟合函数 fit()。该函数需要四个输入参数:前两个是符合上述公式特定数组形状的输入数据,后两个是训练 epoch 数和学习率模型超参数。我们使用了一个轻量级 Python 模块 tqdm 来显示训练进度条------对于大型计算机视觉项目,模型运行时间可能长达数小时甚至数周,这个工具能直观显示剩余等待时间:
python
from tqdm import trange
def fit(x, y, epochs, learn_rate):
W = np.zeros((x.shape[1], 1)) #x.shape[1]=2
progress_bar = trange(epochs)
for i in progress_bar:
y_hat = model(x,W)
loss = criterion(y_hat, y)
progress_bar.set_description(f"loss={loss.item():.9f}" )
progress_bar.set_postfix({'k': W[0,0], 'd': W[1,0]})
W -= learn_rate*gradient(x, y, y_hat)
return W
W = fit(X, Y, n_epochs, lr)在带进度条的拟合函数循环中,程序会计算模型预测值 y_hat 和损失函数值。通过进度条可实时观察训练周期、损失值、斜率 w[0,0] 和截距 w[1,0] 的变化。随后通过梯度下降算法更新权重数组,训练完成后函数返回最终权重数组。调用该拟合函数,这个简单的机器学习项目设置了 20000 次训练 epoch。值得注意的是,即使经过 20000 次训练,线性回归的斜率仍与理论值 1.80 存在 10 − 8 10^{-8} 10−8 量级的误差。若学习率超过 7 × 10 − 3 7×10^{-3} 7×10−3,回归将无法找到正确的斜率和截距。运行以上代码,即可完成线性回归项目并获得模型参数。
(5) 调用以下代码可观察到损失函数在三维数字空间中的轨迹,从下图展示的数字山谷轨迹中,能直观看到程序自动寻找谷底最低点的过程。由于本项目模型仅有两个参数,可以在三维空间中显示以截距 b b b 为 x x x 轴、斜率 k k k 为 y y y 轴、损失值为 z z z 轴构成的山谷曲面。而对于参数规模达数百万甚至数十亿的大型机器学习项目,其损失函数曲面无法直接可视化。
在训练函数 train3d() 中,第二行预先分配了浮点数组 Z Z Z 的内存空间。当训练周期超参数设为 20000 时,数组 Z Z Z 将包含 20000 行 3 列,每行分别记录每个训练周期的斜率、截距和损失值。模型训练完成后,该函数返回记录损失值轨迹的数组 Z Z Z。
python
def train3d(x, y, epochs, learn_rate):
Z = np.empty((epochs, 3))
w = np.zeros((x.shape[1], 1))
progress_bar = trange(epochs)
for i in progress_bar:
Z[i, 0] = w[0,0] # slope k
Z[i, 1] = w[1,0] # intercept b
y_hat = model(x,w)
loss = criterion(y_hat, y)
Z[i, 2] = loss
progress_bar.set_description(f"loss={loss.item():.5f}" )
progress_bar.set_postfix({'k': w[0,0], 'd': w[1,0]})
w -= learn_rate*gradient(x, y, y_hat)
return Z
Z = train3d(X, Y, epochs=n_epochs, learn_rate=lr)
# Plot a 3D surface with data from training
fig, ax = plt.subplots(subplot_kw={"projection": "3d"}, figsize=(16,6))
b_col = np.float32(np.linspace(-2, 38, 801))
k_row = np.float32(np.linspace(0, 4, 401))
b, k = np.meshgrid(b_col, k_row)
L = np.empty((len(k_row), len(b_col)))
w = np.zeros((X.shape[1], 1))
for i, ki in enumerate(k_row):
for j, bj in enumerate(b_col):
w = [[ki], [bj]]
y_hat = model(X,w)
L[i,j] = criterion(y_hat, Y)
surf = ax.plot_surface(b, k, L, cmap='cool')
ax.plot3D(Z[:,1], Z[:,0], Z[:,2], 'k-', lw=2, label='loss')
ax.set(xlabel='b', ylabel='k', zlabel='Loss')
plt.colorbar(surf, shrink=0.8)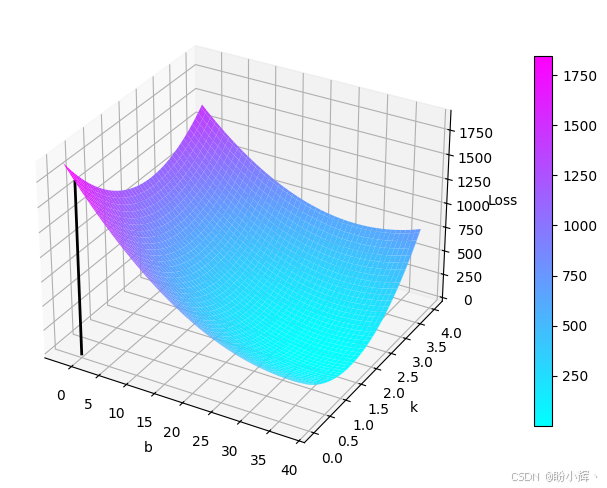
上图所示的输出结果却非常直观:彩色曲面呈现数字山谷的顶部形态,黑色折线则展示了 20000 次训练周期中损失函数的轨迹。若选择更小的学习率,该轨迹将呈现为平滑曲线。
以上代码设置了 16×6 英寸画布尺寸的 3D 投影图,通过 np.linspace 生成截距数组 b_col (-2 至 38 范围 801 个点)和斜率数组 k_row (0 至 4 范围 401 个点),再经 np.meshgrid 转换为 401×801 的二维网格数组。值得注意的是,数组 k 的每列数据相同,数组b的每行数据相同。代码中采用嵌套循环配合 enumerate 函数,在每个网格点构建 2×1 权重数组 w,结合数组 X 和 Y 计算损失函数值,最终通过 ax.plot_surface() 绘制数字山谷曲面,ax.plot3D() 绘制损失轨迹。
这个简单项目其实可通过公式 ∇ L = 0 ∇L=0 ∇L=0 直接解析求解 w = ( X T X ) − 1 X T Y w=(X^TX)^{-1}X^TY w=(XTX)−1XTY,在毫秒级内完成。但我们必须掌握梯度下降算法的应用,因为对于参数规模达数百万甚至数十亿的复杂计算机视觉项目,往往不存在解析解,也无法手动推导损失函数对模型参数的梯度公式。PyTorch 能自动计算这些梯度------这个基于 Torch 库的开源机器学习框架,提供支持 GPU 加速的张量运算,并构建于自动微分系统之上。
2. 自动梯度计算和学习率调度器
在每个计算机视觉项目中,我们至少需要计算一个损失函数对模型参数的梯度。对于分布在多个神经层中、包含数十亿参数的模型而言,手动推导梯度公式几乎不可行。PyTorch 能够在无需提供梯度公式的情况下自动计算这些梯度。标量函数 f ( x , y , z ) f(x,y,z) f(x,y,z) 对向量 V = x , y , z V=x,y,z V=x,y,z 的梯度仍是一个向量,其分量为偏导数: ∇ f = ∂ f / ∂ x , ∂ f / ∂ y , ∂ f / ∂ z ∇f = ∂f/∂x, ∂f/∂y, ∂f/∂z ∇f=∂f/∂x,∂f/∂y,∂f/∂z。例如函数 f ( x , y , z ) = x 2 + y 2 + z 2 f(x,y,z)=x²+y²+z² f(x,y,z)=x2+y2+z2 在点 V = 1 , 2 , 3 V=1,2,3 V=1,2,3 处的梯度为: ∇ f = 2 x , 2 y , 2 z = 2 , 4 , 6 ∇f=2x,2y,2z=2,4,6 ∇f=2x,2y,2z=2,4,6。以下代码演示了如何使用 PyTorch 自动计算梯度。
python
# Auto-grad for gradient calculations
import torch
V = torch.tensor([1.0, 2, 3], requires_grad=True)
print('V=', V)
for i in range(3):
f = torch.sum(V**2) #f=x^2+y^2+z^2
f.backward()
print(i,'\t', V.grad) # df/dV = [2*x, 2*y, 2*z]
#V.grad.zero_() # reset df/dV=0首先导入了 torch 包,该包支持多维张量数据结构并提供张量的数学运算。Torch 张量与 NumPy 数组相似,且可相互转换。使用 Torch 张量的主要优势在于,它们能够被迁移至 GPU 进行并行计算以提升效率。
为了计算标量函数的梯度,作为 torch 张量的向量必须将其属性 requires_grad 设置为 True。通过此设置,PyTorch 会记录该向量的所有数学运算。在 for 循环中,函数 f 必须置于循环内部,随后必须调用 f.backward() 函数来计算所有运算中的梯度。函数的梯度会通过 V.grad 进行累积。每次使用 PyTorch 自动计算梯度时,都需要通过 grad.zero_() 或使用其他方法将梯度重置为零。
python
import torch
x = torch.arange(1,4).to(torch.float)
x.requires_grad=True
print('x=', x)
y=x**2
z=x**3
print('y=', y); print('z=', z)
R=(y.detach()+z).sum()
print('R=', R)
R.backward()
print('dR/dx=', x.grad)
x.grad.zero_()
print('R.requires_grad=', R.requires_grad)对于多变量标量函数,我们可能需要忽略某个变量对函数梯度的贡献。通过上方代码,可以深入了解 PyTorch 的 backward() 函数和 detach() 函数在自动梯度计算中的应用。以函数 R = y + z R = y + z R=y+z 为例,其中 y = x 1 2 + x 2 2 + x 3 2 , z = x 1 3 + x 1 3 + x 3 3 y = x_1^2 + x_2^2 + x_3^2,\ z = x_1^3 + x_1^3 + x_3^3 y=x12+x22+x32, z=x13+x13+x33,变量 x = x 1 , x 2 , x 3 = 1 , 2 , 3 x = x_1, x_2, x_3 = 1,2,3 x=x1,x2,x3=1,2,3。我们可以通过公式 2 x 1 + 3 x 1 2 , 2 x 2 + 3 x 2 2 , 2 x 3 + 3 x 3 2 2x_1 + 3x_1\^2, 2x_2 + 3x_2\^2, 2x_3 + 3x_3\^2 2x1+3x12,2x2+3x22,2x3+3x32 计算梯度 ∇ x R = ∂ R ∂ y ⋅ ∂ y ∂ x + ∂ R ∂ z ⋅ ∂ z ∂ x ∇xR = \frac{∂R}{∂y}·\frac{∂y}{∂x} + \frac{∂R}{∂z}·\frac{∂z}{∂x} ∇xR=∂y∂R⋅∂x∂y+∂z∂R⋅∂x∂z。使用 PyTorch 时无需知晓梯度公式,只需调用 R.backward(),PyTorch 的反向传播算法就会记录并追踪所有中间梯度,随后通过 x.grad 即可获得累积后的 ∇ x R ∇_xR ∇xR。
通过设置 ∂ R ∂ y = 0 \frac {∂R}{∂y} = 0 ∂y∂R=0,我们可以忽略y对∇xR的贡献。在这种情况下, ∇ x R = 3 × x 1 2 , 3 × x 2 2 , 3 × x 3 2 ∇_xR = 3 × x_1\^2, 3 × x_2\^2, 3 × x_3\^2 ∇xR=3×x12,3×x22,3×x32。在以上代码中,y.detach() 用于 ∂ R ∂ y = 0 \frac {∂R}{∂y} = 0 ∂y∂R=0。可以将 y.detach() 改为 z.detach(),以查看梯度输出的差异。基于 PyTorch 中自动梯度计算的知识,我们可以用不同的方式编写简单线性回归的代码来处理温度转换的实验。
python
import torch; import torch.nn as nn; from tqdm import trange
import torch.optim.lr_scheduler as lr_scheduler
import numpy as np; import pandas as pd; import matplotlib.pyplot as plt
n_epochs = 20000
lr = 1.5
# Read data from a csv file and convert array into tensor
CF = np.loadtxt('C2F.csv', delimiter=',', skiprows=1)
X = torch.FloatTensor(CF[:, 0]).view(-1,1)
Y = torch.FloatTensor(CF[:, 1]).reshape(-1,1)Torch 作为 PyTorch 的核心包,支持多维张量及其数学运算,同时提供神经网络构建与模型训练的多种工具。我们将使用 torch.nn 构建线性回归模型,并采用名为 lr_scheduler 的模块实现动态学习率。Pandas 数据框将用于记录模型训练历史------Pandas 作为 Python 工具包,其数据框是包含行列的二维数据结构。在以上代码中,数据输入的变量 X 和 Y 均为 torch 浮点张量 FloatTensors。张量作为数据容器,可存储一维、二维、三维乃至超过四维的数组或矩阵。例如批大小为 64、分辨率为 256×256 的彩色照片,可用形状为 64×3×256×256 的四维 PyTorch 张量存储。
CSV 文件数据首先存入 NumPy 二维数组,随后两列数据分别被转换为形状为 9×1 的 float32 张量。此处 view(-1,1) 与 reshape(-1,1) 功能相同。我们无需将全 1 张量与 X 拼接,PyTorch 会自动处理额外工作。若运行 CF.dtype 或 X.dtype,可以看到数组 CF 的数据类型为 float64,而张量 X 的数据类型为 torch.float32。张量数据类型种类繁多,有时需要进行类型转换。在计算机视觉项目中多数情况下我们处理 torch.float32,优势会使用 torch.float16 以节省内存和训练时间。
python
model = nn.Linear(1,1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
my_lambda = lambda i: 1/10000*i+1e-5 if i<10000 else (
2-1/10000*i if i<17000 else
0.3-5e-5*(i-17000))
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=my_lambda )
print(optimizer.state_dict())
print('initial learning rate=', optimizer.param_groups[0]['lr'])torch 类 nn.Linear(1,1) 用于创建具有单变量输入输出的全连接神经网络层。从数学角度看,该模型实现线性回归功能: X @ w T X@w^T X@wT。默认情况下权重张量 w w w 是形状为 1×2 的张量,其第一、二个元素分别对应斜率和截距(偏置项)。该 torch 模型的功能远超数学运算 X @ w T X@w^T X@wT:它会初始化权重数组 w w w 并存储模型权重参数。以上代码会输出优化器的参数信息。通过 optimizer.param_groups[0]['lr'] 获取训练过程中的学习率。默认情况下,nn.MSELoss() 类根据以下公式执行计算。通过设置 nn.MSELoss(reduction='sum') 可避免除以n的操作以缩短训练时间。运行损失函数的代码后,输出平均损失等于 4.0 (loss = [3 × (2 − 0)²]/3)。
python
import torch; import torch.nn as nn
criterion = nn.MSELoss(reduction='mean')
y_hat = 2*torch.ones(3, 1, requires_grad=True)
y = torch.zeros(3, 1)
print(y_hat, '\n', y)
loss = criterion(y_hat, y)
print(loss)在模型训练过程中,优化器种类繁多,它们用于计算损失函数的梯度并通过 optimizer.step() 自动更新模型权重数组。其中 Adam (自适应矩估计)优化器最为常用。
学习率是模型训练中最重要的超参数。PyTorch 提供了多种学习率调度器,用于在训练过程中动态调整学习率。其中最常用的调度器是 LambdaLR。可以定义以训练轮次 (i) 为变量的任意函数:初始学习率 (lr0) 通常为优化器设置,而第 (i) 轮次的学习率等于 lr0 乘以 Lambda 函数值。
在以下代码中,第一个函数用于实现恒定学习率:lri = 0.5 × lr0。使用第二个lambda函数时,学习率在20000轮训练期间线性递减。若选择第三或第四个函数,学习率将呈指数式下降。第五个lambda函数与PyTorch中的CosineAnnealingLR调度器功能相同。第六个lambda函数包含三个区间段:分别对应i<10000、10000≤i≤17000和i>17000的情况。最后一个lambda函数类似于PyTorch中的StepLR调度器,它通过i//5000作为索引从名为lr_list的列表中选取对应数值。
python
my_lambda = lambda i: 0.5
my_lambda = lambda i: 1-0.99/20000*i
my_lambda = lambda i: 0.9999 ** i
my_lambda = lambda i: np.exp(-i/5000)
my_lambda = lambda i: 0.1+0.4*(1+np.cos(i/20000*np.pi))
my_lambda = lambda i: 1/10000*i+1e-5 if i<10000 else (
2-1/10000*i if i<17000 else 0.3-5e-5*(i-17000))
lr_list = [1.0, 0.5, 0.25, 0.125, 0.06]
my_lambda = lambda i: lr_list[i//5000]在以下代码中,创建了一个名为 df 的 pandas 数据框,用于记录模型训练过程中每个 epoch 的学习率和损失函数值,调用拟合函数即可获取该数据框。nn.Linear(1,1) 模型会自动管理其所有参数。在每个训练 epoch 中,optimizer.zero_grad() 会将损失函数对所有参数的梯度重置为零。正如 optimizer.step() 会逐轮更新模型参数,scheduler.step() 则会更新优化器的学习率。
python
def fit(x, y, epochs):
df = pd.DataFrame(np.empty([epochs, 2]), index = np.arange(epochs),
columns=['lr', 'Loss'])
progress_bar = trange(epochs)
for i in progress_bar:
y_hat = model(x) #model prediction
loss = criterion(y_hat, y) #calculate loss value
df.iloc[i,0] = optimizer.param_groups[0]['lr'] # record learning rate
df.iloc[i,1] = loss.item() # record loss
optimizer.zero_grad() # gradient initializations
loss.backward() # gradient calculations
optimizer.step() # update model parameters
scheduler.step() # update learining rate
progress_bar.set_description("loss=%.9f" % df.iloc[i,1])
progress_bar.set_postfix({'leraning rate': df.iloc[i,0]})
return df
train_history = fit(X, Y, n_epochs)
# Showing training results with graphs
df = train_history
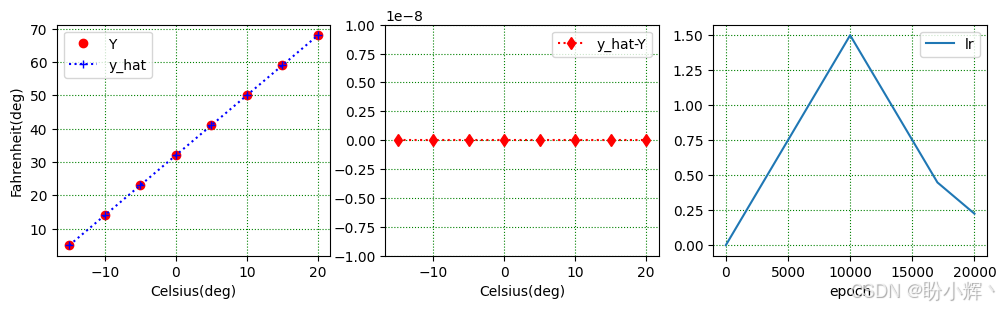
fig, ax = plt.subplots(1,3, figsize=(12,3))
ax[0].plot(X, Y, 'ro', label='Y')
ax[0].plot(X, model(X).detach(), 'b:+', label='y_hat')
ax[0].set(xlabel='Celsius(deg)', ylabel='Fahrenheit(deg)')
ax[1].plot(X, model(X).detach()-Y, 'r:d', label='y_hat-Y')
ax[1].ticklabel_format(style='sci', axis='y', scilimits=(0,0));
ax[1].set(xlabel='Celsius(deg)', ylim=[-1e-8,1e-8])
ax[2].plot(df.iloc[:,0], label='lr'); ax[2].set(xlabel='epoch')
for i in range(3):
ax[i].legend()
ax[i].grid(which='major', axis='both', color='g', linestyle=':')
plt.show()从下图(左图)中,我们仅凭肉眼无法分辨模型预测值 y_hat 与原始数据 Y 之间的差异。运行以上代码后,如下图(中图)所示,可以看到两者的差异小于 10 − 8 10^{-8} 10−8。下图(右图)展示的学习率曲线是通过 my_lambda 函数所设置的。Pandas 具备强大的数据可视化功能,可以使用以下代码绘制学习率曲线。
PyTorch 提供了更智能的学习率调度器,其中 ReduceLROnPlateau() 能在损失函数值或其他指标连续停止改善达到 patience 设定 epoch 数时,自动降低学习率。
我们可以使用以下代码,重新训练模型以生成 3D 图形输出。scheduler.step() 中的 loss.item() 选项明确指示调度器监控损失函数值。若损失函数的最小值在连续 2000 个训练 epoch ( patience 参数)内未发生变化,学习率将减半 (factor = 0.5)。在以上代码,模型参数被赋值给名为 p 的列表。该列表中表示斜率和偏置的两个元素值会在模型训练过程中记录到 pandas 数据框内。
python
def train3D(x, y, epochs):
df = pd.DataFrame(np.empty([epochs, 4]), index = np.arange(epochs),
columns=['slope', 'bias', 'Loss', 'lr'])
progress_bar = trange(epochs)
for i in progress_bar:
p = list(model.parameters())
y_hat = model(x)
loss = criterion(y_hat, y)
df.iloc[i, 0] = p[0].detach().item() # slope
df.iloc[i, 1] = p[1].detach().item() # bias
df.iloc[i, 2] = loss.detach().item() # loss
df.iloc[i, 3] = optimizer.param_groups[0]['lr'] # lr
optimizer.zero_grad() # gradients initialzation
loss.backward() # gradients calculation
optimizer.step() # model update
#scheduler.step() # for lr of LambdaLR
scheduler.step(loss.item()) # for lr of ReduceLROnPlateau
progress_bar.set_description("loss=%.9f" % df.iloc[i,2])
progress_bar.set_postfix({'leraning rate': df.iloc[i,3]})
return df
train_history = train3D(X, Y, n_epochs)待模型训练完成后,返回的数据框将用于绘制如下图所示的三维图形。在以下代码的两个 for 循环内部,必须使用 nn.Parameter() 将张量指定为模型参数。可以尝试不同的初始学习率和调度器设置,观察损失函数轨迹的变化情况。
python
df = train_history # for the training history trace
fig, ax = plt.subplots(subplot_kw={"projection": "3d"}, figsize=(16,12))
b_col = np.float32(np.linspace(-2, 38, 401))
k_row = np.float32(np.linspace(0, 4, 201))
b, k = np.meshgrid(b_col, k_row)
L = np.empty((len(k_row), len(b_col)))
for i, ki in enumerate(k_row):
for j, bj in enumerate(b_col):
model.weight = nn.Parameter(torch.tensor([[ki]], requires_grad=False))
model.bias = nn.Parameter(torch.tensor([bj], requires_grad=False))
y_hat = model(X)
L[i,j] = criterion(y_hat, Y) # creating a 3D loss surface
surf = ax.plot_surface(b, k, L, cmap='Oranges_r') # plot the 3D surface
ax.plot3D(df.iloc[:,1], df.iloc[:,0], df.iloc[:,2], 'k-', lw=5)
#ax.set(zlabel='Loss')
plt.xlabel('intercept b', fontsize=18); plt.ylabel('slope k', fontsize=18);
ax.xaxis.set_tick_params(labelsize=16)
ax.yaxis.set_tick_params(labelsize=16)
ax.zaxis.set_tick_params(labelsize=14)
plt.colorbar(surf, shrink=0.7)
df.plot(y=[3], grid=True, legend=True,
title='the ReduceLROnPlateau learning rate function')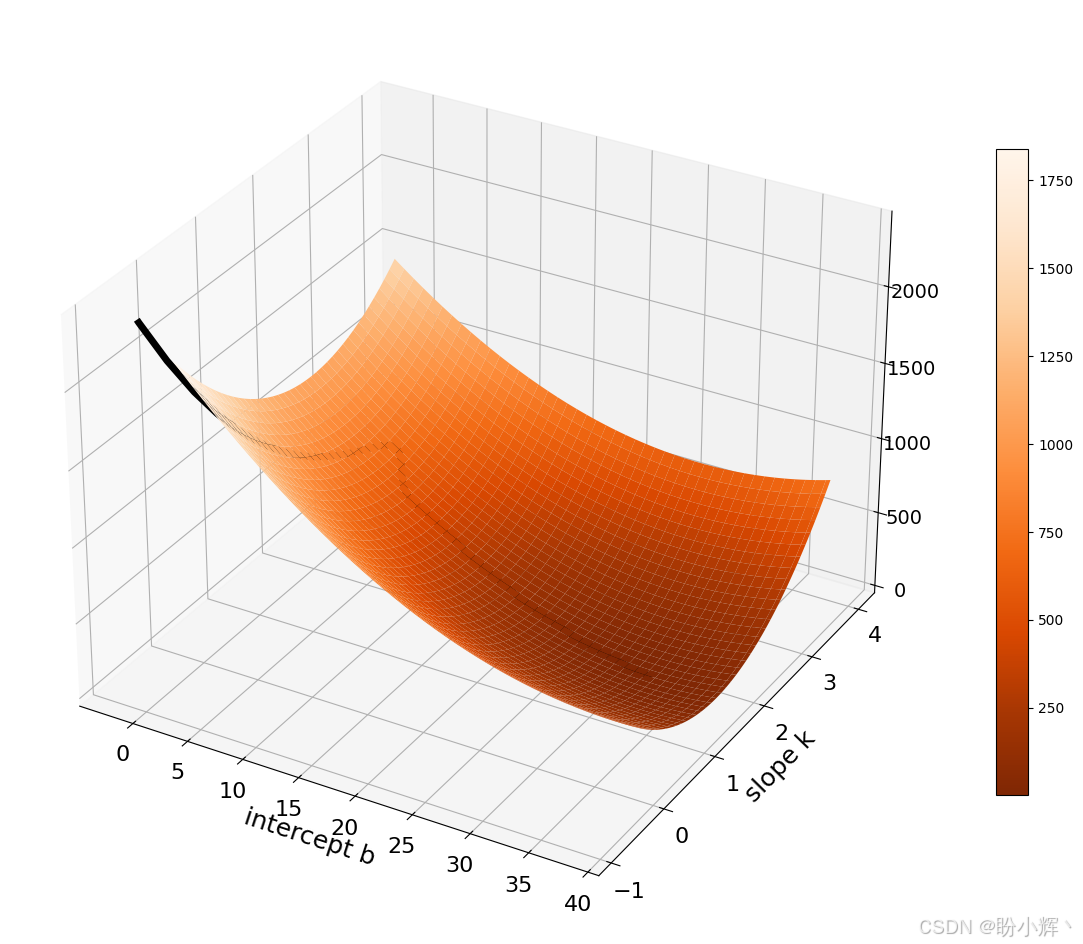
3. 数据集、数据加载器、GPU 和模型保存
在计算机视觉项目中,模型训练的数据应该被打包成数据集。通常,数据集的大小非常庞大。下载数据集后,由于计算机内存不足以单次处理整个数据集,我们需要将数据集切分成包含多个批次 (batch) 的数据加载器。这就像享用大蛋糕时,必须用刀切成小块才能送入嘴中。接下来,我们将学习如何将温度转换的 CSV 文件数据封装成数据集并切分为数据加载器。虽然这对简单项目而言是额外工作,但却是处理计算机视觉大型数据集的关键步骤。
(1) 导入所需库,用于将数据封装成数据集并切分为数据加载器:
python
import torch; import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim.lr_scheduler as lr_scheduler; from tqdm import trange
import numpy as np; import pandas as pd; import matplotlib.pyplot as plt
n_epochs = 20000
batch_size = 3
lr = 0.1 # initial learning rate(2) 以下代码展示了数据封装过程:通过继承PyTorch的torch.utils.data.Dataset子类,我们定义了名为C2F的类。该类的__init__函数使用np.loadtxt方法读取CSV文件数据(以字符串形式传入文件名),其中'np.float32'参数至关重要,它能将数据转换为float32张量。随后记录了两列数据及其各自长度。C2F类中的第二个函数__getitem__可用于根据特定索引提取数据集中的单组数据。通过类中最后的__len__函数,我们可以获取数据集包含的数据对总量。使用文件路径字符串'C2F.csv'创建了C2F类的实例。可以看到C2F类完全实现了预期功能:若将my_dataset0中的索引'0'改为':',将会打印出数组x的全部9个元素和数组y的所有9个元素。
python
class C2F(Dataset):
def __init__(self, filename):
xy = np.loadtxt(filename, delimiter=',', skiprows=1, dtype=np.float32)
self.x = torch.from_numpy(xy[:, 0])
self.y = torch.from_numpy(xy[:, 1])
self.n_samples = xy.shape[0]
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return self.n_samples
# Applications of the class C2F to a text data file 'C2F.csv'
my_dataset = C2F('C2F.csv')
n_samples = len(my_dataset)
print(my_dataset[0])(3) 使用 PyTorch 中 torch.utils.data 的子类 DataLoader 可以轻松将数据集切分成多个小批次,通过设置选项 shuffle=False 可保持数据顺序不变。但对于用于模型训练的图像数据加载器,需要将此选项设为 True 以减少"过拟合"现象。代码中的 for 循环会打印出数据加载器的第一个批次,若移除 break 语句,则会输出全部三个批次的内容:
python
dataloader=DataLoader(dataset=my_dataset, batch_size=batch_size, shuffle=False)
for x, y in dataloader:
print('x=', x)
print('y=', y)
break
batch_per_epoch = int(n_samples/batch_size) #batch_per_epoch=3(4) 我们将线性回归模型定义为 X@w 或 nn.Linear(1,1)。在以下代码单元中,我们通过额外代码重新定义了这个简单模型。通常计算机视觉项目会使用包含多个神经层的网络模型,代码中的 nn.Sequential() 可以容纳多种数学运算来处理和提取数据特征。类中的 forward 函数负责接收输入数据并返回输出结果。最后,我们实例化了 LinearRegression 类定义的模型,并通过 cuda() 将其移至图形处理器内存中。CUDA 的并行计算能力能显著缩短模型训练时间。
python
class LinearRegression(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(1, 1), )
def forward(self,x):
return self.net(x)
model = LinearRegression().cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = lr_scheduler.OneCycleLR(optimizer,
max_lr=lr, anneal_strategy='cos',
steps_per_epoch=batch_per_epoch, epochs=n_epochs, pct_start=0.3)在以上代码中,定义了损失函数 (criterion)、模型优化器和学习率调度器。本节使用了一个名为 OneCycleLR 的学习率调度器。该调度器会在所有周期的所有迭代中调整学习率。由于每个 epoch 有三个批次,20000 个 epoch 的模型训练总共有 60000 次迭代。
(5) 在以下代码中,数据加载器生成的每个 x 和 y 批次数据都通过 cuda() 传送至 GPU,因为模型已位于 GPU 中。通过代码最后两行可以打印出模型参数 k 和 b 的值:
python
def fit(epochs):
iterations = epochs*batch_per_epoch
df = pd.DataFrame(np.empty([iterations, 2]),
index = np.arange(iterations),
columns = ['lr', 'Loss'])
progress_bar = trange(epochs)
for i in progress_bar:
for j, (x, y) in enumerate(dataloader):
x = x.view(-1,1).cuda()
y = y.view(-1,1).cuda()
optimizer.zero_grad()
y_hat = model(x)
loss = criterion(y_hat, y) #loss for a batch
df.iloc[i*3+j, 0] = optimizer.param_groups[0]['lr']
df.iloc[i*3+j, 1] = loss.item()
progress_bar.set_description("loss=%.9f" % loss.item())
progress_bar.set_postfix({'lr': df.iloc[i*3+j, 0]})
loss.backward()
optimizer.step()
scheduler.step()
return df
train_history = fit(n_epochs)
k, b = list(model.parameters())
print('k =', k.item()) # k=1.7999999523162842
print('b =', b.item()) # b=32.0(6) 借助以下代码,模型训练结果以三个图表形式呈现。在计算 y_hat 时,必须将数据集中的 X 数据传送至 GPU。而使用 matplotlib 绘制 y_hat 时,又需要将 y_hat 传回 CPU:
python
df = train_history
fig, ax = plt.subplots(1, 3, figsize=(12,3))
x_dataset, y_dataset = my_dataset[:]
X = x_dataset.view(-1,1)
Y = y_dataset.view(-1,1)
y_hat = model(X.cuda()).detach().cpu() #---X to GUP and y_hat to CPU
ax[0].plot(X, Y, 'ro', label='Y')
ax[0].plot(X, y_hat, 'b:+', label='y_hat')
ax[0].set(xlabel='Celsius(deg)', ylabel='Fahrenheit(deg)')
ax[1].plot(df.iloc[:, 1], 'r-', label='Loss')
ax[1].set(xlabel='interation')
ax[2].plot(df.iloc[:, 0], 'k-', label='learning rate')
ax[2].set_xlabel('interation')
for i in range(3):
ax[i].legend()
ax[i].grid(which='major', axis='both', color='g', linestyle=':')
plt.show()(7) 使用海量数据训练模型可能需要数小时、数天甚至数周时间。当计算机关闭后,训练好的模型参数将会全部丢失,因此我们需要保存训练好的模型参数,以便后续应用。要保存训练好的模型,需要指定文件名(例如:file_name = 'model4LR.pth'),然后使用代码 torch.save(model, file_name) 保存模型。
python
File_name = 'model4LR.pth'
torch.save(model, File_name)
saved_model = torch.load(File_name)
saved_model.eval()
print(saved_model.state_dict())
x_dataset, y_dataset = my_dataset[:]
y_hat = saved_model(x_dataset.view(-1,1).cuda())
y_hat为了避免混淆,使用 saved_model 作为从保存文件中加载的模型名称。在使用加载的模型前,必须通过代码 saved_model.eval() 将模型设置为评估模式。通过打印出训练好模型的参数,可以看到这两个参数准确无误,且保存的模型位于 GPU 中,同时加载的模型可以正常工作。
保存训练模型还有更多方法。第二种方法是仅将模型参数保存至文件,通过将文件中的参数重新加载到模型中即可复用训练好的模型。
python
torch.save(model.state_dict(), 'model4LR2.pth')
saved_model = LinearRegression()
saved_model.load_state_dict(torch.load('model4LR2.pth'))
saved_model.cuda().eval()
x_dataset, y_dataset = my_dataset[:]
y_hat = saved_model(x_dataset.view(-1,1).cuda())
y_hat第三种方法是在训练过程中保存模型检查点。大型计算机视觉项目需要多日进行模型训练,我们需要能够从前一天保存的检查点重新开始训练。使用以下代码,可以将模型参数、优化器参数、损失函数和学习率调度器状态全部保存至一个文件。
python
state = {'epochs': 20000,
'model_state': model.state_dict(),
'optimizer_state': optimizer.state_dict(),
'criterion': nn.MSELoss(),
'scheduler': lr_scheduler.OneCycleLR(
optimizer, max_lr=0.1, anneal_strategy='cos',
steps_per_epoch=3, epochs=n_epochs, pct_start=0.3)}
torch.save(state, 'model4LR3.pth')通过运行以下代码,可以重新加载这些参数。
python
model = LinearRegression().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=1.0)
checkpoint = torch.load('model4LR3.pth')
model.load_state_dict(checkpoint['model_state'])
optimizer.load_state_dict(checkpoint['optimizer_state'])
epochs = checkpoint['epochs']
criterion= checkpoint['criterion']
scheduler = checkpoint['scheduler']
print(model.state_dict())
x_dataset, y_dataset = my_dataset[:]
y_hat = model(x_dataset.view(-1,1).cuda())
y_hat4. 非线性激活函数
在计算机视觉项目中,我们必须使用多个神经层来处理非线性数学问题。然而,模型中连续多个线性层的组合实际上等效于单个线性层。例如,若模型包含两个全连接线性层: Y 1 = w 1 X + b 1 Y_1 = w_1X + b_1 Y1=w1X+b1 和 Y 2 = w 2 Y 1 + b 2 Y_2 = w_2Y_1 + b_2 Y2=w2Y1+b2,最终可得 Y 2 = w 2 w 1 X + ( w 2 b 1 + b 2 ) Y_2= w_2w_1X + (w_2b_1 + b_2) Y2=w2w1X+(w2b1+b2),这仍然是一个线性层。为解决这个数学局限,我们需要在两个线性层之间加入激活函数。激活函数种类繁多且均为非线性,以下是四种常用的激活函数:
-
Sigmoid ,
nn.Sigmoid():f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
-
双曲正切函数 ,
nn.Tanh():f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=ex+e−xex−e−x
-
ReLU ,
nn.ReLU():f ( x ) = { 0 ( x < 0 ) x ( x ≥ 0 ) f(x) = \begin{cases} 0 & (x < 0) \\ x & (x \geq 0) \end{cases} f(x)={0x(x<0)(x≥0)
-
LeakyReLU ,
nn.LeakyReLU(0.1):f ( x ) = { 0.1 x ( x < 0 ) x ( x ≥ 0 ) f(x) = \begin{cases} 0.1x & (x < 0) \\ x & (x \geq 0) \end{cases} f(x)={0.1xx(x<0)(x≥0)
我们将采用 Sigmoid 函数作为非线性激活函数,用于拟合函数 y ( x ) = e − 5 x y(x) = e^{-5x} y(x)=e−5x。所有激活函数中的变量 x x x 可以是标量或数组。当 Sigmoid 函数的输入为数组或矩阵时,该函数会逐元素作用于数组。Sigmoid 函数输出值的每个元素均处于 [0,1] 区间内。本节根据函数 y ( x ) = e − 5 x y(x)=e^{-5x} y(x)=e−5x 创建了一个 CSV 数据文件,其中 x 的取值范围为 0.0 至 1.0,x 数组长度为 51。我们将使用包含两个全连接层的模型来模拟这个指数函数。
(1) 导入 CSV 文件,并将其转换为数据集。批大小设置为 17,数据集被分成三个批次 (batch),通过数据加载器加载。
python
import torch; import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim.lr_scheduler as lr_scheduler; from tqdm import trange
import numpy as np; import pandas as pd; import matplotlib.pyplot as plt
n_epochs = 20000
batch_size = 8
lr = 0.1
class My_Dataset(Dataset):
def __init__(self, filename):
xy = np.loadtxt(filename, delimiter=',', skiprows=1, dtype=np.float32)
self.x = torch.from_numpy(xy[:, 0])
self.y = torch.from_numpy(xy[:, 1])
self.n_samples = xy.shape[0]
def __getitem__(self, index):
return self.x[index], self.y[index]
def __len__(self):
return self.n_samples
# Dataset and Dataloader
dataset = My_Dataset('nonlinearF.csv')
n_samples = len(dataset)
dataloader = DataLoader(dataset=dataset, batch_size=batch_size)
batch_per_epoch = int(n_samples/batch_size)(2) 可视化数据集:
python
x, y = dataset[:]
fig, ax = plt.subplots()
ax.plot(x,y)
ax.set(xlabel='x', ylabel='y', title='y=exp(-5x)')
ax.grid(which='major', axis='both', color='g', linestyle=':');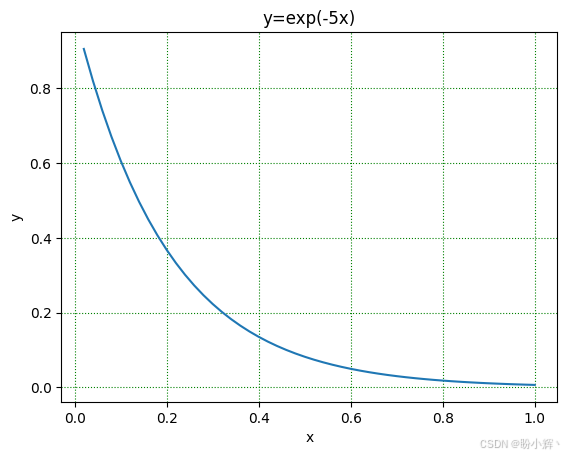
(3) 定义包含两个层的模型:首层与末层为全连接层,其间嵌入了无参数的 Sigmoid 激活函数。本节采用 OneCycleLR 学习率调度器,并将其选项 anneal_strategy 设置为 linear:
python
class NonLinearRegression(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(1,4), nn.Sigmoid(), nn.Linear(4,1))
def forward(self, x):
return self.net(x)
model = NonLinearRegression().cuda()
criterion = nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = lr_scheduler.OneCycleLR(
optimizer, max_lr=lr, anneal_strategy='linear',
steps_per_epoch=batch_per_epoch, epochs=n_epochs, pct_start=0.3)(4) 模型训练结果如下图所示。可以看到,非线性回归效果显著,模型输出 y_hat 与目标 y 之间的最大绝对差值约为 7.5 × 10 − 4 7.5×10^{-4} 7.5×10−4。
python
def fit(epochs):
iterations = epochs*batch_per_epoch
df = pd.DataFrame(np.empty([iterations, 2]),
index = np.arange(iterations),
columns = ['lr', 'Loss'])
progress_bar = trange(epochs)
for i in progress_bar:
for j, (x, y) in enumerate(dataloader):
x = x.view(-1,1).cuda()
y = y.view(-1,1).cuda()
optimizer.zero_grad()
y_hat = model(x)
loss = criterion(y_hat, y) # loss for one batch
df.iloc[i*3+j, 0] = optimizer.param_groups[0]['lr']
df.iloc[i*3+j, 1] = loss.item()
progress_bar.set_description("loss=%.9f" % loss.item())
progress_bar.set_postfix({'lr': df.iloc[i*3+j, 0]})
loss.backward()
optimizer.step()
scheduler.step()
return df
train_history = fit(n_epochs)
df = train_history
fig, ax = plt.subplots(1, 3, figsize=(12,3))
x_dataset, y_dataset = dataset[:]
X = x_dataset.view(-1,1)
Y = y_dataset.view(-1,1)
y_hat = model(X.cuda()).detach().cpu()
ax[0].plot(X, Y, 'r-', label='Y=exp(-5x)')
ax[0].plot(X, y_hat, 'b:+', label='y_hat')
ax[0].set(xlabel='Celsius(deg)', ylabel='Fahrenheit(deg)')
ax[1].plot(df.iloc[:, 1], 'r-', label='Loss')
ax[1].set(xlabel='interation')
ax[2].plot(df.iloc[:, 0], 'k-', label='learning rate')
ax[2].set_xlabel('interation')
for i in range(3):
ax[i].legend()
ax[i].grid(which='major', axis='both', color='g', linestyle=':')
plt.show()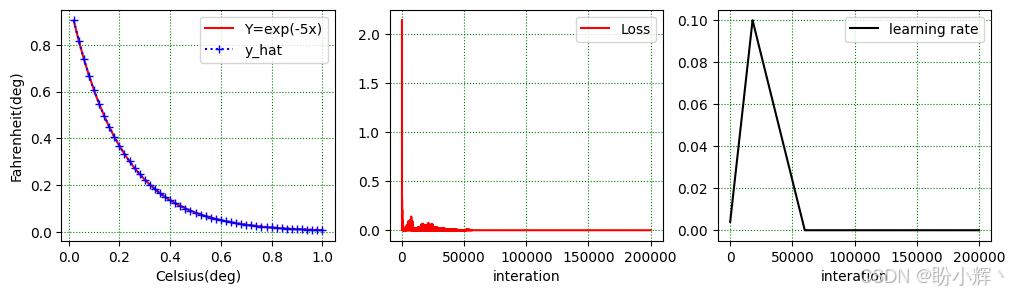
(5) 使用 p = list(model.parameters()); print(p),我们获得四个张量:前两个是第一个全连接层的权重 p[0] 和偏置 p[1],后两个是最后一个全连接层的权重 p[2] 和偏置 p[3]。它们全部存储在 GPU 中,且其 requires_grad 选项均为 true。
以下公式是我们从模型训练中得到的,运行以下代码后,将了解以下公式中模型参数的具体应用方式。神经网络非常强大,可以模拟任何数学函数。在更大型的项目中,模型往往包含众多神经层和参数,我们既无法也无需给出如下形式的完整解析式。
e − 5 X = model ( X ) = σ ( X @ p \[ 0 T + p 1 ) ] @ p 2 T + p 3 e^{-5X}=\text{model}(X)=\\sigma(X@p\[0^T+p1)]@p2^T+p3 e−5X=model(X)=σ(X@p\[0T+p1)]@p2T+p3
python
s = nn.Sigmoid()
p = list(model.parameters()); print(p)
X, Y = dataset[:]
X = X.cuda().view(-1, 1); Y = Y.cuda().view(-1, 1)
z1 = X@p[0].T+p[1]
(s(z1)@p[2].T + p[3]-Y).T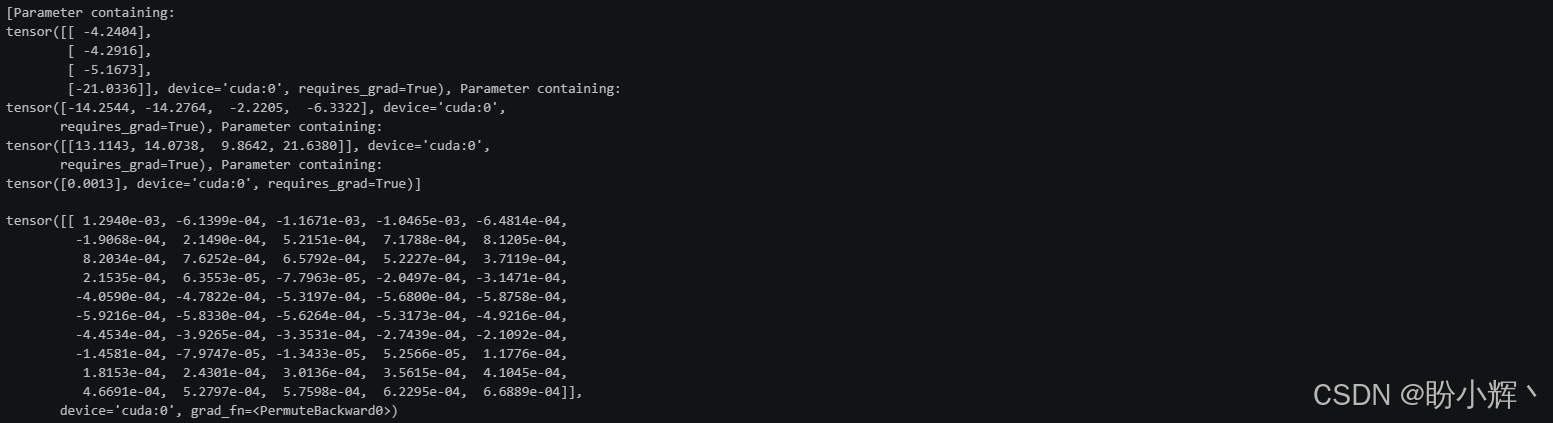
小结
本节介绍了 PyTorch 框架的核心应用。通过线性回归案例,详细阐述了梯度下降算法的工作原理,包括损失函数、学习率、权重更新等关键概念。随后展示了 PyTorch 的自动梯度计算机制,以及 LambdaLR、ReduceLROnPlateau 等多种学习率调度器的使用方法。在工程实践方面,讲解了 Dataset 与 DataLoader 的数据封装、GPU 加速训练、三种模型保存方式。最后以 Sigmoid 激活函数拟合指数曲线为例,说明了非线性建模的必要性。