这里写目录标题
- 前言
- 一、阶段学习目标
- 二、核心基础概念区分
-
- [2.1 ForeignKey 外键(数据库真实字段)](#2.1 ForeignKey 外键(数据库真实字段))
- [2.2 Relationship 关系(仅内存虚拟属性,不建库列)](#2.2 Relationship 关系(仅内存虚拟属性,不建库列))
- [2.3 懒加载 Lazy Loading(默认机制)](#2.3 懒加载 Lazy Loading(默认机制))
- 三、实战1:一对多关联(用户-收货地址,最常用)
-
- [3.1 模型完整定义(双向back_populates)](#3.1 模型完整定义(双向back_populates))
- [3.2 关联数据新增(两种写法)](#3.2 关联数据新增(两种写法))
- [3.3 N+1问题与selectinload预加载优化](#3.3 N+1问题与selectinload预加载优化)
-
- [3.3.1 错误示范(触发N+1)](#3.3.1 错误示范(触发N+1))
- [3.3.2 正确预加载写法(一次性JOIN查询)](#3.3.2 正确预加载写法(一次性JOIN查询))
- [3.4 级联删除演示](#3.4 级联删除演示)
- [四、多表联查 join、左连接](#四、多表联查 join、左连接)
-
- [4.1 内连接 join(只返回有关联数据)](#4.1 内连接 join(只返回有关联数据))
- [4.2 左连接 left join(保留无地址用户)](#4.2 左连接 left join(保留无地址用户))
- [4.3 关联条件过滤](#4.3 关联条件过滤)
- 五、实战2:多对多关联(用户-角色权限)
-
- [5.1 方案1:纯中间表(仅两外键,无额外字段)](#5.1 方案1:纯中间表(仅两外键,无额外字段))
- [5.2 方案2:带扩展字段中间实体(常用:用户角色有效期)](#5.2 方案2:带扩展字段中间实体(常用:用户角色有效期))
- 六、关联数据增删改完整操作总结
-
- [6.1 新增关联](#6.1 新增关联)
- [6.2 修改关联](#6.2 修改关联)
- [6.3 删除关联](#6.3 删除关联)
- 七、阶段核心避坑指南
前言
前两阶段我们掌握单表模型、高级字段、DTO分层、Pydantic数据校验,而真实业务几乎不存在单表场景:用户与收货地址、订单与商品、用户与角色权限,全部依靠表关联实现。
SQLModel依托SQLAlchemy底层提供完整关系映射:一对多、多对多、外键约束、级联操作、多表联查;同时默认懒加载极易产生N+1性能灾难 ,本文重点讲解selectinload预加载优化方案。
本文为系列第三阶段,全天吃透项目核心关联能力,覆盖90%后端业务表结构场景,代码全部可独立运行,完全承接前文分层DTO规范。
一、阶段学习目标
- 分清外键
ForeignKey与Relationship本质区别(新手高频混淆点) - 掌握一对多 双向关联、
back_populates双向同步、级联删除cascade_delete - 学会多对多中间表(无扩展字段纯中间表、带扩展字段中间实体)
- 掌握内连接/左连接
join()多表联合查询 - 彻底理解懒加载N+1问题,熟练使用
selectinload预加载优化性能 - 关联数据新增、修改、删除完整业务操作
- 嵌套DTO序列化,接口直接返回层级关联数据
- 多条件联查、分页、关联过滤实战
二、核心基础概念区分
2.1 ForeignKey 外键(数据库真实字段)
- 会在数据表生成真实列,存储关联主键ID
- 用于数据库层面约束数据完整性
- 语法:
field: int | None = Field(foreign="主表.主键id")
2.2 Relationship 关系(仅内存虚拟属性,不建库列)
- 不会生成数据库字段,仅ORM提供对象级快捷访问
back_populates实现双向关联同步(改一方自动同步另一方)cascade_delete配置级联删除逻辑- 仅在Python代码操作时生效,原生SQL不受控制
2.3 懒加载 Lazy Loading(默认机制)
查询主表时只执行1条SQL;访问关联属性时才二次查询子表,循环遍历会触发N+1,生产必须用预加载优化。
三、实战1:一对多关联(用户-收货地址,最常用)
3.1 模型完整定义(双向back_populates)
一个用户多个地址,一对多标准模板,附带分层DTO
python
from sqlmodel import SQLModel, Field, Relationship, create_engine, Session, select
from sqlalchemy.orm import selectinload
from typing import Optional, List
# ---------------- 地址子表 ----------------
class AddressBase(SQLModel):
province: str
city: str
detail: str
class AddressCreate(AddressBase):
pass
class AddressPublic(AddressBase):
id: int
# 数据库实体
class Address(AddressBase, SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
# 外键:关联用户表id
user_id: Optional[int] = Field(default=None, foreign_key="user.id", ondelete="CASCADE")
# 反向关系:归属用户
user: Optional["User"] = Relationship(back_populates="addresses")
# ---------------- 用户主表 ----------------
class UserBase(SQLModel):
username: str
email: str
class UserCreate(UserBase):
pass
# 返回DTO,嵌套地址列表
class UserPublic(UserBase):
id: int
addresses: List[AddressPublic] = []
class User(UserBase, SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
# 一对多关系:级联删除,删除用户同步删地址
# Relationship 的核心作用是:告诉 SQLModel,当获取到一个 User 对象时,可以自动获取到该用户关联的所有 Address 对象列表,而不需要手动去写 JOIN 查询语句。
addresses: List[Address] = Relationship(back_populates="user", cascade_delete=True)
# 解决循环引用
# 强制重新构建和验证 Address 这个 Pydantic 模型的内部结构。
# 当两个模型互相引用时(例如 User 包含 List[Address],而 Address 又包含 User),就会发生循环引用(Circular Reference)。
# 在 Python 中,当解释器执行到 Address 类时,User 类可能还没有完全定义好(或者反之)。这会导致 Pydantic 在尝试构建模型字段类型时,找不到对应的类,从而引发报错。
# 为了解决这个问题,SQLModel 和 Pydantic 允许我们在定义关系时使用字符串形式的类型提示(例如 Optional["User"])。但这只是推迟了类型的解析,并没有真正完成模型结构的构建。
Address.model_rebuild()
# 数据库初始化
engine = create_engine("sqlite:///relation1.db", echo=False)
SQLModel.metadata.create_all(bind=engine)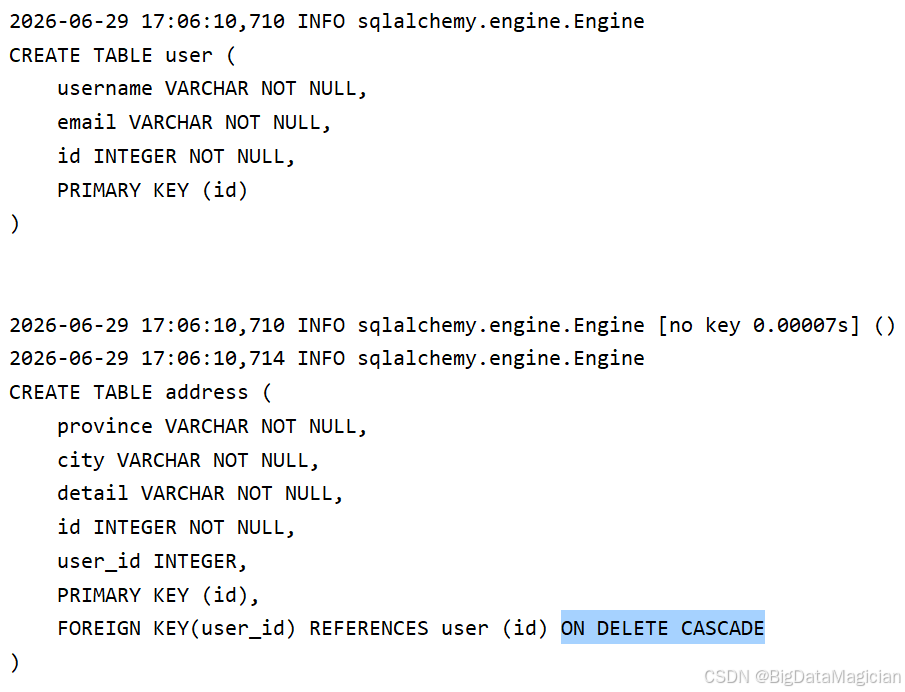
3.2 关联数据新增(两种写法)
python
if __name__ == "__main__":
with Session(engine) as session:
# 写法1:先创建用户,再绑定地址
user1 = User(username="张三", email="zhangsan@qq.com")
addr1 = Address(province="广东", city="深圳", detail="科技园A栋")
addr2 = Address(province="广东", city="深圳", detail="软件园B区")
# 双向自动绑定user_id
user1.addresses.append(addr1)
user1.addresses.append(addr2)
session.add(user1)
session.commit()
session.refresh(user1)
# 写法2:创建地址时直接赋值user对象
user2 = User(username="李四", email="lisi@qq.com")
addr3 = Address(province="北京", city="海淀", detail="中关村", user=user2)
session.add_all([user2, addr3])
session.commit()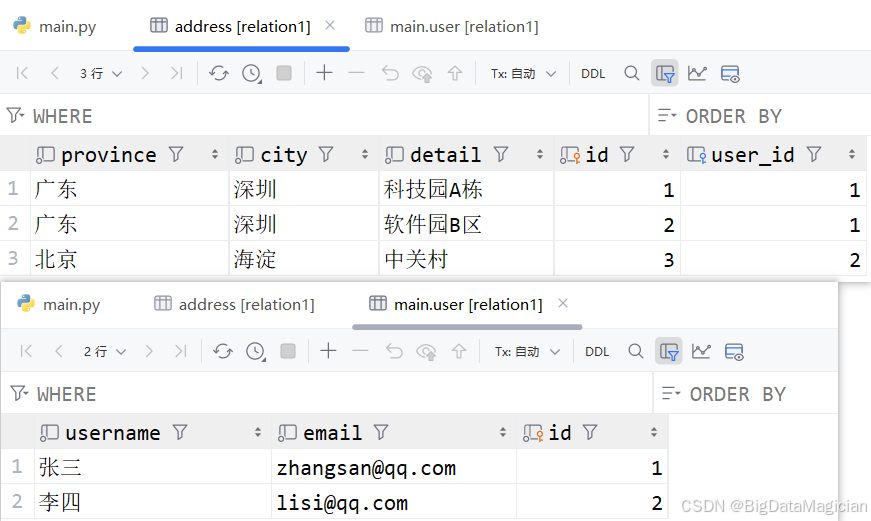
3.3 N+1问题与selectinload预加载优化
3.3.1 错误示范(触发N+1)
python
# 查询所有用户,循环读取地址,每条用户额外执行一次SQL
stmt = select(User)
user_list = session.exec(stmt).all()
for u in user_list:
print(u.addresses) # 循环内访问关联,产生N+13.3.2 正确预加载写法(一次性JOIN查询)
python
# 使用selectinload提前加载关联地址,仅1条SQL
# 1. 构建查询语句 (Statement)
# select(User): 告诉数据库我们需要查询 User 表中的所有记录。
# .options(...): 用于为本次查询配置额外的选项或策略。
# selectinload(User.addresses): 这是一个"预加载(Eager Loading)"策略。
# - 作用:在查询 User 的同时,自动且高效地把每个用户关联的 addresses 列表也查出来。
# - 原理:它会执行两条 SQL。第一条查出所有 User,第二条使用 `IN (...)` 语法一次性查出这些用户的所有地址。
# - 优势:完美避免了 N+1 查询问题(即查了1次用户,又循环查了N次地址),极大提升了查询性能。
stmt = select(User).options(selectinload(User.addresses))
# 2. 执行查询并获取结果
# session.exec(stmt): 将构建好的查询语句发送给数据库执行。
# .all(): 获取查询结果集中的所有记录。
# 返回值 user_list 是一个包含 User 对象的列表,且每个 User 对象的 addresses 属性已经被填充,可以直接使用,无需再次查询数据库。
user_list = session.exec(stmt).all()
# 直接读取,无额外数据库请求
for u in user_list:
print(u.username, [addr.detail for addr in u.addresses])
# DTO序列化直接带出嵌套地址
# model_validate:将传入的对象(通常是 ORM 模型实例或字典)安全地转换并验证为当前 Pydantic 模型(这里是 UserPublic)的实例。
resp_list = [UserPublic.model_validate(u) for u in user_list]
print(resp_list[0].model_dump_json(indent=2))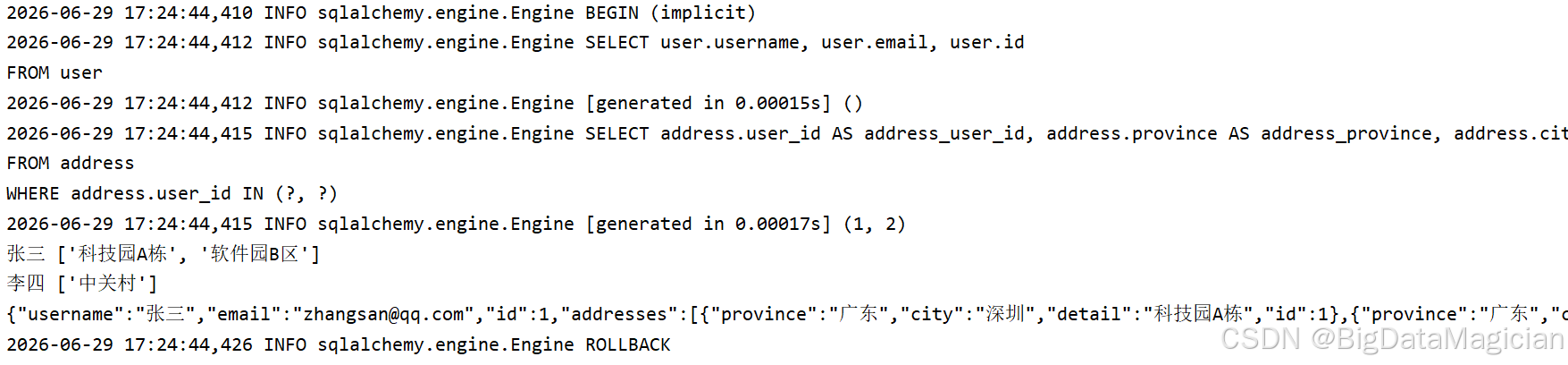
3.4 级联删除演示
python
with Session(engine) as session:
user = session.exec(select(User).where(User.username == "张三")).first()
session.delete(user)
session.commit()
# 用户删除,关联地址自动全部清空(cascade_delete=True生效)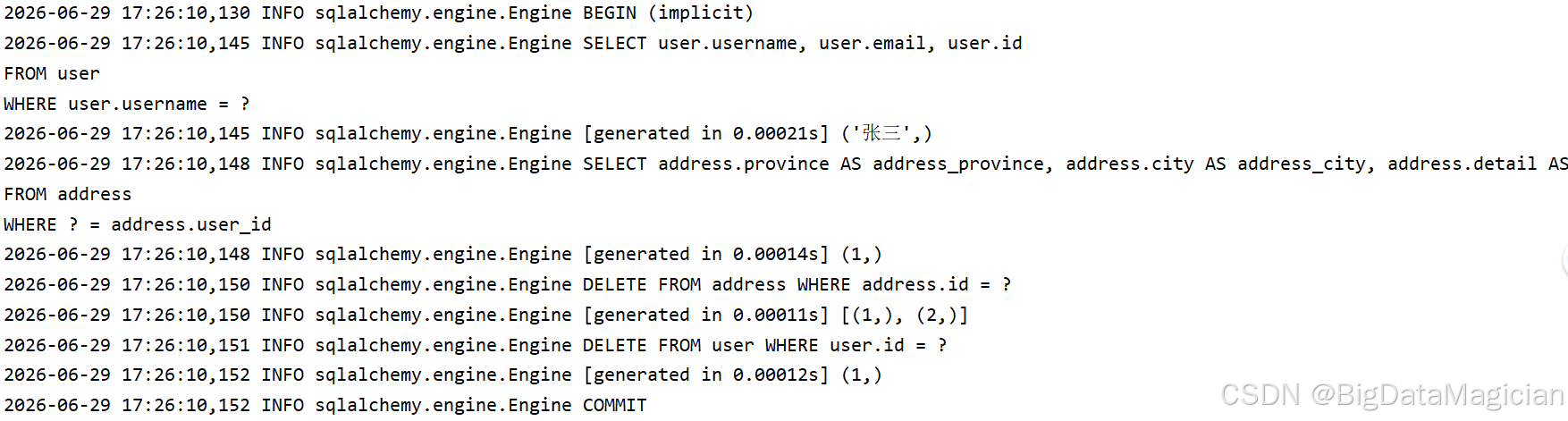
四、多表联查 join、左连接
4.1 内连接 join(只返回有关联数据)
python
# 查询用户+对应地址,仅存在地址的数据
stmt = select(User, Address).join(Address, Address.user_id == User.id)
result = session.exec(stmt).all()
for user, addr in result:
print(user.username, addr.detail)
4.2 左连接 left join(保留无地址用户)
python
stmt = select(User, Address).join(Address, isouter=True)
result = session.exec(stmt).all()4.3 关联条件过滤
python
# 查询深圳地区用户
stmt = select(User).join(Address).where(Address.city == "深圳").distinct()
user_list = session.exec(stmt).all()五、实战2:多对多关联(用户-角色权限)
分两种场景:无扩展字段纯中间表 、带附加字段中间实体
5.1 方案1:纯中间表(仅两外键,无额外字段)
python
from sqlmodel import SQLModel, Field, Relationship, create_engine, Session, select
from sqlalchemy.orm import selectinload
# 中间关联表,table=True,无业务实体类
UserRoleLink = SQLModel.table(
"user_role_link",
Field("user_id", int, foreign_key="user.id", primary_key=True),
Field("role_id", int, foreign_key="role.id", primary_key=True)
)
# 角色表
class Role(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
# 多对多关系
users: List["User"] = Relationship(back_populates="roles", link_model=UserRoleLink)
# 用户表
class User(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
username: str
roles: List[Role] = Relationship(back_populates="users", link_model=UserRoleLink)
Role.model_rebuild()
# 初始化
engine = create_engine("sqlite:///many2many.db", echo=False)
SQLModel.metadata.create_all(engine)新增&查询示例
python
with Session(engine) as session:
# 创建角色
admin = Role(name="管理员")
guest = Role(name="访客")
# 创建用户并绑定多个角色
user = User(username="超级管理员", roles=[admin, guest])
session.add(user)
session.commit()
session.refresh(user)
# 预加载角色避免N+1
stmt = select(User).options(selectinload(User.roles))
res = session.exec(stmt).first()
print([r.name for r in res.roles])5.2 方案2:带扩展字段中间实体(常用:用户角色有效期)
中间表存在expire_time等业务字段,不能用简易table,必须定义独立实体模型
python
from datetime import datetime
# 中间实体(带扩展过期时间)
class UserRoleLink(SQLModel, table=True):
user_id: int = Field(foreign_key="user.id", primary_key=True)
role_id: int = Field(foreign_key="role.id", primary_key=True)
expire_time: datetime # 扩展字段:权限过期时间
# 双向关联
user: Optional["User"] = Relationship(back_populates="role_links")
role: Optional["Role"] = Relationship(back_populates="user_links")
class Role(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
user_links: List[UserRoleLink] = Relationship(back_populates="role")
class User(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
username: str
role_links: List[UserRoleLink] = Relationship(back_populates="user)
UserRoleLink.model_rebuild()六、关联数据增删改完整操作总结
6.1 新增关联
- 主对象.append(子对象) 双向自动填充外键
- 子对象直接赋值主对象实例
addr.user = user
6.2 修改关联
python
user = session.get(User, 1)
# 清空所有地址
user.addresses.clear()
# 替换新地址列表
user.addresses = [Address(city="广州", province="广东", detail="天河")]
session.commit()6.3 删除关联
- 级联删除:配置
cascade_delete=True,删主自动清子 - 手动删除:
session.delete(addr)单独删除单条子数据
七、阶段核心避坑指南
- ❌ 混淆
ForeignKey和Relationship:外键是真实库字段,关系仅内存访问 - ❌ 遗漏
back_populates:双向不同步,修改一方另一方不更新 - ❌ 循环遍历关联对象不使用
selectinload,线上产生N+1卡顿 - ❌ 多对多带扩展字段仍使用简易
SQLModel.table,无法存储附加数据 - ❌ 级联删除只写数据库
ondelete="CASCADE",未配置cascade_delete=True,代码删除不生效 - ✅ 所有列表型关联查询统一搭配
options(selectinload(xxx))预加载 - ✅ 模型存在自引用/循环引用必须执行
.model_rebuild()