一、MongoDB 监控工具全景图
MongoDB 的监控工具可以按响应时效 和数据深度 分为四个层次:
)
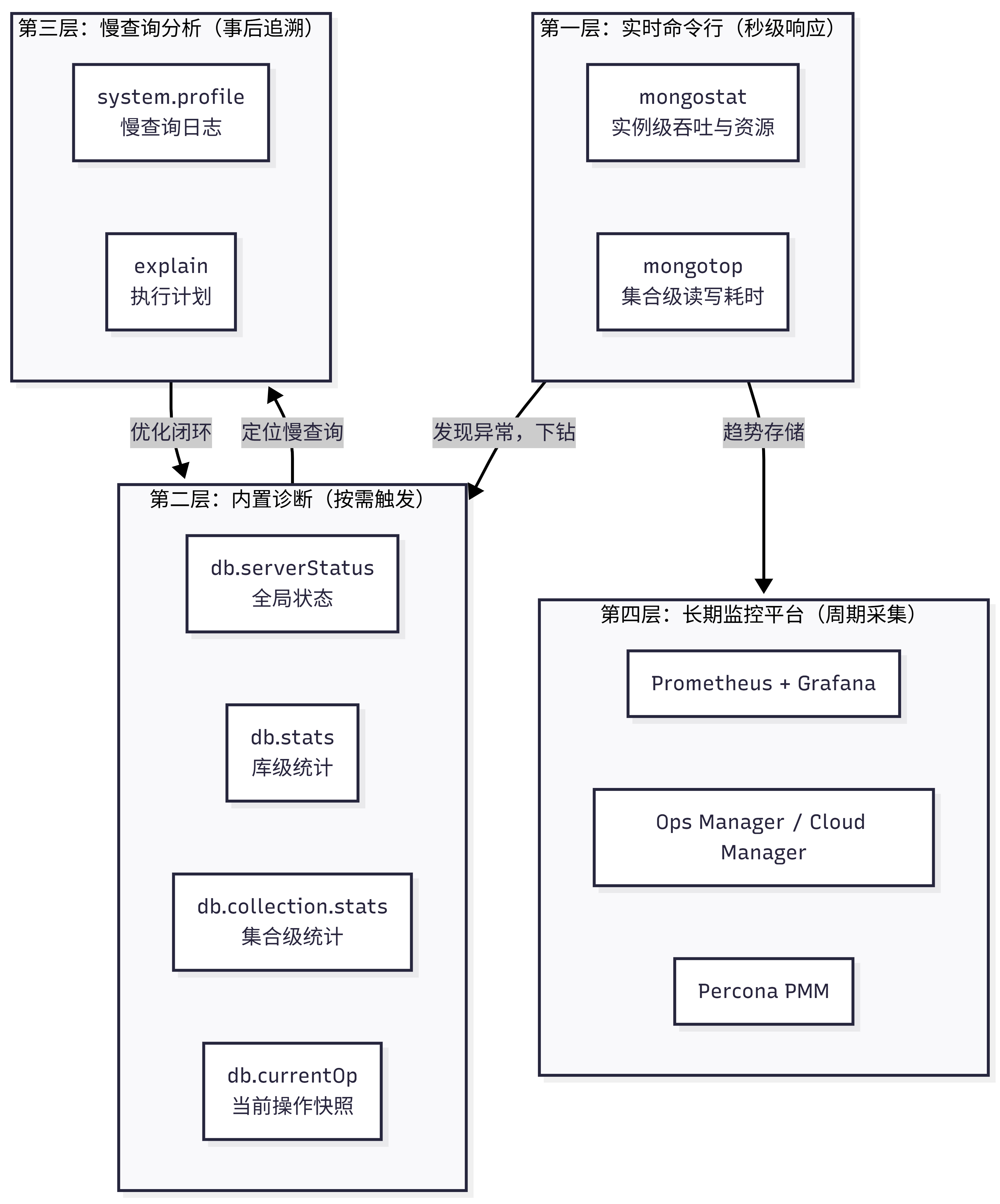
| 层次 | 工具/方法 | 典型场景 | 响应速度 |
|---|---|---|---|
| 实时命令行 | mongostat、mongotop | 突发故障第一响应、日常巡检 | 秒级 |
| 内置诊断 | serverStatus、stats、currentOp | 深度分析、脚本化采集 | 按需(毫秒级返回) |
| 慢查询分析 | system.profile、explain | 性能调优、容量规划 | 事后(分钟/小时级) |
| 长期监控 | Prometheus+Grafana、PMM | 趋势预警、容量预测、SLA 报表 | 周期性(秒/分钟级采集) |
四个层次不是割裂的,而是一个自上而下诊断、自下而上优化 的闭环。日常靠第四层保底,故障时从第一层切入,逐级下钻。
这中间贯穿着一条主线:先看整体 → 下钻到集合 → 定位到具体操作 → 优化并长期观测。
二、mongostat ------ 实例级实时性能仪表盘
1. 工具定位
mongostat 是 MongoDB 发行版自带的轻量级命令行工具,它每秒(可调)捕获一次实例的操作计数和资源状态,并以表格形式输出。它回答了最核心的问题:数据库现在整体忙不忙?在忙什么?
2. 基本用法
bash
# 连接本地默认端口
mongostat "mongodb://root:root@192.168.56.101:27027/?authSource=admin"
# 连接远程副本集(推荐使用 URI,自动发现主节点)
mongostat --uri="mongodb://admin:pass@mongodb0.example.com:27017/?authSource=admin"
# 每 2 秒输出一次,共输出 10 行后退出
mongostat --rowcount 10 --sleep 2
# 输出字段带单位人性化显示(如 1.2G)
mongostat --humanReadable=true权限要求 :执行用户需拥有
serverStatus和replSetGetStatus权限。建议创建专用监控角色:
javascriptdb.createRole({ role: "monitorRole", privileges: [{ resource: { cluster: true }, actions: ["serverStatus", "replSetGetStatus"] }], roles: [] })
3. 核心字段全解析
以下对 mongostat 输出的关键字段进行逐一解读,并给出实战告警阈值:
| 字段 | 含义 | 原理简析 | 告警参考 |
|---|---|---|---|
| insert/query/update/delete | 每秒操作次数(带 * 表示复制操作) |
统计自上次采样以来的增量 | 与业务基线对比,突增/骤降超 50% 需关注 |
| getmore | 每秒游标批量获取次数 | 由 find() 分批返回触发,大结果集查询常见 |
若持续高且伴随 query 不高,可能未用 limit() |
| command | 每秒执行的命令数(如 find、aggregate、count) |
主节点输出格式 `本地 | 复制`(副本集) |
| conn | 当前活跃连接数 | 包括客户端和内部连接 | 接近 net.maxIncomingConnections 的 80% 即警戒 |
| dirty / used | WiredTiger 缓存中脏数据 / 总使用比例(百分比) | 核心指标------见 2.4 节深度解析 | dirty > 5% 告警,> 10% 紧急;used > 95% 告警 |
| flushes | 每秒执行 fsync 将缓存写入磁盘的次数 |
WiredTiger 默认每 60s 一次 checkpoint | 若远超 1次/分钟,说明有主动 fsync 操作 |
| vsize / res | 虚拟内存 / 常驻物理内存(单位:MB/GB) | res 应接近 storage.wiredTiger.engineConfig.cacheSizeGB |
res 持续远超 cacheSizeGB 时说明内存压力大 |
| qrw | 读写操作队列长度(格式:读队列|写队列) | 超过 0 表示操作在等待锁或 IO | 任何非零且持续存在即表示有瓶颈 |
| arw | 活跃的读写操作数(格式:读|写) | 当前正在执行的操作 | 持续高位说明硬件吞吐已达上限 |
| netIn / netOut | 每秒网络入/出流量(字节) | --- | 与带宽容量对比 |
4. 深度原理解析:WiredTiger 缓存与 dirty 指标
dirty 和 used 是 mongostat 中最关键也最易误读的指标。要理解它们,必须深入 WiredTiger 的缓存机制。
WiredTiger 的缓存架构:
- WiredTiger 使用两级缓存:内部缓存(内存)和磁盘数据文件。
- 所有读操作优先从缓存中取数据(
cache),缓存未命中时才触发磁盘读取。 - 写操作先写入内存中的缓存页,并将该页标记为 "dirty"(脏页),随后由后台线程异步刷盘。
检查点(Checkpoint)机制:
WiredTiger 每隔 60 秒 (默认)执行一次全局检查点(checkpoint),将内存中所有脏页的变更以一致性快照的方式写入磁盘。检查点期间,dirty 比例会短暂下降,但检查点的频率是固定的。
dirty 比例持续走高意味着什么?
- 脏数据产生的速度超过了后台刷盘线程(
eviction线程)的消化速度。 - 常见原因:写入量突发暴涨 、磁盘 IOPS 不足 导致刷盘慢、内存太小导致缓存压力过大。
- 当
dirty超过 5%,系统开始进入 "软压力" 状态,后台 eviction 线程会被加速唤醒。超过 20% 时,写入操作会开始被阻塞,直到脏数据被刷出。
used 比例与工作集(Working Set):
used表示当前缓存中有效数据占比(包括干净页和脏页)。- 如果
used持续 > 95%,说明缓存空间已基本占满。此时新的数据页进入缓存,必须驱逐(evict)旧的页,这会消耗额外的 CPU。 - 经验法则 :
used稳定在 70%~85% 是健康状态;95% 以上时,考虑扩大cacheSizeGB或减少工作集大小。
5. 实战场景:通过 mongostat 快速定位故障
场景一:实例突然变慢,但没有报错
bash
$ mongostat
insert query update delete conn dirty used vsize res qrw arw netIn netOut
1200 3400 12 5 128 1.2 72.4 6.1G 3.8G 0|0 3|1 1.8m 3.2mdirty仅 1.2%,缓存健康。qrw=0|0,无排队。used=72.4%,缓存充裕。- 结论 :实例本身负载正常,慢问题大概率出在具体的查询语句上,应进入慢查询分析(见第五章)。
场景二:写入操作卡顿,应用大量超时
bash
$ mongostat
insert query update delete conn dirty used vsize res qrw arw netIn netOut
8500 1200 420 30 512 12.7 96.2 6.1G 5.6G 3|2 5|3 6.8m 9.1mdirty=12.7%远超 5%,used=96.2%接近极限。qrw=3|2有读写排队,arw=5|3活跃线程数很高。- 根因:写入量过高,磁盘刷盘能力不足,缓存堆积大量脏数据。
- 排查方向 :检查是否有大批量导入或密集更新;查看磁盘 IOPS 是否达到瓶颈;考虑调整
eviction_trigger参数或扩容内存/SSD。
三、mongotop ------ 集合级热点定位
1. 工具定位
mongotop 提供每个集合(collection)级别的读写耗时统计 ,是 mongostat 的下钻工具。如果说 mongostat 告诉你"身体发烧了",那 mongotop 就帮你找到"哪个器官发炎了"。
2. 基本用法
bash
# 默认每秒刷新,显示所有集合的读写耗时
mongotop
# 每 30 秒采样一次,更利于观察趋势
mongotop 30
# 连接副本集并指定认证
mongotop --uri="mongodb://admin:pass@mongodb0.example.com:27017/?authSource=admin" 30
# 只输出耗时超过 100ms 的集合(可通过 --threshold 过滤)
mongotop --threshold 1003. 输出格式与字段含义
bash
2025-06-26T10:30:15.123+0800 connected to: mongodb0.example.com
ns total read write
test.orders 82403ms 12ms 82391ms
test.inventory 1520ms 1120ms 400ms
admin.system.users 5ms 5ms 0ms
local.oplog.rs 340ms 340ms 0ms| 字段 | 含义 |
|---|---|
| ns | 命名空间,格式为 数据库名.集合名 |
| total | 该集合在此采样周期内的读写总耗时(毫秒) |
| read | 该集合读操作的耗时总和 |
| write | 该集合写操作的耗时总和 |
注意 :
mongotop统计的是耗时(等待+执行),而非操作次数。一个集合 total 很高,不一定意味着 QPS 高,也可能是单次操作特别慢(如全表扫描)。
4. 实战解读与排查流程
场景:观察到 test.orders 的 total 高达 82403ms,远高于其他集合
排查步骤:
- 确认是读主导还是写主导 :本例
write=82391ms占绝对大头,说明是写入热点。 - 查看该集合的索引策略:高写入耗时通常意味着每次更新/插入要维护大量索引,或索引不适合。
- 检查是否有大量 upsert 或 array 更新:这类操作在 WiredTiger 中可能触发页分裂,加剧写入延迟。
- 查看
db.collection.stats()分析该集合的索引数量和平均文档大小。 - 结合慢查询日志 定位具体慢写入语句。
阈值参考(基于三节点副本集、SSD 存储):
total持续 < 1000ms:健康。total在 1000~5000ms:可接受,需关注趋势。total持续 > 5000ms:必须介入,该集合已成为瓶颈。
5. 副本集环境下的特殊关注
在副本集中,主节点(Primary) 的 mongotop 显示的是业务读写耗时;从节点(Secondary) 的 mongotop 则会显示大量 local.oplog.rs 的读取耗时(因为从节点通过拉取 oplog 来复制数据)。
- 如果从节点的
local.oplog.rs读取耗时异常高,同时业务集合的写耗时也很高,说明复制延迟正在发生。 - 对比主从节点的
mongotop输出,可以辅助判断延迟是来源于网络还是从节点自身的写入能力。
四、内置诊断命令 ------ 系统化的深度透视
1. db.serverStatus() ------ 全局状态总览
db.serverStatus() 是 MongoDB 最全面的内置诊断命令,返回一个包含数百个指标的 JSON 文档。它不会对性能造成明显影响,可放心在线上使用。
javascript
// 在 mongosh 中执行
db.serverStatus()
// 针对性查看关键维度(避免输出过大)
db.serverStatus().connections
db.serverStatus().mem
db.serverStatus().opcounters
db.serverStatus().opLatencies
db.serverStatus().wiredTiger关键指标分组解读
(1)连接与网络
| 指标 | 含义 | 解读 |
|---|---|---|
connections.current |
当前连接数 | 应与 net.maxIncomingConnections(默认 65536)对比 |
connections.available |
剩余可用连接 | 低于 100 时需排查是否有连接泄漏 |
network.bytesIn / bytesOut |
累计网络流量 | 用于计算平均带宽占用 |
(2)操作计数与延迟(OpCounters & OpLatencies)
| 指标 | 含义 |
|---|---|
opcounters.insert/query/update/delete |
自启动以来的累计操作次数 |
opLatencies.reads.latency |
读操作的总延迟(微秒) |
opLatencies.reads.ops |
读操作总次数 |
opLatencies.reads.avg |
平均读延迟(可通过 latency / ops 计算) |
实战技巧 :
opcounters的绝对值意义不大,应与其历史基线 对比。例如,如果query计数在过去 5 分钟内的增量突然翻倍,说明业务或流量发生了变化。
(3)内存与缓存(WiredTiger 核心)
在 wiredTiger.cache 路径下:
| 指标 | 含义 |
|---|---|
bytes currently in the cache |
当前缓存数据字节数 |
bytes dirty in the cache |
当前脏数据字节数 |
pages read into cache |
从磁盘读入缓存的总页数 |
pages written from cache |
从缓存写入磁盘的总页数 |
pages evicted by application threads |
应用线程主动驱逐的页数(若过高说明缓存压力大) |
tracked dirty bytes in the cache |
追踪中的脏字节数 |
计算缓存命中率:
命中率 = 1 - (pages read into cache) / (pages requested from cache)理想值应 > 99%。若命中率低于 95%,说明内存严重不足,大量读请求穿透到磁盘。
2. db.stats() ------ 数据库级存储统计
db.stats() 返回当前数据库的存储概览,常用于容量规划和碎片分析。
javascript
use myApp
db.stats()关键输出示例:
json
{
"db": "myApp",
"collections": 12,
"views": 2,
"objects": 8450000,
"avgObjSize": 512,
"dataSize": 4326400000,
"storageSize": 5120000000,
"indexes": 34,
"indexSize": 1536000000,
"totalSize": 6656000000,
"ok": 1
}| 字段 | 含义 | 实战解读 |
|---|---|---|
dataSize |
逻辑数据大小(压缩后,不含索引) | 反映真实数据量 |
storageSize |
磁盘上实际分配的存储空间 | 大于 dataSize 是因预分配和碎片 |
indexSize |
所有索引的总大小 | 索引大小不应超过数据大小的 2 倍 |
avgObjSize |
平均文档大小 | 过大(>1MB)需考虑子文档拆分 |
如果 storageSize 远大于 dataSize(如 2 倍以上),说明存在大量存储碎片,可考虑执行 compact(副本集需滚动操作)。
bash
db.runCommand({ compact: "<集合名>" })3. db.collection.stats() ------ 集合级深度诊断
db.collection.stats() 提供指定集合的详细统计,是排查单个集合性能问题的核心工具。
javascript
db.orders.stats()
db.orders.stats(1024) // 以 KB 为单位显示重点关注字段:
| 字段 | 含义 | 告警条件 |
|---|---|---|
count |
文档总数 | 与预期不符可能说明同步延迟或业务异常 |
size |
数据占用(压缩后) | --- |
avgObjSize |
平均文档大小 | 突增说明文档结构变化 |
storageSize |
磁盘分配空间 | 明显大于 size 说明需 compact |
nindexes |
索引数量 | 超过 7 个需审慎评估(写入性能影响) |
totalIndexSize |
索引总大小 | --- |
indexSizes |
每个索引的大小详情 | 可发现异常大的索引 |
capped |
是否为固定集合 | --- |
wiredTiger.creationString |
WiredTiger 创建配置 | 可看到 block_compressor 等信息 |
经典场景 :某个集合查询变慢,执行 db.orders.stats() 后发现 totalIndexSize 高达 size 的 3 倍,且 indexSizes 中有一个很少使用的字段索引非常大。结论:维护过多无用索引,占用了内存并拖慢了写入,建议删除冗余索引。
4. db.currentOp() ------ 当前操作快照
db.currentOp() 返回正在执行的所有操作,是诊断"卡住"问题和死锁的利器。
javascript
// 查看所有活跃操作
db.currentOp({ active: true })
// 查看运行超过 5 秒的查询
db.currentOp({
active: true,
secs_running: { $gt: 5 }
})
// 查看特定数据库的操作
db.currentOp({ ns: /^myApp/ })关键输出字段:
opid:操作 ID,可用于db.killOp(opid)终止。ns:操作的命名空间。command:执行的命令内容。secs_running:已运行秒数。waitingForLock:是否在等待锁。locks:当前持有的锁类型。
五、慢查询分析 ------ system.profile 与 explain 闭环
当 mongostat 显示实例繁忙,且 mongotop 定位到热点集合后,下一步就是找到具体是哪条查询(或写入)在作祟。这需要依赖数据库分析器和执行计划工具。
1. 开启与配置系统分析器(Profiler)
MongoDB 内建的分析器会将耗时超过阈值的操作写入 system.profile 集合。
javascript
// 查看当前分析级别:0=关闭,1=记录慢查询,2=记录所有操作
db.getProfilingLevel()
// 设置级别为 1,慢查询阈值 100ms(推荐生产环境)
db.setProfilingLevel(1, { slowms: 100 })
// 查看当前设置
db.getProfilingStatus()级别选择建议:
- 0(关闭):仅用于极致性能压测,不推荐生产环境。
- 1(慢查询) :推荐。阈值依据业务核心查询的平均耗时 * 1.5~2 倍设置。
- 2(全部操作):仅调试临时开启,会显著增加系统开销。
2. 查询 system.profile 定位慢操作
javascript
// 按时间倒序查看最近的 10 条慢查询
db.system.profile.find().sort({ ts: -1 }).limit(10)
// 查找耗时超过 1 秒的查询,按耗时降序
db.system.profile.find({ millis: { $gt: 1000 } }).sort({ millis: -1 })
// 按集合过滤,查看特定表的慢操作
db.system.profile.find({ ns: "myApp.orders" })
// 查看全表扫描的慢查询(即未使用索引)
db.system.profile.find({ "planSummary": { $regex: /COLLSCAN/ } })system.profile 常用字段:
| 字段 | 含义 |
|---|---|
ts |
执行时间戳 |
ns |
命名空间 |
op |
操作类型(query/update/insert/delete/command) |
millis |
执行耗时(毫秒) |
command |
完整的命令或查询语句 |
planSummary |
执行计划摘要(如 IXSCAN、COLLSCAN) |
nreturned |
返回文档数 |
keysExamined |
扫描的索引键数 |
docsExamined |
扫描的文档数 |
3. explain() 分析执行计划
从 system.profile 中找到可疑的慢查询语句后,使用 explain("executionStats") 获取详细执行计划:
javascript
db.orders.find({
customerId: "C10086",
status: "pending",
createdAt: { $gte: ISODate("2025-01-01") }
}).explain("executionStats")输出中的核心指标及诊断规则:
| 指标 | 含义 | 健康标准 |
|---|---|---|
executionTimeMillis |
该查询实际执行耗时 | --- |
totalKeysExamined |
扫描的索引条目数 | 应接近 nReturned |
totalDocsExamined |
扫描的文档数 | 应接近 nReturned |
nReturned |
返回的文档数 | --- |
stage |
顶层执行阶段 | 避免 COLLSCAN |
inputStage.stage |
子执行阶段 | IXSCAN(索引扫描)为优 |
经验法则:
- 若
totalDocsExamined远大于nReturned(如 1000 倍),则索引选择性差或未命中索引。 - 若
stage为COLLSCAN,必须创建索引。 - 若
totalKeysExamined接近totalDocsExamined但远大于nReturned,说明索引字段区分度不足,需考虑复合索引。
示例:创建有效的复合索引
根据上述查询条件,可创建:
javascript
db.orders.createIndex({ customerId: 1, status: 1, createdAt: -1 })创建后再次执行 explain(),确认 stage 变为 FETCH(从索引回表)或 IXSCAN,且 totalDocsExamined 大幅降低。
六、监控体系搭建 ------ 从命令到平台化
1. 分层监控架构设计
一个成熟的 MongoDB 生产环境监控体系,应包含以下五个层次:
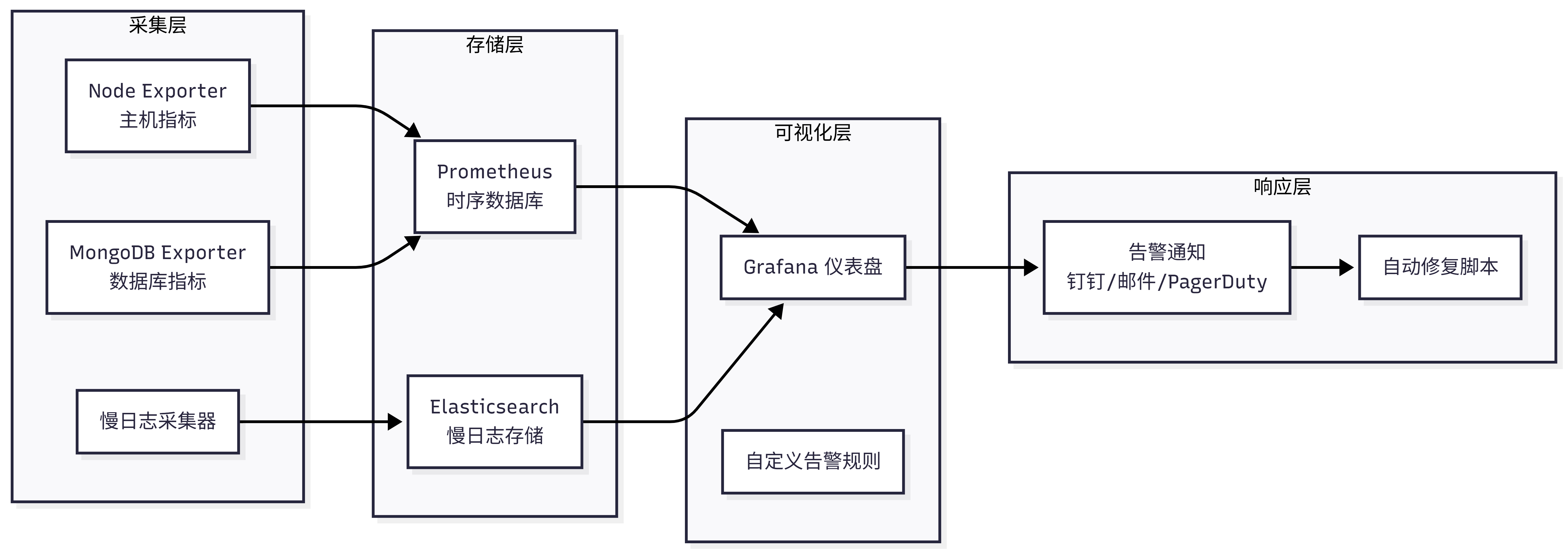
2. 开源方案推荐:Prometheus + Grafana
这是社区最成熟的组合,MongoDB 官方也提供了 Prometheus Exporter:
bash
# 启动 MongoDB Exporter
mongodb_exporter \
--mongodb.uri="mongodb://admin:pass@localhost:27017" \
--collector.database \
--collector.collection \
--collector.topmetrics \
--collector.indexusageGrafana 仪表盘建议 :使用社区广泛验证的 MongoDB 官方仪表盘(ID: 1860),或 Percona 提供的详细仪表盘。关键面板至少包括:
- QPS 与操作类型分布
- 连接数趋势
- WiredTiger 缓存命中率与 dirty 比例
- 复制延迟
- 各集合的读写耗时(Top 10)
告警规则示例(基于 Prometheus 语法):
| 告警规则 | 表达式 | 持续时间 | 级别 |
|---|---|---|---|
| 脏数据比例过高 | mongodb_mongostat_dirty * 100 > 8 |
2m | Warning |
| 脏数据紧急 | mongodb_mongostat_dirty * 100 > 15 |
1m | Critical |
| 缓存使用率过高 | mongodb_mongostat_used * 100 > 95 |
5m | Warning |
| 复制延迟 | time() - mongodb_replset_member_optimeDate > 10 |
1m | Critical |
| 连接数接近上限 | mongodb_connections_current / mongodb_connections_available < 0.2 |
2m | Warning |
七、面试题精选
Q1:用户反馈应用写入超时,登录到 MongoDB 主节点执行 mongostat,看到 dirty 持续 15%,used 98%,qrw 显示 4|2。请说出你的完整排查思路和应对措施。
参考答案:
第一步:现象确认 ------ 从 mongostat 可判断,系统处于缓存高压 + 写入阻塞 状态。dirty=15% 说明脏数据已严重堆积,used=98% 说明缓存几近占满,qrw=4|2 说明有操作在排队等待资源。
第二步:根因定位 ------ 导致脏数据堆积的原因通常有三类:
- 磁盘 IOPS 瓶颈:后台刷盘线程无法及时将脏页落盘。
- 写入流量突增:业务批量导入或密集更新突发。
- 内存不足 :
cacheSizeGB设置过小,工作集超过物理内存。
第三步:快速止血 ------ 如果应用允许,先限流或暂停批量写入操作,避免情况恶化。同时检查磁盘 IO 使用率(如 iostat -x 1),若 %util 接近 100%,确认磁盘瓶颈。
第四步:长期措施:
- 若磁盘 IOPS 不足,升级为本地 NVMe SSD 或提高云盘 IOPS 上限。
- 调整 WiredTiger 刷盘参数:
eviction_trigger和eviction_target(默认无需修改,除非专家调优)。 - 考虑增加
storage.wiredTiger.engineConfig.cacheSizeGB(注意留足内存给操作系统文件缓存)。 - 检查业务写入模式,是否可以改为批量写入或降低写入频率。
Q2:mongotop 显示 test.orders 的 total 高达 30 秒,但该集合的 QPS 只有 200,且索引齐全。你认为可能的原因是什么?如何进一步排查?
参考答案:
原因分析 :mongotop 统计的是总耗时 而非单个操作耗时。total=30s 且 QPS 只有 200,说明单次操作平均耗时高达 150ms(30,000ms / 200),这是不正常的。索引齐全,但仍慢,指向以下可能:
- 索引没有被使用 :查询条件字段顺序与复合索引不匹配,或使用
$or、$regex等无法有效利用索引的操作。 - 大量文档被扫描:虽然索引命中了,但选择性很差(如索引字段只有 2 个枚举值),导致仍要回表扫描大量文档。
- 文档体积过大:每个文档大小超过几 MB,即使通过索引找到,回表取数据也消耗大量时间。
- 锁等待或页分裂:高并发下写入导致 WiredTiger 页分裂,读操作被阻塞。
进一步排查步骤:
- 从
system.profile中捞出该集合最近的慢查询,用explain("executionStats")确认实际执行计划。 - 检查
totalKeysExamined和totalDocsExamined,若后者远大于前者,则索引选择性差。 - 查看
db.collection.stats().avgObjSize,若远大于正常值,考虑拆分文档。 - 结合
db.currentOp()查看是否有长时间持有锁的操作。
Q3:你的监控系统发现副本集的从节点延迟持续增大,从正常的 1s 增长到 10 分钟。你如何定位原因并解决?
参考答案:
定位思路:
- 确认延迟量 :在从节点执行
rs.status().members[1].optimeDate与主节点对比。 - 查看从节点的 mongostat :重点看
qrw和dirty。如果从节点dirty过高,说明从节点自身写入能力不足(可能硬件较差)。 - 查看从节点的
db.currentOp():是否有长时间运行的查询(比如报表分析)阻塞了 oplog 重放?从节点重放 oplog 是单线程的,如果一个分析查询耗时 5 分钟,这 5 分钟内的所有新 oplog 都会积压。 - 检查网络带宽 :主从间
netOut是否接近带宽上限。
解决方案:
- 若是从节点硬件差,考虑升级配置或将读流量切到其他从节点。
- 若是长查询阻塞,终止该操作(
db.killOp())或将其移至只读的隐藏节点(hidden: true, priority: 0)执行。 - 若网络问题,检查交换机或跨机房专线质量。
Q4:某日凌晨,MongoDB 实例的 used 缓存比例从 70% 缓慢上升至 98%,但 dirty 始终低于 3%,查询响应时间没有明显变化。请分析这种现象是否正常,以及是否需要处理。
参考答案:
现象定性 :这是典型的工作集增长现象,但不一定危险。
used上升表示缓存中存储的数据页越来越多,说明查询正在访问此前不常用的数据,将其读入缓存。dirty保持低位,说明没有写入压力,刷盘线程工作正常。- 查询响应时间未变化,说明缓存命中率依然足够高(因为新加载的数据也服务了请求)。
是否需要处理:
- 如果
used上升到 99%~100% 并且开始出现缓存驱逐(pages evicted by application threads计数上升),同时查询变慢,则需要介入。 - 若稳定在 98% 但无驱逐,说明工作集恰好略大于缓存大小,属于临界状态,建议提前扩容内存 或调整
cacheSizeGB。 - 同时检查是否有不合理的全表扫描操作,将大量无关数据加载进缓存,挤占了热数据空间。
Q5:你团队有 20 套 MongoDB 副本集,手工执行 mongostat 已经无法满足日常巡检需求。请你设计一套最低成本的自动化监控方案,并说明核心指标和告警维度。
参考答案:
方案设计(低成本选型):
- 采集层 :在每套集群的主机上部署
mongodb_exporter,或使用 Telegraf 的 MongoDB 插件,采集间隔 30 秒。 - 存储层:单机部署 Prometheus(使用 2TB 磁盘,可保存 30 天)。
- 可视化与告警:Grafana 搭建统一仪表盘,并配置 AlertManager 发送钉钉/邮件告警。
- 补充 :使用
mtail或 Filebeat 采集慢查询日志,存入 Elasticsearch 供临时检索。
核心指标与告警维度(优先级排序):
- S级(立即告警):节点宕机、复制延迟 > 60s、连接数耗尽(< 5% available)、dirty > 10%。
- A级(预警):dirty > 5%、缓存命中率 < 95%、CPU 使用率 > 80%、磁盘可用空间 < 20%。
- B级(日常观察):QPS 趋势、索引大小增长、各集合存储空间变化。
附录:快速索引
| 需求 | 推荐命令/工具 |
|---|---|
| 看一眼整体负载 | mongostat |
| 找热点集合 | mongotop |
| 查全局状态 | db.serverStatus() |
| 看库存储 | db.stats() |
| 看集合详情 | db.collection.stats() |
| 看当前卡住的操作 | db.currentOp() |
| 查慢查询日志 | db.system.profile.find() |
| 分析执行计划 | .explain("executionStats") |
| 长期监控平台 | Prometheus + Grafana / Ops Manager |