1. 分数匹配(Score Matching)的公式使用了tr()
写这个博文,是因为在看《分数匹配(Score Matching)》(就是一种概率密度估计的方法) 相关文献时候,发现了分数匹配的目标函数的变换过程。然后意识到:一个向量场的散度等于其雅可比矩阵的迹。
分数匹配的目标函数定义:在所有可能的数据点 x 上,取模型分数 s_θ(x) 和真实分数 s_data(x) 之间平方距离的平均值,并让它最小化。
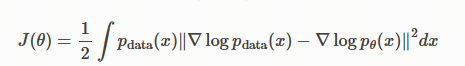
s_data(x) 是我们想要去逼近的真实数据分布的分数,在绝大多数情况下,这个值是未知且无法直接计算的。因此,我们不能直接优化这个目标函数。
分别定义 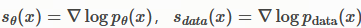
得到了目标函数的一个等价表示。(公式来源:基于分数的生成模型(Score-based generative models))
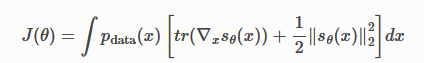
这个新公式的强大之处在于:
- 它完全消除了 s_data(x)。
- 公式中的所有项(tr(∇ₓ s_θ(x)) 和 ||s_θ(x)||₂²)都只依赖于模型 s_θ(x) 和可采样的数据 p_data(x)。
因此,我们可以通过从真实数据分布 p_data(x) 中采样样本 x,然后计算这个新公式的值,并用梯度下降法来优化模型参数 θ,从而使模型分数 s_θ(x) 趋近于真实的 s_data(x)。
要理解这个表达式,我们需要先分解它:
- s_θ(x) : 这是一个向量 。分数(Score)或得分函数 ,是某个对数概率密度函数的梯度。对于每一个输入
x,它都会输出一个向量。 - ∇ₓ : 这是一个梯度算子 。 如果
s_θ(x)是一个 n 维向量,那么∇ₓ s_θ(x)就是一个n x n的方阵。 - tr(∇ₓ s_θ(x)) : 现在,迹运算
tr()就作用于这个n x n的矩阵上。
1.2、为什么目标函数会"等价"?
更准确的理解是:为了摆脱对未知项 s_data(x) 的依赖,原始的均方误差目标函数在数学上被等价地变换成了由 tr(∇ₓ s_θ(x)) 和 ||s_θ(x)||₂² 组成的新目标函数。
让我们简单看看这个变换是怎么来的。我们将展开原始的、不可行的目标函数:
∥ s d a t a ( x ) − s θ ( x ) ∥ 2 2 = ∥ s d a t a ( x ) ∥ 2 2 + ∥ s θ ( x ) ∥ 2 2 − 2 ⋅ s d a t a ( x ) T s θ ( x ) \| s_{data}(x) - s_{\theta}(x) \|2^2 = \| s{data}(x) \|2^2 + \| s{\theta}(x) \|2^2 - 2 \cdot s{data}(x)^T s_{\theta}(x) ∥sdata(x)−sθ(x)∥22=∥sdata(x)∥22+∥sθ(x)∥22−2⋅sdata(x)Tsθ(x)
当我们把这个展开式代入 J(θ) 并对 x 求期望(即积分)时,会得到三项:
- 1 2 E p d a t a ∥ s d a t a ( x ) ∥ 2 2 \frac{1}{2} \mathbb{E}{p{data}} \\\| s_{data}(x) \\\|_2\^2 21Epdata∥sdata(x)∥22: 这一项是常数,与模型参数
θ无关,在求导最小化时可以忽略。 - 1 2 E p d a t a ∥ s θ ( x ) ∥ 2 2 \frac{1}{2} \mathbb{E}{p{data}} \\\| s_{\\theta}(x) \\\|_2\^2 21Epdata∥sθ(x)∥22: 这一项正是新目标函数中的第二项。
- − E p d a t a s d a t a ( x ) T s θ ( x ) -\mathbb{E}{p{data}} s_{data}(x)\^T s_{\\theta}(x) −Epdatasdata(x)Tsθ(x): 这一项包含了
s_data,是我们不想要的。但是,通过分部积分 ,可以证明这一项等于 + E p d a t a t r ( ∇ x s θ ( x ) ) E_{p_{data}} tr(∇_x s_θ(x)) Epdatatr(∇xsθ(x))。
所以,经过等价变换后,我们最终需要优化的目标函数就变成了:
J ( θ ) = 常数项 + E p d a t a t r ( ∇ x s θ ( x ) ) + ½ ∣ ∣ s θ ( x ) ∣ ∣ 2 2 J(θ) = 常数项 + E_{p_data} tr(∇_x s_θ(x)) + ½ \|\|s_θ(x)\|\|_2\^2 J(θ)=常数项+Epdatatr(∇xsθ(x))+½∣∣sθ(x)∣∣22
在分数匹配 这个特定的框架下,原始的、包含未知量的距离度量 (||s_data - s_θ||²),通过数学上的等价变换,被成功地转化为了一个只包含模型本身性质 的、可计算 的新目标函数。这个新函数自然地由散度项 (tr(∇ₓ s_θ(x)))和模方项 (||s_θ(x)||₂²)这两部分组成。
1.3 通过分部积分证明
− E p d a t a s d a t a ( x ) T s θ ( x ) -\mathbb{E}{p{data}} s_{data}(x)\^T s_{\\theta}(x) −Epdatasdata(x)Tsθ(x): 这一项包含了 s_data,是我们不想要的。但是,通过分部积分 ,可以证明这一项等于 + E p d a t a t r ( ∇ x s θ ( x ) ) E_{p_{data}} tr(∇_x s_θ(x)) Epdatatr(∇xsθ(x))。
这是理解分数匹配(Score Matching)理论的核心,也是证明为什么我们可以用 s_θ(x) 来逼近 s_data(x) 而不需要知道 s_data(x) 的数学基础。
推导目标
我们的目标是通过分部积分,将包含未知真实分数的项:
− E p d a t a ( x ) s d a t a ( x ) T s θ ( x ) - \mathbb{E}{p{data}(x)} s_{data}(x)\^T s_{\\theta}(x) −Epdata(x)sdata(x)Tsθ(x)
变换成只包含模型分数 s_θ(x) 的项:
- E p d a t a ( x ) tr ( ∇ x s θ ( x ) ) + \mathbb{E}{p{data}(x)} \\text{tr}(\\nabla_x s_{\\theta}(x)) +Epdata(x)tr(∇xsθ(x))
为了清晰起见,我们先进行符号简化:
- 令
s = s_θ(x),这是我们的模型分数。 - 令
s* = s_data(x),这是真实的、未知的分数。 - 令
p = p_data(x),这是真实数据的概率密度函数。
第一步:写出期望的积分形式
我们关注的目标项是:
− E p d a t a ( x ) s d a t a ( x ) T s θ ( x ) - \mathbb{E}{p{data}(x)} s_{data}(x)\^T s_{\\theta}(x) −Epdata(x)sdata(x)Tsθ(x)
将其写为积分形式:
= − ∫ p ( x ) ( s ∗ ( x ) ) T s ( x ) d x = - \int p(x) (s^*(x))^T s(x) dx =−∫p(x)(s∗(x))Ts(x)dx
这里的积分是对整个数据空间进行的。p(x) 是一个标量函数,(s*(x))ᵀ s(x) 是两个向量的点积,也是一个标量。我们可以把它们写在一起:
= − ∫ p ( x ) ∑ i = 1 n s i ∗ ( x ) s i ( x ) d x = - \int p(x) \sum_{i=1}^{n} s^*_i(x) s_i(x) dx =−∫p(x)∑i=1nsi∗(x)si(x)dx
= − ∑ i = 1 n ∫ p ( x ) s i ∗ ( x ) s i ( x ) d x = - \sum_{i=1}^{n} \int p(x) s^*_i(x) s_i(x) dx =−∑i=1n∫p(x)si∗(x)si(x)dx
其中 s_i(x) 是向量 s(x) 的第 i 个分量。
第二步:代入分数的定义
这是最核心的一步。我们知道:
分数(基于数据变量 x 的一阶偏导)
s(x) = s_θ(x) = ∇ₓ log p_θ(x)s*(x) = s_data(x) = ∇ₓ log p(x)
根据梯度的定义,s_i(x) 和 s*_i(x) 可以写成:
s_i(x) = ∂(log p_θ(x)) / ∂x_is*_i(x) = ∂(log p(x)) / ∂x_i
利用链式法则,∂(log f(x)) / ∂x_i = (∂f(x)/∂x_i) / f(x),我们可以得到:
s*_i(x) = (1/p(x)) * (∂p(x)/∂x_i)
现在,把这个 s*_i(x) 的表达式代回我们的积分中:
- ∫ p(x) s*_i(x) s_i(x) dx = - ∫ p(x) [ (1/p(x)) * (∂p(x)/∂x_i) ] s_i(x) dx
注意 p(x) 和 1/p(x) 抵消了!这非常关键。公式简化为:
= - ∫ (∂p(x)/∂x_i) s_i(x) dx
第三步:应用分部积分法
现在我们对积分 ∫ (∂p(x)/∂x_i) s_i(x) dx 应用分部积分法。
分部积分法 (一维形式)是:∫ u dv = uv - ∫ v du
在多维情况下,我们对 x_i 这个维度进行分部积分。
- 令
u = s_i(x),则du = (∂s_i(x)/∂x_i) dx_i - 令
dv = (∂p(x)/∂x_i) dx_i,则v = p(x)(因为我们是对x_i积分,其他维度是常数)
应用分部积分公式:
∫ (∂p/∂x_i) s_i dx = [ p(x) s_i(x) ]_boundary - ∫ p(x) (∂s_i/∂x_i) dx
这里的 [ ... ]_boundary 表示积分区域的边界。
一个关键的假设: 在机器学习和概率密度估计中,我们通常假设概率密度函数 p(x) 在数据空间的无穷远处迅速衰减到0。也就是说,lim_{||x||→∞} p(x) = 0。在这个假设下,边界项 [ p(x) s_i(x) ]_boundary 就变成了 0 * s_i = 0。
因此,边界项消失,我们得到:
- ∫ (∂p/∂x_i) s_i dx = - [ 0 - ∫ p(x) (∂s_i/∂x_i) dx ]
= + ∫ p(x) (∂s_i(x)/∂x_i) dx
第四步:从积分回到期望
我们将上一步的结果代回我们最初的求和式中:
原始项 = − ∑ i = 1 n ∫ p ( x ) s i ∗ ( x ) s i ( x ) d x - \sum_{i=1}^{n} \int p(x) s^*_i(x) s_i(x) dx −∑i=1n∫p(x)si∗(x)si(x)dx
= + ∑ i = 1 n ∫ p ( x ) ∂ s i ( x ) ∂ x i d x + \sum_{i=1}^{n} \int p(x) \frac{\partial s_i(x)}{\partial x_i} dx +∑i=1n∫p(x)∂xi∂si(x)dx
现在,我们可以把求和符号放进积分里面,并且识别出期望的形式:
= + ∫ p ( x ) ∑ i = 1 n ∂ s i ( x ) ∂ x i d x + \int p(x) \\sum_{i=1}\^{n} \\frac{\\partial s_i(x)}{\\partial x_i} dx +∫p(x)∑i=1n∂xi∂si(x)dx
= + E p ( x ) ∑ i = 1 n ∂ s i ( x ) ∂ x i + \mathbb{E}_{p(x)} \\sum_{i=1}\^{n} \\frac{\\partial s_i(x)}{\\partial x_i} +Ep(x)∑i=1n∂xi∂si(x)
第五步:识别雅可比矩阵的迹 (Trace)
现在,我们来看看表达式 ∑ i = 1 n ∂ s i ( x ) ∂ x i \sum_{i=1}^{n} \frac{\partial s_i(x)}{\partial x_i} ∑i=1n∂xi∂si(x)。
s(x)是一个向量[s₁(x), s₂(x), ..., sₙ(x)]ᵀ。- ∇ x s ( x ) \nabla_x s(x) ∇xs(x) 是
s(x)关于x的雅可比矩阵。这个矩阵的第i行第j列元素是 ∂ s i ( x ) ∂ x j \frac{\partial s_i(x)}{\partial x_j} ∂xj∂si(x)。 - 因此,雅可比矩阵的**迹(Trace)**是其主对角线元素之和,也就是:
tr ( ∇ x s ( x ) ) = ∑ i = 1 n ∂ s i ( x ) ∂ x i \text{tr}(\nabla_x s(x)) = \sum_{i=1}^{n} \frac{\partial s_i(x)}{\partial x_i} tr(∇xs(x))=∑i=1n∂xi∂si(x)
所以,我们的表达式最终变成了:
原始项 = + E p d a t a ( x ) tr ( ∇ x s θ ( x ) ) + \mathbb{E}{p{data}(x)} \\text{tr}(\\nabla_x s_{\\theta}(x)) +Epdata(x)tr(∇xsθ(x))
总结
通过以上五步推导,我们证明了:
− E p d a t a ( x ) s d a t a ( x ) T s θ ( x ) = + E p d a t a ( x ) tr ( ∇ x s θ ( x ) ) - \mathbb{E}{p{data}(x)} s_{data}(x)\^T s_{\\theta}(x) = + \mathbb{E}{p{data}(x)} \\text{tr}(\\nabla_x s_{\\theta}(x)) −Epdata(x)sdata(x)Tsθ(x)=+Epdata(x)tr(∇xsθ(x))
这个等价变换是整个分数匹配方法得以成立的核心。它成功地将一个依赖于未知真实分数 s_data(x) 的项,转换成了一个只依赖于我们可计算的模型分数 s_θ(x) 及其散度 的项。这样,我们就可以通过优化模型参数 θ 来使 s_θ(x) 逼近 s_data(x) 了。
2、Trace(迹)之所以与散度(divergence, div)有关系
tr(∇ₓ s_θ(x)) 的物理/数学意义是:
它计算了分数函数 s_θ(x) 的散度(Divergence)。
- 在向量分析中,一个向量场的散度衡量的是该向量场在某一点的"发散"或"汇聚"程度。
- 在这里,
s_θ(x)是概率密度p(x)的梯度(在对数尺度下),因此tr(∇ₓ s_θ(x))可以被理解为概率密度函数在空间中的某种"体积变化率"。它衡量了当我们沿着概率密度梯度移动时,我们是在"进入"一个更密集的区域还是"离开"它。
Trace(迹)之所以与散度(divergence, div)有关系,是因为散度的数学定义,本质上就是一个雅可比矩阵(Jacobian Matrix)的迹。
2.1. 什么是迹(Trace)?
tr() 是 Trace(迹) 的缩写,它是线性代数中一个非常有用的运算。
迹(Trace) 是一个方阵(行数和列数相同的矩阵)所特有的运算。它的定义非常简单:
一个方阵的迹,就是其主对角线(从左上角到右下角)上所有元素的和。
举个例子:
假设有以下一个 3 × 3 3 \times 3 3×3 的方阵 A:
A = a 11 a 12 a 13 a 21 a 22 a 23 a 31 a 32 a 33 A = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix} A= a11a21a31a12a22a32a13a23a33
那么,A 的迹 tr(A) 就是:
tr ( A ) = a 11 + a 22 + a 33 \text{tr}(A) = a_{11} + a_{22} + a_{33} tr(A)=a11+a22+a33
简单来说,就是把矩阵最中间那条对角线上的数字加起来。
2.2. 从梯度到雅可比矩阵
首先,我们需要理解算子 ∇ₓ 作用在不同对象上会产生什么。
-
梯度 (Gradient, ∇) :通常作用于一个标量函数 (Scalar Field),比如 f(x)。它的结果是一个向量,指向函数值增长最快的方向。
- 例如:f(x, y) = x² + y²,则 ∇f = 2x, 2yᵀ。
-
雅可比矩阵 (Jacobian Matrix, J) :作用于一个向量函数 (Vector Field),比如 F (x) = F₁(x), F₂(x), ..., Fₙ(x)ᵀ。它的结果是一个矩阵。
- 这个矩阵的第 i 行第 j 列的元素,是第 i 个输出分量对第 j 个输入的偏导数:
J_ij = ∂Fᵢ / ∂xⱼ
- 这个矩阵的第 i 行第 j 列的元素,是第 i 个输出分量对第 j 个输入的偏导数:
现在,让我们看看 ∇ₓ s_θ(x) 是什么意思。这里的 s_θ(x) 是一个向量 (分数向量)。所以,∇ₓ 作用于它,得到的就是一个雅可比矩阵:
∇ x s θ ( x ) = ∂ s 1 ∂ x 1 ∂ s 1 ∂ x 2 ... ∂ s 1 ∂ x n ∂ s 2 ∂ x 1 ∂ s 2 ∂ x 2 ... ∂ s 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ s n ∂ x 1 ∂ s n ∂ x 2 ... ∂ s n ∂ x n \nabla_x s_{\theta}(x) = \begin{bmatrix} \frac{\partial s_1}{\partial x_1} & \frac{\partial s_1}{\partial x_2} & \dots & \frac{\partial s_1}{\partial x_n} \\ \frac{\partial s_2}{\partial x_1} & \frac{\partial s_2}{\partial x_2} & \dots & \frac{\partial s_2}{\partial x_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial s_n}{\partial x_1} & \frac{\partial s_n}{\partial x_2} & \dots & \frac{\partial s_n}{\partial x_n} \end{bmatrix} ∇xsθ(x)= ∂x1∂s1∂x1∂s2⋮∂x1∂sn∂x2∂s1∂x2∂s2⋮∂x2∂sn......⋱...∂xn∂s1∂xn∂s2⋮∂xn∂sn
2.3 散度 (Divergence) 的定义
在向量微积分中,一个向量场 F (x) 的散度 (divergence, div) 是一个标量,它衡量了向量场在某一点的"源"或"汇"的强度。它的标准定义是:
div ( F ) = ∇ ⋅ F = ∑ i = 1 n ∂ F i ∂ x i = ∂ F 1 ∂ x 1 + ∂ F 2 ∂ x 2 + ⋯ + ∂ F n ∂ x n \text{div}(\mathbf{F}) = \nabla \cdot \mathbf{F} = \sum_{i=1}^{n} \frac{\partial F_i}{\partial x_i} = \frac{\partial F_1}{\partial x_1} + \frac{\partial F_2}{\partial x_2} + \dots + \frac{\partial F_n}{\partial x_n} div(F)=∇⋅F=i=1∑n∂xi∂Fi=∂x1∂F1+∂x2∂F2+⋯+∂xn∂Fn
简单来说,散度就是把向量场的每一个分量,分别对对应的坐标求偏导,然后把它们全部加起来。
2.4 Trace (迹) 的定义
对于一个方阵,它的迹 (Trace, tr) 是其主对角线上所有元素的总和。
2.5 关键的连接:Trace = 散度
现在,我们将雅可比矩阵的迹和我们刚刚给出的散度定义放在一起比较。
雅可比矩阵的迹 (Trace of the Jacobian):
我们来看前面 ∇ₓ s_θ(x) 那个矩阵的主对角线元素:
tr ( ∇ x s θ ( x ) ) = ∂ s 1 ∂ x 1 + ∂ s 2 ∂ x 2 + ⋯ + ∂ s n ∂ x n \text{tr}(\nabla_x s_{\theta}(x)) = \frac{\partial s_1}{\partial x_1} + \frac{\partial s_2}{\partial x_2} + \dots + \frac{\partial s_n}{\partial x_n} tr(∇xsθ(x))=∂x1∂s1+∂x2∂s2+⋯+∂xn∂sn
向量场 s_θ(x) 的散度 (Divergence of s_θ):
根据散度的定义:
div ( s θ ) = ∇ ⋅ s θ = ∂ s 1 ∂ x 1 + ∂ s 2 ∂ x 2 + ⋯ + ∂ s n ∂ x n \text{div}(s_{\theta}) = \nabla \cdot s_{\theta} = \frac{\partial s_1}{\partial x_1} + \frac{\partial s_2}{\partial x_2} + \dots + \frac{\partial s_n}{\partial x_n} div(sθ)=∇⋅sθ=∂x1∂s1+∂x2∂s2+⋯+∂xn∂sn
比较这两个结果,你会发现它们是完全一样的!
因此,我们可以得出一个非常简洁且重要的结论:
一个向量场的散度,等于其雅可比矩阵的迹。
div ( F ) = ∇ ⋅ F = tr ( ∇ F ) \text{div}(\mathbf{F}) = \nabla \cdot \mathbf{F} = \text{tr}(\nabla \mathbf{F}) div(F)=∇⋅F=tr(∇F)
之前的公式 J(θ) = E[ tr(∇ₓ s_θ(x)) + ... ] 中,项 tr(∇ₓ s_θ(x)) 的物理意义就是模型分数 s_θ(x) 的散度。它衡量了在数据空间中,由模型梯度场引起的"体积"或"概率质量"的发散情况。