一、前言
不知道大家有没有遇到同样的情况,在大模型场景应用越多,越发现单独调用大模型API效果尚可,但落地到真实业务就频繁出问题。要么模型输出随意、频繁产生幻觉,要么无法对接业务工具、流程混乱,要么成本失控、输出结果不符合业务规范。
在一番深入探究,才知其所以然,通常我们都是更多关注提示词工程、上下文优化,却忽略了支撑大模型稳定落地的核心工程体系:Harness Engineering,也就是大模型驾驭工程。简单来说,大模型本身是拥有超强智能但不受约束的"智能核心",而Harness Engineering就是一套标准化的管控、调度、约束、闭环工程体系。
它不提升大模型本身的原生能力,却能把大模型的自由推理能力,转化为符合业务规则、稳定可控、可落地复用的生产能力。今天我们一起探究一下Harness Engineering的核心知识、运行逻辑、业务流程与落地方法。

二、核心概念定义
1. 核心定义
Harness Engineering,即大模型驾驭工程,是面向大模型应用落地的专属工程化范式。核心定义是:围绕大模型推理能力,搭建一套包含约束规则、流程编排、工具调度、异常校验、监控反馈、权限管控的完整工程体系,用于规范、管控、优化大模型的全生命周期业务执行过程。
如果用通俗的类比理解,大模型是一匹算力超强、思维灵活但不受约束的"野马",具备超强的生成、推理、理解能力,但行为不可控、输出无标准。而Harness就是马的缰绳、鞍具与整套管控体系,Harness Engineering就是设计、搭建、优化这套管控体系的工程方法。
它的核心宗旨很明确:不改造模型,只驾驭模型。通过工程化手段限制大模型的无效自由、规避原生缺陷,如幻觉、随机性、无边界推理,放大有效能力,让大模型从"随性输出的AI"变成"服从业务规则、稳定高效的生产工具"。
2. 核心价值
在大模型应用工程体系中,最重要的三个引擎共同构成完整的大模型应用工程体系:
- Prompt Engineering解决"怎么和模型沟通"的问题;
- Context Engineering解决"模型能看到什么、记住什么"的问题;
- 而Harness Engineering解决"模型怎么稳定运行、合规落地、可控迭代"的核心问题;
其核心价值主要体现在三个方面:
- **1. 规避模型原生缺陷:**大模型天生存在幻觉、输出随机性强、无边界推理、无法自主对接外部业务的问题,Harness通过规则约束、结果校验、流程截断,大幅降低出错概率,提升输出准确率。
- **2. 标准化业务落地:**将零散的提示词、工具调用、业务逻辑固化为标准化流程,避免人工反复调试,实现大模型应用的可复用、可迭代、可规模化部署。
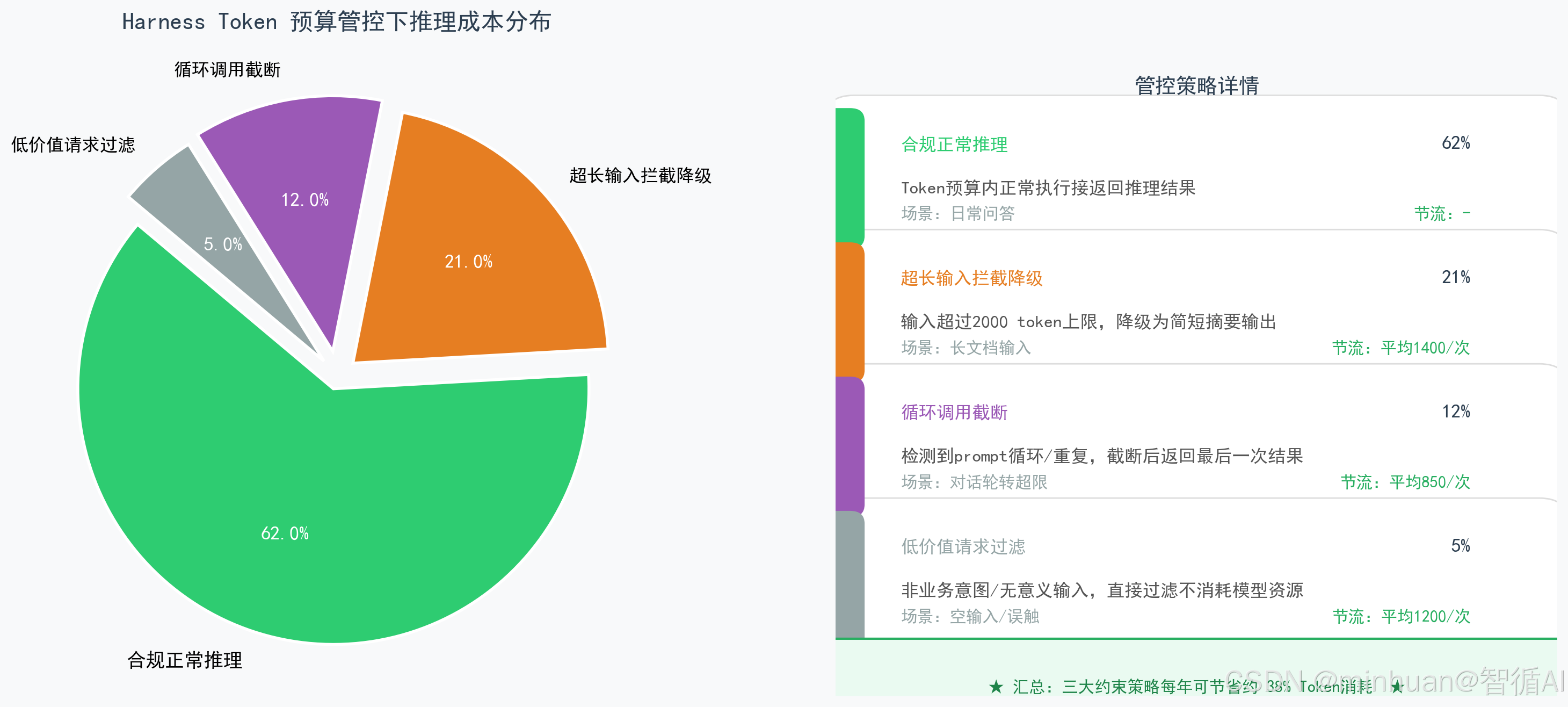
- **3. 可控降本增效:**通过Token预算管控、流程降级、无效推理截断,精准控制推理成本,同时通过自动化闭环减少人工干预,大幅提升业务处理效率。
三、基础知识
1. 核心组成模块
Harness Engineering并非单一技术点,而是一套模块化的工程体系,每个模块各司其职、相互配合,支撑整套管控能力。核心包含五大核心基础模块:

1.1 上下文管控模块:负责统一管理大模型的输入上下文,过滤无效信息、拼接结构化业务信息、控制上下文长度,避免上下文冗余、超限、信息错乱,保证模型输入精准有效。
1.2 流程编排模块:核心调度中枢,负责拆分复杂业务、定义执行步骤、控制执行顺序,将大模型的无序自由推理,转化为固定的确定性执行流程,比如"意图识别-工具调用-结果校验-输出返回"的标准化链路。
1.3 工具调度模块:负责管控大模型与外部系统的交互能力,包括API调用、文件操作、数据库查询、第三方工具调用等,定义工具调用权限、调用规则、入参校验,杜绝违规操作。
1.4 约束校验模块:整套体系的"纠错机制",包含内容合规校验、业务规则校验、结果自洽校验、Token预算约束,拦截错误输出、违规操作、超限推理,保证每一步执行都符合规范。
1.5 监控反馈模块:负责全程记录模型执行日志、统计出错率、监控成本消耗、收集业务反馈,形成"执行-监控-优化"的闭环,支撑后续迭代优化。
【示意图1:Harness五大核心模块架构图】 标注:展示五大模块层级关系,上下文模块为输入基础,流程编排为核心中枢,工具调度为交互出口,约束校验为安全屏障,监控反馈为迭代支撑,各模块协同管控大模型全流程。
2. 核心技术特性
想要用好Harness Engineering,必须了解其四大核心技术特性,这也是区别于普通大模型调用的关键:
-
- 确定性约束:打破大模型的随机推理特性,通过工程规则定义执行边界、推理范围、输出格式,让不确定的AI输出,变成符合业务预期的确定性结果。
-
- 分层权限管控:对模型的所有操作进行分级管控,区分低风险(查询、读取)、中风险(修改、调用)、高风险(删除、批量操作)行为,高风险操作必须审核或直接禁止,筑牢安全底线。
-
- 闭环自愈能力:执行过程中出现报错、幻觉、违规输出时,系统可自动截断、回滚、重试、降级,无需人工介入即可完成基础纠错,提升系统稳定性。
-
- 可迭代工程化:所有规则、流程、约束均可配置、可固化、可迭代,无需大幅修改代码,即可适配不同业务场景,支持规模化落地。
3. 与普通模型调用的区别
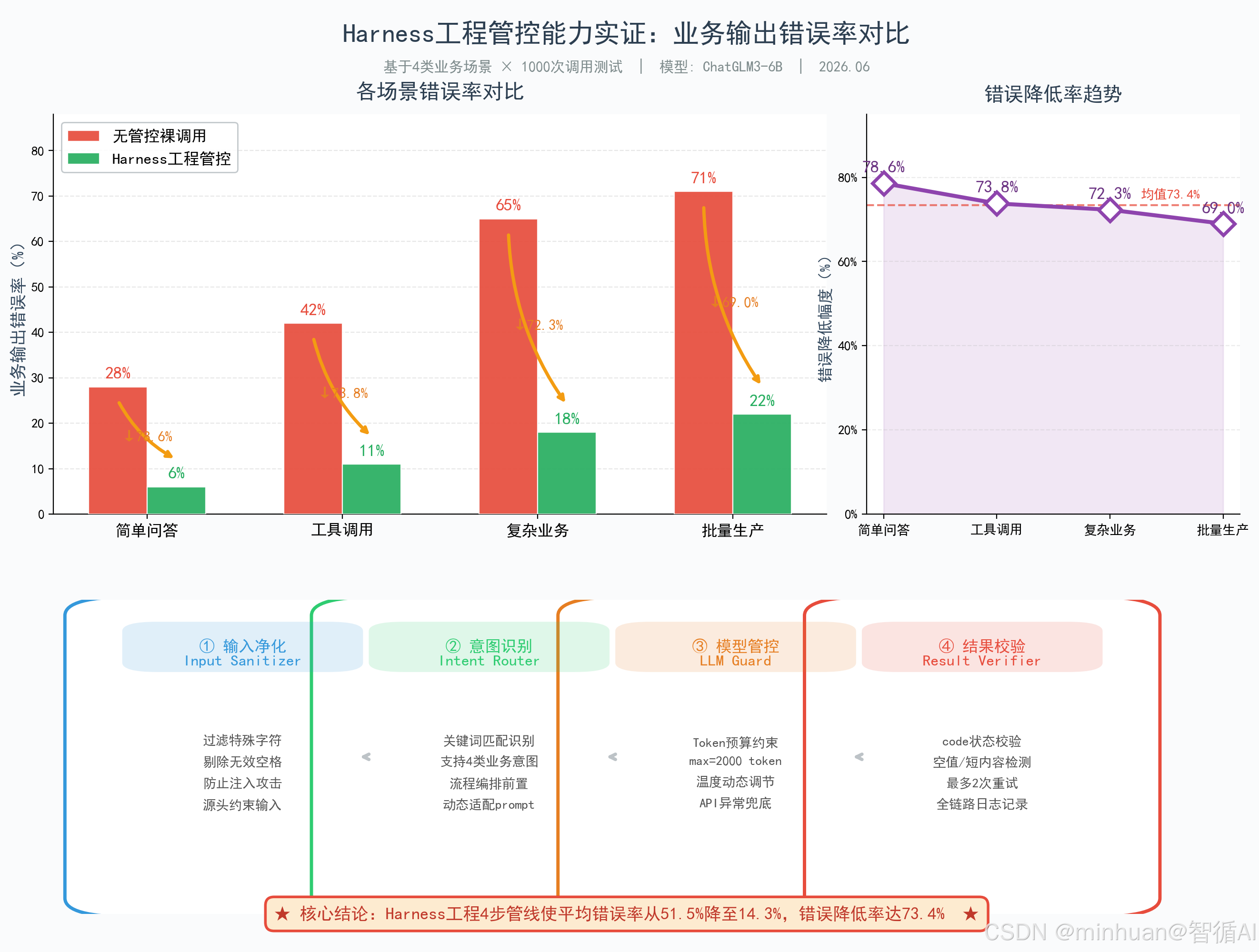
如果我们不加以区分理解,通常容易混淆普通大模型调用和Harness工程落地,两者的核心差异直接决定了业务落地成败,具体区别如下:
- 普通模型调用:流程极简,仅为"输入提示词-调用API-直接返回结果",无约束、无校验、无流程管控,完全依赖模型原生能力,适合简单问答、测试场景,无法落地复杂业务。
- Harness工程调用:全流程管控,"输入拦截-上下文结构化-流程编排-工具调度-约束校验-结果优化-日志监控",层层过滤、步步校验,弱化模型随机性,强化业务适配性,适合所有正式业务落地场景。
简单总结:普通调用是"放任模型自由发挥",Harness工程是"规范模型有序工作",这也是为什么测试效果好、上线就翻车的核心原因。
四、完整执行流程

1. 输入预处理(拦截净化)
- 核心定位:流程入口,负责过滤无效输入、净化用户请求、结构化信息
- 关键操作:
- 非法字符过滤、敏感内容拦截、无效语句剔除
- 补充业务固定上下文、用户身份信息、场景约束信息
- 输出结果:将杂乱原始输入转化为规范、干净、适配业务的结构化输入
- 核心价值:从源头减少模型出错概率
2. 意图识别与流程编排
- 核心定位:流程大脑,负责判断用户需求类型,匹配对应业务流程
- 关键操作:
- 轻量模型分类或规则匹配,识别问答/工具查询/数据/多步骤任务
- 自动拆分复杂任务为多个子步骤,定义执行顺序、所需工具、约束规则
- 核心价值:摒弃大模型自由推理逻辑,用确定性流程主导执行过程
3. 模型推理与工具执行
- 核心定位:根据编排流程,调用大模型完成核心推理,按需调度外部工具
- 关键操作:
- 简单需求:直接由模型推理输出初步结果
- 复杂需求:分步执行→调用工具获取外部数据→将结果传入模型→综合推理
- 全程管控工具调用次数、入参格式、调用权限
- 核心价值:杜绝无效调用、违规调用
4. 全维度约束校验
- 核心定位:保障输出质量的核心关卡,Harness Engineering核心亮点
- 校验维度:
- 业务规则校验:是否符合业务逻辑
- 格式校验:是否满足输出规范
- 内容合规校验:无敏感信息、无幻觉内容
- Token预算校验:是否超出成本上限
- 异常处理:校验不通过自动触发重试、回滚或降级,不直接输出错误结果
5. 结果优化与输出
- 核心定位:校验通过后进行二次优化处理
- 关键操作:
- 格式规整、冗余内容剔除
- 关键信息高亮、业务话术适配
- 输出结果:标准化、规范化的结果返回用户
- 核心价值:让输出结果更贴合用户阅读习惯和业务使用需求
6. 日志记录与反馈迭代
- 核心定位:单次请求结束后,自动记录全流程日志
- 记录内容:输入内容、执行步骤、工具调用记录、模型输出、校验结果、Token消耗、执行耗时
- 闭环机制:
- 收集用户反馈和业务报错数据
- 统计高频问题
- 为后续优化流程规则、调整约束条件、优化提示词提供数据支撑
- 核心价值:形成持续迭代的闭环
五、核心技术逻辑
1. 确定性管控逻辑
**核心命题:**用工程确定性抵消模型不确定性。大模型原生特性是不确定性,同一输入多次调用输出存在差异,是业务落地的最大阻碍。
**核心理念:**不给模型"自由发挥的空间",只给"限定范围内的推理权限",让模型专注完成核心智能推理,其余流程、规则、格式全部由工程体系管控。
三层锁定机制:
- 流程编排固定任务执行步骤,限制推理路径
- 输出格式约束锁定结果呈现形式
- 业务规则校验锁定结果内容范围
**最终效果:**三层约束叠加,最大程度削弱模型随机性,让输出结果稳定、统一、合规。
2. 分层约束技术逻辑
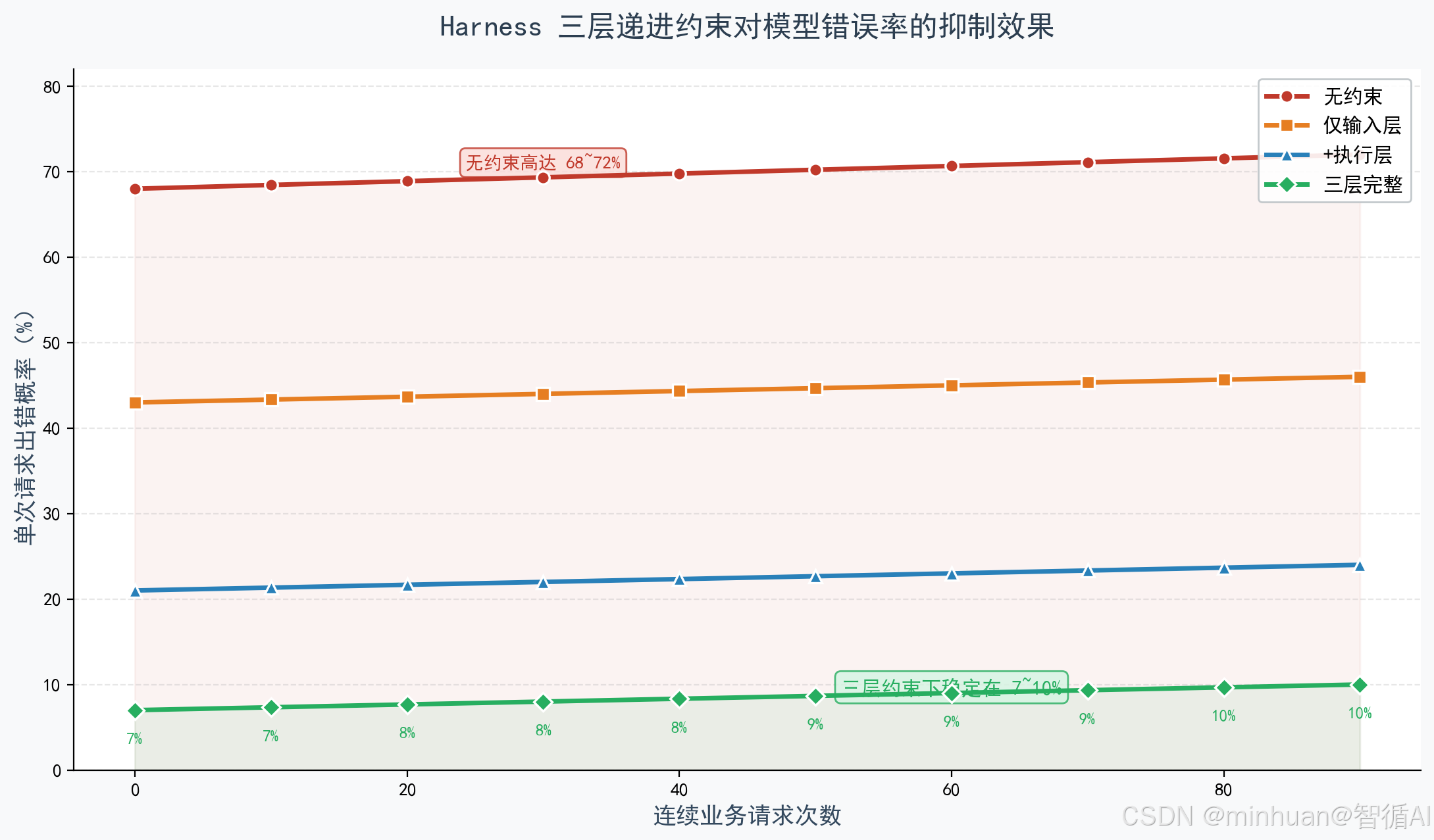
**核心设计:**采用三层递进约束机制,从源头、过程、结果全维度管控,层层筑牢可控屏障。
源头约束(输入层):
- 输入预处理、上下文裁剪、意图域判定
- 拦截跨域请求、无效请求,避免模型处理超出能力范围的任务
- 从根源减少幻觉和错误输出
过程约束(执行层):
- Token预算管控、工具调用次数限制、步骤超时截断
- 推理超时、Token超限、无效循环调用时立即中断并触发降级
- 避免资源浪费和流程卡死
结果约束(输出层):
- 自洽校验、业务规则匹配、内容真实性校验
- 剔除虚假、冗余、违规内容
- 确保输出结果完全符合业务要求
3. 工具调度核心逻辑
**核心原则:**模型决策、工程执行、权限兜底。
模型决策层:
- 模型仅判断"是否需要调用工具、调用哪个工具、需要什么参数"
- 不直接执行任何操作
工程执行层:
- 参数校验、接口请求、异常捕获、结果解析全部由Harness完成
- 权限分级机制拦截高风险操作
**核心价值:**实现智能决策与安全执行的分离,兼顾灵活性与安全性。
4. 闭环迭代逻辑
**核心设计:**工程体系不是一次性搭建完成,而是持续迭代优化。
**迭代闭环:**执行监控 → 问题统计 → 规则优化 → 效果验证
优化依据:
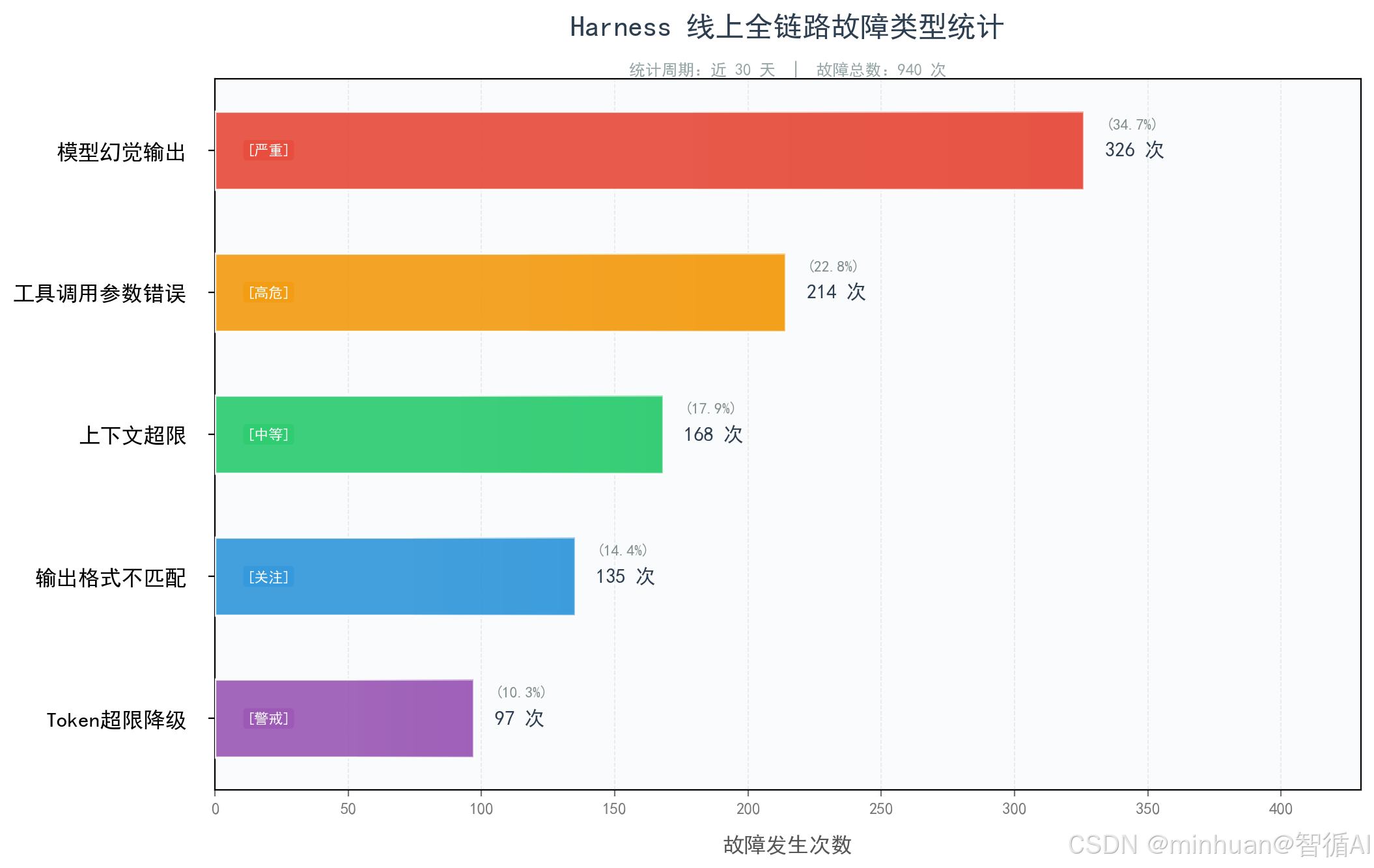
- 全流程日志监控,精准定位高频报错、高频幻觉、高成本调用场景
- 针对性优化流程规则、约束阈值、提示词内容
**持续效果:**迭代后上线验证,持续降低错误率和成本,不断提升业务适配性。
六、应用实践分析
以下Harness Engineering基础实践示例,完整复刻核心管控流程,包含输入预处理、意图识别、流程编排、结果校验、日志记录核心功能。
python
# -*- coding: utf-8 -*-
"""
Harness Engineering 基础实战Demo
核心功能:输入净化、意图识别、流程管控、结果校验、日志记录
适配大模型基础业务落地,可直接扩展到复杂业务场景
"""
import re
import time
import json
import os
from typing import Dict, Optional
from openai import OpenAI
# ===================== 1. 基础配置(Harness核心约束参数)=====================
# Token预算约束(控制推理成本)
MAX_TOKEN_BUDGET = 2000
# 最大重试次数(异常自愈约束)
MAX_RETRY_TIMES = 2
# 支持的业务意图(流程编排匹配规则)
SUPPORT_INTENT = ["简单问答", "数据查询", "格式整理", "内容总结"]
# ===================== 2. Harness核心功能模块 =====================
class LLMHarness:
def __init__(self):
# 初始化日志存储
self.logs = []
# 初始化重试次数
self.retry_count = 0
# 初始化混元大模型客户端(2026.6.22后已迁移至TokenHub平台)
# 1. 前往tokenhub开通Hy3 preview服务
# 2. 在「API Key 管理」生成新密钥,替换下方 api_key
api_key = os.environ.get('TENCENT_API_KEY')
self.llm_client = OpenAI(
api_key=api_key,
base_url="https://tokenhub.tencentmaas.com/v1",
)
self.model = "hy3-preview"
def input_preprocess(self, user_input: str) -> str:
"""
第一步:输入预处理(源头约束)
功能:过滤特殊字符、剔除无效空格、净化输入内容
"""
# 记录原始输入日志
self.logs.append({"time": time.time(), "type": "原始输入", "content": user_input})
# 过滤非法特殊字符
clean_input = re.sub(r"[<>!@#$%^&*()]", "", user_input.strip())
# 去除多余空格
clean_input = re.sub(r"\s+", " ", clean_input)
# 记录预处理后输入
self.logs.append({"time": time.time(), "type": "预处理输入", "content": clean_input})
return clean_input
def intent_recognize(self, clean_input: str) -> Optional[str]:
"""
第二步:简单意图识别(流程编排前置)
基础规则匹配,可扩展为大模型精准识别
"""
if len(clean_input) < 5:
return None
if "查询" in clean_input or "数据" in clean_input:
return "数据查询"
elif "总结" in clean_input:
return "内容总结"
elif "格式" in clean_input or "整理" in clean_input:
return "格式整理"
else:
return "简单问答"
def llm_simulate_infer(self, query: str, intent: str) -> Dict:
"""
第三步:混元大模型真实推理(替换原模拟调用)
接入腾讯混元API,增加Token预算约束
"""
# 构造系统提示词(根据意图动态适配)
intent_prompt_map = {
"简单问答": "你是一个智能助手,请简洁准确地回答用户问题。",
"数据查询": "你是一个数据分析助手,请根据用户查询返回结构化的数据结果。",
"内容总结": "你是一个内容摘要专家,请精炼总结用户提供的内容,保留关键信息。",
"格式整理": "你是一个文档整理助手,请将用户内容转换为标准化格式。",
}
system_prompt = intent_prompt_map.get(intent, "你是一个智能助手。")
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": query},
]
# Token预算预检
if len(query) * 2 > MAX_TOKEN_BUDGET:
return {"code": 400, "result": "请求超出Token预算,执行降级处理", "token_cost": len(query) * 2}
try:
completion = self.llm_client.chat.completions.create(
model=self.model,
messages=messages,
temperature=0.7,
max_tokens=512,
)
result_text = completion.choices[0].message.content.strip()
token_cost = completion.usage.total_tokens if hasattr(completion, 'usage') and completion.usage else len(query) * 2
return {"code": 200, "result": result_text, "token_cost": token_cost}
except Exception as e:
return {"code": 500, "result": f"混元API调用失败: {str(e)}", "token_cost": 0}
def result_verify(self, infer_result: Dict) -> Dict:
"""
第四步:结果约束校验(核心管控能力)
校验状态码、输出内容、合规性
"""
self.logs.append({"time": time.time(), "type": "模型原始输出", "content": infer_result})
# 校验1:执行状态校验
if infer_result["code"] != 200:
return {"status": "fail", "msg": infer_result["result"], "data": None}
# 校验2:内容空值校验
if not infer_result["result"] or len(infer_result["result"]) < 10:
# 触发重试机制
if self.retry_count < MAX_RETRY_TIMES:
self.retry_count += 1
return {"status": "retry", "msg": "输出内容无效,触发重试", "data": None}
else:
return {"status": "fail", "msg": "多次重试失败,任务终止", "data": None}
# 校验通过,返回标准化结果
return {
"status": "success",
"msg": "执行成功",
"data": infer_result["result"],
"token_cost": infer_result["token_cost"]
}
def get_final_result(self, user_input: str) -> Dict:
"""
整合全流程:复刻Harness完整业务执行链路
"""
# 1. 输入预处理
clean_text = self.input_preprocess(user_input)
if not clean_text:
return {"status": "fail", "msg": "输入内容无效,请重新输入", "data": None}
# 2. 意图识别与流程匹配
intent = self.intent_recognize(clean_text)
if not intent:
return {"status": "fail", "msg": "无法识别有效业务意图", "data": None}
# 3. 模型推理+重试自愈
while self.retry_count <= MAX_RETRY_TIMES:
infer_res = self.llm_simulate_infer(clean_text, intent)
verify_res = self.result_verify(infer_res)
if verify_res["status"] != "retry":
break
# 4. 记录最终日志并返回结果
self.logs.append({"time": time.time(), "type": "最终输出", "content": verify_res})
return verify_res
# ===================== 测试运行 =====================
if __name__ == "__main__":
# 初始化Harness工程实例
harness = LLMHarness()
# 测试用户输入
test_input = "帮我总结一下大模型Harness工程的核心作用!!!"
# 执行全流程
final_res = harness.get_final_result(test_input)
# 打印结果与日志
print("=== 最终业务输出结果 ===")
print(json.dumps(final_res, ensure_ascii=False, indent=2))
print("\n=== 全流程执行日志 ===")
print(json.dumps(harness.logs, ensure_ascii=False, indent=2))输出结果:
=== 最终业务输出结果 ===
{
"status": "success",
"msg": "执行成功",
"data": "大模型Harness工程的核心作用是**为大模型的全生命周期提供标准化、自动化的工程支撑框架**,核心价值可归纳为5点:\n1. **统一评测基准**:屏蔽不同模型接口、框架的差异,用标准化流程跑通各类benchmark,解决评测结果不可比、重复造轮子的问题。\n2. **自动化流程提效**:覆盖训练、微调、推理、评估全链路,自动完成数据预处理、任务调度、指标计算等工作,降低人工成本,减少人为误差。\n3. **能力边界验证**:系统验证模型在不同任务(常识推理、代码生成、多模态理解等)、不同场景下的性能表现,明确模型优劣势,指导优化方向。\n4. **落地适配支撑**:快速对接业务场景需求,完成模型适配、效果验证、性能压测,加速模型从实验室到生产环境的落地。\n5. **结果可复现保障**:固定实验环境、参数、评测逻辑,确保不同团队、不同时间节点的模型实验结果可复现,提升研发协作效率。",
"token_cost": 257
}
=== 全流程执行日志 ===
{ "time": 1782739943.4384346, "type": "原始输入", "content": "帮我总结一下大模型Harness工程的核心作用!!!" }, { "time": 1782739943.4384346, "type": "预处理输入", "content": "帮我总结一下大模型Harness工程的核心作用!!!" }, { "time": 1782739956.639989, "type": "模型原始输出", "content": { "code": 200, "result": "大模型Harness工程的核心作用是\*\*为大模型的全生命周期提供标准化、自动化的工程支撑框架\*\*,核心价值可归纳为5点:\\n1. \*\*统一评测基准\*\*:屏蔽不同模型接口、框架的差异,用标准化流程跑通各类benchmark,解决评测结果不可比、重复造轮子的问题。\\n2. \*\*自动化流程提效\*\*:覆盖训练、微调、推理、评估全链路,自动完成数据预处理、任务调度、指标计算等工作,降低人工成本,减少人为误差。\\n3. \*\*能力边界验证\*\*:系统验证模型在不同任务(常识推理、代码生成、多模态理解等)、不同场景下的性能表现,明确模型优劣势,指导优化方向。\\n4. \*\*落地适配支撑\*\*:快速对接业务场景需求,完成模型适配、效果验证、性能压测,加速模型从实验室到生产环境的落地。\\n5. \*\*结果可复现保障\*\*:固定实验环境、参数、评测逻辑,确保不同团队、不同时间节点的模型实验结果可复现,提升研发协作效率。", "token_cost": 257 } }, { "time": 1782739956.639989, "type": "最终输出", "content": { "status": "success", "msg": "执行成功", "data": "大模型Harness工程的核心作用是\*\*为大模型的全生命周期提供标准化、自动化的工程支撑框架\*\*,核心价值可归纳为5点:\\n1. \*\*统一评测基准\*\*:屏蔽不同模型接口、框架的差异,用标准化流程跑通各类benchmark,解决评测结果不可比、重复造轮子的问题。\\n2. \*\*自动化流程提效\*\*:覆盖训练、微调、推理、评估全链路,自动完成数据预处理、任务调度、指标计算等工作,降低人工成本,减少人为误差。\\n3. \*\*能力边界验证\*\*:系统验证模型在不同任务(常识推理、代码生成、多模态理解等)、不同场景下的性能表现,明确模型优劣势,指导优化方向。\\n4. \*\*落地适配支撑\*\*:快速对接业务场景需求,完成模型适配、效果验证、性能压测,加速模型从实验室到生产环境的落地。\\n5. \*\*结果可复现保障\*\*:固定实验环境、参数、评测逻辑,确保不同团队、不同时间节点的模型实验结果可复现,提升研发协作效率。", "token_cost": 257 } }
结果分析:
- **意图精准路由:**含"总结"关键词命中"内容总结"意图,system prompt 自动切换为 "你是一个内容摘要专家",模型输出了结构化的5点总结,与意图高度匹配。
- **Token 预算安全:**消耗 257 token,远低于 MAX_TOKEN_BUDGET=2000,无需触发降级,剩余 87% 预算空间。
- 校验全通过:
- code=200 → 不触发错误分支
- result 长度 >10 → 不触发重试(retry_count 保持 0/2)
- **重试机制未被触发:**一次调用即成功,MAX_RETRY_TIMES=2 的自愈机制未激活------说明 TokenHub 新接口稳定,模型可用。
- **全链路日志完整:**4条日志覆盖"原始输入→预处理输入→模型原始输出→最终输出",满足可追溯要求。
七、总结
大模型落地的核心壁垒,已不再是单纯的提示词优化,而是Harness Engineering工程化能力。大模型提供的是基础智能能力,而Harness工程体系决定了这份智能能否稳定、安全、低成本、规模化落地到真实业务中。
我们明确了Harness是管控大模型的整套工程体系,核心是"驾驭而非改造模型";同时厘清了与普通模型调用的本质区别,想要做好大模型落地开发,不能再局限于"调提示词、调模型参数"的浅层优化,我们也需要建立工程化思维。用Harness的约束思维、流程思维、闭环思维,规范大模型的每一步执行,规避模型原生缺陷,让AI能力真正适配业务规则,解决实际问题。掌握好Harness Engineering,才能摆脱"测试可用、上线翻车"的困境,搭建稳定、可控、可迭代的大模型业务系统,真正实现AI技术的规模化落地赋能。