BERT vs GPT 区别(2026 详解):从 Encoder 读懂到 Decoder 续写,一次讲透两条大模型路线

TL;DR
- 场景:很多同学在做 NLP / 大模型选型时,最常踩的两个坑是「BERT 已经过时了」和「GPT 能干所有事」,结果在分类/搜索/Embedding 场景硬上大模型,又贵又慢。
- 结论:BERT 走 Transformer Encoder 路线,做双向理解的判别式模型;GPT 走 Transformer Decoder 路线,做从左到右自回归生成。两者不是同一代替代关系,而是同一代分工关系。
- 产出:一张 BERT/GPT 选型对照表、一套组合架构示例(BERT 做意图识别/Reranker,GPT 做生成/Agent),以及常见误解的错误速查卡。
TL;DR
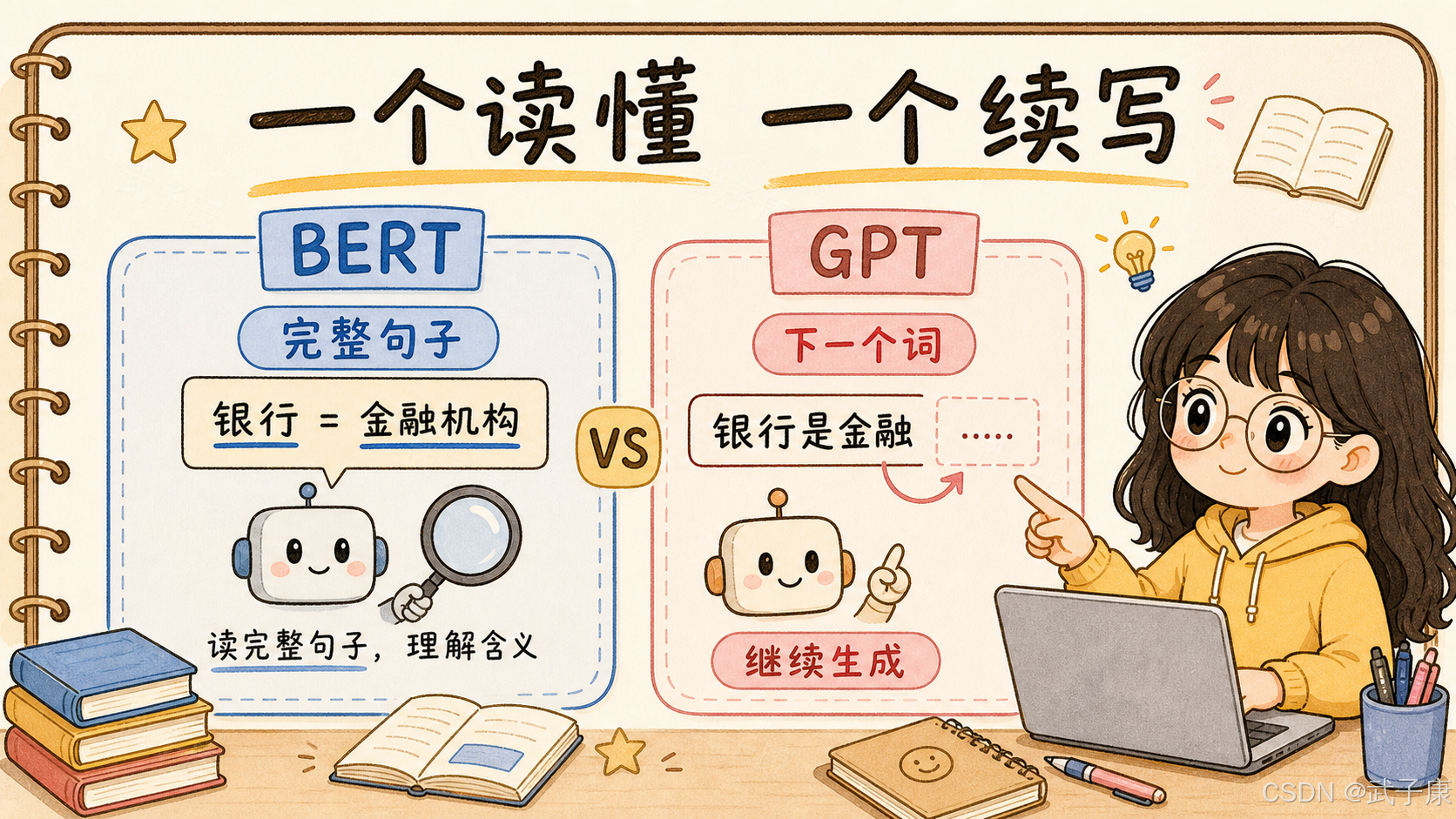
如果只用一句话概括 BERT 和 GPT 的区别,可以这样说:
BERT 更像阅读理解模型,擅长读懂一段已有文本;GPT 更像续写生成模型,擅长根据上文继续写下去。
这句话听起来简单,但背后对应两条不同的模型路线:
text
BERT:看完整上下文,做理解、判断、匹配、抽取
GPT:从左到右预测下一个 token,做生成、对话、写作、推理所以 BERT 和 GPT 的差异不是"谁更高级",而是它们一开始解决的问题就不同。
BERT 代表了经典的语言理解路线。
GPT 代表了后来成为主流的生成式语言模型路线。
在真实工程里,它们不是简单替代关系,而是经常分工协作。
1. 先从一个直觉例子开始
看这句话:
text
我今天去银行办理了贷款。如果模型要判断这里的"银行"是什么意思,它需要看到后面的"贷款",才能知道这是金融机构,不是河岸。
这类任务强调的是:
text
读完整句话
理解词和词之间的关系
做分类、判断、匹配、抽取这就是 BERT 更擅长的方向。
再看另一个任务:
text
我今天去银行办理了模型需要接着写:
text
贷款。这类任务强调的是:
text
只能根据前面已经出现的内容
预测后面最可能出现什么
一步一步生成下文这就是 GPT 更擅长的方向。
2. BERT 是什么?
BERT 的全称是 Bidirectional Encoder Representations from Transformers。
拆开看有三个关键词:
text
Bidirectional:双向
Encoder:编码器
Representations:语义表示BERT 主要使用 Transformer Encoder 结构。
它的核心能力是把一段文本编码成高质量语义表示。
因为 BERT 是双向的,所以它在理解一个词时,可以同时看左边和右边的上下文。
例如:
text
我把钱存进了银行。BERT 可以看到"钱""存进"等上下文,从而更容易判断"银行"是金融机构。
再比如:
text
河边的银行长满了草。如果语境足够明确,BERT 也可以根据完整上下文判断这里更接近"河岸"含义。
所以 BERT 很适合做理解类任务:
text
文本分类
情感分析
语义匹配
搜索排序
实体识别
阅读理解
句子相似度
信息抽取它的典型输出不是长篇自然语言,而是标签、分数、向量、片段或分类结果。
3. GPT 是什么?
GPT 的全称是 Generative Pre-trained Transformer。
拆开看也有三个关键词:
text
Generative:生成式
Pre-trained:预训练
Transformer:Transformer 架构GPT 主要走 Transformer Decoder 路线,并采用从左到右的自回归生成方式。
所谓自回归,就是每一步根据前面已经出现的内容预测下一个 token。
比如:
text
今天天气很好,我想去模型可能预测:
text
公园下一步再根据:
text
今天天气很好,我想去公园继续预测:
text
散步最终生成:
text
今天天气很好,我想去公园散步。GPT 的核心能力是根据已有上下文持续生成后续内容。
所以它更适合:
text
对话
写作
代码生成
摘要
翻译
问答
Agent 推理
工具调用
长文本生成GPT 的输出通常是连续自然语言、代码、结构化文本或工具调用参数。
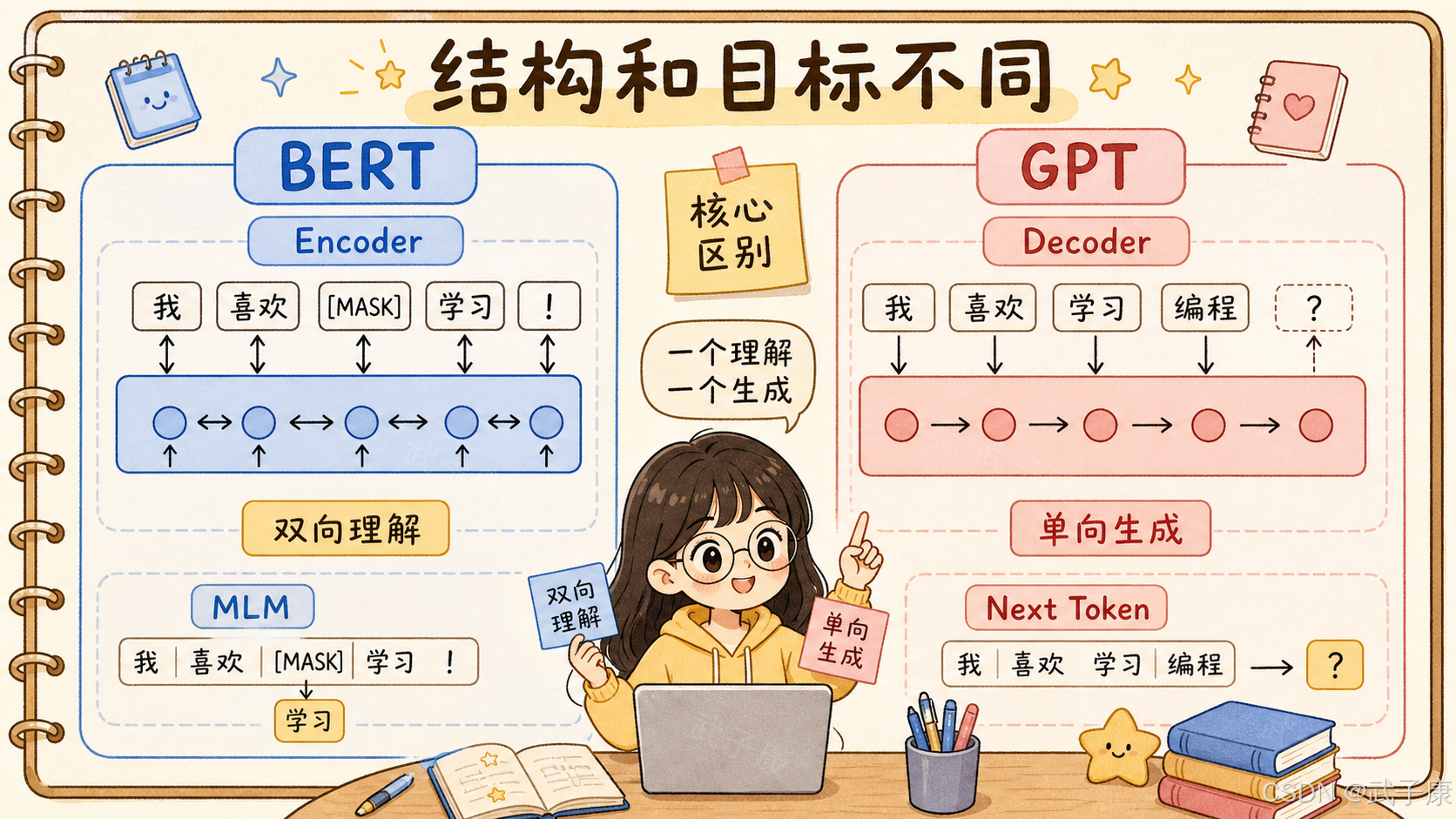
4. 最核心差异:双向理解 vs 单向生成
BERT 和 GPT 最关键的区别,在于它们"看文本"的方式不同。
BERT 是双向理解。
它在理解一句话时,可以同时看到左边和右边上下文。
例如:
text
我今天去银行办理了贷款。BERT 在理解"银行"时,可以看到:
text
左边:我今天去
右边:办理了贷款它利用完整句子做判断。
GPT 是单向生成。
它生成文本时,只能看到已经出现的内容,不能提前看到未来答案。
例如:
text
我今天去银行办理了GPT 只能根据前文预测下一个 token,不能提前看到后面一定是"贷款"。
这就是两者的根本差异:
text
BERT 适合理解完整文本
GPT 适合生成后续文本5. 训练目标:完形填空 vs 下一个词预测
BERT 的经典训练目标之一是 Masked Language Modeling,也就是 MLM。
它会把句子中的一部分 token 遮住,让模型根据上下文猜出来。
原句:
text
我今天去银行办理贷款。训练时变成:
text
我今天去 [MASK] 办理贷款。模型要预测:
text
银行这很像完形填空。
因为 BERT 可以同时看 [MASK] 左边和右边,所以它能学习双向语义理解。
GPT 的训练目标是 causal language modeling,也可以理解成 next token prediction。
给它:
text
我今天去银行它要预测下一个 token:
text
办理再根据:
text
我今天去银行办理预测:
text
贷款这就是从左到右的连续预测。
所以 GPT 学到的是持续生成能力:给定前文,预测后文。
6. 结构路线:Encoder vs Decoder
Transformer 最初包含 Encoder 和 Decoder 两部分。
BERT 主要使用 Encoder。
Encoder 适合把输入文本整体读进去,然后提取语义表示。
它像阅读理解考生:
text
先拿到完整文章
再回答问题GPT 主要使用 Decoder。
Decoder 适合根据已有内容一步步生成新内容。
它像续写作者:
text
先拿到开头
再接着往下写这个结构差异影响了它们的工程使用方式。
BERT 类模型通常一次前向推理就能得到分类分数、向量或 span。
GPT 类模型通常要逐 token 生成,输出越长,推理越久。
7. 任务适配:理解任务 vs 生成任务
BERT 更适合传统 NLP 理解任务。
例如文本分类:
text
输入:这家店服务很好,下次还会来。
输出:正面例如句子匹配:
text
北京今天下雨了吗?
今天北京天气有雨吗?
输出:语义相似例如命名实体识别:
text
马斯克创办了 SpaceX。
输出:马斯克 / 人物,SpaceX / 组织例如搜索排序:
text
query:BERT 和 GPT 区别
document:一篇解释 BERT/GPT 差异的文章
输出:相关性分数GPT 更适合生成和交互任务。
例如对话:
text
用户:BERT 和 GPT 有什么区别?
模型:生成完整解释。例如写作:
text
用户:写一篇 BERT 和 GPT 的科普文章。
模型:生成文章。例如代码生成:
text
用户:用 Python 写一个读取 CSV 并统计字段的脚本。
模型:生成代码。例如 Agent:
text
用户:帮我查天气,然后安排出门计划。
模型:理解意图,调用工具,整合结果,生成计划。一句话:
text
BERT 更像判别器和编码器
GPT 更像生成器和交互入口8. 为什么以前 BERT 很火,现在 GPT 更火?
这不是因为 BERT 没用了,而是需求变了。
2018 到 2020 年前后,NLP 领域的核心任务大多是理解类任务:
text
分类
匹配
抽取
阅读理解
搜索排序这些任务通常有明确输入和明确输出,不需要生成很长文本。
BERT 在这类任务上非常强,所以它迅速成为工业界和学术界的主流基础模型。
后来,模型规模变大、训练数据变多、算力增强,生成式模型开始展现更强的通用能力。
GPT 路线不只是做一个分类任务,而是能通过自然语言接口完成很多任务:
text
写文章
写代码
做总结
聊天
推理
调用工具
规划任务它从"一个模型解决一个任务",走向"一个模型通过提示词解决很多任务"。
这就是 GPT 路线后来更受关注的原因。
9. BERT 过时了吗?
没有。
BERT 在很多场景仍然有价值,尤其是强调稳定、低延迟、低成本、可控输出的理解任务。
比如:
text
搜索排序
文本分类
风控审核
日志分类
客服意图识别
语义相似度
信息抽取
Reranker
Embedding如果只是判断一句话属于哪个类别,或者判断两个文本是否相似,不一定需要 GPT 类大模型生成长篇回答。
例如:
text
用户:我的订单什么时候发货?
系统只需要识别意图:查询物流这类任务用 BERT、RoBERTa、Sentence-BERT、MiniLM 等路线的模型,可能更便宜、更快、更稳定。
所以 BERT 不是过时,而是角色变了。
它从"通用 NLP 主角",变成了"理解类任务中的高效组件"。
10. GPT 能完全替代 BERT 吗?
不能简单这么说。
GPT 的能力更通用,但不代表所有任务都应该用 GPT。
原因有四个。
第一,成本不同。
GPT 类大模型通常参数更多,推理成本更高。如果只是做分类,用大模型可能浪费。
第二,延迟不同。
BERT 类模型通常一次前向推理给出结果;GPT 需要逐 token 生成,长输出会增加延迟。
第三,可控性不同。
BERT 输出通常是固定标签、分数或向量。GPT 输出自然语言,灵活但更难完全约束。
第四,部署复杂度不同。
小型 BERT 类模型更容易部署到 CPU、边缘设备或轻量服务里;大型 GPT 模型通常对 GPU、显存和推理框架要求更高。
更准确的判断是:
text
GPT 扩大了语言模型能力边界
BERT 仍然适合高频、明确、稳定的理解任务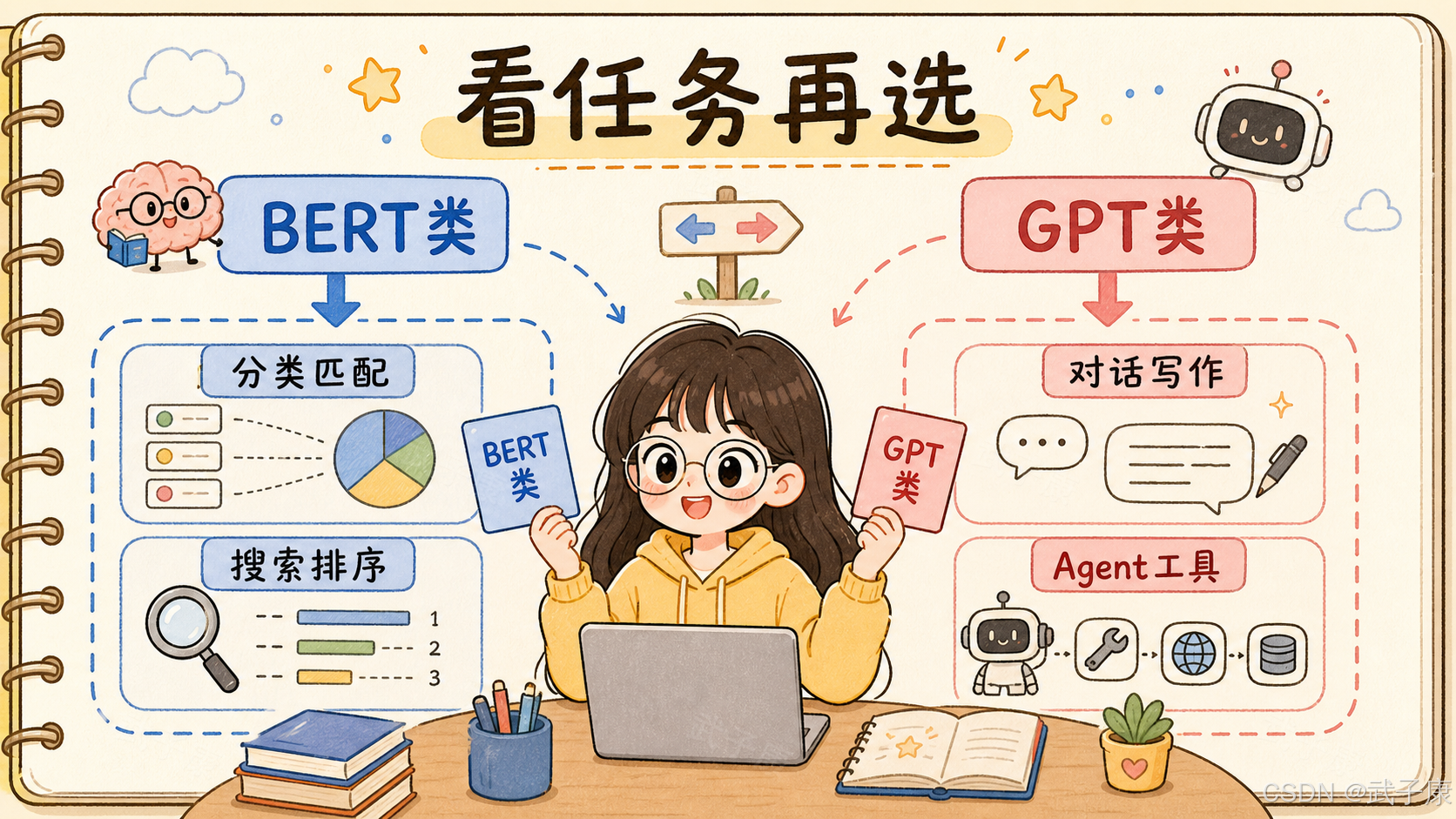
11. 工程上怎么选?
如果你要做的是理解、判断、分类、匹配、排序,优先考虑 BERT 类模型。
例如:
text
用户意图识别
文本分类
情感分析
语义相似度
搜索排序
实体抽取
Reranker如果你要做的是生成、对话、写作、代码、复杂推理、多轮交互,优先考虑 GPT 类模型。
例如:
text
智能客服
AI 助手
文章生成
代码生成
Agent
RAG 问答
多轮语音对话
工具调用如果系统比较复杂,通常不是二选一,而是组合使用。
比如一个智能客服系统:
text
BERT:意图识别、问题分类、相似问检索
GPT:生成回答、总结上下文、调用工具、处理复杂问题再比如一个 RAG 系统:
text
Embedding:把文本转成向量
Reranker:对候选文档重新排序
GPT:基于检索结果生成最终答案这里的 Embedding 和 Reranker 很多都与 BERT 路线有关,而最终回答通常由 GPT 类模型完成。
12. 一张表总结 BERT 和 GPT
| 对比维度 | BERT | GPT |
|---|---|---|
| 核心定位 | 理解模型 | 生成模型 |
| 结构路线 | Transformer Encoder | Transformer Decoder |
| 看文本方式 | 双向看上下文 | 从左到右看上下文 |
| 训练目标 | Masked Language Modeling | Next Token Prediction |
| 典型任务 | 分类、匹配、抽取、排序 | 对话、写作、代码、推理 |
| 输出形式 | 标签、分数、向量、片段 | 连续自然语言、代码、工具参数 |
| 推理特点 | 一次编码,通常更快 | 逐 token 生成 |
| 工程优势 | 稳定、低成本、适合判别任务 | 通用、灵活、适合复杂交互 |
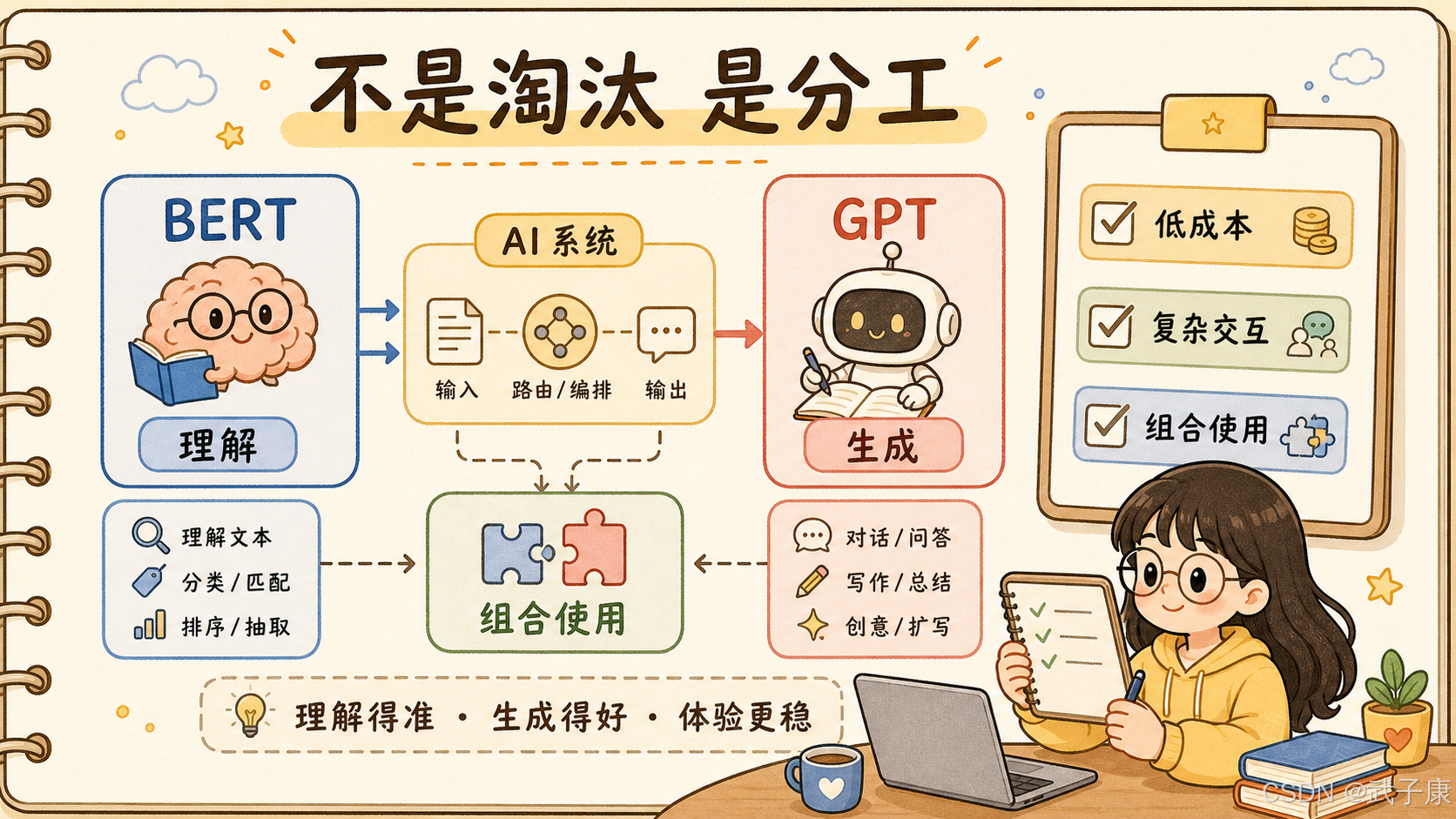
13. 小结:不是淘汰,而是分工
很多人会把 BERT 和 GPT 理解成两个时代:
text
BERT 是上一代
GPT 是下一代这个说法有一定道理,但不完整。
更准确的理解是:
text
BERT 代表语言理解模型的经典路线
GPT 代表生成式语言模型的主流路线BERT 的优势在编码和理解。
GPT 的优势在生成和交互。
BERT 像系统里的语义编码器、分类器、排序器。
GPT 像系统里的生成器、规划器、交互入口。
现代 AI 应用里,两者经常同时存在。
真正成熟的工程选型,不是问"BERT 和 GPT 谁赢了",而是问:
text
这个环节需要理解,还是生成?
需要稳定标签,还是自然语言回答?
需要低成本高吞吐,还是复杂交互能力?把这个问题想清楚,BERT 和 GPT 的分工也就清楚了。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 分类任务用 GPT 大模型,延迟高、成本贵 | 把 GPT 的生成长文能力等同于"更强",忽视参数规模和推理成本 | 监控分类接口的 P99 延迟与单次 token 消耗 | 低频分类、意图识别改回 BERT / RoBERTa / SBERT / MiniLM 路线 |
| 认为 "BERT 已经过时,被 GPT 取代" | 误把"BERT 类路线"等同于"BERT 单模型",忽略 RoBERTa、ERNIE、DeBERTa、SBERT、ModernBERT 等持续演进 | 看团队是否仍在用 bert-base-chinese / hfl/chinese-roberta-wwm-ext 这类老基座 |
按场景选 BERT 路线小模型,而非无脑上 GPT |
| GPT 输出格式不稳定,难以做严格分类 | GPT 走自然语言生成路径,难以约束为固定标签/向量 | 跑测试集发现分类结果有 hallucination | 把"理解/分类/匹配"前置用 BERT 类模型,GPT 只负责最后生成 |
| 短文本 RAG 召回不准,还想靠 GPT 解决 | Embedding 模型效果差,单靠 GPT 生成答案救不了 | 用诊断集测试 hit rate / MRR | 升级 BGE / M3E / SBERT 这类 BERT 系 Embedding,配合 BERT 系 Reranker |
| BERT 单次只能输入 512 token,长文本效果差 | 把 BERT 当作通用大模型用,没用 Longformer / RoPE 长上下文方案 | 看是否有"前面被截断"的报错 | 长文本理解用 Longformer、LED,或切段+BERT Embedding+Reranker |
| Agent 工具调用总出错,认为 GPT 不可靠 | 实际是任务分错了------把意图识别交给 GPT 在每轮重做 | 看 prompt token 中是否重复出现完整的意图分类指令 | 意图识别用 BERT 类小模型常驻,只把"复杂决策"留给 GPT |
作者:武子康的个人博客