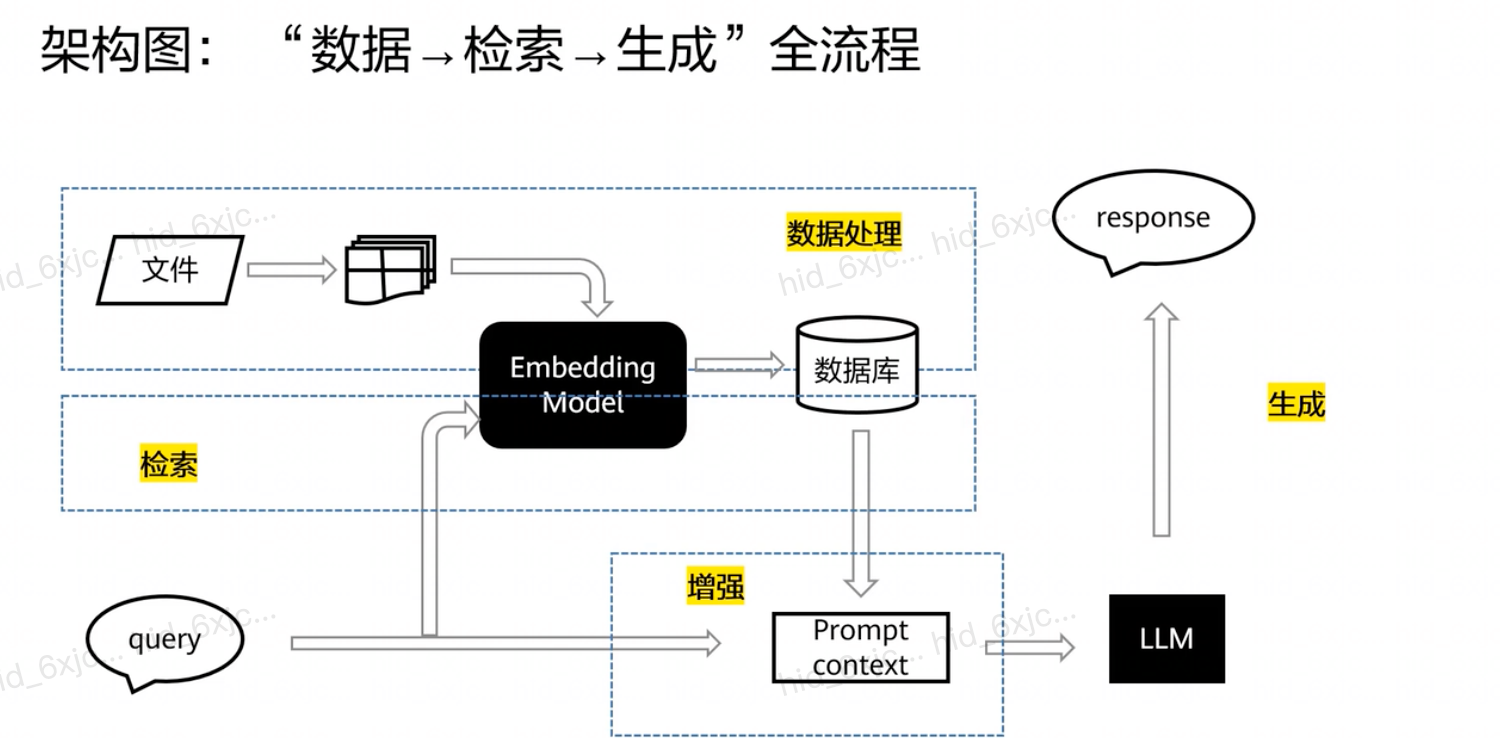
- RAG技术核心目标 :
- 增强领域适配性:引入外部知识,解决LLM在特定领域的知识时效性问题,减少模型产生幻觉的风险。
- 实现企业私有数据利用:动态检索与安全调用企业私有数据,将企业内部文档、数据库等信息集成到智能应用中。
- 构建端到端流程:涵盖数据预处理、信息检索、答案生成以及评估与优化,提升智能应用性能和可靠性。
- RAG核心工作流程 :
- 索引环节:对领域知识库进行数据预处理,将文档智能分块,用嵌入模型将文本块转换为向量表示,存储到向量数据库。
- 检索阶段:用户提问时,将查询语句向量化,在向量数据库中进行相似度搜索,返回topk个文档片段。
- 生成阶段:将检索到的文档与用户问题输入到大语言模型,生成精准回答。
- 数据预处理 :
- 数据加载:支持多种数据格式接入,去除文档中的噪音数据。
- 文本分块 :采用固定长度分块(如500词一块)和按段落或语义分割的智能分块方式,使用Langchain的character text splitter工具,设置重要参数保证上下文连贯性。

separator="\n"分割分隔符,这里指定换行符 \n 作为优先切割标记。
chunk_size=1000单个文本块最大字符长度上限,这里设为 1000 个字符。
chunk_overlap=50相邻两个文本块之间重叠字符数量,此处前后块重叠 50
个字符。核心目的:防止关键语义被切割在两块交界处丢失,提升检索时的召回完整性。
length_function=len用于计算文本长度的函数,默认使用 Python 内置len()统计字符数。
split_text(text):拆分方法,传入原始完整长文本,返回分块后的字符串列表 [chunk1, chunk2,chunk3...]。
- 向量化与存储 :
- 嵌入模型选择:有开源模型路线(如BGE、NOMIC、embedded等)和商业API方案(如Openai的embedding服务)。
- 向量数据库部署 :主流工具包括轻量级的Bromadb和高性能的Faiss,展示了Faiss的批量插入实现代码。

- 混合检索策略 :
- 语义检索:基于向量相似度进行文档匹配,使用余弦相似度,根据用户问题语义特征在知识库中找相关文档片段。
- 生成回答 :将匹配的文档作为上下文,请求Deepseek 1.5B模型生成最终回答,展示了关键代码实现。

.similarity_search():执行向量相似度匹配
answer_question():封装了调用deepseek的逻辑
通过 Streamlit 网页把结果返回给用户
- 上下文注入prompt模板设计 :
- 模板结构:包含系统指令(要求模型仅基于资料回答)、检索结果(动态插入相关文档片段)、用户问题。
- 工具示例 :利用Langchain的retriever QA链简化流程,展示了关键代码示例实现全流程自动化。

temperature=0.5:控制随机性。较低值回答更稳定
model_name="DeepSeek:1.5b":指定模型
chain_type="stuff":使用stuff模式合并上下文。最简单的上下文注入策略
逻辑:把所有检索到的docs文档全部拼接,一次性塞进 Prompt 的{context}占位符,完整注入上下文;适合检索文档总长度较短、不超过 LLM 上下文窗口的场景。
-
问答系统代码分析:
- 函数定义:定义answer question函数,根据知识库内容回答用户问题。
- 参数设置:设置Openai API密钥、基础URL,选择模型(如Deepseek 21),从session state获取温度值控制生成文本随机性。
- 侧边栏设置:使用streamlit侧边栏构建滑块控件,让用户调整温度参数,解释参数含义和作用。
- 生成回答流程 :检查知识库是否加载,使用向量数据库检索相关文档,调用answer question函数生成答案。

-
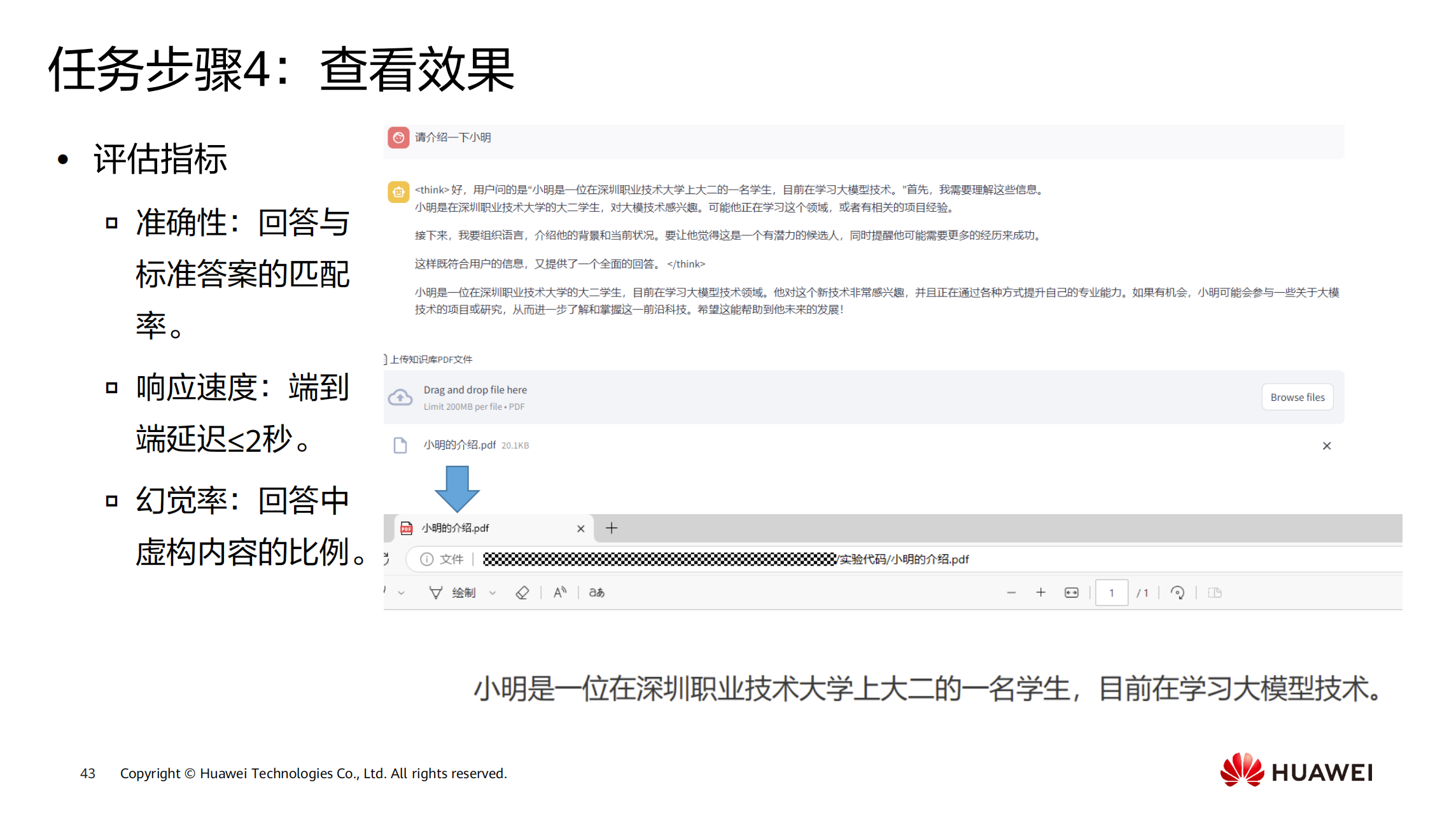
大模型回答指标:
- 准确性:衡量模型生成答案与标准答案的匹配程度,是核心指标。
- 响应速度:目标是保持端到端延迟在2秒以内,提供流畅体验。
- 幻觉率 :衡量回答中虚构内容的比例,需尽可能降低。
-
查看效果与优化方向:
- 效果评估:关注检索结果相关性、生成回答准确性,检查是否存在信息遗漏或冗余。
- 分块策略调整 :通过调整chunk size和chunk overlap优化分块策略,对比不同分块粒度对检索的影响。

-
提升智能小助手工作效率:
- 模型参数优化:调整模型参数(如温度)提高模型准确性和效率。
- 检索算法优化:使用向量索引和近似最近邻搜索技术加速检索过程,提高响应速度。
- 提高生成速度:采用分块策略调整提升生成速度。
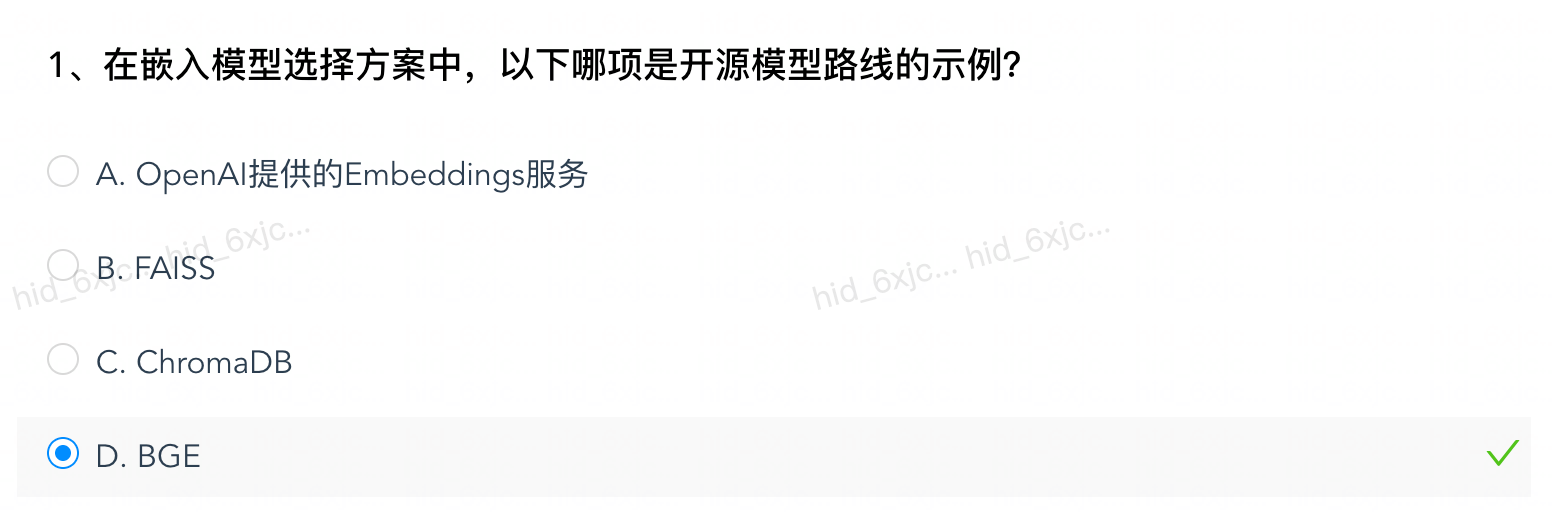
A 选项:OpenAI Embeddings 是商业 API 闭源嵌入服务,不属于开源模型路线。
B 选项:FAISS 是 Meta 开源的向量检索引擎 / 向量数据库工具,不是嵌入模型。
C 选项:ChromaDB 是轻量级向量数据库,不是嵌入模型。
D 选项:BGE 是国内开源的高质量嵌入模型,属于开源嵌入模型路线的典型示例。
限制对话轮数是硬性约束手段,不是对多轮对话本身效果的优化,只是粗暴截断对话,不属于优化方向。
A. 可以是开源预训练模型 ✅
RAG 的基座大模型没有闭源强制要求,Llama、Qwen、GLM 这类开源预训练模型都能作为 RAG 的生成端基座,该选项正确。
B. 必须针对特定任务微调 ❌
RAG 的核心是靠检索外部知识库补充信息,不需要一定对大模型做任务微调,只用提示词把检索到的片段喂给模型就能完成生成,微调只是优化手段、不是硬性要求,该选项错误。
C. 负责生成最终答案 ✅
检索模块只负责找出相关参考文本,把检索结果和用户问题拼接后,由大语言模型整合信息、输出最终回答,这是 LLM 在 RAG 里的核心职责,该选项正确。
D. 与检索模块相互独立 ❌
RAG 的流程是先检索、再把检索结果输入大模型,二者是强联动的上下游环节,不是相互独立的,该选项错误。
A. 初始化 LLM 连接
load_qa_chain接收已经初始化好的 LLM 实例作为入参,它本身不会创建、初始化 LLM 连接,LLM 需要提前外部实例化,所以 A 错误。
B. 加载问答链
load_qa_chain是工厂函数,核心作用就是根据传入的 LLM、chain_type参数,创建 / 加载对应的文档问答链对象,B 正确(你图里勾选的这一项是对的)。
C. 采用 "stuff" 模式合并上下文
函数可以通过设置chain_type="stuff"指定使用 stuff 模式,内部会用StuffDocumentsChain把检索到的多段文档拼接合并为单段上下文,这是该函数支持的核心能力之一,C 正确。
D. 调用模型生成回答
load_qa_chain只是构建链结构,只有后续执行chain.run()/chain()调用链实例时,才会触发 LLM 生成回答;函数本身不会直接调用模型产出结果,D 错误。