TL;DR
Addy Osmani 与 Google 合著的白皮书提出:AI 正在重塑软件开发生命周期(SDLC),核心理念不是"让 AI 替你写代码",而是"让 AI 跑在一个你设计的循环里"。本文基于白皮书中的 Harness 架构模式,从零搭建一条 Claude Code 驱动的自动化开发流水线------代码生成、审查、测试、文档,全部串在一个可控的循环里,附完整配置和可运行脚本。
1. 背景:SDLC 正在被重写
2026 年 6 月 16 日,Addy Osmani 发布了一篇名为《The New Software Lifecycle》的博文,背后是他与 Google 合著的一份白皮书。核心观点很直接:过去两年我们花了大量精力让 AI 写代码更快,但很少有人重新思考"软件开发到底该长什么样"。
传统的 SDLC 是线性的:需求 → 设计 → 编码 → 测试 → 部署 → 维护。AI 工具最初只是被塞进"编码"这个环节------你问 Copilot 要一段补全,让 ChatGPT 写个函数。但 Osmani 指出,真正有效的模式是把 AI 放进一个循环(loop),而不是一个点。
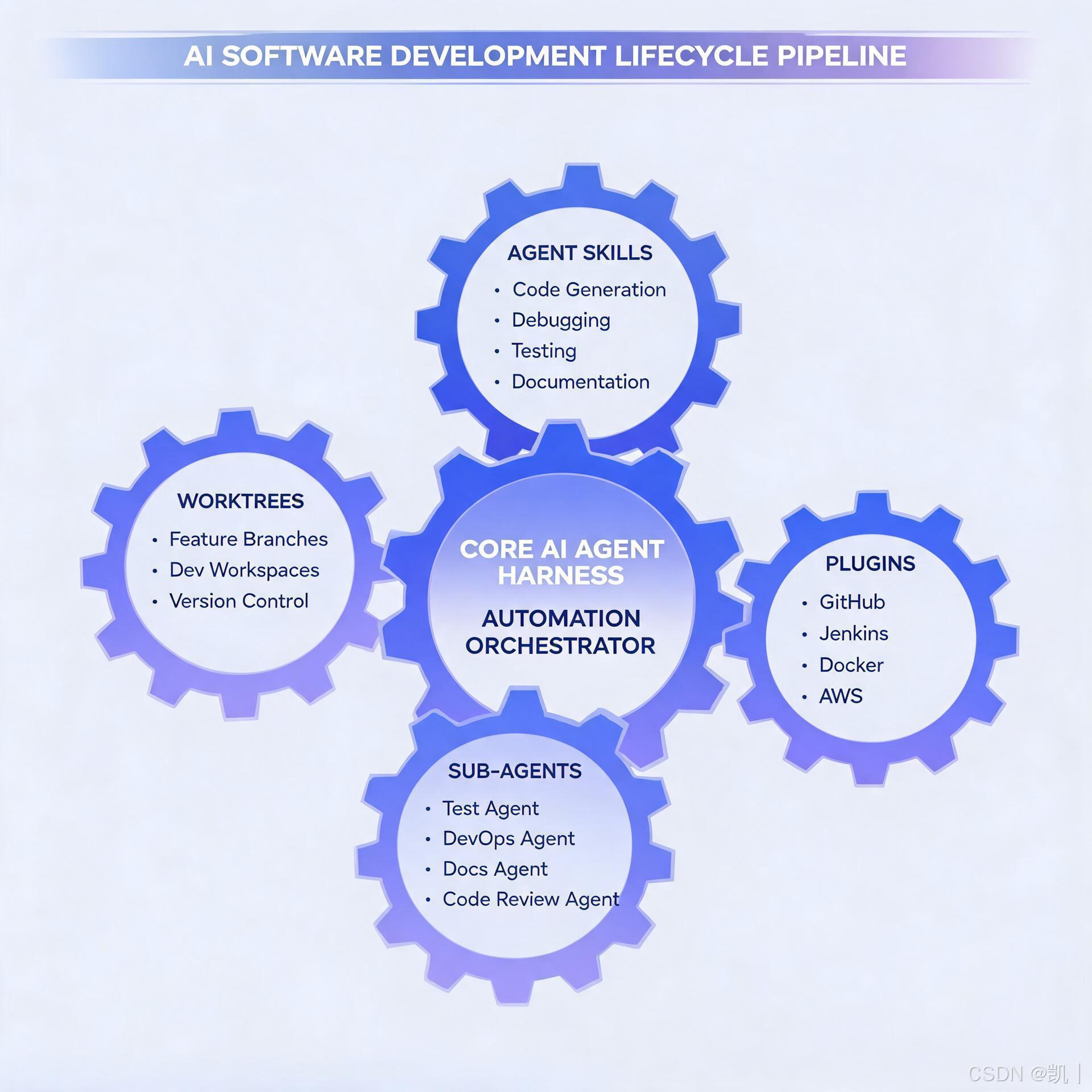
这个循环的核心是一个叫做 Harness(挽具)的架构模式。Harness 不是让一个超级 Agent 做所有事,而是用多个专门化的组件(自动化、工作树、技能、插件、子智能体)组成一条可控的流水线,人的角色从"执行者"变成"设计者+把关者"。
本文的目标就是把这篇白皮书里的概念,翻译成一套你能直接跑的配置和脚本。
2. Harness 架构拆解
在动手之前,先理解 Harness 的五个组件,因为后面的配置都围绕它们展开:
自动化(Automation):循环的心跳。定时或事件触发,让工作流自动运转,而不是每次都手动敲命令。
工作树(Worktrees):让多个任务并行而不互相踩脚。每个 Agent 在隔离的 git worktree 里工作,互不干扰。
技能(Skills):给 Agent 装上领域知识。不用每次都解释项目背景------把规范、编码风格、踩过的坑写成 skill 文件,Agent 自动加载。
插件/连接器(Plugins & Connectors):让 Agent 触碰真实工具------GitHub、Slack、Linear、数据库,而不是活在沙箱里。
子智能体(Sub-agents):把"创作者"和"审查者"分开。一个 Agent 写代码,另一个 Agent 审代码,互相制衡。
下面我们把这五个组件落成一套实际配置。
3. 环境准备
确保已安装 Claude Code(需要 Node.js 18+):
bash
npm install -g @anthropic-ai/claude-code
claude --version创建项目目录:
bash
mkdir ai-sdlc-harness && cd ai-sdlc-harness
git init
mkdir -p .claude/skills .claude/workflows scripts4. 第一步:定义技能文件(Skills)
给 Claude Code 装上项目背景。创建 .claude/skills/project-context.md:
markdown
# 项目背景
## 技术栈
- 前端:Next.js 14 + TypeScript + Tailwind CSS
- 后端:FastAPI + PostgreSQL
- 部署:Docker + GitHub Actions
## 编码规范
- 函数不超过 40 行
- 所有公开 API 必须有类型注解
- 错误处理:永远不要吞异常,用结构化日志记录
## 已知坑位
- Next.js middleware 里不能用 Node.js 原生模块
- PostgreSQL connection pool 上限 20,批量操作注意释放
## 测试要求
- 单元测试覆盖率 > 80%
- API 端点必须有集成测试创建 .claude/skills/code-review-checklist.md:
markdown
# 代码审查清单
审查每段代码时,逐项检查:
1. 安全性:是否有 SQL 注入、XSS、未校验的用户输入?
2. 性能:是否有 N+1 查询、未加索引的排序?
3. 错误处理:是否所有异常都有合理的处理路径?
4. 可读性:变量名是否自解释?是否有不必要的嵌套?
5. 测试:是否覆盖了边界条件和异常路径?5. 第二步:搭建自动化流水线(Automation)
创建 .claude/workflows/daily-pipeline.sh:
bash
#!/bin/bash
# 每日自动化开发流水线
# 用法: bash .claude/workflows/daily-pipeline.sh
set -e
BRANCH=$(date +%Y-%m-%d)-auto
echo "[1/4] 创建今日工作分支: $BRANCH"
git checkout -b "$BRANCH"
echo "[2/4] Claude Code 生成代码..."
claude "根据 .claude/skills/project-context.md 中的规范,
在 src/ 目录下实现 TODO.md 中列出的今日任务。
每完成一个任务,自己运行 npm run typecheck 验证。"
echo "[3/4] Claude Code 自动审查..."
claude "根据 .claude/skills/code-review-checklist.md 审查
当前分支的所有变更,生成审查报告写入 .claude/review-$(date +%F).md"
echo "[4/4] 提交并创建 PR..."
git add -A
git commit -m "auto: daily pipeline $(date +%F)"
git push origin "$BRANCH"
gh pr create --title "Daily Pipeline $(date +%F)" --body "自动生成的每日变更"赋予执行权限并测试:
bash
chmod +x .claude/workflows/daily-pipeline.sh6. 第三步:配置工作树隔离(Worktrees)
创建 .claude/workflows/parallel-tasks.sh:
bash
#!/bin/bash
# 并行任务管理器------每个 Agent 在独立 worktree 工作
# 用法: bash .claude/workflows/parallel-tasks.sh "实现用户模块" "实现订单模块"
TASK1_DESC="$1"
TASK2_DESC="$2"
BASE_DIR=$(pwd)
WT_DIR=$(mktemp -d)
echo "[1/3] 为任务 1 创建隔离 worktree..."
git worktree add "$WT_DIR/task1" -b "auto/task1-$(date +%s)"
echo "[2/3] 为任务 2 创建隔离 worktree..."
git worktree add "$WT_DIR/task2" -b "auto/task2-$(date +%s)"
echo "[3/3] 并行启动两个 Claude Code Agent..."
# Agent 1: 在 task1 worktree 中工作
(cd "$WT_DIR/task1" && claude "$TASK1_DESC") &
PID1=$!
# Agent 2: 在 task2 worktree 中工作
(cd "$WT_DIR/task2" && claude "$TASK2_DESC") &
PID2=$!
wait $PID1 $PID2
echo "两个任务完成。审查合并..."
claude "审查 $WT_DIR/task1 和 $WT_DIR/task2 的变更,
检查是否有冲突,生成合并建议。"
# 清理
git worktree remove "$WT_DIR/task1"
git worktree remove "$WT_DIR/task2"
rm -rf "$WT_DIR"这个脚本的精妙之处在于:两个 Agent 在物理隔离的文件系统中工作,永远不会出现"改了同一个文件"的冲突。等两边都完成后,再由一个审查 Agent 做合并判断。
7. 第四步:连接外部工具(Plugins)
创建 .claude/workflows/notify.sh,让流水线完成后自动通知团队:
bash
#!/bin/bash
# 流水线完成后的通知
# 依赖: gh (GitHub CLI), curl
REPORT_FILE=".claude/review-$(date +%F).md"
STATUS="${1:-success}"
if [ "$STATUS" = "success" ]; then
SUMMARY=$(head -20 "$REPORT_FILE" 2>/dev/null || echo "今日流水线完成")
# 发 GitHub PR 评论
gh pr comment "$(gh pr list --limit 1 --json number -q '.[0].number')" \
--body "## 今日自动流水线报告
$SUMMARY
> 自动生成于 $(date '+%Y-%m-%d %H:%M')"
echo "通知已发送"
else
echo "流水线失败,请检查日志"
# 可以接入 Slack webhook 等
fi8. 踩坑与最佳实践
坑 1:Agent 的"过度自信"
Claude Code 在生成代码时偶尔会产生幻觉------引用了不存在的 API 或库。解决方案:在 skill 文件中明确列出项目的 package.json 依赖,让 Agent 在生成代码前先确认库是否可用。也可以在流水线中加一步 npm run typecheck 自动拦截。
坑 2:worktree 清理不及时
git worktree add 后如果进程崩溃,会留下孤儿 worktree。建议在脚本开头加 git worktree prune,并在 crontab 里定期执行清理。
坑 3:技能文件会过时
当你修改了技术栈或编码规范,记得同步更新 skill 文件。一个有效的做法是把 skill 文件纳入 code review 范围------每次 PR 如果改了规范相关代码但没有更新 skill 文件,CI 就报 warning。
坑 4:成本控制
每个 Claude Code Agent 调用都消耗 token。一个实用的技巧:在非关键任务上使用 claude --model haiku(更便宜更快的模型),只在核心代码生成和审查上使用完整模型。
9. 让它每天自动跑
用 cron 或 GitHub Actions 定时触发:
bash
# 添加到 crontab:每个工作日早上 9 点跑
# crontab -e
0 9 * * 1-5 cd /path/to/project && bash .claude/workflows/daily-pipeline.sh >> /tmp/pipeline.log 2>&1或者用 GitHub Actions(.github/workflows/daily-pipeline.yml):
yaml
name: Daily AI Pipeline
on:
schedule:
- cron: '0 9 * * 1-5'
jobs:
pipeline:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: anthropics/claude-code-action@v1
with:
prompt: "运行 .claude/workflows/daily-pipeline.sh"10. 这意味着什么
Addy Osmani 的白皮书揭示了一个正在发生的转变:软件工程的角色正从"写代码的人"变成"设计系统的人"。Harness 架构不是要取代工程师,而是把重复性的执行工作外包给 AI 循环,让人把精力花在架构决策、代码审查和领域理解上。
你今天搭的这条流水线,三个月后可能就是团队的标准工作方式。关键不是一步到位,而是先跑通最小的循环,然后逐步加组件。