预训练三剑客:BERT、GPT 与 T5 架构对比与实战【NLP系列第五篇】
1. 同一个 Transformer,三种用法
上一篇我们拆完了 Transformer 的每个零件:自注意力、多头、位置编码、残差连接、LayerNorm、FFN......但你可能注意到一个问题------市面上主流的大模型,用的并不是同一个 Transformer。
- BERT 只拿 Encoder
- GPT 只拿 Decoder
- T5 才拿完整的 Encoder + Decoder
同一个架构,为什么有三种用法?它们各自擅长什么?怎么选?
这篇博客就来回答这些问题。我们沿着预训练 + 微调这条主线,把 BERT、GPT、T5 的结构、预训练目标、微调方式逐一对比,最后落到实战:什么场景选什么模型、怎么写代码。
2. 核心概念:预训练 + 微调范式
在讲具体模型之前,先理解一下"预训练 + 微调"这个范式。它改变了 NLP 的游戏规则。
2.1 预训练
在大规模无标注 文本上训练模型,让它学会通用的语言能力------语法、语义、常识等。这个过程是 self-supervised 的,不需要人工标注数据,直接从原始文本中自动构造训练样本。
比如 GPT 的预训练任务就是"根据前面的词预测下一个词"------每一段文本天然就是训练数据。
2.2 微调
预训练完后,模型已经"会说人话"了,但要它做具体任务(情感分类、问答、翻译),还需要用少量标注数据做二次训练。微调时模型主体不变,只在顶部加一个简单的输出层,用小学习率(2e-5 ~ 5e-5)更新全部参数。
为什么有效? 因为预训练让模型学到了通用的语言知识,微调只是把这些知识"引导"到具体任务上------比从头训练快得多、效果好得多。
3. 三大模型架构对比
3.1 GPT(Decoder-only)
GPT 系列由 OpenAI 提出,核心思路很直接:用 Transformer 的 Decoder 做语言模型,根据左侧上下文预测下一个 token。
模型结构
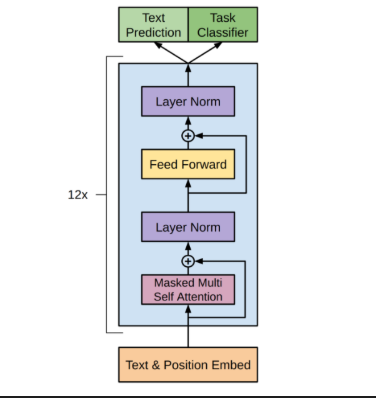
GPT 使用的是 Transformer Decoder 的一部分 ------只保留了 Masked Self-Attention + FFN 的结构,去掉了交叉注意力(因为没有 Encoder)。解码器层堆叠 12 层(GPT-1)。
GPT 的位置编码和原始 Transformer 不同,不再是固定的正弦余弦编码,而是改用可学习的位置嵌入------每个位置对应一个可学习的向量,训练过程中自动优化。
最终每个 token 的表示是词嵌入 + 位置嵌入的向量和,维度 768。
预训练:自回归语言建模
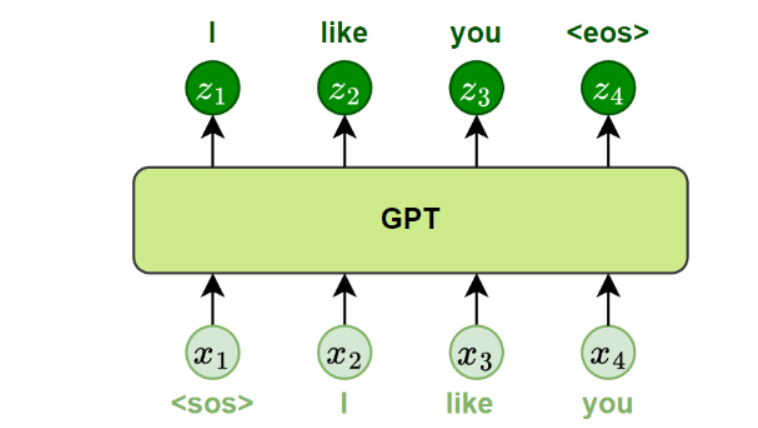
训练目标就是标准的自回归语言模型(Autoregressive LM):根据已看到的前文,预测下一个位置的 token。训练数据直接从原始文本中自动构建------拿一段文本,把它切成"前文→下一个词"的样本对即可。
这种方式的优点是数据获取成本为零,缺点是只能看到左侧上下文,无法利用右侧信息。
微调
GPT 微调时在模型顶部加一个线性分类头(Linear Head),将最后一个位置的隐状态映射到任务标签上。
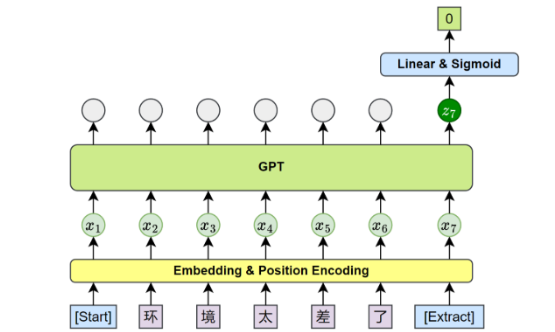
每个任务在输入前加上特殊标记 Start 和 Extract,模型只取 Extract 位置的输出做分类。
2018 年 GPT-1 发布时,微调是通过 Task Classifier 做的。后来 GPT-3 发现直接写 Prompt 让模型生成也能做分类------这就是 In-Context Learning。两种方式都能用,微调效果更稳定,Prompt 更灵活。
3.2 BERT(Encoder-only)
BERT 由 Google 于 2018 年提出,和 GPT 走了完全相反的路------它用 Transformer 的 Encoder ,核心思想是双向自注意力。
模型结构
BERT 直接使用 Transformer Encoder ,每个 token 的自注意力可以看到序列中的所有位置(包括左右两侧)。

两个版本:
| 模型版本 | 层数 | 模型维度 | 注意力头数 | 参数量 |
|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 1.1 亿 |
| BERT-large | 24 | 1024 | 16 | 3.4 亿 |
BERT 的输入由三部分嵌入相加组成:
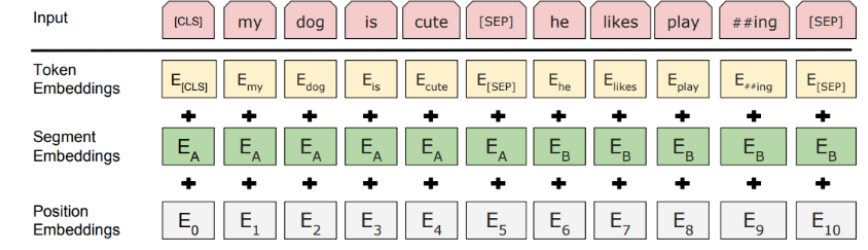
- Token Embedding:词本身的语义表示
- Position Embedding:可学习的位置向量
- Segment Embedding:区分句子对中的两个句子
此外,输入中通常包含两个特殊符号:
[CLS]:句首标记,其输出向量常用于下游分类任务[SEP]:句间分隔符,出现在每个句子末尾
预训练:MLM + NSP
BERT 的预训练包含两个任务:
掩码语言模型(MLM):

随机遮盖输入中 15% 的 token,让模型根据双向上下文预测被遮的词。遮盖策略:
- 80% 替换为
[MASK] - 10% 替换为随机词
- 10% 保持不变
这样模型既能看到左侧也能看到右侧,实现了真正的双向建模------这是 BERT 相比 GPT 最大的优势。
下一句预测(NSP):
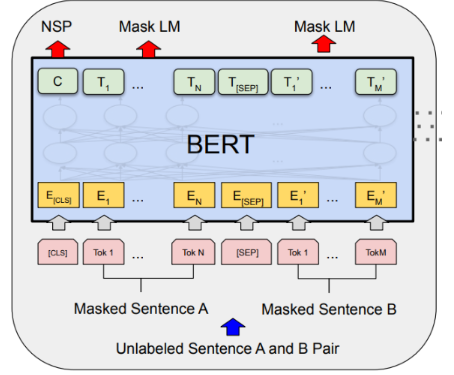
训练模型判断两个句子是否是连续的。这个任务提升了 BERT 在问答、推理等需要理解句子关系的任务上的表现。
微调
BERT 微调非常灵活:
- 文本分类 :取
[CLS]位置的输出,过一个线性层 - 序列标注:取每个 token 位置的输出,逐 tokek 分类
- 问答:预测答案的起始位置和结束位置
微调时模型主体不变,只加一个简单的输出层,用下游数据对整个模型做端到端训练。
3.3 T5(Encoder-Decoder)
T5 由 Google 在 2020 年提出,它走了第三条路------完整的 Encoder + Decoder。
核心思想
T5 的想法很纯粹:所有 NLP 任务本质上都是"文本到文本"的转换。分类也好、翻译也好、摘要也好------输入是文本,输出也是文本。
模型结构
T5 大体遵循原始 Transformer 架构,Encoder 做双向理解,Decoder 做自回归生成。此处不再展开,上一篇讲得够多了。
预训练:Corrupted Span Prediction

T5 的预训练目标结合了 BERT 和 GPT 的思路:
- 随机遮盖:在输入文本中随机遮盖若干连续片段(span),平均长度约 3 个 token
- 替换标记 :每个被遮盖的 span 替换为一个特殊标记
<X> - 生成目标:Encoder 读被破坏的文本,Decoder 生成被遮盖的 span 内容
举个例子,原始文本为 "Thank you for inviting me to your party":
Encoder 输入:Thank you <X> me to <Y> party.
Decoder 输出:<X> for inviting <Y> your这样既保留了 Encoder 的双向建模能力 (理解完整上下文),又为训练提供了生成式学习信号(Decoder 输出遮盖内容)。
微调:Text-to-Text Format
T5 微调时不需要加任何分类头------只需要在输入前加一个任务前缀(task prefix):
| 任务类型 | 输入形式 | 目标输出 |
|---|---|---|
| 翻译 | translate English to German: That is good. |
Das ist gut. |
| 情感分类 | sentiment: This movie was great. |
positive |
| 问答 | question: What is the capital of France? ... |
Paris |
| 摘要 | summarize: The study found that... |
生成的摘要 |
好处是:一个模型、一套架构做所有任务,不需要为分类、翻译、摘要分别设计不同的输出头。
4. 代码实战:用 HuggingFace Transformers 跑三大模型
下面演示如何用 transformers 库加载三种预训练模型,做推理。所有代码都标注了输入输出的 shape。
4.1 GPT-2 文本生成
python
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载 GPT-2 模型和分词器
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
# 输入文本
prompt = "The future of AI is"
inputs = tokenizer(prompt, return_tensors="pt")
# inputs.input_ids shape: (1, seq_len) --- batch=1
print(f"输入 shape: {inputs.input_ids.shape}") # torch.Size([1, 5])
# ⭐ 自回归生成:逐个 token 预测
output_ids = model.generate(
inputs.input_ids,
max_new_tokens=20, # 最多生成 20 个新 token
do_sample=True, # 采样(而不是 greedy)
temperature=0.7, # 控制随机性,越低越确定
pad_token_id=tokenizer.eos_token_id,
)
print(f"输出 shape: {output_ids.shape}") # torch.Size([1, 5 + 20])
# 解码输出
generated = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(f"生成结果:\n{generated}")
# 输出示例: "The future of AI is bright, but it's also a future that we need to be careful about..."4.2 BERT 情感分类
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch.nn.functional as F
# 加载 BERT 分类模型(预训练在 IMDB 上)
tokenizer = AutoTokenizer.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
model = AutoModelForSequenceClassification.from_pretrained(
"nlptown/bert-base-multilingual-uncased-sentiment"
)
# 输入文本
text = "This movie was absolutely fantastic!"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
# inputs.input_ids: (1, seq_len)
# inputs.attention_mask: (1, seq_len) --- 区分 padding 和真实 token
print(f"input_ids shape: {inputs.input_ids.shape}") # torch.Size([1, 8])
print(f"attention_mask shape: {inputs.attention_mask.shape}") # torch.Size([1, 8])
# BERT 前向传播
outputs = model(**inputs)
# outputs.logits: (1, num_labels) --- [CLS] 经过分类头的输出
print(f"logits shape: {outputs.logits.shape}") # torch.Size([1, 5])
# softmax 得到概率分布
probs = F.softmax(outputs.logits, dim=-1)
pred = probs.argmax(dim=-1).item()
print(f"情感得分 (1-5): {pred + 1}") # 1=最差, 5=最好
print(f"各星级概率: {probs[0].tolist()}")4.3 T5 翻译
python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# 加载 T5-small
tokenizer = AutoTokenizer.from_pretrained("t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# T5 微调时只需加 task prefix
input_text = "translate English to German: That is good."
inputs = tokenizer(input_text, return_tensors="pt")
# inputs.input_ids shape: (1, seq_len)
print(f"输入 shape: {inputs.input_ids.shape}") # torch.Size([1, 9])
# T5 用 Encoder-Decoder 生成
output_ids = model.generate(
inputs.input_ids,
max_new_tokens=20,
)
print(f"输出 shape: {output_ids.shape}") # torch.Size([1, ~5])
translation = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(f"翻译结果: {translation}") # "Das ist gut."三个模型的输入输出对比:
| 模型 | 输入格式 | 输出是什么 | 输出维度 |
|---|---|---|---|
| GPT | 文本(续写开头) | 自回归生成的 token 序列 | (1, input_len + gen_len) |
| BERT | 文本 + 注意力掩码 | 每个 token 的隐状态 / [CLS] 分类 |
(1, seq_len, 768) / (1, num_labels) |
| T5 | 文本 + task prefix | Encoder-Decoder 生成的 token 序列 | (1, gen_len) |
5. 避坑指南
5.1 预训练不要自己练
GPT-3 一次训练成本约 1200 万美元。哪怕 BERT-base 也要 16 块 TPU 跑 4 天。绝大多数场景直接使用 HuggingFace 上开源的预训练权重,微调就够了。
5.2 模型选择看任务
- 分类 / 匹配 / NER:选 BERT(Encoder-only),双向上下文理解最强
- 文本生成 / 对话 / 续写:选 GPT(Decoder-only),自回归天生适合生成
- 翻译 / 摘要 / 多任务统一:选 T5(Encoder-Decoder),text-to-text 框架最灵活
- 如果拿不准,T5 是最稳妥的选择------Encoder-Decoder 既能理解又能生成
5.3 微调 learning rate 要小
预训练模型的权重已经收敛到一个很好的局部最优了,微调只是为了"适配"下游任务。学习率设太大(>1e-4)会破坏预训练学到的语言知识。
建议范围:2e-5 ~ 5e-5,AdamW 优化器 + linear warmup。
5.4 输入长度限制
| 模型 | 最大输入长度 |
|---|---|
| BERT | 512 token |
| GPT-2 | 1024 token |
| T5 | 512 token |
超长文本需要切片处理。BERT 的 512 限制是 Transformer 的 self-attention 复杂度 O ( n 2 ) O(n^2) O(n2) 决定的。
5.5 GPU OOM
从 batch size = 8 或 16 开始试,OOM 了就减半。也可以用 gradient_accumulation_steps 等效增大 batch size。
python
# 显存不够时:batch_size=8,梯度累积 4 步 ≈ batch_size=32
training_args = TrainingArguments(
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
)6. 总结
三大模型对比
| 维度 | BERT (Encoder) | GPT (Decoder) | T5 (Enc-Dec) |
|---|---|---|---|
| 注意力 | 双向(全可见) | 单向(因果掩码) | 双向 + 单向 |
| 预训练目标 | MLM + NSP | 预测下一个 token | Span Corruption |
| 是否能生成 | 否 | 是 | 是 |
| 是否能理解 | 是 | 是 | 是 |
| 擅长的任务 | 分类、NER、QA | 对话、续写、代码生成 | 翻译、摘要、统一框架 |
| 代表模型 | BERT、RoBERTa | GPT、LLaMA、Qwen | T5、Flan-T5 |
| 输入长度限制 | 512 | 1024~8192+ | 512 |
一句话总结
BERT 最懂你,GPT 最能写,T5 最全能。选模型先看任务:理解用 BERT,生成用 GPT,想做所有事用 T5。