ChatGPT 凭什么记住你上句说的?Spring AI 多轮对话记忆,3 步搞定
这是 Spring AI 系列第 2 篇。还没看过第 1 篇《Java 后端 1 小时跑通第一个 AI 应用》的,点这里。
上篇我跑通了 Spring AI + 智谱 GLM 的 hello world,满怀信心地做了个 AI 接口。
但马上发现一个诡异的现象:我跟 AI 说"我叫张三",下一句问它"我叫什么",它居然回------
抱歉,您还没告诉我您的名字。
我:??我上一秒才说的啊。
如果你也在调 AI 接口,大概率遇到过这个"失忆"问题。
这不是 bug,是 LLM 的本质------大模型是无状态的,每次请求对它来说都是初次见面。
那 ChatGPT、智谱清言怎么做到多轮对话的?答案就藏在 Spring AI 的 ChatMemory 里。
这篇就用 50 行代码,让你的 AI 接口也能"记住上下文"。
一、为什么 LLM 会"失忆"?
理解这点很重要,不然后面看代码会懵。
LLM 的本质是无状态 :你调用一次 /v1/chat/completions,服务器处理完返回结果,这次连接就结束了。下次再调用,模型完全不知道你刚才说了什么------它的"记忆"只存在于这一次请求的 prompt 里。
那 ChatGPT 怎么做到多轮对话的?
答案:把历史消息一起发给它。
第 1 轮:
你:我叫张三
AI:你好,张三
第 2 轮(实际发送给模型的):
你:我叫张三
AI:你好,张三
你:我叫什么?
AI:(模型看到上面两行,所以能回答)张三就这么简单。所谓"多轮对话",本质就是把历史聊天记录塞进 prompt 里再发给模型。
那这件事谁来做?------Spring AI 的 ChatMemory 就是干这个的。
二、Spring AI 的 ChatMemory 是什么?
一句话:ChatMemory 就是 Spring 帮你管理的"聊天记录仓库"。
它的工作流是这样的:
用户发消息
↓
ChatMemory 根据 sessionId 取出历史消息
↓
历史消息 + 新消息 一起发给模型
↓
模型回复
↓
新消息 + 回复 存回 ChatMemory这里有几个关键概念:
| 概念 | 作用 |
|---|---|
| ChatMemory | 聊天记录仓库,负责存取 |
| sessionId | 会话 ID,区分不同用户的对话(就像浏览器的 cookie) |
| MessageChatMemoryAdvisor | Advisor 是 Spring AI 的"拦截器",自动注入历史消息 |
| MessageWindowChatMemory | 滑窗实现,只保留最近 N 条消息(避免 token 爆炸) |
理解了这 4 个概念,代码就是顺水推舟的事。
三、50 行代码实现多轮对话
我的项目结构(基于上一篇的 hello-ai):
css
hello-ai/
└── src/main/java/com/fuqiang/helloai/
├── HelloAiApplication.java
├── HelloAIController.java ← 改这里
└── ChatMemoryConfig.java ← 新增好消息:不用加新依赖。 MessageWindowChatMemory 和 MessageChatMemoryAdvisor 已经包含在 spring-ai-starter-model-openai 里了。
Step 1:配置 ChatMemory Bean
新建 ChatMemoryConfig.java:
java
@Configuration
public class ChatMemoryConfig {
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(20) // 滑窗:只保留最近 20 条消息
.build();
}
}maxMessages(20) 是关键:意思是"每个会话只保留最近 20 条消息"。
为什么要滑窗?------token 是要钱的。如果你跟 AI 聊了 1000 句,全塞进 prompt 一次请求就爆 token 了。滑窗机制保证只发最近 N 条,既保留了"近期记忆",又控制了成本。
Step 2:启用 Advisor + 加多轮对话接口
修改 HelloAIController.java,加一个带记忆的 ChatClient 和 /ai/chat 接口:
java
@RestController
@RequestMapping("/ai")
public class HelloAIController {
private final ChatClient chatClient;
private final ChatClient memoryChatClient;
public HelloAIController(ChatClient.Builder builder, ChatMemory chatMemory) {
// 无记忆版(保留原 hello 接口)
this.chatClient = builder
.defaultSystem("你是一个友好的助手,回答简洁清晰。")
.build();
// 带记忆版
this.memoryChatClient = builder
.defaultSystem("你是一个友好的助手,会结合上下文进行多轮对话。")
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}
@GetMapping("/hello")
public String hello(@RequestParam String message) {
return chatClient.prompt().user(message).call().content();
}
@GetMapping("/ping")
public String ping() {
return "pong";
}
// ✨ 新接口:带记忆的多轮对话
@GetMapping("/chat")
public String chat(@RequestParam String sessionId,
@RequestParam String message) {
return memoryChatClient.prompt()
.user(message)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, sessionId))
.call()
.content();
}
}两个 ChatClient 共存的设计:
chatClient:无记忆版,保留/ai/hello,用于一次性问答(翻译、补全)memoryChatClient:有记忆版,用于多轮对话场景
核心就这一行:
java
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, sessionId))每次调用时,把 sessionId 作为会话标识传给 Advisor,Advisor 就会自动从 ChatMemory 里取出该会话的历史消息塞进 prompt。
四、效果演示(4 个测试)
启动应用,跑 4 个测试。
测试 1:同一 sessionId,记忆生效 ✅
bash
http://localhost:8080/ai/chat?sessionId=user001&message=我叫张三,今年28岁返回:你好,张三!28 岁正是好年纪...
bash
http://localhost:8080/ai/chat?sessionId=user001&message=我叫什么名字?返回:您叫张三。

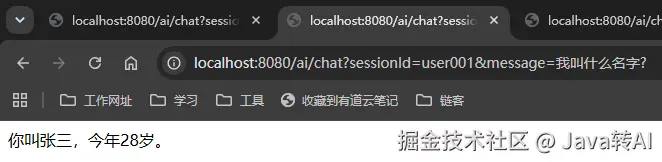
第一次告诉 AI"我叫张三",第二次只问"我叫什么",AI 居然答对了------它记住了。
测试 2:换 sessionId,完全失忆 ✅
bash
http://localhost:8080/ai/chat?sessionId=user002&message=我叫什么名字?返回:抱歉,您还没有告诉我您的名字。
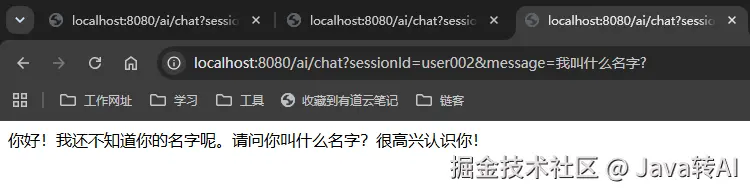
同样的问题,user002 得到的回答完全不同。这就是 sessionId 的作用:不同用户、不同设备、不同会话,各自独立。
测试 3:原接口不受影响 ✅
bash
http://localhost:8080/ai/hello?message=你好返回:你好!有什么可以帮你的?

无记忆版完好无损,新旧接口共存。
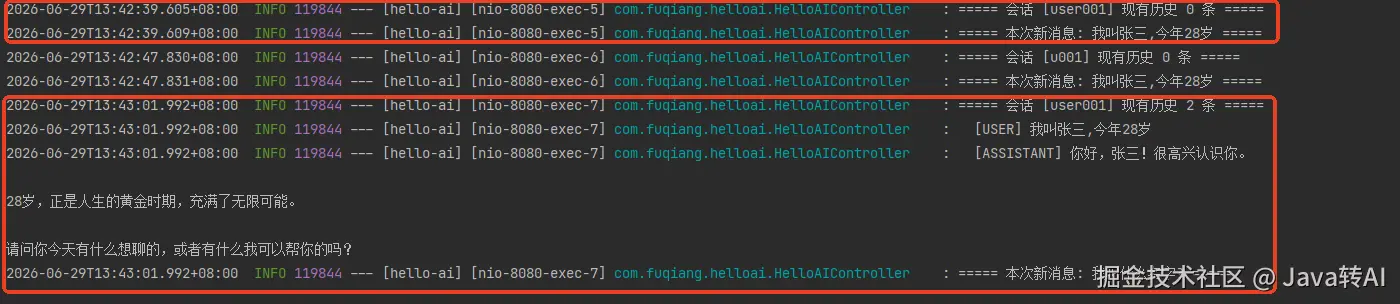
测试 4:控制台日志,看清"记忆"的真相 🔍
光看接口返回还不够直观。我在 /ai/chat 里临时加了几行日志,把每次请求前 ChatMemory 里已存的历史消息打印出来:
java
List<Message> history = chatMemory.get(sessionId);
log.info("===== 会话 [{}] 现有历史 {} 条 =====", sessionId, history.size());
history.forEach(m -> log.info(" [{}] {}", m.getMessageType(), m.getText()));第一次请求时,历史还是空的;第二次请求时,控制台输出:
css
===== 会话 [user001] 现有历史 2 条 =====
[USER] 我叫张三,今年28岁
[ASSISTANT] 你好,张三!很高兴认识你。28岁,正是人生的黄金时期...
===== 本次新消息: 我叫什么名字? =====这就是"记忆"的真相:第二次请求时,ChatMemory 里已经存了上一轮的 USER 消息和 ASSISTANT 回复。Advisor 会自动把这 2 条历史 + 本次新消息,一起塞进发给模型的 prompt。
模型看到的不是孤立的"我叫什么名字?",而是完整的上下文------所以它才能答出"张三"。
五、踩坑提醒(本文最值钱的部分)
整个过程看起来顺,但我踩了 2 个坑,提前给你避雷。
🕳️ 坑 1:sessionId 用错,以为多轮对话"失效"
我最开始的测试是没传 sessionId:
bash
http://localhost:8080/ai/chat?message=我叫张三
http://localhost:8080/ai/chat?message=我叫什么?结果第二句 AI 还是失忆。
排查后才发现:不传 sessionId,Advisor 会用默认值,而默认值对所有请求是同一个,理论上应该能记住------但如果你像我一样,中间改过代码重启过应用,内存里的 ChatMemory 就被清空了。
教训 :测试时显式传 sessionId,别依赖默认值。
🕳️ 坑 2:重启应用,记忆全丢了
某次测试:我跟 AI 聊了 5 句,记得好好的。重启应用后,再问"我叫什么",AI 又失忆了。
根因 :我们用的是 MessageWindowChatMemory,数据存在 JVM 内存里。应用一重启,内存清空,记忆全丢。
这是内存版的根本局限,生产环境不能这么用。解决方案:
| 方案 | 实现 | 适用场景 |
|---|---|---|
| JDBC 持久化 | 实现 ChatMemoryRepository 接口,存数据库 |
单机生产环境 |
| Redis 持久化 | 用 Spring AI 的 Redis 实现 | 多实例、高并发 |
这就是下一篇要写的内容(文末有预告)。
六、进阶:maxMessages 怎么选?
maxMessages(20) 不是拍脑袋定的,有几个考虑:
| 值 | token 消耗 | 记忆范围 | 适用场景 |
|---|---|---|---|
| 10 | 低 | 短期对话 | 客服 FAQ、简单问答 |
| 20 | 中 | 中等 | 大多数场景(推荐) |
| 50 | 高 | 长期上下文 | 长文档讨论、深度咨询 |
| 100+ | 很高 | 接近完整历史 | 不推荐,token 爆炸 |
经验法则:
- 一条消息平均 50-200 token
- glm-4.7 单次请求上限约 8K-128K token
- 20 条 ≈ 2000-4000 token,既够用又不浪费
真正的多轮对话产品,不会用固定窗口。会用"摘要 + 滑窗"组合:超过窗口时,把老消息压缩成摘要再丢弃。Spring AI 1.0 还没原生支持,需要自己实现
ChatMemory接口。这是值得单独写一篇的话题。
七、我学到了什么
- LLM 无状态是本质,不是 bug------理解这点,所有"AI 应用"的设计逻辑就通了
- 所谓"记忆"= 把历史塞进 prompt------这个心智模型比记住 API 重要 100 倍
- Advisor 是 Spring AI 的精髓------类似 Spring AOP,把横切逻辑(记忆、日志、风控)和业务代码解耦
- sessionId 是开发者的责任------AI 框架不会自动知道"这是同一个用户"
- 内存版只能开发用,生产必须持久化------别让用户聊到一半发现 AI "失忆"了
最大的收获:多轮对话的"魔法",拆开看就是个简单的存储 + 拼接逻辑。AI 应用没有想象中神秘,工程问题占 90%。
八、下一篇预告
这篇用了 MessageWindowChatMemory,数据在内存里。重启就丢,多实例不能共享。
下一篇我会写:
《Spring AI ChatMemory 持久化:用 MySQL/Redis 存对话记录》
包括:
- 实现
ChatMemoryRepository接口 - MySQL 表设计 + JDBC 配置
- Redis 方案对比
- 生产环境的 3 个最佳实践
这是把 demo 推向生产必须迈过的一步。
写在最后
我是一名8年 Java 后端,正在转型 AI 应用开发。Spring AI 系列会持续更新,从 hello world 到 RAG 到 Agent,一路踩坑一路写。
如果你也在转型 AI,关注我,一起走。有问题评论区聊,我会逐条回复。
如果这篇文章帮到了你,点个赞就是对我最大的鼓励 ❤️