2026年AI新范式:本体论与知识图谱的战略性回归
尽管大语言模型(LLM)的能力边界持续拓展,但在2023至2026年间,业界对本体论(Ontology)与知识图谱(Knowledge Graph, KG)的研究热度并未如预期般衰退,反而呈现出显著的逆势上扬态势。针对"知识图谱是否已过时"的行业疑问,微软、AWS、英伟达等头部科技企业的技术布局给出了明确回应:知识图谱并非历史遗存,而是正在被重构为新一代AI系统的核心基础设施。
这一趋势背后的深层逻辑,主要源于当前大模型技术在落地应用中面临的两大结构性瓶颈:
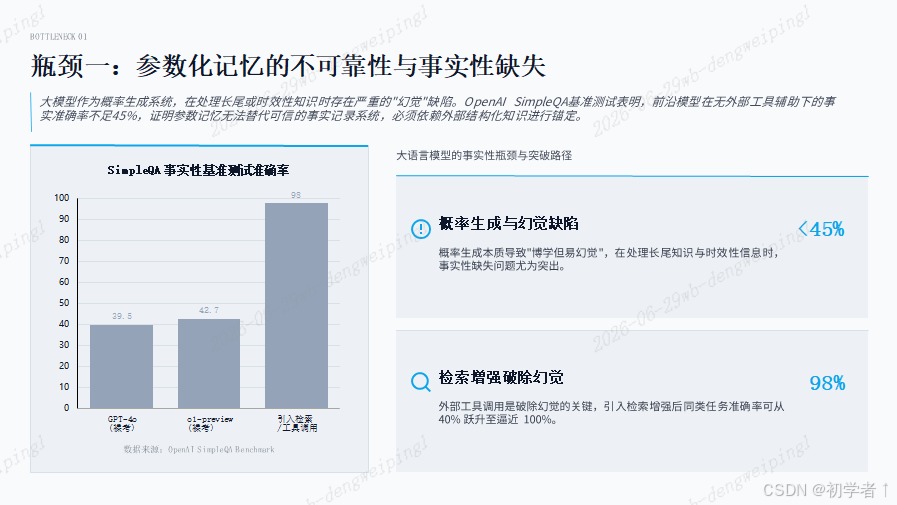
一、 参数化记忆的不可靠性与事实性缺失
大模型本质上是一个概率生成系统,而非可信的知识档案库。其"博学但易幻觉"的特性在处理长尾知识或时效性信息时尤为突出。根据OpenAI于2024年发布的事实性基准测试SimpleQA结果显示,即便是GPT-4o模型,在无外部工具辅助的"裸考"模式下准确率也不足40%;o1-preview模型虽有所提升,也仅达到42.7%。然而,当引入检索增强或工具调用后,同类任务的准确率可逼近100%。这充分证明:模型的参数记忆不等于可信的事实记录系统,必须依赖外部结构化知识进行锚定。
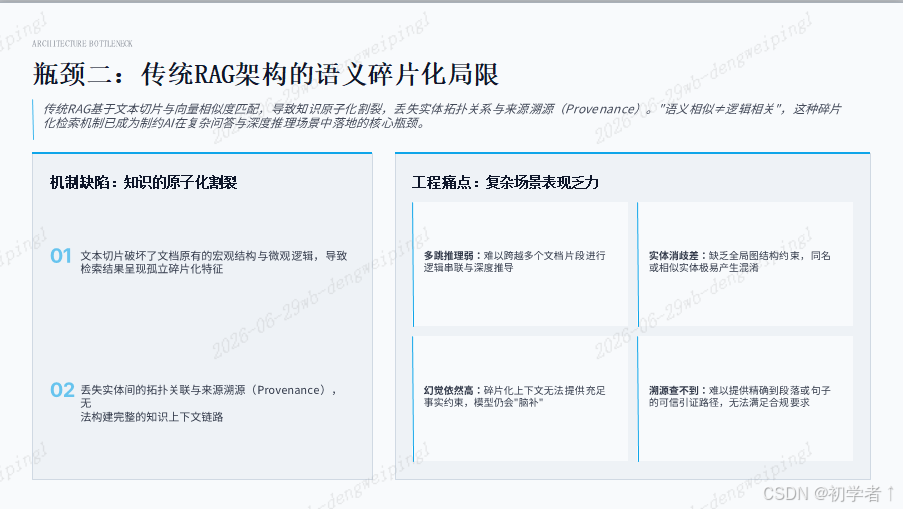
二、 传统RAG架构的语义碎片化局限
传统的检索增强生成(RAG)技术多基于文本切片与向量相似度匹配,这种机制虽然高效,却导致了知识的原子化割裂。由于丢失了实体间的拓扑关系与来源溯源(Provenance),传统RAG在多跳推理、实体消歧及复杂问答场景下表现乏力,且难以提供可信的引证路径。语义相似并不等同于逻辑相关,缺乏结构化关联的碎片化检索已成为制约AI深度应用的瓶颈。

三、 知识图谱在大模型时代的四重战略定位
基于上述痛点,知识图谱在2026年的AI技术栈中已演化出四个关键角色:
- 事实核查底座: 通过结构化知识约束生成内容,从源头抑制幻觉;
高阶检索底座(GraphRAG): 弥补向量检索在复杂语义理解上的不足; - 智能体(Agent)认知底座: 为Agent提供长期记忆、状态追踪与任务规划的结构化支撑;
- 企业治理与合规底座: 满足数据安全、权限管控及审计溯源等企业级刚需。
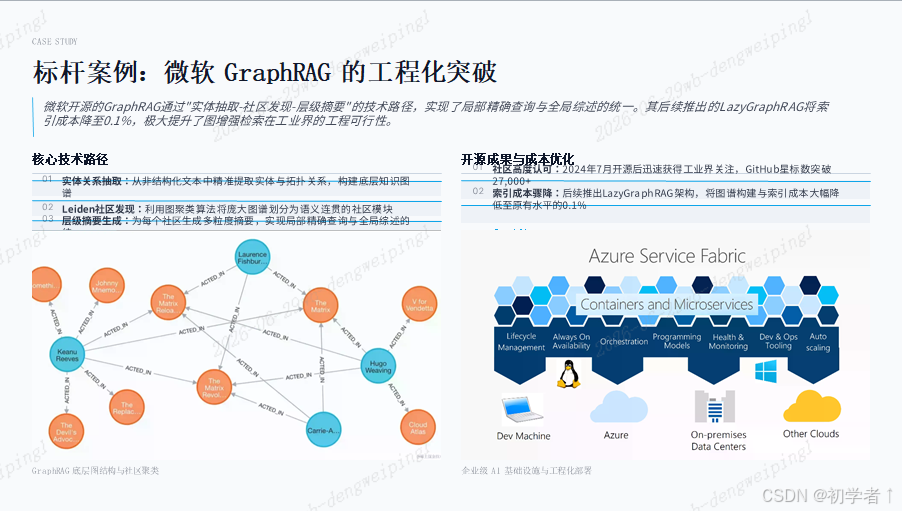
以微软开源的GraphRAG为例,该项目通过"实体关系抽取→Leiden算法社区发现→层级摘要生成"的技术路径,实现了局部精确查询与全局综述能力的统一。自2024年7月开源以来,其GitHub星标数突破2.7万,后续推出的LazyGraphRAG更将索引成本降低至原有水平的0.1%,极大提升了工程可行性。
四、 实践启示:摒弃"唯图论",走向融合架构
尽管GraphRAG优势显著,但2026年的最新实证研究表明,不应盲目追求"All-in GraphRAG"。在与传统向量RAG的对标测试中,两者呈现出明显的互补特征:
- 单跳事实查询: 向量RAG在成本与响应速度上更具优势,精度亦不逊色;
- 多跳推理与全局洞察: GraphRAG表现出压倒性优势。据AWS合作伙伴Lettria的实测数据显示,在需要引文溯源和跨文档综合的任务中,图结构的精度较纯向量方案最高提升达35%。
结论: 未来的AI应用架构并非单一技术的取舍,而是向量检索与知识图谱的深度融合。根据业务场景的复杂度动态选择或组合检索策略,才是构建高可信、高性能AI系统的务实之道。