系列07-如何用 AI 从 PRD 批量生成功能测试用例?Vision 读图与章节分批实战
一份 40 页的 PRD,测试负责人往往要 2~3 天 拆功能点、写步骤预期,还要对齐禅道「产品 / 模块 / 研发需求 / 适用阶段」。直接丢给 AI大模型,常见问题不是「写不出来」,而是 写不稳:
- 第 15 页流程图里的校验规则 根本没进用例
- 禅道
product被 AI 编造成不存在的模块路径 - 同一项目里,三个人用 AI 写,标题格式各一套
工程化做法不是「更大的 Prompt」,而是 解析 → 范围裁剪 → 双模型 → 结构化入库 → 平台注入元数据 。本文基于 BrickCore 需求测试中心(routers/ai/requirements.py + test_analysis.py)讲完整链路;设计思路可脱离具体平台复用。
演示与源码
| 地址 | |
|---|---|
| 功能演示 | http://43.142.83.156/showcase/ (「AI 需求 → 功能用例」含录屏;平台 admin / BrickCore123456) |
| 开源仓库 | https://gitee.com/BanZhuanKeOrz/BrickCore |
线上菜单:AI 测试 → 需求测试中心。建议先看演示录屏,再按第九节实操。
一、AI大模型 单对话 vs 平台流水线
| 维度 | 单对话粘贴 PRD | 平台流水线 |
|---|---|---|
| 上下文长度 | 易超 Token,只能手工砍章节 | scope_section_ids 按章裁剪 |
| 内嵌图片 | 需截图逐张贴 | Vision 读 PDF/Word 嵌入图 |
| 禅道字段 | LLM 编造 product/module | 平台绑定注入,不进 Prompt |
| 标题规范 | 每次格式漂移 | Jinja2 模板 + 语义槽位 |
| 可追溯 | 聊天记录 | 需求版本、批次、source_ref |
| 大文档 | 一次失败重来 | 异步 Job 分批 + 进度轮询 |
| 质量约束 | 靠人盯 | Prompt grounding + 禁止空洞表述 |
二、四层架构(从上传到导出)
┌─────────────────────────────────────────────────────────┐
│ 1. ingest 上传 PRD → MinIO 原文件 + 解析 document_structure │
│ 2. scope 章节树 → 勾选范围 → estimate_scope(ok/warn/block) │
│ 3. generate Vision 读图 → 正文+[图-N] 交错 → 文本 LLM → JSON │
│ 4. publish Jinja2 标题 + 禅道绑定 → 表格编辑 → 导出 XLSX │
└─────────────────────────────────────────────────────────┘设计原则 :LLM 只负责 语义内容 (步骤、预期、模块槽位);元数据与格式 由平台配置,避免幻觉污染导入。
三、文档解析:章节树与原文保真
上传 PDF / Word / TXT / Markdown 后,解析器产出 parsed_content:
| 字段 | 含义 |
|---|---|
sections |
章节树(id、title、level、block_ids、image_indices) |
blocks |
正文块,与章节关联 |
image_count |
内嵌图数量 |
原文件进 MinIO (ai-requirements bucket),结构存 DB;支持 reparse-document 换解析规则后重切章节,不丢原文件。
实操建议 :生成前打开章节树,确认「一级模块 / 二级功能」与 PRD 目录一致;错乱时优先换 Word/MD 或重解析,不要硬生成。
四、双模型:Vision 读图 + 文本 LLM 写用例
4.1 为什么必须双模型
| 模型 | 职责 | 不做 |
|---|---|---|
| Vision(qwen-vl 等) | 读流程图、原型、表格截图 → 结构化文字摘要 | 不直接输出完整用例表 |
| 文本 LLM(DeepSeek 等) | 读「章节正文 + 图-N 摘要」→ JSON 用例数组 | 不读二进制图 |
纯文本模型对 PDF 内图片 无能为力 ;若范围含图却未配 Vision,Backend 直接 400(避免 silent 漏规则):
python
# test_analysis.py --- _build_scoped_content
if image_count > 0 and not vision_config_id:
raise HTTPException(
status_code=400,
detail=f"选中范围包含 {image_count} 张图片,请选择 Vision 模型配置",
)4.2 正文与读图如何合并
Vision 逐张分析后,build_interleaved_content 把 正文块 与 [图-N] 读图 JSON 按章节顺序交错拼进 Prompt。文本 LLM 看到的是「可引用的图内控件名、提示文案、布局」,而不是附件。
4.3 源码视角:scope 裁剪
python
selected_sections = resolve_sections(all_sections, scope_section_ids)
scoped_content = build_interleaved_content(blocks, selected_sections, vision_text_by_index)
scoped_content, _ = truncate_scope_text(scoped_content) # 上限约 48000 字
scope_est = estimate_scope(scoped_content, image_count)
if scope_est["level"] == "block":
raise HTTPException(status_code=400, detail=scope_est["message"] + ";请减少勾选的章节后重试")产品含义:用户勾选 1~2 章试跑 = 只把选中段落送进 LLM,Token 可控。
五、Token 预估:ok / warn / block
estimate_scope(core/requirement_document.py)粗算输入 Token:
python
est_tokens = int(chars / 1.6) + image_count * 600
# warn ≥ 12_000 tokens → level "warn"
# block ≥ 28_000 tokens → level "block",禁止同步生成| level | 含义 | 建议 |
|---|---|---|
| ok | 可一次生成 | 直接点生成 |
| warn | 章节偏多 | 缩小范围或降低目标条数 |
| block | 接近上限 | 减少勾选章节,或走 异步分批 Job |
大批量时创建 AiRequirementGenerateJob ,前端轮询 status/progress;任务可取消,比 AI大模型 粘贴「整份 Word 超时重来」可运维得多。
六、Prompt 工程:LLM 输出什么
场景模板 requirement_doc_to_cases (core/ai_prompts.py)对输出做了硬约束,核心包括:
6.1 语义槽位(LLM 输出),禁止直接拼标题
json
{
"main_module": "订单",
"sub_module": "创建",
"feature_point": "提交订单",
"case_description": "正常提交成功",
"precondition": "环境:测试站可访问\n角色:已登录\n数据:购物车已有商品",
"steps": [
{"step": "点击\"提交订单\"按钮", "expect": "Toast 显示\"下单成功\""}
],
"priority": "2",
"test_design": "正向流程",
"type": "功能测试"
}Prompt 明确要求:
- 禁止 输出
title字段;禁止 自行拼接【#...】完整标题 - 禁止 空洞表述:「执行操作」「符合预期」「功能正常」
- steps 须一步一
expect;交互流程通常 2~4 步,只读展示可 1 步 - grounding :文件大小、配额、错误提示等 必须与 PRD 一致,未写明则标「(需求待确认)」
- 含 图-N 时:至少约 30% 用例应引用图内的 ui_elements / exact_messages
6.2 测试设计维度配比(写入 test_design,不是 type)
| test_design | 建议占比 |
|---|---|
| 正向流程 | 35%~45% |
| 异常/反向 | 30%~40% |
| 边界值 | 15%~25% |
| 接口校验 | 范围内出现 API 描述时 |
type 走禅道「用例类型」枚举(功能测试、接口测试等),与 test_design 分离,避免把「正向/异常」写进 type 字段。
七、标题 Jinja2 + 禅道字段:平台注入
7.1 标题组装(入库前)
项目级模板(core/case_naming.py),默认示例:
text
【#{{ story_no }}_{{ main_module }}_{{ sub_module }}】({{ feature_point }}){{ case_description }}LLM 只填槽位 → Jinja2Template.render(**slots) → _clean_rendered_title。换项目规范 只改模板,不重训模型。
7.2 禅道字段:不进 Prompt
| 字段 | 来源 |
|---|---|
| product | 项目「禅道绑定」 |
| module(路径) | 项目绑定 + 需求级 export_defaults 覆盖 |
| related_story | 绑定配置 |
| stage | 按 priority 映射冒烟/系统阶段(resolve_stage) |
python
# zentao_bindings.py --- merge_bindings
# 需求级非空字段覆盖项目级
for key in ("product", "module", "related_story", ...):
if req.get(key):
merged[key] = req[key]LLM 只写步骤、预期、前置条件 ;导出 XLSX 时 apply_bindings_to_case_fields 写入禅道列,导入失败率显著下降。
八、全量生成 vs 补充生成
| 模式 | 参数 | 行为 |
|---|---|---|
| 全量/替换 | replace_existing=true |
清空旧草稿再生成(慎用) |
| 默认追加 | replace_existing=false |
新批次追加,不删旧用例 |
| 补充生成 | supplement_batch_name |
带已有用例摘要进 Prompt 去重,专补缺口章节 |
补充生成时 Prompt 会带上同批次已有用例摘要,减少 feature_point 重复;仍须人工删明显幻觉行。
批次名 batch_name 写入 source_ref=batch:名称,便于按章节筛选「哪次生成」的用例。
九、实操步骤(10 步 + 审查清单)
9.1 操作步骤
- AI 测试 → 需求测试中心,新建需求
- 上传 PRD(PDF / Word / TXT / Markdown)
- 等待解析,检查 章节树 与目录是否一致
- 项目配置 :禅道绑定、用例 标题模板(可先预览一条)
- 勾选本次 scope 章节 (大文档先 1~2 章 +
estimate-scope看 ok/warn) - 场景绑定 :Vision(有图必填)+
requirement_case文本模型 - 设置目标条数(通常 10~20/批),点击生成
- 表格审查:步骤是否 有具体对象+动作 ,预期是否 可判定
- 未覆盖章节 → 补充生成(勿一次 block 硬跑全文)
- 导出禅道 XLSX → 禅道导入验证
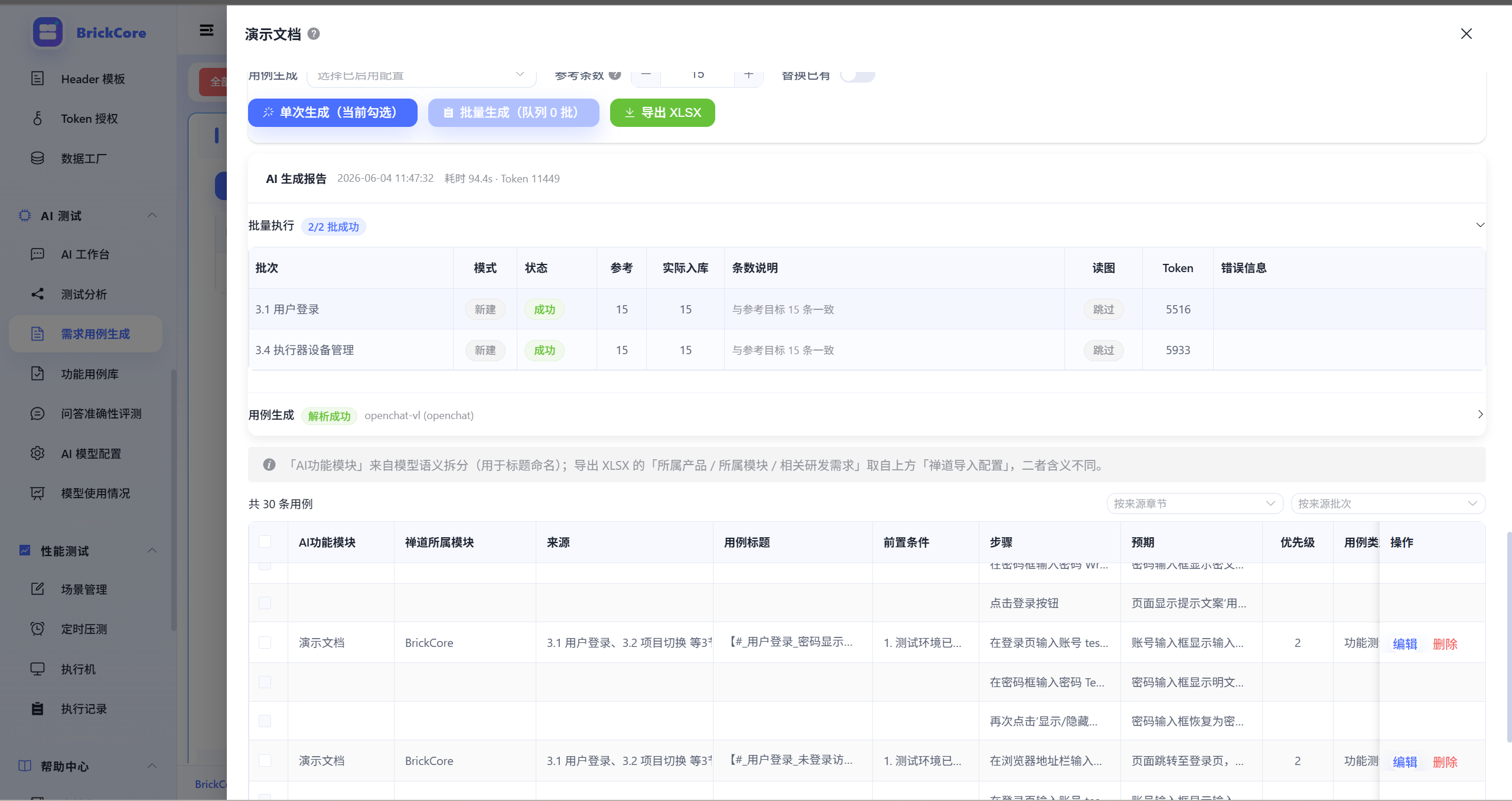
9.2 人工审查清单(导出前必过)
| 检查项 | 不合格示例 |
|---|---|
| 前置条件三段式 | 只有「已登录」无环境/数据 |
| 每步有 expect | step 写 3 步,expect 只有一句 |
| 数值与 PRD 一致 | 编造「最多 999 条」但 PRD 写 100 |
| 图内规则已覆盖 | 流程图有「超限提示」但无用例 |
| 标题无重复 feature_point | 同批 5 条「正常提交成功」 |
| 优先级合理 | 全 P1 或全 P4 |
原则 :AI 出 80% 草稿 ,测试负责人对 业务规则与边界 做最终签字。
十、常见失败排错
| 现象 | 原因 | 处理 |
|---|---|---|
| 生成按钮灰 / block | scope Token ≥ 28k 预估 | 减章节;异步分批 Job |
| warn 仍要跑 | 12k~28k | 降 count 或再缩 scope |
| 400 请选择 Vision | 范围内有图未选 Vision 配置 | 平台配置 → 场景绑定 |
| 章节树空/乱 | PDF 解析差 | 换 Word/MD;reparse-document |
| 禅道导入字段错 | 未配绑定 | 项目 + 需求级 export_defaults |
| 标题重复/不规范 | 模板未配或 LLM 槽位撞车 | 改 Jinja2;补充生成带去重 |
| 步骤空洞 | 模型弱或 scope 太短 | 换更强文本模型;加 extra_instructions |
| 图内规则仍漏 | Vision 弱或图模糊 | 换 Vision;关键图手工补 2~3 条 |
十一、给测开 / 后端:落地要点
| 要点 | 说明 |
|---|---|
| 原文件与结构分离 | MinIO 存 PRD,DB 存 document_structure JSON |
| scope 是一等公民 | 所有生成 API 带 scope_section_ids |
| 双模型边界清晰 | Vision 只产文字描述,文本 LLM 不读二进制 |
| 元数据不进 Prompt | 禅道 product/module/story 绑定注入 |
| 标题与内容解耦 | Jinja2 + 槽位,Prompt 禁止 output title |
| 任务化 | AiRequirementGenerateJob 支持取消、进度、分批 |
| 权限隔离 | 需求按 project_id,避免跨项目 PRD 泄露 |
十二、小结
- Vision + 文本 双模型,解决 PRD 图文混排 漏读。
- 章节 scope + estimate_scope 控制 Token,block 时 分批 Job 而非硬塞。
- Prompt grounding 约束步骤/预期质量;平台管标题与禅道字段。
- 补充生成 补缺口,全量替换慎用。
- 导出前走 审查清单 ,AI 是辅助,业务准确性人把关。
附录 A:源码文件索引
| 顺序 | 文件 | 关注点 |
|---|---|---|
| 1 | routers/ai/requirements.py |
上传、generate-cases、导出、Job |
| 2 | routers/ai/test_analysis.py |
_build_scoped_content、测试点/方案 |
| 3 | core/requirement_document.py |
estimate_scope、章节解析 |
| 4 | core/ai_prompts.py |
requirement_doc_to_cases 模板 |
| 5 | core/case_naming.py |
Jinja2 标题、render_case_title |
| 6 | core/zentao_bindings.py |
绑定合并、resolve_stage |
| 7 | core/zentao_case_export.py |
禅道 XLSX 导出 |
支持与交流
- 演示:http://43.142.83.156/showcase/ · 源码:https://gitee.com/BanZhuanKeOrz/BrickCore
- 觉得有用欢迎 Star ⭐,问题评论区留言或 Gitee Issues