【C/C++】从 DPDK 收包到用户态 TCP/IP 协议栈:一个 ustack 示例拆解
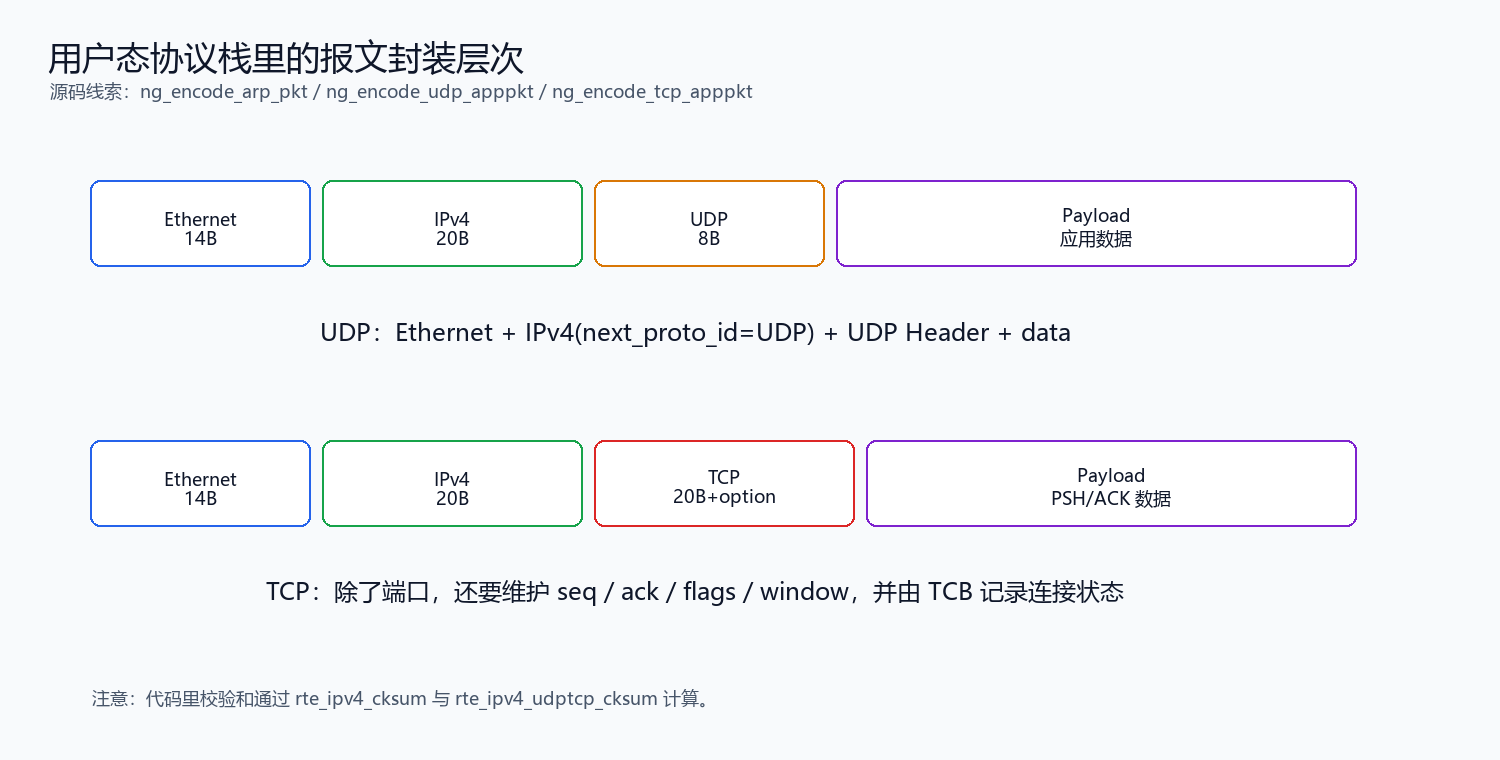
1. 先把边界说清楚:DPDK 不是协议栈
Linux 内核网络路径大致是:
text
电信号 -> 网卡 -> 网卡驱动 -> TCP/IP 协议栈 -> POSIX API -> APPDPDK 做的事情,是让应用绕过内核协议栈,直接从网卡收发包。它更像"高速收包/发包工具箱",不是完整 TCP/IP 协议栈。真正的以太网、ARP、IP、UDP、TCP 解析和 socket 语义,仍然要由用户态程序自己实现。
这个 ustack 示例的分层可以理解成:
text
网卡队列 -> DPDK PMD -> rte_mbuf -> ring -> 协议解析 -> UDP/TCP/KNI -> 应用 API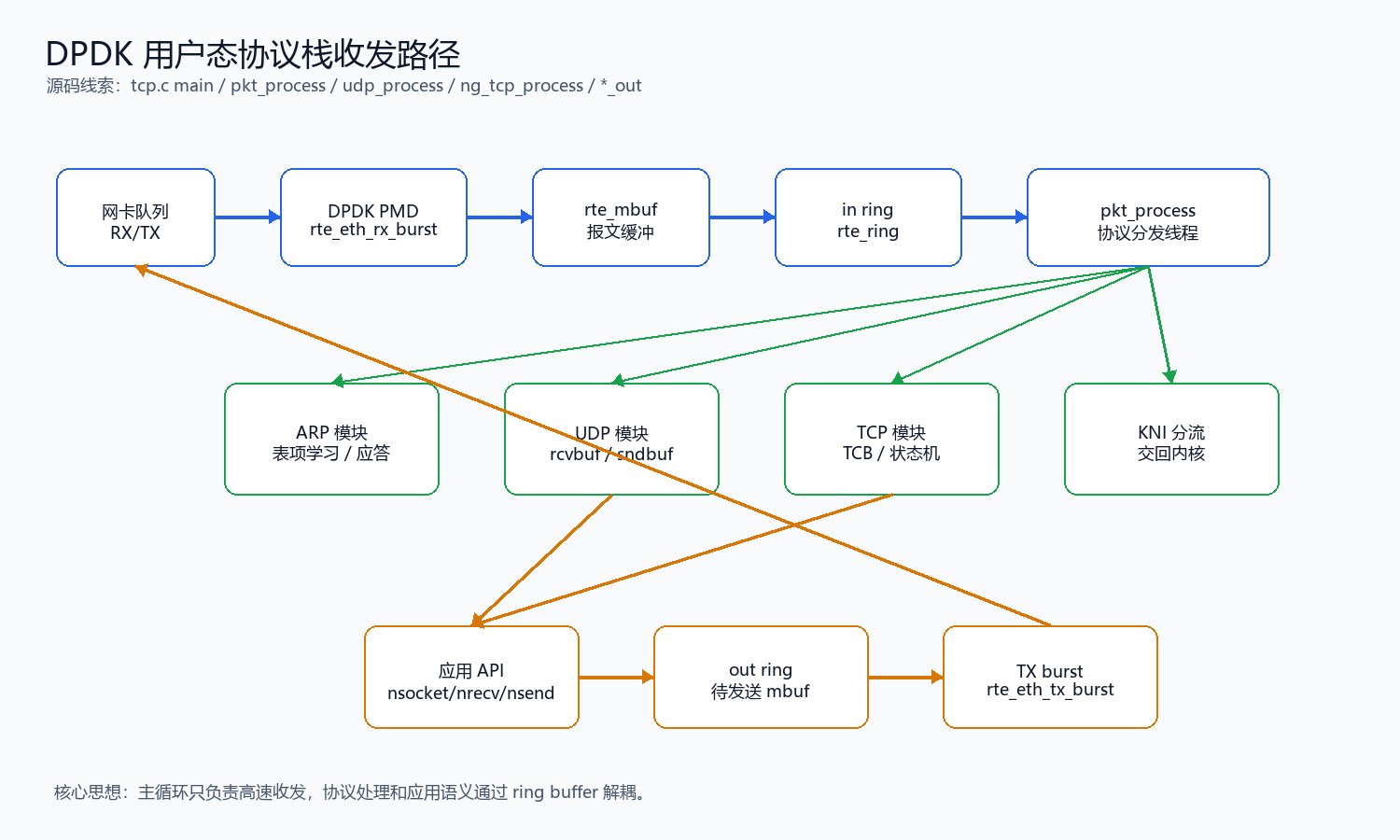
2. DPDK 初始化:EAL、mempool、网卡队列
用户态协议栈启动时,第一步不是 socket(),而是初始化 DPDK 的运行环境和 mbuf 内存池。
代码片段来自 ustack-main/tcp.c:
c
if (rte_eal_init(argc, argv) < 0) {
rte_exit(EXIT_FAILURE, "Error with EAL init\n");
}
struct rte_mempool *mbuf_pool = rte_pktmbuf_pool_create("mbuf pool", NUM_MBUFS,
0, 0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());
if (mbuf_pool == NULL) {
rte_exit(EXIT_FAILURE, "Could not create mbuf pool\n");
}这里的 rte_mbuf 可以类比内核协议栈里的 sk_buff:它不是单纯的数据指针,而是"报文数据 + 元信息"的载体。DPDK 收到包后,应用拿到的不是裸字节数组,而是一个个 struct rte_mbuf *。
网卡端口初始化的核心逻辑如下:
c
static void ng_init_port(struct rte_mempool *mbuf_pool) {
uint16_t nb_sys_ports = rte_eth_dev_count_avail();
if (nb_sys_ports == 0) {
rte_exit(EXIT_FAILURE, "No Supported eth found\n");
}
const int num_rx_queues = 1;
const int num_tx_queues = 1;
struct rte_eth_conf port_conf = port_conf_default;
rte_eth_dev_configure(gDpdkPortId, num_rx_queues, num_tx_queues, &port_conf);
rte_eth_rx_queue_setup(gDpdkPortId, 0, 1024,
rte_eth_dev_socket_id(gDpdkPortId), NULL, mbuf_pool);
rte_eth_tx_queue_setup(gDpdkPortId, 0, 1024,
rte_eth_dev_socket_id(gDpdkPortId), &txq_conf);
rte_eth_dev_start(gDpdkPortId);
}这段代码做了三件关键事:
- 检查当前系统是否有 DPDK 可用网卡。
- 配置 1 个 RX 队列和 1 个 TX 队列。
- 把 RX 队列挂到前面创建的
mbuf_pool上。
如果要把性能扩展到多核,后面通常会改成多 RX/TX 队列,让不同 lcore 轮询不同队列。这也是为什么虚拟机环境里经常建议使用 vmxnet3 这类更适合多队列的虚拟网卡。
3. 主循环:网卡收包进 in ring,out ring 再发回网卡
示例代码没有把所有逻辑都堆在主循环里,而是用两个 ring 做解耦:
ring->in:主循环从网卡收到包后塞进去。ring->out:协议栈或应用构造好回包后塞进去。pkt_process:另一个 lcore 从in ring拿包,做协议分发。
主循环代码节选:
c
while (1) {
struct rte_mbuf *rx[BURST_SIZE];
unsigned num_recvd = rte_eth_rx_burst(gDpdkPortId, 0, rx, BURST_SIZE);
if (num_recvd > 0) {
rte_ring_sp_enqueue_burst(ring->in, (void **)rx, num_recvd, NULL);
}
struct rte_mbuf *tx[BURST_SIZE];
unsigned nb_tx = rte_ring_sc_dequeue_burst(ring->out, (void **)tx, BURST_SIZE, NULL);
if (nb_tx > 0) {
rte_eth_tx_burst(gDpdkPortId, 0, tx, nb_tx);
for (unsigned i = 0; i < nb_tx; i++) {
rte_pktmbuf_free(tx[i]);
}
}
}这个结构很适合教学:主循环只管高速搬运,协议处理线程只管理解报文。后续要做 DDOS 检测、ACL、防火墙、用户态 TCP,都可以挂在中间的协议处理层。
4. 协议分发:Ethernet -> IPv4 -> UDP/TCP/KNI
pkt_process() 是用户态协议栈真正开始"像协议栈一样工作"的地方。
代码节选:
c
static int pkt_process(void *arg) {
struct rte_mempool *mbuf_pool = (struct rte_mempool *)arg;
struct inout_ring *ring = ringInstance();
while (1) {
struct rte_mbuf *mbufs[BURST_SIZE];
unsigned num_recvd = rte_ring_mc_dequeue_burst(
ring->in, (void **)mbufs, BURST_SIZE, NULL);
for (unsigned i = 0; i < num_recvd; i++) {
struct rte_ether_hdr *ehdr =
rte_pktmbuf_mtod(mbufs[i], struct rte_ether_hdr *);
if (ehdr->ether_type == rte_cpu_to_be_16(RTE_ETHER_TYPE_IPV4)) {
struct rte_ipv4_hdr *iphdr = rte_pktmbuf_mtod_offset(
mbufs[i], struct rte_ipv4_hdr *, sizeof(struct rte_ether_hdr));
ng_arp_entry_insert(iphdr->src_addr, ehdr->s_addr.addr_bytes);
if (iphdr->next_proto_id == IPPROTO_UDP) {
udp_process(mbufs[i]);
} else if (iphdr->next_proto_id == IPPROTO_TCP) {
ng_tcp_process(mbufs[i]);
} else {
rte_kni_tx_burst(global_kni, mbufs, num_recvd);
}
}
}
udp_out(mbuf_pool);
ng_tcp_out(mbuf_pool);
}
}这段逻辑很直观:
- 先看二层
ether_type,只处理 IPv4。 - 取出三层
rte_ipv4_hdr。 - 顺手把源 IP 和源 MAC 写入 ARP 表。
- 根据
next_proto_id分发到 UDP 或 TCP。 - 不认识的包交给 KNI,让内核继续处理。
KNI 这一层在教学里很有价值:不是所有协议都必须用户态自己写。你可以先实现 UDP/TCP 主路径,不关心的报文交回内核,降低调试难度。
5. UDP 入应用缓冲:从报文变成 recv 能读的数据
UDP 的接收路径体现了"协议栈"和"应用 API"之间的分界。
代码节选:
c
static int udp_process(struct rte_mbuf *udpmbuf) {
struct rte_ipv4_hdr *iphdr = rte_pktmbuf_mtod_offset(
udpmbuf, struct rte_ipv4_hdr *, sizeof(struct rte_ether_hdr));
struct rte_udp_hdr *udphdr = (struct rte_udp_hdr *)(iphdr + 1);
struct localhost *host = get_hostinfo_fromip_port(
iphdr->dst_addr, udphdr->dst_port, iphdr->next_proto_id);
if (host == NULL) {
rte_pktmbuf_free(udpmbuf);
return -3;
}
struct offload *ol = rte_malloc("offload", sizeof(struct offload), 0);
ol->dip = iphdr->dst_addr;
ol->sip = iphdr->src_addr;
ol->sport = udphdr->src_port;
ol->dport = udphdr->dst_port;
ol->protocol = IPPROTO_UDP;
ol->length = ntohs(udphdr->dgram_len);
ol->data = rte_malloc("unsigned char*",
ol->length - sizeof(struct rte_udp_hdr), 0);
rte_memcpy(ol->data, (unsigned char *)(udphdr + 1),
ol->length - sizeof(struct rte_udp_hdr));
rte_ring_mp_enqueue(host->rcvbuf, ol);
pthread_mutex_lock(&host->mutex);
pthread_cond_signal(&host->cond);
pthread_mutex_unlock(&host->mutex);
rte_pktmbuf_free(udpmbuf);
return 0;
}这里发生了一次语义转换:
text
rte_mbuf 中的完整以太网帧
-> 提取 IPv4/UDP 头
-> 找到绑定了目标 IP/端口的 localhost
-> 拷贝 payload 到 offload
-> 放入 host->rcvbuf
-> 唤醒正在 nrecvfrom 等待的应用线程这就是用户态协议栈实现 recvfrom() 的基础。应用看到的是"某个 socket 收到了数据",协议栈内部看到的是"某个 UDP 报文被解析并投递到对应接收队列"。
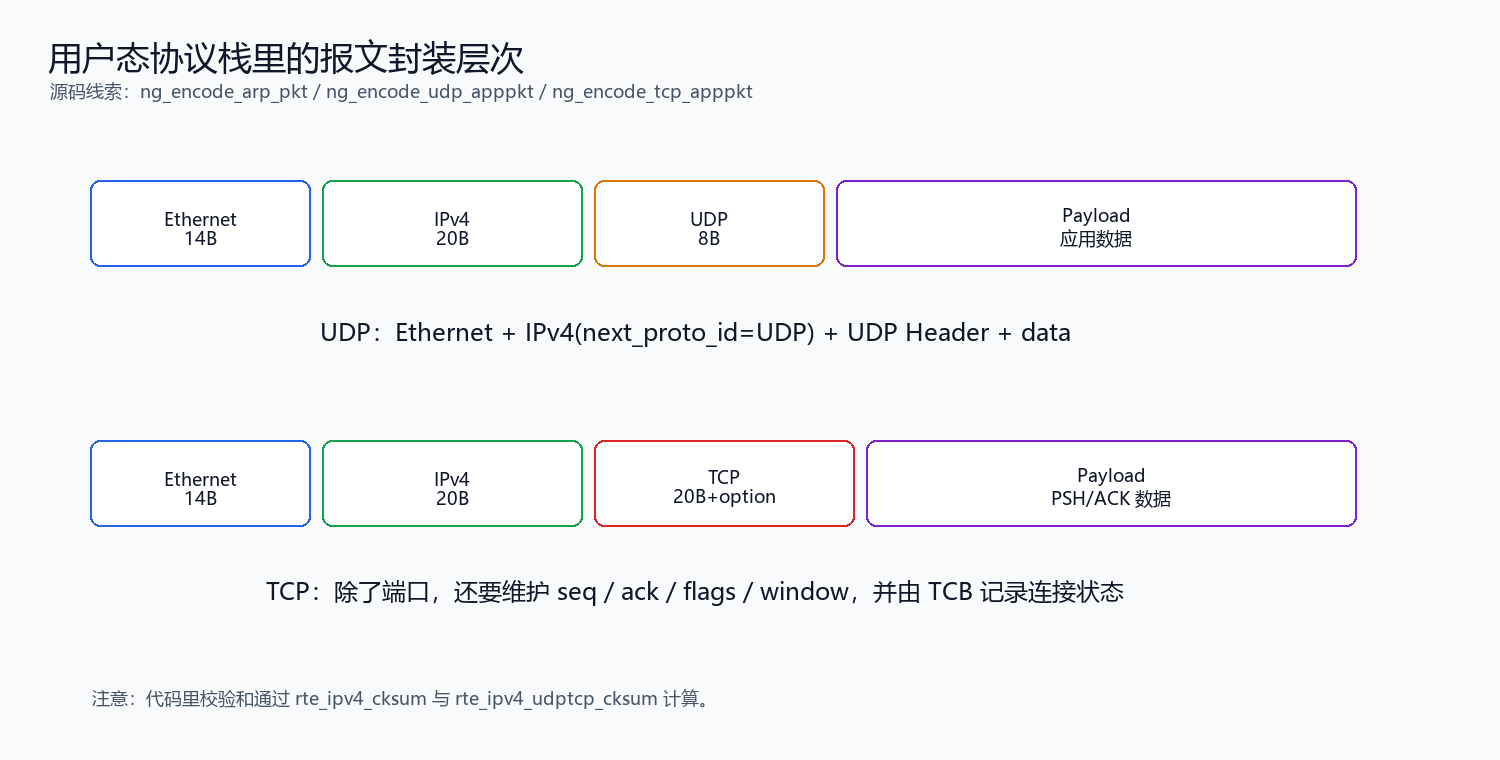
6. TCP 更复杂:它不只是多了一个头
UDP 只要找到端口,把 payload 投递到接收队列即可。TCP 不一样,TCP 要维护连接状态:
LISTENSYN_RCVDESTABLISHEDCLOSE_WAITLAST_ACK
示例代码里用 struct ng_tcp_stream 作为 TCB:
c
struct ng_tcp_stream {
int fd;
uint32_t dip;
uint16_t dport;
uint16_t sport;
uint32_t sip;
uint32_t snd_nxt;
uint32_t rcv_nxt;
NG_TCP_STATUS status;
struct rte_ring *sndbuf;
struct rte_ring *rcvbuf;
pthread_cond_t cond;
pthread_mutex_t mutex;
};这里最重要的不是字段多少,而是含义:
sip/dip/sport/dport确定一条连接。snd_nxt/rcv_nxt维护序列号和确认号。status决定当前收到 SYN、ACK、PSH、FIN 时该怎么处理。sndbuf/rcvbuf把协议栈线程和应用线程隔离开。
所以实现 TCP 的难点不在"能不能读出 TCP header",而在状态机、重传、窗口、乱序、拥塞控制等一整套行为。这个示例先实现了教学主干,适合用来理解 TCP 协议栈的骨架。
7. VMware + DPDK 环境几个实战注意点
结合目录里的笔记,实验环境最容易卡在这些地方:
bash
# 查看网卡和队列/中断线索
ip -br link
cat /proc/interrupts | grep ens
# DPDK 19.08.2 常见环境变量
export RTE_SDK=/root/dpdk-stable-19.08.2/
export RTE_TARGET=x86_64-native-linux-gcc
# 编译老版本 DPDK 时,新的 GCC 可能需要
make EXTRA_CFLAGS="-fcommon" -j$(nproc)虚拟机网络模式建议:
- 桥接:虚拟机和物理网络同网段,但桥接 WLAN 时二层帧不一定稳定。
- NAT:适合上网,不一定适合从主机直接构造二层包打进 DPDK。
- Host-only:主机和 VM 在同一个干净的虚拟二层网络里,配静态 ARP 后更适合先跑通实验。
Windows 主机添加静态 ARP 的例子:
powershell
netsh interface ipv4 add neighbors 10 192.168.0.7 00-0C-29-5A-7A-0F如果使用 VFIO,而 VMware 没暴露 IOMMU,可以临时打开 no-IOMMU 模式做实验:
bash
sudo modprobe vfio
echo 1 | sudo tee /sys/module/vfio/parameters/enable_unsafe_noiommu_mode
sudo modprobe vfio-pci这只建议在实验环境里使用。生产环境绕过 IOMMU 的安全隔离是不合适的。
8. 总结
这个 ustack 示例最值得看的地方,是它把用户态协议栈拆成了几层很清楚的结构:
text
DPDK 收发包
-> rte_mbuf 承载报文
-> ring buffer 解耦线程
-> Ethernet/IP/ARP/UDP/TCP 解析
-> rcvbuf/sndbuf 承接应用 API
-> KNI 兜底交回内核写用户态协议栈时,DPDK 解决的是高速 I/O,真正决定系统行为的是协议栈本身:ARP 表怎么维护,UDP 怎么投递,TCP 状态机怎么推进,应用线程怎么被唤醒。把这些边界分清楚,后面再看 mTCP、F-Stack、VPP、lwIP,就不会只停留在"绕过内核很快"这一句口号上。