随着视觉AI算法和工业摄像头的成熟,用AI替代或辅助人工质检已经不再是"能不能"的问题,而是"怎么做才稳定、怎么做才划算"的问题。但在大量制造企业实际推进的过程中,"模型没人会训"、"数据没人会标"、"系统没人会维护"三座大山让很多项目卡在概念验证阶段,无法真正落地到产线。
DLTM企业级AI模型工作站的出现,正是为了打通这条"最后一公里"。本文将围绕工业质检的真实业务场景,剖析制造业的四大典型痛点,并给出一套基于企业AI算力工作站DLTM的端到端落地方案。
一、工业质检的四大典型痛点
1、人工成本高,招工越来越难
某汽车零部件厂商的注塑车间,质检岗位近三年的人员流失率超过60%。愿意在强光、噪声、机油气味中持续盯产线的年轻人越来越少。即便用高薪勉强留住人,单工位的年人力成本也已经突破10万元。
2、漏检误检率难以下降
人眼的分辨力在持续工作2小时后会出现明显衰减。有数据显示,熟练工在前2小时与后2小时的漏检率差距可达30%以上。对于表面缺陷、细微裂纹、装配错位等"非典型"问题,漏检带来的返修成本、客退成本、召回风险更是数倍于质检本身的成本。
3、 传统视觉方案成本高、周期长
引入一套传统的工业视觉检测系统,从需求评估、定制开发、现场调试到验收交付,往往需要3-6个月,单条产线投资动辄几十万元。中小制造企业很难承受这种"重资产、长周期"的模式。
总结:不是企业不想上AI,而是传统的"项目制"AI落地路径门槛太高、风险太大。
二、企业AI算力工作站DLTM的工业质检落地四步法
企业AI算力工作站DLTM的设计哲学是"让不懂算法的工程师也能用AI"。在工业质检场景下,我们把整个落地过程抽象为数据---训练---部署---运维四个标准步骤。
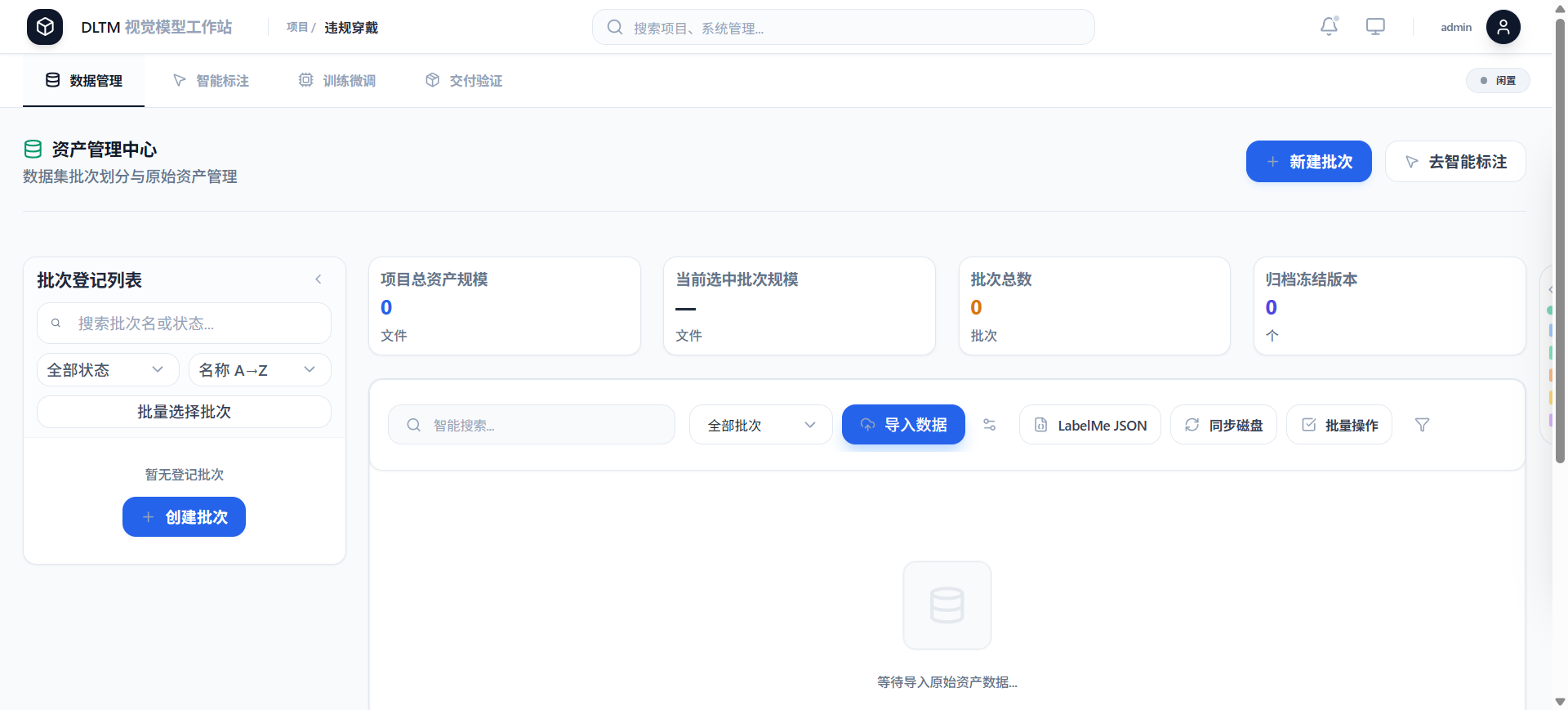
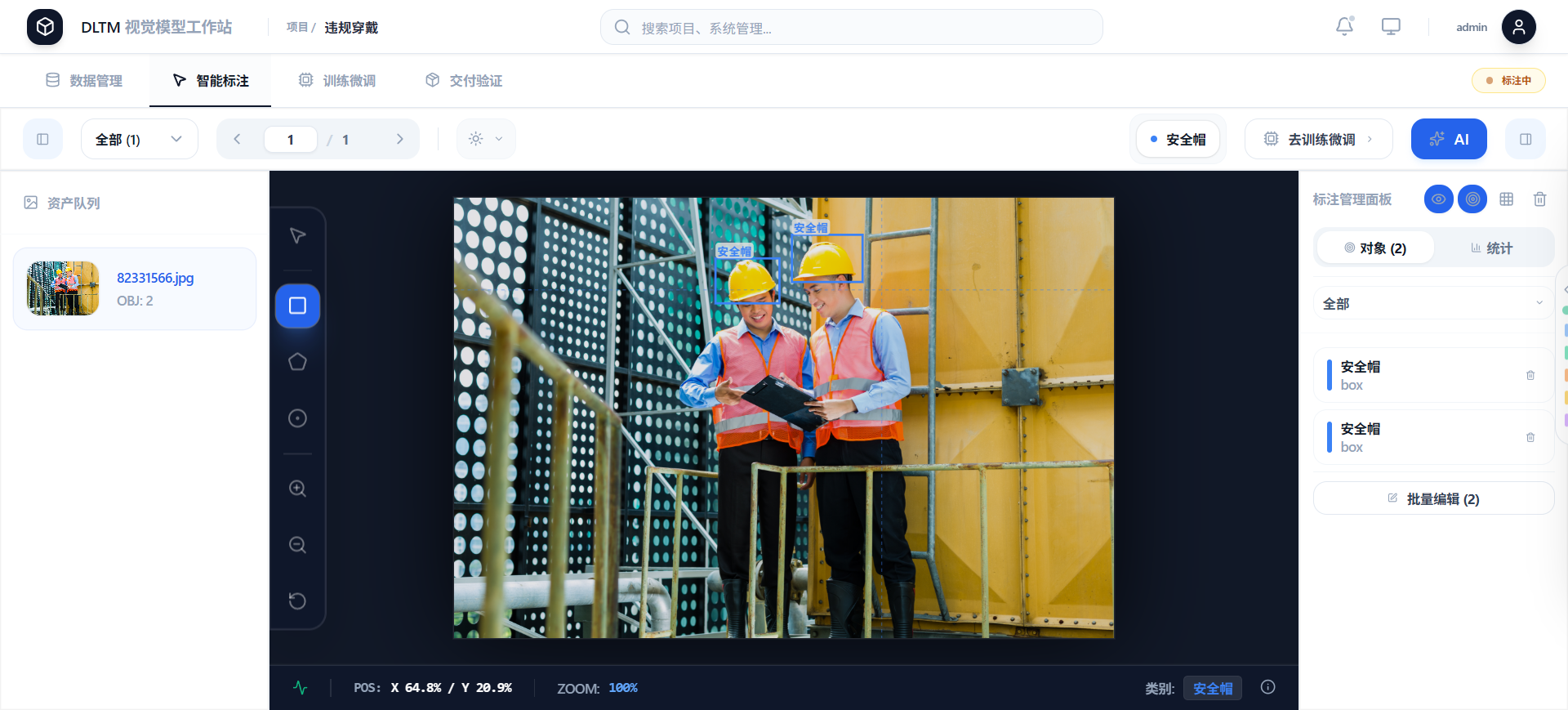
1、第一步:数据采集与智能标注
在企业AI算力工作站DLTM中,数据上传支持单张/批量/文件夹多种方式,单条产线的历史图片可以在1-2小时内完成入库。
标注环节是真正的"AI赋能"亮点:
AI预标注:企业AI算力工作站DLTM内置的预训练模型可以自动框出疑似缺陷区域,标注员只需要做"确认/修正"操作。
半监督学习:对于大量未标注的负样本,企业AI算力工作站DLTM可以通过置信度自动挑选高价值样本反哺训练。
协同标注:支持多人协作、权限分级、版本管理,避免"一个人在A电脑上标了一半,换电脑就找不到"的问题。
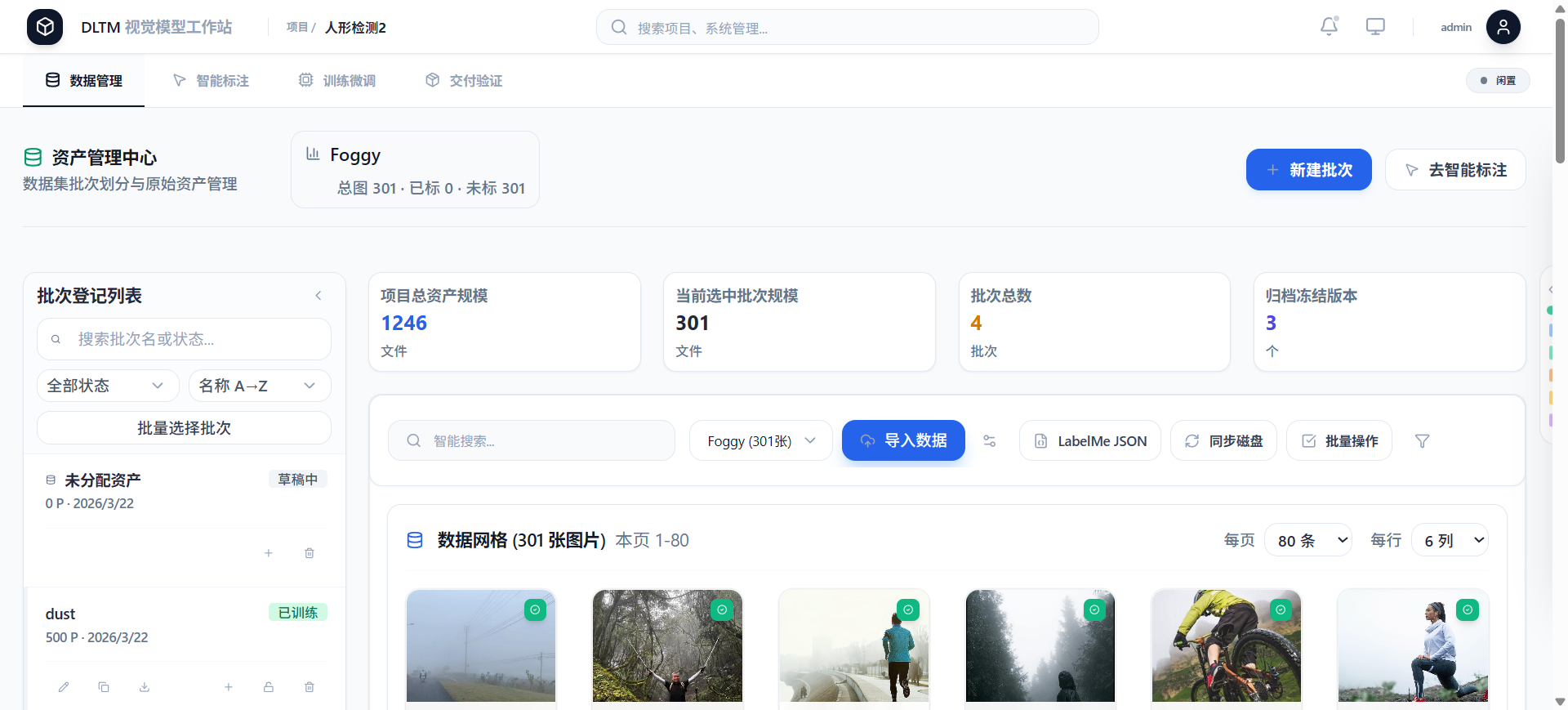
2、第二步:零代码训练
企业AI算力工作站DLTM把训练过程做成"配置式"操作:
-
选择任务类型(分类/检测/分割)
-
选择预训练基座
-
选择数据集
-
配置训练参数
-
一键启动训练
整个过程完全在Web界面上完成,不需要写一行代码,也不需要去终端敲命令行。
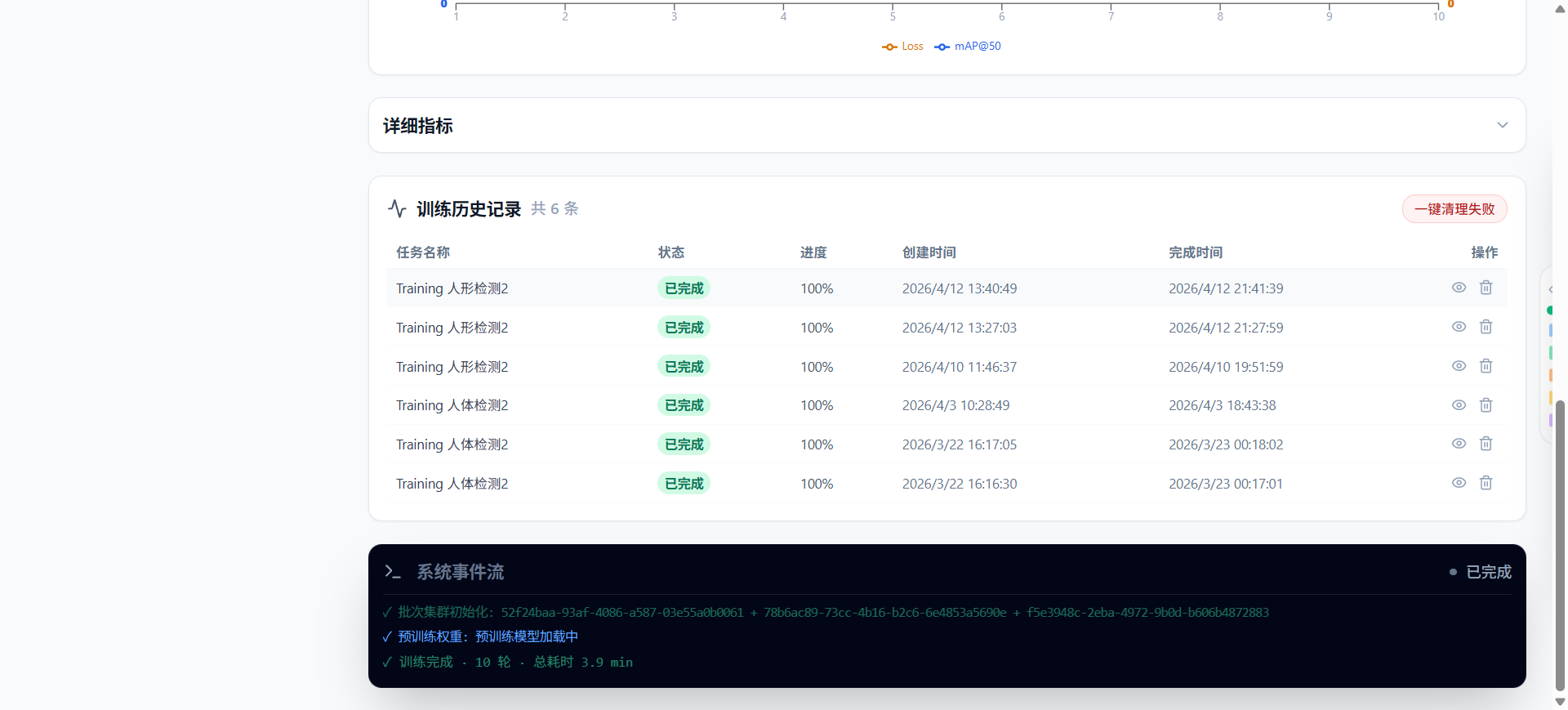
3、第三步:模型评估与版本管理
训练完成的模型,企业AI算力工作站DLTM会自动给出多维度的评估报告:
-
精确率、召回率
-
混淆矩阵(哪个类容易被误判为另一个类)
-
PR曲线、Loss曲线
-
推理速度(单张图片在CPU/GPU上的耗时)
4、第四步:一键部署到产线
企业AI算力工作站DLTM的部署方式非常灵活:
本地服务:模型直接部署在工厂内网,PLC通过RESTful API触发推理
边缘设备:支持GPU工控机、系列边缘盒
WebSocket实时推送:相机推流,模型实时返回结果
与企业系统对接:可对接 MES、ERP等自动写入检测结果、触发不良品剔除
整个接口通过120+项企业级API稳定性测试,可以应对产线7×24小时连续工作的严苛要求。
三、典型案例:3C 产品外观缺陷检测
1、业务背景
某3C产品组装企业,主要生产手机中框,需要检测:
-
表面划痕
-
凹坑/麻点
-
异色点
-
装配错位
2、实施方案
数据采集:4个工位×2000张正样本+1500张负样本
数据标注: AI辅助标注
模型训练:YOLO基座,迁移学习
现场联调:工业相机对接,光源适配
试运行:与MES对接,跑通数据闭环
四、结语
工业质检的AI化,本质上是一次"把老师傅经验数字化"的过程。它的难点不在算法,而在"能不能让现场工程师自己玩得转"。企业AI算力工作站DLTM提供的"零代码训练+一键部署+持续迭代"完整闭环,正是为了让AI真正走出实验室、走进车间。