前端人的 AI 入门不必学 Python------用你最熟的 JS,配合 LangChain + DeepSeek + 本地 Embedding,把团队四个项目的私有文档喂进去,搭一个「只懂我们代码」的 AI 助手。
一、起因:天天画页面,迟早被替代?
今年年初,Cursor 能写组件了,GitHub Copilot 能自动补全了,公司领导在会上来了一句:"咱们的 GitLab MR 能不能用 AI 自动审查?"
会后我坐在工位上想了两件事:
- 页面画得再好,迟早被 AI 吃掉增量市场。
- 但 AI 落地的最后一公里------渲染 UI、打字机效果、流式传输、接到 DevOps 管道------全是我们前端的活。
于是我决定:不卷下一个前端框架了,用我最熟的 JavaScript,给团队搭一个能读懂我们四个项目私有文档的 AI 助手。
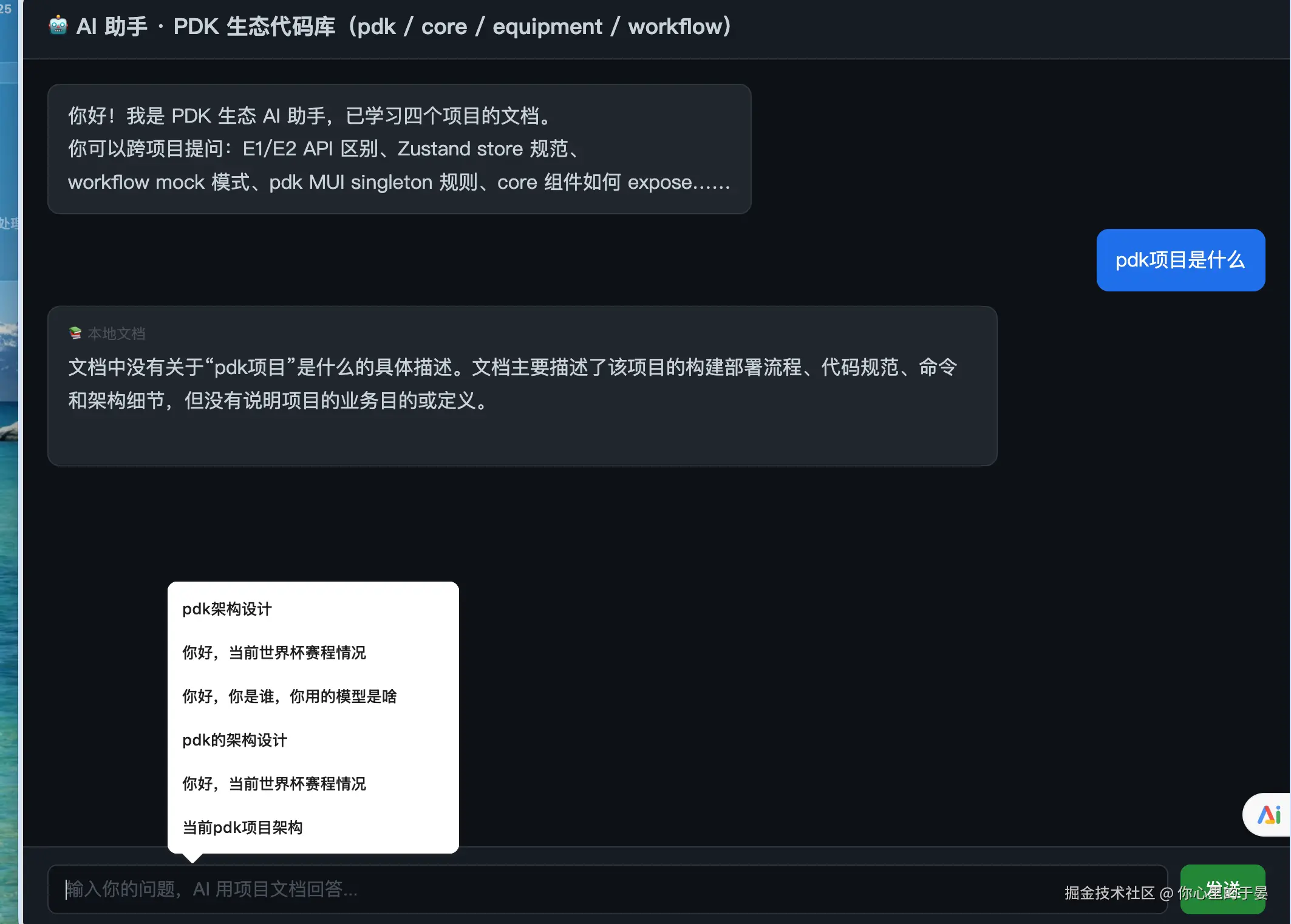
二、先看效果(比你想象的简单)
一个下午,npm install + 几段代码,跑出来的效果:
📚 本地知识库模式:
👨💻 问:E1 和 E2 两套 API 有什么区别?
🤖 答(📚 本地文档 · 4 个片段):
维度 E1 (legacy) E2 (new) 前缀 /api/e1/api/e2成功标识 status: 0code: 200Ajax 工厂 Ajax()createE2Ajax()
------这是我项目 AGENTS.md 里的真实约定,ChatGPT 永远答不出。
🌐 联网搜索模式(本地没有的自动切):
👨💻 问:今天深圳天气怎么样?
🤖 答(🌐 联网搜索 · 4 条结果): 深圳今天多云转晴,气温 28-34°C......
------这一步接入了博查 AI 搜索引擎,本地没命中的自动兜底联网。
一整页代码就跑了,不依赖任何外部数据库、向量服务、Python 环境。
三、架构极简:能用一个文件的,绝不多开一个端口
bash
提问 →
│
├─ 识别是本地问题?(含 pdk/core/equipment/workflow 关键词?)
│ ├─ 是 → RAG 检索本地 docs/*.md → LLM 判断片段相关?
│ │ ├─ 相关 → 用本地文档回答
│ │ └─ 不相关 → 联网搜索
│ └─ 否 → 联网搜索
│
└─ 流式输出 + 打字机光标 + Markdown 渲染四个技术栈全在一个 server.js(~270 行)里跑:
| 层 | 技术 | 作用 |
|---|---|---|
| 模型 | DeepSeek(via LangChain) | 理解问题、生成回答 |
| 向量化 | transformers.js + BGE-small-zh | 本地把文档转向量,不调 API 不花钱 |
| RAG | MemoryVectorStore | 内存向量库,检索最相关文档片段 |
| 联网 | 博查 Web Search API | 本地没有的自动联网搜索 |
| 交付 | Node 原生 http + 流式 chunked | 打字机效果 + Markdown 渲染 |
没有 Chroma/Pinecone,没有 Docker,没有 Python 虚拟环境。
四、核心代码拆解(只讲干货)
4.1 本地 Embedding:0 元、0 API、纯 JS
整个系统最硬核也最爽的一环------我用的不是 OpenAI Embedding API,而是一个叫 @huggingface/transformers 的 npm 包,在本地 Node 进程里直接跑 BGE-small-zh 模型:
js
import { pipeline } from '@huggingface/transformers';
const pipe = await pipeline('feature-extraction', 'Xenova/bge-small-zh-v1.5', { dtype: 'fp32' });
const vec = await pipe('E1和E2两套API的区别', { pooling: 'mean', normalize: true });
// vec.data = Float32Array[384] ← 这段文字变成了 384 维向量然后包裹成 LangChain 的 Embeddings 接口:
js
class LocalEmbeddings {
async embedQuery(text) { return Array.from((await this.pipe(text)).data); }
async embedDocuments(texts) { return Promise.all(texts.map(t => this.embedQuery(t))); }
}第一次下载模型 ~100MB,之后秒开。按 1 万次调用算,OpenAI Embedding 大概要几十块钱------而这套方案:零。
⚠️ 踩坑:huggingface.co 在国内被墙。用 hf-mirror.com 镜像解决:
jsimport { env } from '@huggingface/transformers'; env.remoteHost = 'https://hf-mirror.com';
4.2 RAG 完整流程(读文档 → 切块 → 向量化 → 检索 → 喂 LLM)
js
// 1. 读 docs/ 目录下所有 .md 文件
const files = readdirSync('./docs').filter(f => extname(f) === '.md');
const raw = files.map(f => readFileSync(join('./docs', f), 'utf-8')).join('\n\n');
// 2. 切块(500字符一块,80字符重叠)
const splitter = new RecursiveCharacterTextSplitter({ chunkSize: 500, chunkOverlap: 80 });
const docs = await splitter.splitDocuments([new Document({ pageContent: raw })]);
// 3. 向量化 + 存入内存库
const store = await MemoryVectorStore.fromDocuments(docs, new LocalEmbeddings());
// 4. 提问时检索最相关的 4 个块
const hits = await store.similaritySearchWithScore(question, 4);
// 5. 喂给 DeepSeek
const context = hits.map(([doc]) => doc.pageContent).join('\n\n');
const answer = await model.invoke([
{ role: 'system', content: `仅用以下文档回答:\n\n${context}` },
{ role: 'user', content: question }
]);这五步一跑通,你的 AI 助手就能用你们的私有文档回答问题了。 知识库里目前放的是我们团队 pdk/core/equipment/workflow 四个项目的 AGENTS.md,加起来大约 30KB 的文档。
4.3 双路检索:本地优先,LLM 判断兜底,不靠谱的才联网
最开始我省事用向量相似度阈值------topScore > 0.5 就算命中。结果「今天国际原油价格」这种跟代码八竿子打不着的问题,BGE-small 竟然给了个 0.4 的相似度......
换成 LLM 自己判断:
js
const checkChunks = hits.map(([doc]) => doc.pageContent.slice(0, 250)).join('\n---\n');
const check = await model.invoke([
{ role: 'system', content: '严格判断:这些片段能切实回答用户问题吗?不确定就答"不能"。只回能或不能。' },
{ role: 'user', content: `问题: ${q}\n\n片段:\n${checkChunks}` }
]);
if (check.content.includes('能')) {
/* 走本地文档 */
} else {
/* 走博查联网搜索 */
}比向量阈值靠谱十倍。LLM 自己知道「国际原油」和 AGENTS.md 里的代码规范不沾边。
4.4 流式输出 + 打字机光标 + Markdown 渲染
三个细节让体验从"能用"变成"舒服":
js
// 后端:DeepSeek stream
const stream = await model.stream(messages);
res.writeHead(200, { 'Transfer-Encoding': 'chunked' });
res.write(`SOURCE:${source}|${count}\n`);
for await (const chunk of stream) {
if (chunk.content) res.write(chunk.content);
}
res.end();
// 前端:ReadableStream 逐字追加
const reader = res.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
raw += decoder.decode(value, { stream: true });
body.textContent = raw; // 字一个字蹦出来
}
body.innerHTML = marked.parse(raw); // 完成后渲染 Markdown配上 CSS 闪烁光标:
css
@keyframes blink { 0%,100% { opacity: 1 } 50% { opacity: 0 } }
.streaming::after { content: "|"; animation: blink .8s infinite; color: #7ee787; }字一个一个蹦,末尾绿色光标一闪一闪------这就是前端给 AI 加的"人味儿"。
五、踩过的坑(你的时间就是在这省的)
| 坑 | 现象 | 解决办法 |
|---|---|---|
| huggingface 被墙 | transformers.js 下模型超时 | 设 env.remoteHost = 'https://hf-mirror.com' |
| Node v25 undici 不吃 HTTP_PROXY | 代理设了但 fetch 仍直连 | 用镜像代替代理,或 setGlobalDispatcher |
| 向量阈值不可靠 | 不相关问题给高分 | 改用 LLM 判断相关性 |
| DeepSeek key 带引号 | .env 里 KEY='sk-...' → 认证失败 |
不要引号:KEY=sk-... |
| 模板字符串嵌套 | HTML 内的 JS 嵌套 ${} 报错 |
外层用拼接代替模板 |
六、为什么是前端,不是 Python?
因为 AI 落地的最后一公里全是前端的活:
- 打字机效果、Markdown 渲染 → 前端
- 流式数据传输(SSE / chunked transfer)→ 前端
- 把 AI 接进 GitLab CI、飞书 Bot、DevOps → 前端
Python 能调 API、写 RAG、跑模型------但把 AI 变得「丝滑可用」的,是前端。
我的建议:别再去死磕下一个前端轮子了。你已经是 JS 高手,LangChain 有完整的 JS SDK,DeepSeek 有 OpenAI 兼容接口------你只需要一个周末。
七、下一步
这套东西现在跑在我们内部演示里,下一步计划:
- 接 GitLab API,每个 MR 自动拉 diff → RAG 检索项目规范 → AI 出审查报告
- 扩散到飞书 Bot,团队成员 @ 一下就能问
- 把 Swagger JSON 也喂进去,「这个接口返回什么字段?」秒答
源码
需要的自己去ai生成看看
目录结构:
bash
ai-share-demo/
├── server.js # 主程序(~270 行,含全部功能)
├── step1-hello.js # Demo 1: 5 行 JS 调 DeepSeek
├── step2-structured.js # Demo 2: Zod 结构化 JSON 输出
├── step3-rag.js # Demo 3: RAG 独立命令行版
├── docs/ # 知识库文档(放 .md 即涨知识)
│ ├── PDK.md
│ ├── Core.md
│ ├── Equipment.md
│ └── Workflow.md
├── package.json
└── .env.example一键启动:npm run web,浏览器打开 localhost:3456。
如果这篇文章让你觉得「我好像也能做」,那就是我写它的全部意义。前端没有天花板,JavaScript 能做的事比你想的多。
------写于一个用公司真实文档跑通 AI 助手的下午