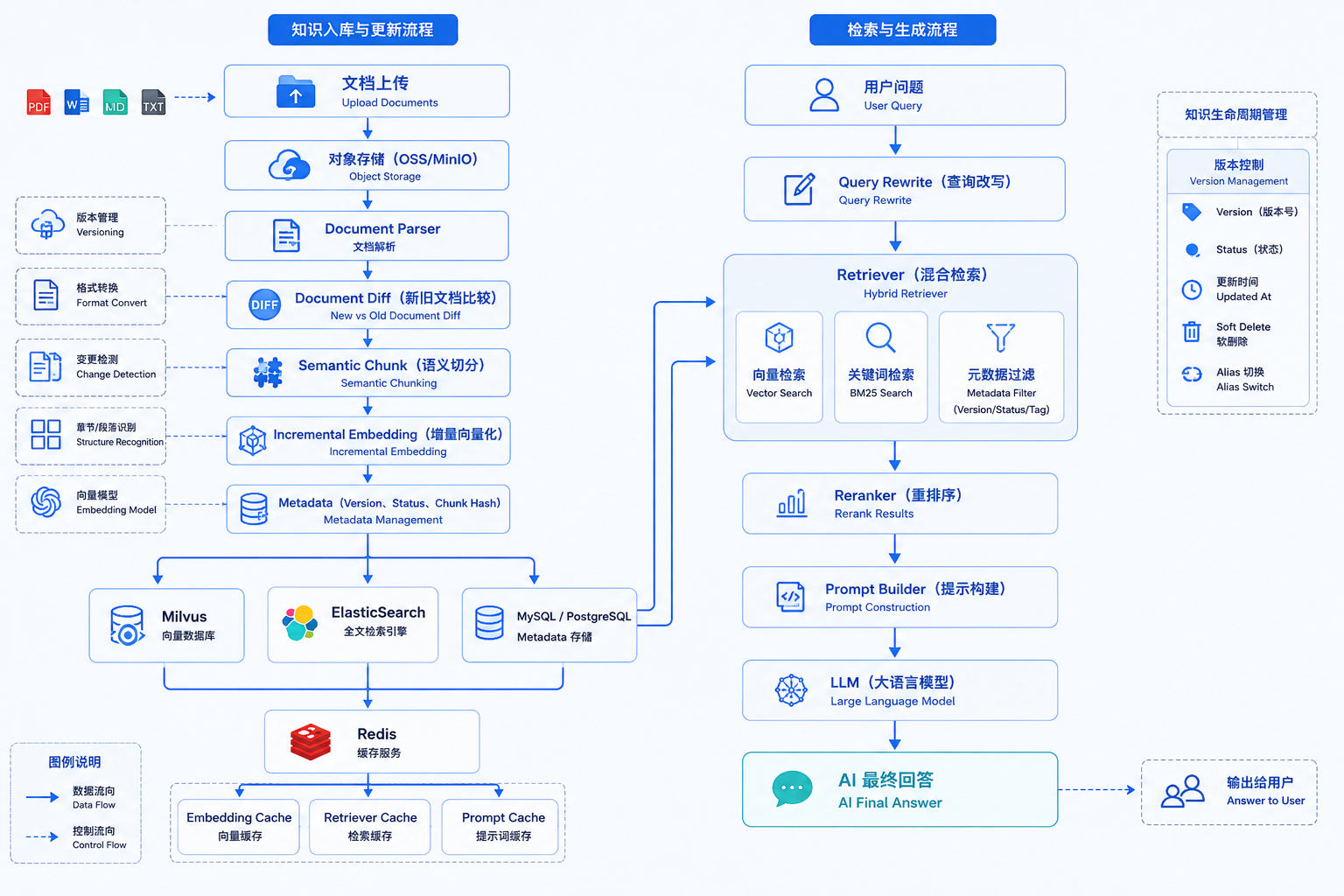
企业级 RAG 知识库更新方案:上传新文档后,如何保证 AI 检索的一定是最新内容?
摘要
很多团队上线 RAG 后都会遇到同一个问题:文档已经更新,但 AI 仍然回答旧内容。真正的问题不是重新生成 Embedding,而是知识生命周期管理、索引一致性、缓存刷新、版本控制和增量更新。
一、为什么会回答旧内容?
典型原因:
- 旧 Chunk 未删除
- Metadata (元数据)无版本号
- 向量库更新成功,ES 未更新
- Redis/Prompt Cache 未失效
- Embedding 异步生成期间发生查询
- Retriever(信息检索) 未过滤 active 版本
二、企业级整体架构
text
上传新文档(documentId)
↓
找到旧版本文档
↓
Document Diff(比较文档差异)
↓
定位修改区域
↓
只重新Chunk修改区域
↓
重新Embedding变化Chunk
↓
更新Metadata
↓
Milvus
↓
刷新Cache
↓
完成三、企业为什么不用全量重建?
假设:
- PDF:1000 页
- Chunk:5000 个
- 修改:2 个 Chunk
全量更新需要重新生成 5000 个 Embedding。
企业通常采用:
text
Old Chunk
│
New Chunk
│
Diff
│
仅重新Embedding变化Chunk
│
更新索引可将计算成本降低 95%~99%。
四、Metadata 设计
json
{
"docId":"employee-handbook",
"version":3,
"status":"active",
"chunkId":"c-1024",
"updateTime":"2026-06-29"
}Retriever 查询必须追加:
sql
status='active'避免旧版本参与召回。
五、缓存刷新策略
- Embedding Cache:更新后删除
- Retriever Cache:按 docId 失效
- Prompt Cache:版本变更立即失效
- Redis:使用版本号作为 Key 前缀
六、企业实践
某医疗知识库每天更新诊疗规范。
最终方案:
- 文档上传
- Kafka 投递任务
- Diff Chunk
- Embedding Worker
- Milvus 更新
- ES 更新
- Alias 切换即蓝绿切换
- Redis Cache Evict
- 通知检索恢复
更新期间采用双索引保证不停机。
七、常见踩坑
| 问题 | 原因 | 解决 |
|---|---|---|
| 回答旧知识 | 旧Chunk仍存在 | Soft Delete |
| 查询混乱 | Metadata无Version | 增加Version |
| 更新慢 | 全量Embedding | Diff更新 |
| 召回旧数据 | ES未同步 | 双写 |
| 缓存旧答案 | Redis未失效 | 主动删除 |
八、高频面试题(重点)
Q1 为什么更新知识库后仍然回答旧内容?
为什么问
考察是否理解 RAG 不只是向量检索,还涉及索引、缓存和一致性。
标准回答
原因通常包括:
- 旧 Chunk 未删除;
- Metadata 无版本;
- ES 与向量库不同步;
- Cache 未刷新;
- Embedding 异步尚未完成。
Q2 企业为什么不用重新 Embedding 全部文档?
回答:
成本高、速度慢、影响在线服务。
企业一般采用 Diff Chunk,只更新变化部分。
Q3 如何保证检索一定是最新版本?
回答:
- Metadata Version
- status=active
- Alias 蓝绿切换
- Cache Refresh
- MQ 最终一致性
Q4 向量数据库支持 Update 吗?
多数向量库底层更推荐 Delete + Insert,而不是真正覆盖。
因此业务层一般通过版本管理屏蔽旧数据。
Q5 为什么要使用 Alias?
因为索引重建期间不能影响线上查询。
Alias 可以实现秒级切换。
Q6 如何保证更新期间不停机?
双索引:
Index_A(在线)
Index_B(构建)
完成后 Alias 切换。
Q7 如何保证 ES 与 Milvus 一致?
采用 MQ + Outbox Pattern。
失败自动补偿。
Q8 Soft Delete 为什么优于物理删除?
方便回滚、审计和灰度验证。
Q9 为什么 Metadata 比 Embedding 更重要?
Embedding 负责语义,相同语义无法区分版本。
真正控制生命周期的是 Metadata。
Q10 企业级最佳实践
- Diff 更新
- Version 控制
- Active 过滤
- Alias 切换
- 双索引
- 最终一致性
- Cache Evict
- 生命周期管理
Q11 提问文档前面增加300字,不是所有 Chunk 都变了吗?
回答:
如果采用最简单的固定 Token Chunk,确实会导致后续 Chunk 全部偏移,因此 Hash 全部变化,最终只能全量重新 Embedding。这也是很多简单实现 RAG 时遇到的问题。
企业级系统通常不会采用这种方案,而是结合 文档级 Diff + 语义切分(Semantic Chunk)+ 稳定 Chunk ID(Stable Chunk)+ 增量 Embedding。先定位真正发生修改的章节或段落,再仅对受影响区域重新切分和生成向量,从而避免因为局部插入内容导致整个知识库重建。
对于结构化文档(Markdown、Word、HTML、带目录的 PDF),这种方案可以将一次局部修改的更新成本从全量 Embedding 降低到仅更新几个 Chunk,同时保证检索结果始终对应最新版本。
总结
1.企业级 RAG 的核心不是 Embedding,而是知识生命周期管理。真正稳定的系统必须同时解决版本控制、索引一致性、缓存刷新、增量更新和在线切换问题。
2.小型文档可以进行长度切割,大文档必须要进行时语义切割,否则数据已更新整个chunk的diff就会全部重新embedding。