从混乱 HTML 到干净表格:用智能采集 API精准提取结构化电商数据
一、场景痛点:一个商品页,就能让你的正则表达式彻底失控
做过电商数据采集的人,大概都有过这样的深夜:你写好了一套 requests + BeautifulSoup + 正则 的解析脚本,本地跑得好好的,上线一周后突然大面积返回空字段。打开浏览器一看------页面没改版,但 HTML 里你要的价格不见了。
原因往往是这几类「非规范网页」的典型毛病叠加在一起:
-
动态加载 :价格、库存、配送时效、变体(颜色/尺寸)是 JS 异步渲染或懒加载的,初始返回的 HTML 里根本没有这些节点,
requests抓到的是一具「空壳」。 -
不完整 / 不一致的 HTML :同一个站点对不同地区、不同账号、不同 A/B 实验返回的 DOM 结构不一样。价格可能在
a-price__offscreen、也可能在priceblock_dealprice、促销时又跑到另一个块里。 -
反爬阻碍:高频请求触发验证码、直接吐 503,你的解析逻辑还没跑到就已经拿不到数据了。
更要命的是维护成本。每一处选择器、每一条正则,都是对目标站点「当前这一版结构」的硬编码假设。对方一次小改版,你就要重写一批规则、回归测试一遍、再发一次版。采集脚本于是从「写一次用很久」变成了「天天打补丁」。
本文用一个最典型的例子------亚马逊商品详情页------教你完整演示如何规避这套脆弱的解析链路,直接从「混乱 HTML」拿到「干净表格」。
二、反面教材:自建解析为什么越来越难维护
先看看传统做法长什么样。下面是一段「看起来能用」的亚马逊商品解析代码:
python
import re
import requests
from bs4 import BeautifulSoup
def parse_amazon(url: str) -> dict:
html = requests.get(url, headers={"User-Agent": "Mozilla/5.0 ..."}).text
soup = BeautifulSoup(html, "html.parser")
# 1) 标题:id 经常随 A/B 测试变化
node = soup.select_one("#productTitle") or soup.select_one("h1 span")
title = node.get_text(strip=True) if node else None
# 2) 价格:散落在多个候选节点,只能一个个试
price = None
for sel in ["span.a-price span.a-offscreen",
"#priceblock_ourprice",
"#priceblock_dealprice",
".apexPriceToPay span"]:
n = soup.select_one(sel)
if n:
price = re.sub(r"[^\d.]", "", n.get_text())
break
# 3) 评分:直接从文本里抠数字,脆得不能再脆
m = re.search(r"([\d.]+)\s*out of 5", html)
rating = m.group(1) if m else None
return {"title": title, "price": price, "rating": rating}这段代码的问题不在于「写得不好」,而在于它的脆弱性是结构性的:
-
价格逻辑用了 4 个候选选择器,仍然覆盖不全促销/会员/拆单场景;
-
库存、配送、变体信息根本抓不到 ------它们是动态渲染的,不在
html文本里,你得再接一个无头浏览器(Selenium/Playwright)去渲染,复杂度翻倍;
-
反爬没处理------真实环境里你还要叠加代理IP、指纹、重试、验证码识别;
-
每次改版都要回来改这段,而你维护的站点越多,这种「补丁工作量」就越线性膨胀。
一句话总结:自建解析方案,本质是在持续为目标站点的结构变化买单。
三、产品能力拆解:把「写规则」变成「提需求」
3.1 方案提出
在数字化浪潮席卷全球的今天,数据已成为驱动商业决策与AI模型训练的核心引擎。然而,面对日益复杂的网站防护机制、动态内容加载以及跨地域的访问,企业往往在数据获取环节耗费大量精力。为了打破这一瓶颈,Dataify 网页采集 API 应运而生,致力于为企业提供一站式的全球公开数据获取方案,将繁琐的底层技术对抗转化为简单的接口调用,让高质量数据真正赋能业务增长。
3.2 为什么选择 Dataify 网页采集 API
选择 Dataify 网页采集 API,意味着企业能够以低成本的工程获得企业级的数据采集能力。它具备强大的 AI 智能驱动与全球节点覆盖,能够自动识别并处理各类验证码、动态渲染(JS)及浏览器指纹检测,通过模拟真实用户行为有效应对复杂的反爬机制,保障 7×24 小时的高成功率采集。其次,Dataify 大幅降低了开发与维护门槛,开发者无需再手写复杂的请求、解析和清洗逻辑,只需通过标准化的 API 接口,即可将原始网页直接转化为干净的 JSON 等结构化数据,无缝对接下游分析系统或大模型。此外,它支持高并发批量处理与链路自动重试机制,确保在海量数据采集时依然稳定可靠。最重要的是,Dataify 采用按成功计费的透明模式,无效数据不计费,在帮助企业实现从"项目式开发"向"服务式调用"转型的同时,有效控制了数据获取的综合成本。
Dataify官网链接:https://dataify.com?utm_source=hhzz&utm_term=01
3.3 核心思路
Dataify 网页采集 API 的核心思路,是把「解析」这件事从开发者手里收走,交给云端的智能采集引擎来做。它解决上面三类痛点的方式分别是:
-
智能字段识别:引擎内置了对主流电商站点(亚马逊、Walmart、eBay 等 120+ 站点)的语义模型,能自动推断「列表页」和「详情页」的字段(标题、品牌、价格、币种、评分、评论数、库存、图片......),你不需要写任何 CSS 选择器或正则。
-
动态内容已渲染:API 在服务端完成页面渲染与异步内容加载,返回的是「渲染后」的结构化结果,懒加载/JS 的字段一并拿到。
-
反爬全托管 :代理轮换、浏览器指纹、验证码处理都在 API 内部完成,并且只为成功请求计费------失败不收费,这直接改变了成本结构。
调用模型是一个清晰的「任务式」流程:
python
提交采集任务(POST /builder) -> 返回 task_id
|
v
轮询任务状态(tasks_status) -> Running / Ready / Failed
|
v
下载结构化结果(tasks_download) -> 干净的 JSON / CSV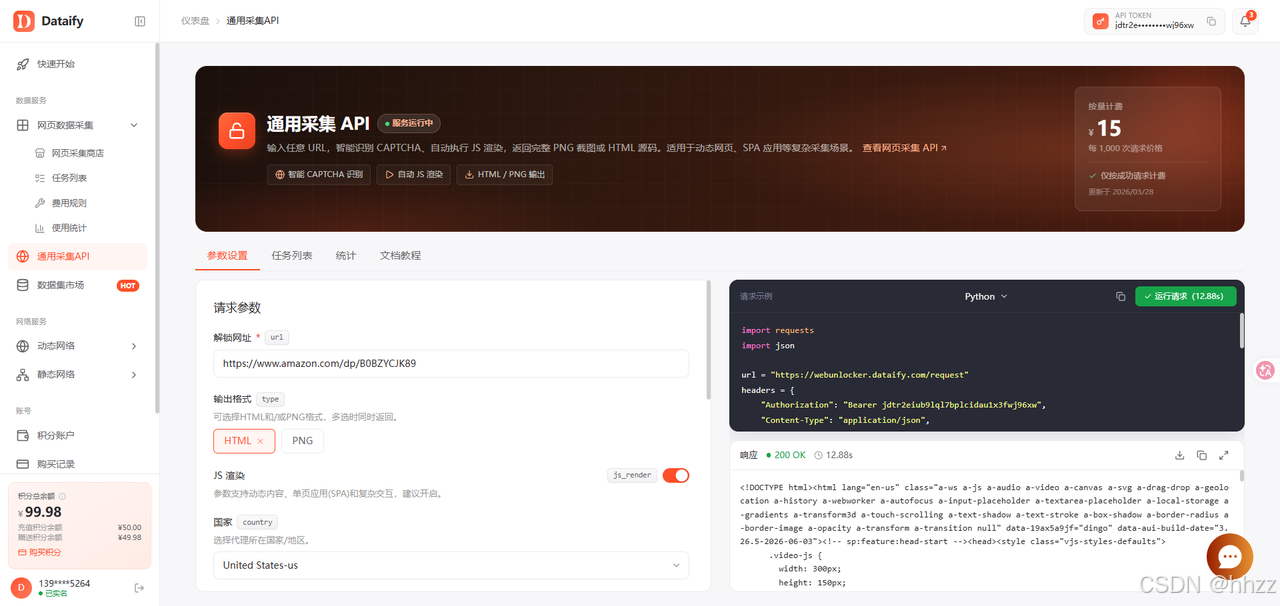
四、代码实战:提交任务 → 轮询 → 下载 → 落地为干净表格
4.1 环境与依赖
python
pip install requests pandas openpyxl把你的 API Token 放进环境变量(不要硬编码进代码或提交到仓库):
python
# Linux / macOS
export DATAIFY_TOKEN="你的_API_Token"
# Windows (PowerShell)
setx DATAIFY_TOKEN "你的_API_Token"4.2 完整脚本 amazon_scraper_dataify.py
python
"""
amazon_scraper_dataify.py
使用 Dataify 网页采集 API 精准提取亚马逊商品结构化数据。
流程:创建任务 -> 轮询状态 -> 下载结果 -> 清洗为干净表格
"""
import os
import json
import time
import requests
import pandas as pd
# ---------------- 配置 ----------------
API_TOKEN = os.environ.get("DATAIFY_TOKEN")
if not API_TOKEN:
raise SystemExit("请先设置环境变量 DATAIFY_TOKEN")
# 创建任务接口(官方文档明确给出的真实地址)
BUILDER_URL = "https://scraperapi.dataify.com/builder"
# 公共任务接口的路径见官方「公共API > 网页采集API」;
# host 以你仪表板「设置-Token管理 / API」页面展示的为准。
PUBLIC_API_BASE = "https://scraperapi.dataify.com"
STATUS_URL = f"{PUBLIC_API_BASE}/api/open/web_scraper/tasks_status"
DOWNLOAD_URL = f"{PUBLIC_API_BASE}/api/open/web_scraper/tasks_download"
SESSION = requests.Session()
# ---------------- 1. 创建采集任务 ----------------
def create_task(product_url: str, zip_code: str = "94107") -> str:
"""提交一个亚马逊「通过 URL 采集商品信息」的任务,返回 task_id。"""
headers = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/x-www-form-urlencoded",
}
payload = {
"spider_name": "amazon.com",
"spider_id": "amazon_product_by-url", # 详情页采集工具
"spider_parameters": json.dumps([{"url": product_url, "zip_code": zip_code}]),
"spider_errors": "true",
"file_name": "{{TasksID}}",
}
resp = SESSION.post(BUILDER_URL, headers=headers, data=payload, timeout=30)
resp.raise_for_status()
result = resp.json()
if result.get("code") != 200:
raise RuntimeError(f"创建任务失败: {result}")
task_id = result["data"]["task_id"]
print(f"[+] 任务已创建 task_id={task_id}")
return task_id
# ---------------- 2. 轮询任务状态 ----------------
def wait_until_ready(task_id: str, interval: int = 5, timeout: int = 600) -> None:
"""轮询直到任务 Ready;Failed 抛错,超时抛 TimeoutError。"""
headers = {"ApiKey": API_TOKEN, "Content-Type": "application/json"}
deadline = time.time() + timeout
while time.time() < deadline:
resp = SESSION.post(STATUS_URL, headers=headers,
json={"task_ids": [task_id]}, timeout=30)
resp.raise_for_status()
items = resp.json().get("data", [])
status = next((i.get("status") for i in items
if i.get("task_id") == task_id), None)
print(f" 状态: {status}")
if status == "Ready":
return
if status == "Failed":
raise RuntimeError(f"任务执行失败 task_id={task_id}")
time.sleep(interval)
raise TimeoutError(f"任务超时 task_id={task_id}")
# ---------------- 3. 下载结构化结果 ----------------
def fetch_result(task_id: str, fmt: str = "json"):
"""获取下载地址并拉取结构化数据。"""
headers = {"ApiKey": API_TOKEN, "Content-Type": "application/json"}
resp = SESSION.post(DOWNLOAD_URL, headers=headers,
json={"task_id": task_id, "type": fmt}, timeout=30)
resp.raise_for_status()
download_url = resp.json()["data"]["download"]
return SESSION.get(download_url, timeout=60).json()
# ---------------- 4. 清洗为干净表格 ----------------
FIELDS = ["asin", "title", "brand", "price", "currency",
"rating", "reviews_count", "availability", "image", "url"]
def to_dataframe(records: list) -> pd.DataFrame:
rows = [{k: r.get(k) for k in FIELDS} for r in records]
df = pd.DataFrame(rows, columns=FIELDS)
df["price"] = pd.to_numeric(df["price"], errors="coerce") # 价格转数值
df["rating"] = pd.to_numeric(df["rating"], errors="coerce")
return df
def main():
urls = [
"https://www.amazon.com/dp/B0BZYCJK89",
"https://www.amazon.com/dp/B0CHHSFMRL",
]
all_records = []
for u in urls:
try:
tid = create_task(u)
wait_until_ready(tid)
data = fetch_result(tid, "json")
records = data if isinstance(data, list) else data.get("data", [])
all_records.extend(records)
except Exception as e:
print(f"[!] {u} 采集失败: {e}")
df = to_dataframe(all_records)
print("\n=== 干净表格 ===")
print(df.to_string(index=False))
df.to_excel("amazon_products.xlsx", index=False)
print(f"\n[✓] 已导出 {len(df)} 条记录 -> amazon_products.xlsx")
if __name__ == "__main__":
main()4.3 运行效果:从「混乱 HTML」到「DataFrame」
提交任务后,控制台会打印类似下面的过程(响应结构来自官方文档示例):
python
[+] 任务已创建 task_id=68a21d2e8f2645e39f3d62231ef6d829
状态: Running
状态: Running
状态: Ready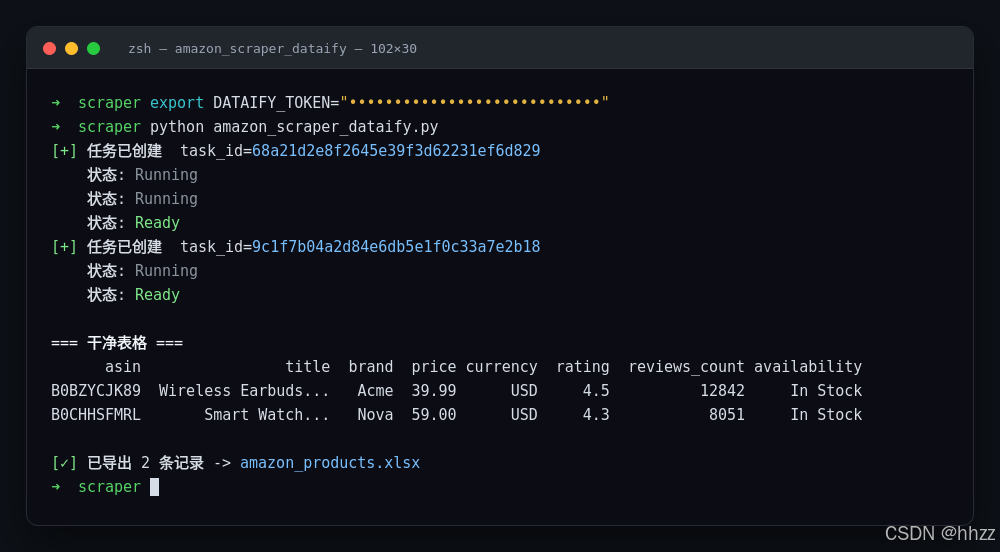
图 2 脚本运行:创建任务 → 轮询 → 输出干净表格并导出 xlsx(模拟测试截图)
下载得到的不再是一坨 HTML,而是字段清晰的 JSON,整理进 DataFrame 后就是一张可直接入库/分析的干净表格(下方为字段示意):
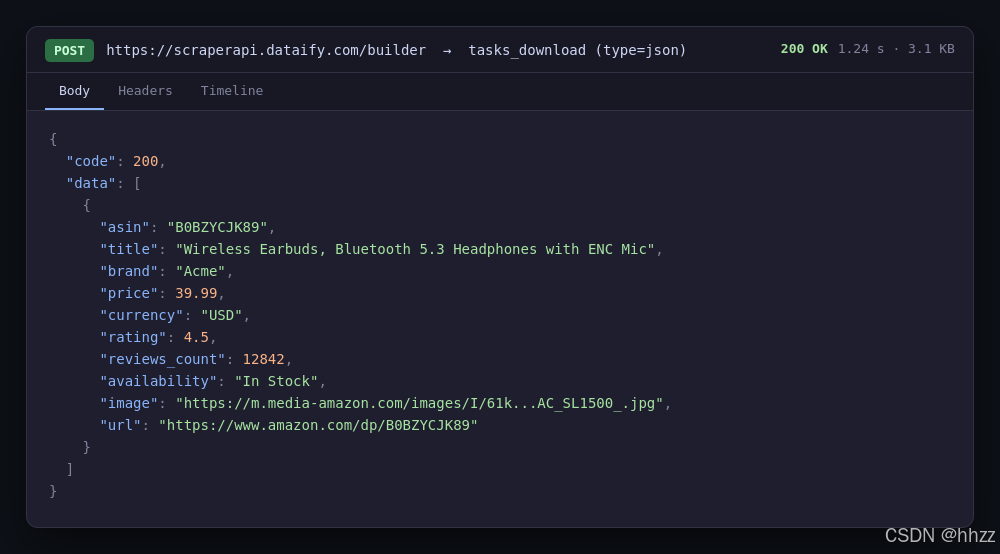
图 3 采集 API 返回的干净结构化 JSON------无需任何选择器即可直接入库(模拟测试截图)
| asin | title | brand | price | currency | rating | reviews_count | availability |
|---|---|---|---|---|---|---|---|
| B0BZYCJK89 | Wireless Earbuds ... | Acme | 39.99 | USD | 4.5 | 12842 | In Stock |
| B0CHHSFMRL | Smart Watch ... | Nova | 59.00 | USD | 4.3 | 8051 | In Stock |
整个过程里,你没有写一行选择器、没有处理一次验证码------这正是「智能识别引擎」要替你省掉的那部分工作。
五、效果对比:自建解析 vs. 采集 API
| 对比维度 | 自建 requests+正则/BeautifulSoup |
Dataify 网页采集 API |
|---|---|---|
| 核心代码行数 | ~180 行(选择器+重试+代理+渲染) | ~40 行(提交+轮询+落表) |
| 动态加载内容 | 需自接无头浏览器渲染 | API 内部已渲染并结构化 |
| 反爬(代理/指纹/验证码) | 自行搭建并长期维护 | 内置自动处理 |
| 解析规则维护 | 高:改版/AB 测试就要重写 | 几乎为零:引擎自动推断字段 |
| 典型成功率 | 受反爬影响,约 60--70% | 约 98%+(官方口径) |
| 计费模式 | 代理流量 + 服务器固定成本 | 仅按成功请求计费,失败不收费 |
| 上线到稳定运行 | 数天调试 + 持续打补丁 | 当天即可跑通 |
最值得关注的不是某个单点指标,而是维护成本曲线:自建方案的成本随「站点数量 × 改版频率」线性增长,而 API 方案把这条曲线压平了------这对要长期、规模化采集的团队来说,才是真正的分水岭。
六、实践
1)并发与批量控制
tasks_status 接口的 task_ids 支持数组,批量采集时一次提交多个任务、再用一次状态查询批量轮询,能显著降低请求次数。同时把并发控制在账户允许的上限内,避免无效排队。
2)数据存储分层
建议「原始层 + 清洗层」分离:下载的原始 JSON 先落 MongoDB / Postgres 的 JSONB 字段,保留全部字段以便回溯;清洗后的结构化表再进数仓。用 asin(或商品 ID)做主键去重,天然支持增量更新。
3)成本优化
利用「只为成功计费」的特性,优先用 by-url / by-asin 这类精准采集而非整站采集;定期调用使用统计接口监控成功率与积分消耗,把钱花在真正产出数据的请求上。
4)安全
Token 一律走环境变量或密钥管理服务,不要硬编码、不要进 Git 历史。本文示例正是从 DATAIFY_TOKEN 读取,方便你直接套用。
七、延伸讨论:采集 API + 数据集,搭一条端到端流水线
单点采集只是起点。把 Dataify 的几类产品组合起来,可以搭出一条完整的数据流水线:
-
发现层:用搜索引擎 API(Google/Bing)做选品与关键词发现,拿到候选 URL / ASIN;
-
结构化层:用本文的网页采集 API 做详情与列表的结构化抽取,处理动态加载与反爬;
-
沉淀层:把清洗后的结构化数据版本化,沉淀为可复用的高质量数据集,供 BI 分析或模型训练增量同步。
这样一来,「选品发现 → 详情结构化 → 长尾兜底 → 数据资产沉淀」形成闭环,既保住了规模化采集的稳定性,又把工程团队从「天天修选择器」里解放出来,去做更有价值的事。
结语
非规范网页的数据清洗难题,本质是「目标站点的不确定性」与「你硬编码的解析假设」之间的长期对抗。正则和选择器能赢一时,却很难赢一世。把解析交给智能识别引擎,把反爬交给托管基础设施,你需要维护的就只剩下「业务需要哪些字段」这一件真正属于你的事。
从混乱 HTML 到干净表格,中间那段最磨人的距离,本就不该由你的正则表达式来承担。