可以这样说:
BA = 重投影模型 + 链式法则 + Jacobian + LM优化
而 Jacobian 就是 BA 的灵魂。
SO(3) Jacobian 完整推导(左雅可比 / 右雅可比)_雅可比矩阵的推倒-CSDN博客
一、为什么要计算 Jacobian?
1、重投影误差
先看 BA 的目标函数,对于第i个相机 看到的第j个点:
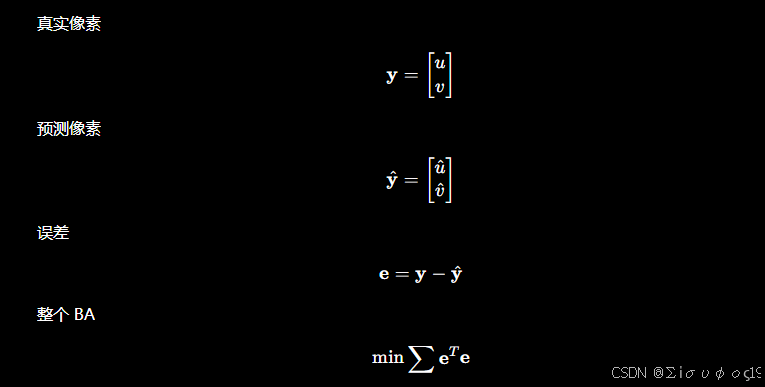
2、那么有个问题: 如何降低误差?
- 相机姿态移动,比如相机左右移动
3、那么怎么知道左移还是有移呢?
答案就是 求导 就是 Jacobian 这个理解非常重要
4、Jacobian 本质是什么
举例1: y= 那么导数就是
其几何意义是 :当x 移动2mm,那么y就变换4mm
举例2: f(x,y) 进行导数:
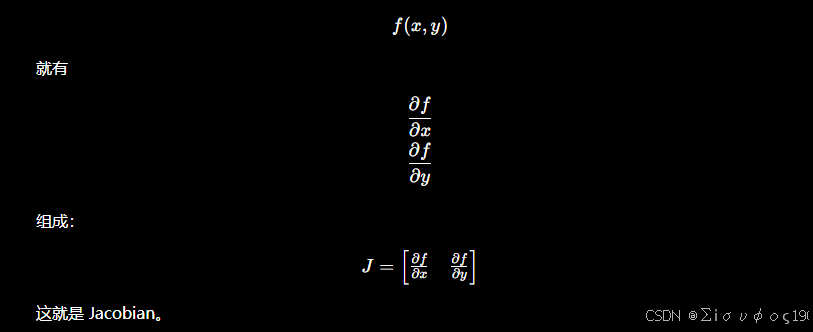
那么在BA中Jacobian
输出: (u,v)
输入: R t P
那么 Jacobian就是:
cpp
输出 (u,v)
↑
Jacobian 像素坐标对位姿、三维点变化的敏感程度
↑
输入 R t P二、BA 的函数和链式法则推导
1、核心公式

分三层理解:
1、世界坐标 =
2、相机坐标:
3、投影 (u,v)
那这个函数的整个流程就是
cpp
P
↓
RP+t
↓
(X,Y,Z)
↓
(u,v)因此必须求导,从第一步到低三步,一层一层的求解
2、链式法则
假设
对x项求导数 : 这个很重要
BA和上面的假设是一样的:
因为 -> (u,v)
那么 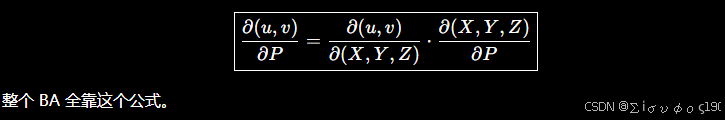
3、数学推导
第一步:投影函数求导
投影:
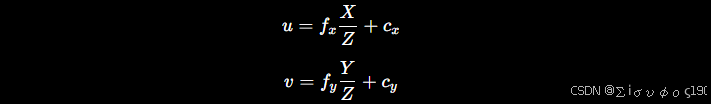
开始求偏导数
对u求导
a 对X 求偏导数:
 Z是常数
Z是常数
b 对Y求偏导数
u中没有y 所以
c 对z求偏导数
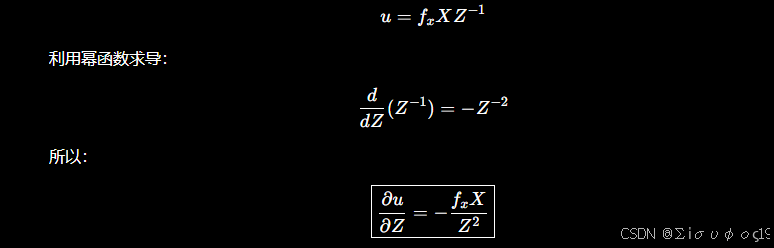
同理 对v求导
BA 的 Jacobian
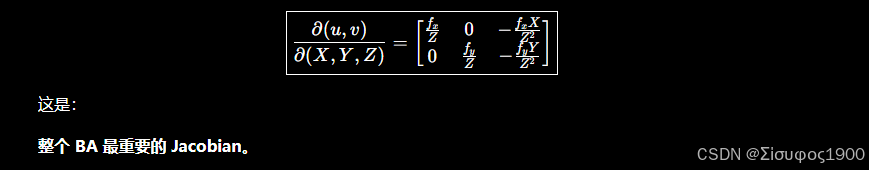
第二步:相机坐标对世界点求导
相机坐标:
展开: 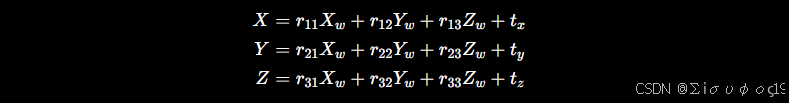 对P开始求偏导数:
对P开始求偏导数:
这一步也是计算偏导
第三步:组合起来(对三维点求导)
利用链式法则:
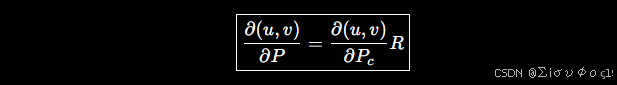
因此:
Jacobian:
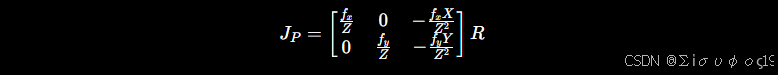
第四步:对平移 t 求导
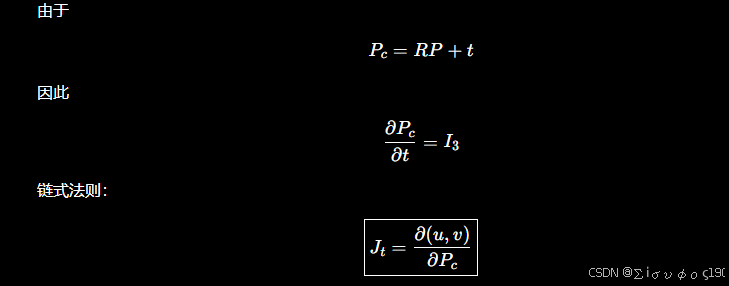
也就是说:
对平移的 Jacobian 就是第五步那个 2×3 投影 Jacobian。
直观理解也很简单:平移直接改变相机坐标,不经过旋转矩阵。
第五步:对旋转 R 求导(真正困难的地方)
这里也是 BA 最容易让人困惑的地方。
如果直接把旋转矩阵九个元素都当未知数,会遇到两个问题:
1、旋转矩阵必须满足
det(R)=1
9 个元素之间存在约束,不能独立优化。
2、优化后矩阵容易失去正交性。
a、定义小角度增量
因此现代 BA 不会直接优化 R ,而是优化一个三维旋转增量:
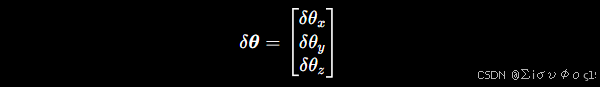
表示绕三个轴的小角度增量 (优化步长) 把三维向量变成反对称矩阵

b、李群旋转更新公式

- 背景:旋转矩阵是李群 SO(3),直接加减会破坏正交性,所以用李代数增量更新。
- 含义:给当前旋转 R 加一个小角度增量 (
c、小角度近似

用李代数的小角度增量来更新旋转矩阵,既保证了矩阵始终是合法旋转,又能像普通变量一样做优化,小角度下还能用一阶近似简化计算
d、相机坐标点定义
世界坐标系下的点 P,经过旋转矩阵 R 变换,得到相机坐标系下的点。
e、微小变化推导

f、相机点对旋转的偏导

- 含义:从上面的线性关系可以看出,点的变化量 (
- 作用:这个雅可比描述了「旋转变化 1 个单位」时,相机坐标系里的点会移动多少。
g、链式法则求像素对旋转的雅可比

- 我们最终要的是像素坐标 (u,v) 对旋转增量 (
- 第一步:先算「像素坐标对相机点
- 第二步:乘上「相机点对旋转的偏导」:

- 第一步:先算「像素坐标对相机点
- 根据链式法则,把两个偏导乘起来,就得到了 BA 优化中需要的旋转雅可比
总结
整个推导的核心就是:
- 用李代数的小角度近似,把旋转变化转化为相机点的位移;
- 用反对称矩阵的叉乘性质,得到点位移对旋转的偏导;
- 再用链式法则,结合投影模型的雅可比,得到像素对旋转的雅可比,用于 BA 优化。
第六步:整个 Jacobian 的最终结构
对于一条观测(一个相机看到一个点),误差只有二维,因此对应的 Jacobian 是一个 2×(6+3) 的块矩阵:

这只是一条观测对应的 Jacobian。
如果系统中有 m 个相机、n个三维点、总共 N 条观测,那么所有这样的 2×9 小块会按照观测关系拼接成一个巨大但高度稀疏的 Jacobian 矩阵。正是这种稀疏块结构,使 BA 能够利用舒尔补(Schur Complement)、稀疏 Cholesky 等算法高效求解,而不是直接处理一个庞大的稠密矩阵。
总结
整个 Jacobian 可以理解为回答三个问题:
- 三维点移动 1 mm,图像上的像素会移动多少? (
- 相机平移 1 mm,图像上的像素会移动多少? (
- 相机旋转 1 rad(或一个很小的角度),图像上的像素会移动多少? (
这些导数共同构成了 BA 的雅可比矩阵,LM 或高斯-牛顿算法正是利用这些"敏感度"来计算每一步应该如何更新相机位姿和三维点,从而不断降低重投影误差。
三、求解雅克比矩阵
PnP 的 2×6 重投影雅可比矩阵
问题背景
假设有一个三维点
当前 PnP 求出的相机位姿是
- 旋转:单位矩阵 R=I
- 平移:t=(0,0,0)
相机内参
因此三维点在相机坐标系中仍然是
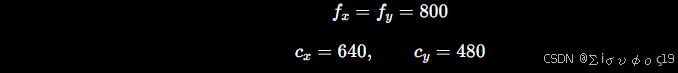 第一步:计算像素坐标
第一步:计算像素坐标
计算
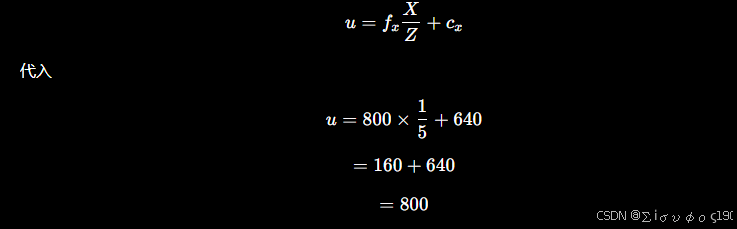
再计算
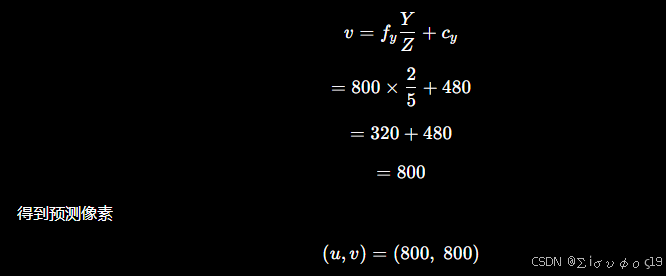
第二步 :PnP优化
PnP优化的是6个变量

因此 输出:(u,v) 输入: 6个参数
第三步 :计算前三列(平移)
由于相机平移会直接影响相机坐标,因此前三列比较容易计算。
第一列
假设相机沿 X 方向移动
那么新的三维点就是 (1.01,2,5)
那么重新计算 =800*1.01/5+640=801.6
移动0.01m x 方向移动1.6个像素
那么 =1.6/0.01=160
同理对v : ,所以第一列就是
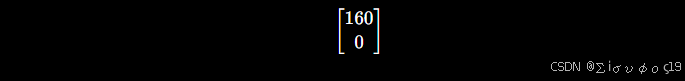
第二列
移动 0.01 -》(1,2.01,5) 计算得到 :=800*2.01/5+480=801.6
=1.6/0.01=160 ,所以因此第二列
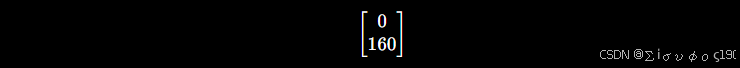
第三列
移动 0.01m 新的深度 Z=5.01
计算 u 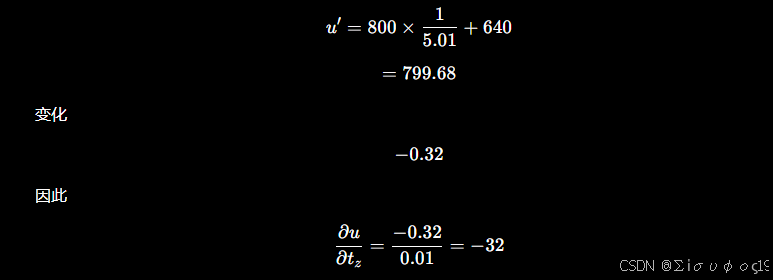
计算v:
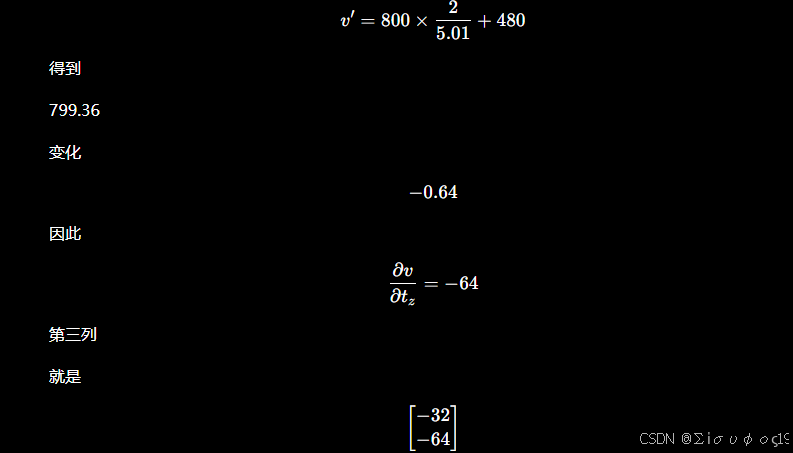
那么前三列:

第四步 :计算后三列(旋转)
PnP中旋转一般采用小角度扰动(例如每次扰动 0.0010.0010.001 rad),通过重新投影计算像素变化,再用"变化量 ÷ 扰动量"得到对应列。
第一列 绕 X 轴旋转
施加 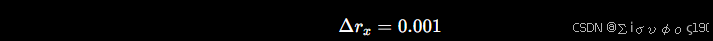
重新投影后得到像素:(799.936,799.072)
那么误差就是 : (−0.064,−0.928),那么除以0.001
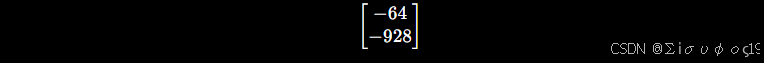
第二列 绕 Y 轴旋转
扰动 0.001
重新投影后得到像素:(800.832,800.064)
那么误差就是 : (0.832,0.064),那么除以0.001

第三列 绕 Z 轴旋转
扰动 0.001
重新投影后得到像素:(799.680,800.160)
那么误差就是 : (−0.320,0.160) ,那么除以0.001 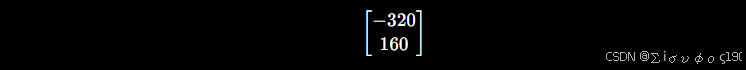
第五步 组合
最终得到完整的 2×6 重投影雅可比
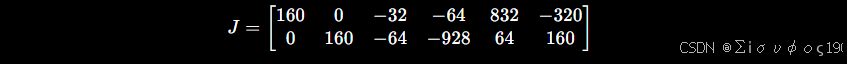
| 列 | 参数 | 数值(u, v) | 含义 |
|---|---|---|---|
| 1 | (t_x) | (160, 0) | 相机沿 X 平移 1 m,u 增加约 160 像素 |
| 2 | (t_y) | (0, 160) | 相机沿 Y 平移 1 m,v 增加约 160 像素 |
| 3 | (t_z) | (-32, -64) | 相机前后移动,目标变远,像素坐标向主点收缩 |
| 4 | (r_x) | (-64, -928) | 绕 X 轴旋转主要影响 v 坐标 |
| 5 | (r_y) | (832, 64) | 绕 Y 轴旋转主要影响 u 坐标 |
| 6 | (r_z) | (-320, 160) | 绕 Z 轴旋转使图像发生平面旋转 |
第六步:在 LM / 高斯--牛顿中的实际用途
假设当前重投影误差为:
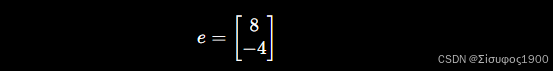
即预测点比真实点右偏 8 像素、上偏 4 像素。
优化器会利用刚才求出的雅可比矩阵计算位姿更新量:
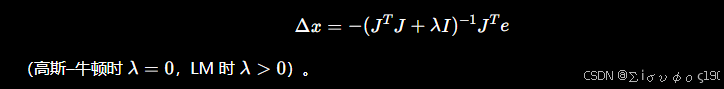
Bundle Adjustment 的稀疏雅可比
Bundle Adjustment(BA)雅可比矩阵 是在 PnP 的 2×6 雅可比基础上扩展而来的。
可以这样理解:
PnP:优化一个相机位姿。
BA:同时优化所有相机位姿 + 所有三维点。
因此 BA 的雅可比矩阵比 PnP 大很多,但每一块的计算方式其实和 PnP 基本一致
案例说明
假设有:
- 2 台相机
- 3 个三维点
如下图(示意)
需要优化的变量:
相机位姿
Camera1: 6个
Camera2: 6个
三维点:
P1 P2 P3 9个变量 总共是21 个变量
分析:
每个点被两台相机看到。所以观测数量 2*3=6 每次观察(u,v)y因此每次观察误差维度 6*2=12
因此BA雅可比矩阵大小: 12*21
计算第一条观测
对于Camera1 看到P1

计算像素坐标:

假设 真实像素 (805,798) 因此误差为: (-5,2)
计算pose
这个和PnP完全一样。得到
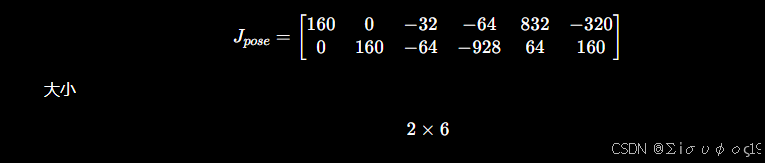
计算 Point 雅可比
现在还需要求像素对三维点的变化。对于P1得到
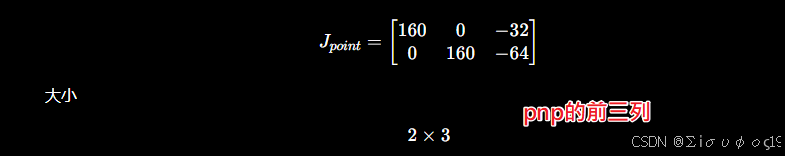
于是这一条观测完整雅可比就是
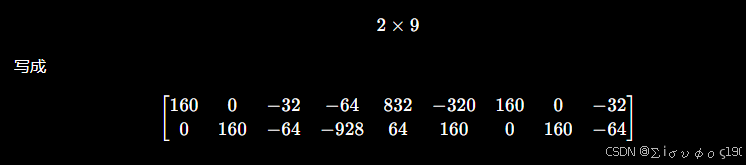
放入整个 BA 矩阵
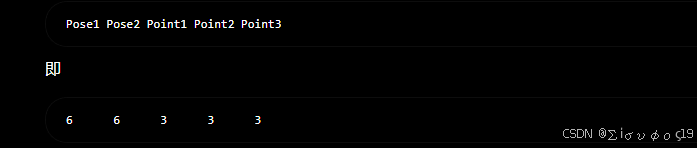
计算第二条观测
Camera1看P2Pose雅可比一样Point雅可比一样只是P2的位置移动了。
于是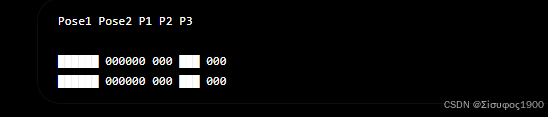
计算剩下的4个观测

整合为稀疏矩阵:
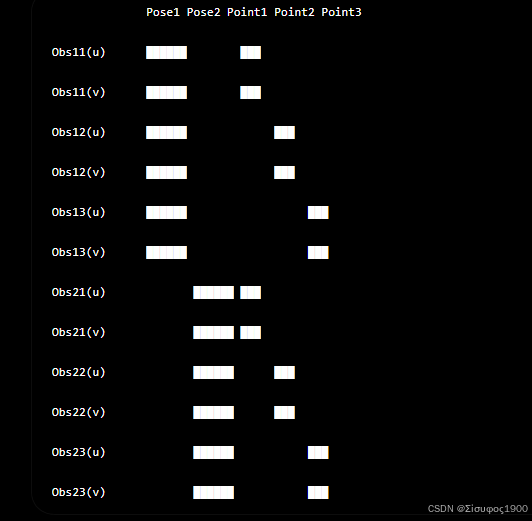
总结
为什么它是稀疏的
每一条观测只与:
- 1 个相机位姿(6 个变量)
- 1 个三维点(3 个变量)
有关。
所以每两行(对应一个观测)只有:
- Pose:6 个非零元素
- Point:3 个非零元素
总共 9 个非零元素。
而本例中总变量有 21 个 ,因此每两行只有 9 列非零,12 列为 0。
在真实工程中,例如:
- 1000 个关键帧(约 6000 个位姿变量)
- 100000 个三维点(约 300000 个点变量)
总变量超过 30 万 。虽然雅可比矩阵规模巨大,但每个观测仍然只涉及 9 个变量 ,因此绝大多数元素都是 0。这正是 BA 能够高效求解的原因,也是 g2o 、Ceres Solver 和 GTSAM 等优化库都会采用块稀疏矩阵(Block Sparse Matrix)和舒尔补(Schur Complement)等技术的根本原因。
PnP 与 BA 雅可比的关系
| 项目 | PnP | Bundle Adjustment |
|---|---|---|
| 优化变量 | 1 个相机位姿(6 维) | 多个相机位姿 + 多个三维点 |
| 单个观测雅可比 | 2×6 | 2×9(2×6 Pose + 2×3 Point) |
| 整体雅可比 | 多个 2×6 堆叠 | 大型块稀疏矩阵 |
| 稀疏性 | 不明显 | 非常明显(每个观测仅关联一个位姿和一个点) |
| 常用求解 | 高斯--牛顿、LM | 高斯--牛顿、LM + 舒尔补 + 稀疏线性代数 |
BA 的每一个非零块,本质上就是由一个 PnP 的 2×6 位姿雅可比,加上一个 2×3 三维点雅可比组成。
理解了 PnP 的重投影雅可比,BA 的雅可比结构也就迎刃而解。