现在都在用多模态数据建模,如何能保证各模态数据特征被充分提取呢?
论文:Amplifying Prominent Representations in Multimodal Learning via Variational Dirichlet Process
代码:https://github.com/HKU-MedAI/DPMM
0、摘要
在多模态融合 的实际应用中(如医疗健康与金融领域),如何兼顾各模态内部的特征表达 效力与跨模态交互 学习,始终是核心难点(研究意义)。以往方法多侧重跨模态对齐 ,但过分强调模态边缘分布的对齐,易引入过度正则化,反而制约模态内部有意义的表征学习。(当前研究不足)
狄利克雷过程(DP) 混合模型作为一类强大的贝叶斯非参数方法,凭借其"富者愈富"的特性,能够放大最显著的特征并为之分配递增的权重 。(DP 的特点与优势)
受此启发,本文提出一种基于 DP 驱动的多模态学习框架,可自适应地实现模态内显式表征学习与跨模态对齐之间的最优平衡。
具体而言,本文假设各模态服从多元高斯混合分布 ,并引入 DP 来计算所有混合分量的权重。该设计使得 DP 借助其"富者愈富"机制,动态调整各特征的贡献度并筛选出最具区分力的特征,从而有效促进多模态融合。(作用机制)
在多个多模态数据集上的大量实验表明,本模型性能优于现有对比方法。消融分析进一步验证了 DP 在模态分布对齐中的有效性,以及其对关键超参数变化的鲁棒性。
1、引言
1.1、研究意义与当前挑战
(1)多模态学习旨在整合来自多种模态的信息,为下游任务生成有意义的表征。(本文面向多模态学习)
(2)多模态学习的核心任务之一是融合来自不同模态的信息,这一过程可分为早期融合 、联合融合 或晚期融合 策略。其中联合融合策略 因其强大的模态间结构交互捕捉能力而成为最主流的多模态融合范式。(多模态学习的不同方案)
(3)现有跨模态对齐方法过于侧重特征对齐而忽视模态内表征,致使融合效果欠佳,故需设计兼顾两者之新策略。(现有研究不足)
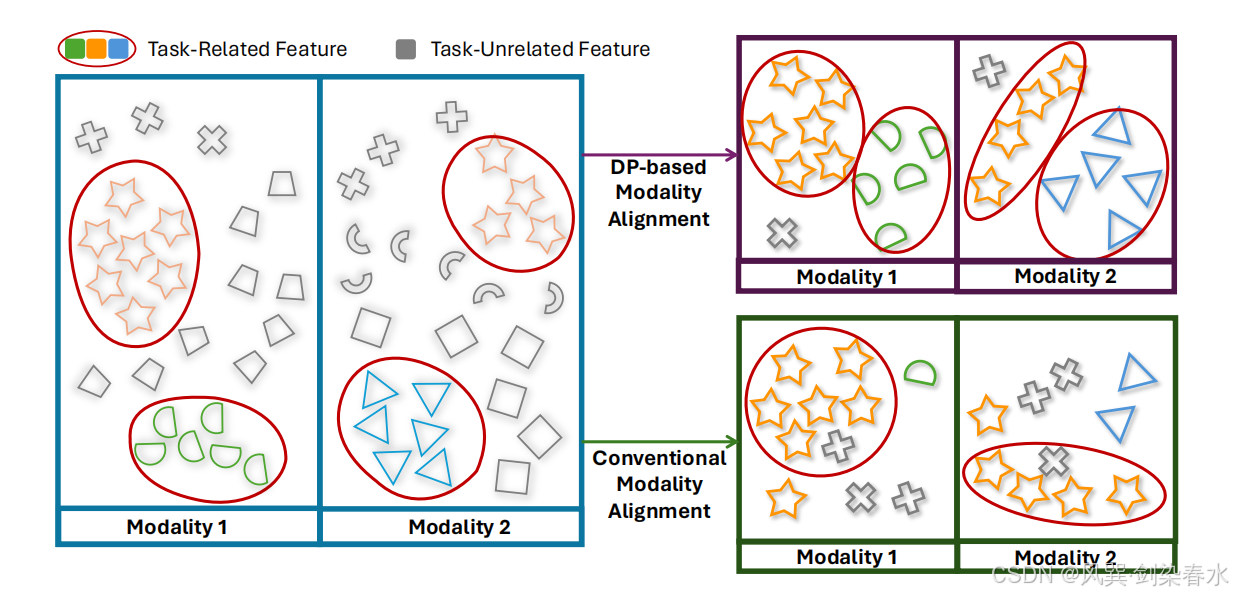
(4)DP 虽能放大显著特征(图 1),但其在多模态学习中尚待探索;面对常见的模态缺失问题,现有处理方式会削弱表征,亟需通过强化模态内表征来改善。
**Figure 1 | 基于狄利克雷过程的模态对齐(右上)与传统模态对齐(右下)对比:**狄利克雷过程会分配更多权重以捕捉显著特征(如 ⋆, △),而传统方法在对齐过程中难免会压缩模态内部特征。
1.2、本文贡献
本文提出一种基于狄利克雷过程驱动的多模态学习框架,称为 DPMM(Dirichlet Process Mixture Multimodal Learning),从概率视角重新审视多模态融合范式。本文贡献如下:
(1)引入基于狄利克雷过程的新型多模态学习框架,在放大特征信号的同时,实现模态间的合理对齐;(建立了一个框架)
(2)采用随机变分推断 对模型进行高效优化,克服了传统基于马尔可夫链蒙特卡洛(MCMC)算法的可扩展性瓶颈,使模型能够适用于大规模数据集;(解决了传统问题)
(3)利用学习到的边缘分布 作为表征生成器,借助 DP 强调的显著特征,对缺失观测进行准确填补。由此改善训练及下游任务所使用的特征质量,进而提升整体性能;(对缺失学习的作用)
(4)在四个多模态数据集上的实验结果表明,本框架性能优越;消融分析进一步验证了 DP 在模态对齐与特征放大中的有效性;(实验结果优秀)
2、相关工作
(1)跨模态对齐: 现有跨模态对齐方法偏重模态间共性,却容易削弱各模态自身的特有信息,影响后续任务效果。
(2)深度贝叶斯非参数方法: 贝叶斯非参数方法尤其是 DP 在深度学习中已有拓展,但在多模态学习领域应用有限且场景受限,缺乏通用性。
(3)缺失数据学习: 现有缺失数据应对策略主要围绕结构交互或简单填充,却忽略了特征放大,使得生成的表征缺乏区分力。
3、方法
3.1、基础
(1)狄利克雷过程
狄利克雷过程记作 DP ( η , G ) \text{DP}(\eta, G) DP(η,G),是定义在样本空间 X \mathcal{X} X 上的随机概率测度。对 X \mathcal{X} X 任意可测有限划分 S = { B i } i = 1 K S=\{B_i\}_{i=1}^K S={Bi}i=1K,满足:
( G ( B 1 ) , G ( B 2 ) , ... , G ( B K ) ) ∼ Dir ( η G ( B 1 ) , η G ( B 2 ) ... , η G ( B K ) ) , \left(G(B_1), G(B_2), \dots, G(B_K)\right) \sim \text{Dir}\big(\eta G(B_1),\eta G(B_2) \dots,\eta G(B_K)\big), (G(B1),G(B2),...,G(BK))∼Dir(ηG(B1),ηG(B2)...,ηG(BK)),式中 G G G 为基概率测度, η \eta η 为集中参数, Dir ( ⋅ ) \text{Dir}(\cdot) Dir(⋅) 代表狄利克雷分布。
推荐阅读:【AI】通俗详解狄利克雷分布(Python 应用示例)
可以把基测度 G G G 想象成一块总质量为 1 1 1 的"概率黏土",而划分 S S S 则是把这团黏土预切成了 K K K 个小块。各小块上实际分配到的质量 G ( B i ) G(B_i) G(Bi) 并不是固定的,而是服从一个狄利克雷分布------相当于把这团黏土的总质量按某种随机比例撒到各个块上。
狄利克雷过程可直观理解为:一个用于生成随机概率分布的分布,它通过调节 η \eta η 来控制概率质量在划分单元间的聚集或分散程度。
(2)多模态学习
给定多模态训练数据集 D tr = { ( x 1 ( i ) , ... , x M ( i ) , y ( i ) ) } i = 1 n \mathcal{D}\text{tr}=\big\{\big(x_1^{(i)},\dots,x_M^{(i)},y^{(i)}\big)\big\}{i=1}^n Dtr={(x1(i),...,xM(i),y(i))}i=1n,其中 x m ( i ) ( m = 1 , ... , M ) x_m^{(i)}\ (m=1,\dots,M) xm(i) (m=1,...,M) 表示第 m m m 个模态的第 i i i 个观测样本, y ( i ) y^{(i)} y(i) 为对应标签。多模态学习的目标是训练参数为 Θ \boldsymbol{\Theta} Θ 的多模态神经网络 f Θ ( ⋅ ) f_{\boldsymbol{\Theta}}(\cdot) fΘ(⋅),使模型在下游任务中取得最优性能。
3.2、基于狄利克雷过程的多模态学习
**本文提出的多模态学习框架将多模态特征分布建模为高斯混合模型,其混合权重由狄利克雷过程(DP)分配。**DP 的分配机制可确保显著特征获得递增的关注。图 2 概述了所提 DPMM 模型的整体架构,算法 1 给出了详细计算步骤。
Figure 2 | 本文所提狄利克雷过程混合模型(DPMM)整体框架:首先将输入数据送入编码器,得到隐嵌入向量 z 1 , ... , z M z_1,\dots,z_M z1,...,zM;随后依托狄利克雷过程的断棍构造方式,求解混合权重集合 { π m k : m ∈ M , k ∈ K } \{\pi_{mk}: m\inM,\,k\inK\} {πmk:m∈M,k∈K};结合该组混合权重与多元高斯混合 假设,进一步计算加权似然;最后融入任务专属损失函数,得到用于编码器训练的证据下界(ELBO)。针对训练过程中存在的样本模态不匹配问题,本文采用梯度保持采样策略补全缺失观测样本,同时保证梯度能够正常反向传播。
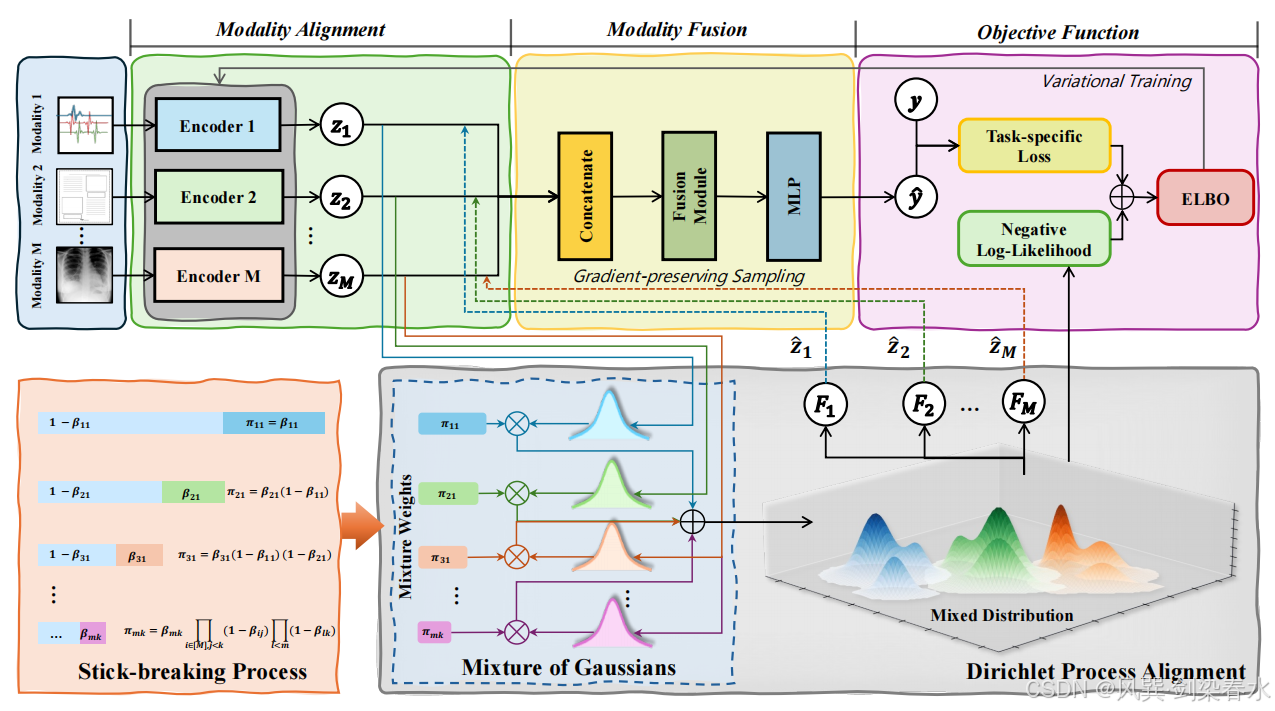

在标准深度学习训练循环中,嵌入一个由断棍构造驱动的概率混合模型,并利用变分推断的 ELBO 作为损失函数,同时更新神经网络编码器和混合模型参数。
(1)混合权重的断棍构造过程
本文将狄利克雷过程多模态学习框架设定为包含 M × K M\times K M×K 个成分的混合模型,假定每个混合成分服从多元高斯分布。采用常用的断棍过程,对权重先验分布 做如下定义:
β m k ∼ Beta ( 1 , η ) , π m k = β m k ∏ i ∈ M , j < k ( 1 − β i j ) ∏ l < m ( 1 − β l k ) (1) \beta_{mk} \sim \operatorname{Beta}(1,\eta),\quad \pi_{mk} = \beta_{mk}\prod_{\substack{i\inM,j<k}} (1-\beta_{ij})\prod_{l<m} (1-\beta_{lk}) \tag{1} βmk∼Beta(1,η),πmk=βmki∈M,j<k∏(1−βij)l<m∏(1−βlk)(1) 式中, π m k \pi_{mk} πmk 代表分配给第 m m m 个模态下第 k k k 个混合成分的概率;图 3 直观展示多模态场景下断棍过程的原理。借助断棍过程完成混合权重选取后,狄利克雷过程可依托其 "富者愈富" 特性,自动筛选各模态中最具显著性的特征。
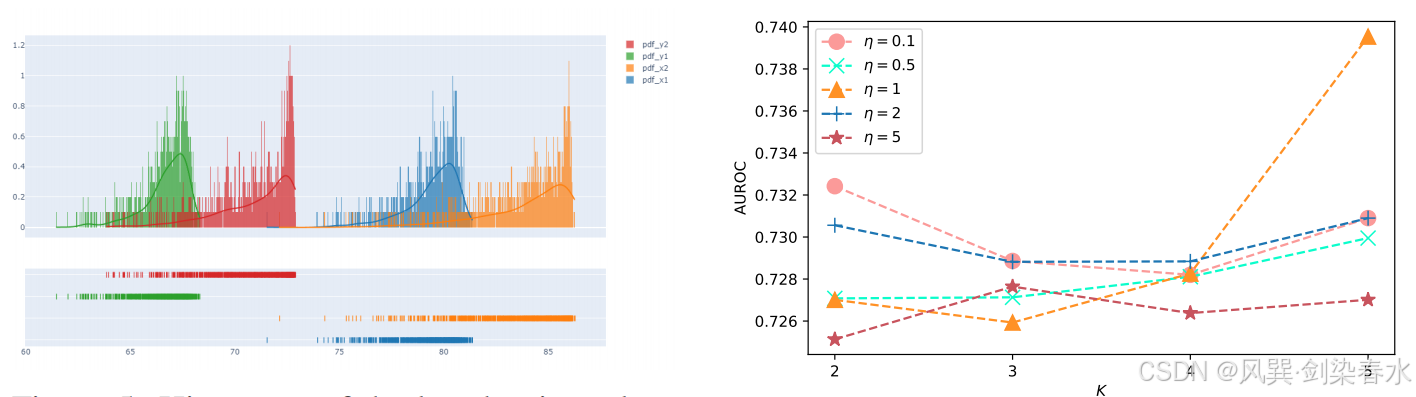
在多模态学习的 DPMM 框架中, η η η 就是模型"稀疏性"的总开关。如果想让模型只抓取最核心的少数几个特征,就把 η η η 设小一点(或让模型从数据中学出一个较小的 η η η);如果认为特征应该均匀分布在各个维度,就让 η η η 大一些。
**Figure 3 | 多模态场景下断棍过程原理示意图:**本方法先按模态划分区间,再针对各模态内部完成混合成分的分段操作。该设计可使狄利克雷过程(DP)为各个模态中显著性最强的特征分配更高权重。

(2)以高斯混合分布作为边缘分布
为更灵活地对高维特征表征的分布规律进行建模,本文假定第 m m m 个模态的特征分布服从含 k k k 个成分的多元高斯混合模型(GMM),表达式如下:
f m ( z ) = ∑ k = 1 K π m k N ( z ∣ μ m k , Σ m k ) , m = 1 , ... , M (2) f_m(\boldsymbol{z}) = \sum_{k=1}^{K} \pi_{mk}\mathcal{N}\big(\boldsymbol{z}\big|\boldsymbol{\mu}{mk},\boldsymbol{\Sigma}{mk}\big),\quad m=1,\dots,M \tag{2} fm(z)=k=1∑KπmkN(z μmk,Σmk),m=1,...,M(2) 式中: π m k \pi_{mk} πmk 为第 m m m 个模态下第 k k k 个混合成分的权重; μ m k \boldsymbol{\mu}{mk} μmk 为该成分的均值向量; Σ m k \boldsymbol{\Sigma}{mk} Σmk 为对应协方差矩阵。高斯混合模型是高维分布建模领域的常用方法 。
定义参数集合 μ = { μ m k : m ∈ M , k ∈ K } \boldsymbol{\mu}=\{\boldsymbol{\mu}{mk}:m\inM,k\inK\} μ={μmk:m∈M,k∈K}、 Σ = { Σ m k : m ∈ M , k ∈ K } \boldsymbol{\Sigma}=\{\boldsymbol{\Sigma}{mk}:m\inM,k\inK\} Σ={Σmk:m∈M,k∈K},将 μ \boldsymbol{\mu} μ 与 Σ \boldsymbol{\Sigma} Σ 设置为可学习参数,依靠梯度反向传播完成参数更新;再令整体参数集 θ = { μ , Σ } \theta=\{\boldsymbol{\mu},\boldsymbol{\Sigma}\} θ={μ,Σ}。为提升计算效率,本文引入文献 8 的参数化技巧,约束每个协方差矩阵 Σ m k \boldsymbol{\Sigma}_{mk} Σmk 为对角矩阵。
第 m m m 个模态的密度函数 f m f_m fm 已由式 (2) 定义,在此基础上,联合分布表达式为:
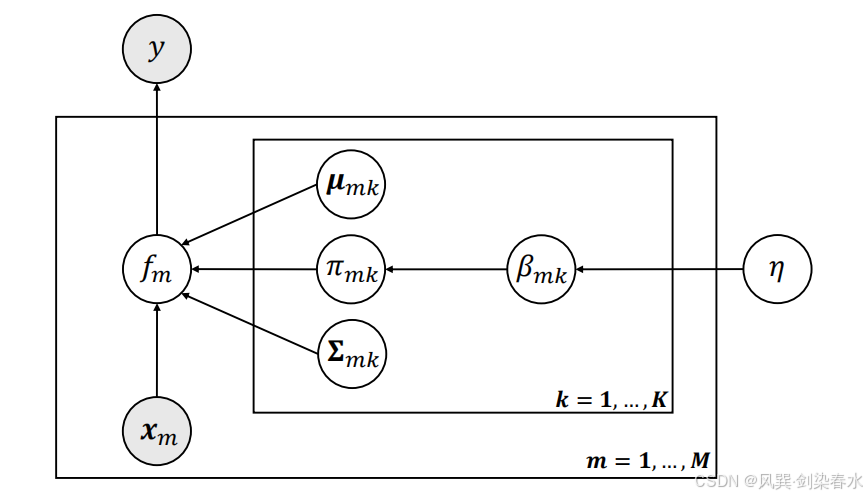
F ( z ) = ∑ k = 1 K ∑ m = 1 M π m k F m ( z ; μ m k , Σ m k ) F(\boldsymbol{z}) = \sum_{k=1}^{K}\sum_{m=1}^{M} \pi_{mk} F_m\big(\boldsymbol{z};\boldsymbol{\mu}{mk},\boldsymbol{\Sigma}{mk}\big) F(z)=k=1∑Km=1∑MπmkFm(z;μmk,Σmk) 式中混合权重由式 (1) 给出, F m ( z ; μ m k , Σ m k ) F_m(\boldsymbol{z};\boldsymbol{\mu}{mk},\boldsymbol{\Sigma}{mk}) Fm(z;μmk,Σmk) 代表第 m m m 个模态下第 k k k 个混合成分的分布函数。本文采用盘式记号绘制的概率图模型如 图 4 所示。
断棍构造只负责"切饼",决定了每块饼(混合成分)有多大;而高斯混合负责"做馅",决定了每块饼里面具体装着什么样的数据特征。
Figure 4 | 所提出的 DPMM 模型的图示标注:
(3)讨论
本文将多模态特征分布 建模为狄利克雷过程混合模型 ,借助狄利克雷过程为有效特征分量 m k mk mk 分配更高关注度,以此凸显第 m m m 个模态各自最重要的贡献。另一方面,高斯分量的协方差矩阵能够刻画各向异性(马氏距离几何特性),助力跨模态结构学习。因此,所提方法可自适应权衡两项目标:突出模态内部显著性特征、实现高效的跨模态对齐。
(4)截断操作下的表达能力
对狄利克雷过程(DP)在分量数 K K K 处做截断处理,不会损失其模型表达能力。Ishwaran 与 Zarepour 提出采用有限混合模型形式对狄利克雷过程建模。
定理 1 (Ishwaran、Zarepour):设狄利克雷过程的基测度为 G G G,对任意关于 G G G 可积的可测函数 f f f,当 K → ∞ K\to\infty K→∞ 时,满足依分布收敛关系:
∫ f ( θ ) d G K ( θ ) ⟶ D ∫ f ( θ ) d G ( θ ) \int f(\boldsymbol{\theta})dG^K(\boldsymbol{\theta}) \stackrel{\mathcal{D}}{\longrightarrow} \int f(\boldsymbol{\theta})dG(\boldsymbol{\theta}) ∫f(θ)dGK(θ)⟶D∫f(θ)dG(θ) 式中, G G G 由无限混合形式近似得到, G K G^K GK 为仅含 K K K 个混合分量的狄利克雷过程混合模型。
该定理的一个重要启示在于:**狄利克雷过程混合模型对应的表征后验分布具备收敛保证。**即便将混合分量截断至 K K K 个,学习得到的分布仍可等价保留无限分量混合模型的特性。依托狄利克雷过程,可精准拟合各模态嵌入的分布规律,生成表征能力充足的特征。
理论上的狄利克雷过程需要无限多个混合成分,但实际算法中我们只截取有限的 K K K 个成分------而且这样做不会损失精度,因为数学上保证了有限个成分可以无限逼近无限个成分的效果。
3.3、随机变分推断
为使本文方法能够适配大规模数据场景,本文采用随机变分推断求解狄利克雷过程混合模型的参数,设定变分分布族形式如下:
q ( β , y ∣ θ ) = ∏ m = 1 M ∏ k = 1 K q ( β m k ) ∏ i = 1 n q ( y ( i ) ∣ β , θ ) q(\boldsymbol{\beta},\boldsymbol{y}\mid\boldsymbol{\theta}) = \prod_{m=1}^{M}\prod_{k=1}^{K} q(\beta_{mk}) \prod_{i=1}^{n} q(y^{(i)}\mid\boldsymbol{\beta},\boldsymbol{\theta}) q(β,y∣θ)=m=1∏Mk=1∏Kq(βmk)i=1∏nq(y(i)∣β,θ) 式中 q ( ⋅ ) q(\cdot) q(⋅) 为变分后验分布(近似分布),其作用是逼近难以直接求解的真实后验分布。证据下界(ELBO)表达式为:
ELBO = − KL ( q ( β ) ∥ p ( β ) ) − KL ( q ( θ ) ∥ p ( θ ) ) − ∑ i KL ( q ( y ( i ) ) ∥ p ( y ^ ( i ) ) ) (3) \text{ELBO} = -\text{KL}\big(q(\boldsymbol{\beta})\parallel p(\boldsymbol{\beta})\big) - \text{KL}\big(q(\boldsymbol{\theta})\parallel p(\boldsymbol{\theta})\big) - \sum_{i}\text{KL}\big(q(y^{(i)})\parallel p(\hat{y}^{(i)})\big) \tag{3} ELBO=−KL(q(β)∥p(β))−KL(q(θ)∥p(θ))−i∑KL(q(y(i))∥p(y^(i)))(3) 其中 KL ( q ( y ( i ) ) ∥ p ( y ^ ( i ) ) ) \text{KL}\big(q(y^{(i)})\parallel p(\hat{y}^{(i)})\big) KL(q(y(i))∥p(y^(i))) 可理解为第 i i i 个样本对应的任务专属损失。借助随机变分推断,可将概率模型的似然值作为代理损失函数开展反向传播优化,从而让狄利克雷过程混合模型能够高效完成高维场景下的多模态学习任务。
(1)后验混合权重的变分更新
下面给出断棍构造权重对应的变分后验闭式更新公式。设 γ 1 , m , γ 2 , m ∈ R K \gamma_{1,m},\gamma_{2,m}\in\mathbb{R}^K γ1,m,γ2,m∈RK 分别为第 m m m 个模态下变分因子 q ( β m k ) = B e t a ( γ 1 , m k , γ 2 , m k ) q(\beta_{mk})=\mathrm{Beta}(\gamma_{1,mk},\gamma_{2,mk}) q(βmk)=Beta(γ1,mk,γ2,mk) 对应 Beta 分布的两个形状参数。最小化 KL 散度项后可得更新式:
γ 1 , m k = 1 + ∑ i = 1 n ϕ i , m k , γ 2 , m k = η + ∑ i = 1 n ∑ r = m k + 1 M K ϕ i , r , (4) \gamma_{1,mk} = 1+\sum_{i=1}^n \phi_{i,mk},\quad \gamma_{2,mk} = \eta+\sum_{i=1}^n \sum_{r=mk+1}^{MK} \phi_{i,r}, \tag{4} γ1,mk=1+i=1∑nϕi,mk,γ2,mk=η+i=1∑nr=mk+1∑MKϕi,r,(4) 式中 η \eta η 为浓度超参数;向量 ϕ i ∈ R M K \boldsymbol{\phi}_i\in\mathbb{R}^{MK} ϕi∈RMK 存放第 i i i 个样本在全部 M K MK MK 个混合分量上的后验责任度(即未归一化后验权重)。责任度的对数形式为:
log ϕ i , m k = E β ∼ q log π m k + E log p ( x ( i ) ) + H q ψ m k ( ⋅ ∣ z i = ( m , k ) , x ( i ) ) + c o n s t , (5) \log\phi_{i,mk} = \mathbb{E}{\beta\sim q}\big\\log\\pi_{mk}\\big+\mathbb{E}\big\\log p(\\boldsymbol{x}\^{(i)})\\big+\mathbb{H}\bigq_{\\psi_{mk}}(\\cdot\\mid z_i=(m,k),\\boldsymbol{x}\^{(i)})\\big+\mathrm{const}, \tag{5} logϕi,mk=Eβ∼qlogπmk+Elogp(x(i))+Hqψmk(⋅∣zi=(m,k),x(i))+const,(5) 随后对每个样本做归一化处理: ∑ r = 1 M K ϕ i , r = 1 \sum{r=1}^{MK}\phi_{i,r}=1 ∑r=1MKϕi,r=1。其中: π m k \pi_{mk} πmk 由变分贝塔因子推导得到,代表混合权重; H ( ⋅ ) \mathbb{H}(\cdot) H(⋅) 为熵函数; z i z_i zi 为混合分量的指示变量; x ( i ) = ( x 1 ( i ) , ... , x M ( i ) ) \boldsymbol{x}^{(i)}=\big(\boldsymbol{x}1^{(i)},\dots,\boldsymbol{x}M^{(i)}\big) x(i)=(x1(i),...,xM(i)) 为观测输入; q ψ m k q{\psi{mk}} qψmk 是以 ψ m k \psi_{mk} ψmk 为参数、以混合分量为条件的变分分布。
3.4、缺失模态补全
本文所提狄利克雷过程混合模型(DPMM)本身属于概率框架,可原生实现缺失模态补全。在常用随机缺失(MAR)假设下,从联合分布 F F F 中求解得到边缘分布 F 1 , ... , F M F_1,\dots,F_M F1,...,FM。针对第 m m m 个模态存在观测缺失的样本 x m ( i ) x_m^{(i)} xm(i),从高斯混合分布中采样得到补全结果: x m ( i ) ∼ F m x_m^{(i)} \sim F_m xm(i)∼Fm。经由该方式采样得到的嵌入特征,同时融合跨模态关联信息与模态内部显著性特征信息。
4、实验
4.1、数据集与实验设置
(1)数据集与预处理
在两个大规模临床多模态数据集 MIMIC-III、MIMIC-IV 上验证 DPMM 的性能。由于 MIMIC-III 数据集未提供胸片(CXR)影像,本文采用临床病历文本作为第二种模态替代胸片。
从 MIMIC-IV 中提取包含电子病历(EHR)的 25071 条重症监护(ICU)住院记录,其中 5931 条记录可匹配对应的胸片影像与诊断报告;同理,从 MIMIC-III 中提取 21139 条带有电子病历的 ICU 住院记录,其中 5273 条可匹配临床病历文本。
为评估 DPMM 的跨模态对齐能力,本文在完全匹配的双模态、三模态实验场景下开展测试;同时在部分匹配数据集上完成实验,验证该模型在存在模态缺失场景下的鲁棒性。
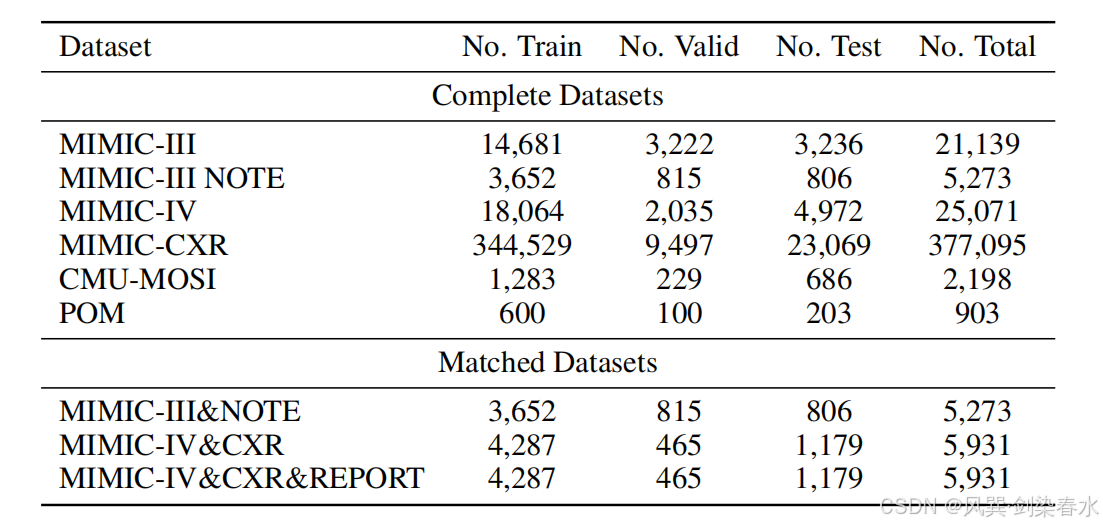
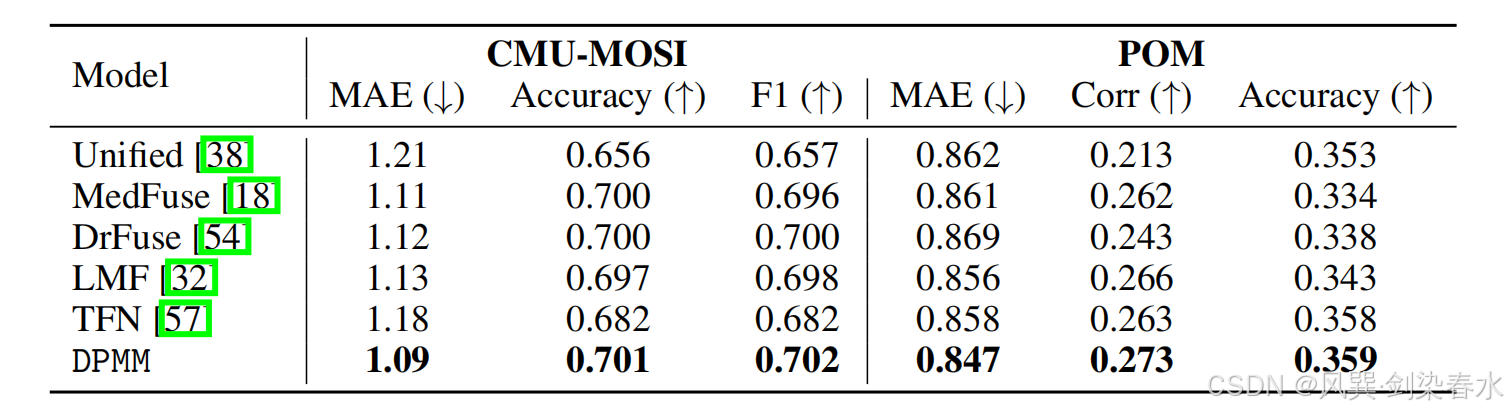
为验证本框架的泛化能力 ,本文参照 Liu 等人 32 的实验方案,在 CMU-MOSI、POM 两个通用多模态数据集上开展实验,两类数据集均包含视频、音频、文本三种模态。表 1 汇总了本文全部实验所用数据集概况。
Table 1 | 数据集汇总:
(2)任务与评价指标
本文设置两项临床预测任务:(1) 院内死亡(IHM)预测 ,判断患者住院期间是否发生死亡;(2) 再入院(READM)预测,预测患者出院 30 天内是否再次入院。
针对 CMU-MOSI 与 POM 数据集,本文沿用文献 32 的实验设定,分别开展电影情感分析 、电影属性预测两类任务。各项任务对应的详细评价指标将在补充材料中予以说明。
4.2、比较方法
在临床数据集基准上,将所提 DPMM 模型与五种基线方法开展对比:
(1) DrFuse: 基于 Transformer 架构,借助解耦表征学习在电子病历(EHR)与图像模态间构建共享表征,可适配单模态缺失场景。
(2) MMTM: 一种灵活的即插即用模块,用于实现不同模态间信息交互。该模型默认所有模态完整可用,因此本文在训练与测试阶段,对缺失胸片(CXR)、临床病历的位置补全全零向量以完成缺失值填充。
(3) DAFT: 专为表格数据与图像模态信息交互设计的模块,可嵌入卷积神经网络(CNN)中使用。同理,本文在训练、测试过程中采用零矩阵替代缺失的胸片与临床病历数据。
(4) Unified: 一种动态多模态融合方案,能够整合辅助模态数据、学习各模态专属表征,并通过统一分类器完成特征融合;该方法原生支持缺失数据处理,可充分利用现有模态的全部有效信息。
(5) MedFUSE: 依托长短期记忆网络(LSTM)完成特征融合,将图像编码器、文本编码器输出特征与电子病历编码器特征进行拼接;针对模态缺失问题,该方法为缺失胸片或临床病历的样本学习全局表征以实现补全。
除上述临床领域基线模型外,本文针对 CMU-MOSI、POM 数据集额外引入两类通用多模态融合基线:低秩多模态融合(LMF) 借助低秩张量提升多模态融合计算效率;张量融合网络(TFN) 将多模态建模问题拆解为模态内部、模态间关联关系建模,并通过可学习张量拟合两类动态关联规律。
4.3、实验结果
**Table 2 | 模态完全匹配设定下,MIMIC-III、MIMIC-IV 数据集以 AUROC、AUPR、F1 为指标并附带 95% 置信区间的实验结果:**最优结果以加粗字体标注。本文所提 DPMM 在全部实验场景下性能均优于各类基线模型。
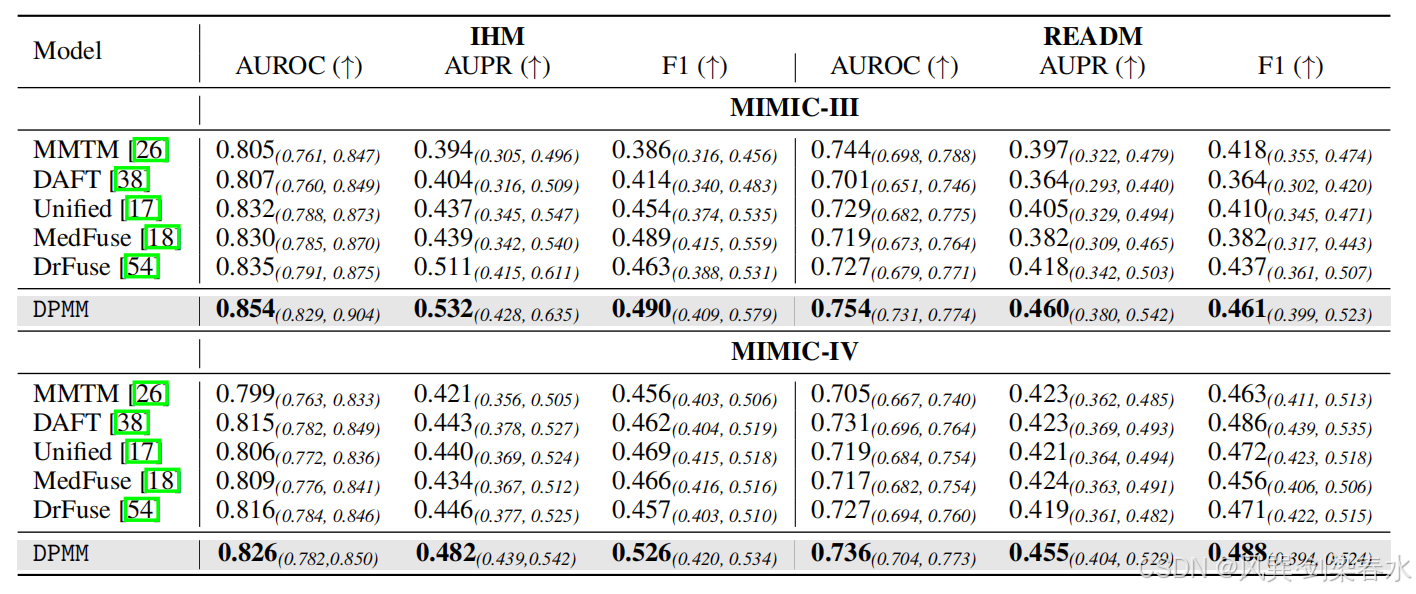
**Table 3 | 模态部分匹配(即存在模态缺失)设定下,MIMIC-III、MIMIC-IV 数据集以 AUROC、AUPR、F1 为评价指标并附带 95% 置信区间的实验结果:**最优结果采用加粗字体标注。本文提出的 DPMM 方法在全部实验场景下性能均优于基线模型。
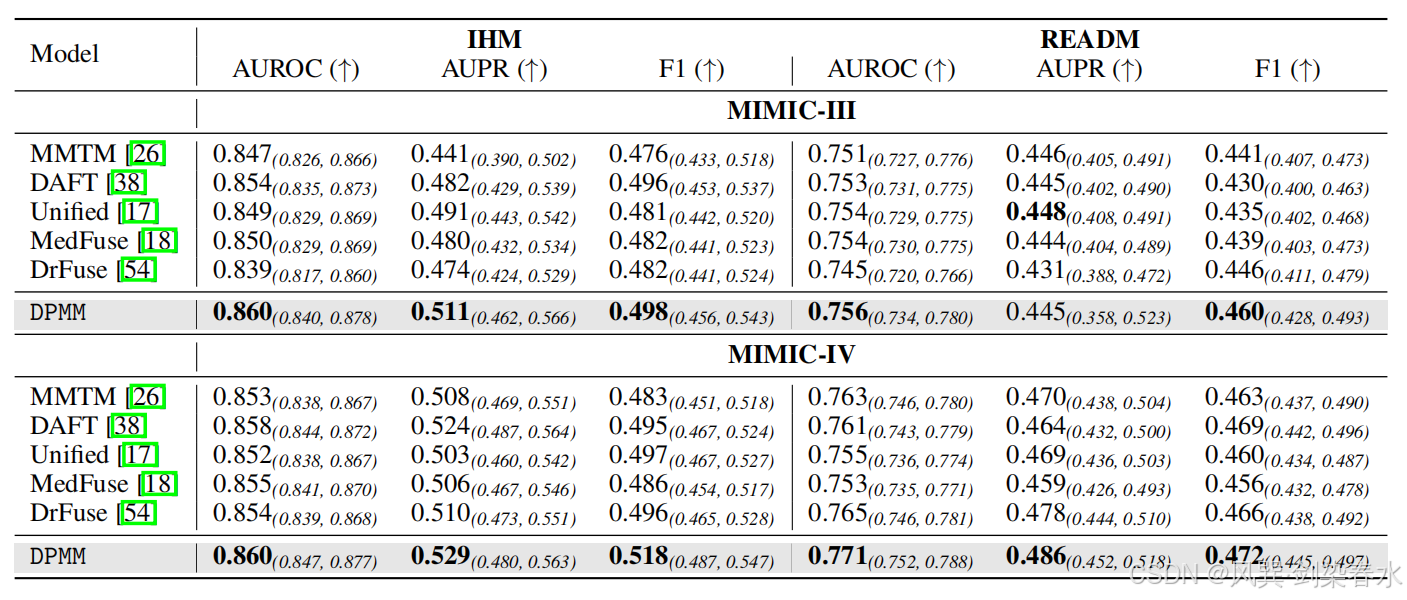
Table 4 | 不同模态组合设置下,MIMIC-IV 再入院预测任务的 AUROC、AUPR 指标结果:

Table 5 | 两个通用多模态数据集(CMU-MOSI、POM)上的性能对比结果(单位:%):
**Figure 5 | M M M 个模态各自排名前 2 混合分量的对数密度值直方图:**可以观察到,狄利克雷过程(DP)能够依据特征分量的显著性程度,对每个模态内的特征分量完成排序。
**Figure 6 | MIMIC-IV 再入院预测任务下,不同截断分量数 K K K 与浓度参数 η \eta η 对应的 AUROC 性能曲线:**每条曲线对应一组不同的 η \eta η 取值。
**Table 6 | 本文所提方法不同模块(如梯度保持采样、融合模块)的消融实验结果:**在 MIMIC-IV 数据集上以 AUROC、AUPR、F1 为评价指标,并附带 95% 置信区间。
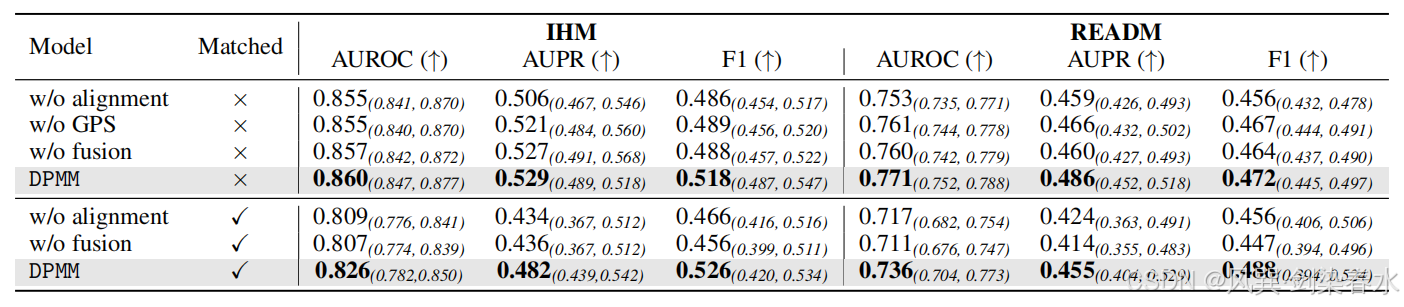
**Table 7 | 对齐损失项消融实验结果:**在 MIMIC-IV 数据集上以 AUROC、AUPR、F1 作为评价指标,所有结果均附带 95% 置信区间。

又学会一个分类小技巧(●'◡'●)