基于b站锋考视频
必备知识
第一章:
算法的5个特性
利用栈求解迷宫
数组:
考试时注意开始是1还是0
树:高度问题不考
三个必会公式:
(1)n=度之和+1;度之和=分支数
(2)n=n0+n1+n2+nm;(下标)
(3) 度之和=1n1+2n2+...mnm(下标)
第一章:数据结构与算法

数据相关概念

举完整串联例子
一张班级学生 Excel 表:
- 整张表格里所有内容属于数据;
- 全班所有学生行构成数据对象;
- 其中一行(单个学生的整行信息)是数据元素;
- 这一行里的 "学号""姓名" 单独单元格是数据项;
- 学生行之间按学号排序的前后关系、表格怎么存在电脑里、怎么增删查改这些规则,就是数据结构
层级关系梳理(从上到下粒度由大到小)
数据(宽泛所有符号)→ 数据对象(同类数据元素集合)→ 数据元素(单条记录)→ 数据项(记录里最小字段)
题目:

D

D
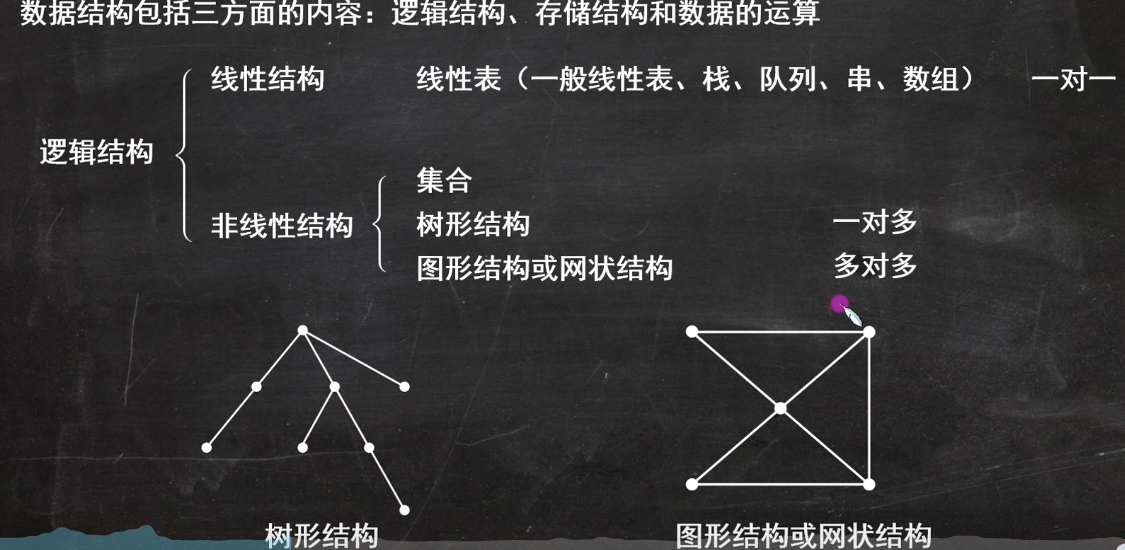
数据结构(逻辑,存储,数据的运算)

集合,线性,树形,图型
题目:

D

题目:


有顺序,链式,索引,哈希就是存储结构,
然后就是有序表只是描述逻辑关系,所以可以顺序,链式储存
算法

题目

算法目标

正确结果,看得清楚,对异常做出处理,时间存储效率
时间复杂度与空间复杂度

题目



练习题

B x C B

一对多 ✔ A
7.C
先区分概念:
- 存储结构(物理结构):顺序表、哈希表、单链表,描述数据在内存的存放方式,对应 A、B、D;
- 逻辑结构:有序表描述元素之间逻辑上的先后有序关系,和物理存储无关,选C. 有序表
第八题出错了

有穷性 确定性
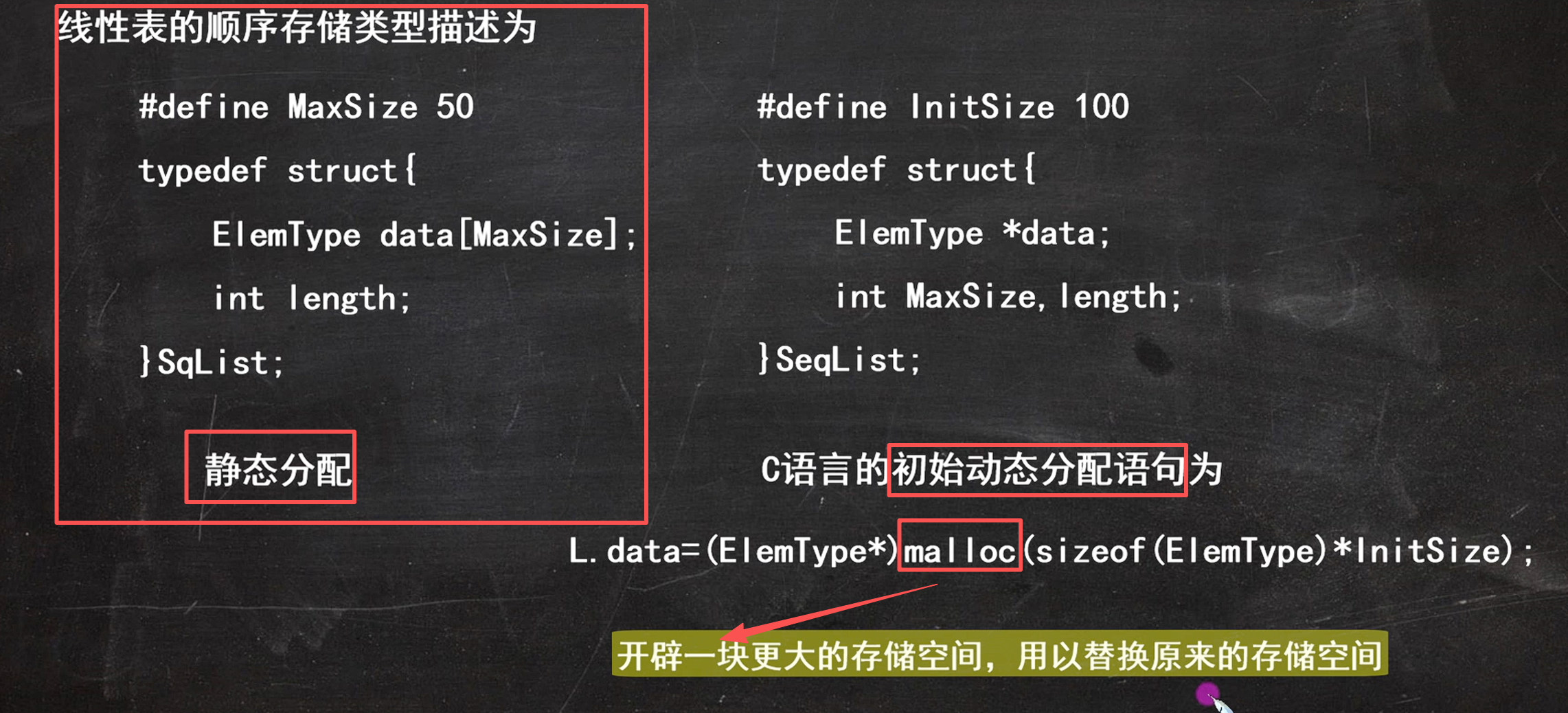
第二章:顺序表
1
线性表概念

题目

线性表基本操作


题目:注意题2

2

**随机存取(最主要特点)**的定义:只要给出元素的序号,就能直接算出它的内存地址,一步定位到目标元素,和前面有多少个元素无关,时间复杂度稳定是\(O(1)\)
题目

3
插入
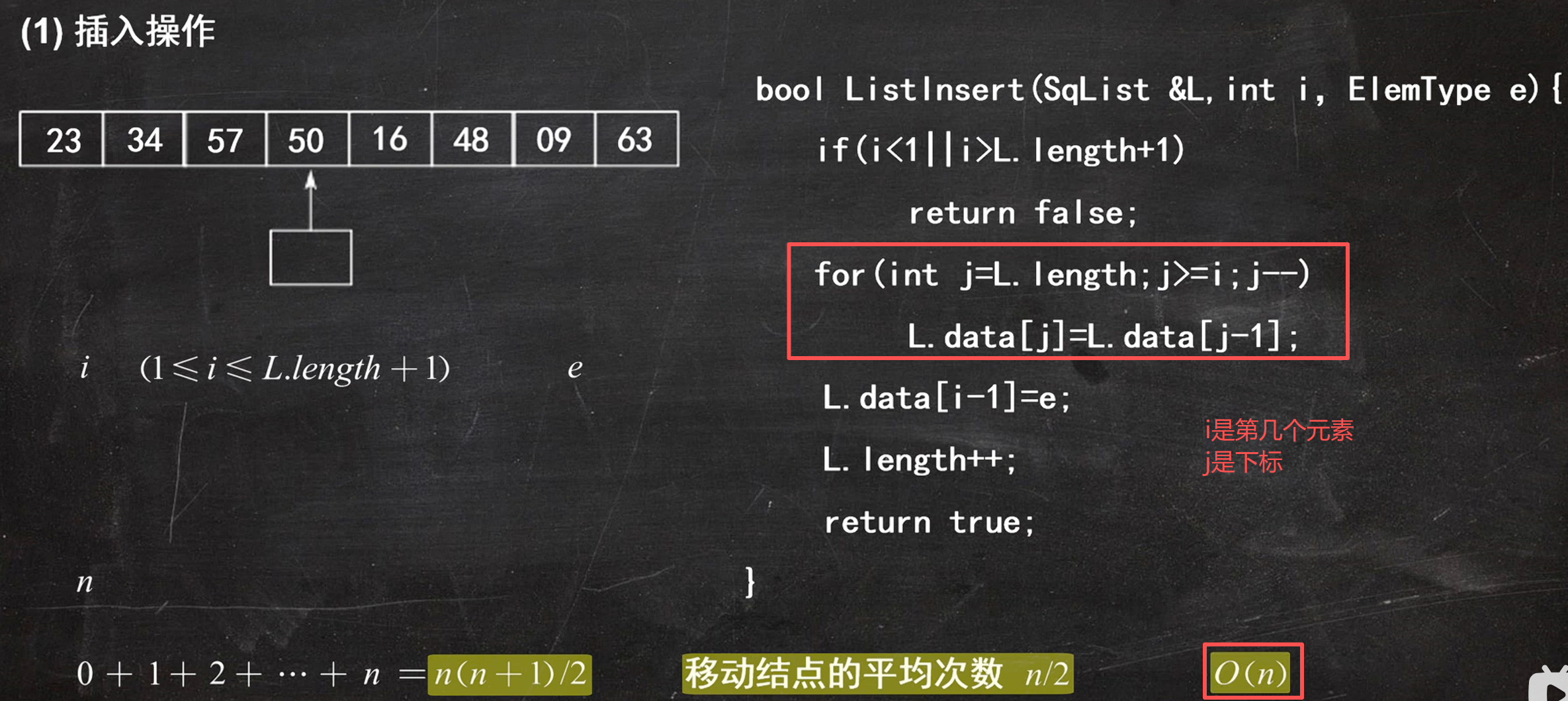
题目:

删除

题目:

按值查找

按位置查找

题目:

练习题:注意7

x A A A ✔

A D
D 错误:线性表长度n可以为 0(空线性表),不是必须(n≠0)

1340:85*4【注意是20个每行】
第三章:链表
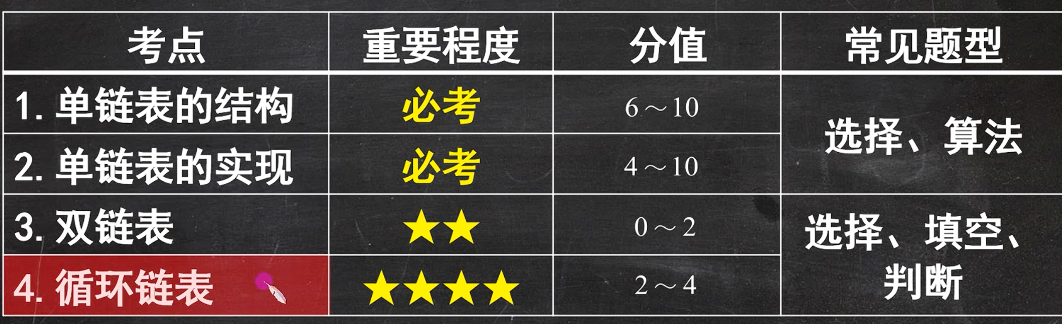
1

 ;
;
题目:

题目2解析:
如果对一个不带头节点的单链表进行操作,这个时候我们需要把第一个元素节点和后面的元素节点进行分类【麻烦】
那如果说增加一个头节点之后就不需要进行分类了
2


题目

红框重点
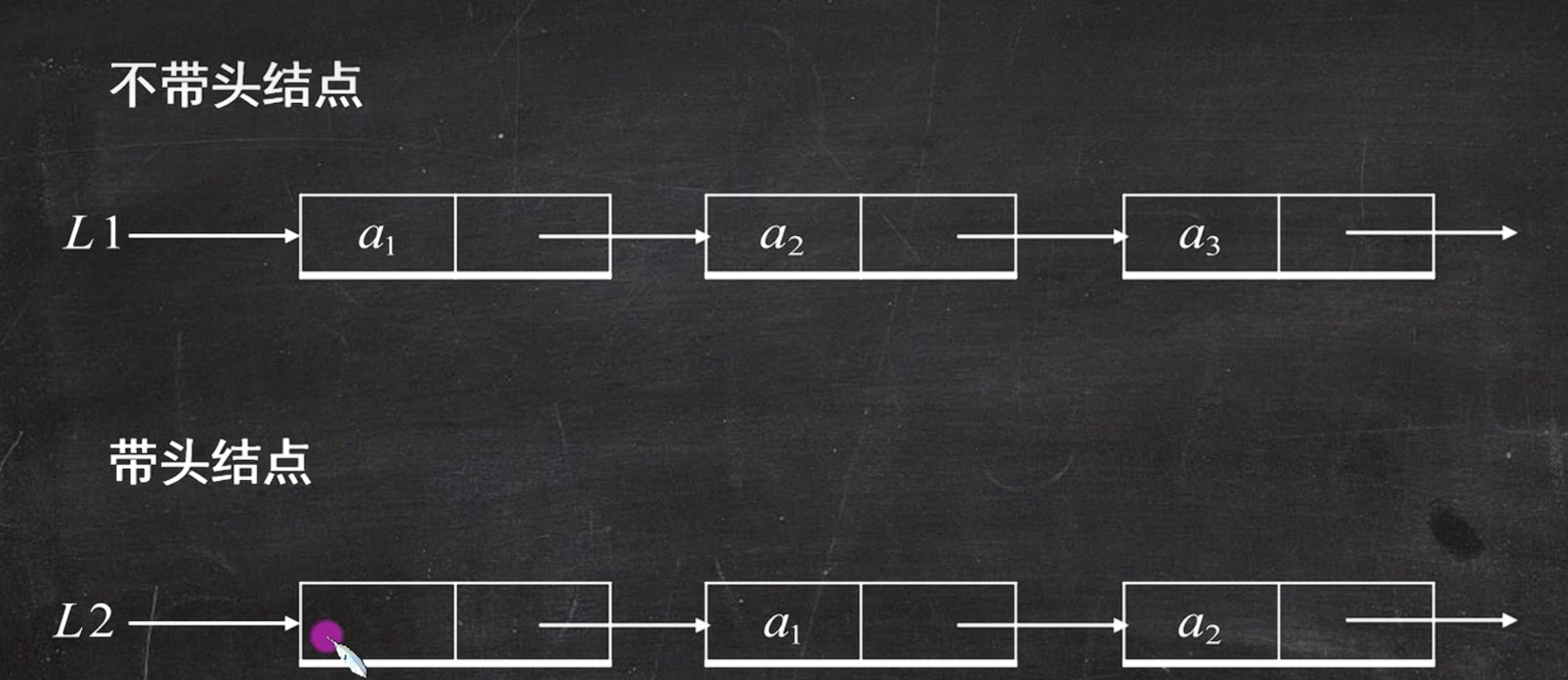
单链表插入第
i个位置,常规做法是找到第i-1个结点p,把新结点s插在p的后面,这叫后插 (插在p的后继位置)。而前插 ,指的是把新结点
s插在p结点前面 (p原本的位置),但单链表只有next后继指针,无法直接让p的前驱指向s,所以用了「换值模拟前插」的技巧,因此得名前插操作。
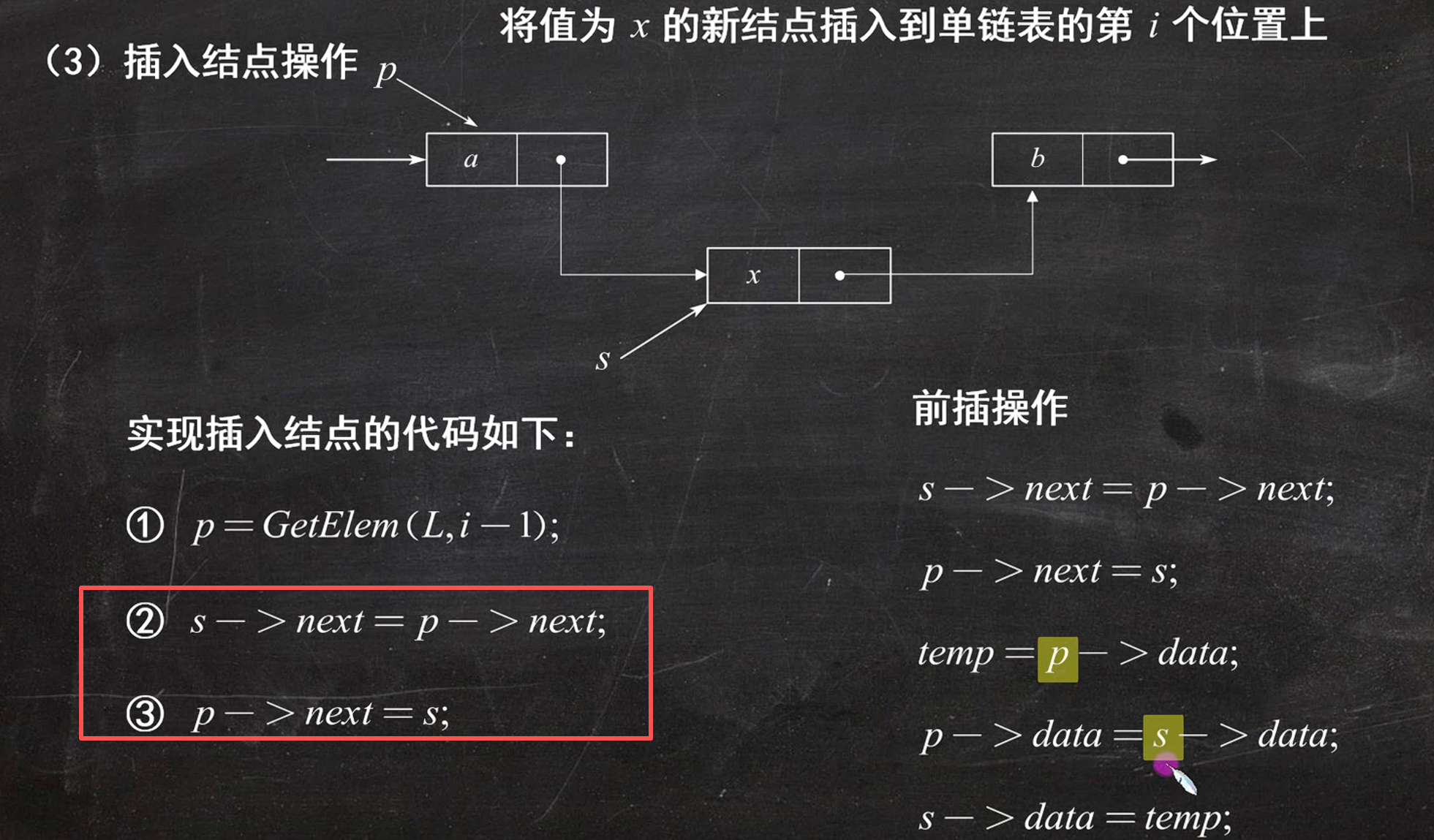
题目:注意
注意:
如果没有单独变量 p ,只靠
q->next访问 p,顺序就不能颠倒

3
题目

相关操作:
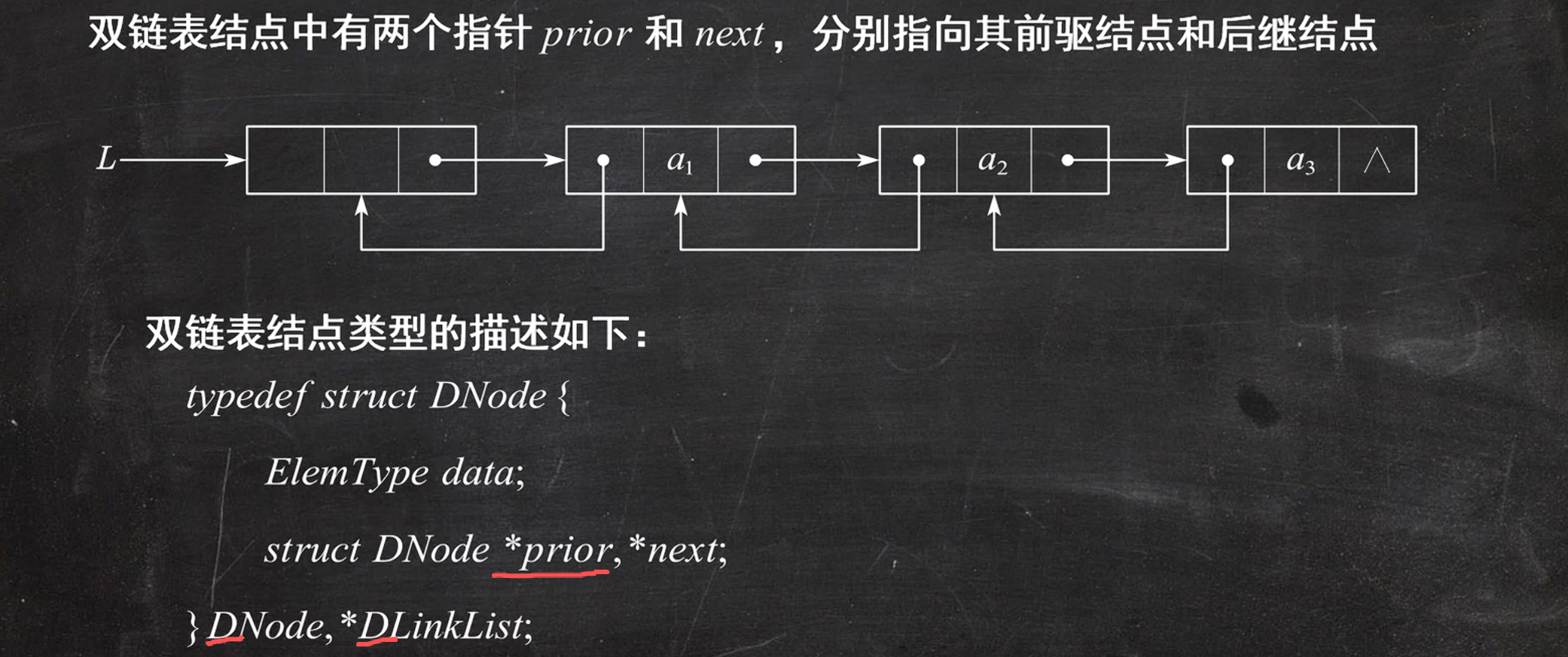
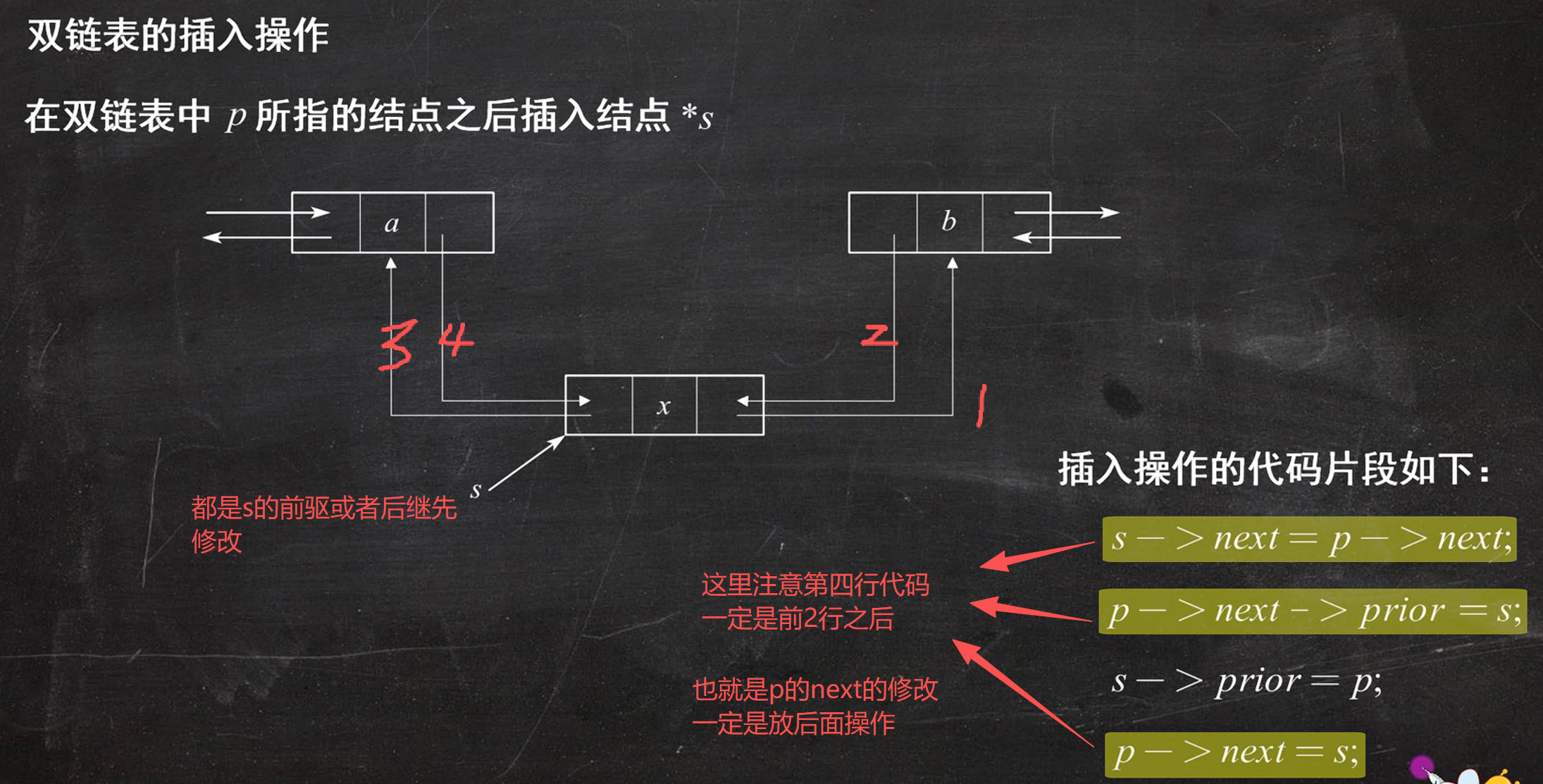
双链表插入(重点)
p指针的修改尽量放在后面
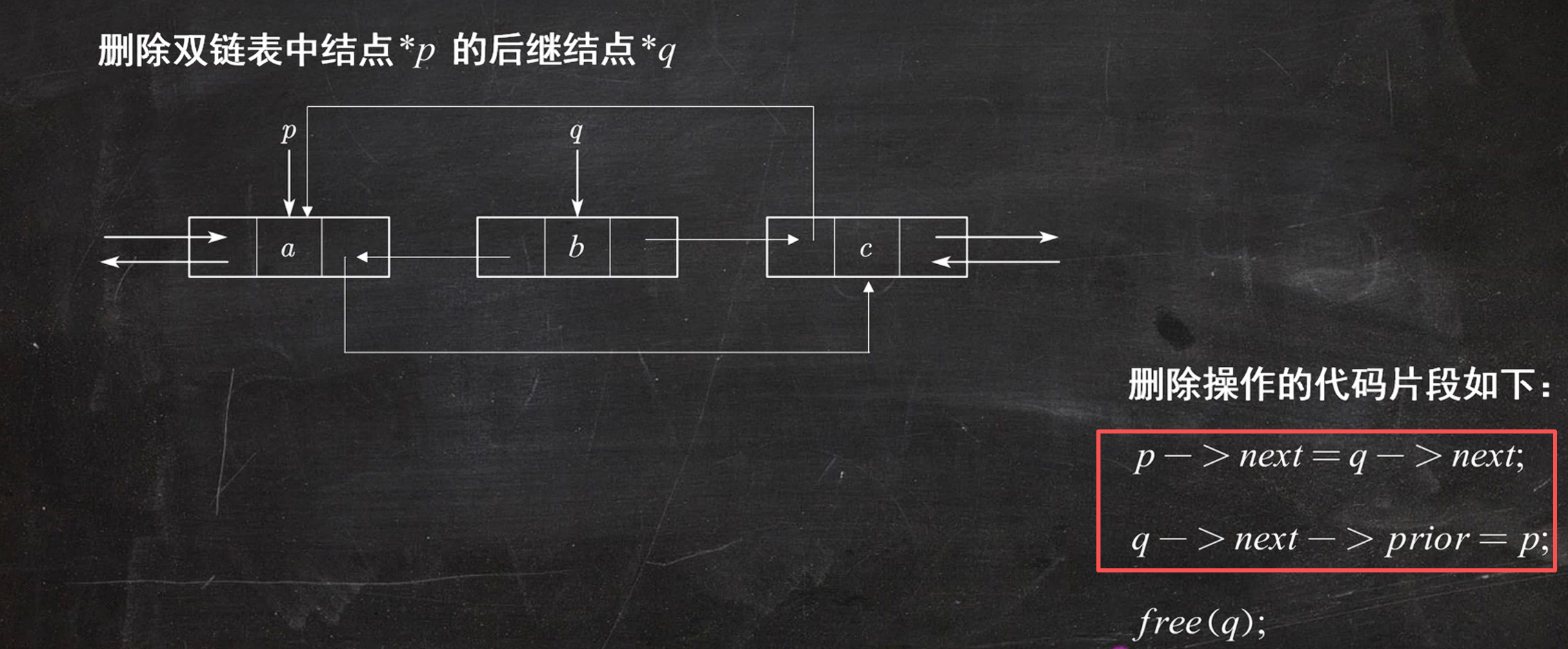
双链表删除(重点)
改一个前驱和后继即可
4
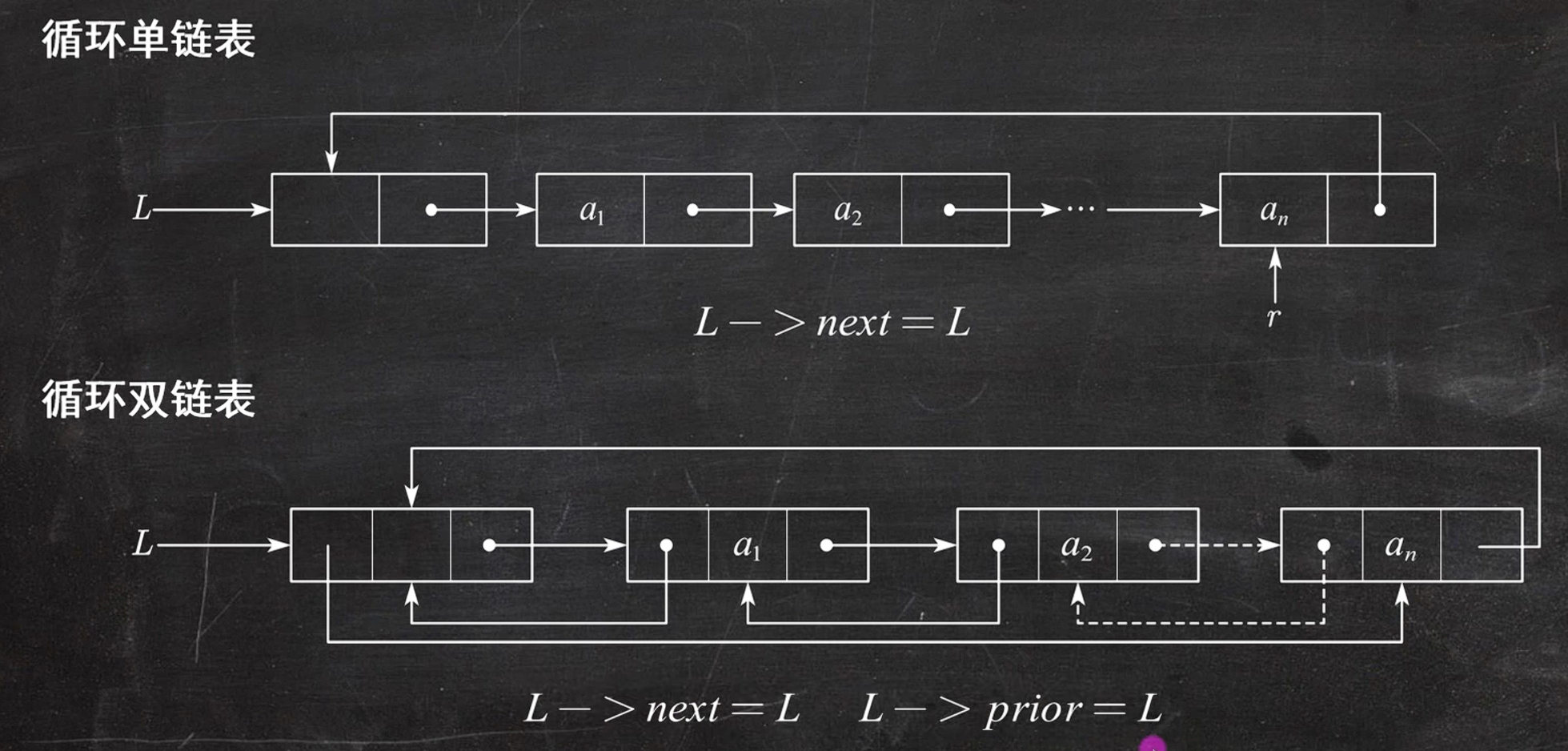
题目

循环单链表都有后继
循环双链表都有前驱和后继
对比:非循环

注意
循环链表不会有null出现
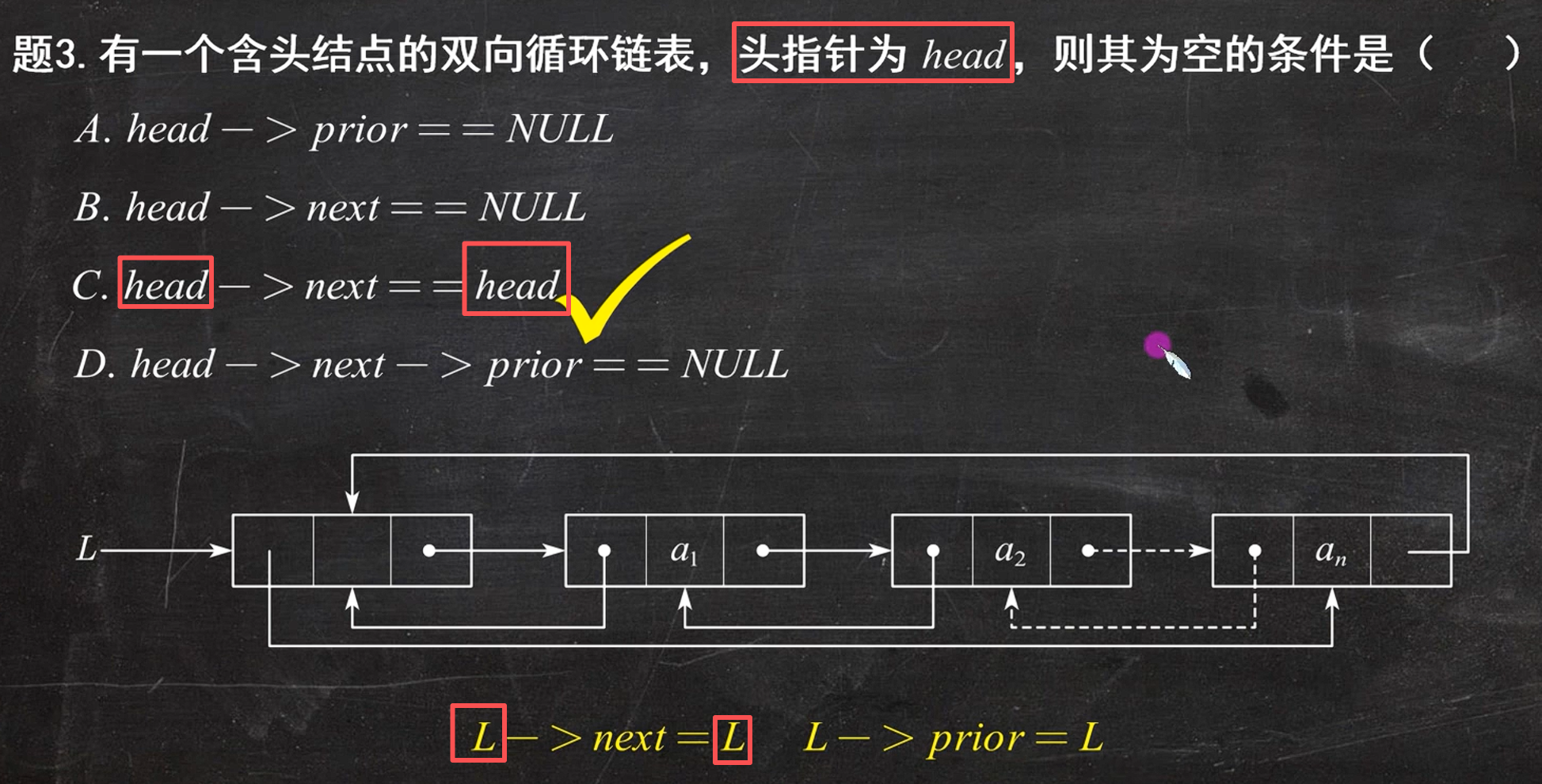
带头结点的循环单 / 双链表,正常状态下全程不会出现
NULL。它是闭环结构:尾结点的next会指回头结点,头结点的prior(双链表)也会指向自己 / 尾结点,不存在指针指向空的情况,所以选项里带==NULL的 A、B、D 错误
- 普通非循环链表判空:
head->next == NULL- **循环(单 / 双)链表判空:**循环链表依靠指针闭环实现遍历,全程不用 NULL 做结束标记,这是和普通链表最大的区别
单:
head->next == head
双:head->next == head
head->prior == head

练习题 注意2 3 6 7 8

D ;✅ ; 考s插入到p的前驱位置: p->prior p->prior->next【根据节点都是有2前2后的特点得到】; B
第二题
×(错误)解析:顺序表支持随机访问、存储密度高;链表插入删除高效但随机访问弱。二者各有适用场景,不能直接判定顺序表不如链表。

C ; 对 ; O(1) ;B ; x
第 6 题
错误(×)解析:线性表分为顺序存储和链式存储,二者的数据元素都可以是简单类型或复杂结构体类型,不存在 "线性表只能简单类型、链表才能复杂类型" 的限制,说法错误
第 7 题
需要先遍历找到链表B的尾结点,遍历次数为m,之后直接把B尾结点的 next 指向A的头结点即可,时间复杂度由遍历B的长度决定。答案:(O(m))
第 8 题
- 顺序表表头插入要大量后移元素,效率低;普通单链表、头指针单循环链表找尾结点需要遍历。
- 尾指针表示的单循环链表,可直接访问表头和表尾,首尾插入都能高效完成。答案:C
一、头指针表示的单循环链表(只有 head)
结构:
head固定指向头结点 链表闭环:头结点 → a₁ → a₂ → ... → aₙ → 头结点
- 找表头 :直接
head->next,一步拿到第一个元素,表头插入快- 找尾结点 aₙ : 没有指针直接指向尾,必须从头结点
head顺着next一路循环遍历,直到结点的next == head,才能找到尾。 时间复杂度\(O(n)\),尾部插入 / 删除效率极低。
二、尾指针表示的单循环链表(只有 rear,rear 指向尾结点\(a_n\))
闭环不变:
头结点 → a₁ → a₂ → ... → aₙ → 头结点现在rear直接存尾结点\(a_n\)的地址1. 一步拿到表头、一步拿到表尾
- 表尾结点 :直接
rear,不用遍历- 表头第一个元素 :
rear->next->next拆解:rear= 尾结点\(a_n\)rear->next= 头结点rear->next->next= 第一个数据结点\(a_1\)
重点

这里判断后续结点数据和基准
temp是否相等,相等就直接后移跳过:填:p->data == temp
这里循环批量删除所有值等于
temp的重复结点:填:p->data == temp完整逻辑说明
- 外层
while(p!=NULL)遍历每一个保留下来的基准结点;temp = p->data记录当前要保留的数值,q标记基准结点位置;- 第一个
if先快速跳过连续重复项;若不相等进入else,用内层while循环把后续所有同值结点逐个释放空间;- 最后让
q->link接上不重复的新p,完成链表去重。
第四章 栈和队列
重点:迷宫
右→下→左→上顺次探,有路就进压栈存;
碰壁回头出栈退,全路走完得解痕;
标记走过防死循环,栈空代表无路径。
极简速记版(考试填空 / 简答)
四向顺搜、入栈存点、碰壁回退、标记防重、栈空无解
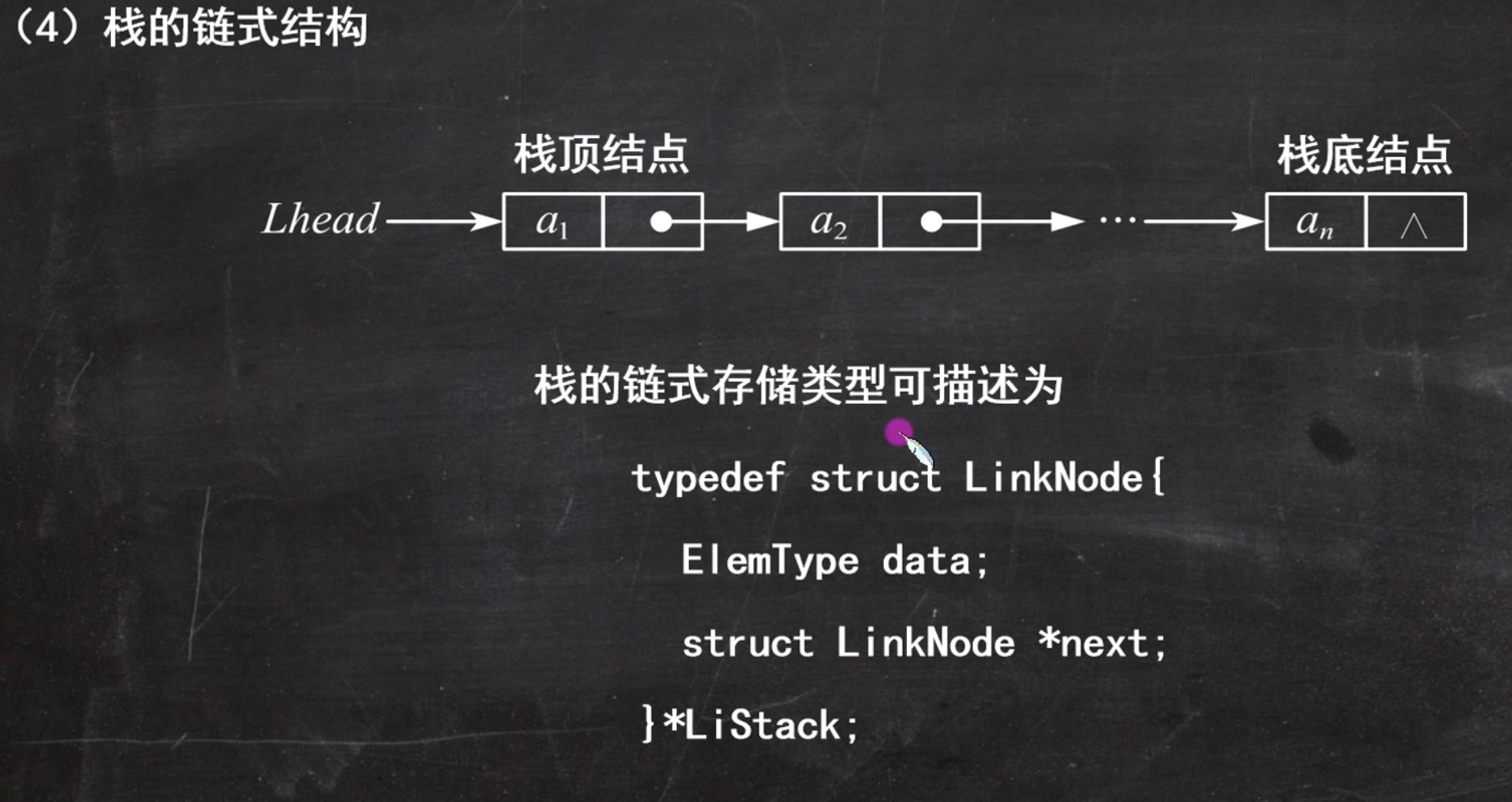
1

栈底不允许插入或者删除
题目:重点2



2
顺序栈:用数组考虑
固定不变的底端是栈底,top 指针指着的最靠上的有效元素位置是栈顶
- 入栈:新元素放到
top的下一个位置,再更新top指向新元素; - 出栈:先取出
top指向的元素,再把top往栈底方向回退一格。

题目


题目:重点

任意一个元素x,它后面比x小的元素,必须是严格逆序递减出现的(因为小元素先进栈、被压在x下面,只能从大到小往外弹)

题目


题目:不鸟

题目

3
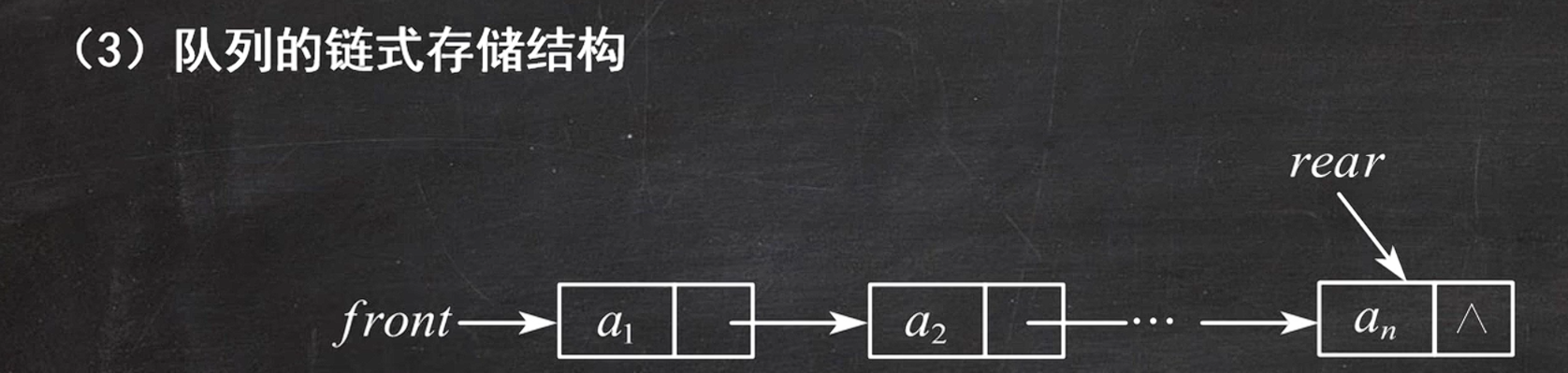
队列是一端插入一端删除,栈是只能在同一端插入或删除
- 队首(front) :最先进入队列的元素,出队(删除)只在队首操作
- 队尾(rear) :最后进入队列的元素,入队(新增)只在队尾操作

题目


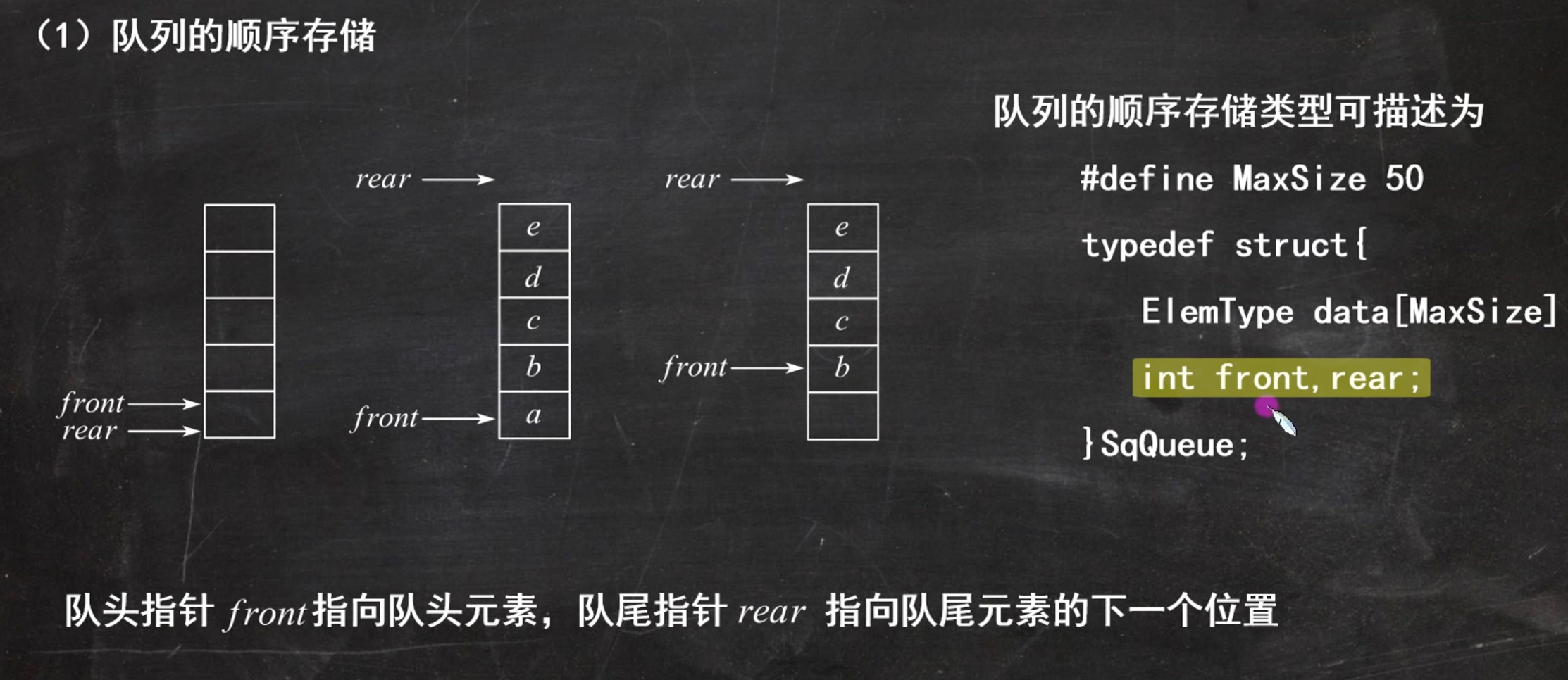
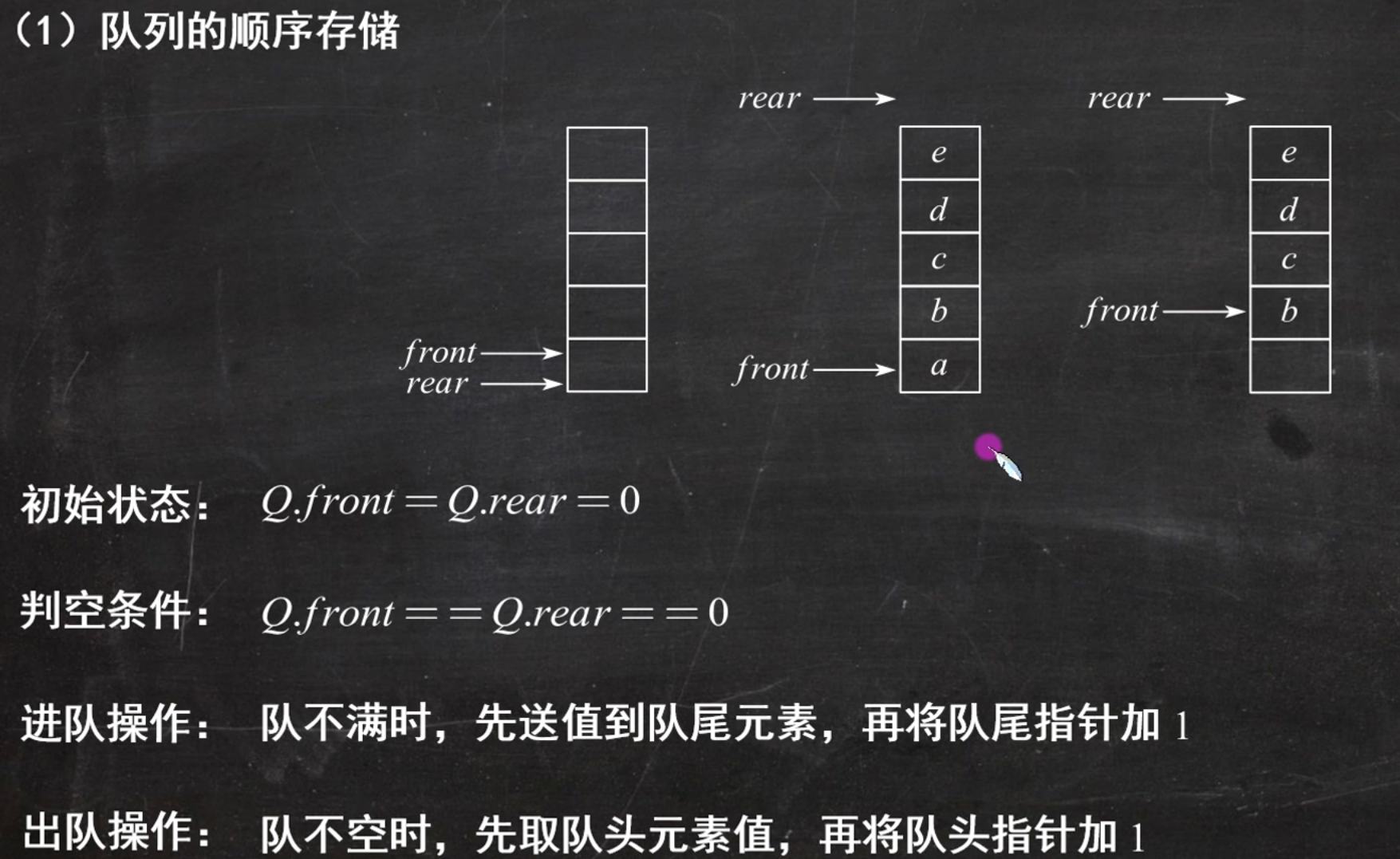
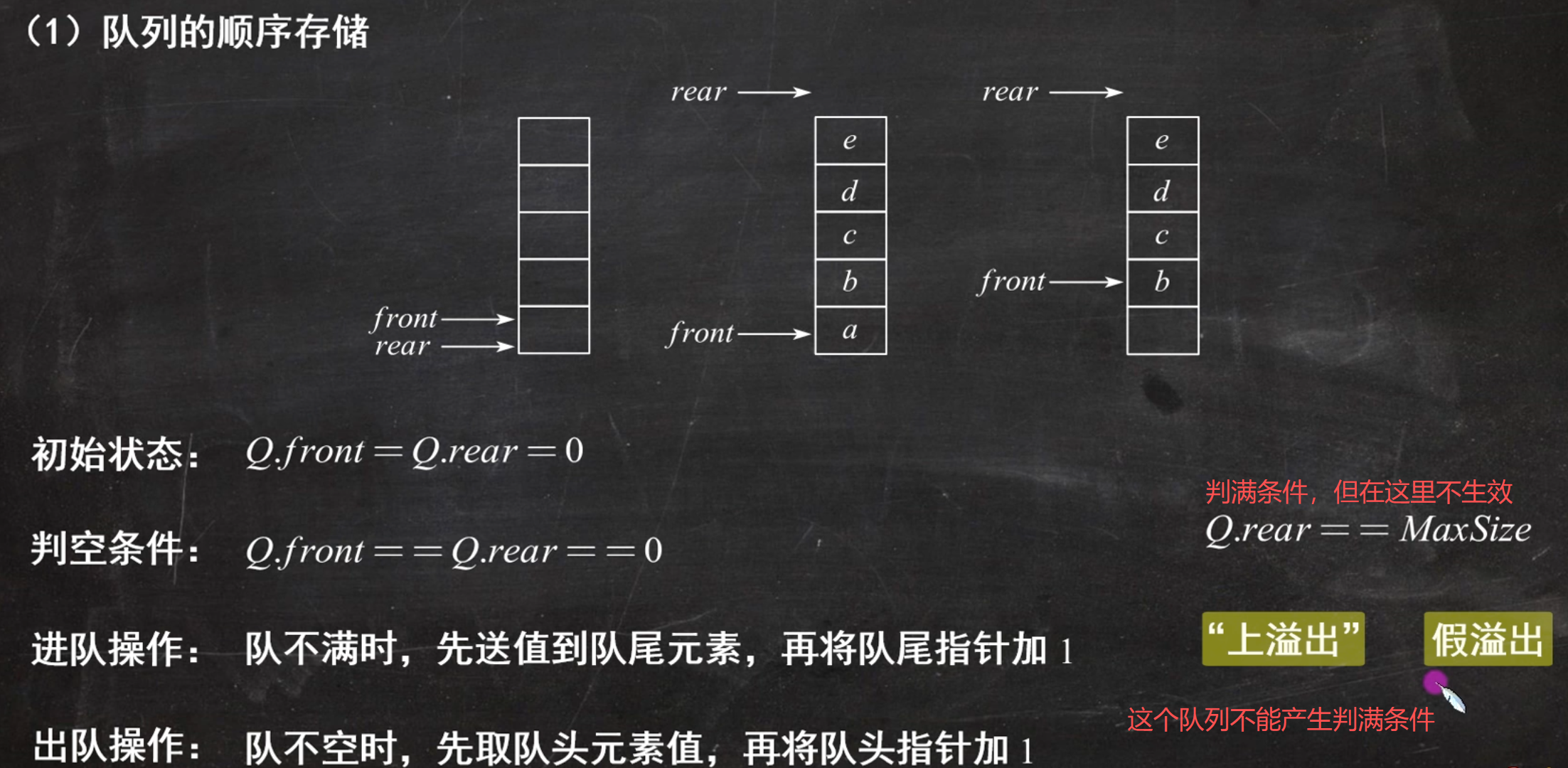
重点

入队出队都+1
关于队列长度:
长度 = (Q.rear + MaxSize - Q.front) % MaxSize作用:防止rear < front(rear 绕到 front 前面)时出现负数。 举例:MaxSize=6,front=5,rear=1肯定是尾部-首部

队满条件不能和队空条件一样,所以要多用一个位置存空值来区分队空和队满
注意:
用循环队列存储,只能存储最大容量减一的数据元素
题目

4
题目

练习题:注意4

第三题求Pi
A ; x ; C ;B
两个栈共享一片向量(数组)空间,两个栈从两端向中间生长,能灵活利用空闲空间,节省存储空间,相比单独分配固定空间,大幅降低了栈满上溢的概率;存取时间不会缩短,也不影响下溢(栈空出栈才会下溢)概率
分开开数组时,单个栈容量固定,容易提前存满溢出; 双栈共享同一整块内存,两个栈的空闲空间可以互相借用,同等总内存下,填满整块数组的难度大大增加,栈满上溢发生概率大幅降低。

A ; 3 ; n-1 ; C

B
第五章 串
1

注意连续子序列
题目

题目

2:重点

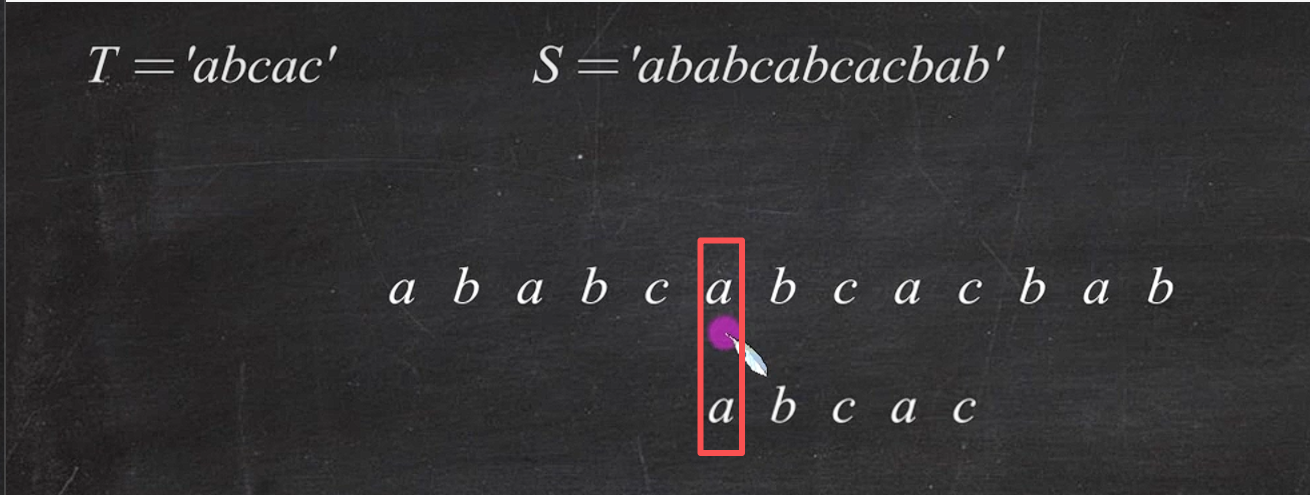
返回6,代表匹配的是第六个也代表匹配了6次
KMP
串的模式匹配:在主串 S 里找子串 T 第一次出现的位置
KMP 两个核心模块:
模块 1:预处理模式串 T,生成 next 数组(最难、考试重点)
next 数组只和模式串 T 自己有关,和主串 S 无关。 定义:
next[j]表示:T 的前 j 个字符构成的子串,最长相等真前缀、真后缀的长度。
- 真前缀:不能包含最后一个字符
- 真后缀:不能包含第一个字符
- 相等:前缀和后缀字符完全一样
next 数组有什么用?
匹配时如果 S[i] ≠ T[j],不用 j 回到 0,直接令 j = next[j],跳到能复用的前缀位置继续对比,前面匹配成功的部分不再重复比较。
模块 2:匹配过程(i 不回退,只调整 j)
- 指针 i(主串 S)、j(模式串 T)都从 0 开始;
- 两种情况: ①
S[i] == T[j]:i++,j++,继续下一位; ②S[i] != T[j]:j = next j;若 j=-1,说明首位都不匹配,i++、j++;- 终止:j 走到 T 的长度,说明匹配成功;i 走完 S 仍没匹配,匹配失败
总结:
提前算出模式串的重复前缀信息存进 next 数组,匹配失败时,主串指针不回头,利用已匹配成功的重复前缀,让模式串指针直接跳到下一个可对比位置,消除暴力匹配的重复比较
3


题目

该公式适用于二维数组下标从1开始,一维数组从0开始

题目


题目

练习题:5 6 8 9

A ; B ; BC

22,like coffee and child ; A ; 模式匹配 ; D
5.普通线性表可以针对单个元素插入 / 删除;串的操作大多以 ** 子串(串整体)** 为操作单位,比如删除一段子串、插入一段子串。
答案:A
7.


C ; B; D
这里说了按行优先存储
第六章 树和二叉树
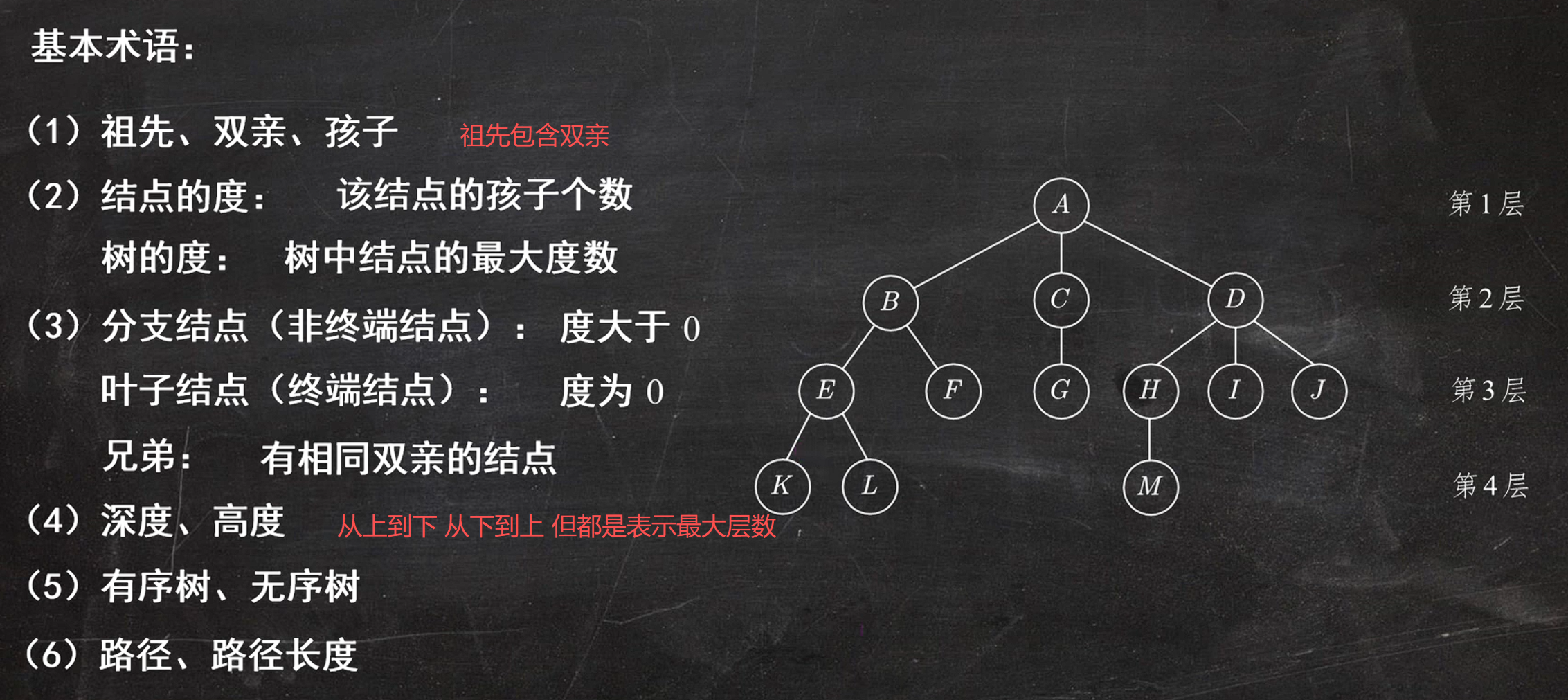
深度看离根有多远 ,从上计数;高度看离最底层叶子有多远,从下计数。