引言
智能体时代的核心是算力及生产 "聪明的 Token"。专为 Agentic AI 工作负载设计的推理引擎会是 Agent 时代基础设施竞争的一个焦点。
背景:随着 Coding Agent 的蓬勃兴起,AI 的角色正在从 "问答工具" 转变为 "持续运行的办公 / 软件协作者" 。以 Claude Code、Codex、Cursor 等为代表的产品,让单次会话轻松突破 50K Tokens,系统负载日益转向更极端、更复杂的智能体工作负载 ,对话也经常跨越数十轮 。大多数公开基准测试并不能充分捕捉这种行为,这种转变让算力压力变得前所未有地突出,但同时也为算力架构的创新与基础设施的升级打开了重要的机遇窗口。
TokenSpeed 是什么?
在 Coding Agent 等智能编码工具带来的机遇下,一支来自 LightSeek Foundation(https://x.com/lightseekorg)的小团队,仅用两个月时间就打造出了一款全新的、号称 "光速" 的大模型推理引擎 ------ TokenSpeed(https://github.com/lightseekorg/tokenspeed)。

TokenSpeed 的性能可与 TensorRT-LLM 媲美,易用性则与 vLLM 相当;同时,它还提供了目前 NVIDIA Blackwell 上最快的 MLA 注意力内核,这就是 NVIDIA 也力荐的原因。

TokenSpeed 的出现,旨在通过更现代化的架构设计,突破传统推理框架在易用性与极致性能之间的折衷。从功能层面看,TokenSpeed 是一个新兴 LLM 推理 / 服务引擎:只需提供大模型权重,它就能对外提供高并发、低时延的 Token 生成服务,接口兼容 OpenAI API,并配有 serve 命令行工具。
从底层设计理念来看,它更像一个专为 "智能体(Agentic)工作负载下的数据搬运与 CPU 开销" 进行深度优化的计算引擎。围绕这一目标,它有四项关键的技术决策:
- MLA + FP4 + MoE 三重压缩,将解码阶段的显存带宽压力降到最低(解码的性能瓶颈主要在于显存带宽);
- 基于 C++ 类型系统的 FSM 调度器,在编译期保证 KV 资源安全,同时将 CPU 调度开销压至极低水平(这是维持高生成速率的关键),CUDA Graph + 双流重叠循环 + GIL-free Rust 网关 SMG;
- 自动生成集合通信的 SPMD 建模层,让 "编写模型" 与 "编写并行策略" 解耦(这决定了系统的可维护性与可扩展性);
- PD 分离架构搭配分层的多厂商算子注册表,让预填充和解码各得其所,且不被单一硬件平台锁定(这是保障部署灵活性的核心)。
一言以蔽之:TokenSpeed 将 LLM 推理中每一次字节搬运和每一微秒的 CPU 开销都视为可工程优化的对象,通过 MLA、推测解码、C++ FSM 调度、CPU 调度开销深度优化、自动并行和 PD 分离这套技术组合,尽力逼近 AI 硬件 Roofline,是一款面向 Agentic AI 的推理引擎。
TokenSpeed GitHub 链接:https://github.com/lightseekorg/tokenspeed
博客标题:TokenSpeed: A Speed-of-Light LLM Inference Engine for Agentic Workloads
博客链接:https://lightseek.org/blog/lightseek-tokenspeed.html
TokenSpeed 是一个新兴的大模型推理引擎,目前处于预览版阶段,尚未达到生产可用的成熟度。这一版本主要用于复现 TokenSpeed 官方博客中展示的 Kimi K2.5 模型在 B200 上的基准测试结果,以及其 MLA 实现(TokenSpeed MLA)在 B200 上的性能数据。项目的 README 明确声明:「Do not use this preview release for production deployments」(请勿将本预览版用于生产部署)。
从定位上看,TokenSpeed 介于研究性探索与生产级推理服务之间。它在并行逻辑自动化和调度安全方面提出了清晰的技术主张,但由于仍处于预览期,公开的基准测试数据以及所支持的模型覆盖范围都还比较有限。
如果您是推理引擎开发者或 AI Infra 从业者,该项目所采用的 local-SPMD 静态编译思路值得持续关注;如果您是应用开发者,建议等待正式版本发布,或密切留意其后续的模型支持进展。
TokenSpeed 的架构设计与核心模块
TokenSpeed 想同时拿到两样东西:TensorRT-LLM 级别的性能 + vLLM 级别的易用性。
为什么 TokenSpeed 这个推理框架能那么快?TokenSpeed 的架构示意图如下所示:
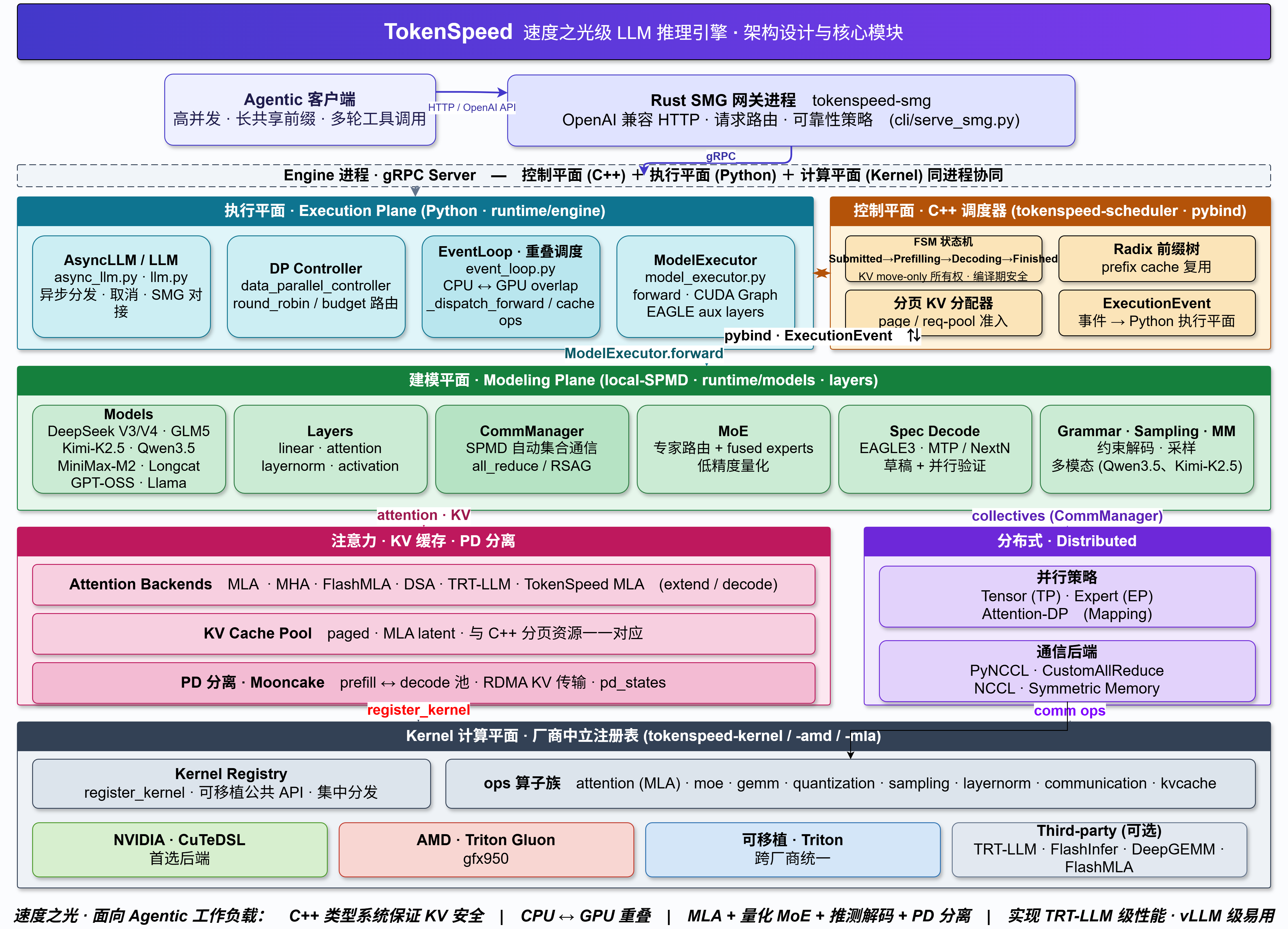
TokenSpeed 从第一性原理出发,专门为智能体工作负载推理场景设计。核心包括:基于编译器的并行建模机制、高性能调度器、安全的 KV 资源复用约束、支持异构加速器的可插拔分层 Kernel 系统,以及用于低开销 CPU 侧请求入口的 GIL-free Rust 网关 SMG 集成。
在结构上采用 "Python 执行平面 + C++ 控制平面(同进程)+ 厂商中立 Kernel 计算平面" 的三层解耦设计。这一骨架经过代码核实,完全属实。不过,围绕它的几项标志性 "卖点" 在代码中仅获得了部分支撑。
将介绍 TokenSpeed 的文章里表述拉回到与当前代码一致的精度(Commit ID:8a9a2c65604538f5faa5b929c679379a3fd59e41)。
-
关于"C++ 类型系统在编译期保证 KV 复用安全"
代码事实: 编译期真正保证的是资源所有权安全 ------ 通过删除拷贝构造函数、采用移动语义和 RAII,使得
OwnedPages/NodeRef等对象无法拷贝,析构时恰好释放一次,从而杜绝重复释放或别名问题。而状态迁移是否合法,则完全由运行期检查负责:每个事件继承InvalidTransitionHandler的兜底operator(),任意(event, state)组合都能通过编译,非法迁移只在运行时通过throw std::logic_error暴露(test_abort.cpp直接断言)。代码中并不存在编译期迁移表。客观判断: 该说法在 "所有权安全" 层面成立,但扩展到 "迁移安全" 就夸大了编译期的作用,宜表述为 "编译期仅保证资源所有权正确,状态迁移合法性由运行时动态检查"。
-
关于 "静态编译器从放置标注自动生成集合通信,用户无需手写并行"
代码事实: 相关编译器确实存在(
models/base/compiler.py+placement.py),可以基于REPLICATE/SHARD/PARTIAL标注自动插入AllReduce/ReduceScatter/AllGather等通信。但代码自身的 docstring 将其标为 "opt-in",并称CommManager为 "the default"。在 16 个DecoderLayer类中,仅 1 个(gpt_oss)真正走了该编译器路径;其余 15 个 ------ 包括旗舰 agentic 模型(DeepSeek V3/V4、GLM5、Qwen3.5/MoE 等)------ 全部采用手写方式,直接调用comm_manager.*甚至torch.distributed.all_gather。两条路径最终都归约到相同的运行时tp-size比较。客观判断: 自动并行编译器是一项已落地的基础能力,但目前只在极少数模型中作为可选特性被采用,主流模型仍以手写为主。将其描述为普遍自动化的默认行为,与现状不够吻合。
-
关于 "可插拔通信后端(PyNCCL / CustomAllReduce / NCCL / 对称内存)"
代码事实: 后端的类定义齐全,但默认启动路径中仅有原生
torch.distributed的 NCCL 真正生效(外加用于 token-aware 的 Triton RSAG,以及用于小尺寸 bf16 的 Triton AR)。PyNCCL、CustomAllReduce、Lamport/trtllm AR等后端没有被任何配置入口激活 ------initialize_comm_backend调用数为零,相关开关默认为False,disable_custom_all_reduce属于死代码。所谓 "对称内存" 也并非一个通用通信后端,而是 DP-sampling 的一条单边快路;--enable-symm-mem仅设置了环境变量NCCL_CUMEM_ENABLE。此外,引擎不包含流水线并行(PP)。客观判断: 多通信后端的框架已经预留,但当前默认状态下并未打通,"可插拔" 更像一个已铺好接口、待接入实现的方向,而不是开箱即用的特性。
-
关于 "fp4/fp8 量化 MoE 以削减 decode 显存带宽"
代码事实: 实际端到端打通的量化格式共有 5 种:
unquant、fp8、nvfp4(FP4)、mxfp4(FP4)、mxint4(仅权重 INT4)。原表述中的 "fp4/fp8" 漏掉了 INT4 格式。同时,MoE 代码中并未出现 "decode" "HBM" "带宽" 等关键词 ------ 该效果属于合理的性能推断,而非代码中的明确声明。客观判断: 量化支持的覆盖面比表述更广,但对解码带宽的强调偏向推断,原文在完整性上略有欠缺。
进程拓扑与三平面结构(已核实)
- 进程拓扑:通过
ts serve(serve_smg.py)编排,拉起两个 OS 进程 ------ SMG HTTP 网关(python -m smg launch,承载 OpenAI 兼容 API、路由、tool-call 解析)与 gRPC 引擎(smg_grpc_servicer.tokenspeed);引擎再为每个 GPU fork 一个 scheduler worker 进程,运行事件循环。整体链路为:网关 → gRPC 引擎 → 各 GPU worker。 - 三平面同进程:在每个 worker 内部,控制平面(C++ 调度器,以 nanobind 扩展形式嵌入,单地址空间、无 IPC)、执行平面(Python 事件循环)和计算平面(kernel)均位于同一进程内。控制与执行同进程协同这一关键设计属实。
核心模块(精确陈述)
① 控制平面 · C++ 调度器 (已验证)
请求生命周期建模为一个包含 13 种状态的 std::variant 有限状态机(Bootstrapping → ... → Decoding → ... → Finished)。事件以右值方式消费旧状态,将 KV/页所有权句柄 move 到新状态。调度器同时持有 radix 前缀树和分页分配器。安全性边界如上文所述:编译期保证 move-only 资源所有权,迁移合法性由运行时异常机制兜底。
② 执行平面 · 重叠事件循环 (部分实现)
Python 循环通过 next_execution_plan() 获取执行计划,ModelExecutor 运行前向(CUDA Graph 按 batch 分桶),再以 advance(ExecutionEvent) 回灌结果。event_loop_overlap 在独立 CUDA stream 上先发射当前步前向,再同步提交上一步结果(推迟 copy_event.synchronize()),实现 CPU 后处理与 GPU 计算的深度-1 重叠。需注意,eager-grammar 批、DP idle-forward 等场景会改变提交顺序,且 prefill-PD 与 spec+paged-cache 下整体禁用重叠。
③ 建模平面 · SPMD (已验证并校准)
并行编译器真实存在但为 opt-in 模式(仅 gpt_oss 使用),主流模型通过 CommManager 手写 per-layer 的 all_reduce 或 reduce-scatter + all-gather,选择依据是注意力 TP 与 dense/MoE TP 是否相等。
④ 注意力 · MLA (经阅读核实)
采用自注册多后端表 _BACKEND_REGISTRY,按 AttentionArch ∈ {MLA, MHA, DSA} 分派。MLA 存储压缩的低秩潜在 KV(每 token 一行 latent),以降低 KV 缓存占用和带宽压力,配有独立的 tokenspeed-mla 包与 kernel。DSA(DeepSeek 稀疏注意力)架构同样被支持。
⑤ MoE · 量化 (部分实现)
MoELayer 将每个专家的 GEMM1 → SwiGLU → GEMM2 融合,并由注册表按 (weight_dtype, arch) 选择相应 kernel。已支持的格式为前述 5 种(含 INT4),后端覆盖:trtllm fp4/int4/fp8 对应 Blackwell,gluon mxfp4 对应 AMD gfx950。
⑥ 推测解码 (已验证)
实现三种方法:EAGLE3 / MTP(NextN) / DFLASH。EAGLE3 与 MTP 共用同一 Eagle drafter(仅草稿模型结构不同)。过程为:自回归草拟 spec_num_steps 个 token → 目标模型一次并行前向验证 → 贪心线性链接受(argmax + cumprod 前缀,非 Medusa 树)。NextN 草稿覆盖 DeepSeek V3/V4、GLM5、Qwen3.5 等模型。
⑦ PD 分离 (已验证并校准)
prefill 与 decode 是两个单角色服务实例(每个进程一种 --disaggregation-mode),通过 HTTP + ZMQ bootstrap 配对;KV 由 Mooncake TransferEngine 的单边 RDMA 写从 prefill 推送到 decode。状态机中仅 Bootstrapping 一态为 PD 专属,其余复用通用 forward 态,PD 行为通过事件(BootstrappedEvent / RemotePrefillDoneEvent / SucceededEvent)表达。
⑧ 分布式
并行轴包括 TP / EP / attn-DP(以及由环境变量门控的 CP),无 PP。实际生效的通信后端为原生 NCCL + Triton RSAG/AR。MoE 不允许 TP 与 EP 同时大于 1。
⑨ Kernel 注册表 (部分实现)
单例 KernelRegistry + @register_kernel(按 (family, mode) 注册 KernelSpec),select_kernel 根据平台 capability(vendor/arch/features)和优先级选择。对外提供 mm/argmax/moe_apply 等可移植族 API。后端涵盖 Triton(最丰富)、FlashInfer、TRT-LLM、DeepGEMM、CuTe-DSL、CUDA、Gluon、参考实现及 entry-point 插件;第三方依赖采用惰性 guarded import,保持可选。AMD kernel 独立为 tokenspeed_kernel_amd 发行包,由核心单向再注册(边界测试采用强制模式)。小瑕疵:FlashInfer/flash_mla 位于 ops/ 内直接 import,并非全部归入 thirdparty/。
⑩ KV 缓存 / 前缀 (经阅读核实)
分页 KV 缓存配合 radix 前缀树实现跨请求复用,形成三级层次:L1 设备内存、L2 主机(CPU)内存、L3 外部存储(Mooncake),与 C++ 调度器中的 radix 结构对应。
⑪ Agentic 外围
约束解码仅使用 xgrammar(支持 json/regex/ebnf/structural_tag,默认关闭,具备 reasoning-aware 能力);采样后端包括 flashinfer / flashinfer_full / greedy;多模态支持 Qwen3.5(图像+视频)和 Kimi-K2.5 VLM(AUDIO 仅声明未实际接入);监控方面依赖 Prometheus 并支持可选的逐请求统计;tool-call 解析放在 SMG 网关,不在引擎内部。
自动并行编译器在主流模型上尚未普遍启用,多通信后端的可插拔性在默认路径上还未实现,编译期安全仅覆盖资源所有权层面,而非完整的状态机验证。换言之 ------ TokenSpeed 在调度器、Kernel、MLA 和 PD 分离这条主干上的工程实力确凿可信;而 "全自动并行 + 可插拔通信 + 编译期安全" 则更像是已经打好了地基、但尚未全面接线的未来方向,并非当前默认形态。
深入了解 TokenSpeed 技术细节
代码仓 Commit ID:8a9a2c65604538f5faa5b929c679379a3fd59e41
Agent 流量与常规聊天 serving 在四个维度上存在本质差异,每一点都直接决定了工程资源的投向:
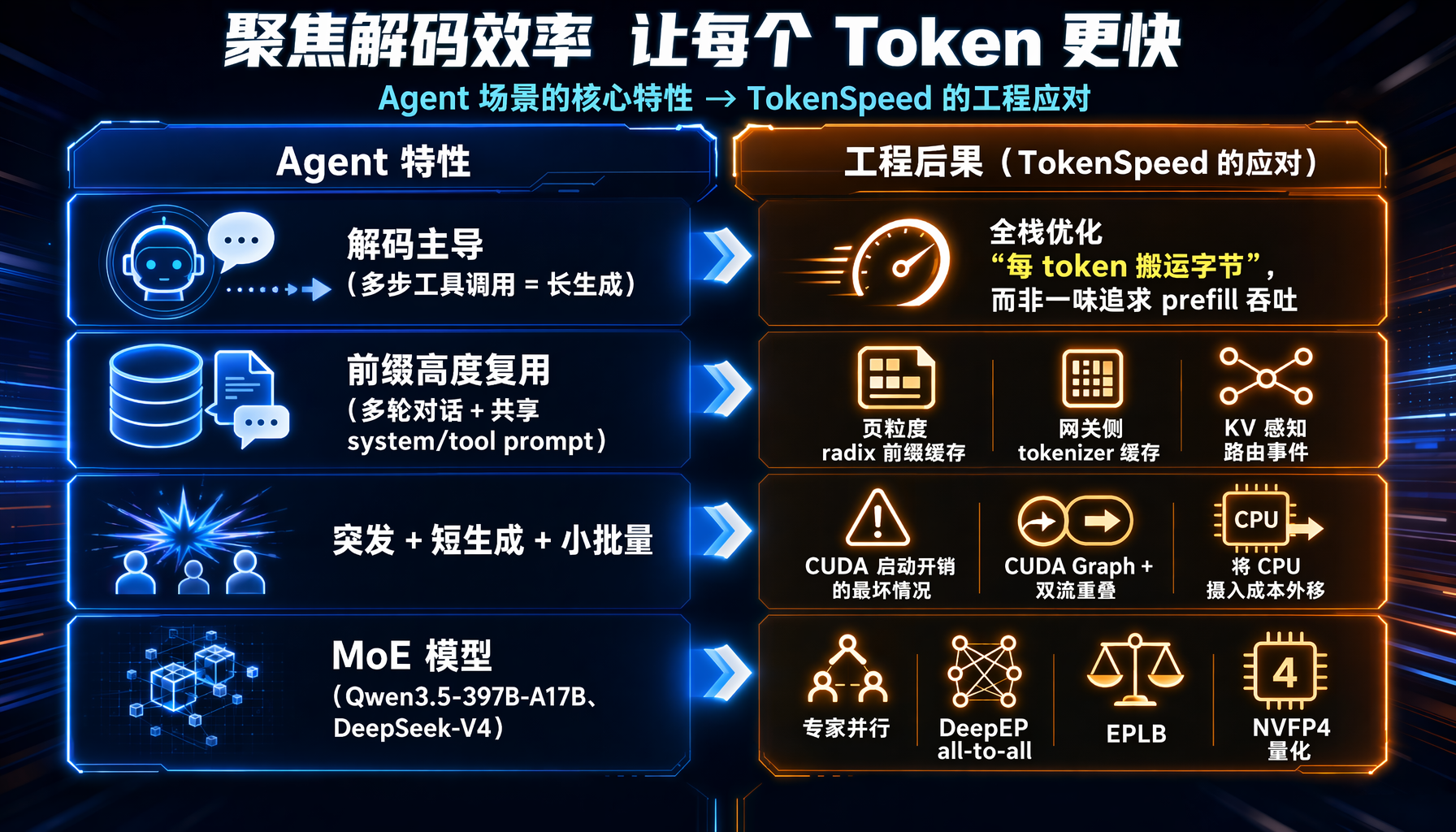
下文中的每个设计都可以回溯到这四行中的某一项。
最值得研习的十个设计(已落地、可迁移)
① 类型拥有的 KV 页 ------ 用编译器消灭 KV 别名与双重释放
请求的生命周期被建模为一个包含 13 种状态的 std::variant 有限状态机(fsm/states.h:32)。每个状态都是独立的 C++ 类型,物理上持有 move-only 的 RAII 句柄(如 OwnedPages、unique_ptr<NodeRef>,拷贝构造均标记为 =delete,访问资源的访问器为 && 限定)。事件是 operator()(State&&) -> NextState 形式的所有权转移函数(forward_events.cpp:259),状态析构即自动归还资源。
→ 启示:将 "资源在错误生命周期阶段被复用" 转变为编译期即可阻止的错误,而不是依赖运行时的引用计数与断言去赌。这是整个仓库中最巧妙设计。
→ 诚实边界:页别名和双重释放由编译期保证;但转移图的合法性仍通过运行时检查(非法转移会抛出 std::logic_error,base_event.h:32),引用计数是运行时整数。
② 控制面与执行面分离到极致
C++ 侧承担控制面职责(准入、前缀匹配、KV 分配、淘汰、生命周期),每几毫秒决策一次,几乎零开销。Python 退化为 "填充缓冲、发起前向、接收结果" 的薄执行驱动。跨 FFI 边界只传递可拷贝的 POD "外部事件",所有 move-only RAII 类型一律不绑定到 Python(bindings/python_module.cpp 中没有任何 nb::class_ 绑定 RAII 类型)。
→ 启示:若要让 LLM serving 循环的策略层不受 GIL 影响,应将所有权语义封闭在 C++ 内部,FFI 仅传递扁平 POD。这比常见的 "全 Python 调度器" 分离得更为彻底。
③ 页粒度 radix 前缀缓存 + 跨 rank 确定性 LRU
一次下行遍历即可同时计算出 device 与 host 两层命中深度(radix_tree.cpp:134)。前缀物理上仅存一份,通过 NodeRef RAII 锁住整条祖先路径来 pin。淘汰使用 (Time, SeqId, TreeNode*) 排序,其中 SeqId 是单调构造序号 ------ 专门用来抵消 ASLR 指针随机化,确保张量并行(TP)各 rank 的淘汰顺序逐比特一致(tree_resource.h:145),否则集合通信会死锁。
→ 启示:在分布式推理中,任何 "各 rank 独立做出的决策"(如淘汰、批次构成)必须比特级一致,否则会挂死 collective 操作。使用确定性的构造序号作为 tiebreaker 是关键手段。
④ 派发先于提交的双流重叠 + 设备常驻 token 反馈
重叠循环在提交第 N-1 步的 D2H 之前,就已派发第 N 步(event_loop.py:1489)。copy_event 每步一个,晚一步才进行同步。下一轮输入 token 写入 GPU 常驻的 future_input_map(runtime_states.py:52),step 间反馈数据不下设备,配合 CUDA Graph 连续 replay。侧流进行状态变更,使用 wait_stream 栅栏而非全设备同步。
→ 启示:交互式解码的标准,不要让 host 取结果的阻塞拖住加速器;尽量把跨步依赖打断在设备上。
⑤ CUDA Graph 的工程化(含一组防 "静默挂死" 的实战细节)
按 batch 分桶各捕获一张图,共享 mempool,原地写常驻 IO(cuda_graph_wrapper.py:301)。难点集中在失败模式:padding 行被路由到专门设置的哨兵 req-pool 槽(而非 slot 0),否则会继承 0 号请求的增长上下文,导致草稿 kernel 静默挂死;输入缓冲每步重刷 padding 尾部;在图前和图后设置两道 vocab clamp(一个越界 id 在捕获图中即等同于设备 assert,导致整服务死亡,见 input_buffer.py:367 / model_executor.py:1764);推测解码路径的 req_to_page 超额预留 spec_num_tokens*64 页,防止越界写。
→ 启示:捕获图会将 "页表/形状" 冻结,任何越界都会从 "丢失一个请求" 升级为 "杀死整服务"。防御性 clamp + 哨兵槽 + 页表余量构成了必要的安全包络。
⑥ 图内可捕获的结构化输出 grammar bitmask(与工具调用 / JSON 约束密切相关)
grammar mask 的填充利用 cudaLaunchHostFunc 挂在侧流上,使其在图捕获中可用(capturable_grammar.py:339)。matcher 的推进延迟一步(第 N 步的接受在第 N+1 步的 host 回调中执行)。bitmask buffer 永久绑定,使捕获的 sampler 对 "有无 grammar" 的分支无关。推测解码中每个草稿位置都能执行 mask 与回滚。
→ 启示:若要在 CUDA Graph 内支持动态约束解码(Agent 的 JSON / 工具 schema),关键是把 "动态 CPU 决策" 塞进 host 回调侧流,并永久绑定 buffer 以消除分支。这是 Agent Infra 中极易踩坑,而此处处理得最为干净的一块。
⑦ 无损投机解码
verify_chain_greedy:草稿的第 i 个 token 当且仅当等于目标序列中 i-1 位置的 argmax 时才被接受,通过 cumprod 进行匹配(greedy.py:66)。目标的 bonus token 总是被提交,因此即使整条草稿被拒绝,也能至少前进 1 步。整条草稿循环并入目标的 CUDA Graph(cuda_graph_wrapper.py:401)。EAGLE3 草稿头由 3 层 aux-hidden concat + 单 midlayer + d2t 热 token 重映射构成;NextN/MTP 头复用目标的 embed/lm_head,不占用独立 KV。
→ 启示:投机解码应设计为 "无损 + 永远净前进 ≥1",并且 draft 与 verify 处于同一图内,这样才能在小批量场景下真正节省开销。
⑧ PD 分离作为一等公民,而非补丁
Prefill/Decode 分离被编码进同一套类型态 FSM(Bootstrapping/Prefilling/Decoding/WritingBack/Draining/Retracting)。transfer_plan.py 按 BufferKind(target_k/v、draft_k/v、mamba_state)制定区间交集计划,支持 prefill/decode 异构 TP。采用双通道传输:大块 KV 走 Mooncake RDMA,但 prefill 的首个采样 token 与投机候选则通过 ZMQ 状态消息传递(mooncake/prefill.py:637),操作的成功与否以该元数据为准。跨 rank 失败通过 gloo all-reduce-MIN 投票达成共识(pd/utils.py:61)。
→ 启示:异构 TP 的 KV 搬运宜采用 "按 buffer 类型 + 区间交集" 来建模;控制元数据与大块数据分走两条链路,是 PD 分离的正确形态。
⑨ 将重 CPU 工作移出引擎进程
OpenAI HTTP/JSON/chat 模板/工具解析,以及 tokenizer 前缀缓存,全部放在外部 Rust 网关 SMG 中处理(进程外、无 GIL)。引擎只负责 tokenize 与入队。内置 inline detokenizer 节省了一次 IPC 开销(generation_output_processor.py:963,并硬编码为 True,不对外暴露 CLI 开关)。引擎仅构建 tokenizer,从不实例化 HF AutoProcessor(多模态预处理由 SMG 完成)。http_server.py 仅充当健康检查/abort 旁路与反向代理 ------ OpenAI API 层并不在本仓库中。客户端断连被建模为 asyncio.CancelledError,在 finally 块中发送 AbortReq 以秒级释放 KV 资源(async_llm.py:388),不依赖轮询 is_disconnected。
→ 启示:每个请求的 CPU 摄入开销(HTTP / 模板/解析)是一阶延迟成本,应外移到编译型、无 GIL 的进程中。断连应通过异常传播来响应,而非轮询。
⑩ 厂商中立的 kernel registry + 静态 SPMD 通信编译器
Registry:@register_kernel 装饰器使得导入即注册,然后先按硬件能力 + 格式签名 + trait 进行硬过滤,再按优先级带(REFERENCE/PORTABLE/PERFORMANT/SPECIALIZED/PLUGIN)排序(registry.py:306/75)。公共 op(如 mm/mha_prefill/moe_apply)与硅无关。插件式的 entry point 允许厂商通过发布 wheel 包来支持新硬件。SPMD 编译器:Placement(Replicate/Shard/Partial × ATTN_TP/DENSE_TP/MOE_TP_EP,placement.py:34)加上 compile_decoder_layer,可顺着子模块追踪 hidden/residual 布局,仅在不匹配处插入最小集合通信,并做代价感知(如 use_all_reduce 根据 TP 宽度在 AllReduce 和 RS+AG 间选择;can_fuse_reduce_norm 将 reduce 折叠进 RMSNorm;residual 保持 Shard 以节省带宽)。
→ 启示:kernel 选择可做成"能力门控的静态路由 + 插件 wheel",解耦硬件与引擎。并行通信可从布局标注中编译生成,而非手工编写。
→ 诚实边界见审计:registry 的自适应层目前是静态的;SPMD 编译器仅在 gpt-oss 一个模型上使用。
完整技术清单(按子系统,附成熟度与锚点)
成熟度标记:shipped/default-on 表示默认路径正在使用;opt-in 表示需要开关或仅单模型启用;dormant 表示代码存在但从未被调用;scaffolded 表示框架已搭好但关键组件未接入;overstated 表示声称强于代码实际。
调度器 / KV 缓存(C++ 控制面,最成熟):
NodeRef<Device|Host>单模板 RAII 锁,构造/析构即上锁解锁,锁会延伸到根节点------持有叶引用即保护整条共享前缀不被淘汰。shipped- Touch-while-locked 的 LRU 失效修复:在 RefCount 从 1→0 的边沿懒刷新 LRU 键(OnNodeEvictable),避免 O(n) 重排。shipped
- 状态复用通过继承实现:Retracting IS-A WritingBack,FinishEvent 将 Retracting 切片为 WritingBack 以复用回写完成路径。shipped
- 拆分安全回写:转移时快照具体的
(device_page, host_page)对,完成时不再经过 radix 树。shipped - 持有快照的节点不可分裂(否则借出的 id 会悬空);CommitChunk 使用 SplitAt 物化对齐边界。shipped
- KV-cache 事件发布:块哈希向根链式串联并去重,发出 KvBlockStored/Removed 事件------这正是全局 KV 感知路由器需要消费的接口。opt-in(enable_kv_cache_events)
- 借用页与自有页分离(PagedCacheGroupTable):前缀复用零物理拷贝,仅拷贝 id。opt-in
- 混合 Mamba/SSM 前缀缓存:分支点采用 COW 与 L2 host 降级;独立的 mamba 淘汰索引(同样基于 (Time,SeqId) 保证确定性)。opt-in
- PageAllocator 即为一个 LIFO free-list,无合并操作------分页化后分配器退化为可互换页表,价值全在 OwnedPages RAII。shipped
执行循环:
fused_decode_input_prep:解码快路径以一次 Triton 启动替代 4 个 prep kernel(每个标量只读取一次)。shipped- NanGuard:图安全、无同步的每请求数值容错(OVERSTATED:实际上是可选的,默认使用 no-op 单例)。opt-in
- 空 DP forward 保持各 rank 的图 lockstep 一致;grammar 正确性异常时会反转 dispatch/commit 顺序。shipped
分布式通信:
- 拆分式 TP:attn/dense/moe 各自独立的 TP 宽度,驱动每个边界在 AllReduce 与 RS+AG 间选择;token 感知的非均匀 RS/AG(dp-major/tp-minor 计数表)。shipped
- trtllm 融合 AR/RS/AG + residual + RMSNorm,单节点 Hopper+ / AMD TP 上默认开启。default-on
- DP 投机验证采样通信:在可用时自动选择**单边 NVLink(symmetric memory)**路径。default-on
- 进程组按 rank 元组寻址,按 stride 懒物化(NCCL+gloo)。shipped
- 无流水线并行(PP);CP 仅是 ENABLE_CP 对 TP 的重解释,并非独立维度。
MoE / 专家并行:
- DeepSeek-V4 融合路由使用 CUDA routing_flash kernel 进行 bias 校正 top-k 计算;其余路由走 eager torch。shipped
- 共享专家 MLP 在分叉的 CUDA 流上运行------这是 MoE 中唯一真正的并发执行(但仅在 CUDA Graph 捕获期间开启)。opt-in
- masked grouped GEMM 使用
masked_m仅计算活跃行,但仍会遍历所有本地专家槽(按容量 padding,非活跃专家并未实现真正的稀疏)。opt-in
MLA(tokenspeed-mla,手写 CuteDSL,面向 Blackwell):
- 潜在 KV 行(512 latent + 64 rope)仅存一份,通过转置视图同时充当 K 和 V。shipped
- 两段 split-KV 解码:split kernel 将 fp32 partial 结果写入 workspace,独立的 reduction kernel 做 LSE 重缩放合并与 FP8→BF16 cast。shipped
fold_sq_factor:当 num_heads<128 时,将 query token 组折叠进 MMA 的 M(head)轴。shipped- M64 单 CTA warp-specialized 路径手写
tcgen05.mma.ws(以绕过 CuTe DSL 缺失的支持);SM103(B300) 提供单独的 TMEM load-with-MAX-reduce softmax 路径。shipped/opt-in - 融合 K/V-pack + FP8 量化由 Triton(而非 CuteDSL)实现,仅用于 FP8 prefill 路径;BF16 时退回 torch.cat。default-on
量化 / GEMM:
- 格式签名 + trait 注册表作为厂商中立的派发底座;在线激活量化 layout 由获胜 kernel 名决定,而非量化类型。shipped
- 块缩放 FP8 dense GEMM 走 mxfp8 签名(非 fp8);
per_token_group_quant_fp8具备三级回退(FlashInfer SM90→TRT-LLM→Triton)。shipped - FP8 KV cache 根据 NVFP4 checkpoint 元数据自动开启(model_runner.py:81)。shipped
- 每半 gate/up 全局 scale 修复 trtllm NVFP4 fused MoE(近期 #543)。opt-in
采样 / 结构化输出:
- RNG 完全移出图:预填充 coin buffer + Philox seed/offset。default-on
- 池索引 sampler 状态 + rid-flip 检测,置于图外;TP-rank 输出广播以 kernel 位可复现性为条件。default-on
- 融合 top-k+top-p renorm(哨兵-K 路由 + PDL 启动链);verify 输出通过 aliased backing store 单次 D2H。default-on
- CuTe DSL argmax(能力门控 + H20 cluster-launch 特例)。default-on
Attention 接入 / KV host 分层:
- 两级后端选择:Python AttentionBackend 注册表(架构门控)包裹在 kernel registry(能力+trait+优先级)之上。shipped
- ⚠️ 默认 MLA 路径为 in-tree "mla" 后端,运行 Triton kernel;flash_mla/tokenspeed_mla 是绕过 kernel registry 的 opt-in 再导出方式。opt-in
req_to_token_pool与KVAllocator分离:页表元数据与物理 KV 解耦,双长度水位支持重叠调度。shipped- 融合 FP8 KV-pack kernel:量化并散写进分页缓存,一次 Triton 启动(3D grid)。shipped
- DSA(DeepSeek 稀疏注意力):indexer 驱动 top-k 稀疏解码,并支持可选 FP4 indexer cache。opt-in
模型/层机制("低成本添加模型" 的兑现之处):
- EntryClass 自动发现注册表:只需添加文件、导出 EntryClass 即可。shipped
- ModuleSpec + Placement DSL 驱动层编译器自动插入 TP 通信 op ------ 这是 "用户无需手写并行" 的真正卖点所在。opt-in
- GDN/Mamba 混合:conv1d 实现为 ColumnParallelLinear,状态池按调度器槽位键控;Mamba 状态缓存支持投机解码(COW 槽 + MTP 输出索引 + 中间态检查点)。shipped
- DeepSeek-V4 多头卷积(mHC):残差流复制 hc_mult 份,通过 Sinkhorn 归一化矩阵在融合 Triton/TF32 kernel 中混合。opt-in
- 三种融合 norm+collective(根据 kernel 能力选择,包含 Gemma 预计算技巧);
get_rope()工厂 + 进程级缓存覆盖 9 种缩放变体;VocabParallelEmbedding是torch.compile的 masked gather。shipped
入口 / 可观测 / 配置:
--enable-log-request-stats:仅 host 侧提供每请求性能摘要,通过冻结的 NOOP 单例消除每请求分支(近期特性)。opt-in- 流式指标手动穿透
prometheus_client内部,一次调用观测 N 个 token;RequestOutputCollector 就地合并流式帧。default-on memory_occupation:标签序 sleep/wake,并显式声明 "KV 释放安全" 能力(面向 RLHF 共置场景)。opt-inserve_smg:编排器通过改写 argv 注入网关默认值与模型族解析默认值。shipped
AMD 路径(补充):tokenspeed-kernel-amd 是面向 gfx950(MI350) 的 Gluon kernel ------ 涵盖 mha decode/prefill(fp16)、fused mxfp4 MoE 和 argmax 采样。范围比 NVIDIA CuteDSL 那套窄很多,属于部分对等而非全功能实现。opt-in
诚实成熟度审计(哪些可以依赖,哪些仍是脚手架)
对于 Infra 选型而言,这是最关键的一节 ------ 应避免被博客中的招牌宣传所误导:

两个安全提示:自定义 logit processor 采用 dill 反序列化,并在 JSON 中使用 hex 格式(custom_logit_processor.py:30),而 ExtensibleLM 从外部文件路径注入 input/output processor ------ 这两处都属于 "加载即执行任意代码" 的攻击面,多租户部署时应进行隔离。
研习路线与可直接借鉴的模式,建议阅读顺序(按 "启示密度/可迁移性" 排序):
- tokenspeed-scheduler/csrc/fsm/ + resource/allocator/owned_pages.* ------ 类型态 FSM + RAII 所有权(全仓库最值得借鉴的范式)
- resource/radix_tree/ + kv_prefix_cache/ ------ 前缀缓存 + 跨 rank 确定性淘汰 + KV 事件发布
- runtime/engine/event_loop.py + runtime/execution/{cuda_graph_wrapper,input_buffer,model_executor}.py ------ 重叠循环 + CUDA Graph 防挂死细节
- runtime/grammar/capturable_grammar.py ------ 图内可捕获约束解码(工具调用 / JSON Schema 的关键)
- runtime/pd/ ------ PD 分离 + BufferKind + 双通道传输
- runtime/models/base/{placement,compiler}.py + tokenspeed-kernel/{registry,selection}.py ------ 通信编译器 + kernel 派发抽象(读完同时明了哪些是脚手架)
可直接迁移至自身技术栈的模式:
- move-only RAII × 状态机,消灭资源别名与双重释放(不仅限于 KV,任何 "恰好一个所有者" 的资源均适用)。
- 分布式决策的确定性 tiebreaker(使用构造序号而非指针)防止 collective 死锁。
- CUDA Graph 的失败工程经验:哨兵槽、双端 clamp、页表余量、padding 尾重刷 ------ 防止越界从 "丢请求" 升级为 "死服务"。
- 约束解码图内化:将动态 CPU 决策塞进 cudaLaunchHostFunc 侧流 + 永久绑定 buffer。
- CPU 边界外移:将 HTTP/模板/解析/tokenizer 缓存放入进程外无 GIL 的网关;断连时通过异常快速释放资源。
- KV 事件接口(链式块哈希 + 去重)作为前缀感知路由的标准对接面。
- kernel 能力门控 + 插件 wheel,解耦硬件与引擎。
一句话总结:TokenSpeed 已兑现的硬资产包括控制面(C++ 类型态 FSM + 类型拥有 KV)、消除字节的开销(MLA/ 量化 /radix)、消除空闲时间(CUDA Graph / 双流重叠),以及 CPU 职责外移;而自适应 kernel 选择、加速通信后端、EPLB 在线均衡、SPMD 全面采用、最快的 AOT MLA 等,则属于 "脚手架已搭起,但尚未通电" 的部分。对于 Agent Infra 而言 ------ 地基与模式值得逐行研习,而那几个最耀眼的招牌,建议按 "未验证" 状态来对待。
小结
推理优化的战场,正在从「通用聊天时延、吞吐」变成「数十轮、多步工具调用、长上下文、可恢复状态的 Agent 会话体验」。
为什么 Coding Agent 的推理必须单独优化?
针对 Agentic Workloads,推理的瓶颈,靠换一个 Attention Kernel 解决不了。需要 Modeling、Scheduler、Kernel、请求入口全部协同改。把通用聊天场景的时延、吞吐指标简单外推到 Agent 场景这种做法是不合适的,应该把 Coding Agent 的服务形态当作一等公民。
Coding Agent 对推理性能的要求极为苛刻 ------ 上下文常常超过 10 万 Tokens,对话往往跨越几十轮。传统 Benchmark 通常将一次请求看作 "输入 Prompt → 输出回复" 的单次事件,但 Coding Agent 的真实工作模式完全不同,主要体现在以下几个方面:
- 长历史上下文:Agent 会读取整个仓库的文件、修改代码、运行测试、解析报错,这些信息全部堆积在上下文窗口中。根据 TokenSpeed 公开的实测分享,平均输入长度约为 63K Tokens,P99 超过 70K Tokens。
- 多轮工具调用:每轮都可能涉及文件读取、代码编辑、终端命令等多个工具调用。
- KV Cache 大量复用 :同一仓库的上下文在多轮交互中反复出现。数据显示 KV cache 命中率约 91%,说明大量前缀和工具调用轨迹在多轮中得到了复用。
- 推测解码(Speculative Decoding)加速 Decoding:采用多词元预测(MTP)算法时,平均每次迭代解码 3.43 个 Token,接受率约 71%。
这意味着,在 Agentic 场景下,性能瓶颈已从 "单次 Attention 计算" 转变为 "多轮状态管理" ------ 包括如何可靠、安全地复用 KV Cache、如何调度长 Prefillling 与 Decoding 阶段的资源竞争、如何在推测解码中维持足够准的接受率,以及如何在并发上升时找到时延与吞吐的平衡点。正是由于通用推理引擎的设计假设与 Agentic 推理的现实需求之间出现了结构性的错位,TokenSpeed 才选择重新设计 Scheduler、Kernel 与 Modeling 层。
TokenSpeed 仓库已经把 Qwen3.5-397B NVFP4 的 Agentic 性能测试写进 CI Workflow,参考线定在 530 TPS/User。达成针对 Agentic 工作负载的极限性能,源于系统性消除内存拷贝、先进的内核融合,以及完全重叠的 CPU-GPU 执行 ------ 始终保持 GPU 满负荷运转。在功能层面,TokenSpeed 还支持混合前缀缓存和统一的 Prefill-Decode 状态传输,以应对复杂的 Agentic 服务场景。
此外,在推理优化中,仅仅报告一个笼统的 TPS 数值已经不够了。还需要明确说明,这是谁的 TPS、是在怎样的负载条件下测得。这背后其实是一条帕累托(Pareto)曲线:
- 如果你做的是 IDE 中的编码 Agent ------ 用户盯着屏幕等待实时输出------那么你追求的应该是尽可能高的单用户吞吐(TPS/User),并且需要压低并发数。
- 如果你做的是云端批量 Agent 平台 ------ 后台需要并行运行成百上千个 Agent 来自动修改代码 ------ 那么你更关注的则是单位 GPU 的高吞吐(TPS/GPU),可以充分放开并发度。
因此,TokenSpeed 目前更适合被视作一条技术路线和性能工程的参考样板,而非能够直接替换线上推理集群的成熟产品。它最值得研究的地方,在于将智能体推理的典型痛点进行了系统化抽象,这些痛点包括:长上下文、短解码(short decoding)、高并发、KV 缓存复用、低 CPU 开销、异构 kernel 选择,以及控制平面的安全性。
未来,大模型推理系统的竞争不会只停留在单个 kernel 谁更快,而是要看谁能围绕模型建模、请求调度、缓存管理、核心引擎、流量入口和服务拓扑等环节,构建出一套可验证、可扩展且可持续优化的系统。