聊《Java 转大模型开发:适合普通开发者的入门路线》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
之前我在做传统后端架构时,总觉得"AI 是个黑盒",调个 API 就能解决一切。直到最近参与了一个企业级知识库问答系统的重构,我才发现,这根本不是简单的 CRUD 叠加,而是一场关于确定性工程 与概率性生成的博弈。
很多 Java 兄弟问我:现在转大模型开发晚不晚?我的回答是,如果你只盯着 PyTorch 底层去学,那确实晚了,而且路很窄。但对于大部分后端开发者来说,现在的机会在于应用层。我们需要做的,不是成为算法科学家,而是成为能把 LLM(大语言模型)稳稳地嵌入现有业务系统的"AI 工程师"。
今天这篇,我不讲理论推导,只讲我从零开始搭建 RAG(检索增强生成)系统时的真实踩坑记录和路线规划。重点聊聊在这个新领域里,我们熟悉的 Java 优势在哪,以及必须补齐的那些"非标"技能。
目录
- Java 开发者的天然护城河
- 必须补齐的 AI 短板
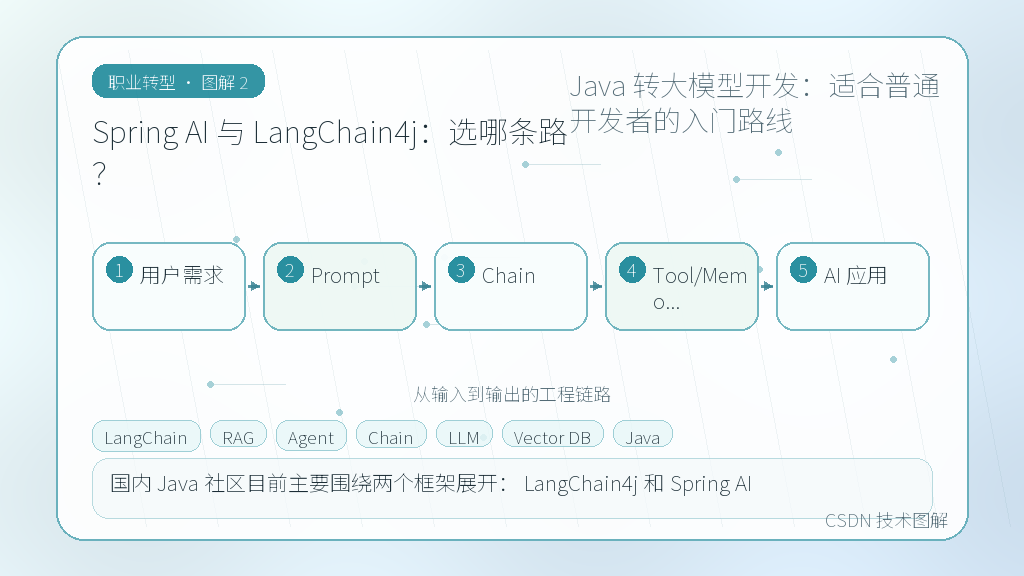
- Spring AI 与 LangChain4j:选哪条路?
- 项目练习:从 Demo 到可维护的系统
- 面试准备:如何展示你的优势
- 总结
Java 开发者的天然护城河

别妄自菲薄。在大模型应用落地的最后一公里,Java 不仅没死,反而因为生态的成熟度变得更具竞争力。
Python 在模型训练和原型验证上确实无敌,但在高并发、强类型约束、微服务治理以及复杂的业务逻辑编排上,Java 依然是王者。大模型应用的核心难点从来不是"调用接口",而是:
-
上下文管理 :如何高效地缓存 Token,如何处理海量文档的切片。
-
稳定性保障 :模型会幻觉,API 会超时,网络会抖动,系统必须具备重试、熔断和降级机制。
-
数据一致性:向量数据库与传统关系型数据库的数据同步,事务的一致性边界在哪里。
这些正是 Java 后端的看家本领。所以,转型的第一心态调整是:你不是去学怎么训练模型,你是去学怎么控制模型。
必须补齐的 AI 短板
虽然语法可以复用,但思维模式必须切换。作为 Java 开发者,你需要重点补三个维度的知识:
1. Prompt Engineering 的结构化
以前我们写 SQL 或正则,讲究精确匹配;现在写 Prompt,讲究语义引导。你需要理解什么是 Few-Shot(少样本学习),什么是 Chain-of-Thought(思维链)。这不是玄学,而是通过结构化输入来约束输出的概率分布。
2. Embedding 与向量数据库
传统数据库查的是 ID,向量数据库查的是"相似度"。你需要搞懂余弦相似度、欧氏距离,以及为什么要把文本切分成片段(Chunking)而不是整篇扔进去。常用的向量库如 Milvus、Chroma 或 pgvector,了解它们的索引机制(HNSW vs IVF)对性能优化至关重要。
3. Context Window 的成本意识
Token 就是钱。每一个请求都在烧预算。你需要学会评估上下文长度,如何通过摘要(Summarization)压缩历史对话,如何在本地缓存热门查询以减少重复推理。

Spring AI 与 LangChain4j:选哪条路?
国内 Java 社区目前主要围绕两个框架展开:LangChain4j 和 Spring AI。
- LangChain4j:由 LangChain 官方驱动,社区活跃,文档丰富,插件生态(如各种 Embedding 实现、Store 实现)非常完善。如果你的团队偏向于快速构建 Agent 和工作流,它是首选。
- Spring AI:Spring 官方出品,深度集成 Spring Boot 生态。如果你已经有一套完善的 Spring Cloud 微服务体系,引入 Spring AI 的成本最低,配置最统一。
我的建议:如果是新项目,且团队对 Spring 生态依赖极深,直接上 Spring AI。它让 RAG 的构建变得极其声明式。以下是一个使用 Spring AI 构建简单 RAG 检索的代码片段,展示了如何将非结构化数据转化为可检索的知识:
java
// 这是一个典型的 Spring AI RAG 构建流程
@Service
public class KnowledgeService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
public KnowledgeService(ChatClient chatClient, VectorStore vectorStore) {
this.chatClient = chatClient;
this.vectorStore = vectorStore;
}
/**
* 执行基于上下文的问答
*/
public String query(String userInput) {
// 1. 将用户问题向量化,并在向量库中检索相似片段
List<Document> relevantDocs = vectorStore.similaritySearch(
new SimilarityRequest(userInput).withTopK(3)
);
// 2. 构建带有上下文的 Prompt
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("\n\n"));
String prompt = String.format("""
基于以下上下文回答用户问题。如果上下文中没有答案,请说明无法回答。
上下文:
%s
用户问题:
%s
""", context, userInput);
// 3. 调用模型获取结果
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}注意这里的 SimilarityRequest,这就是利用向量数据库进行语义搜索的关键入口。相比于 Python 中繁琐的数据预处理,Java 的强类型在这里反而让代码意图更清晰。
项目练习:从 Demo 到可维护的系统
很多初学者容易犯的错误是:写了一个能跑的 Hello World,就觉得学会了。在企业环境中,可观测性比功能更重要。
建议你的第一个练习项目是:企业内部文档智能助手 。
不要只做一个聊天框,要做成具备以下特征的系统:
-
文档入库流水线 :支持 PDF/Word 解析,自动分片,存入向量库,并记录元数据(来源文件、时间、作者)。
-
混合检索 :结合关键词搜索(BM25)和向量搜索(Semantic Search),提高召回准确率。
-
引用溯源 :生成的答案必须标注出自哪篇文档的第几页,方便用户核实。这是 AI 产品经理最看重的功能之一。
-
日志与追踪:使用 OpenTelemetry 或 Langfuse 追踪每一次调用的 Latency、Token 消耗和 Prompt 内容。当模型回答错误时,你能回溯是因为检索不到,还是模型理解偏差。
面试准备:如何展示你的优势
在面试中,HR 或技术面试官通常担心 Java 转 AI 的人"理论基础薄弱"。你要反其道而行之,强调你的工程化能力。
在简历和面试中,多讲这些细节:
- "我设计了重试机制,应对 LLM API 的瞬断。"
- "我通过调整 Chunk Size 和 Overlap,将检索准确率从 60% 提升到了 85%。"
- "我引入了缓存层,将高频问题的响应延迟从 3s 降低到 200ms。"
- "我实现了 Prompt 的版本管理和 A/B 测试流程。"
这些话题展示的是你对生产环境的掌控力,而这恰恰是目前最稀缺的。
总结
从 Java 后端转向大模型应用开发,并不是抛弃过去,而是升级工具箱。LLM 不是魔法,它是概率统计在大规模数据上的体现。作为工程师,我们的价值在于用确定的代码逻辑,去包裹和控制这种不确定性。
保持对新技术的敏感度,但更要深耕那些不会过时的工程原则:模块化、可测试性、可观测性。当你能够写出既懂业务又懂 AI 边界的代码时,你就是市场上最抢手的那类人才。别焦虑,动手写代码,去踩坑,去填坑,这就是最好的学习路线。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。
