在大型集团或超大型组织(如拥有 10 万10 \text{ 万}10 万 以上员工及数千个嵌套部门的组织)的数字化底座建设中,通讯录同步(Contacts Synchronization) 往往是后端研发团队最先需要啃下的硬骨头。
虽然企业微信(WeCom)提供了通讯录管理的一系列 API(如成员、部门的增删改查),但在超大规模组织架构同步的真实生产环境下,传统的"全量遍历写入"或"无序递归更新"极易导致系统崩溃。开发者通常会遭遇以下三大核心技术瓶颈:
接口频次与写入放大(Write Amplification):大规模拉取或同步时,极易触发企业微信对通讯录写入接口的限频机制(如单次批量导入限制)。
依赖关系破裂(Dependency Breakage):在无序同步部门时,如果子部门先于父部门被创建,或者员工先于其所属部门被创建,企微 API 将直接报错拒绝。
多源冲突(Multi-source Conflicts):当系统同时对接本地 Active Directory(AD 域)、本地 HR 数据库、以及企业微信本身时,三方数据不一致将引发数据覆盖、人员漏同步等逻辑混乱。
本文将从图论算法与分布式系统设计的视角,硬核拆解一套能够支撑百 K 级(十万级以上)组织架构树的高性能、强一致性同步架构。
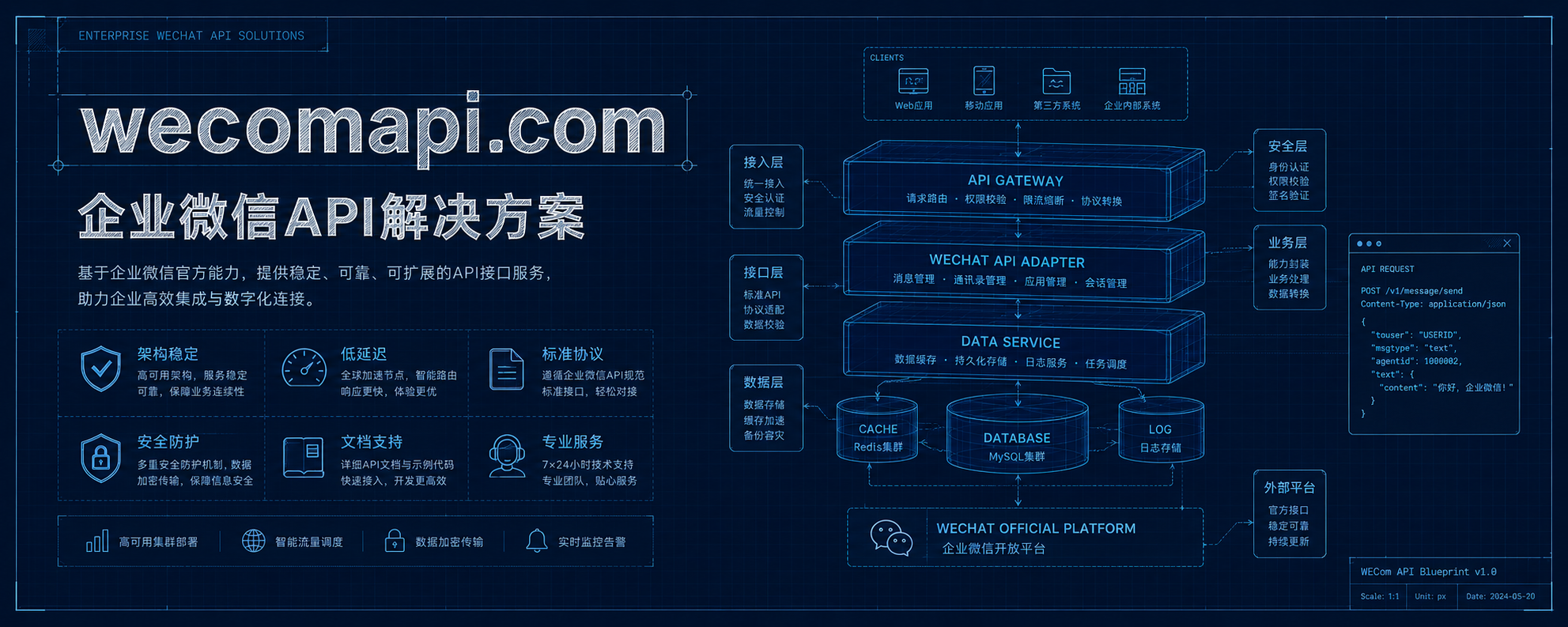
一、基础架构:全量拉取过滤与全异步化流水线
对于十万级以上的组织架构,严禁在同步任务中对每一个成员或部门发起单次的 HTTP 同步请求。这会产生数十万次网络 I/O,不仅耗时数小时,更会瞬间拉爆企微的调用限额。
- 全量拉取阶段的压缩策略
在全量对账或冷启动阶段,应采用"大包拉取+本地差分"的策略:
部门拉取:调用 /cgi-bin/department/list 接口,一次性获取全量部门数据(该接口单次可返回数万级数据)。
成员拉取:调用 /cgi-bin/user/list?department_id=1&fetch_child=1 获取根部门(ID为1)下级所有子部门的成员详情。这同样能够实现单次连接拉取数十万数据,极大地减少了 HTTP 请求开销。
- 异步流水线架构设计
由于全量数据对比与转换极其消耗 CPU 与内存,必须建立基于消息队列的"多阶段流水线(Pipeline)"架构:
定时/手动触发 \] ──\> \[ 全量数据拉取器 (Puller)
│
▼ (内存/临时表 Raw Data)
差分对比计算引擎 (Diff Engine)
│
┌────────────────┼────────────────┐
▼ ▼ ▼
待新增队列 \] \[ 待更新队列 \] \[ 待删除队列
│ │ │
└────────────────┼────────────────┘
▼ (进行拓扑排序规划顺序)
拓扑编排网关 (Scheduler)
│
▼ (并发滑动窗口执行调用)
企微 API 执行引擎
二、拓扑排序:解决嵌套部门依赖关系错乱
在同步组织架构部门树时,部门与部门之间存在严格的父子层级依存关系。
设部门 DAD_ADA 是 DBD_BDB 的父部门,在调用企微创建接口 /cgi-bin/department/create 时,必须保证 DAD_ADA 先于 DBD_BDB 被创建;同理,在删除部门时,必须保证子部门 DBD_BDB 先于父部门 DAD_ADA 被删除。
如果仅仅按照数据库自增 ID 或是拼音顺序去调用 API,必定会触发大量的因父部门不存在而导致的创建失败报错。
- 将组织架构建模为有向无环图(DAG)
我们将每一个部门视为一个顶点 VVV,父子关系视为一条有向边 E=⟨Vparent,Vchild⟩E = \langle V_{parent}, V_{child} \rangleE=⟨Vparent,Vchild⟩。
整个组织架构树本质上是一个单根(或多根)的有向无环图(DAG)。我们可以利用拓扑排序(Topological Sort) 算法,计算出绝对安全的线性执行顺序。
- 基于 Kahn 算法的拓扑排序实现(Go 示例)
Kahn 算法的核心在于利用入度(In-degree) 的变化来确定节点的排队顺序。
正向拓扑排序(用于创建/更新流程):入度为 000 的节点(无父部门,如根节点)最先被同步,随后将其子节点的入度减 1,循环往复。
逆向拓扑排序(用于删除流程):出度为 000 的节点(叶子部门,无任何子部门)最先被删除。
package main
import (
"errors"
)
// DepartmentNode 部门图节点
type DepartmentNode struct {
ID int32
ParentID int32
Name string
}
// TopologicalSortDepartment 拓扑排序算法
func TopologicalSortDepartment(nodes \[\]DepartmentNode) (\[\]DepartmentNode, error) {
// 1. 构建邻接表与入度图
adjList := make(mapint32\[\]int32)
inDegree := make(mapint32int)
nodeMap := make(mapint32DepartmentNode)
for _, node := range nodes {
nodeMap[node.ID] = node
inDegree[node.ID] = 0 // 初始化入度
}
for _, node := range nodes {
// 如果父部门在本次需要同步的列表中,说明存在依赖边
if _, exists := nodeMap[node.ParentID]; exists && node.ParentID != node.ID {
adjList[node.ParentID] = append(adjList[node.ParentID], node.ID)
inDegree[node.ID]++
}
}
// 2. 将所有入度为 0 的节点放入队列
queue := make([]int32, 0)
for id, degree := range inDegree {
if degree == 0 {
queue = append(queue, id)
}
}
// 3. 开始 Kahn 算法核心流转
result := make([]DepartmentNode, 0, len(nodes))
for len(queue) > 0 {
u := queue[0]
queue = queue[1:]
result = append(result, nodeMap[u])
for _, v := range adjList[u] {
inDegree[v]--
if inDegree[v] == 0 {
queue = append(queue, v)
}
}
}
// 4. 环路检测:如果排序结果数量少于原始数量,说明数据存在循环依赖(脏数据)
if len(result) != len(nodes) {
return nil, errors.New("detected circular dependency in department tree")
}
return result, nil}
使用该拓扑排序算法对差分计算出的待新增/待更新部门列表进行一次前置处理,可以保证后续发起的每一个 API 调用 100%100\%100% 符合依赖顺序。
三、增量同步:基于 Versioned Event Callbacks 的秒级变更
当完成初次全量同步后,后续的日常运转应该依靠企业微信的"通讯录变更回调事件(change_contact)"来驱动增量同步。
- 应对"异步回调乱序"的边界问题
当 HR 修改了员工 E1E_1E1 的部门,接着将其禁用。企业微信服务器会迅速向你的回调网关发出两条消息:
事件 AAA:变更部门。
事件 BBB:禁用账号。
如果因为公网网络波动、网关消费队列时发生局部抖动,导致事件 BBB 先于事件 AAA 被消费。你的本地数据库先将该员工置为"禁用",随后又执行了事件 AAA 的更新,并错误地将该员工恢复成了"启用"状态。
- 本地版本戳(Version Stamp)防线
为了防止回调乱序覆盖数据,我们在本地数据库成员表、部门表中引入 change_version(基于时间戳或自增序列)进行乐观锁控制。
在企微回调 XML 数据体中,提取 标签作为版本比对源 TmsgT_{msg}Tmsg。
本地更新 SQL 必须增加版本过滤:
UPDATE t_employee SET dept_id = ?, change_version = Tmsg WHERE userid = ? AND change_version < Tmsg\text{UPDATE t\_employee SET dept\_id = ?, change\version = } T{msg} \text{ WHERE userid = ? AND change\version < } T{msg}UPDATE t_employee SET dept_id = ?, change_version = Tmsg WHERE userid = ? AND change_version < Tmsg
只有当新接收到的事件时间戳大于本地已有版本时,更新才会被实际执行,从而天然杜绝了分布式乱序引起的"幽灵更新(Phantom Update)"。
四、冲突解决:多源合并冲突矩阵(Conflict Resolution Matrix)
中大型企业往往存在多套权威数据源,最典型的是:本地 HR 系统 →\rightarrow→ 本地数据库 →\rightarrow→ 企业微信 →\rightarrow→ 本地 AD 域。
如果缺乏清晰的数据流向与冲突决策机制,不同的定时同步脚本、事件回调之间会发生恶性数据覆盖,导致数据反复横跳。
-
制定单向可信数据源矩阵

-
双向冲突合并控制机制(Merge Strategy)
以"手机号/邮箱"字段为例,由于用户可能会在企业微信端直接进行实名认证或修改:
下行流(HR →\rightarrow→ WeCom):
当 HR 系统中发生了人员信息变更并向下同步给企业微信时,在组装 API Payload 时,自动忽略已被标记为"企微端权威"的字段(如手机号),不将其写入 API 参数。
上行流(WeCom →\rightarrow→ HR):
订阅企微的 update_user 回调。当监听到用户修改手机号事件后,反向同步给本地数据库及 HR 系统的临时接收表(待人工或规则核验后再覆盖本地),从而保证多套系统的平滑一致。
五、结语
海量组织架构与通讯录同步的开发,是一门关于"图论算法"、"高性能队列"与"精细状态冲突合并"的后端工程艺术。从全量差分过滤,到基于 Kahn 算法的拓扑依赖排序,再到基于 Version 时间戳的增量事件防无序防抖设计,每一个细节都决定了集团数字化中台的稳定性下限。
在实现这套架构并对接调试极其冗长、嵌套深厚的通讯录 XML 回调数据时,验证流程往往枯燥而复杂。建议在团队开发内部沉淀出一套标准的加解密与 JSON 验证脚本套件,这能极大地提升联调和架构调优的效率。
彻底扫清底座上的障碍,上层的业务应用才能稳健前行。大家在构建大型企业的通讯录同步树时,还遇到过哪些棘手的业务场景或奇葩的逻辑冲突?欢迎在评论区一起讨论!