作者:来自 Elastic Ashish Tiwari
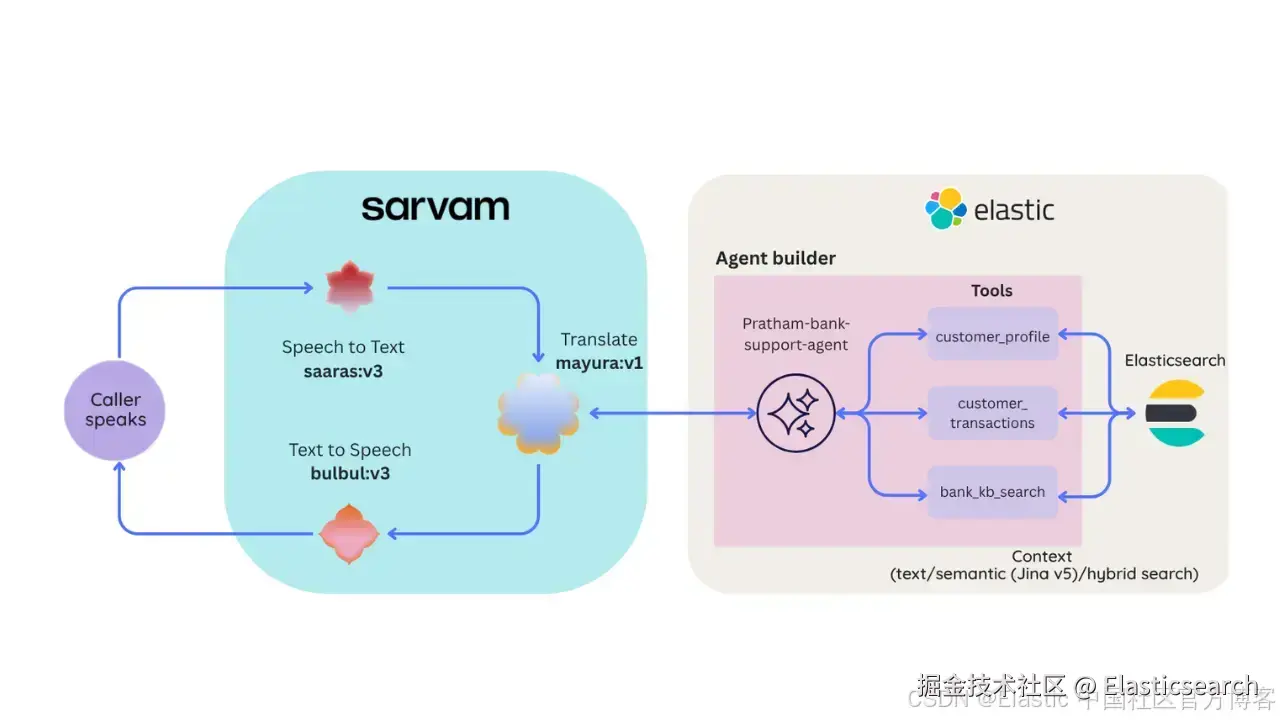
一个可运行的演示,将 Sarvam AI 语音与 Elastic Agent Builder 相结合:身份验证、针对每位客户的 ES|QL 查询,以及在通话过程中无需多语言索引即可在 22 种印度语言之间切换。
Agent Builder 现已 正式发布 。立即开始使用 Elastic Cloud Trial ,并查看 Agent Builder 的文档。
Mitr 是一个银行语音 agent,能够理解印地语、马拉地语、英语以及另外 19 种印度语言,并且无需事先告知,就能够在一句话中途、一次通话中途自动切换语言。在一次语音交互背后: Sarvam AI 负责转录并翻译来电者的问题,Elastic Agent Builder 负责验证其身份并查询其私有交易账本,随后 Sarvam 使用来电者自己的语言播报答案。整个过程只需五个 HTTP 调用。无需自定义 RAG 框架。无需多语言索引。该 agent 运行在基于 semantic_text 与参数化 ES|QL 的 hybrid search 之上,而这一切都构建于 Elastic Agent Builder。
问题:以多语言语音方式访问私有银行数据
对于许多用户来说,访问个人财务信息(例如交易记录、工资入账或待退款项)一直受到语言障碍的困扰。虽然用户更倾向于使用自己的母语进行交互,但大多数银行和金融系统仅支持英语。这就造成了一个明显的鸿沟:用户需要查询特定的、私有的财务数据,却无法用自己最熟悉的语言自然地完成这一过程。一个真正有效的解决方案必须弥合这一鸿沟,使用户无论选择哪种语言,都能够通过自然对话安全、实时地访问私有交易数据。
再进一步考虑印度所具有的独特情况:来电者最熟悉的语言可能是印地语、马拉地语、泰米尔语,或者二十多种语言中的任意一种,并且可能会在一句话中途切换语言。而能够回答他们问题的数据,却存储在使用英语和结构化查询的系统中。此外,在你播报哪怕一卢比的余额之前,都必须先验证来电者的身份,并且绝不能跨越客户边界访问数据。
因此,一个真正有用的语音 agent 必须同时完成三项困难的任务:
-
理解并使用来电者的语言进行回复,并且能够跟上他们在通话过程中切换语言。
-
访问每位客户私有且敏感的交易数据,即真实的交易账本,而不仅仅是常见问题文章。
-
保证安全性 ;在披露任何信息之前验证身份,并且将每一次 query 的范围严格限定为单一客户。
我将这一切构建成了一个开源演示:"Mitr" (在印地语中意为"朋友"),面向一家虚构的 "Pratham Bank" 。其核心场景是日常资金相关问题,以及 UPI 欺诈举报。这是一个绝佳的压力测试,因为它迫使上述三项要求同时得到满足,并且对于全国各地的用户来说都极具现实意义。
什么是 Sarvam AI,以及为什么要用于印度语音 agent?
Sarvam AI 是一家印度 AI 公司,提供语音转文本(speech-to-text)、翻译(translation)以及文本转语音(text-to-speech)API,这些能力专门为 22 种印度语言构建。
如果你在为印度用户开发产品,Sarvam AI 是一个非常值得了解的方案。该公司成立于 2023 年,总部位于班加罗尔,由 Vivek Raghavan 和 Pratyush Kumar 创立,两人都曾参与 AI4Bharat。Sarvam 已成为印度 "主权 AI" 推动中的重要公司之一,并在 IndiaAI Mission 下被选中为国家构建基础模型。
Sarvam 之所以适合这个场景,并不只是因为模型本身,而是它专门为印度语言打造的语音与语言技术栈,并以干净的 REST API 形式提供。我们在这里使用了其中三个能力:
- Saaras(saaras:v3):覆盖 22 种印度语言加英语的语音转文本,并具备自动语言检测能力。这种检测能力是 "随时切换语言" 体验中的关键隐藏能力:用户不需要声明语言,模型会在每一次语音输入中自动识别。
- Mayura(mayura:v1):针对印度语言以及混合语言(code-mixed language,即人们日常说话中夹杂英语的方式)优化的翻译模型。
- Bulbul(bulbul:v3):文本转语音系统,提供 30 多种自然的印度口音与声音。
这三项能力都非常简单:只需通过 HTTP 调用即可完成,例如 POST /speech-to-text、POST /translate、POST /text-to-speech,对接地址为 api.sarvam.ai,并通过 api-subscription-key 头进行认证。
Sarvam 还提供多种集成方式,包括 HTTP、WebSocket 和 Batch 处理,可以根据不同的技术需求选择最合适的方式。
西方的 STT/TTS 技术栈往往把印度语言当作 "附加支持";而 Sarvam 是把它们当作核心场景来设计的。对于面向未来五亿用户的银行语音客服来说,这种差异是决定性的。
多语言语音 agent 架构如何工作?
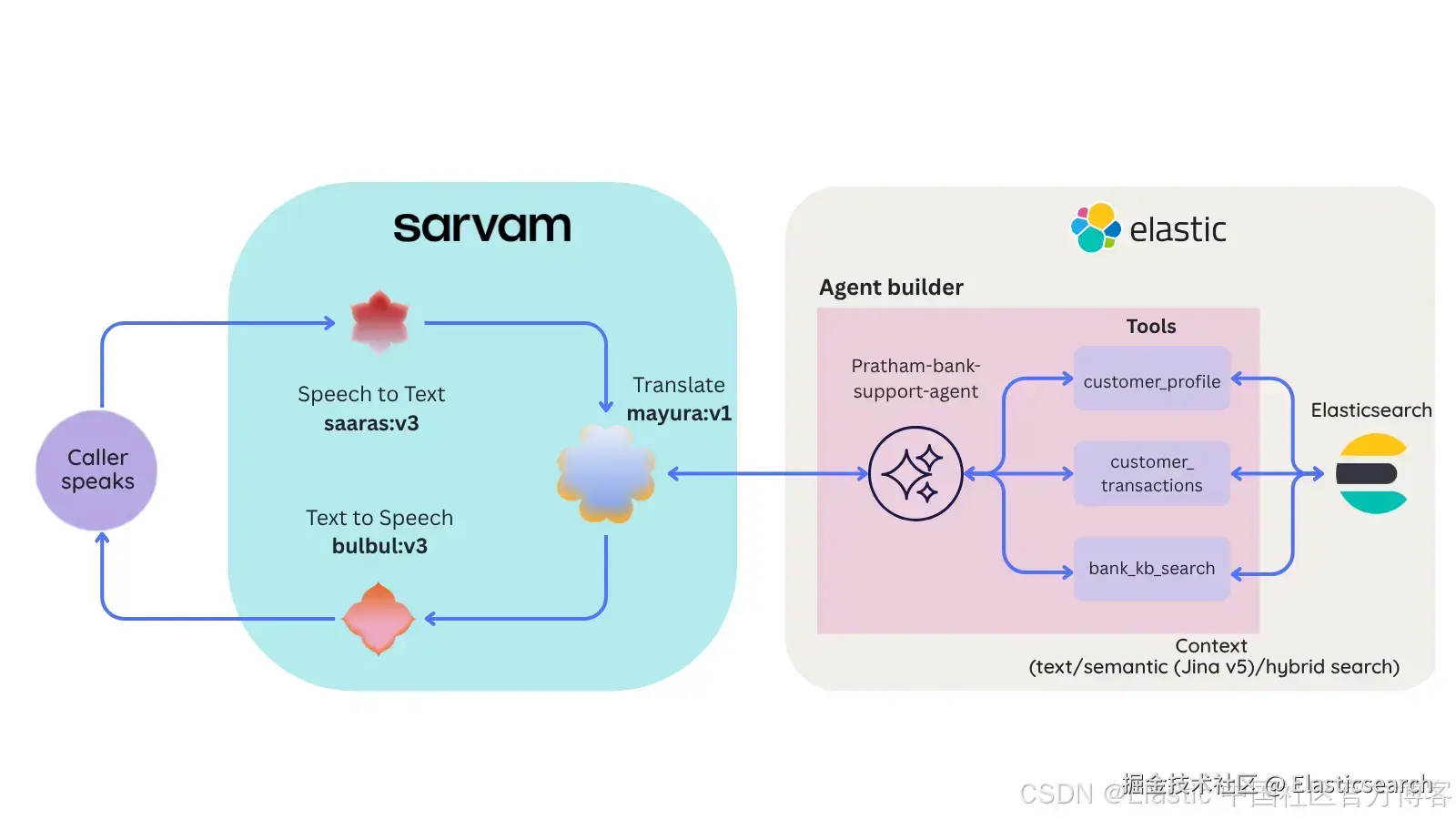
多语言语音 agent 架构如何工作?
整个系统依赖一个核心设计决策,这个决策让其余所有复杂性都得以保持简单:
来电者始终用自己的语言被听见并被回应,而 ElasticSearch 始终使用英语进行查询,以通过 agent 获取正确上下文。 Sarvam 负责两端的翻译,因此数据层和推理层保持语言无关;你不需要让索引、工具或 agent prompt 变成多语言版本。不过我们在语义搜索中使用的是 Jina 模型 v5,用于 semantic search,它支持多语言搜索。
下面是一次完整语音交互的端到端流程,由一个轻量 FastAPI 后端编排,本质上只是按顺序执行五个 HTTP 调用:
以下是单次语音交互的逐步流程:
-
音频输入(Audio Input): 过程从麦克风捕获用户语音开始。
-
语音转文本(STT)与语言检测: 音频被发送到 Sarvam AI 的 Saaras(v3)模型。该步骤负责转录语音并自动识别来电者使用的语言。
-
翻译为英语: 转写结果被传递给 Sarvam 的 Mayura(v1)翻译模型,将用户语音转换为英语。这确保推理层保持语言无关。
-
推理与工具执行: 英文文本被发送到 Elastic Agent Builder 的 POST /api/agent_builder/converse endpoint。该 agent 会验证用户身份,并通过工具检索信息(例如查询交易数据或知识库),然后生成回复。
-
翻译回母语与语音合成(TTS):
-
生成的英文回复会通过 Sarvam Mayura 模型翻译回来电者的原始语言。
-
最后,翻译后的文本会发送到 Sarvam Bulbul(v3)模型,生成自然语音(WAV)文件并播放给用户。
-
后端(Python 应用)本身不包含任何业务逻辑。它不会决定调用哪个工具、如何组织回答,或者是否验证通过,这些全部都在 Elastic Agent Builder 的 agent 内部完成。这种分层是刻意设计的:编排层保持极简、无状态(每次请求),而 "智能大脑" 则在 Elastic 中以声明式方式配置。
如何为语音 agent 设计 Elasticsearch 索引结构
我们使用三个索引,并按照 数据是什么(what the data is)以及如何查询(how it's queried)进行拆分 ------ 而这个拆分方式直接决定了整个 agent 的设计方式。
| 索引 | 数据类型 | 查询方式 | 使用场景 |
|---|---|---|---|
| bank-support-kb | 通用知识 | 混合 BM25 + 语义检索 | "如何举报欺诈?" |
| bank-transactions | 私有结构化数据 | 参数化 ES | QL |
| bank-customers | 私有结构化数据 | 参数化 ES | QL |
索引 1:通用知识(语义检索)--- bank-support-kb
贷款利率、费用说明、欺诈处理流程、退款规则以及养老金到账时间等内容 ------ 这些都是用户以模糊、多种表达方式提问的知识。
我们将其存储为 semantic_text,因此可以在零 embedding 代码的情况下实现混合关键词 + 语义检索。关键技巧是 copy_to:一个普通文本字段会被镜像到一个 semantic_text 字段中,并绑定到一个 inference endpoint,这样你就可以在同一份内容上同时获得 BM25 和向量检索能力。
bash
`
1. {
2. "mappings": {
3. "properties": {
4. "title": { "type": "text" },
5. "category": { "type": "keyword" },
6. "content": { "type": "text", "copy_to": "content_semantic" },
7. "content_semantic": {
8. "type": "semantic_text",
9. "inference_id": ".jina-embeddings-v5-text-small"
10. }
11. }
12. }
13. }
`AI写代码Embeddings 在 ingest(数据写入阶段)由所引用的 inference endpoint 生成(例如 [jina-embeddings-v5-text-small](https://www.elastic.co/docs/explore-analyze/machine-learning/nlp/ml-nlp-jina#jina-embeddings-v5-text-small "jina-embeddings-v5-text-small") )。整个过程中没有 embedding pipeline 需要运行,也不需要维护 vector store,更不需要处理 chunking 这种复杂的拼接逻辑。你只需要写入文档,然后用自然语言查询;Elasticsearch 会自动处理 BM25 + 向量融合。
索引 2 和 3:私有数据(精确结构化)
bank-transactions 是一个按客户划分的账本:工资、EMI、UPI、ATM、退款、养老金等,每一条记录都包含金额、渠道、交易对手、状态以及实时余额。
bank-customers 则保存每个客户的一条档案记录,其中包含用于验证的 dob 等信息。这些都是结构化数据,必须保证精确性,因此使用 ES|QL 查询,并且始终限定在单个 customer_id 范围内。你不希望用模糊语义去判断一笔 ₹14,999 的扣款是否发生,你需要的是确定性、可重复的精确查询。
如何为私有数据配置 Elastic Agent Builder 工具
Elastic Agent Builder 允许你在不使用独立 vector database、不搭建 RAG 框架、也不写复杂编排代码的情况下,让 agent 直接基于数据工作。
不过在这个场景中,我们仍然会显式给 agent 提供工具,以确保执行精度。因此你只需要添加工具和一段指令 prompt;Elastic 会负责推理循环、工具调用,并流式返回答案。
我们的 agent 只有三个工具,而它们的划分方式与数据模型完全一致:
-
bank_kb_search:用于知识库的 index_search 工具(针对 "如何举报欺诈?" 这类问题的 hybrid retrieval),在知识库上执行 BM25 + semantic search 的混合检索。 -
customer_profile:参数化 ES|QL 工具,用于验证 DOB 并检查账户状态。下面是 ES|QL 查询的写法:
vbnet
`1. {
2. "id": "customer_profile",
3. "type": "esql",
4. "description": (
5. "Fetch ONE customer's profile by customer_id,
6. ....
7. ),
8. "configuration": {
9. "query": (
10. f"FROM {CUST_INDEX} | WHERE customer_id == ?customer_id "
11. "| KEEP customer_id, name, dob, dob_display, mobile_last4, "
12. "account_last4, city, products, kyc_status, upi_status, "
13. "account_status | LIMIT 1"
14. ),
15. "params": {
16. "customer_id": {"type": "string", "description": "Authenticated customer id, e.g. CUST1002"}
17. },
18. },
19. },`AI写代码customer_transactions:一个参数化 ES|QL 工具:用于资金类问题("我的工资到账了吗?","那笔扣款是什么?")。示例交易工具:
vbnet
`1. {
2. "id": "customer_profile",
3. "type": "esql",
4. "description": (
5. "Fetch ONE customer's profile by customer_id,
6. ....
7. ),
8. "configuration": {
9. "query": (
10. f"FROM {CUST_INDEX} | WHERE customer_id == ?customer_id "
11. "| KEEP customer_id, name, dob, dob_display, mobile_last4, "
12. "account_last4, city, products, kyc_status, upi_status, "
13. "account_status | LIMIT 1"
14. ),
15. "params": {
16. "customer_id": {"type": "string", "description": "Authenticated customer id, e.g. CUST1002"}
17. },
18. },
19. },`AI写代码这些 ES|QL 工具是在设计层面就被"护栏化(guardrailed by construction)"的 :LLM 只能控制一个带类型的参数,而不能控制查询结构本身。它无法扩大 WHERE 子句,无法移除 customer_id 过滤条件(因为它更像一个 primary_key),也无法访问其他客户的数据行。
agent 本身是通过 POST /api/agent_builder/agents 创建的,其中包含定义行为的指令:向来电者问候、在披露任何信息之前验证出生日期(date of birth) 、将每次查询都限制在已认证的 customer_id 范围内,并根据意图选择合适工具(查询交易用 transactions,回答 "如何举报欺诈" 用 KB)。
因为这些逻辑都存在于 Kibana 中,而不是后端服务里,所以要修改 agent 的人格或规则,只需要编辑这些 instructions 并重新运行创建脚本即可。运行中的服务器本身不会改变;改变的是 agent 的定义。你也可以在 Kibana -> Agents 中直接修改这些指令。
如何调用 Elastic Agent Builder 的 converse API
在运行时,后端不会直接与 LLM 或索引交互。它只会将一个英文问题发送到 Agent Builder 的流式 converse endpoint,然后由 Elastic 负责编排工具调用与模型推理:
bash
`
1. POST {KIBANA_URL}/api/agent_builder/converse/async
2. Authorization: ApiKey <key>
3. kbn-xsrf: true
5. {
6. "agent_id": "pratham-bank-support-agent",
7. "input": "[AUTHENTICATED CALLER customer_id=CUST1002, name=Priya ...] Customer says: why was money debited?",
8. "conversation_id": "<persisted per call>",
9. "inference_id": "groq-1"
10. }
`AI写代码开发者需要重点注意的三点:
-
可信上下文,而不是 LLM 可以伪造的工具。 已认证的
customer_id由后端作为可信上下文注入到 agent 输入中。模型只是使用它来填充 ES|QL 参数,但它从不 "选择" 这个值,因此用户无法通过对话诱导系统访问其他账户。 -
跨轮次的身份保持。 后端为每个来电者维护一个
conversation_id。一旦 agent 在第一轮验证了来电者的 DOB,这个验证状态会在整个通话过程中持续生效,无需重复询问。出于演示目的,我们这里只加入了 DOB 验证,但可以扩展为更多验证参数。 -
可插拔的推理 LLM。 converse 请求体中的
inference_id字段(由AGENT_INFERENCE_ID环境变量设置)用于选择 agent 推理所使用的 chat-completion endpoint;如果留空,则使用 Agent Builder 默认模型。关键点是:这与semantic_text字段上的 embeddinginference_id是完全不同的概念。一个用于生成文档 embedding,一个用于进行推理。
响应采用 Server-Sent Events(SSE)流式返回;最终答案出现在 message_complete 事件的 message_content 字段中。(也建议显式处理 error 事件,否则工具调用失败时可能会静默退化为空回答。)
实际运行效果展示
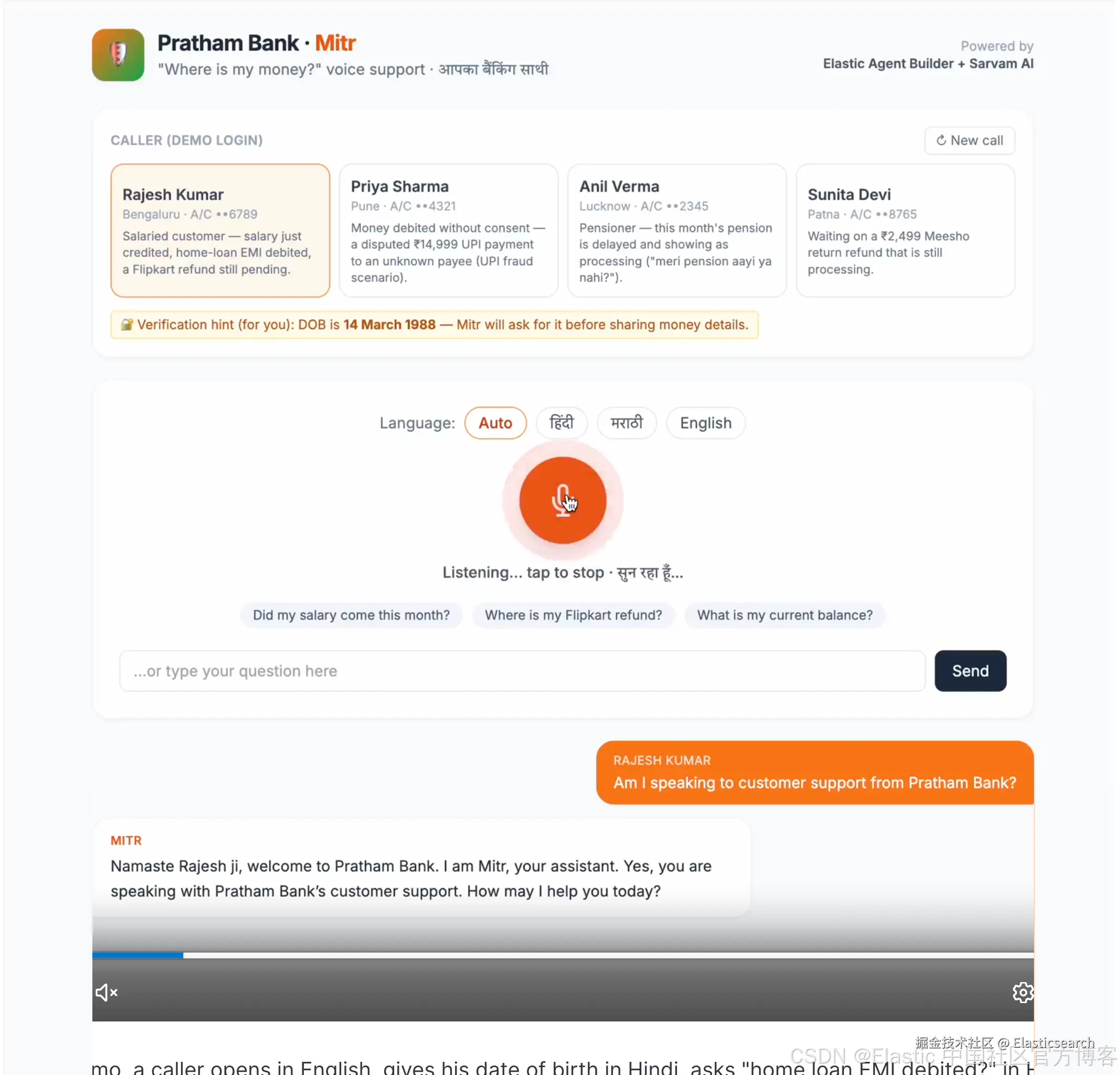 www.bilibili.com/video/BV1fg...
www.bilibili.com/video/BV1fg...
在这个 demo 中,用户一开始用英语发起对话,随后用印地语提供出生日期(date of birth),再用印地语询问 "home loan EMI debited?"(房贷 EMI 是否被扣款),之后又切换到马拉地语继续整个对话。
在这一次交互背后,agent 验证了他的 DOB,并通过 ES|QL 工具确认了他的房贷状态以及 Flipkart 退款情况。
还有另一个 demo 场景:"未经授权扣款(Money debited without consent)",在这个场景中,agent 会建议用户拨打印度 1930 网络犯罪热线,并通过语义知识库(semantic knowledge base)进行 UPI ID 冻结与处理建议。两个工具、三种语言、一次对话。在同一个 agent 中看到它在通话中平滑切换语言,是 Sarvam + Elastic 组合真正"成立"的时刻。
将多语言语音 agent 推向生产环境
这是一个 demo。所有数据都是合成的,"Pratham Bank" 是虚构的。但走向生产环境的路径主要是 "加固(hardening)",而不是重新设计。
在真实部署中,你需要做的是:
-
使用 Elasticsearch document-level security / RBAC ,基于已认证用户进行每个用户的访问控制,而不是信任传入的
customer_id; -
在浏览器麦克风之前增加真实的身份认证与电话系统或 WebRTC 层;
-
将密钥存储在托管的 secrets 管理系统中,而不是
.env文件。
但核心不会改变:
semantic_text + 参数化 ES|QL 的分层设计、先验证再查询的身份流程,以及严格的查询契约。
自行运行
整个系统是一个 Docker 工作流(清理、初始化索引与数据导入、构建 agent、启动服务),通过 .env 文件注入 Elastic 和 Sarvam 的凭证即可运行。
准备一个启用 Agent Builder的 Elastic 部署,并配置一个 text-embedding inference endpoint,再添加 Sarvam API key,几分钟内就可以和 Mitr 对话。
完整代码、配置和 demo 在这个 repo 中。
关键总结
-
让每个平台发挥各自优势。 Sarvam 负责语音与印度语言,Elastic Agent Builder 负责数据推理,两者之间只用一个轻量编排层连接。
-
"用用户语言回答"是一条单行契约,它让多语言系统保持可维护性;索引、工具和 prompt 都不需要多语言化。
-
semantic_text+ 参数化 ES|QL 工具 覆盖了智能体的两大核心能力(语义理解 + 精确私有数据),无需额外基础设施。 -
先验证身份,始终做作用域隔离。 身份验证和 per-customer 限制必须在工具层实现,而不是依赖模型判断,这是 demo 和生产系统的关键分界线。
Demo 中所有数据均为合成,"Pratham Bank"为虚构。基于 Elastic Agent Builder + Sarvam AI 构建。
原文:Mitr: multilingual banking voice agent with Sarvam AI - Elasticsearch Labs