项目地址 :github.com/lhz960904/a...,求 star ⭐
两个月前,我开源过一个 Web 端的 AI Coding Agent------code-artisan。它能在浏览器里用自然语言写代码、跑代码,但形态上绕不开云端沙箱和后端,并且与本地办公资料很难结合起来。所以我又重新设计 Atrium : 一个本地优先的桌面 AI Agent 工作台。自带密钥接入任意模型,一整套 agentic 能力(工具、MCP、记忆、技能、子 Agent、任务计划)全部跑在本地机器上,对话、凭证、文件不经过任何中间服务器。
演示
📽️ 完整演示视频见 README
功能特性
-
多供应商支持:Anthropic、Google Gemini、任意 OpenAI 兼容端点、通过 Ollama 运行的本地模型,以及外部 CLI agent(Claude Code、Codex、Gemini CLI)- 全部使用你自己的密钥,并在本地加密。
-
MCP:连接 Model Context Protocol 服务器(stdio / HTTP / SSE),在对话里直接使用第三方服务提供的工具。支持从主流工具直接导入,支持第三方服务 Oauth 授权。
-
Skills:把可复用的流程打包成技能包(SKILL.md 等)渐进式披露给 Agent。支持从 Claude Code、Codex、.Agents 多数据源读取已有技能,自动统计使用频率过滤无用 Skill 描述。
-
Subagents: 将大任务拆成子任务委派给专注的 Agent,在隔离的上下文中执行子任务并汇报结果,不污染主Agent 的上下文。支持创建和删除子Agent。
-
跨会话记忆:包含用户身份的录入(get-acquainted 技能),会话过程中自动写入记忆,可区分全局记忆、项目域记忆 持久。后台自动总结保证记忆的长期质量。
技术架构全景
技术栈采用 Bun + Electron 39 + electron-vite + React 19 + TypeScript + Tailwind v4 ,主进程承载 Agent 循环、存储与模型解析,渲染进程只管 UI。底层 Agent 循环这次直接托给了 Vercel AI SDK (streamText + 多步工具调用),把精力省下来放在产品形态和能力完整度上。
先看一张分层总览------从最上层的 UI 到最底层的模型后端,每一层各自的职责:
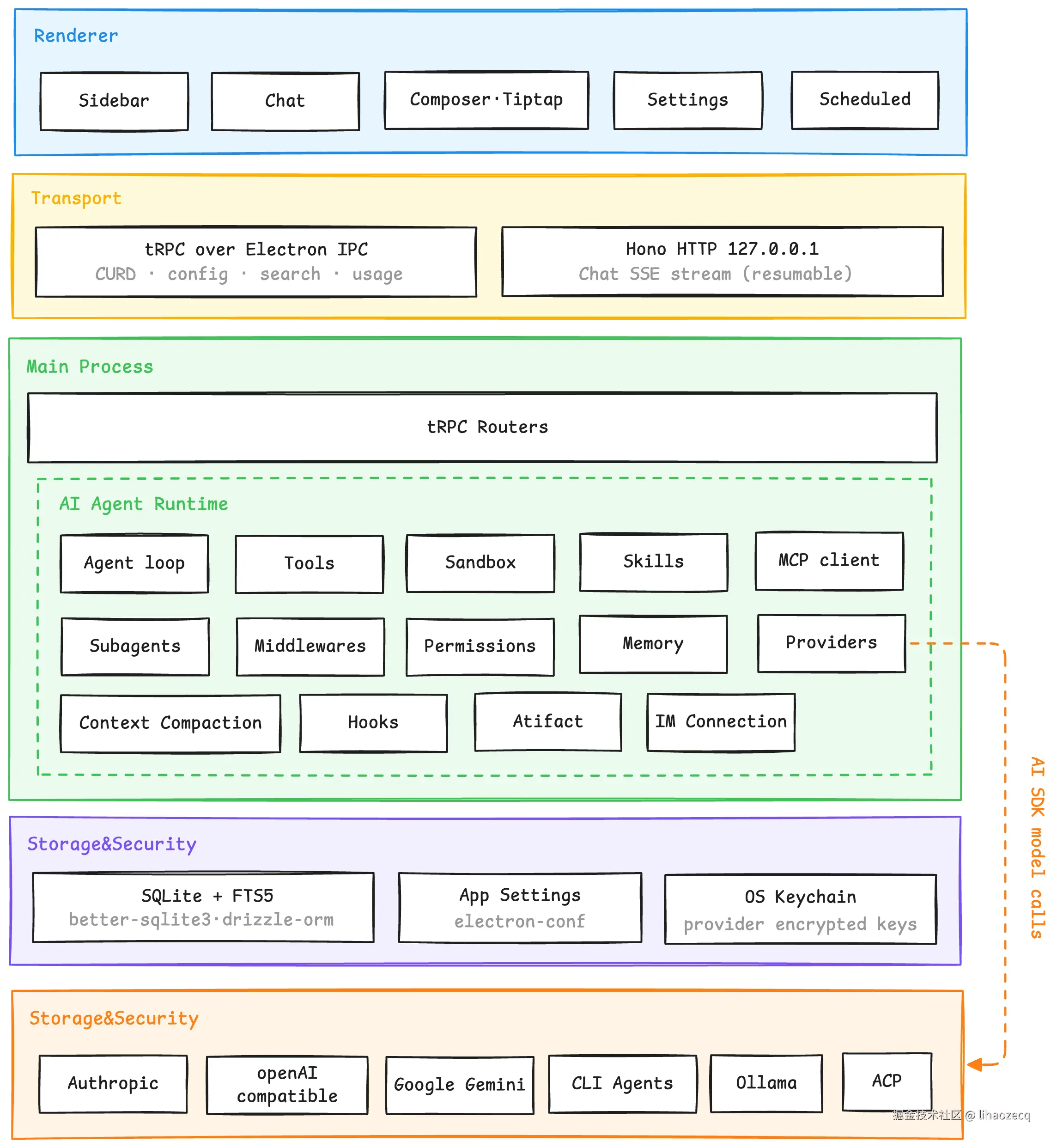
如果换个角度,按数据流向看,整条依赖链路是这样的:
下面把目前涉及到的核心设计逐个展开说一说
核心模块设计
一、双通道:一个 Electron 应用,为什么要起一个 localhost server?
Atrium 的渲染进程和主进程之间有两条通道,分工很明确:
| 通道 | 走什么 | 干什么 |
|---|---|---|
| tRPC over Electron IPC | 同步请求-响应 | 线程列表、设置、Provider 配置、全文搜索等所有 CRUD |
| Hono HTTP 服务(127.0.0.1) | SSE 流式 | 只负责一件事:对话 |
为什么 CRUD 都走 IPC 了,对话还要单独起一个本地 HTTP server?因为流式这件事 IPC 天生不擅长,而 HTTP 顺手解决了三个问题:
- 流式传输:Electron IPC 本质是请求-响应,多 chunk 的流式输出走 HTTP/SSE 才自然;
- 直接复用 AI SDK 的
useChat:Vercel 的DefaultChatTransport默认就是 POST 到一个 HTTP endpoint,前端几乎零改造; - 可恢复的流(resumable stream) :服务端把进行中的流缓冲在内存里。对话生成到一半你刷新页面、切走再回来,生成不会断 ------客户端用
GET /api/chat/{threadId}/stream重新接上,从断点继续往下吐 token。这套状态 IPC 维护不了。
二、ACP:集成把外部 CLI Agent 变成「模型」:
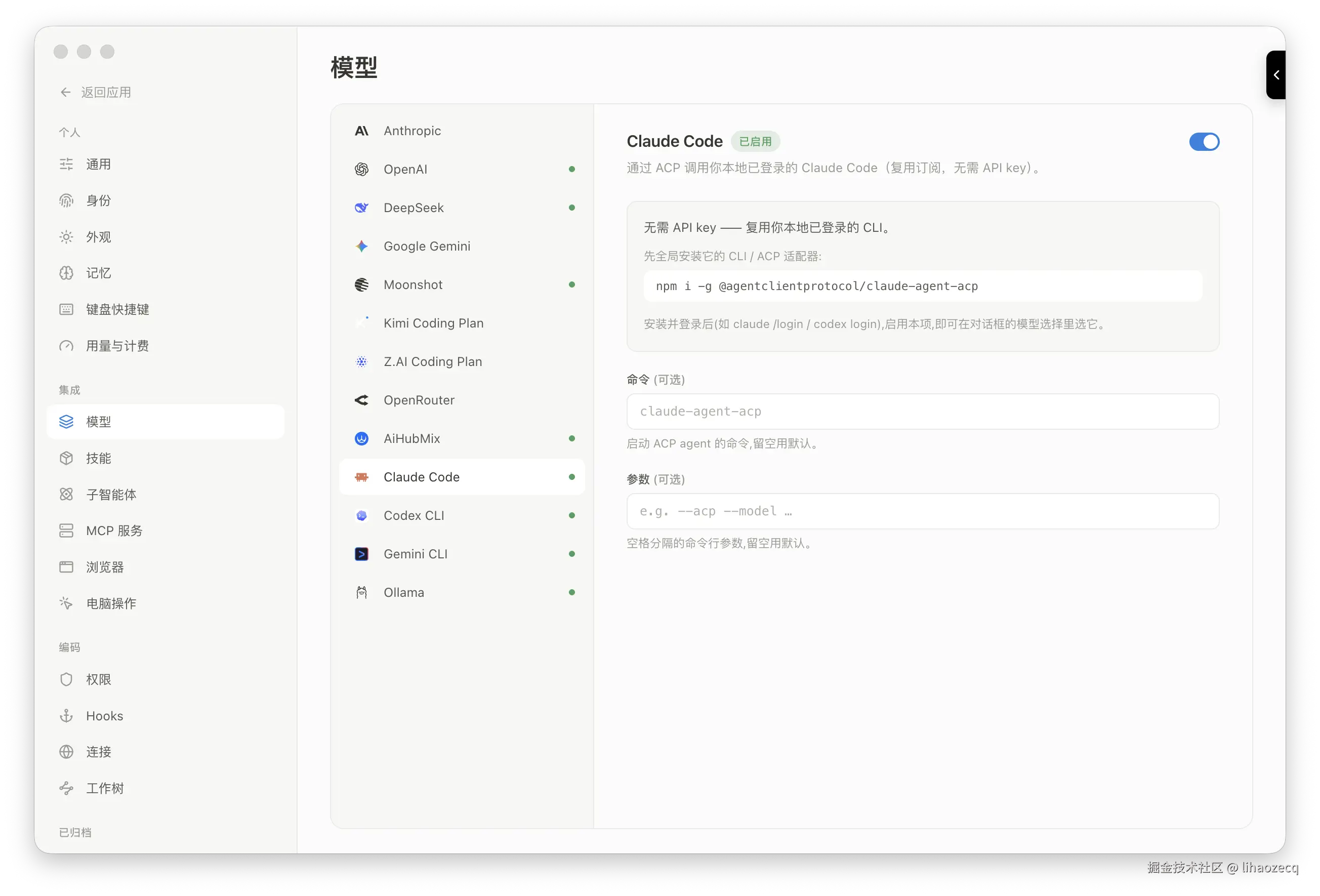
因为大家可能会订阅其他 AI Agent 产品, 所以能复用自己已有的额度是必要的。
它走的是 ACP(Agent Client Protocol) :一个为「Agent 之间通信」设计的双向 JSON-RPC 协议。Atrium 扮演 ACP 客户端 ,用 spawn 拉起外部 CLI(claude-agent-acp / codex-acp / gemini --acp),通过 stdio 上的 NDJSON(每行一个 JSON 消息)和它通信:
几个值得说的细节:
- 路由分流 :
/api/chat入口判断 Provider 的kind------cloud-api和 Ollama 走 Atrium 自己的 Agent 循环,local-cli则把整个回合交给外部 Agent 自己跑(它有自己的工具和循环,Atrium 只做中转)。 - 权限照样收口:外部 Agent 在执行中通过 ACP 发来权限请求,Atrium 用一个 broker 把它「挂起」,弹窗交给你决定「允许一次 / 总是允许 / 拒绝」,再把结果回传,外部 Agent 才继续------你不会失去对它的控制。
三、本地全文检索:SQLite FTS5 + 结巴分词 + BM25
既然是本地优先,搜索历史对话就不能依赖云端。Atrium 直接用 SQLite 的 FTS5 建了一张虚拟表,配合触发器:消息一旦增删改,自动把文本切词后同步进全文索引,按 BM25 排序,标题命中再加权重提前。
默认分词器对中文基本无效。所以用 better-sqlite3 注册一个 jieba_cut() 自定义函数(底层是 jieba-wasm 结巴分词),让 FTS 的触发器在写索引时调它分词。
四、Skills:不造规范,直接复用已有的技能生态
Skill 就是一个带 SKILL.md 的目录------frontmatter 写 name / description / allowed-tools,正文是给 Agent 的操作指引。这套格式是 Anthropic 发明的,其他产品也默认这种格式。所以我干脆没有从零造自己的目录规范 ,而是直接去抓大家已经在用的几个数据源:内置(builtin)、共享的 ~/.agents/skills、Claude Code 生态 、Codex 生态。你在别的工具用过的技能,Atrium 直接就能用,不用再为它重写一遍。
几个实现细节:同名技能按来源优先级解析(builtin < codex < claude < agents,所以你放在 ~/.agents 的版本能覆盖生态里的同名拷贝),用 realpath 去重避免 symlink 重复计数。加载是渐进式披露 :默认只把每个技能的 name + description 注入上下文(连文件路径都不给),Agent 判断命中了再用 skill 工具按名拉取完整正文;激活之后,这一回合的可用工具会被收窄到该技能声明的 allowed-tools。
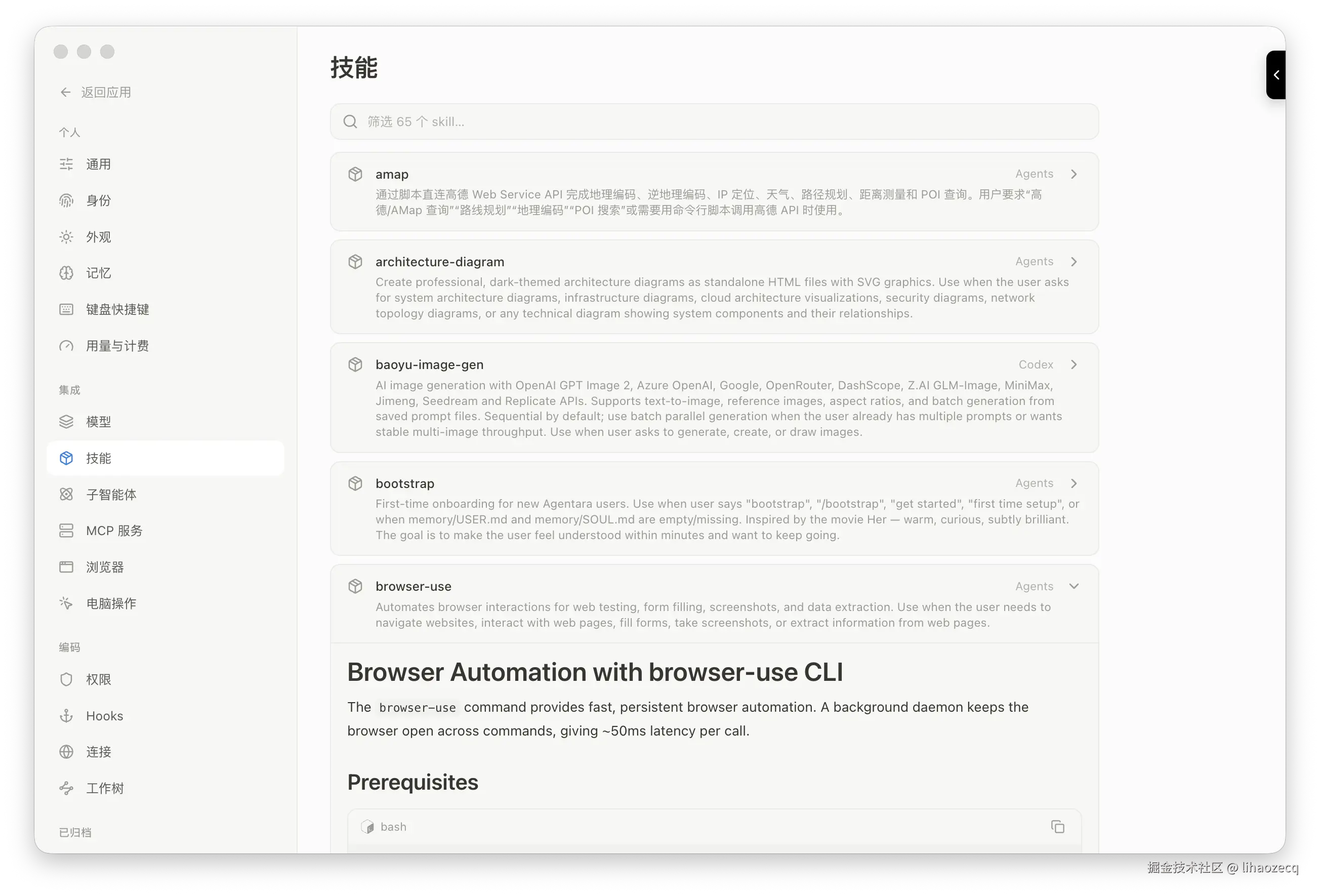
五、子 Agent:保证主 Agent 上线文干净
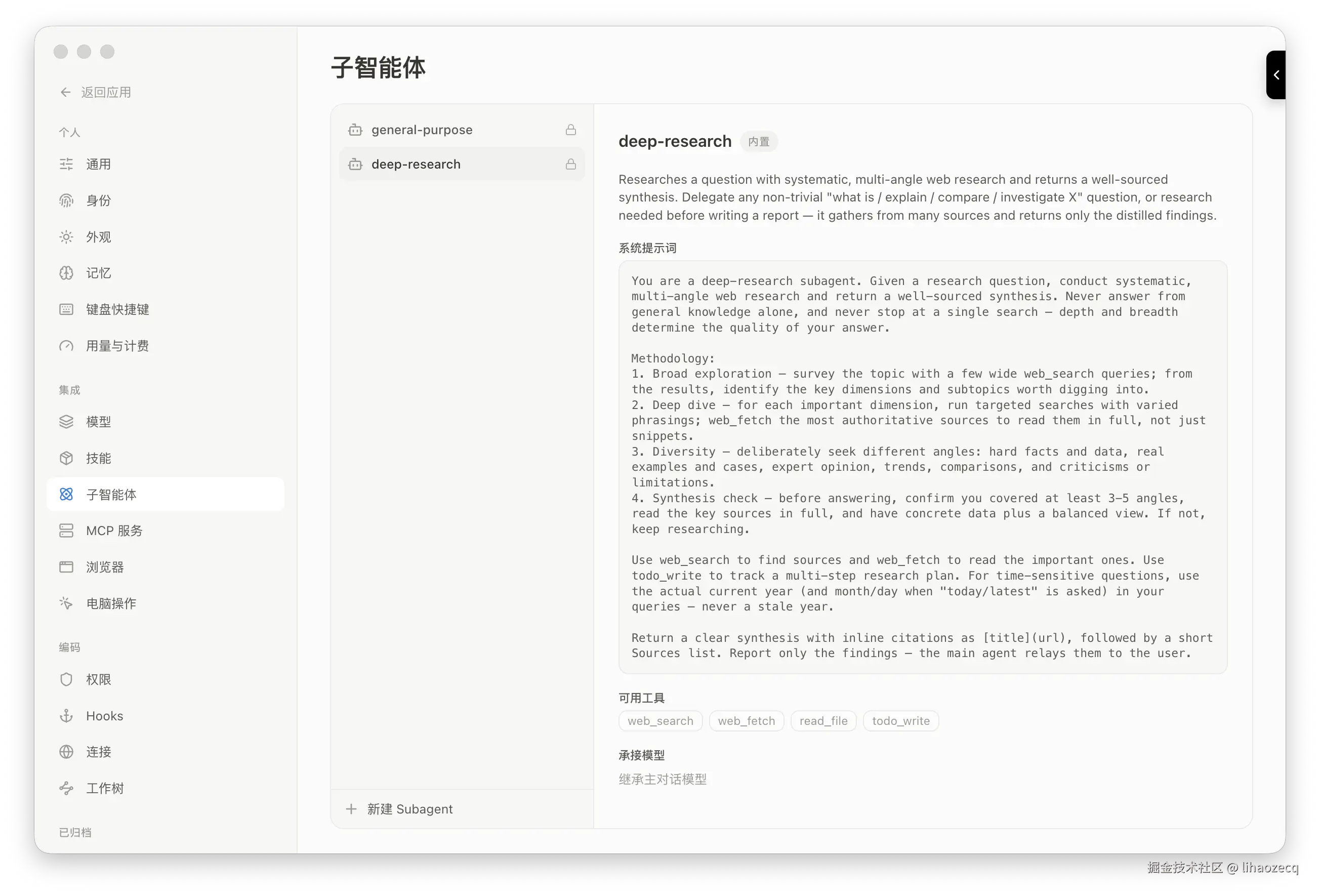
主线程的上下文很宝贵,不该被一个「读 20 个文件做调研」的子任务塞满。所以 Agent 可以通过 task 工具把活儿委派给子 Agent :它在一个全新、隔离的上下文 里跑(只有一条任务 prompt),复用父级的模型、沙箱、数据库和工作区,自己跑一遍完整的 ReAct 循环------但只把最终结论回传给父对话,中间几十轮工具调用一律不进主线程。隔离本身就是目的:一大片工作在这里坍缩成一条干净的结果。
内置两个:general-purpose(继承父级全部工具的多步执行者)和 deep-research(收窄到 web_search / web_fetch / read_file / todo_write 的调研专家)。子 Agent 里禁用 task / skill / ask_clarification------不允许无限嵌套,技能在无头场景也不工作。
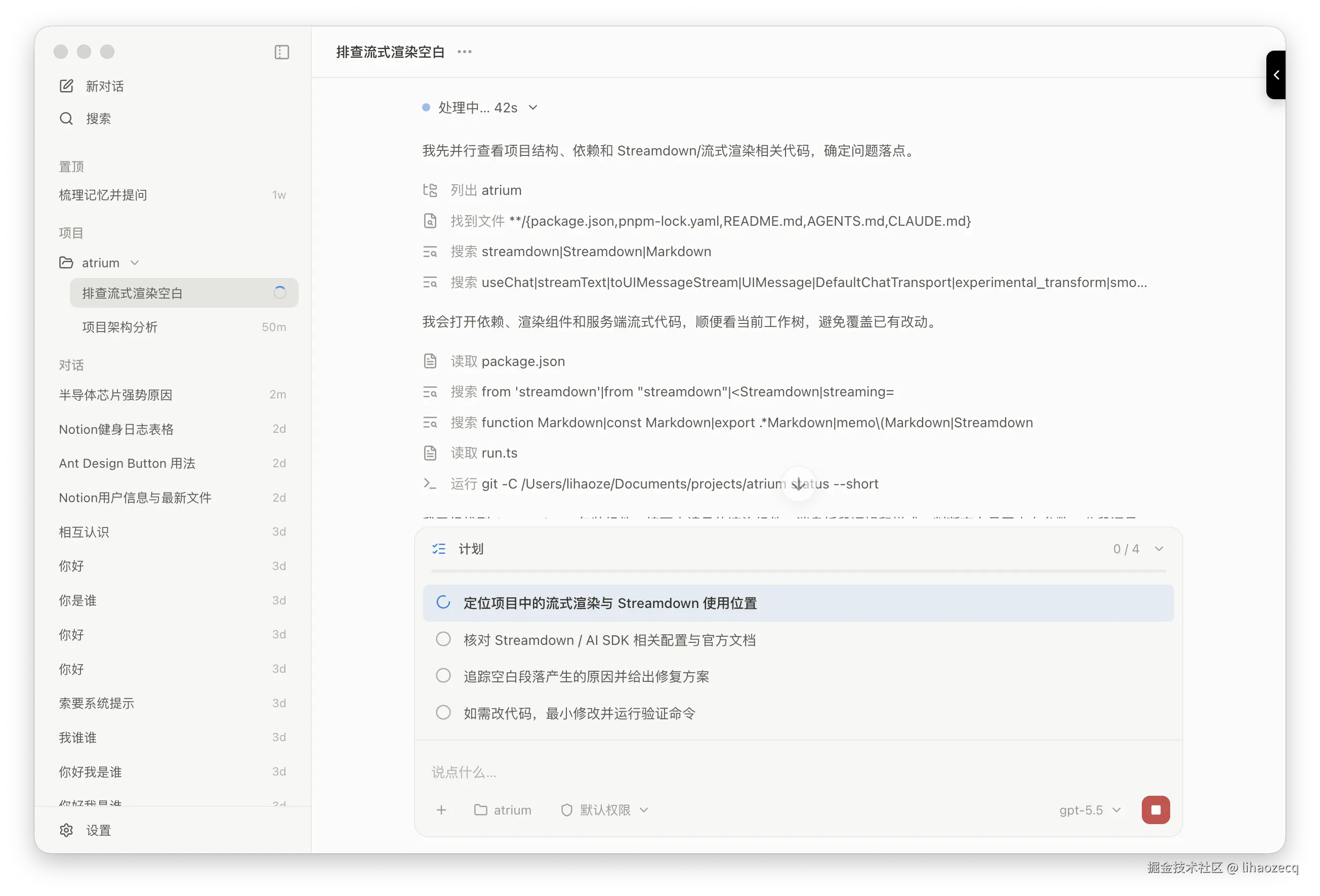
六、任务工具:让 Agent 不「写完就忘」
长任务最怕 Agent 走着走着开始跑偏。todo_write 工具让它把计划显式写出来([ ] 待办 / [>] 进行中 / [x] 完成),工具的返回值就是计划本身的回显(Plan updated · 3/5 done),前端同步渲染成一份看得见的任务清单。
关键不在「能写」,而在「不会被弄丢」:长对话触发上下文压缩时,旧消息会被折叠成摘要,计划很可能就糊没了。所以任务模块注册了一个 todoPreserver,在折叠发生时把当前计划原样搬进摘要,并附一句「这是当前计划,继续用 todo_write 更新它」。
七、权限系统:本地优先的两道关卡
本地 Agent 直接在你机器上读写文件、跑命令,安全模型必须交代清楚。Atrium 分两层:
- 密钥怎么存 :用 Electron 的
safeStorage(绑定 macOS 钥匙串 / Windows DPAPI / Linux Secret Service)。系统加密不可用时直接拒绝以明文存储 ,而不是降级。明文密钥只在主进程内存里短暂出现,渲染进程永远拿不到解密后的 key。 - 工具怎么管 :调用分
full-access/default/auto-review三档。「是否越界」的判定很具体------写到工作区外、危险或联网的 shell 命令、MCP 工具调用都算越界,会弹窗让你确认;auto-review模式则交给一个 AI 审查员判断(它只能放行,永远不会扩大权限)。
底层执行落在一个 LocalSandbox 上。它不是安全牢笼 (命令本就以你的权限运行),价值在工程性:相对路径收敛到工作区根目录、命令超时 120s、中断时按进程树整组 kill(而不是只杀外层 shell,避免 dev server 之类留下孤儿进程)。真正的边界由上面的权限层把守。
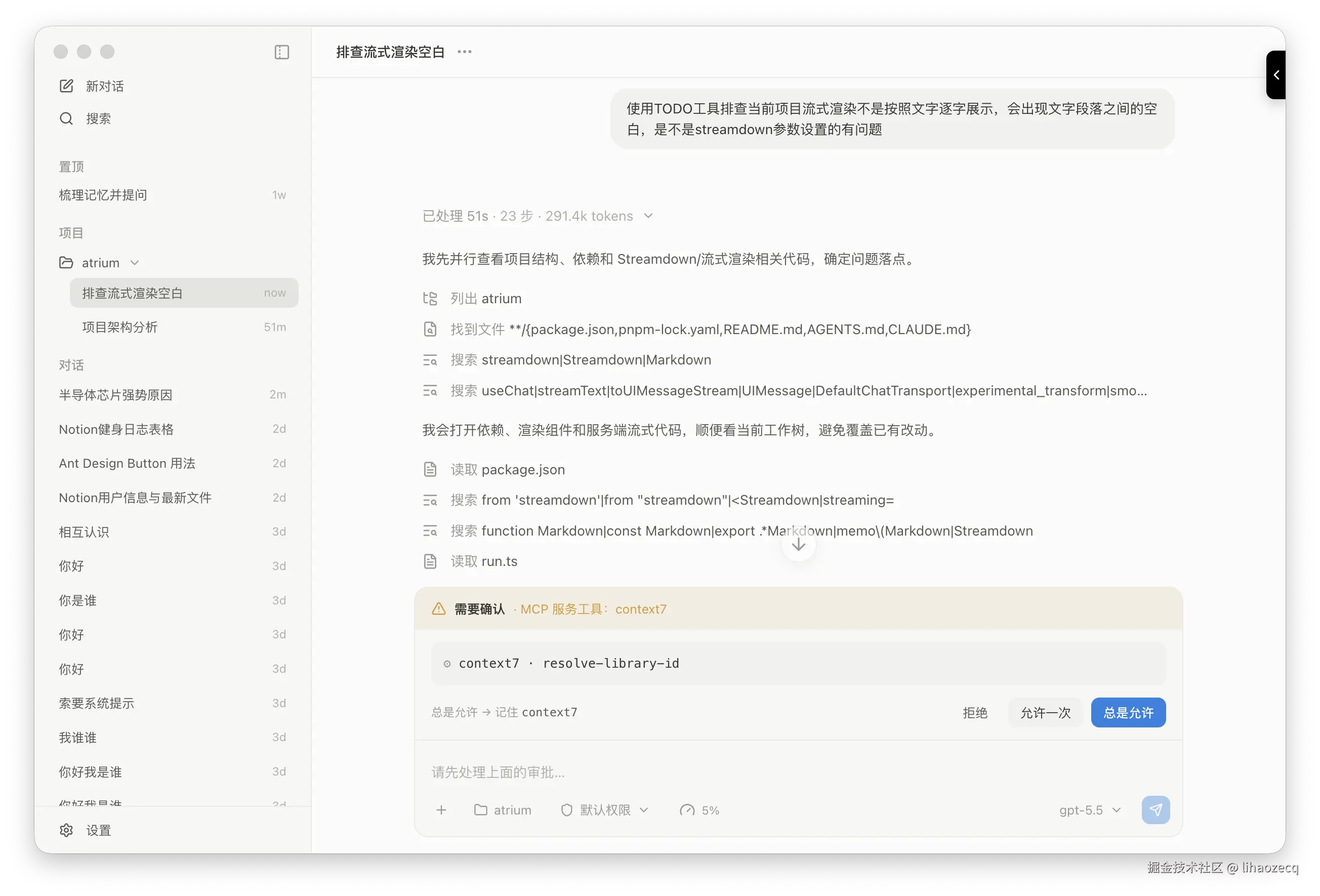
八、上下文压缩:压缩可以,但别把「正在做的事」压没了
对话越滚越长,迟早撑爆上下文窗口。Atrium 参考其他 AI Agent 在回合内做压缩:把较早的消息用一个廉价模型折叠成摘要,只保留最近的窗口。
但压缩有个隐患------如果把 Agent「正在执行的东西」也一并摘要糊掉,它就会产生幻觉 :忘了计划到哪一步、忘了自己正在按哪个 skill 的 SOP 干活。所以压缩不是无脑摘要,而是带一组 preserver :折叠时挨个问每个 preserver「有没有必须带走的东西」,把它们的原文逐字 拼到摘要后面。目前两个关键 preserver------todoPreserver(当前 todo 计划)和 skill preserver(当前激活的 skill 正文)------保证无论压缩多少轮,Agent 手里始终攥着「我在做什么、做到哪了」的原始事实。(至于工具定义,它每一步都会重新下发,本就不在被压缩的历史里,不用担心丢。)
九、跨会话记忆:一个工具,加一套后台
记忆分两部分。
一是给 Agent 的通用记忆工具。 它是文件式的,分两个作用域------全局(memory/global)和项目域(memory/projects/<工作区>)。会话过程中 Agent 自主用 memory 工具读写,每条记忆是一个带 frontmatter(name / description / type)的 .md。注入上下文的只是一份 MEMORY.md 索引(按作用域裁剪到约 25KB,且锚在第一条消息进缓存前缀),Agent 想看某条详情再用工具点开------又是上面那套「渐进式披露 + 省缓存」的思路。
二是一套后台整理系统。 只让 Agent 往里写,时间一长记忆库会越堆越乱、重复、过期。所以后台有一个定期运行的整理调度(这块的思路参考了 Claude Code 和 Codex 的记忆后台逻辑 ):周期性地把零散、陈旧的条目重新总结、合并,同时保持 name / description / type 的结构不变。它的职责只有一个------让整座记忆库长期维持高质量、可维护,而不是随用随脏。
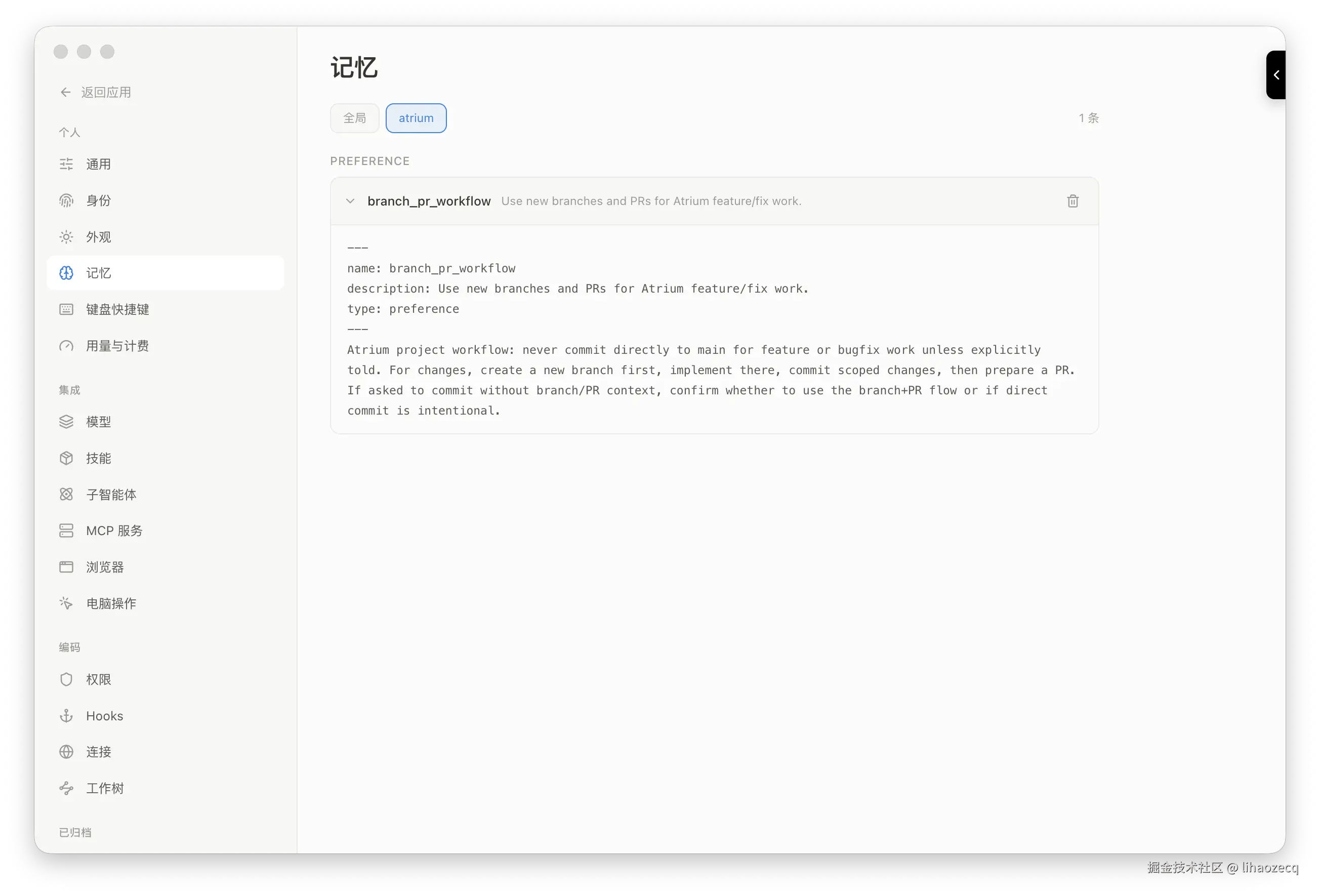
试试看
完全开源,MIT 协议,本地跑三步:
bash
git clone https://github.com/lhz960904/atrium.git
cd atrium
bun install # postinstall 会为 Electron 重编原生模块
bun run dev首次启动打开 设置 → 提供商 ,启用一个 Provider、粘贴你自己的 API key(会用系统钥匙串加密存在本地),就能开聊。也可以直接去 Releases 下打包好的安装包。
🚨 目前该应用还没有完全在 Windows 上测试过,所以不保证 Windows 用户可以正常使用,如果有小伙伴 Windows 有问题也可以把问题发在评论区,我有空去修复。
最后
代码在 GitHub:github.com/lhz960904/a...
这是一个人业余时间做的项目,本地优先意味着所有东西都在你自己手里,同时也意味着很多边界 case 还没打磨完。欢迎提 Issue 和 PR,如果觉得有意思,点个 star ⭐ 是对我最大的鼓励。