Function Calling 是 Agent 的"手"。
模型是"大脑",负责思考和决策。工具是"手",负责执行和操作。大脑再聪明,手不好使,活儿照样干不了。
但现实是什么?
90% 的 Agent 项目,把 90% 的精力花在调 Prompt、选模型、搭 RAG 上。工具设计?随便写个 JSON Schema,能跑就行。
结果就是:Agent 的大脑越来越聪明,手却越来越笨拙。
今天我们来"审"几个真实的工具设计案例。不讲理论,只看代码。好的工具设计长什么样,坏的工具设计坑在哪里,一目了然。
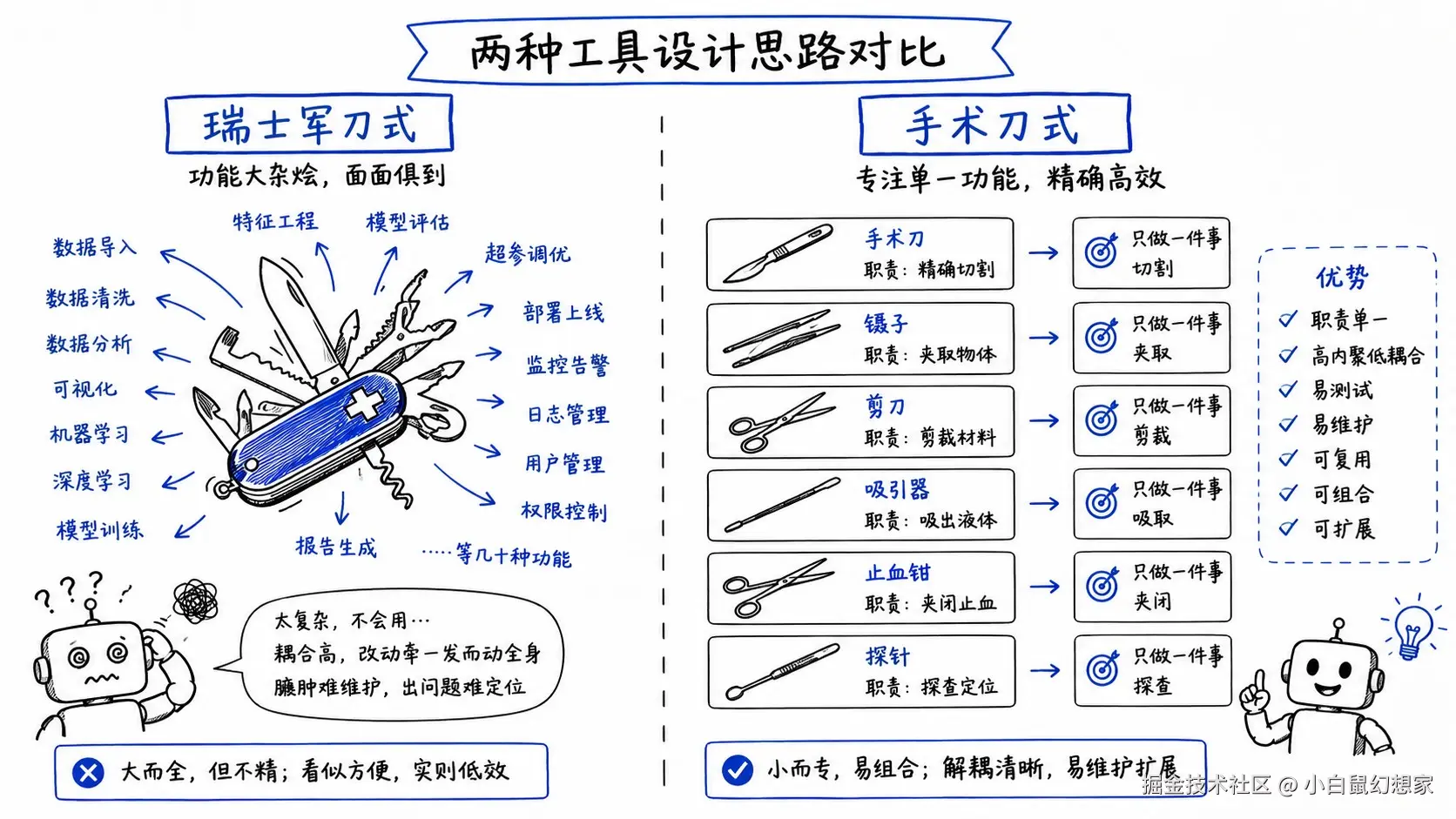
Code Review #1:工具粒度------"瑞士军刀"vs"手术刀"
先看第一个案例。
python
# ❌ 反模式:瑞士军刀式工具
@tool
def do_everything(action: str, params: dict) -> str:
"""执行各种操作:查询订单、修改用户、发送邮件、生成报告..."""
if action == "query_order":
return query_order(params["order_id"])
elif action == "update_user":
return update_user(params["user_id"], params["data"])
elif action == "send_email":
return send_email(params["to"], params["subject"], params["body"])
# ... 还有 20 个 elif问题诊断:
这是一个典型的"瑞士军刀"工具------一个函数干所有事。
表面上看,这样设计很"简洁":Agent 只需要调用一个工具,传不同的 action 就行。但实际上,这是给 Agent 挖坑。
坑 #1:参数验证地狱
params 是个万能字典,什么都能塞进去。Agent 调用 query_order 时,params 里应该只有 order_id。但如果 Agent 幻觉了,往 params 里塞了个 user_id 呢?工具不会报错,只会忽略这个多余参数。Agent 以为自己传对了,实际上工具根本没用到这个参数。
坑 #2:错误信息模糊
如果 action 拼错了(比如 qurey_order),工具会返回什么?大概率是一个通用的 "Invalid action" 错误。Agent 看到这个错误,根本不知道是自己拼错了,还是参数有问题,还是权限不足。
坑 #3:模型困惑
Function Calling 的核心是让模型理解"什么时候调用什么工具"。如果你只有一个 do_everything 工具,模型就得在每次调用时都"思考":这次我应该传什么 action?这个认知负担,会显著降低模型的准确率。
python
# ✅ 正确模式:手术刀式工具
@tool
def query_order(order_id: str) -> Order:
"""查询订单详情。
Args:
order_id: 订单编号,格式为 ORD-123456
Returns:
Order 对象,包含订单状态、金额、商品列表等
Raises:
OrderNotFoundError: 订单不存在
PermissionDeniedError: 无权访问该订单
"""
return order_service.get_order(order_id)
@tool
def update_user(user_id: str, email: str = None, phone: str = None) -> User:
"""更新用户信息。
Args:
user_id: 用户 ID
email: 新邮箱地址(可选)
phone: 新手机号(可选)
Returns:
更新后的 User 对象
Raises:
UserNotFoundError: 用户不存在
ValidationError: 邮箱或手机号格式错误
"""
return user_service.update_user(user_id, email=email, phone=phone)
@tool
def send_email(to: str, subject: str, body: str) -> EmailReceipt:
"""发送电子邮件。
Args:
to: 收件人邮箱地址
subject: 邮件主题
body: 邮件正文(支持 HTML)
Returns:
EmailReceipt 对象,包含发送状态和消息 ID
Raises:
InvalidEmailError: 邮箱地址格式错误
SendFailedError: 发送失败
"""
return email_service.send(to, subject, body)为什么这样更好?
- 参数类型明确 :
order_id: str而不是params: dict,模型知道该传什么。 - 错误信息精确 :
OrderNotFoundError比 "Invalid action" 有用 100 倍。 - 模型决策简单:模型只需要判断"我是否需要查询订单",而不是"我应该传什么 action"。
核心原则:一个工具做一件事。
就像手术刀------眼科医生不会用同一把刀切角膜和缝伤口。Agent 也不应该用同一个工具查询订单和发送邮件。
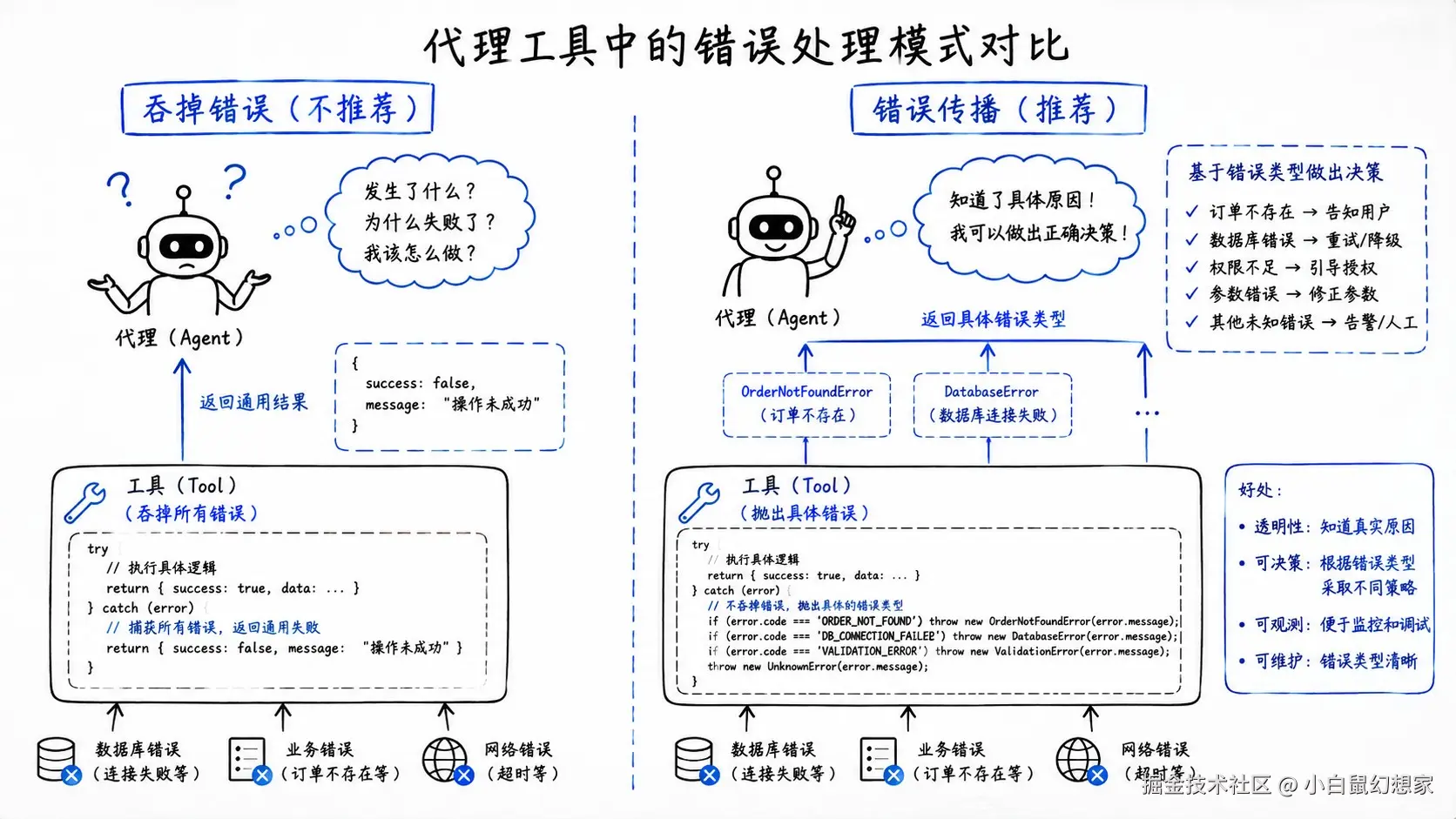
Code Review #2:错误传递------"沉默的杀手"
再看第二个案例。
python
# ❌ 反模式:吞掉错误
@tool
def query_order(order_id: str) -> dict:
"""查询订单详情"""
try:
order = order_service.get_order(order_id)
return {"success": True, "data": order}
except Exception as e:
# 吞掉所有错误,返回一个"安全"的默认值
return {"success": False, "data": None}问题诊断:
这个工具"吞掉"了所有错误。表面上看,它永远不会抛异常,Agent 调用它很"安全"。但实际上,这是给 Agent 喂毒药。
毒药 #1:Agent 不知道发生了什么
如果订单不存在,工具返回 {"success": False, "data": None}。Agent 看到这个结果,会怎么想?
- 订单不存在?
- 数据库连接失败?
- 权限不足?
- 参数格式错误?
Agent 完全不知道。它只能看到一个模糊的 success: False,然后陷入困惑。
毒药 #2:错误不会传播
假设 Agent 的工作流是:查询订单 → 检查订单状态 → 发送通知。如果查询订单失败了,Agent 应该立即停止,而不是继续执行后续步骤。但这个工具吞掉了错误,Agent 以为"查询成功了,只是数据为空",然后继续执行,最后发送了一个空订单的通知。
毒药 #3:调试噩梦
当系统出问题时,你去看日志,发现工具返回了 {"success": False, "data": None}。然后呢?没有错误堆栈,没有错误类型,没有错误信息。你只能猜。
python
# ✅ 正确模式:错误必须传播
@tool
def query_order(order_id: str) -> Order:
"""查询订单详情。
Raises:
OrderNotFoundError: 订单不存在
DatabaseError: 数据库连接失败
PermissionDeniedError: 无权访问该订单
"""
return order_service.get_order(order_id)为什么这样更好?
- 错误类型明确 :
OrderNotFoundError告诉 Agent "订单不存在",Agent 可以立即回复用户"您查询的订单不存在"。 - 错误会传播:如果工具抛出异常,Agent 框架会捕获它,Agent 知道"这一步失败了",可以决定是重试还是停止。
- 调试友好:错误堆栈会记录在日志里,你可以看到具体是哪一行代码出了问题。
核心原则:让错误"响"起来。
就像现实世界------如果你的手碰到火,神经系统会立即传递"疼痛"信号。如果神经系统"吞掉"了这个信号,你的手会被烧焦,而你的大脑还以为一切正常。
Agent 的工具也是一样。错误必须传递,必须"响"起来。
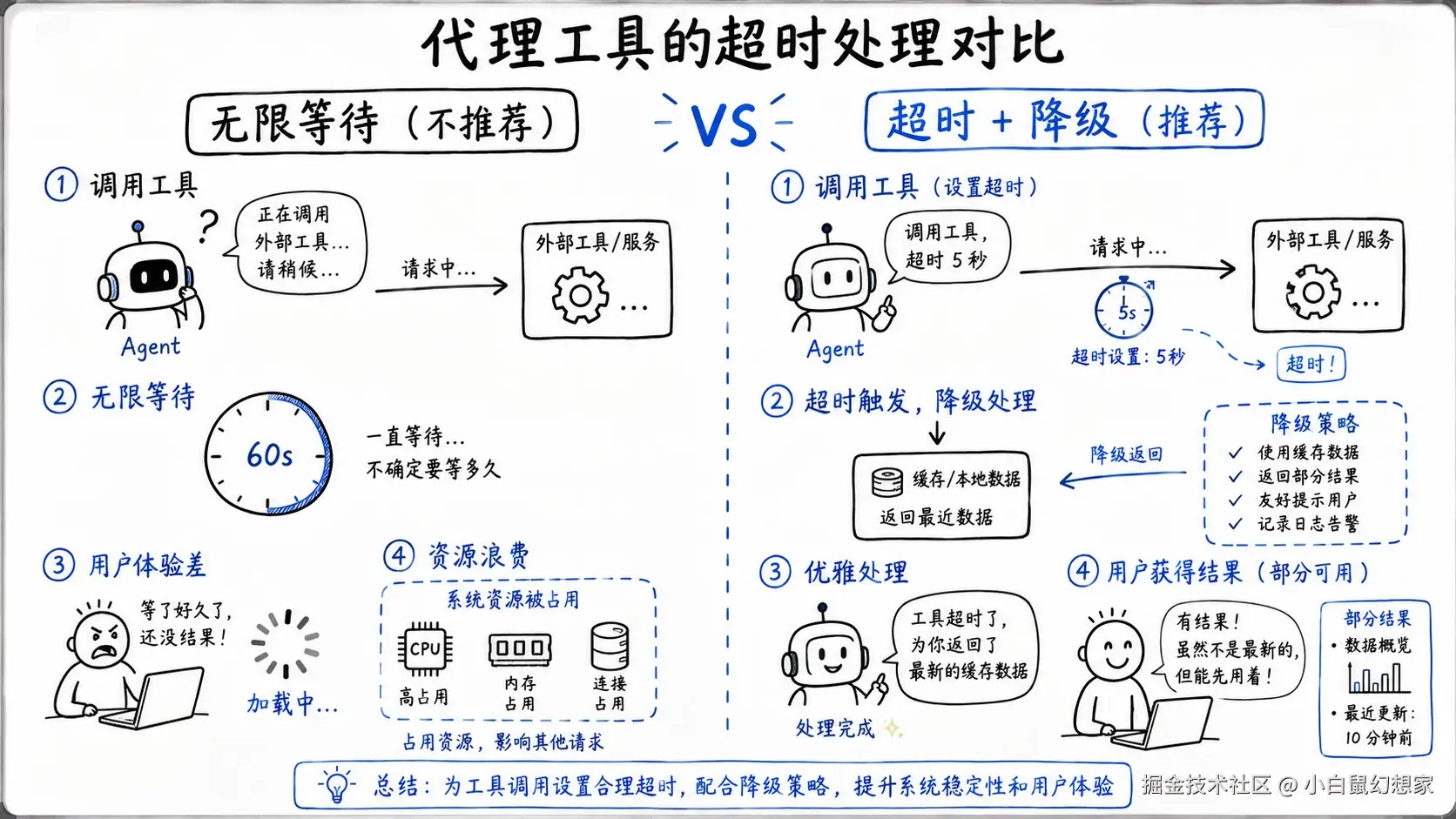
Code Review #3:超时处理------"无限等待"vs"优雅降级"
第三个案例。
python
# ❌ 反模式:无限等待
@tool
def call_external_api(endpoint: str, data: dict) -> dict:
"""调用外部 API"""
response = requests.post(endpoint, json=data)
return response.json()问题诊断:
这个工具没有设置超时。如果外部 API 挂了,requests.post 会一直等,直到 TCP 连接超时(通常是 60 秒)。
在这 60 秒里,Agent 在干什么?它在等。用户在看什么?用户在看一个转圈的加载动画。
问题 #1:用户体验崩塌
用户问了一个问题,期望 2-3 秒内得到回答。结果等了 60 秒,最后得到一个 "API 调用失败" 的错误。用户会怎么想?"这破 Agent 是不是卡死了?"
问题 #2:资源浪费
Agent 框架通常会为每个请求分配一个线程或协程。如果工具调用卡了 60 秒,这个线程就被占用了 60 秒。如果有 10 个用户同时提问,10 个线程都被卡住,系统直接瘫痪。
问题 #3:级联故障
如果这个工具被多个 Agent 共享,一个 Agent 的超时会导致其他 Agent 也超时。这就是经典的"级联故障"------一个外部 API 挂了,整个系统都挂了。
python
# ✅ 正确模式:超时 + 降级
@tool
def call_external_api(endpoint: str, data: dict) -> dict:
"""调用外部 API。
Args:
endpoint: API 地址
data: 请求数据
Returns:
API 响应数据
Raises:
TimeoutError: 请求超时(超过 5 秒)
APIError: API 返回错误
"""
try:
response = requests.post(
endpoint,
json=data,
timeout=5 # 5 秒超时
)
response.raise_for_status()
return response.json()
except requests.Timeout:
# 超时:返回一个"降级"结果,而不是抛异常
return {
"status": "degraded",
"message": "外部服务暂时不可用,已使用缓存数据",
"cached_data": get_cached_response(endpoint, data)
}
except requests.RequestException as e:
# 其他网络错误:抛异常,让 Agent 决定是否重试
raise APIError(f"API 调用失败: {str(e)}")为什么这样更好?
- 超时可控:5 秒超时,用户最多等 5 秒,不会等 60 秒。
- 优雅降级:如果外部 API 超时,返回缓存数据,而不是直接失败。Agent 可以告诉用户"外部服务暂时不可用,这是之前的数据,可能不是最新的"。
- 错误分类:超时返回降级结果,其他错误抛异常。Agent 可以根据错误类型决定是重试还是停止。
核心原则:给等待一个期限,给失败一个出路。
就像现实世界------你叫外卖,如果 30 分钟没到,你会打电话问,而不是一直等到饿死。Agent 的工具也是一样,必须设置超时,必须有降级方案。
Code Review #4:工具描述------"写给人类"vs"写给模型"
最后一个案例。
python
# ❌ 反模式:描述太简略
@tool
def search_products(query: str) -> list:
"""搜索商品"""
return product_service.search(query)问题诊断:
这个工具的描述只有 4 个字:"搜索商品"。人类看了能懂,但模型看了会困惑。
困惑 #1:搜索范围是什么?
query 是商品名称?商品描述?商品 ID?还是全文搜索?模型不知道。
困惑 #2:返回结果是什么?
返回的是商品列表?商品数量?还是分页结果?模型不知道。
困惑 #3:什么时候该用这个工具?
用户问"有没有红色的衣服",应该用这个工具吗?用户问"这个商品的库存有多少",应该用这个工具吗?模型不知道。
python
# ✅ 正确模式:描述写给模型看
@tool
def search_products(query: str, category: str = None, max_results: int = 10) -> list[Product]:
"""根据关键词搜索商品。
适用场景:
- 用户想找某类商品(如"红色连衣裙"、"iPhone 15")
- 用户描述了商品特征但没有具体商品 ID
不适用场景:
- 用户已经提供了商品 ID(应该用 get_product_detail)
- 用户想查询商品库存(应该用 check_inventory)
- 用户想查询商品价格(应该用 get_product_price)
搜索范围:
- 商品名称
- 商品描述
- 商品标签
- 品牌名称
Args:
query: 搜索关键词,支持中文和英文,如"红色连衣裙"、"wireless earbuds"
category: 商品分类过滤,如"服装"、"电子产品"(可选)
max_results: 最大返回结果数,默认 10,最大 50
Returns:
Product 列表,按相关性排序。每个 Product 包含 id、name、price、image_url。
如果没有匹配结果,返回空列表。
Example:
search_products("iPhone 15", category="电子产品", max_results=5)
-> [Product(id="P123", name="iPhone 15 128GB", price=5999), ...]
"""
return product_service.search(query, category=category, limit=max_results)为什么这样更好?
- 明确适用场景:模型知道什么时候该用这个工具,什么时候不该用。
- 明确搜索范围 :模型知道
query会搜索哪些字段。 - 明确返回格式:模型知道返回的是 Product 列表,每个 Product 包含哪些字段。
- 提供示例:模型看到一个具体的调用示例,更容易理解。
核心原则:工具描述是写给模型的"使用手册"。
就像现实世界------你买了一个新电器,如果说明书只有 4 个字"使用电器",你会怎么用?你会一头雾水。Agent 也是一样,它需要详细的"说明书"才能正确使用工具。
工具设计的 5 条铁律
审完 4 个案例,我们来总结一下工具设计的 5 条铁律。
铁律 #1:一个工具做一件事
不要做"瑞士军刀",要做"手术刀"。工具粒度太粗,模型会困惑;工具粒度太细,模型会选择困难。找到那个"刚刚好"的粒度。
铁律 #2:错误必须传播
不要吞掉错误。错误类型要明确,错误信息要详细。让 Agent 知道"发生了什么",才能决定"怎么办"。
铁律 #3:超时必须有
所有外部调用都必须设置超时。超时后要有降级方案,而不是直接失败。给等待一个期限,给失败一个出路。
铁律 #4:描述写给模型看
工具描述不是写给自己看的,是写给模型看的。明确适用场景、参数含义、返回格式、使用示例。让模型一看就懂。
铁律 #5:返回值要有结构
不要返回一个万能字典 {"success": True, "data": ...}。要返回明确的类型(Order、User、EmailReceipt),让模型知道返回的是什么。
写在最后
工具设计是 Agent 工程的"脏活儿"。
不像调 Prompt 那样有即时反馈,不像选模型那样有跑分对比,不像搭 RAG 那样有炫酷的架构图。工具设计就是写一堆 JSON Schema,枯燥、繁琐、没人关注。
但正是这些"脏活儿",决定了 Agent 能不能真正干活。
大脑再聪明,手不好使,活儿照样干不了。
先把工具设计好,再谈智能。不然你的 Agent 就是个"脑强手弱"的残废------想得很多,做得很少。