论文总结
1. 研究目的
- 系统比较不同组学(Omics)构建的生物年龄时钟(Omics Aging Clocks)的性能。
- 评估不同Age Clock预测年龄、疾病发生及健康风险因素的能力。
- 探究不同Age Clock是否反映相同的生物衰老信息(Biological Age)。
2. 数据集
- 以 ORCADES 队列作为主要训练数据集。
- 利用 UK Biobank、Estonian Biobank、Generation Scotland、Croatia-Vis、Croatia-Korčula 等多个独立队列进行外部验证。
- 覆盖年龄范围 16--100岁。
3. 数据类型
论文共比较了11类年龄时钟,包括:
- DNA甲基化(DNA methylation)
- PEA蛋白质组学(PEA Proteomics)
- NMR代谢组学(NMR Metabolomics)
- MS代谢组学(MS Metabolomics)
- MS复杂脂质组学(MS Complex Lipidomics)
- MS脂肪酸脂质组学(MS Fatty Acid Lipidomics)
- UPLC IgG糖组学(UPLC IgG Glycomics)
- DEXA身体成分
- 临床指标(Clinomics)
- Mega-omics(所有组学融合)
- 已发表年龄时钟(Horvath、Hannum、MetaboAge、GlycanAge等)。
4. 研究方法
- 基于 Elastic Net回归 分别构建各组学年龄时钟。
- 定义 OCAA(Omics Clock Age Acceleration) 作为生物年龄加速指标。
- 利用 Pearson相关分析 和 方差分解(Variance Partitioning) 比较不同Age Clock之间的一致性。
- 利用 Cox比例风险模型 分析OCAA与疾病发生的关系。
- 利用 线性回归 分析OCAA与健康风险因素的关系。
- 采用 Benjamini--Hochberg(BH)方法 进行FDR多重比较校正。
5. 主要结果
7. 主要结论
-
不同组学均可构建高精度年龄预测模型,准确预测Chronological Age。
-
不同Age Clock之间存在较高的信息重叠,说明它们反映了共同的衰老过程。
-
OCAA能够预测未来疾病发生及多种健康风险因素,如BMI、CRP、总胆固醇等。
-
不同Age Clock具有不同的预测优势:
- PEA蛋白质组学更擅长预测风险因素;
- DNA甲基化和IgG糖组学更擅长预测疾病发生。
-
仅使用少量核心特征或少数主成分(PCs)即可获得与完整模型相近的预测能力。
6. 创新点
-
首次在同一研究框架下系统比较11类不同组学年龄时钟。
-
提出Age Clock之间信息重叠(Overlap)的分析方法,评估不同时钟是否测量相同的衰老信息。
-
同时比较不同Age Clock在年龄预测、疾病预测和风险因素预测中的表现,为不同组学时钟的应用提供依据。
-
生物年龄(Biological Age)可以通过多组学数据进行有效评估。
-
不同组学构建的Age Clock既存在共同信息,也反映了不同的生物衰老过程。
-
预测Chronological Age最准确的Age Clock,并不一定具有最好的疾病预测能力。
-
未来Biological Age Clock的构建应更多以疾病、发病率或死亡等临床结局作为训练目标,而不仅仅是Chronological Age。
摘要
生物年龄(BA)是一种衡量功能状态并能预测健康结局的指标,可区分具有相同实际年龄(chronAge)的个体。目前已有多种生物标志物可用于其估算。以往的比较研究主要采用表观遗传模型(衰老时钟),而本研究则纳入约1000名参与者,对比了15种组学衰老时钟;即使对部分生物标志物进行大幅筛选后,这些时钟与chronAge的相关系数仍维持在0.21至0.97之间。这些时钟均能反映衰老过程中的共同特征,且不同时钟所解释的chronAge变异度占比达95%。BA与chronAge之间的差异------即组学时钟年龄加速值(OCAA)------通常与健康指标密切相关:一年的 OCAA 对风险因素或十年疾病发病率的影响,相当于0.09年或0.25年的chronAge变化。表观遗传时钟和IgG糖组学时钟主要反映整体衰老趋势,而其他时钟则侧重捕捉特定风险因素。我们得出结论:BA具有可测量性和预测价值,未来研究应优先关注其对健康结局的影响而非chronAge本身。
引言
年龄是我们都熟悉的表型特征,也是包括主要致死原因在内的多种疾病的首要风险因素1。我们都能观察到伴随衰老而出现的明显变化:头发变白、脱发、皮肤弹性下降以及体态改变加剧;这些变化在相同实际年龄(chronAge)的人群中存在显著差异。然而,衰老还伴随着一些分子层面的特征------如端粒缩短、基因组不稳定性及细胞衰老------这些特征在同一实际年龄群体中也表现出变异1。此前已有假说认为,由这些分子特征所标志的潜在生物学年龄(BA),正是导致年龄相关性疾病风险增加的关键因素。2. 因此,测量生物年龄(BA)相较于 chronological age(chronAge)更能有效预测健康状况和功能能力;更重要的是,与chronAge不同4,BA具有可逆性3。自这一概念提出以来,学界致力于构建基于多种统计方法和生物标志物的BA模型;由此得出的估算值我们称之为组学时钟年龄(OCAs)。首批OCAs是表观遗传时钟模型,它们利用全基因组CpG位点的甲基化水平------即DNA甲基化(DNAme)------通过惩罚回归法估算chronAge5,6。OCAs相较于chronAge的优势在于其代表了"组学时钟年龄加速值"(OCAA),有望反映潜在的生物学效应。当Horvath时钟计算得出的DNAme OCAA 与全因死亡率存在关联时7,证实了DNAme作为有意义的BA指标而非单纯统计误差的有效性。此后,基于chronAge训练的衰老时钟模型已扩展至涵盖DNA甲基化5,6,8,9、端粒长度9,10、面部形态11、神经影像数据12--15、代谢组学16、糖组学17、蛋白质组学9,18--20以及免疫细胞计数21等多种维度。然而,目前针对不同组学衰老时钟(尤其是同一组个体中)在预测准确性、相关性等性能指标方面的比较研究仍较为有限。众所周知,第二代衰老时钟如DNAm PhenoAge和DNAm GrimAge已被证实能更精准地预测死亡率及健康结局,优于以往的衰老时钟2,22。但鉴于已发表的研究数量有限,且已有多项研究表明某些时钟对超越chronAge时间点的未来健康结局具有预测价值23--28,目前针对基于chronAge数据训练的衰老时钟特性研究仍显不足。若要深入理解这些年龄加速指标实际反映的内容,就必须对基于chronAge训练的多种组学衰老时钟进行进一步特征分析:OCA指标究竟是否能追踪超越chronAge的时间点的潜在生物年龄变化?还是说不同时钟的OCA指标对特定健康结局的预测能力存在差异?
对基于苏格兰人口的奥克尼复合疾病研究29队列(orcades)开展的深度组学分析及健康结局注释,使得我们能够评估基于chronAge训练的生物年龄(BA)时钟的实用价值与局限性。本研究在orcades同一批约1000名个体数据中,比较了我们基于9种不同组学检测方法构建的11个自研衰老时钟与4个已发表衰老时钟的表现,并纳入了全身成像数据以及基于所有组学数据综合分析得出的时钟模型。随后,我们通过评估这些推导出的 OCAA 指标与健康相关表型及随访长达10年的住院事件(评估后)之间的关联性,探讨其生物学意义。生物年龄概念引发了若干根本性问题:一个人是否仅对应单一生物年龄,还是存在可能涉及不同生理系统的多种生物年龄20,30?基于chronAge训练的各类OCAs指标究竟是在追踪同一生物年龄(其差异源于检测重点与准确性不同),还是分别反映不同的潜在生物年龄?本研究旨在对此展开深入探讨。
结果
组学时钟的性能表现
我们在orcades队列中构建了11个独立的衰老时钟模型,并使用chronAge数据集进行训练。这些模型基于已知能够有效构建衰老时钟的检测指标5,6,17,18,涵盖血浆免疫球蛋白G(IgG)聚糖、蛋白质、代谢物、脂质、DNA甲基化以及一系列常用临床参数(如体重、血压、空腹血糖等),我们将其统称为"临床组学"数据集。此外,我们还新增了两种用于构建衰老时钟的新型组学数据集:一种是基于 DEXA 全身成像技术获取的身体成分测量数据集;另一种则是整合所有相关组学检测结果的数据集,我们称之为"超级组学"数据集(详见表1及方法部分中的检测项目说明)。值得注意的是,在已有成熟且经过广泛验证的DNA甲基化时钟模型的基础上,我们的甲基化时钟预测模型并未完全创新------其预测变量集直接源自Hannum和Horvath开发的表观遗传时钟所使用的CpG位点子集,这些数据可通过Illumina EPIC 850k甲基化芯片获取。基于此前提,所有时钟模型均采用现有预测变量集并通过弹性网络回归法从零开始构建。我们首先评估了多种惩罚性回归方法:lasso回归、固定α值为0.5的弹性网络回归、以及通过交叉验证计算α值的弹性网络回归,并在orcades队列的75%样本上训练模型,剩余25%样本作为测试集进行验证。我们发现,在所有检测方法中,时钟模型在估算chronAge时的表现均与所使用的惩罚回归方法无关(补充图1),因此后续分析仅采用固定α值为0.5的弹性网络回归模型。为便于与基于chronAge训练的成熟组学衰老时钟模型进行比较,我们还计算了先前在orcades数据库中针对同一约1000名个体已报道的四种衰老时钟模型:Hannum 20135、Horvath 20136、GlycanAge17和MetaboAge16。我们承认 DEXA 衍生指标与常规临床指标之间存在差异。
虽然这些测量指标(临床组学)在技术上并非组学检测方法,但为便于后续表述,我们将所有衰老时钟统称为"组学时钟"。在测试集中,模型估算的年龄值(即OCAs)与大多数测试的组学时钟的chronAge值高度相关(表1),尤其是基于PEA蛋白质组学(r=0.93)和DNA甲基化数据(Hannum CpGs:r=0.96;Hannum 2013:r=0.95;Horvath 2013:r=0.94;Horvath CpGs:r=0.93)的时钟(我们使用orcades软件训练的自建时钟在训练集中的相关性见补充图2)。不出所料,宏组学OCAs的相关性最高(r=0.97)。尽管所有特征均被赋予同等贡献权重,但算法筛选出的特征主要基于DNA甲基化和PEA蛋白质组学(CpGs占34.6%,PEA蛋白质组学占31.8%,质谱代谢物占20.6%,其他占13.1%)。我们发现MetaboAge和MS脂肪酸脂质组学OCAs与chronAge的相关性最低(r=0.21;r=0.45;图1)。各组学时钟中可用于建模的生物标志物数量及最终入选列表详见表1(各检测方法中测量的完整生物标志物清单见补充表2,各时钟对应的系数见补充表3)。
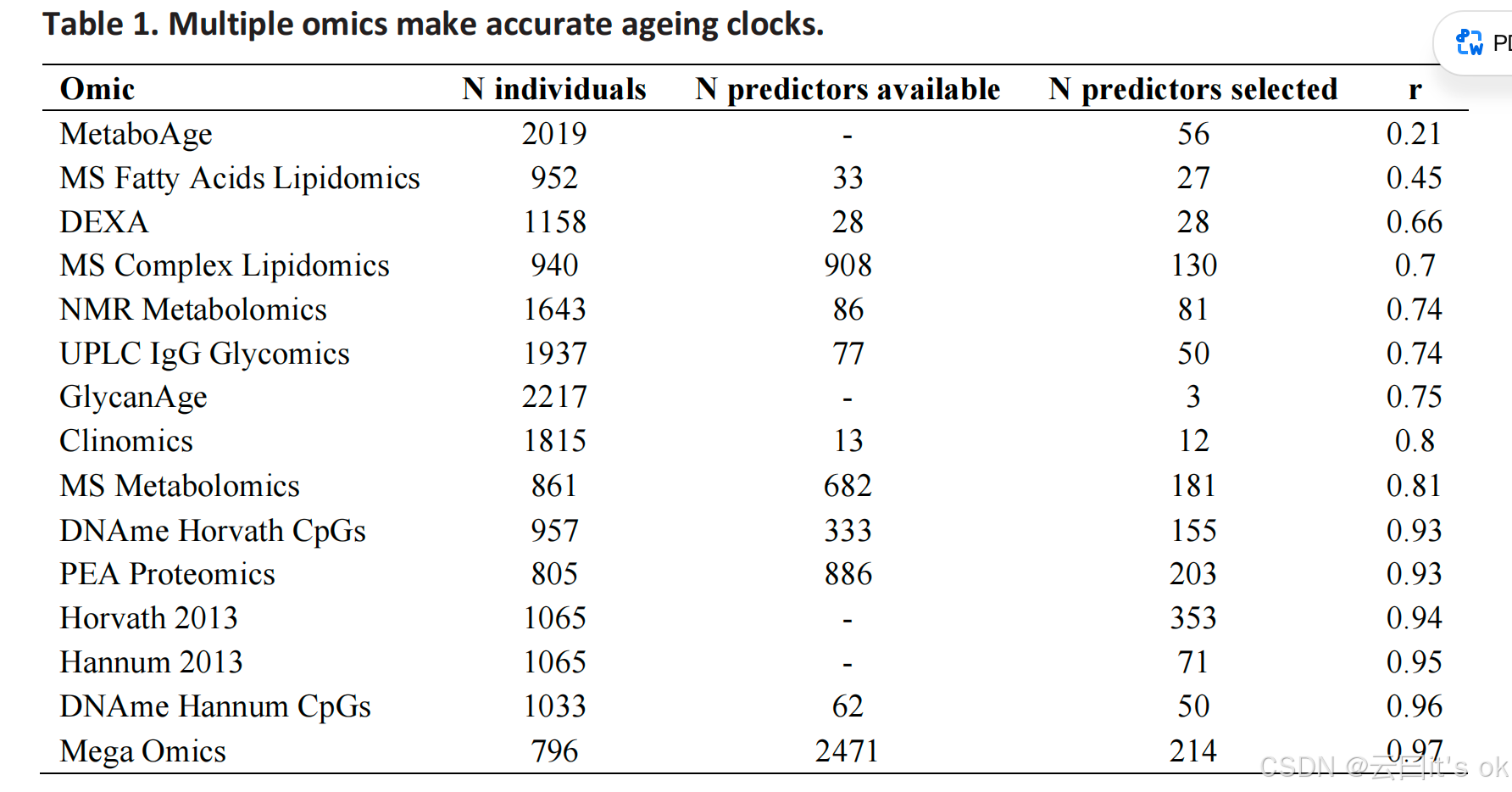
各组学检测指标说明如下:N个体数:奥卡德斯队列中通过质量控制的个体数量;可用预测因子数:通过检测层面质量控制、可纳入标准模型筛选的预测因子数量;已选预测因子数:被选定纳入标准模型的预测因子数量;r:组学时钟年龄(OCA)与chronAge之间的皮尔逊相关系数; DEXA :双能X射线吸收测定法;DNAme:DNA甲基化水平;CpG:胞嘧啶核苷酸后接鸟嘌呤序列(5'→3'方向);MS:质谱分析;NMR:核磁共振;PEA:邻近延伸分析; UPLC :超高效液相色谱;IgG:免疫球蛋白G。各组学类别中,受试者基线平均年龄为53--56岁(标准差15),不同时钟系统的年龄范围为16--100岁,女性比例为55--61%(见补充表1)。
在独立队列中验证时钟性能
随后,我们利用在Orcades数据库中训练的自建生物钟模型,对独立欧洲人群进行年龄估算,以验证该方法是否可广泛应用于奥克尼群岛以外地区。研究发现,OCA与chronAge之间的相关性在不同独立人群中均呈现不同程度的复现(补充图3)。基于PEA蛋白质组学和DNA甲基化数据构建的生物钟模型显示,欧洲人群中的OCA与chronAge相关系数为0.89--0.98,与Orcades数据中的0.91--0.96范围一致; UPLC IgG糖组学及Clinomics OCA模型在独立人群中测得的OCA-chronAge相关系数为0.56--0.62,低于Orcades数据中的0.74--0.80;而NMR代谢组学和 DEXA 模型在验证队列中的相关系数仅为0.26--0.55,显著低于Orcades数据中的0.66--0.73。
具备丰富核心生物标志物子集的时钟模型能够实现精确性能
若目标是开发具有临床应用潜力的BA时钟,则将更为高效且成本更低的减少患者需检测的生物标志物数量具有显著优势。为此,我们采用精简的生物标志物组合评估了所开发生物钟模型的性能。针对我们自主研发的11种组学生物钟模型,均参照Enroth等人18的方法(详见方法部分),仅选取在500次模型构建迭代中被纳入模型的比例超过95%的生物标志物来构建"核心"生物钟模型。结果显示,在全部11种模型中,OCA与chronAge指标均能通过少量核心生物标志物实现高度相关性(图2),这表明使用较少数量的预测因子(例如30至60个生物标志物)即可获得精确的年龄校正值(OCAs)。
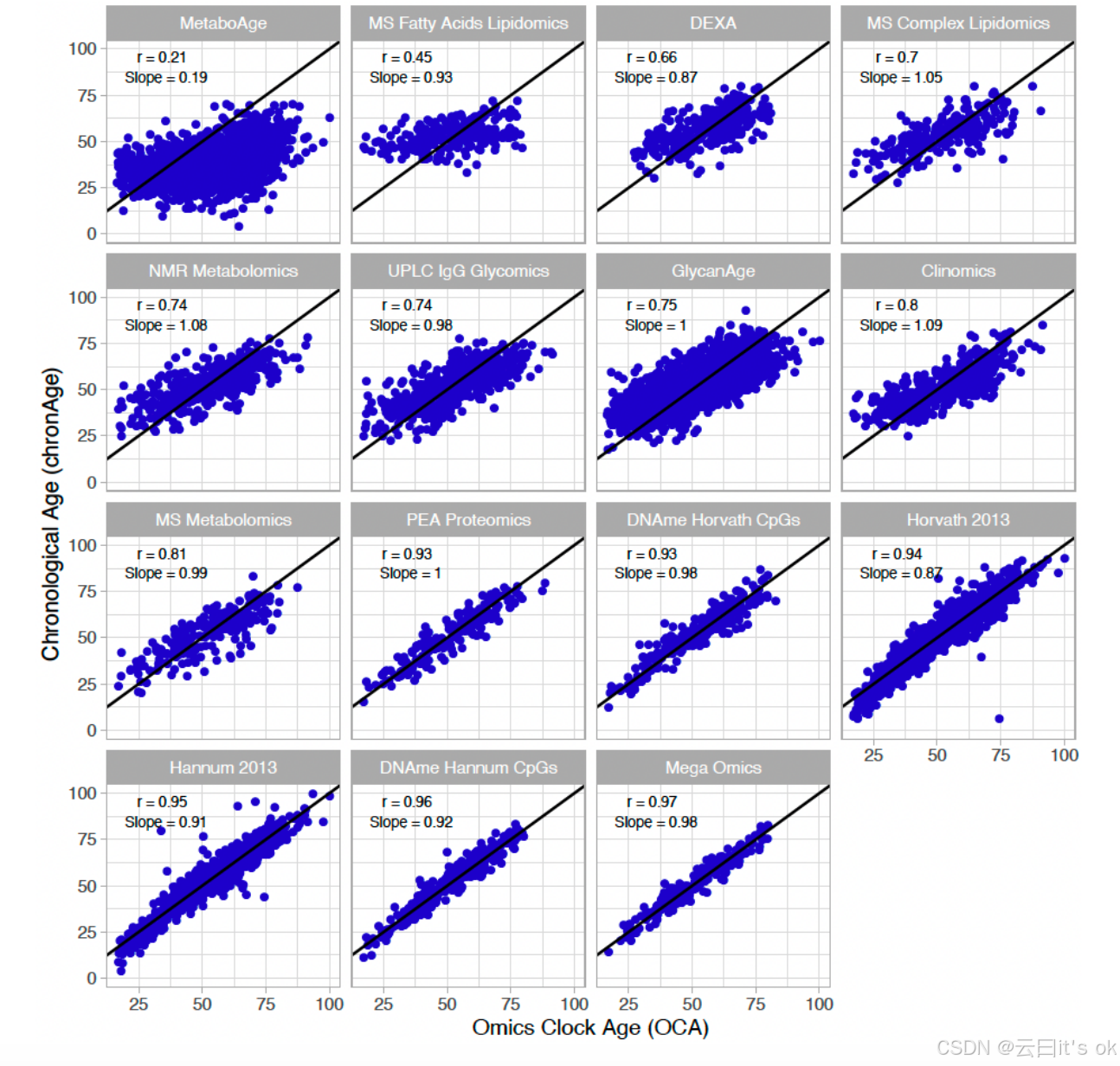
图1。多种组学方法以大致无偏的方式估算时序年龄,其准确性存在差异。纵轴上的chronAge值与orcades测试样本中通过组学衰老时钟(OCA)估算的年龄之间的相关性如图所示;各子图中均标注了皮尔逊相关系数(r)以及OCA对chronAge的回归斜率。黑色实线表示一致性线。
不同生物钟所显示的生物学年龄比较
组学时钟年龄加速指标(OCAAs)在不同时钟模型之间显示出不同程度的正相关性(图3)。不出所料,我们基于orcades和GlycanAge数据训练的 UPLC IgG糖组学时钟是相关性最高的OCAAs(r=0.94)。四个基于DNA甲基化的OCAAs在层次聚类中形成独立群体------其中两个基于orcades数据训练(补充图4),DNAme Hannum CpG位点与DNAme Horvath CpG位点OCAAs的相关系数为r=0.73。在包含其他组学OCAAs的另一簇中:主要基于脂质种类及组分构建的三个时钟模型(MS脂肪酸脂质组学、MS代谢组学和MS复杂脂质组学)均聚在一起; DEXA 、Clinomics、 UPLC IgG糖组学及GlycanAge时钟则构成一个关联群组。值得注意的是,PEA蛋白质组学 OCAA 在更大的非DNA甲基化簇中呈现独立聚类(补充图4)。为明确起见,所有不同OCAAs之间的相关性分析以及后续报告的所有下游分析均采用源自标准组学时钟的OCAAs进行计算,而非前文第2图中所述的"核心"时钟模型。
不同时钟模型所解释的年龄变异比例
为确定我们使用的不同生物钟是否解释了chronAge数据中相同或不同的变异度,我们将chronAge的变异度按各生物钟进行分解分析。我们计算了每个OCA模型单独解释的chronAge变异度(即chronAge与OCA模型之间的平方部分相关系数),并控制了其他所有生物钟的影响。结果显示:94.9%的chronAge变异度可由两个及以上生物钟共同解释;3.6%的变异度无法被所测试的14种衰老生物钟单独解释;其余1.5%则可由单一生物钟独立解释(补充图5A)。PEA蛋白质组学模型和Hannum 2013生物钟模型分别解释了其他任何模型均未能捕捉到的最大变异量(分别为0.46%和0.37%;补充图5B)。各生物钟间的两两比较结果详见补充图6。
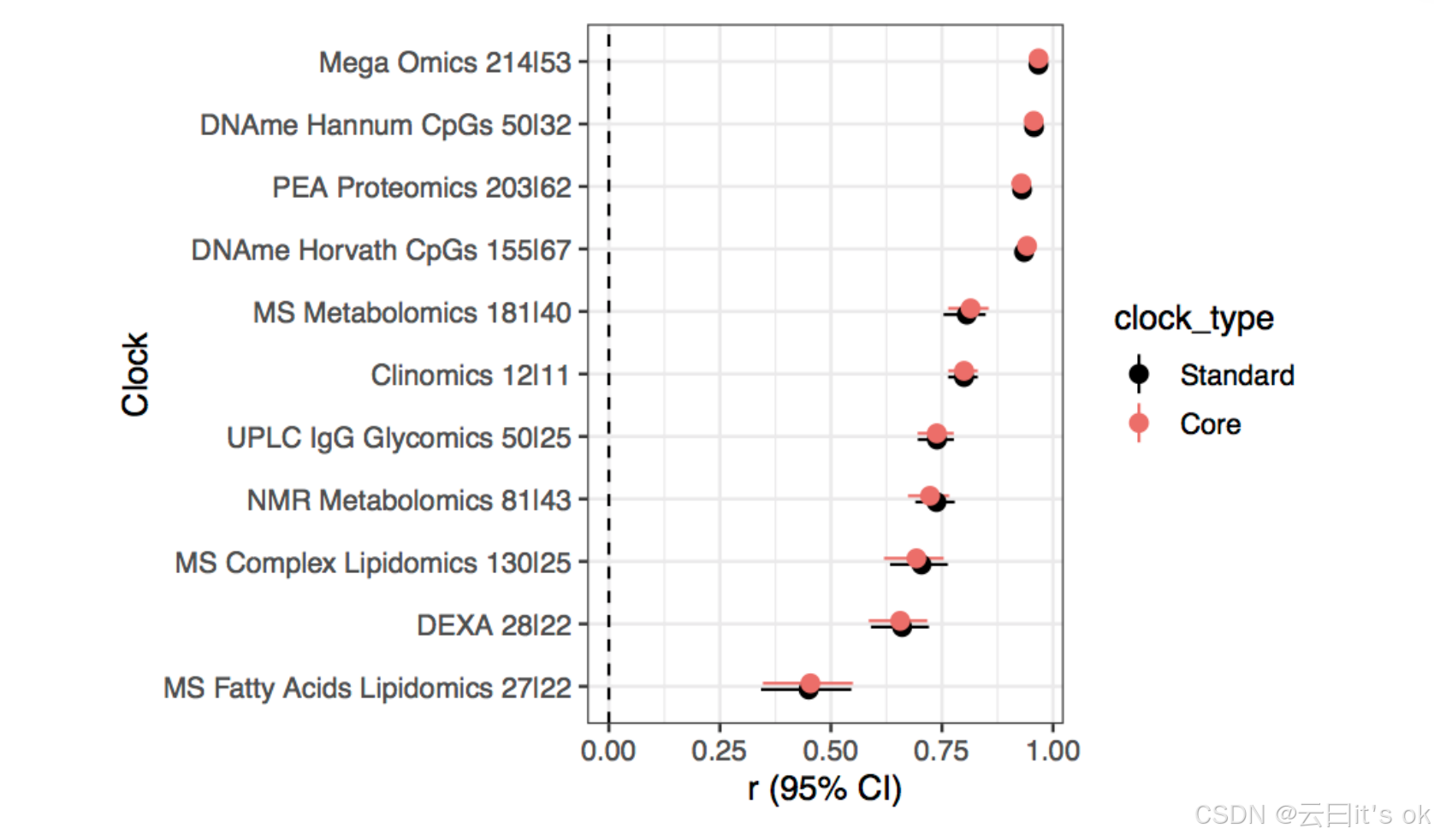
图2。对生物标志物进行大幅子集筛选仅导致准确度轻微降低。纵轴显示orcades测试样本中各组学检测方法的标准模型与核心模型中chronAge及OCAs的Pearson相关系数(r)及其95%置信区间;标准模型与核心模型中选取纳入的预测变量数量标注于纵轴标签(standard|core)。
在发现这些生物钟所提供的关于年龄(chronAge)的信息存在重叠后,我们进一步检验:若两组生物钟各自独立从年龄的完整潜在预测变量集合(ISLSP)中采样,则它们共同解释的年龄变异比例是否高于预期值。该分析旨在揭示这些生物钟是否追踪了衰老过程中的互补维度------即当两组生物钟的重叠程度低于独立采样时预期值的情况(该量表上的数值为负值)。值得注意的是,除MS脂肪酸脂质组学与MetaboAge这对生物钟外,所有其他组合均存在显著的超额重叠(图4)。其余所有组合的超额重叠值均大于0.16(以MetaboAge与 DEXA 生物钟为例),表明这些生物钟在成对分析时更多反映的是年龄的共同特征而非互补特征。不出所料,重叠度最高的当属我们在orcades数据库训练的 UPLC IgG糖组学生物钟与GlycanAge生物钟(超额重叠值为1;需注意:按本量表定义,生物钟与自身重叠值为1.00,而 ISLSP 则显示为0.00),这表明二者能够准确捕捉年龄变化的关键特征。
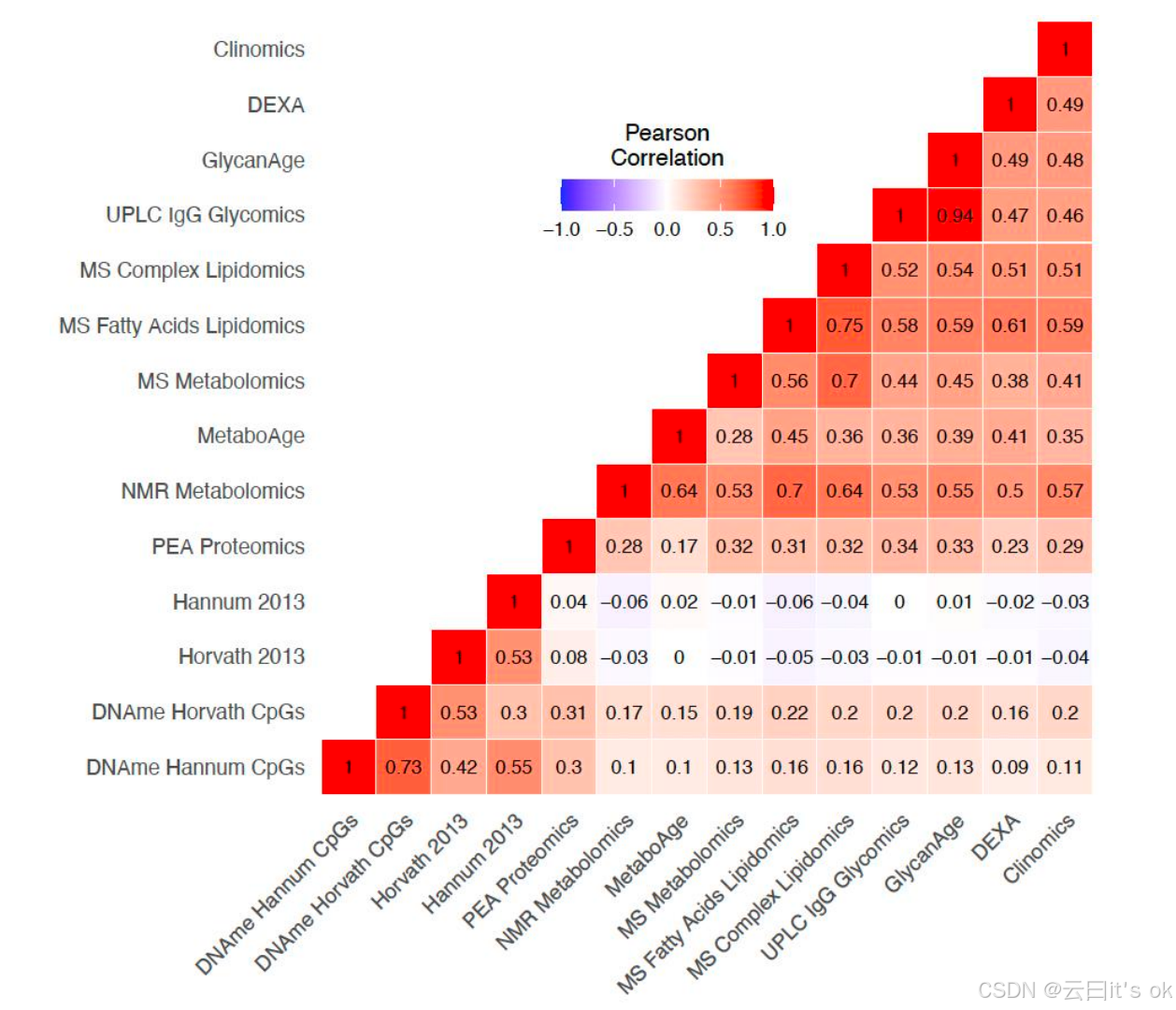
图3. 不同组学年龄加速指标之间的可变正相关关系。orcades测试样本与训练样本中OCAA(组学时钟年龄--实际年龄)的皮尔逊相关系数。颜色表示相关方向,色阶与数值表示相关强度。行列顺序基于成对相关性的层次聚类结果确定。
这些基于糖组学的生物钟在年龄预测方差上呈现完全重叠。它们与PEA蛋白质组学生物钟显示出高度超额重叠(分别为0.95和0.96)。质谱脂肪酸脂质组学、质谱复杂脂质组学及质谱代谢组学生物钟之间也存在显著超额重叠(0.97--0.98)。值得注意的是,同样包含多种脂质特征的核磁共振代谢组学生物钟并未与这三种生物钟形成聚类。基于DNA甲基化的四种生物钟则紧密聚集在一起,其中DNA甲基化汉纳姆CpG位点与DNA甲基化霍瓦特CpG位点的超额重叠度达0.91。由于这些生物钟是极其精准的年龄预测指标,其解释方差的大量重叠不可避免------它们共同追踪着衰老过程中的共性特征。有趣的是,MetaboAge生物钟独立成簇,且与DNA甲基化及PEA蛋白质组学生物钟的超额重叠度均高于基于代谢物或脂质指标的生物钟。
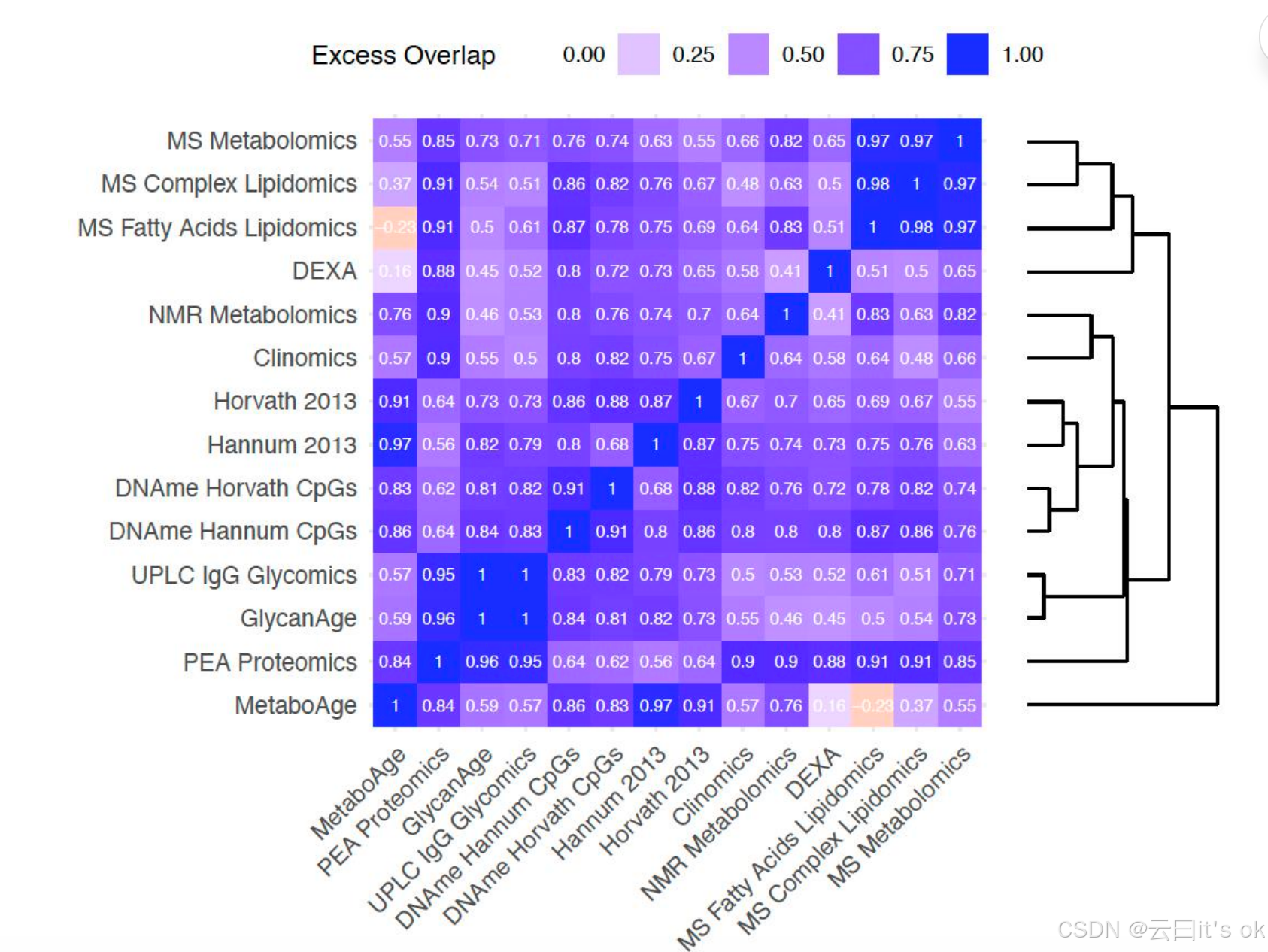
图4。双变量分析表明,在所解释的chronAge方差中,时钟对之间的重叠程度往往超出随机预期。图中为每对时钟标注了随机情况下预期的额外重叠量------该数值表示:当假设两个时钟均为来自一组潜在完整预测变量的独立样本时,包含一对OCAs的双变量模型对chronAge方差的解释能力与该时钟对在已知其各自解释力的情况下所能解释的方差之间的偏差。这一观测值与期望值的偏差指标经过标准化处理(详见方法部分):值为1表示第二个时钟提供的信息并未超过第一个时钟,意味着两者在描述chronAge方面完全重合;值为0则表明观测到的chronAge方差解释量与两个时钟独立采样时的预期值完全一致;负值则表明所追踪的chronAge成分存在显著互补性偏差。
与chronAge相比,OCAAs作为疾病风险预测因子的表现
接下来,我们旨在比较OCAAs与chronAge对风险因素及评估后疾病发生率(以orcades队列中的住院率为衡量指标)的影响------该结局指标被预先认为与年龄相关。针对风险因素,我们选取了体重指数(BMI)、收缩压(SBP)、皮质醇、肌酐、C反应蛋白(CRP)、第一秒用力呼气容积(FEV1)以及总胆固醇;针对疾病,则选择了《国际疾病分类第十版》(ICD -10)中的第二章(肿瘤------编码C)、第四章(内分泌、营养及代谢性疾病------编码E)、第九章(循环系统疾病------编码I)和第十章(呼吸系统疾病------编码J)。所使用的 ICD -10疾病模块及其编码名称详见补充表4。为比较 OCAA 与chronAge的影响,我们首先量化了chronAge对风险因素及疾病的效应(见补充图7A、7B)。所有7项风险因素及44个疾病模块中的32个均被纳入分析,因其与chronAge显著相关(β>0,FDR<10%)且各疾病模块均存在超过5例新发病例。chronAge对(标准化)风险因素的影响因个体特征而异;而对于疾病,则其影响(在风险比尺度上)在不同疾病间基本一致,风险每14年均翻倍。我们以chronAge和性别作为协变量,检验了风险因素与疾病的关联性。随后,通过将观察到的 OCAA 效应除以前一步骤确定的chronAge对结局指标的影响值,将结果按每岁chronAge效应进行标准化处理。这一处理针对各风险因素分别进行,并对所有疾病组及章节采用统一效应值:-0.0492 logeHR。尽管检测 OCAA 与疾病关联的统计效能有限,但480次检验中有6次具有统计学显著性(FDR<10%),90个 OCAA -风险因素关联中也有19个达到显著水平。我们还发现 OCAA 对两种风险因素(81.1%)和疾病(73%)的正向效应均存在富集现象,其中分别有43.3%和22.3%达到名义显著性(单侧p<0.05)。在不同生物钟模型中, OCAA 每增加一年对风险因素/疾病的逆方差加权平均效应值均与chronAge每增加0.09年/0.25年相当(标准误约0.01/0.02;注:此处及其他文献中的"~"表示近似值,详见方法部分)。值得注意的是,DNAme Hannum/Horvath CpG位点 OCAA 每增加一年对所有疾病的平均效应值与chronAge每增加一年相近(比值:1.03/0.85,标准误约0.18),但其对风险因素的影响显著较低(比值:0.06/0.17,标准误约0.09)。完整结果见补充表5,逆方差加权效应见补充图8A。总体而言,仅与Clinomics OCAA 相关的关联符合错误发现率(FDR)标准;而DNAme Hannum CpGs OCAA 、我们基于orcades数据训练的 UPLC IgG糖组学 OCAA 以及GlycanAge则与12个ICD10疾病模块存在名义上的关联(比Clinomics和DNAme Horvath CpGs OCAA 多一个,见图5)。相比之下,PEA蛋白质组学时钟(与chronAge的相关系数r=0.93)仅显示一个具有名义显著性的疾病- OCAA 关联。按疾病类别划分,E70-E90代谢性疾病组和J09-J18流感及肺炎组在所有OCAA中显示出最多的名义关联;而值得注意的是,C34-C44黑色素瘤组和C51-59女性生殖器官恶性肿瘤组则未呈现显著关联。
该疾病可反映更广泛的衰老趋势(补充图8B)。我们旨在验证观察到的 OCAA 与健康之间的关联是否源于健康状况与吸烟、以及 OCAA 与吸烟之间的关联。将吸烟状态作为混杂因素纳入分析后,结果表明这些关联并不存在(补充图9A、9B)。
不同OCAA模型对风险因素及疾病的预测能力比较
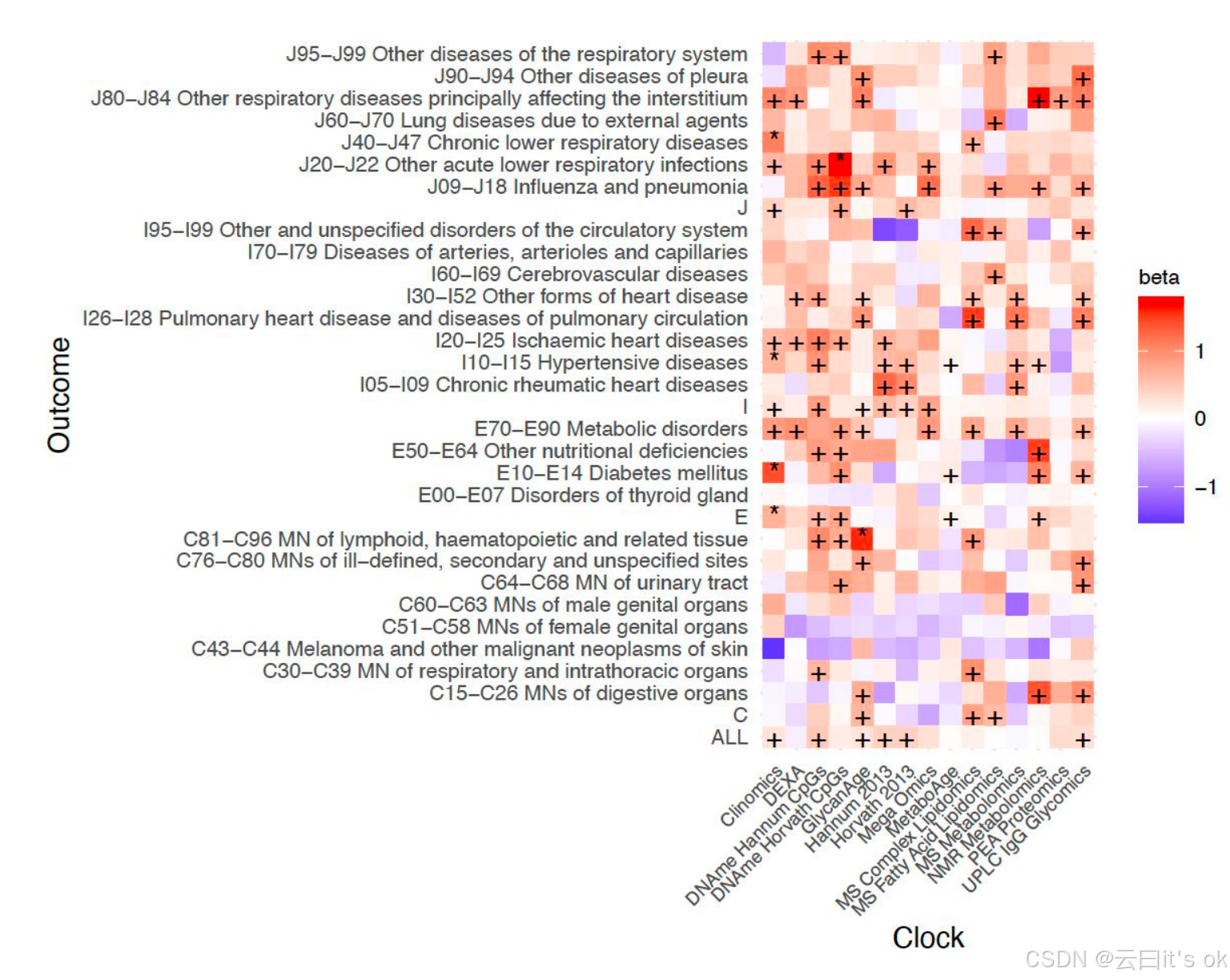
图5. 观察到年龄增长与疾病风险增加呈正相关关系;同时与住院率存在关联。+/* 标号表示在频率学检验中 OCAA 对结局具有正向影响且名义显著性/FDR<10%。β值:一年 OCAA 干预相对于一年chronAge干预对疾病的影响强度(初始以对数风险比表示,效应值经除法运算后无量纲)。数值为1时表示一年 OCAA 干预与一年chronAge干预具有同等危害性,该数值以鲑鱼色标示。为便于阅读,请注意:DNAme Horvath CpGs-BMI的β值为1.02,DNAme Hannum CpGs-C81-C96I的β值为1.00。Clock:用于测量 OCAA 干预效果的组学时钟。疾病组:根据ICD-10编码定义的疾病集合,在评估时首先检测其首次发病情况,并排除已患病病例(各疾病组病例数见补充表5)。
原则上,两种OCAA指标对疾病的影响程度可能相同,但如果其中某项指标的取值范围变异更大,则其对整体人群的预后预测价值可能远高于另一项。为明确哪些OCAA指标能更准确地区分个体间的健康差异,我们使用标准化OCAA指标重复了先前分析。风险因素的标准化OCAA指标取值范围较窄;标准化NMR代谢组学 OCAA 指标的预测能力最强,所有风险因素的 IVW 平均效应值为0.09(标准误约0.01);其他生物钟指标的效应值介于0.07至0.03之间,而Hannum 2013、Horvath 2013、MetaboAge及MS脂肪酸脂质组学OCAA指标的效应值更低,范围仅为-0.01至0.01(所有案例的标准误均约0.01)。相反, CRP 和总胆固醇则通过标准化 OCAA 模型预测的可预测性最高(分别为0.08和0.06,标准误约0.01,基于多个生物钟数据的 IVW 平均值);而收缩压的可预测性最低(0.02,标准误约0.01)。标准化 OCAA 对不同疾病的影响呈现不一致的模式(补充图8B):除PEA蛋白质组学研究和Horvath 2013研究分别得出0.017和0.026的结果外(标准误约0.04和0.03),其他疾病的IVW平均效应值均介于0.09(Hannum 2013)至0.24之间。尽管统计效力有限,但对跨生物钟标准化 OCAA 最敏感的疾病组为J80-J84(主要累及间质的其他呼吸系统疾病;效应量0.56,标准误约0.13)。我们关注OCA疾病关联效应在性别间是否一致。为解决样本量问题,我们将分析限定于汇总分析中具有名义显著性的 OCAA -疾病区块关联(p<0.05)。在汇总分析的107个名义显著关联中,有78个满足评估标准(与chronAge显著相关、β>0、FDR<10%且病例数>5例),可分别按性别进行单独分析(补充表6)。在这78个 OCAA -疾病关联中,92.3%的效应符号在不同性别间保持一致;对于符号不一致的6个案例,我们采用双侧t检验检验标准化效应量是否存在统计学显著差异,实质上验证该差异是否可能由偶然因素导致。所有结果在名义水平上均未显示显著差异(p<0.05)。
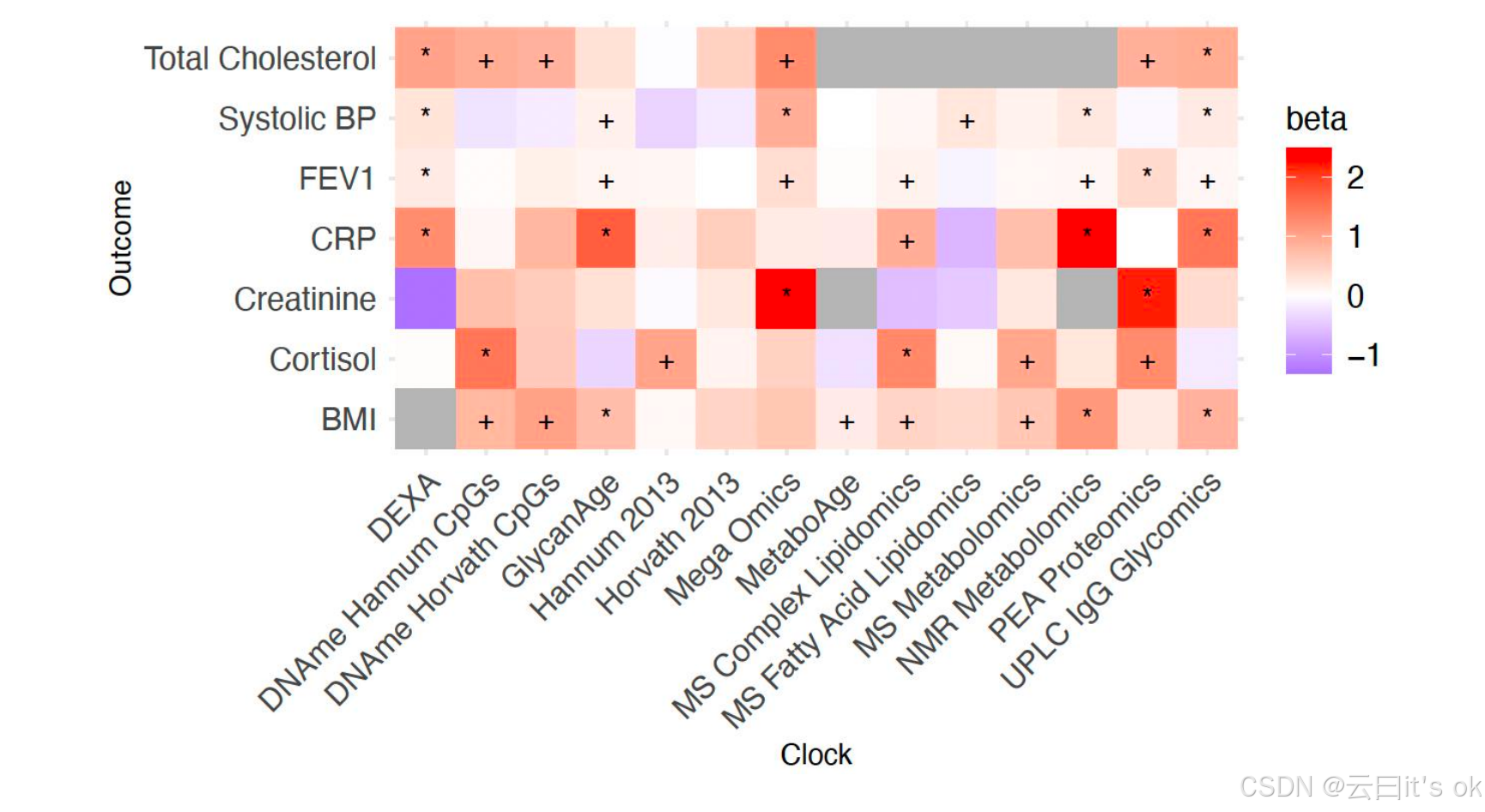
图6.观察到年龄增长与疾病风险增加之间存在正向加速关联。该关联与疾病风险因素相关。+/*符号表示在频率学检验中 OCAA 对风险因素具有正向影响且名义显著性/FDR<10%。β值:一年 OCAA 治疗相对于一年慢性年龄对风险因素的相对影响(效应量除以1后无量纲)。数值为1表明一年 OCAA 治疗与一年慢性年龄具有同等危害性,该数值以鲑鱼色标示。
基于少数组学主成分构建的时钟模型可有效预测健康结局
最后,我们降低了数据维度,并评估了不同组学指标在检测层面所捕捉到的关于衰老的潜在信息,而非仅限于模型中选取的预测因子。我们利用组学测量数据中的若干主成分(PCs)作为预测变量,在ORCades数据库中构建了自定义生物钟模型,并使用这些标准化的OCAAs重复了前述分析:计算chronAge值(补充图10),并预测健康结局(补充图11A、11B)。结果令人瞩目:针对所有风险因素,三个PC OCAAs组合产生的 IVW 均值效应量均超过两倍。
我们的标准OCAA模型(补充图11A)。对于所有基于DNAme数据的OCAA模型(包括包含更多组学主成分的时钟模型),其预测风险因素差异的能力均有所下降。除PEA蛋白质组学 OCAA 外,基于3个主成分的时钟模型与标准OCAA模型对疾病的影响 IVW 均值基本相当;而基于3个主成分的时钟模型在该模型中的预测性能比标准时钟模型高出10倍。总体而言,基于少量组学主成分构建的OCAA模型在预测疾病方面与标准模型预测能力相当,在预测健康风险因素方面则更具优势。
讨论
我们迄今开展了针对不同组学检测方法作为年龄潜在生物标志物最全面的比较研究。首先,我们证明利用多种组学生物标志物构建衰老时钟能够实现对chronAge的高度精准估算;其次,基于PEA蛋白质组学、DNA甲基化、 UPLC IgG糖组学以及orcades临床风险因素构建的自研衰老时钟,在独立人群中均能准确估算chronAge;第三,使用各检测方法提供的核心生物标志物子集同样可实现同等精度的chronAge估算。尽管各OCAA指标间仅呈现较弱正相关,但我们发现这些时钟模型在解释chronAge变异方面存在显著重叠------这种重叠程度远超其独立采样于完整预测变量集合时的随机预期。研究显示OCAA与总胆固醇、C反应蛋白、体重指数(BMI)、肌酐、皮质醇、第一秒用力呼气容积(FEV1)及收缩压均存在关联;共发现6项统计学显著(错误发现率FDR<10%)的独立关联,并有充分证据表明 OCAA 与各类疾病发病风险存在显著富集关联(其中22.3%达到名义显著性p<0.05)。值得注意的是, OCAA 在不同风险因素间的预测能力变异度低于其在不同疾病间的变异度差异。总体而言,我们估算出一年的 OCAA 数据对风险因素/疾病发病率的影响相当于0.09至0.25个chronAge年,并证明基于组学分析中若干主成分构建的生物钟所生成的 OCAA 模型,在预测能力上与整合所有可用特征的模型相当。我们的PEA蛋白质组学、DNA甲基化、 UPLC IgG糖组学、OCA指标及chronAge之间的相关系数与已发表模型报告的结果5,6,17,18一致。在orcades软件内部对比自建模型与已发表模型时发现:IgG糖组学和DNA甲基化检测结果与chronAge的相关性均保持稳定;但我们的NMR代谢组学OCA模型与chronAge的相关系数(r=0.74)显著高于MetaboAge模型(r=0.21)。不出所料,基于DNA甲基化的orcades生物钟能在苏格兰(Generation Scotland)和爱沙尼亚生物样本库(EBB)中准确估算年龄------因为Hannum 2013和Horvath 2013表观遗传生物钟已在多个群体中成功应用。我们首次证实:基于Olink PEA蛋白质组学构建的生物钟在EBB和Croatia-Vis样本中具有良好的可重复性;而使用SOMAlogic20蛋白质组学平台构建的生物钟此前已被证明在不同人群中具有可重复性。我们的 UPLC IgG糖组学生物钟在独立人群中同样表现出良好可重复性,印证了已发表GlycanAge评估方法的有效性17。相比之下,我们的NMR代谢组学和 DEXA 生物钟在EBB和 UKB 样本中与chronAge的相关性显著降低。这些衰老时钟模型的成功似乎具有研究特异性:奥克尼群岛人群与英国及爱沙尼亚普通人群在生活方式和环境因素方面存在随年龄变化的差异,这可能是其成功的原因。值得注意的是,虽然MetaboAge模型已在两个群体中得到验证(OCAA 与chronAge之间均呈现稳定相关性,r=0.65和r=0.70)9,16,但在奥克尼群岛人群中相关性显著降低(r=0.21)。这些发现警示了此类衰老时钟模型向新人群推广时的普适性问题。
要使生物年龄(BA)评估方法具备临床实用性和高效性,理想情况下应基于尽可能少的预测因子进行精准年龄估算。我们大幅减少了各检测项目中纳入生物标志物的数量,并证实所有自建生物钟模型均未出现性能下降。Enroth等人18曾证明基于蛋白质的生物钟模型同样可实现此目标,但我们通过更大比例减少蛋白质数量仍能保持与之相当的chronAge估算精度。这种仅使用少量预测因子即可实现如此高精度的结果,在九种不同类型的生物标志物中尚属首次系统性验证。研究报道的OCA与chronAge之间极高的相关性(如Mega-omics OCA模型中的r=0.97)凸显了先前研究中讨论的一个关键问题:若模型包含足够多的生物标志物,则可能实现chronAge的完美估算,从而无法有效识别(差异化的)生物学年龄。Lehallier等人20表明,OCA与chronAge的相关性随模型中蛋白质数量的增加而增强;此外,在大规模样本中利用DNA甲基化数据可解释chronAge变异的100%31。完美的年龄预测模型无法反映同龄个体间的年龄差异,即便是近乎完美的模型,其 OCAA 变异度也过低,难以反映chronAge之外的健康状况或临床结局32。我们的研究结果也印证了这一趋势。
评估年龄(chronAge)最准确的方法------宏组学和PEA蛋白质组学中的OCAAs指标与后续住院率无显著关联,基于DNA甲基化的OCAAs指标与风险因素亦无显著关联。当然,极高精度的年龄评估方法确实具有特定用途(例如在法医学领域33),但在生物年龄(BA)评估方面并无实际价值。这并非意味着这些检测方法无法用于估算生物年龄,而是凸显了基于年龄数据训练生物钟模型存在的局限性。理想的生物年龄指标应能反映超越年龄层面的健康状况或临床结局。研究发现,基于DNA甲基化的OCAAs在预测疾病发生方面优于风险因素,这与Horvath 2013表观遗传时钟的已知性能一致;多项研究均表明Horvath 2013 OCAA 值与后续全因死亡率相关7,34--37,且在多种疾病表型中均观察到病例组与对照组间Horvath 2013 OCAA 值存在差异34,38--47。相比之下,Horvath 2013 OCAA 值与低密度脂蛋白胆固醇、 CRP 等常见风险因素无显著关联28,这一结论我们也得到了验证。研究显示,PEA蛋白质组学和宏组学OCAAs在预测风险因素方面优于预测疾病风险,而基于DNA甲基化和IgG糖组学的OCAAs则呈现相反趋势。相比之下,基于DNA甲基化和IgG糖组学的OCAAs指标不仅能预测与年龄相关的疾病发生风险,还表明它们更有可能反映潜在的生物标志物关联。Clinomics OCAA 研究显示出与疾病关联性的最强证据也就不足为奇了------该研究采用了公认的、具有疾病预后意义的临床指标。这一结果无疑为相关概念提供了令人安心的验证依据。 OCAA 与疾病及危险因素关联的整体显著富集现象,进一步支持了通过组学标记物追踪生物标志物关联的观点。Jansen等人9的研究表明,代谢综合征和心脏代谢性疾病患者的MetaboAge值显著高于对照组,但并未对疾病发生具有预测价值;而van den Akker等人的研究则发现MetaboAge与全因死亡率、冠心病及心血管事件风险升高存在关联16。尽管统计效力有限,我们的结果仍与后一项研究结论一致:我们发现Orcades数据库中的MetaboAge OCAA 与新发糖尿病(E10-E14)、高血压疾病(I10-I15)以及ICD-10第E组编码存在名义上的关联(p<0.05)(图5)。同样,我们自主研发的NMR代谢组学 OCAA 也与多个代谢疾病类别存在名义上的关联(p<0.05),这表明在样本量更大的情况下该关联将具有显著性。此前已有研究表明,GlycanAge与风险因素相关17;而IgG聚糖(即并非 OCAA 本身,而是聚糖水平本身)是预测2型糖尿病发病及心血管事件的有效指标48--50。然而,我们首次证实基于IgG聚糖的生物钟模型(GlycanAge及我们自主研发的 UPLC IgG糖组学 OCAA)能够有效预测疾病发生,并强调这一效果并非仅源于对所考虑风险因素的追踪。
MetaboAge在多项分析中均表现突出:其与chronAge的相关性较低、对chronAge解释的独立方差较小,且在与其他所有生物钟模型进行两两比较时,两者解释的方差重叠度也较低,这些均表明MetaboAge可能未能准确反映chronAge的变化。结合尽管统计效力有限但MetaboAge OCAA 与心血管代谢疾病发病率仍存在名义上的关联这一事实,进一步支持了以下观点:组学衰老生物钟应更加聚焦于具体疾病结局,并避免基于chronAge进行训练。根据定义,BA值为+1意味着个体的功能能力及罹患年龄相关性疾病的风险与比其年长一岁的平均个体相同,这表明真实BA的影响等同于1年的chronAge。我们估算出 OCAA 每增加1年对疾病发病率的平均影响相当于0.25年的chronAge,这一结果具有重要意义。因此,BA似乎是真实可测的指标,其效应强度与chronAge相当;不过相较于chronAge,我们的估计值显著偏低,这可能源于 OCAA 仅能反映BA的某些方面(取决于检测方法和组织类型),而非BA本身。开发更精准的BA评估方法以及能够逆转已明确BA变化的干预措施均值得深入研究。黑色素瘤与其他皮肤恶性肿瘤(C43-C44)以及多种衰老时钟指标之间的负相关关系,使我们推测久坐行为减少不仅会导致 OCAA 值降低,还会增加日晒暴露时间。若这一结论得到验证,将表明皮肤生物标志物与其他生物标志物的关联未必紧密;我们推测这一发现也可能适用于其他器官。本研究的优势在于采用了数量庞大、种类丰富的检测方法及组学衰老时钟,并在同一受试者中对这些时钟的表现进行了比较,而以往的研究仅限于基于DNA甲基化的时钟23,24,51或结合DNA甲基化、临床风险因素及衰弱指标的时钟25。我们还直接将基于orcades队列数据构建的自研组学衰老时钟与已发表的时钟模型进行了对比,并尝试在可获得的独立人群中验证该模型以证明其更广泛的适用性。先前研究的一个局限性在于其年龄范围较为狭窄。
在训练样本中,例如Lee等人基于妊娠队列数据训练的表观遗传时钟模型对45岁以下个体的chronAge预测极为准确,但对年长个体的年龄估计偏低52。我们的时钟模型因纳入了Orcades队列中涵盖广泛年龄范围(16--100岁)的个体而避免了这一局限。本研究创新性地评估了不同时钟模型之间的重叠程度,这是其一大优势------此前尚未有证据表明,在多种不同的组学检测中,这些时钟模型的重叠度会超过随机 ISLSP 情况下的预期值,这表明它们追踪的是衰老过程中更普遍而非互补的特征。另一大优势在于效应量的标准化处理:我们按每单位chronAge年数测量了 OCAA 效应值,从而建立了直观易懂的量化尺度。此外,该研究覆盖范围广泛,针对多种与年龄相关的疾病进行了验证。当然,这也构成一个局限性,因为在多重检验校正后会降低统计效力。不过,对各类疾病群体及其对应时钟模型采取基本中立的态度,有效降低了发表偏倚的风险。本研究的一个局限性在于样本量相对较小,这既体现在接受多项组学检测的个体数量上,也体现在随访期间新发住院病例的数量上。由于样本中死亡病例较少,我们目前尚无法像以往研究那样检验 OCAA 指标与死亡率之间的关联。样本量不足加之多重检验效应的影响,限制了我们评估 OCAA 指标对后续疾病发生影响的能力(相较于以往研究7,25中常见的风险因素),但这一问题应在更大样本中进一步探讨。不过,我们确实考察了OCAA指标对不同性别人群疾病发生率的影响是否存在差异。为提高统计效力并控制多重检验风险,我们将分析范围限定于汇总分析中名义上(p<0.05)显著且符合相同标准(β值>0、FDR≤10%、与chronAge存在单侧关联且病例数>5例)的关联关系。结果未发现显著的性别差异证据。鉴于本研究旨在阐明基于多种组学检测数据构建的chronAge老化时钟的特性,以深入理解这些指标实际反映的生物学机制(该领域研究尚不充分),因此我们未将所得时钟模型与基于死亡率指标训练的时钟模型2,22进行比较。虽然可以开展一项系统比较chronAge与基于死亡率的年龄估算方法效用的研究,但这并非我们的研究目的。由于orcades项目可获得的组学数据属于横断面数据,我们无法评估个体 OCAA 随时间的变化情况。不过,我们成功探究了单个时间点的OCAAs指标在为期10年的随访期内对住院率的预测能力。尽管未明确检验OCAAs与Zenin等人53定义的健康寿命之间的关联,但通过将ALL(在所考虑疾病类别中首次确诊)纳入分析,我们评估了等效的重大疾病风险指标。主要区别在于:我们未纳入痴呆症(因其发病率极低),也未包含死亡数据(如前所述),需注意Zenin等人曾将死亡视为界定健康寿命的关键指标。
我们研究样本属于群体隔离样本,这意味着局部因素可能影响我们的研究结果。我们已证明这一情况并不适用于部分组学时钟的准确性(补充图2),因为这些结果在其他人群中均得到了成功复现;然而,这可能是导致 DEXA 和NMR代谢组学时钟复现性较差的原因之一。使用住院率作为发病率衡量指标存在局限性,对于通常在社区治疗的疾病(如2型糖尿病和流感)而言尤为明显。尽管如此,我们很可能已经涵盖了最严重的病例,并验证了这种严重程度是否与 OCAA 及推测的衰弱状态相关------后者可能导致患者对疾病的体验更为严峻。其次,检测方法与疾病结局之间存在关联性,导致我们的检验结果缺乏独立性(尽管这使得错误发现率校正更为保守)。一项统计效力更高的研究可尝试区分各个生物标志物(尤其是我们核心组学时钟中保留的那些),并评估其作为因果通路组成部分的生物学合理性。当然,相关性并不等同于因果关系。虽然前瞻性队列研究降低了反向因果关系的风险,但基线时未确诊的病例仍可能影响我们观察到的结果;不过更可能的情况是存在一组潜在的内在特征共同影响疾病易感性及生物标志物的表现。尽管如此,即便不存在因果关系, OCAA 似乎仍常可作为疾病及潜在生物钟异常(BA)的生物标志物。综上所述,我们的研究进一步有力证实了BA与chronAge存在本质区别,同时指出 OCAA 中相当一部分数据属于噪声。数据还表明可能存在多种类型的BA------这些类型由不同的生物钟机制决定,并导致不同程度的疾病易感性差异。
我们的证据最有力地表明,皮肤年龄与心脏年龄可能呈现相反的变化趋势。我们还强调,某些基于组学分析的方法(如PEA蛋白质组学)能够捕捉特定风险因素并因此与健康状况相关联,而其他方法(如基于DNA甲基化和IgG糖组学的方法)则能反映更普遍的衰老特征。我们观察到,仅基于少数组学主成分构建的生物钟在估算实际年龄(chronAge)时准确性较低,但更能有效预测风险因素;这表明寻找生物钟应聚焦于生物学中的显著特征。这一结论支持了近期基于全因死亡率指标2,22、DNA甲基化PhenoAge2及GrimAge22构建的衰老生物钟所取得的成功------这些模型比直接基于实际年龄训练的DNA甲基化生物钟更能准确预测健康状况和死亡结局24--26,54。类似地,Deelen等人开发的基于死亡率训练的核磁共振代谢组学指标,在预测5年及10年全因死亡率方面均优于传统死亡风险因素模型55。因此,我们建议未来研究的重点应继续转向基于死亡率或更理想地基于全因发病率构建的生物钟模型,这类模型能更好地预测后续健康结局,而非单纯作为精确的实际年龄估算工具。
材料和方法
队列数据
分析主要基于奥克尼复合疾病研究(orcades)29开展,该研究是一项基于人群的独立队列研究,其特征已通过传统表型、组学检测以及基于关联电子健康记录(EHR)长达12年的平均随访数据得到全面阐明。此外,还利用克罗地亚-维斯队列和克罗地亚-科尔丘拉队列56,57验证了在orcades数据集中训练的组学衰老时钟模型:克罗地亚-维斯队列用于验证基于orcades数据集、使用蛋白质子集(即Olink CVDII 、 CVDIII 和INF1检测板所测蛋白质,称为蛋白质子集1)及 UPLC IgG糖组学时钟训练的模型;克罗地亚-科尔丘拉队列则用于复现基于orcades数据集训练的NMR代谢组学时钟和 UPLC IgG糖组学时钟;爱沙尼亚生物样本库58(EBB)队列用于验证基于蛋白质子集(即Olink CVII 、 CVDIII 、INF1和 ONCII 检测板所测蛋白质,称为蛋白质子集2)及NMR代谢组学时钟训练的模型;同时采用EBB队列与苏格兰家庭健康研究(GS: SFHS)59(一个涵盖苏格兰各地志愿者的家庭队列)评估两种基于DNA甲基化的衰老时钟模型;最后利用英国生物样本库60(UKB)验证在orcades数据集中训练的Clinomics和 DEXA 时钟模型。
组学分析
双能X线吸收测定法(DEXA)
全身成像检查采用Hologic扇形束 DEXA 扫描仪(GE Healthcare)完成。身体成分参数通过 DEXA 扫描数据,分别使用APEX2软件计算骨骼、瘦组织和脂肪含量,并使用APEX4软件测定安卓型脂肪、女性型脂肪、内脏脂肪及瘦体脂肪质量占比。研究选取了涵盖以下主要类别的28项指标进行分析:骨密度、骨矿物质含量、头部、躯干及四肢的脂肪/瘦体重百分比。这些指标在计算时均未使用chronAge数据,且均可从英国生物样本库中获取。所有测量值均以z值截断值为6剔除异常值后进行性别预校正;剩余数据进一步通过设定z值截断值为3来剔除异常值并进行阈值处理。
DNA甲基化
本研究采用Illumina EPIC 850K芯片测定orcades样本的DNA甲基化水平。质量控制工作通过meffilQC流程61和minfi软件包62完成:若超过1%的探针检测p值>0.01、存在性别一致性问题、出现染料偏倚现象或中位甲基化信号z值未达到3分界值,则这些样本被判定为异常值予以剔除;若超过1%样本的检测p值>0.01或至少5%样本的探针计数<3,则该探针亦被视为异常值。使用"minfi"软件包中的preprocessNoob函数对芯片数据进行标准化处理,以消除不必要的技术变异。M值通过 GCTA - REML 方法63针对以下技术协变量进行校正:板编号(作为随机效应)、采血季节、采血年份、板位置以及对照探针的10个主成分(作为固定效应)。鉴于已有文献中存在成熟的DNA甲基化时钟模型,本研究未自行构建新模型,而是基于Hannum和Horvath提出的原始表观遗传时钟模型进行构建,并与我们的其他组学数据进行对比。由于orcades实验采用Illumina EPIC 850K芯片而非Hannum和Horvath使用的早期450K/27K芯片,我们的甲基化时钟模型属于其模型的子集。已有研究表明,对850K芯片缺失但450K/27K芯片中存在的探针进行填补会低估已发表的所有衰老指标64。因此,对于我们的Hannum CpGs和Horvath CpGs基因座数据集,我们分别向惩罚回归算法提供了71个位点中的62个以及353个位点中的333个(均存在于850k芯片上),用于模型选择。随后,将z值阈值为6内的 REML 残差进行了性别校正。
核磁共振代谢组学
采用高通量核磁共振代谢组学检测法(EDTA血浆样本,生产商:Nightingale Health Ltd.,芬兰赫尔辛基)对225项代谢指标进行了摩尔浓度单位的定量分析。这些指标包括氨基酸、酮体、低分子量代谢物以及多种脂质和脂蛋白亚类。在orcades地区及克罗地亚科尔丘拉地区,所有代谢指标均根据z值截断值为6(并已针对性别因素及他汀类药物使用情况进行二元变量校正)被剔除作为异常值;此外,残差数据亦按z值截断值为3被进一步剔除作为异常值。
MS脂肪酸脂质组学
采用散弹枪脂质组学与液相色谱串联质谱法(LC-MS/MS)对44种脂肪酸的摩尔浓度进行定量分析,方法如先前文献65所述。基于z值截断值为6的标准,将脂肪酸测量值中的异常值剔除,并对性别、板孔编号、培养板位置及他汀类药物使用情况进行了预校正。
组学指标的质量控制
异常值的判定基于z分数阈值,该阈值因组学数据集的不同而异,具体取决于原始测量值的分布特征。所有组学测量值均采用固定效应线性回归或其他指定方法对已知批次效应及协变量(如上所述)进行预校正。随后对残差施加第二次z分数阈值分析,以进一步识别异常值。剔除了部分检测项目及所有缺失值。随后对协变量校正产生的残差进行标准化和中心化处理,使其均值为零、标准差为一,以确保模型中各变量的效应量具有可比性。
时钟构建
每一种组学检测平台
奥卡德斯队列中的个体被分为75%用于训练集、25%用于测试集。为比较不同组学平台上的时钟性能表现,测试集中的25%样本优先选取自所有组学平台数据均完整的个体群体。在训练集中采用十折交叉验证法确定惩罚回归模型的收缩参数 λ 值,该参数通过估计可获得均方误差最小的模型。研究使用R语言中的glmnet69和caret包,以静脉穿刺时的chronAge作为因变量,采用三种不同方法构建模型:i) 最小绝对收缩与选择算子(Lasso)回归;ii) α值为0.5的弹性网络回归;iii) 在训练集中进行十折交叉验证并采用α选择参数的弹性网络回归。三种方法的性能无显著差异,因此后续分析均采用α值为0.5的弹性网络回归模型。该模型随后被用于估算测试样本及(若可用)队列外独立样本的chronAge值。由于该流程存在随机性,所选纳入模型的变量会因训练样本中选取的具体个体而异;时钟构建过程重复进行了500次,并记录了最终选定的特征以及模型估算出的chronAge与年龄之间的相关性,以确保本文呈现的模型性能结果具有代表性,而非因训练样本中包含分布极端值个体或使用罕见模型得出结论而导致的异常结果(数据未显示)。
宏组学
该模型整合了所有组学平台提供的全部特征。数据集本身是通过合并经平台级质量控制后校正的所有组学测量值(残差)并再次将所有特征标准化至均值为零、标准差为一而构建的。时间轴的构建采用了上述相同的流程
核心模型
这些模型均根据组学检测方案构建。弹性网络回归算法仅采用那些在相关组学平台的500次时钟构建迭代中被选入模型的比例超过95%的预测因子。随后,该精简预测因子集按上述方法进行时钟构建。
主成分时钟
为确保chronAge中不同组学时钟所解释的方差差异并非源于各组学类型中可用特征数量及最终选定纳入模型的特征数量之间的差异,而是不同组学方法所捕获的衰老信息存在本质区别,我们采用相关组学平台的主成分(PCs)作为特征构建了时钟模型。具体而言:在R语言中使用prcomp函数从平台层面经过协变量校正、标准化和中心化的组学数据中提取前3、5、10及20个主成分;随后将这些主成分输入弹性网络算法进行时钟构建。
出版时钟
为将基于orcades数据集训练的时钟与现有文献中的时钟进行比较,我们计算了四个已在chronAge数据库中发布的衰老时钟模型:Hannum等人(Hannum 2013)5提出的DNA甲基化时钟、Horvath开发的基于DNA甲基化的全组织时钟(Horvath 2013)6、 UPLC IgG糖组学时钟GlycanAge17以及NMR代谢组学时钟MetaboAge16。Hannum 2013和Horvath 2013的研究中使用的OCAAs值通过在线计算器http://dnamage.genetics.ucla.edu/计算;MetaboAge值则通过metaboage.researchlumc.nl在线计算器得出;GlycanAge值则是通过对GP6、GP62、GP14和GP15基因表达量分别针对不同性别与静脉穿刺时的实际年龄进行回归分析后得到的残差值。
OCAA之间的相关性
我们计算了10种OCAA之间的成对皮尔逊相关系数,其中Mega-omics OCAA 及所有时钟基因组比较数据均被排除在外,因其包含涉及多项检测方法的预测因子。
在 chronAge 中解释的方差划分
每个时钟(sri 2)对chronAge所解释的独立方差,通过计算chronAge(Y)与由时钟i估算的年龄之间的平方部分相关系数来确定,并在控制所有其他k个时钟的影响后得出。部分相关系数采用R语言"ppcor"包中的spcor.test函数进行计算70。由所有k个时钟共同解释的chronAge方差占比,即以下模型得出的R²值:
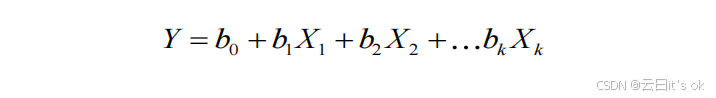
其中 Y 表示 chronAge(时间年龄),X1...k 表示由第 1 至第 k 号时钟估算出的年龄值;该模型用于将 chronAge 的总方差进一步划分为:无法通过这 10 个时钟解释的部分(1 -- R²)以及可由重叠时钟解释的部分。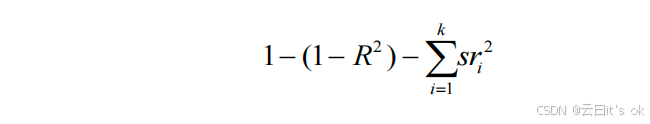
为更深入地探究不同生物钟之间的关系,我们进行了成对比较分析。按照上述相同流程,每对生物钟中任一钟表所解释的chronAge(时间年龄)独特方差,即为chronAge与另一钟表估算年龄之间的平方部分相关系数,并在控制这对钟表中另一钟表估算年龄的影响后计算得出。任一钟表均无法解释的方差则对应双变量模型中的R²值减去1。通过相减法计算得出的重叠部分,特指这对钟表共同解释的chronAge方差。这与前一步骤中计算的重叠部分有所不同------此前我们仅能确认该方差并非特定钟表所独有,但无法进一步分解其构成。
评估时钟之间的重叠情况
我们评估了由两台时钟共同解释的chronAge综合方差,是否偏离了以下预期值:若两台时钟均独立地从chronAge的潜在预测变量集(ISLSP)中采样,则该方差应符合随机预期。通过双变量模型计算两台时钟共同解释的chronAge综合方差(即多重R²),其中chronAge为因变量,两台时钟提供的估计年龄为自变量。每台时钟(i)单独解释chronAge的方差(vi)则对应估计年龄对chronAge回归分析中的单变量R²。两台时钟随机解释的chronAge预期方差(E)计算如下:
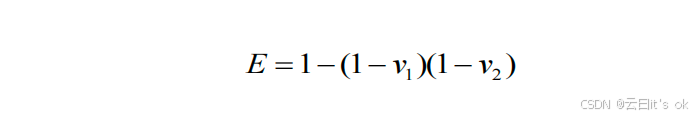
其核心思想是:chronAge中尚未被第一个时钟解释的方差为1 − vi。在零假设下(即两个时钟是从完整的潜在预测变量集合中独立抽取的样本,因此只能部分解释关于年龄的信息),加入第二个时钟后预期未解释的方差为(1 -- v1)(1 -- v2)。为便于比较不同时钟组合下观测到的chronAge所解释方差(O)与理论值(E)之间的偏差,我们对这一偏差进行了重新标度------因为vi的大小直接影响O可能取值的范围。理论上,两个时钟所能解释的最小方差(Emin)仅由较大的那个时钟单独提供(此时第二个时钟仅提供第一个时钟已包含的信息);理论最大值(Emax)则为v1 + v2(若v1 + v2 > 1,则为1,表示两个时钟完全解释了非重叠方差)。包含高vi值时钟的比较中,O的可能取值范围远小于低vi值时钟的情况,因此直接比较观测值与期望值的偏差幅度并非理想方法。本文呈现的结果采用超额重叠度量尺度,计算公式如下:
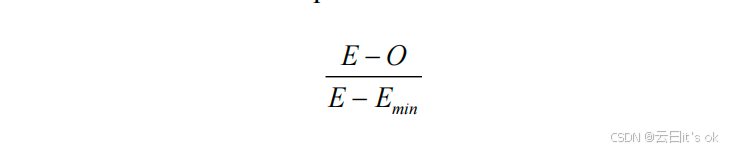
值为0表示观测到的方差解释量等于时钟独立时由随机性产生的预期值;值为1则表明加入第二个时钟并未带来额外的方差解释。负值意味着两个时钟的时间重叠程度低于预期,且分别追踪时间衰老的不同方面。
与健康相关表型及新发疾病之间的关联
研究人员检测了OCAAs与健康相关风险因素及年龄相关性新发疾病(以住院治疗为衡量指标)之间的关联性。
与 chronAge 的关联
我们首先检验了风险因素及疾病结局是否与chronAge(慢性病患病时长)相关。针对新发疾病:采用Cox比例风险模型71以及R语言"survival"包中的Surv函数,对从评估时间至疾病发病或研究结束(即SMR01数据提取日期:2017年12月,约为评估后十年)的时间间隔进行建模。已患有基础疾病的受试者被排除在外。基线风险取决于评估后的时长,而风险比则取决于chronAge和性别。我们选择评估后时间而非chronAge作为基线风险的决定因素,以便明确哪些分组具有更强的年龄相关性效应,并比较 OCAA 与chronAge的影响差异。关于chronAge(及后续 OCAA)关联性的P值均通过单侧检验计算得出,原假设H1为chronAge(或 OCAA)会增加风险。
与OCAA组织的关联
采用标准化风险因素(表型标准差单位),通过线性回归分析,并将chronAge和性别作为固定效应协变量。为减轻多重检验带来的负担,我们仅针对那些与发病时年龄(Benjamini-Hochberg错误发现率<10%)存在统计学显著关联(效应量>0)且具有>5例新发病例(疾病组块)的风险因素或疾病组块,检验了OCAAs的关联性。我们使用与分析年龄相同的模型(包含年龄和 OCAA 作为效应变量),评估了OCAAs对各疾病组的影响。虽然 OCAA 未进行标准化处理,但观测到的效应量均通过除以年龄效应值进行重新缩放(即除以1),从而可比较一年 OCAA 变化与一年年龄变化的效应差异(数值为1时表示相同效应)。错误发现率仍采用Benjamini-Hochberg方法计算(FDR<10%)。在风险因素和疾病分析中,我们均发现较大的估计效应值往往伴随较大的标准误出现。为便于可视化呈现结果,我们对最可靠的估计值应用了收缩方法:对观测到的β值似然函数施加先验分布假设(均值0,标准差1),使标准误较大的估计值向0方向收缩。由于多重检验及 OCAA 变异度较低(相较于年龄),单个关联检验的统计效能普遍有限。因此,我们采用逆方差加权法(IVW)对各结局指标的 OCAA 结果进行了综合分析。结果变量与预测变量之间的协方差关系表明,元分析(或符号检验)所需的独立性假设并未满足。虽然这不会导致估计值产生偏倚,但其精确度会被高估。我们认为这些结果仅具有描述性意义,并不符合正式统计检验的要求。我们使用"~"符号表示在违反独立性假设条件下计算的标准误(SE),但仍认为其有助于反映效应量的大小;反之,出于相同原因,我们进行的正式检验(错误发现率FDR)结果可能较为保守。我们采用标准化OCAA方法重复了这些分析,以比较不同OCAA模型在人群层面、不同风险因素及疾病类型中的预后预测能力,并与我们的PC时钟OCAA模型进行对比。
数据的可用性
本研究未获得任何研究伦理委员会的批准,也未取得个体参与者的知情同意,因此无法公开发布支撑本研究的个体层面研究数据。如需更多信息,请联系 QTL 数据访问委员会(accessQTL@ed.ac.uk)。获取GS: SFHS 数据库的数据需提交申请(access@generationscotland.org),且采用统一管理流程;而爱沙尼亚生物样本库的数据则需申请获取,并由爱沙尼亚生物伦理与人类研究委员会负责管理。