你给 agent 接上了"长期记忆",跑了两个月。某天用户问"按我上次说的偏好来",它一脸茫然。可你的离线评测明明显示任务成功率 99%。问题出在哪?
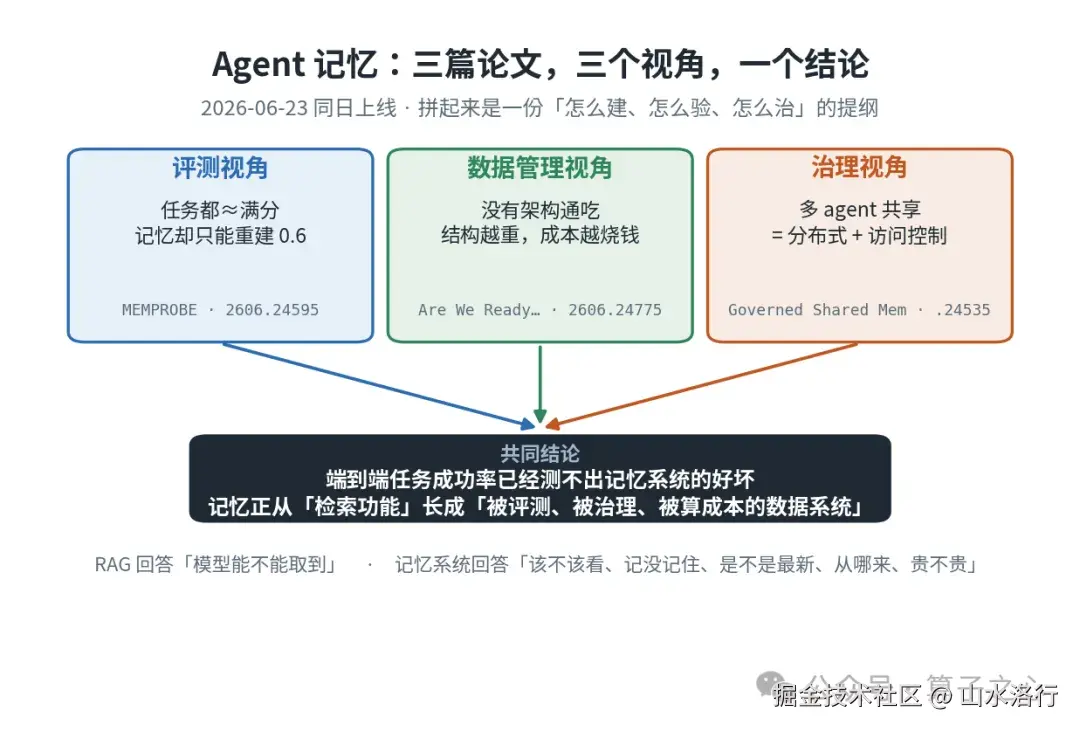
2026 年 6 月份,arXiv 上相继挂出三篇论文,从三个完全不同的角度回答了这个问题。读完我的判断是:我们给 agent 做记忆,可能从一开始就在用错误的尺子量它。
这三篇分别是 MEMPROBE(评测视角)、《Are We Ready For An Agent-Native Memory System?》(数据管理视角)、《Governed Shared Memory for Multi-Agent LLM Systems》(治理视角)。它们没有互相引用,但拼在一起,几乎是一份"agent 记忆系统该怎么建、怎么验、怎么治"的完整提纲。
下面我按"先动摇你对评测的信任 → 再给一张选型地图 → 最后讲多 agent 场景下的治理"这个顺序来讲,最后落到工程上能直接动手的几件事。
一、一个让人不安的实验:任务都答对了,记忆却是空的
先说最扎心的那篇------MEMPROBE。
它的思路很简单,但之前几乎没人这么干:把记忆当成一次交互结束后留下的"制品",直接去审计它。 不看 agent 后续回答得好不好,而是问一句------这次协助结束后,从它留下的记忆里,到底能重建出多少关于用户的结构化信息?
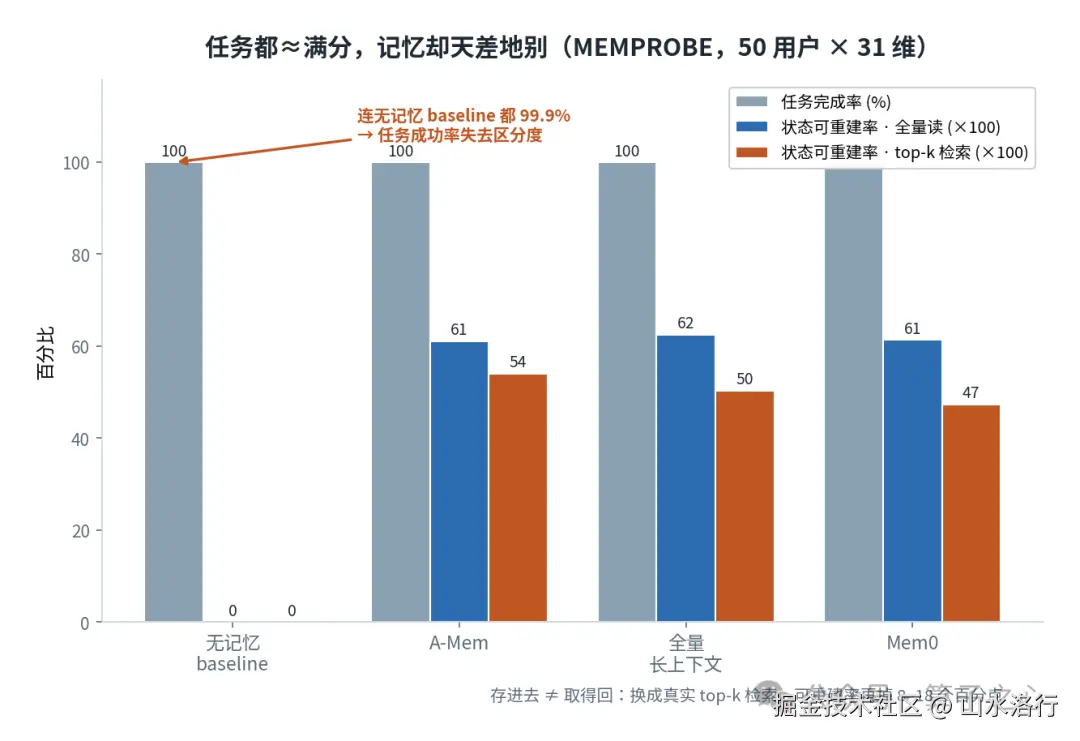
作者给每个(模拟)用户预先设定了一个隐藏的状态库:31 个维度、5 类(技能、知识、过往经历、自我认知、协助偏好),全程对 agent 不可见,只作为打分的 ground truth。任务设计上特意"防钓鱼"------只在邻近话题上请求帮助,绝不点名目标值,还有一个只看任务文字的盲审把"光看任务就能猜到答案"的题打回。50 个用户 × 31 维 = 1550 个重建目标。
结果是这样的:
| 系统 | 任务完成率 | 重建分(全量读) | 重建分(top-k 检索) | | --- | --- | --- | --- | | 无记忆 baseline | 99.9% | 0.00 | --- | | A-Mem | 99.9% | 0.61 | 0.54 | | 全量长上下文 | 99.9% | 0.62 | 0.50 | | Mem0 | 99.9% | 0.61 | 0.47 |
你没看错。连完全没有记忆的 baseline,任务完成率都是 99.9%,用户偏好分 4.58/5。 所谓"任务成功率"在这个测试里彻底失去了区分度------所有系统都满分,可它们记住的东西天差地别。真正能拉开差距的"重建分",最好的也才 0.6 出头;一旦换成真实的 top-k 检索(而不是把整个库倒出来读),还会再掉 8 到 18 个百分点。
这里藏着两个独立的失败点,MEMPROBE 用两种读取方式把它们分开了:把整个存储倒出来读(dump),测的是"到底有没有写进去 ";只读 top-k=5(retrieve),测的是"写进去了能不能取回来 "。两者一对比,结论很清楚------很多系统把原始对话老老实实存下来了,却没有把它整理成检索接口能浮出来的紧凑用户状态。 存了,但取不回。
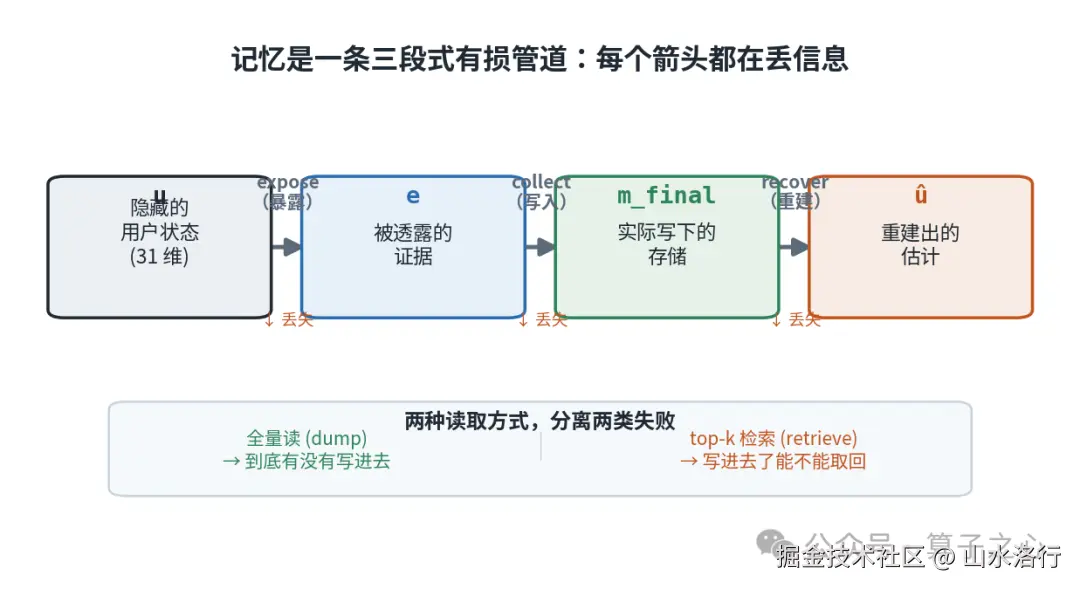
还有一个细节对做工程的人特别有用:五类记忆里,"协助偏好"最好恢复,"过往经历"最难,难到只有前者的三分之一到一半。 原因不是它稀有,而是一个"绑定问题"------写入端常常保住了"发生了什么",却丢了"当 X 发生时,导致了 Y"这条事件--语境--后果的链接。
把这三句记住就够了:任务做得好 ≠ 记得住;存下来 ≠ 取得回;一次性的、带时间的事件,比稳定偏好难记得多。
如果你手上正好有个接了记忆的 agent,今晚就能做的一件事:随便挑几个它"应该知道"的用户事实,把整个记忆库倒出来看在不在(写入对不对),再走一遍正常检索看捞不捞得到(检索对不对)。两者差很多,说明你该修的是检索;两者都低,说明问题在写入。
二、那到底什么样的记忆结构才行?
MEMPROBE 告诉你"现在的不行",但没回答"什么样的行"。这就是第二篇------清华数据库组和 MemTensor 那篇综述+横评------的价值。它把 12 个有代表性的记忆系统拉到统一测试床上(5 类 workload、11 个数据集),还给了一张能把所有系统都装进去的框架图。
它把一个记忆系统拆成四个模块,这个拆法本身就值得抄进设计文档:
-
表示与存储:用 token、向量、还是知识图谱/树;存在内存寄存器、单引擎向量库、还是多引擎后端。
-
抽取:把多轮对话、工具日志这些原始流,转成记忆原语------是原样拼接,还是语义抽取,还是结构化抽取。
-
检索与路由:kNN、子图遍历、LLM 规划式路由、多阶段混合。
-
维护:冲突消解与多版本、容量淘汰、语义合并。
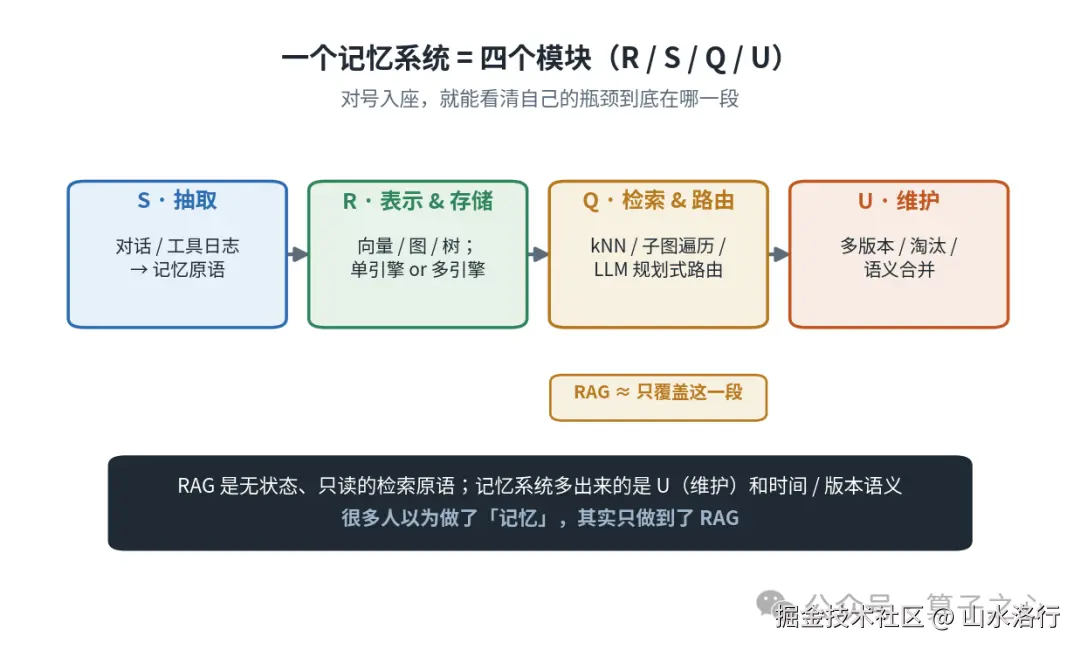
它还顺手把一件常被混为一谈的事说清楚了:RAG 不是记忆系统。 RAG 是无状态、只读的检索原语,给个 query 从静态语料里捞段落;记忆系统是持久、可更新、要管完整长期生命周期的基础设施。差的正是后面两个模块------维护和时序。很多人以为自己做了"记忆",其实只做到了 RAG。
横评里几个结论,我挑工程上最有指导意义的:
没有一种架构通吃。 跨会话、强关系的场景,图/时序结构(Zep、Cognee)赢;长但连贯的对话要精确定位,混合过滤(MemOS、MemoryOS)赢;强调操作顺序的状态化执行,保留原始交互轨迹反而最稳。有效性取决于"记忆结构对不对得上你 workload 的瓶颈",而不是哪个架构更高级。
保住原文,比"更抽象、更分层"更重要。 消融实验里,存原始用户话语的版本在所有指标上都赢过存摘要的版本;加深树结构只有微弱收益。深层结构能帮你导航,但救不回表示阶段就丢掉的内容。这条和 MEMPROBE 的"过往经历最难记"是同一个病根------别让 summary 把关键的时间、数值、后果抹平。
写入端要"晚过滤",别在写时就激进裁剪。 有个对比很刺眼:同一个系统,"快速记忆"模式在某数据集上 25.5 分,换成精细抽取的"细记忆"模式直接掉到 2.5 分。精细抽取换来一点字面匹配指标,却把多跳推理需要的上下文搞没了。
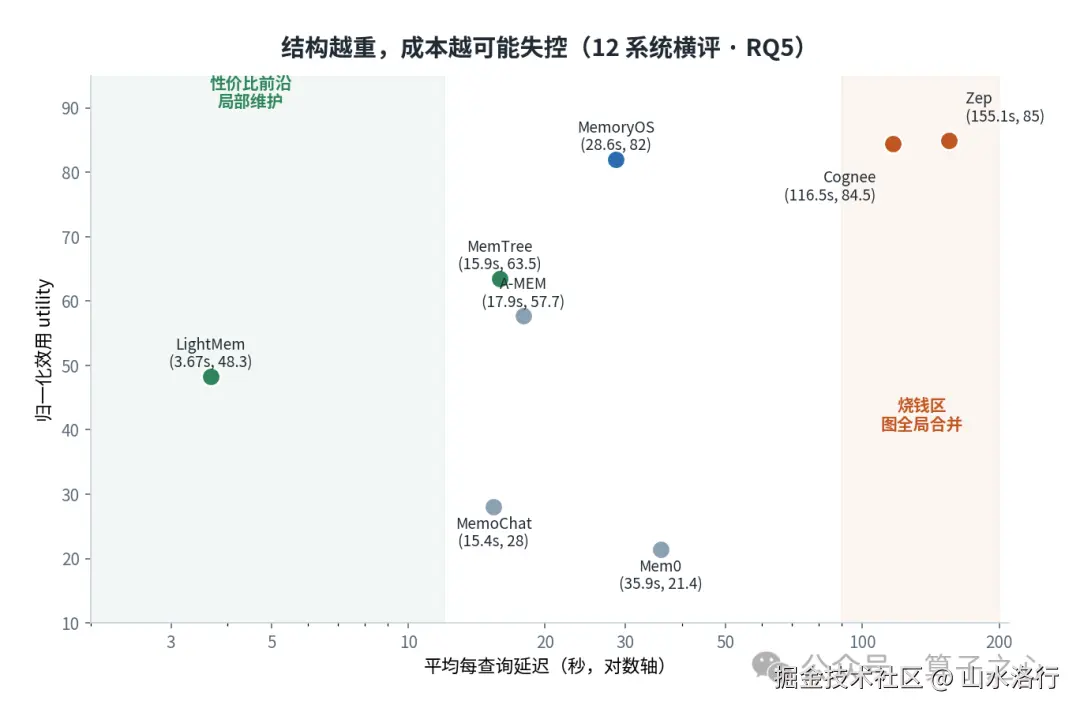
结构化越重,成本越可能失控。 这是最该贴在选型会议墙上的一条。论文的成本曲线显示:轻量的局部维护方案(LightMem、MemTree)能用几秒到十几秒的每查询延迟拿到不错的效果;而 Cognee、Zep 这类要做图全局合并的,得花到 116 秒、155 秒才换来更高的分数。在长上下文 workload 下,有些系统的每查询延迟会飙到 300--550 秒。组织得更好是真的,但成本随记忆增长爆炸也是真的。 一句话规则:局部更新/检索省钱,全局重写烧钱,除非你的场景真的非图不可,否则别默认上重结构。
三、当记忆被一群 agent 共享,它就变成了分布式系统问题
前两篇基本是"单 agent、单用户"。第三篇(Caura.ai 和本-古里安大学)把场景拉到一群协作 agent 共享同一块内存------他们叫它 fleet-memory------于是问题的性质彻底变了。
论文一句话点题:AI 记忆正在从一个"上下文窗口问题",变成一个"分布式系统问题"。 单 agent 记忆优化的是检索相关性、对话连续性、语义相似度;而多个 agent 共享一块内存时,你额外需要一整层东西:谁有权读哪条、两个 agent 写了矛盾的事实怎么办、旧状态怎么作废、每条记忆能不能追回是谁写的、知识怎么安全地跨 agent 边界传播。
他们把这些归纳成四种失败模式,几乎可以直接当成"多 agent 记忆的威胁清单":
-
越权泄漏:agent 读到了授权范围外的记忆(客服 agent 读到只该财务看的备注);
-
陈旧传播:更新没同步好,旧值还在被读;
-
矛盾持久:互斥的两条记忆并存,没人消解;
-
来源断链:记忆追不回 writer、source、时间,出了事查不到这条"知识"怎么进来的。

最值得说的是它的评测方式 :不做 baseline 横评,而是用一个开源探针直接打自家的生产服务 API,而且把负面结果当成核心贡献。这态度本身就比刷榜诚实。它真的曝出了两个生产 bug:
第一个是经典的"糊涂副手"(confused-deputy)。 语义搜索接口会按权限范围过滤,但"按 ID 直取"那个接口,解析了调用方身份之后......又忽略它,直接返回。结果就是越权------绕过搜索的旁路把不该看的记忆给端出来了。教训很硬:权限过滤必须施加在每一条读路径上,不能只挂在搜索接口上。(论文披露后服务方已修复。)
第二个更隐蔽:去重把矛盾检测"饿死"了。 系统有个同步的"近重复"门,会在异步的矛盾检测器看到之前,就把"长得很像"的写入当重复挡掉。问题是------一条"把参数从 A 改成 B"的更新,和原记录在 embedding 上高度相似,于是它被当成重复扔了,旧值永远不会被新值取代。测出来的现象是:矛盾消解只对"被收下的写入"有效(满分),但整体检测率只有 0.49。去重和矛盾消解在流水线上是有顺序冲突的,而矛盾更新往往就长得像重复。
正面结果也有:来源追溯做得很干净,深度 4 的派生链 100% 能重建、writer 身份全对;跨 fleet 的泄漏为零。但这两个 bug 的意义在于------它们都是"设计文档上看不出来、只有真跑起来才暴露"的问题。 这正是这篇最想说的。
四、把三篇拼起来,我的几个判断
三篇视角不同,但拼起来有清晰的共识,也有谁都没填的坑。
共识一:评测指标错位,是当前最大的问题。 任务成功率、F1 已经饱和、失去区分度。该看的是证据级保真度、可重建性、治理正确性。如果你现在还只用任务成功率验收记忆系统,基本等于没验。
共识二:写入比读取更被低估。 三篇都指向写入端------"保住原文、晚过滤","存了没整理成可取回的状态","去重把矛盾写入挡了"。记忆系统的成败,很大一半在写入策略,而大多数人的注意力都在检索那一侧。
共识三:时间和来源,是被忽视的一等公民。 时序更新、版本作废、派生链,这些在 RAG 时代基本没人管,却恰恰是 agent 长期运行不"精神分裂"的关键。
至于坑------没有任何一篇真正打通了"治理 + 评测 + 成本"这三件事。 第二篇有成本曲线但不碰多租户治理;第三篇有治理但只测了一个生产服务、不横评;MEMPROBE 评测漂亮但用的是合成用户、且限于单 agent。把 MEMPROBE 那套"可重建性审计"搬到多租户的 fleet 上,再叠上成本度量------这是一个明显值得做、但还空着的方向。
另外提醒一句别过度解读:三篇都是 v1 预印本,没经过同行评审;MEMPROBE 用合成用户和 LLM 打分,外推到真实分布需要自己验证;第三篇也明说它测的是单个生产服务,曝出的 bug 是"这类问题会发生"的存在性证明,不是"所有系统都这样"。
五、如果你正在搭这套东西
落到工程上,我会按这个优先级动手。
第一,先给记忆层画四象限,找到你真正的瓶颈。 表示/存储、抽取、检索/路由、维护------把你现有方案对号入座。我的经验是,大多数从 RAG 起步的系统,最薄弱的是"维护"(状态会变、配置会更新、工单会关闭)和"时序",而注意力却全花在了检索调参上。
第二,把"记忆审计"加进评测,别只看 Recall@K 和任务成功率。 借 MEMPROBE 的做法:为关键实体预设一组隐藏的状态维度,跑完一段对话后用 LLM 去重建、打分;并且一定做"全量读 vs top-k 读"的双读对比来定位问题。这是最便宜、最能看清病根的诊断。
第三,给强时序的记忆显式做"绑定"。 拿运维告警举例最直观:一条告警是典型的"过往经历"------某时刻、某网元、某指标跌破阈值,触发了某工单,根因是某变更。别让语义合并把这条因果链拍平成一句摘要。在记忆对象里显式存下事件、语境、后果、时间戳几个字段,而不是塞进一段自由文本。
第四,把第三篇那两个 bug 固化成代码里的两条铁律。 这是我从论文里拿走的、最具体的两行设计:
bash
# 铁律 1:每条读路径都要重新施加权限过滤------包括"按 id 直取",
# 否则就是 confused-deputy 越权。
async def read_by_id(mem_id, caller):
obj = await store.get(mem_id)
if obj is None or not policy.can_read(caller, obj):
return None
return obj
# 铁律 2:先判"是不是同一 (实体, 谓词) 的矛盾更新",再做近重复去重;
# 否则矛盾写入会被当重复挡掉,旧值永远不会被取代。
async def write(obj, caller):
if obj.predicate and obj.subject_entity_id:
prior = await store.find_active(obj.subject_entity_id, obj.predicate)
if prior and prior.content != obj.content:
obj.supersedes = prior.id
await store.mark(prior.id, status="superseded") # 时序消解优先
return await store.insert(obj)
if await dedup.is_near_duplicate(obj): # 去重放在矛盾判定之后
return obj.id
return await store.insert(obj)如果你用向量库(比如 Milvus)做 scope 隔离,把租户/团队/agent 维度做成标量字段或 partition key,检索时带上过滤------但记住,按 id 直取那条旁路也要走同一套策略。这正是铁律 1 的意义。至于性能开销(partition key + 标量过滤的组合查询),不同版本差异不小,需要自己压测,第三篇那条成本警告在这里同样成立。
记忆这件事,过去几年我们默认它是检索的延伸------把历史塞进向量库,需要时捞出来。这三篇放在一起,说的其实是同一件事:当 agent 要长期运行、要协作、要被审计,记忆就不再是一个检索功能,而是一个需要被评测、被治理、被算成本的数据系统。
RAG 解决的是"模型能不能取到";而这三篇要回答的,是"该不该看、记没记住、是不是最新、从哪来、贵不贵"。如果你正在做这件事,最该立刻动手的三件:补上"全量读 vs top-k 读"的记忆审计、给强时序记忆做事件--语境--后果的绑定、把权限过滤施加到每一条读路径上。
三篇论文(均为 2026-06 提交的 arXiv 预印本):
-
Are We Ready For An Agent-Native Memory System? --- arXiv:2606.24775
-
MEMPROBE: Probing Long-Term Agent Memory via Hidden User-State Recovery --- arXiv:2606.24595
-
Governed Shared Memory for Multi-Agent LLM Systems --- arXiv:2606.24535
文中数字引自各论文正文;schema 字段与"两条铁律"为综合三篇得出的设计建议,非原文。
希望这篇文章能为您带来一些帮助。如果有任何疑问或建议,请在评论区留言,我们将尽力回答!
欢迎添加微信交流: wandering_blade
让我们一起探索并推动前沿技术发展!🚀💻
祝好运!😊✍️