一句话讲完决策树:"像做选择题一样,一层一层往下问,直到得出答案。"
写在前面
今天讲一个特别直观、特别好懂 的算法------决策树(Decision Tree)。
你平时生活里其实天天都在用决策树,只是你自己没意识到。比如:
-
你去相亲,心里会过一遍:年龄合不合适?→ 长得帅不帅?→ 工作好不好?→ 见还是不见?
-
你买西瓜,会敲一敲:声音闷不闷?→ 瓜蒂新不新鲜?→ 皮薄不薄?→ 买还是不买?
决策树就是把这种"一问一答"的决策过程,用计算机自动学出来。
第一部分:决策树是什么?
1.1 一个真实的小故事:银行柜员小张的烦恼
小张在银行工作,每天要审批信用卡申请。他的判断标准是:
python
申请人月收入是否大于8000?
├── 是 → 是否有稳定工作(在职满1年)?
│ ├── 是 → 信用分是否大于650?
│ │ ├── 是 → ✅ 批卡(额度较高)
│ │ └── 否 → ✅ 批卡(额度较低)
│ └── 否 → ❌ 拒绝
└── 否 → ❌ 拒绝小张的经验,就是一棵决策树。
1.2 决策树的三个核心概念
| 概念 | 通俗解释 | 对应上面的例子 |
|---|---|---|
| 内部节点 | 每个"判断条件" | "月收入>8000?""在职满1年?" |
| 分支 | 判断的结果 | "是 / 否" |
| 叶子节点 | 最终结论(不再继续分了) | "✅批卡"或"❌拒绝" |
1.3 决策树能解决两类问题
和KNN一样,决策树也是分类回归通吃:
| 任务类型 | 预测内容 | 举例 |
|---|---|---|
| 分类树 | 预测"是哪一类" | 信用卡批不批?(批/拒) |
| 回归树 | 预测"是多少" | 批多少额度?(连续数值:5000~10万) |
第二部分:决策树的构建流程(4步走)
一颗决策树的"生长"过程分为4步:
| 步骤 | 做什么 | 白话解释 |
|---|---|---|
| 1 | 特征选择 | 从所有特征里挑一个"最有用"的,放在树根 |
| 2 | 分裂 | 根据这个特征把数据分成两组(或多组) |
| 3 | 递归 | 对分出来的每一组,重复步骤1-2 |
| 4 | 停止 | 直到所有叶子节点都"纯"了,或者达到设定的停止条件 |
最关键的是第1步------怎么判断哪个特征"最有用"? 这就是CART算法的核心。
第三部分:CART决策树(最主流的实现)
3.1 什么是CART?
CART = Classification And Regression Tree(分类与回归树)。
它是目前最主流的决策树实现,也是随机森林、XGBoost、LightGBM这些高级算法的"地基"。
3.2 CART的三个核心规则
| 规则 | 说明 | 举例 |
|---|---|---|
| 规则1:强制二分 | 每次分裂只能分成两组 | 问"收入>8000?"→ 是/否,不能分成"高/中/低"三组 |
| 规则2:贪心选择 | 每一步都选当前"最有用"的特征 | 比较所有特征,选那个让数据分得最"干净"的 |
| 规则3:递归进行 | 一层一层往下分,直到满足停止条件 | 分完一组再分下一组,像剥洋葱 |
3.3 怎么判断特征"最有用"?(基尼系数)
CART分类树用的是**基尼系数(Gini Index)**来度量"纯度"。
公式:
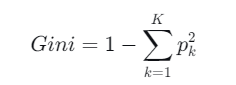
-
pk = 某组数据中第 k 类样本的比例
-
Gini越小 → 数据越"纯"(大家都是一个类)
-
Gini越大 → 数据越"混"(各类都有)
一个特征"有用" ,就是用它划分后,两组的Gini系数之和最小(分得最干净)。
3.4 CART回归树(预测数值)
如果我们要预测"批多少额度"(连续数字),CART也能做。区别在于:
| 对比 | 分类树 | 回归树 |
|---|---|---|
| 目标 | 预测类别 | 预测数值 |
| "纯度"衡量 | 基尼系数(Gini) | 均方误差(MSE) |
| 叶子节点输出 | 投票选最多的类别 | 该组所有样本的平均值 |
回归树分裂时,找的是让MSE下降最多的那个分裂点。
第四部分:决策树超参数(防过拟合的武器)
4.1 决策树容易过拟合
决策树有个特点:如果不加限制,它可以一直往下分,直到每个叶子节点只剩一个样本 。这样的模型在训练集上100%准确,但在新数据上表现极差------这就是过拟合。
4.2 常用超参数(限制树的大小)
| 参数 | 作用 | 建议值 |
|---|---|---|
max_depth |
树的最大深度(层数) | 3~10,太深容易过拟合 |
min_samples_split |
内部节点再划分所需的最小样本数 | 默认2,可设5~20 |
min_samples_leaf |
叶子节点最少样本数 | 默认1,可设3~10 |
max_features |
每次分裂考虑的最大特征数 | 默认全部,可设 sqrt(n) |
4.3 剪枝(Pruning)------更高级的防过拟合
剪枝就是砍掉一些没用的树枝,让树变简单。
两种剪枝方式:
| 方式 | 时机 | 做法 | 优缺点 |
|---|---|---|---|
| 预剪枝 | 树生长过程中 | 每次分裂前评估:分了能提升效果吗?不能就停 | 省时间,但可能"错过好分支" |
| 后剪枝 | 树完全长成后 | 从下往上检查:这个分支有用吗?没用就砍掉 | 效果好,但耗时更久 |
sklearn的
DecisionTreeClassifier默认是预剪枝 ------通过max_depth、min_samples_split等参数限制。
第五部分:信用卡审批预测
5.1 生成数据
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 设置随机种子
np.random.seed(42)
# 生成2000条信用卡申请数据
n = 2000
# 特征:月收入(万)(0.5~15)、在职月数(1~120)、信用分(300~850)、负债率(0~0.9)
income = np.random.uniform(0.5, 15, n)
work_months = np.random.randint(1, 121, n)
credit_score = np.random.randint(300, 851, n)
debt_ratio = np.random.uniform(0, 0.9, n)
# 生成标签(批卡=1,拒卡=0)
# 业务逻辑:收入高+信用分高+负债低 → 批卡
score = (income * 0.6 + credit_score * 0.01 - debt_ratio * 3 + work_months * 0.01)
y = (score > 5).astype(int) # 综合得分>5批卡
# 拼成DataFrame
data = pd.DataFrame({
'月收入(万)': income,
'在职月数': work_months,
'信用分': credit_score,
'负债率': debt_ratio,
'是否批卡': y
})
print("数据前5行:")
print(data.head())
print(f"\n总样本数:{len(data)},批卡比例:{y.sum()/n*100:.1f}%")5.2 划分训练集和测试集(决策树不需要标准化)
python
# 特征和标签分开
X = data[['月收入(万)', '在职月数', '信用分', '负债率']]
y = data['是否批卡']
# 训练集70%,测试集30%
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
print(f"训练集:{len(X_train)}条,测试集:{len(X_test)}条")注意 :和KNN不同,决策树不需要做标准化!因为决策树是"按阈值比较",不是算距离,特征尺度不影响分裂结果。
5.3 训练决策树模型(分类)
python
# 创建决策树分类器(限制深度防止过拟合)
model = DecisionTreeClassifier(
max_depth=5, # 最大深度5层
min_samples_split=20, # 节点至少20个样本才继续分
min_samples_leaf=10, # 叶子节点至少10个样本
random_state=42
)
# 训练
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 准确率
acc = accuracy_score(y_test, y_pred)
print(f"测试集准确率:{acc * 100:.2f}%")
# 详细分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=['拒卡', '批卡']))5.4 特征重要性分析(决策树的隐藏技能)
决策树能告诉我们:哪个特征对决策最重要?
python
# 获取特征重要性
importance = model.feature_importances_
feature_names = ['月收入(万)', '在职月数', '信用分', '负债率']
print("\n特征重要性(加起来=1):")
for name, imp in zip(feature_names, importance):
print(f" {name}:{imp:.3f}")
# 可视化特征重要性
plt.figure(figsize=(8, 5))
plt.barh(feature_names, importance, color='steelblue')
plt.xlabel('重要性')
plt.title('信用卡审批决策树-特征重要性')
plt.show()输出示例:
python
特征重要性(加起来=1):
月收入(万):0.452
在职月数:0.098
信用分:0.335
负债率:0.115说明:月收入和信用分是最关键的两个因素。
5.5 可视化决策树(画出来看看!)
python
plt.figure(figsize=(25, 15))
plot_tree(
model,
feature_names=feature_names,
class_names=['拒卡', '批卡'],
filled=True, # 用颜色表示类别
rounded=True, # 圆角框
fontsize=12,
max_depth=4 # 只画前4层,不然太密
)
plt.title('信用卡审批决策树')
plt.show()5.6 决策树回归(预测授信额度)
如果把标签改成连续值(批多少额度),就是用回归树。
python
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 生成新的标签:授信额度(万),范围2~50
limit = 2 + income * 2.5 + credit_score * 0.02 - debt_ratio * 10 + np.random.normal(0, 2, n)
limit = np.clip(limit, 2, 50)
# 重新切分
X_train, X_test, y_train_reg, y_test_reg = train_test_split(
X, limit, test_size=0.3, random_state=42
)
# 创建回归树
reg_model = DecisionTreeRegressor(
max_depth=6,
min_samples_split=20,
min_samples_leaf=10,
random_state=42
)
# 训练
reg_model.fit(X_train, y_train_reg)
# 预测
y_pred_reg = reg_model.predict(X_test)
# 评估
mse = mean_squared_error(y_test_reg, y_pred_reg)
mae = mean_absolute_error(y_test_reg, y_pred_reg)
print(f"回归树 - 均方误差(MSE):{mse:.2f}")
print(f"回归树 - 平均绝对误差(MAE):{mae:.2f}")
print(f"真实额度前5个:{y_test_reg[:5]}")
print(f"预测额度前5个:{y_pred_reg[:5]}")第六部分:决策树 vs KNN(什么时候用谁?)
| 对比维度 | 决策树 | KNN |
|---|---|---|
| 是否需要标准化 | ❌ 不需要 | ✅ 必须做 |
| 可解释性 | ✅ 超强(可以画出来看) | ❌ 黑盒 |
| 训练速度 | ✅ 快 | ❌ 慢(要存所有数据) |
| 预测速度 | ✅ 极快(就几层判断) | ❌ 慢(要算距离) |
| 对缺失值处理 | 可以处理 | 无法处理 |
| 过拟合风险 | 高(需要剪枝) | 低(调K值就好) |
| 非线性数据 | ✅ 能处理 | ❌ 效果差 |
经验建议:
-
需要解释给老板/客户听 → 选决策树(可以画图展示)
-
数据特征少、干净 → 选KNN
-
数据有缺失值 → 选决策树
-
追求预测速度(在线服务)→ 选决策树
-
追求极致准确率 → 两个都试试,选好的
第七部分:CART的优缺点
7.1 优点(5个)
| 优点 | 说明 |
|---|---|
| 简单易懂 | 画出来一看就懂,非技术人员也能理解 |
| 功能强大 | 分类回归通吃 |
| 规则简洁 | 强制二分,逻辑清晰 |
| 鲁棒性好 | 自带剪枝,抗过拟合 |
| 应用广泛 | 是随机森林、XGBoost的基石 |
7.2 缺点(3个)
| 缺点 | 说明 |
|---|---|
| 容易过拟合 | 不加限制的话,可以完美拟合训练集 |
| 结果不稳定 | 数据稍微变一点,整棵树可能完全不一样 |
| 非全局最优 | 每一步只选当前最优(贪心),不保证整体最优 |
第八部分:剪枝详解(两种方式对比)
8.1 预剪枝(Pre-pruning)
在树生长过程中就决定"要不要继续分"。
python
# 这就是预剪枝------通过参数限制树的生长
model = DecisionTreeClassifier(
max_depth=5, # 到5层就不分了
min_samples_split=20, # 样本少于20就不分了
min_samples_leaf=10 # 叶子少于10就不分了
)| 优点 | 缺点 |
|---|---|
| 省时间(不用长完整棵树) | 可能"短视"------现在没用但后面有用的分支被误砍 |
| 防止过拟合 | 容易欠拟合 |
8.2 后剪枝(Post-pruning)
先让树完全长成,再从下往上检查:这个分支有用吗?没用就砍掉。
sklearn的DecisionTreeClassifier的ccp_alpha参数可以实现成本复杂度剪枝(一种后剪枝)。
python
# 用ccp_alpha做后剪枝(值越大剪得越狠)
model_pruned = DecisionTreeClassifier(
ccp_alpha=0.005, # 剪枝系数,需要调参
random_state=42
)
model_pruned.fit(X_train, y_train)| 优点 | 缺点 |
|---|---|
| 比预剪枝效果好(保留了更多有用分支) | 耗时(先要长完整棵树) |
实战建议 :先用预剪枝(限制max_depth等),简单高效;如果效果还不够好,再尝试后剪枝。
第九部分:完整知识点脑图
python
决策树(CART)
│
├── 核心思想
│ └── 像做选择题一样,一层层往下问,直到出答案
│
├── 三大规则
│ ├── 强制二分(每次只分两组)
│ ├── 贪心选择(每一步选最"纯"的特征)
│ └── 递归进行(一层一层往下分)
│
├── 两种任务
│ ├── 分类树(基尼系数衡量纯度)
│ └── 回归树(MSE衡量纯度,叶子输出平均值)
│
├── 防止过拟合
│ ├── 预剪枝(限深度、限样本数)← sklearn默认
│ └── 后剪枝(先长完整棵树再砍)← ccp_alpha
│
├── 优势
│ ├── 可解释性强(可以画图)
│ ├── 不需要标准化
│ └── 能处理缺失值
│
└── 劣势
├── 容易过拟合
├── 结果不稳定(数据一变树就变)
└── 贪心策略不保证全局最优第十部分:总结
| 模块 | 核心内容 |
|---|---|
| 决策树思想 | 一层一层做选择题,直到得出结论 |
| CART算法 | 强制二分 + 基尼系数 + 递归分裂 |
| 分类 vs 回归 | 分类看基尼,回归看MSE |
| 超参数 | max_depth、min_samples_split等(防过拟合) |
| 剪枝 | 预剪枝(生长时限制)和后剪枝(长完再砍) |
| 对比KNN | 决策树可解释性强、不需标准化、速度快 |
| 代码实战 | 信用卡审批预测(分类)+ 额度预测(回归) |
给新手的3个建议:
-
先理解"树是怎么长的":每次找一个特征分裂→让数据变纯→递归→停止。把这句话背下来,决策树的骨架你就有了。
-
重视max_depth这个参数 :它是防止过拟合最简单粗暴的手段。从
max_depth=3开始试,慢慢加深。 -
画图看树 :
plot_tree是你理解模型最好的工具。画出来一看,比看100行代码都管用。