目录
- 一、分析
- [二、Python 实现](#二、Python 实现)
-
- [2.1 纯 Python 复现版本](#2.1 纯 Python 复现版本)
- [2.2 Python 调用 JS 复现版本](#2.2 Python 调用 JS 复现版本)
- [2.3 运行结果摘要](#2.3 运行结果摘要)
- 三、总结
免责声明:本文内容仅用于合法授权范围内的技术学习、安全研究、逆向分析方法交流与风控防护理解,不针对任何网站、产品或服务提供绕过、攻击、滥用或破坏性使用建议。文中涉及的接口分析、参数加解密、调试定位、代码复现、数据请求等内容,仅用于说明相关技术原理和分析流程。读者应在遵守相关法律法规、平台规则、robots 协议、用户协议以及获得合法授权的前提下进行学习和实验。请勿将本文中的方法、脚本或思路用于未授权访问、批量采集、账号撞库、绕过风控、破坏验证码体系、规避平台限制、侵犯数据权益、商业化滥用或影响线上系统稳定性的行为。对于真实网站案例,读者不应直接复制代码对线上服务进行高频请求或非授权调用。若相关网站、产品方、权利方或平台认为本文内容存在不适宜公开展示之处,可通过评论区、私信或作者主页提供的联系方式联系我;核实后将及时删除、替换或调整相关内容。读者因不当使用本文内容造成的任何法律责任、业务风险或经济损失,均由使用者自行承担,与作者无关。
一、分析
目标地址:
text
https://jzsc.mohurd.gov.cn/data/company本案例需要抓取全国建筑市场监管公共服务平台的企业列表数据,循环采集前 3 页,并提取每条记录中的统一社会信用代码、企业名称、企业法定代表人和企业注册属地。
打开 F12 进入 DevTools,切换到 Network 面板并清空请求记录。由于列表页数据是通过 Ajax 动态加载的,先筛选 Fetch/XHR 请求,再通过翻页触发接口调用,定位到目标数据包:
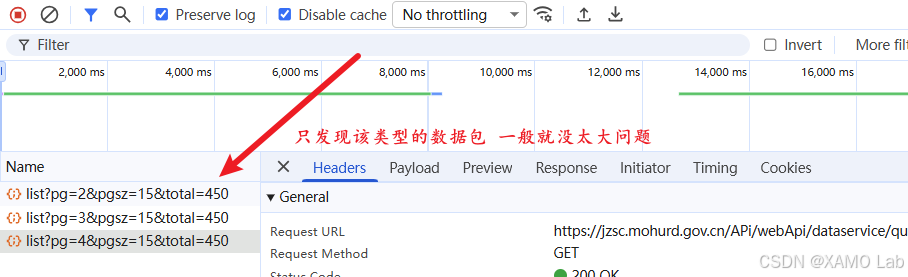
目标接口是一个 GET 请求:
text
GET https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list?pg=2&pgsz=15&total=450
GET https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list?pg=3&pgsz=15&total=450
GET https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list?pg=4&pgsz=15&total=450可以很明显地看出,只有 pg 参数是动态变化的,而其他请求参数都是明文传输,所以这个案例不需要额外考虑请求参数加密。接着看一下响应内容,会发现返回结果是加密的,如下:
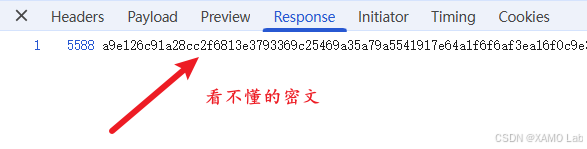
再看一下 Headers,如下:
http
GET /APi/webApi/dataservice/query/comp/list?pg=3&pgsz=15&total=450 HTTP/1.1
Accept: application/json, text/plain, */*
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: keep-alive
Cookie: Hm_lvt_b1b4b9ea61b6f1627192160766a9c55c=1780369208,1782328514; HMACCOUNT=0703805E4B458F81; Hm_lpvt_b1b4b9ea61b6f1627192160766a9c55c=1782761708
Host: jzsc.mohurd.gov.cn
Pragma: no-cache
Referer: https://jzsc.mohurd.gov.cn/data/company
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36
accessToken: jkFXxgu9TcpocIyCKmJ+tfpxe/45B9dbWMUXhdY7vLWybhbMLlsuA4d7x6oBdwP7hpUUKvcMtoMqfGfwdLCb8g==
sec-ch-ua: "Google Chrome";v="149", "Chromium";v="149", "Not)A;Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
timeout: 30000
v: 231012这里有两个比较少见的请求头字段 accessToken 和 v,初看上去像是自定义校验字段。先说 accessToken:经过实测,把它置空、甚至整个 Cookie 都不带,接口依然能正常返回数据,所以它并不是本案例的必需校验字段,这里先不展开。v 看起来像是一个版本号,三个数据包里它的值都固定是 231012,可以先记下来------后面分析密钥时会发现,这个字段其实直接决定了服务端返回密文的加密版本,是一个不能忽略的关键字段。
当前更重要的是处理响应密文的解密逻辑,所以先采用最直接的方式,全局搜索 decrypt 等关键字,看看解密代码位于哪里,如下:
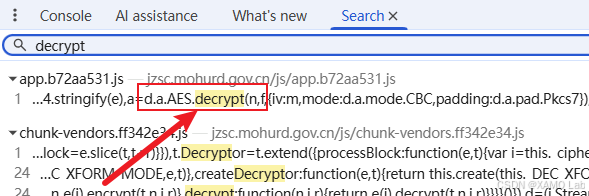
这个位置非常明显。按照前面几个案例的经验,直接点进去查看即可,定位到 /js/app.b72aa531.js,可以看到核心代码 d.a.AES.decrypt(n, f, {。我们在这里下一个断点,然后翻页触发请求,观察是否会断住。结果不出意外,断点成功命中,如下:
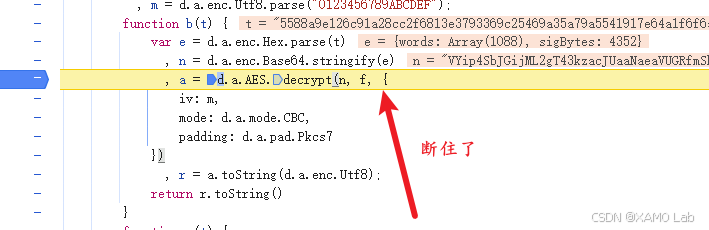
代码最终断在 b 函数中,所以把这个函数单独拿出来看最合适。这里的逻辑并不复杂,核心就是把接口返回的密文转成明文 JSON,分析如下:
javascript
function b(t) {
// d.a 是 CryptoJS 对象
// t 是接口返回的密文
// f 是 AES 密钥
// m 是 IV
// 这里使用的是 AES-CBC,填充方式为 Pkcs7
var e = d.a.enc.Hex.parse(t)
, n = d.a.enc.Base64.stringify(e)
, a = d.a.AES.decrypt(n, f, {
iv: m,
mode: d.a.mode.CBC,
padding: d.a.pad.Pkcs7
})
, r = a.toString(d.a.enc.Utf8);
return r.toString()
}到这里其实已经很清楚了,剩下要确认的就是密钥 f 和 iv m。这里容易踩的一个点是,b 函数内部并没有直接定义这两个变量,它们都来自上层闭包,所以不能只盯着函数体本身看。按照逆向习惯,继续往上翻就能找到它们的定义位置,如下:
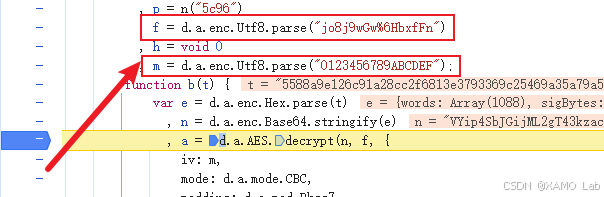
紧接着就可以在本地把这段逻辑改写出来,如下:
javascript
const CryptoJS = require('./CryptoJS')
// f = d.a.enc.Utf8.parse("jo8j9wGw%6HbxfFn")
f = CryptoJS.enc.Utf8.parse("jo8j9wGw%6HbxfFn")
// , h = void 0
// m = d.a.enc.Utf8.parse("0123456789ABCDEF");
m = CryptoJS.enc.Utf8.parse("0123456789ABCDEF");
function b(t) {
// var e = d.a.enc.Hex.parse(t)
var e = CryptoJS.enc.Hex.parse(t)
// , n = d.a.enc.Base64.stringify(e)
, n = CryptoJS.enc.Base64.stringify(e)
// , a = d.a.AES.decrypt(n, f, {
, a = CryptoJS.AES.decrypt(n, f, {
iv: m,
// mode: d.a.mode.CBC,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
})
// , r = a.toString(d.a.enc.Utf8);
, r = a.toString(CryptoJS.enc.Utf8);
return r.toString()
}但实际运行时发现,无论怎么改写都无法正常解密密文,一直会报错:
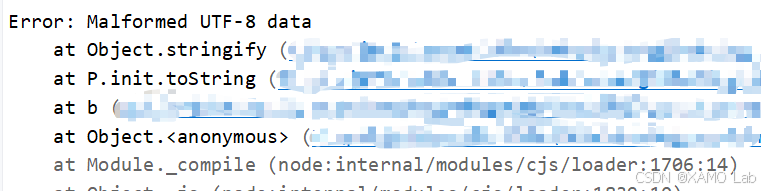
这时就要开始排查,是不是代码被动态改写过,或者是密钥、IV 取值不对。先看当前 f 的字节数组,再对比上面赋值 f 的位置 d.a.enc.Utf8.parse("jo8j9wGw%6HbxfFn"),会发现字节数组并不一致,如下:
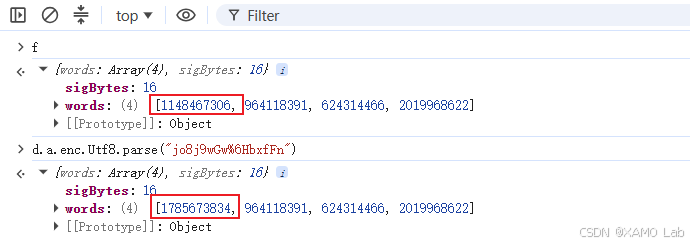
再对比一下 iv,可以看到这一项是一致的:
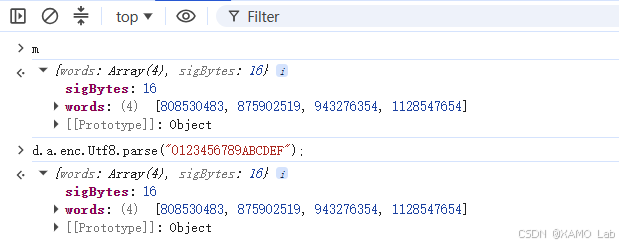
其实这里直接使用字节数组去解密也是可以的。不过继续看右侧面板可以发现,f 确实位于上层闭包 Closure (27fe) 中,而且字节数组的第一个元素和浏览器里使用的是同一个,如下:
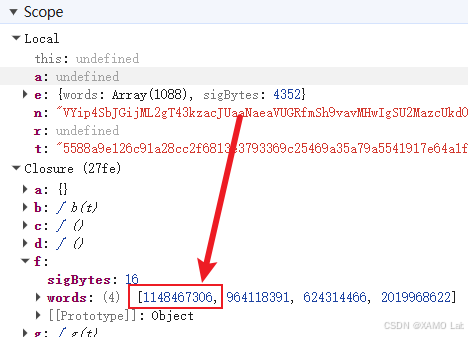
但它又不是 d.a.enc.Utf8.parse("jo8j9wGw%6HbxfFn") 的结果。看到这里基本就能判断,在这个闭包或者模块内部,f 还有其他地方被重新赋值了。继续往下翻找,果然发现 f 被再次赋值了,如下:
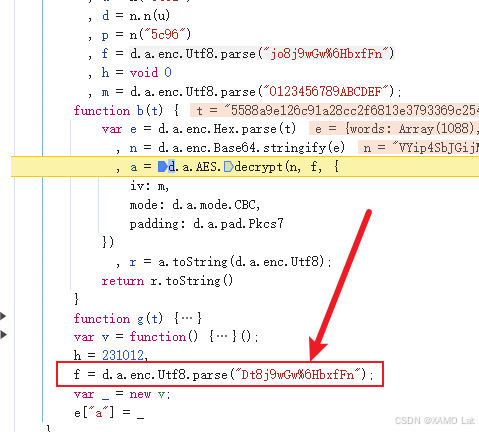
于是我们改用这个值再试一次,本地 js 代码调整如下:
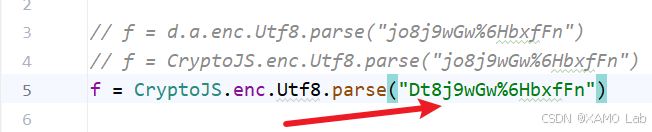
重新执行 js 代码后,解密成功:

不过到这里可能会留下一个疑问:源码里先写了 f = ...parse("jo8j9wGw%6HbxfFn"),后面又把 f 覆盖成 Dt8j9wGw%6HbxfFn,前一个难道只是用来迷惑人的诱饵吗?多测几次会发现并不是------这两个 key 其实都是「真」的,区别在请求头里的 v:
- 不带
v:服务端返回的密文是95780...开头,要用jo8j9wGw%6HbxfFn才能解开; - 带
v: 231012:服务端返回的密文是55...开头,要用Dt8j9wGw%6HbxfFn才能解开。
也就是说,v 是一个接口版本号,服务端会根据它返回 不同版本(不同密钥) 加密的密文。两种情况解出来的明文 JSON 完全一致,IV、加密模式和填充方式也都没变(依旧是 AES-CBC / Pkcs7,IV 固定为 0123456789ABCDEF),唯一的差别就是加密所用的 key。
再回头看前端代码就通了:getInsideConfig 里写死了请求头 v: h,而 h = 231012,所以浏览器发出的请求 永远带 v: 231012 ,拿到的必然是 55... 格式,于是代码也顺势把 f 覆盖成配套的 Dt8j9wGw%6HbxfFn。前面那行 jo8j9wGw%6HbxfFn 只是旧版本(无 v)遗留下来的 key,在当前浏览器流程里属于永远走不到的「死代码」,但服务端出于向后兼容仍然认它------这才是它看起来像诱饵、实际却能解开另一种格式密文的真正原因。
所以后面用 Python 复现时,有两条都能走通的路:要么 带上 v: 231012、用 Dt8j9wGw%6HbxfFn 解 (与浏览器真实行为一致,推荐这种);要么干脆不带 v、改用 jo8j9wGw%6HbxfFn 解。两者拿到的数据完全相同,本案例统一按浏览器口径走第一种。
至此,这个案例的响应解密部分就已经分析完成了。这个网站真正的难点并不在响应解密,而在点击进入详情页时的校验流程,如下:


这个点后续有机会再单独展开,这里先不作为本节重点。
二、Python 实现
前面已经把接口定位、参数规律、响应解密逻辑(含 v 头与密钥版本的关系)都分析清楚了。这里把最终可运行代码整理成两个版本:
- 纯 Python 复现:直接用 Python 改写前端
b函数的 hex → AES-CBC/PKCS7 解密逻辑。 - Python 调用 JS:保留浏览器中扣下来的
b函数(重命名为decryptRes),通过execjs调用本地 CryptoJS 完成解密。
考虑到本案例只是循环抓取前 3 页,请求量很小,且页码之间无依赖,这里统一采用顺序抓取,不引入多线程并发。
目录结构:
text
jzsc-company-aes-cbc
├─ README.md
├─ jzsc_company_python_spider.py
├─ jzsc_company_execjs_spider.py
├─ jzsc_company.js
└─ CryptoJS.js字段提取说明:
| 字段 | 说明 | 来源 |
|---|---|---|
page |
页码(从 1 展示) | 请求参数 pg(从 0 开始)+1 |
credit_code |
统一社会信用代码 | 响应字段 QY_ORG_CODE |
company_name |
企业名称 | 响应字段 QY_NAME |
legal_person |
企业法定代表人 | 响应字段 QY_FR_NAME |
region_name |
企业注册属地 | 响应字段 QY_REGION_NAME |
2.1 纯 Python 复现版本
运行方式:
bash
python jzsc_company_python_spider.py完整代码如下:
python
# -*- coding: utf-8 -*-
"""
@File : jzsc_company_python_spider.py
@Author : XAMO Lab
@Date : 2026/6/30 5:46
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc : 全国建筑市场监管公共服务平台企业信息采集(AES/CBC/PKCS7 响应解密,顺序抓取)
"""
import binascii
import json
import sys
import time
import warnings
from typing import Any, Dict, List
warnings.filterwarnings(
"ignore",
message=r"urllib3 .* or chardet .*charset_normalizer .* doesn't match a supported version!",
)
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
from loguru import logger
logger.remove()
logger.add(sys.stdout, level="INFO")
class JzscCompanySpider:
"""全国建筑市场监管公共服务平台企业列表爬虫。"""
API_URL = "https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list"
SITE_URL = "https://jzsc.mohurd.gov.cn/data/company"
# 逆向自 js/app.b72aa531.js 模块 27fe:
# m = Utf8.parse("0123456789ABCDEF") -> IV
# f = Utf8.parse("jo8j9wGw%6HbxfFn") -> 旧版本(不带 v 头)遗留 key
# h = 231012, f = Utf8.parse("Dt8j9wGw%6HbxfFn") -> 覆盖为新版本 key
# 浏览器请求头固定带 v=231012,服务端返回 "55" 开头的新版本密文,
# 因此真正生效的是 Dt8j9wGw%6HbxfFn;jo8j9wGw%6HbxfFn 仅用于不带 v 头的旧格式。
AES_KEY = b"Dt8j9wGw%6HbxfFn"
AES_IV = b"0123456789ABCDEF"
V_HEADER = "231012"
# 解析输出的目标字段:统一社会信用代码 / 企业名称 / 法定代表人 / 注册属地
FIELD_MAP = {
"QY_ORG_CODE": "credit_code",
"QY_NAME": "company_name",
"QY_FR_NAME": "legal_person",
"QY_REGION_NAME": "region_name",
}
def __init__(self, page_size: int = 15, retries: int = 3, timeout: int = 30) -> None:
"""
:param page_size: 每页条数,页面默认 15
:param retries: 单页请求失败后的重试次数
:param timeout: 单次请求超时时间(秒)
"""
self.page_size = page_size
self.retries = retries
self.timeout = timeout
self.session = requests.Session()
self.session.headers.update({
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Referer": self.SITE_URL,
# v 是接口版本号,决定服务端返回密文的加密版本,必须带上才能用新版 key 解密。
"v": self.V_HEADER,
# accessToken 实测可为空字符串,接口仍正常返回,这里保留以贴近浏览器请求。
"accessToken": "",
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/149.0.0.0 Safari/537.36"
),
})
def _params(self, pg: int, total: int = 0) -> Dict[str, Any]:
"""组装查询参数。pg 从 0 开始计数,total 传 0 时服务端会回填真实总数。"""
return {"pg": pg, "pgsz": self.page_size, "total": total}
def _decrypt(self, ciphertext: str) -> Dict[str, Any]:
"""Hex 密文文本 -> AES/CBC/PKCS7 解密 -> dict。
前端 b(t) 里先 Hex.parse 再 Base64.stringify 喂给 CryptoJS,本质等价于
把 hex 字符串直接还原成密文字节,因此这里 unhexlify 即可。
"""
raw = binascii.unhexlify(ciphertext.strip())
cipher = AES.new(self.AES_KEY, AES.MODE_CBC, self.AES_IV)
plaintext = unpad(cipher.decrypt(raw), AES.block_size).decode("utf-8")
return json.loads(plaintext)
def _parse_item(self, item: Dict[str, Any], page: int, index: int) -> Dict[str, Any]:
"""提取企业字段,统一输出结构。"""
row: Dict[str, Any] = {"page": page, "index": index}
for src_key, dst_key in self.FIELD_MAP.items():
row[dst_key] = item.get(src_key) or ""
return row
def fetch_page(self, pg: int, total: int = 0) -> List[Dict[str, Any]]:
"""请求单页、解密响应并返回结构化企业数据。pg 从 0 开始。"""
params = self._params(pg, total)
display_page = pg + 1
for attempt in range(1, self.retries + 1):
try:
logger.info("page={} (pg={}) 开始请求 | params={}", display_page, pg, params)
response = self.session.get(self.API_URL, params=params, timeout=self.timeout)
response.raise_for_status()
# 响应体是 hex 密文文本,不是 JSON 对象。
data = self._decrypt(response.text)
if data.get("code") != 200:
logger.warning(
"page={} 接口异常 code={} message={}",
display_page, data.get("code"), data.get("message"),
)
return []
body = data.get("data") or {}
rows = [
self._parse_item(item, display_page, idx)
for idx, item in enumerate(body.get("list") or [], 1)
]
logger.success(
"page={} 解密成功,获取 {} 条企业数据 | total={}",
display_page, len(rows), body.get("total"),
)
return rows
except Exception as exc:
if attempt >= self.retries:
raise
logger.warning("page={} 第 {} 次请求失败,准备重试: {}", display_page, attempt, exc)
time.sleep(0.5 * attempt)
return []
def run(self, pages: int = 3) -> List[Dict[str, Any]]:
"""顺序采集前 pages 页企业数据(pg 从 0 开始)。"""
logger.info("开始采集建筑市场企业数据 | 共 {} 页 | 每页 {} 条", pages, self.page_size)
all_rows: List[Dict[str, Any]] = []
for pg in range(0, pages):
try:
all_rows.extend(self.fetch_page(pg))
except Exception as exc:
logger.error("page={} (pg={}) 采集失败: {}", pg + 1, pg, exc)
time.sleep(0.3) # 顺序抓取,轻微间隔,降低请求频率
logger.info("采集完成,共 {} 条企业数据", len(all_rows))
return all_rows
if __name__ == "__main__":
spider = JzscCompanySpider(page_size=15, retries=3)
result = spider.run(pages=3)
for row in result:
logger.info("{}", json.dumps(row, ensure_ascii=False))2.2 Python 调用 JS 复现版本
这个版本尽量保留浏览器里扣下来的解密逻辑:jzsc_company.js 中保留前端 b 函数(这里命名为 decryptRes),只额外补上 require("./CryptoJS.js") 和 module.exports。Python 再通过 execjs 把 CryptoJS.js 和解密脚本编译成上下文调用。
需要注意的是,Windows 下 PyExecJS 默认按系统编码(GBK)读写 node 子进程,而我们的 JS 带中文注释、响应数据也含中文,直接运行会报 'gbk' codec can't decode。常见做法是把 subprocess.Popen 强制成 utf-8,但如果像 functools.partial 那样替换会破坏 asyncio 等库对 subprocess.Popen 的继承(loguru 会间接 import asyncio),因此这里改用一个强制 utf-8 的 Popen 子类,并放在 import execjs 之前。
运行方式:
bash
python jzsc_company_execjs_spider.pyJS 解密代码(jzsc_company.js)如下:
javascript
// 全国建筑市场监管公共服务平台 ------ 企业列表响应解密
//
// 逆向自 https://jzsc.mohurd.gov.cn/js/app.b72aa531.js 模块 27fe,原函数名为 b()。
// m = CryptoJS.enc.Utf8.parse("0123456789ABCDEF") -> IV
// f = CryptoJS.enc.Utf8.parse("jo8j9wGw%6HbxfFn") -> 旧版本(不带 v 头)遗留 key
// h = 231012, f = CryptoJS.enc.Utf8.parse("Dt8j9wGw%6HbxfFn") -> 覆盖为新版本 key
// 浏览器请求头固定带 v=231012,服务端返回 "55" 开头的新版本密文,因此真正生效的是
// Dt8j9wGw%6HbxfFn;jo8j9wGw%6HbxfFn 只用于不带 v 头时的旧格式("95780" 开头),这里用不到。
const CryptoJS = require("./CryptoJS.js");
// const f = CryptoJS.enc.Utf8.parse("jo8j9wGw%6HbxfFn"); // 旧版本 key(无 v 头)
const f = CryptoJS.enc.Utf8.parse("Dt8j9wGw%6HbxfFn"); // 新版本 key(v=231012)
const m = CryptoJS.enc.Utf8.parse("0123456789ABCDEF"); // IV
// 对应前端的 b(t):hex 密文 -> AES-CBC/PKCS7 解密 -> 明文 JSON 字符串
function decryptRes(t) {
const e = CryptoJS.enc.Hex.parse(t);
const n = CryptoJS.enc.Base64.stringify(e);
const a = CryptoJS.AES.decrypt(n, f, {
iv: m,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7,
});
const r = a.toString(CryptoJS.enc.Utf8);
return r.toString();
}
if (typeof module !== "undefined") {
module.exports = {
decryptRes,
};
}CryptoJS.js 为标准 CryptoJS 打包文件,直接复用即可,这里不再贴出。
Python 代码(jzsc_company_execjs_spider.py)如下:
python
# -*- coding: utf-8 -*-
"""
@File : jzsc_company_execjs_spider.py
@Author : XAMO Lab
@Date : 2026/6/30 5:54
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc : 全国建筑市场监管公共服务平台企业信息采集(execjs 调用 JS 复现 AES/CBC/PKCS7 响应解密,顺序抓取)
"""
import json
import subprocess
import sys
import time
import warnings
from pathlib import Path
from typing import Any, Dict, List
warnings.filterwarnings(
"ignore",
message=r"urllib3 .* or chardet .*charset_normalizer .* doesn't match a supported version!",
)
import requests
from loguru import logger
# Windows 下 PyExecJS 默认用系统编码(GBK)读写 node 子进程管道,
# 而 JS 源码含中文注释、响应数据含中文,会触发 'gbk' codec 解码报错。
# 这里用一个强制 utf-8 的 Popen 子类替换(保持它仍是"类",避免像 functools.partial
# 那样破坏 asyncio 等库对 subprocess.Popen 的继承),必须在 import execjs 之前完成。
class _Utf8Popen(subprocess.Popen):
def __init__(self, *args, **kwargs):
kwargs.setdefault("encoding", "utf-8")
super().__init__(*args, **kwargs)
subprocess.Popen = _Utf8Popen
import execjs
logger.remove()
logger.add(sys.stdout, level="INFO")
BASE_DIR = Path(__file__).resolve().parent
class JzscCompanyExecjsSpider:
"""全国建筑市场监管公共服务平台企业列表爬虫(Python 调用 JS 解密版本)。"""
API_URL = "https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list"
SITE_URL = "https://jzsc.mohurd.gov.cn/data/company"
V_HEADER = "231012"
# 解析输出的目标字段:统一社会信用代码 / 企业名称 / 法定代表人 / 注册属地
FIELD_MAP = {
"QY_ORG_CODE": "credit_code",
"QY_NAME": "company_name",
"QY_FR_NAME": "legal_person",
"QY_REGION_NAME": "region_name",
}
def __init__(self, page_size: int = 15, retries: int = 3, timeout: int = 30) -> None:
"""
:param page_size: 每页条数,页面默认 15
:param retries: 单页请求失败后的重试次数
:param timeout: 单次请求超时时间(秒)
"""
self.page_size = page_size
self.retries = retries
self.timeout = timeout
self.js_ctx = self._load_js_context()
self.session = requests.Session()
self.session.headers.update({
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Referer": self.SITE_URL,
# v 是接口版本号,决定服务端返回密文的加密版本,必须带上才能用新版 key 解密。
"v": self.V_HEADER,
# accessToken 实测可为空字符串,接口仍正常返回,这里保留以贴近浏览器请求。
"accessToken": "",
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/149.0.0.0 Safari/537.36"
),
})
@staticmethod
def _load_js_context() -> "execjs.ExternalRuntime.Context":
"""加载本地 CryptoJS 与解密脚本,编译成 execjs 上下文。
execjs 没有 require 机制,这里把 CryptoJS.js 直接拼接到前面,再用一个桥接语句
把它暴露成全局 CryptoJS 变量,最后去掉 jzsc_company.js 里的 require 行。
"""
cryptojs = (BASE_DIR / "CryptoJS.js").read_text(encoding="utf-8")
decrypt_code = (BASE_DIR / "jzsc_company.js").read_text(encoding="utf-8")
decrypt_code = decrypt_code.replace('const CryptoJS = require("./CryptoJS.js");', "")
bridge = 'var CryptoJS = typeof module !== "undefined" && module.exports ? module.exports : this.CryptoJS;'
return execjs.compile(f"{cryptojs}\n{bridge}\n{decrypt_code}")
def _params(self, pg: int, total: int = 0) -> Dict[str, Any]:
"""组装查询参数。pg 从 0 开始计数,total 传 0 时服务端会回填真实总数。"""
return {"pg": pg, "pgsz": self.page_size, "total": total}
def _decrypt(self, ciphertext: str) -> Dict[str, Any]:
"""调用 JS 的 decryptRes(即前端 b 函数)解密 hex 密文,再转 dict。"""
plain_text = self.js_ctx.call("decryptRes", ciphertext.strip())
return json.loads(plain_text)
def _parse_item(self, item: Dict[str, Any], page: int, index: int) -> Dict[str, Any]:
"""提取企业字段,统一输出结构。"""
row: Dict[str, Any] = {"page": page, "index": index}
for src_key, dst_key in self.FIELD_MAP.items():
row[dst_key] = item.get(src_key) or ""
return row
def fetch_page(self, pg: int, total: int = 0) -> List[Dict[str, Any]]:
"""请求单页、解密响应并返回结构化企业数据。pg 从 0 开始。"""
params = self._params(pg, total)
display_page = pg + 1
for attempt in range(1, self.retries + 1):
try:
logger.info("page={} (pg={}) 开始请求 | params={}", display_page, pg, params)
response = self.session.get(self.API_URL, params=params, timeout=self.timeout)
response.raise_for_status()
# 响应体是 hex 密文文本,不是 JSON 对象。
data = self._decrypt(response.text)
if data.get("code") != 200:
logger.warning(
"page={} 接口异常 code={} message={}",
display_page, data.get("code"), data.get("message"),
)
return []
body = data.get("data") or {}
rows = [
self._parse_item(item, display_page, idx)
for idx, item in enumerate(body.get("list") or [], 1)
]
logger.success(
"page={} 解密成功,获取 {} 条企业数据 | total={}",
display_page, len(rows), body.get("total"),
)
return rows
except Exception as exc:
if attempt >= self.retries:
raise
logger.warning("page={} 第 {} 次请求失败,准备重试: {}", display_page, attempt, exc)
time.sleep(0.5 * attempt)
return []
def run(self, pages: int = 3) -> List[Dict[str, Any]]:
"""顺序采集前 pages 页企业数据(pg 从 0 开始)。"""
logger.info("开始采集建筑市场企业数据 | 共 {} 页 | 每页 {} 条", pages, self.page_size)
all_rows: List[Dict[str, Any]] = []
for pg in range(0, pages):
try:
all_rows.extend(self.fetch_page(pg))
except Exception as exc:
logger.error("page={} (pg={}) 采集失败: {}", pg + 1, pg, exc)
time.sleep(0.3) # 顺序抓取,轻微间隔,降低请求频率
logger.info("采集完成,共 {} 条企业数据", len(all_rows))
return all_rows
if __name__ == "__main__":
spider = JzscCompanyExecjsSpider(page_size=15, retries=3)
result = spider.run(pages=3)
for row in result:
logger.info("{}", json.dumps(row, ensure_ascii=False))2.3 运行结果摘要
两种方案都已实际请求验证,均能顺序采集前 3 页,每页 15 条、共 45 条。日志摘要如下:
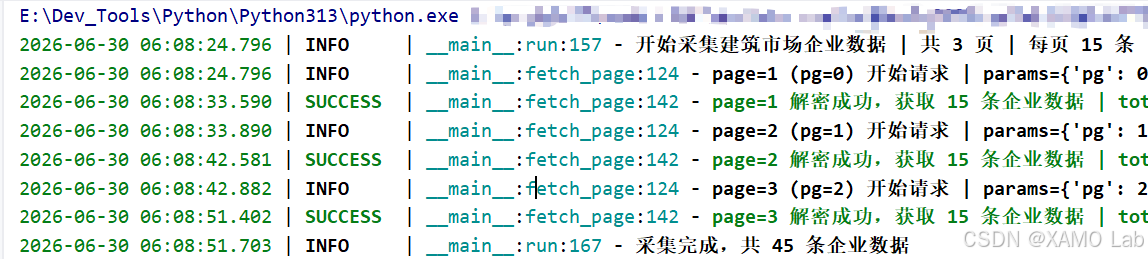
部分输出字段示例:

三、总结
这个案例的主线是先定位企业列表接口 comp/list,再处理响应密文解密。请求本身是普通 GET,分页参数明文传输,没有请求体加密;难点集中在响应解密的密钥取值上。
这里需要注意几点:
- 响应是 hex 密文,解密算法为
AES-128-CBC/Pkcs7,IV 固定为0123456789ABCDEF。 - 密钥
f在 JS 中被赋值两次,真正生效的是后赋值的Dt8j9wGw%6HbxfFn,前一个jo8j9wGw%6HbxfFn不是诱饵,而是旧版本(不带v头)遗留的 key。 - 请求头
v: 231012决定服务端返回密文的加密版本,必须带上;浏览器始终带v,故统一用新 key 解密。accessToken实测可为空。 - 分页参数
pg从 0 开始;total传 0 时服务端会回填真实总数。 - 前端
b函数里Hex.parse → Base64.stringify → AES.decrypt的来回转换,在 Python 中等价于直接unhexlify还原密文字节再解密。 - 用
execjs调 JS 复现时,Windows 下要把subprocess.Popen强制成utf-8(用子类替换,避免破坏asyncio对Popen的继承),否则会因中文触发gbk解码报错。