【深度学习入门 Day 2】从单样本到多样本:向量化训练与分类边界
本文记录深度学习学习第 2 天的内容:把昨天的单样本 sigmoid 神经元扩展到多样本训练,理解
X @ w + b、平均损失、梯度聚合X.T @ dL_dz,以及训练出来的w和b为什么对应一条分类边界。
文章目录
- 一、从单样本训练到多样本训练
- 二、多样本数据如何表示
- 三、向量化前向传播:
X @ w + b - 四、多个样本的损失怎么合并
- 五、多样本反向传播:为什么是
X.T @ dL_dz - 六、一次多样本参数更新
- 七、
w和b的几何意义:分类边界 - 八、今天的上机练习代码
- 九、今日总结
- 十、课后自测
一、从单样本训练到多样本训练
昨天我们只训练了一个样本:
python
x = np.array([2.0, 3.0])
y = 1.0模型形式是:
text
z = w1*x1 + w2*x2 + b
a = sigmoid(z)这只能说明一件事:
对于
[2, 3]这个点,让模型输出尽量接近1。
但机器学习真正要做的不是只记住一个点,而是从多个样本中学习规律。今天我们把单个输入 x 扩展为样本矩阵 X。
二、多样本数据如何表示
今天使用 4 个二维样本:
python
X = np.array([
[2.0, 3.0],
[1.0, 1.0],
[3.0, 4.0],
[0.0, 2.0],
])
y = np.array([1.0, 0.0, 1.0, 0.0])其中:
text
X.shape = (4, 2)
y.shape = (4,)含义是:
text
4 个样本
每个样本 2 个特征
每个样本对应 1 个标签参数仍然是:
python
w = np.array([0.5, -1.0])
b = 1.0因为每个样本有 2 个特征,所以权重 w 有 2 个分量。
三、向量化前向传播:X @ w + b
单样本时:
python
z = np.dot(w, x) + b多样本时:
python
z = X @ w + b形状关系是:
text
X.shape = (4, 2)
w.shape = (2,)
z.shape = (4,)语义上,z 是 4 个样本各自的线性输出:
text
z = [z1, z2, z3, z4]代入初始参数:
text
样本1: z1 = 2*0.5 + 3*(-1) + 1 = -1
样本2: z2 = 1*0.5 + 1*(-1) + 1 = 0.5
样本3: z3 = 3*0.5 + 4*(-1) + 1 = -1.5
样本4: z4 = 0*0.5 + 2*(-1) + 1 = -1所以:
text
z = [-1, 0.5, -1.5, -1]经过 sigmoid:
text
a = sigmoid(z) ≈ [0.269, 0.622, 0.182, 0.269]对应标签:
text
y = [1.000, 0.000, 1.000, 0.000]当前预测情况:
text
样本1:预测 0.269,标签 1,偏低,希望输出变大
样本2:预测 0.622,标签 0,偏高,希望输出变小
样本3:预测 0.182,标签 1,偏低,希望输出变大
样本4:预测 0.269,标签 0,偏高,希望输出变小这就是多样本训练和单样本训练的本质差别:
同一组参数要同时照顾多个样本,最终更新方向是多个样本意见的综合。
四、多个样本的损失怎么合并
单样本平方损失:
text
L = (a - y)^2多样本时通常取平均:
python
loss = np.mean((a - y) ** 2)数学上可以写成:
text
loss = 1/N * Σ(ai - yi)^2其中 N 是样本数量。
为什么要取平均?
因为我们希望优化的是整体效果,而不是只服务某一个样本。如果只看单个样本,参数可能朝着对其他样本更差的方向更新。
五、多样本反向传播:为什么是 X.T @ dL_dz
平方损失下,反向传播可以写成:
python
N = len(y)
dL_da = 2 * (a - y) / N
da_dz = a * (1 - a)
dL_dz = dL_da * da_dz这里的 dL_dz 是每个样本对 z 的梯度信号:
text
dL_dz.shape = (4,)近似计算得到:
text
dL_dz ≈ [-0.072, 0.073, -0.061, 0.027]符号含义:
text
负数:希望对应样本的 z 变大
正数:希望对应样本的 z 变小权重梯度是:
python
dL_dw = X.T @ dL_dz形状关系:
text
X.shape = (4, 2)
X.T.shape = (2, 4)
dL_dz.shape = (4,)
dL_dw.shape = (2,)也就是得到:
text
[dL/dw1, dL/dw2]具体展开:
text
X 第一列 = [2, 1, 3, 0]
X 第二列 = [3, 1, 4, 2]所以:
text
dL/dw1 = 2*dL_dz1 + 1*dL_dz2 + 3*dL_dz3 + 0*dL_dz4
dL/dw2 = 3*dL_dz1 + 1*dL_dz2 + 4*dL_dz3 + 2*dL_dz4这就是 X.T @ dL_dz 的核心含义:
把每个样本的误差信号,按照每个特征列加权汇总,得到每个权重的梯度。
偏置梯度更简单:
python
dL_db = np.sum(dL_dz)因为每个样本的 z 都加了同一个 b,所以偏置梯度就是所有样本误差信号的总和。
六、一次多样本参数更新
近似有:
text
dL_dz ≈ [-0.072, 0.073, -0.061, 0.027]计算 w1 梯度:
text
dL/dw1 = 2*(-0.072) + 1*(0.073) + 3*(-0.061) + 0*(0.027)
= -0.144 + 0.073 - 0.183 + 0
≈ -0.254计算 w2 梯度:
text
dL/dw2 = 3*(-0.072) + 1*(0.073) + 4*(-0.061) + 2*(0.027)
= -0.216 + 0.073 - 0.244 + 0.054
≈ -0.333计算 b 梯度:
text
dL/db = -0.072 + 0.073 - 0.061 + 0.027
≈ -0.033设学习率:
text
lr = 0.1初始参数:
text
w1 = 0.5
w2 = -1
b = 1更新:
text
w1_new = 0.5 - 0.1*(-0.254) = 0.5254
w2_new = -1 - 0.1*(-0.333) = -0.9667
b_new = 1 - 0.1*(-0.033) = 1.0033注意:w2 从 -1 变成 -0.9667 也是变大,因为它没有那么负了。
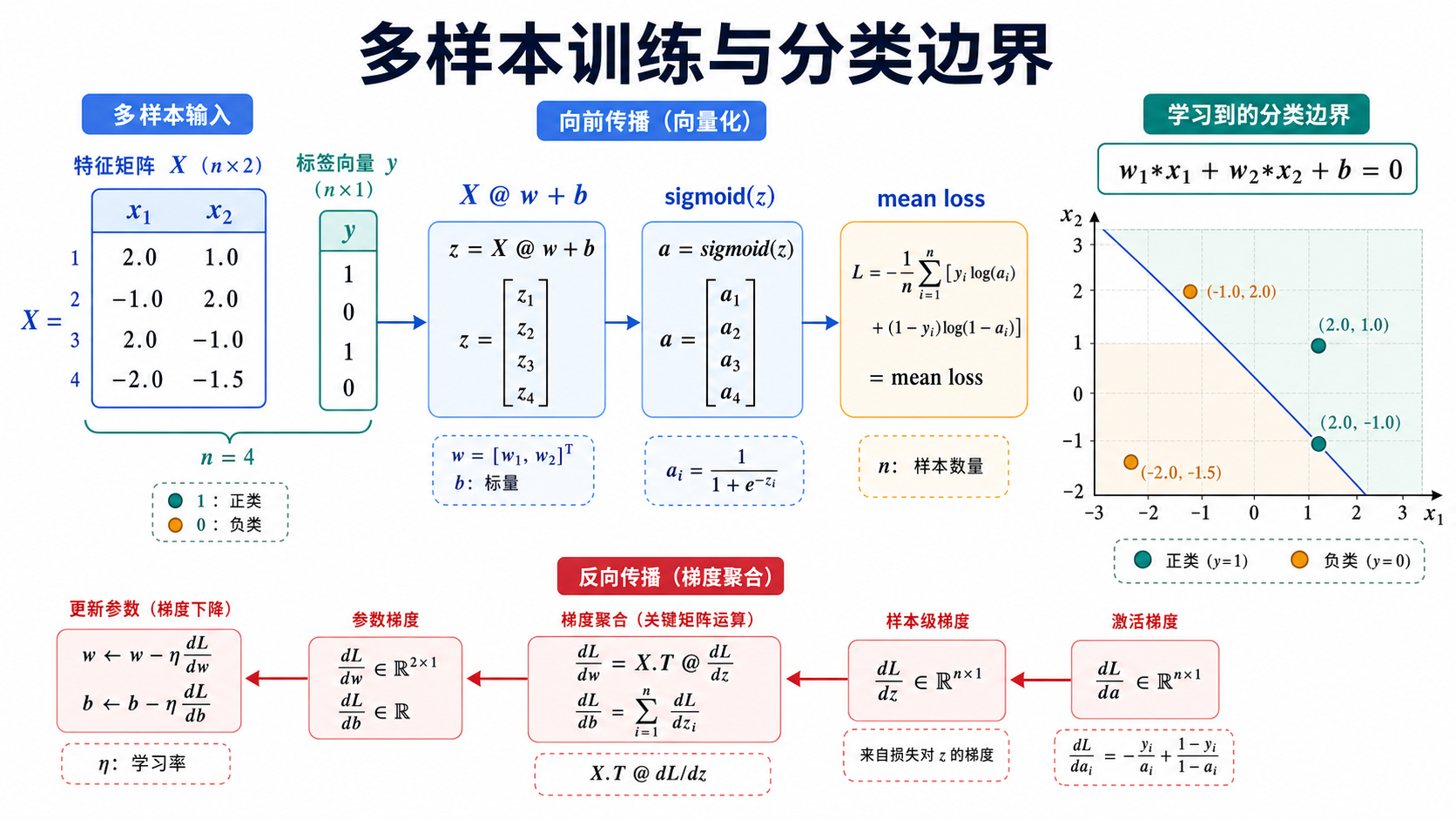
七、w 和 b 的几何意义:分类边界
对于二维输入:
text
z = w1*x1 + w2*x2 + b预测规则是:
text
z > 0 -> sigmoid(z) > 0.5 -> 预测 1
z = 0 -> sigmoid(z) = 0.5 -> 在边界上
z < 0 -> sigmoid(z) < 0.5 -> 预测 0因此分类边界是:
text
w1*x1 + w2*x2 + b = 0这是一条直线。
把它改写成 x2 = k*x1 + c 的形式:
text
w2*x2 = -w1*x1 - b
x2 = -(w1/w2)*x1 - b/w2所以:
text
斜率 = -w1 / w2
截距 = -b / w2这里要注意:
b不是斜率。w1和w2决定直线方向,b控制直线整体平移。
举例,初始参数:
text
w1 = 0.5
w2 = -1
b = 1分类边界:
text
0.5*x1 - x2 + 1 = 0
x2 = 0.5*x1 + 1对于点 [3, 4]:
text
边界上的 x2 = 0.5*3 + 1 = 2.5
实际 x2 = 4它在直线上方。但是否预测为 1,不能只看"上方"两个字,还要看 z 的符号:
text
z = 0.5*3 - 4 + 1 = -1.5 < 0所以初始模型预测为 0。
一个可以分开这组数据的边界是:
text
x1 + x2 - 4 = 0对应:
text
w = [1, 1]
b = -4检查:
text
[2, 3]: 2+3-4 = 1 -> 预测 1
[3, 4]: 3+4-4 = 3 -> 预测 1
[1, 1]: 1+1-4 = -2 -> 预测 0
[0, 2]: 0+2-4 = -2 -> 预测 0所以训练的目标可以理解为:
找到一组
w和b,让正类和负类尽量落在分类边界的不同侧。
八、今天的上机练习代码
python
import numpy as np
# 4 个样本,每个样本 2 个特征
X = np.array([
[2.0, 3.0],
[1.0, 1.0],
[3.0, 4.0],
[0.0, 2.0],
])
# 标签:1 表示正类,0 表示负类
y = np.array([1.0, 0.0, 1.0, 0.0])
# 初始化参数
w = np.array([0.5, -1.0])
b = 1.0
lr = 0.1
def sigmoid(z):
return 1 / (1 + np.exp(-z))
for step in range(101):
# forward
z = X @ w + b
a = sigmoid(z)
loss = np.mean((a - y) ** 2)
# backward
N = len(y)
dL_da = 2 * (a - y) / N
da_dz = a * (1 - a)
dL_dz = dL_da * da_dz
dL_dw = X.T @ dL_dz
dL_db = np.sum(dL_dz)
# update
w = w - lr * dL_dw
b = b - lr * dL_db
if step % 10 == 0:
pred = (a >= 0.5).astype(int)
print(
f"step={step:03d}, "
f"loss={loss:.6f}, "
f"a={np.round(a, 3)}, "
f"pred={pred}, "
f"w={np.round(w, 4)}, "
f"b={b:.4f}"
)重点观察:
text
loss 是否下降
a 是否逐渐靠近 y
pred 是否从错误变正确
w 和 b 如何变化尤其要盯住这行:
python
dL_dw = X.T @ dL_dz它是多样本训练从"逐样本计算"走向"矩阵化计算"的关键。
九、今日总结
今天的核心内容可以压缩成 4 点:
- 单样本输入
x扩展为多样本矩阵X。 - 前向传播从
np.dot(w, x) + b变成X @ w + b。 - 多样本梯度通过
X.T @ dL_dz聚合。 - 二维 sigmoid 神经元学到的
w和b对应一条分类直线。
最终要记住这句话:
多样本训练不是让某一个点输出正确,而是找到一组参数,让整体平均损失下降,并让不同类别尽量落在分类边界的不同侧。
十、课后自测
- 为什么
X @ w + b的结果是 4 个z,而不是 1 个? X.T @ dL_dz为什么能得到[dL/dw1, dL/dw2]?- 为什么
w1*x1 + w2*x2 + b = 0是分类边界? b是斜率吗?如果不是,斜率和截距分别是什么?- 如果
z = -2,sigmoid 输出大于 0.5 还是小于 0.5?预测为哪一类?