前言
传统爬虫要么要手写一堆复杂 DOM 选择器,页面结构一改代码直接报废;纯 AI 提取又拿不到网页真实渲染后的完整内容。今天给大家一套方案:Puppeteer 无头浏览器爬取完整页面 + AI 自动解析 HTML,不用死磕选择器,页面改版也不用大幅改代码,几行 JS 就能全自动抓取全套信息,还能一键导出本地 JSON 文件。
一、什么是爬虫?有什么方法?
爬虫本质就是批量拉取网页 / 服务器数据,分两大路线:
- 接口直爬:直接请求后端 API 拿 JSON 数据,速度最快,但很多网站会加密接口、做鉴权拦截;
- 网页渲染爬虫(本文方案) :模拟真实浏览器打开页面,等待 JS、动态列表完全加载后,再拿完整 HTML 源码。
二、实战爬虫:获取文章榜信息
咱们就直接拿掘金的文章榜举例,实现爬取掘金文章榜的信息。
步骤 1:环境准备与配置文件
项目根目录新建.env.local文件,存放 AI 大模型密钥配置:
env
OPENAI_API_KEY=Your_API_Key
OPENAI_BASE_URL=Your_API_Base_URL
OPENAI_MODEL=Your_API_Model填入你自己的大模型接口密钥、中转地址、模型名称。
步骤 2:爬虫完整核心代码
采用 ES Module 模块化写法,自动读取环境变量、启动无头浏览器、爬取页面、AI 解析、本地存文件,完整代码如下,每一行都带详细注释:
JavaScript
import dotenv from 'dotenv' // 读取本地.env环境变量
import path from 'path' // node内置路径处理模块
import { fileURLToPath } from 'url'
import { createCrawl, createCrawlOpenAI } from 'x-crawl' // 封装好的爬虫、AI解析工具包 x-crawl
import fs from 'fs' // node内置文件读写模块
// 加载.env.local环境配置文件,兼容ES Module __dirname缺失问题
dotenv.config({
path: path.join(
path.dirname(fileURLToPath(import.meta.url)),
'..',
'.env.local'
)
})
// 从环境变量读取AI接口配置
const apiKey = process.env['OPENAI_API_KEY'];
const baseURL = process.env['OPENAI_BASE_URL'];
const model = process.env['OPENAI_MODEL'];
// 初始化爬虫实例,内置Puppeteer浏览器内核
const crawlApp = createCrawl();
// 主爬虫执行函数
async function main() {
// 掘金热榜目标页面 + 自定义抓取条数上限
const url = 'https://juejin.cn/hot/articles';
const limit = 50;
console.log(`准备打开页面:${url}`);
// 无头浏览器访问目标网页,拿到页面、浏览器操控对象
const res = await crawlApp.crawlPage(url);
const { page, browser } = res.data;
// 等待文章列表DOM渲染完成,最长等待20秒,防止网络慢加载不全
await page.waitForSelector('.article-item-link', { timeout: 20000 });
// 提取热榜列表整块完整HTML源码,后续交给AI解析
const targetHTML = await page.$eval('.hot-list', (el) => el.outerHTML);
// 判断是否配置AI密钥,有密钥才启用AI自动解析数据
if (apiKey) {
// 初始化AI解析实例,注入大模型接口信息
const crawlOpenAIAPP = createCrawlOpenAI({
clientOptions: { apiKey, baseURL },
defaultModel: {
chatModel: model,
}
});
// 核心:AI自动从HTML中提取我们指定的字段,不用手写选择器!
const aiResult = await crawlOpenAIAPP.parseElements(
targetHTML,
`这是掘金文章热榜列表,需要获取每条文章的以下信息。严格使用括号内英文作为返回对象属性名:
- 排名(rank)
- 标题(title)
- 文章链接(url),需要补全完整域名https://juejin.cn/xxx
- 作者名称(author)
- 作者链接(author_url),需要补全完整域名https://juejin.cn/xxx
- 热度值(heat)
- 浏览量(views)
- 互动数(interactions)
- 收藏数(collections)`
);
// 爬取解析完成,关闭浏览器释放内存
await browser.close();
// 将AI提取好的结构化数据,写入本地JSON文件,时间戳命名避免覆盖
fs.writeFileSync(`./juejin_hot_${Date.now()}.json`, JSON.stringify(aiResult, null, 2), 'utf-8');
console.log('✅ 掘金热榜数据抓取完成,JSON文件已保存到本地!');
} else {
// 未配置AI密钥时兜底逻辑
console.log('未检测到AI接口密钥,仅获取到页面HTML源码:');
console.log(targetHTML);
await browser.close();
}
}
// 启动爬虫主函数
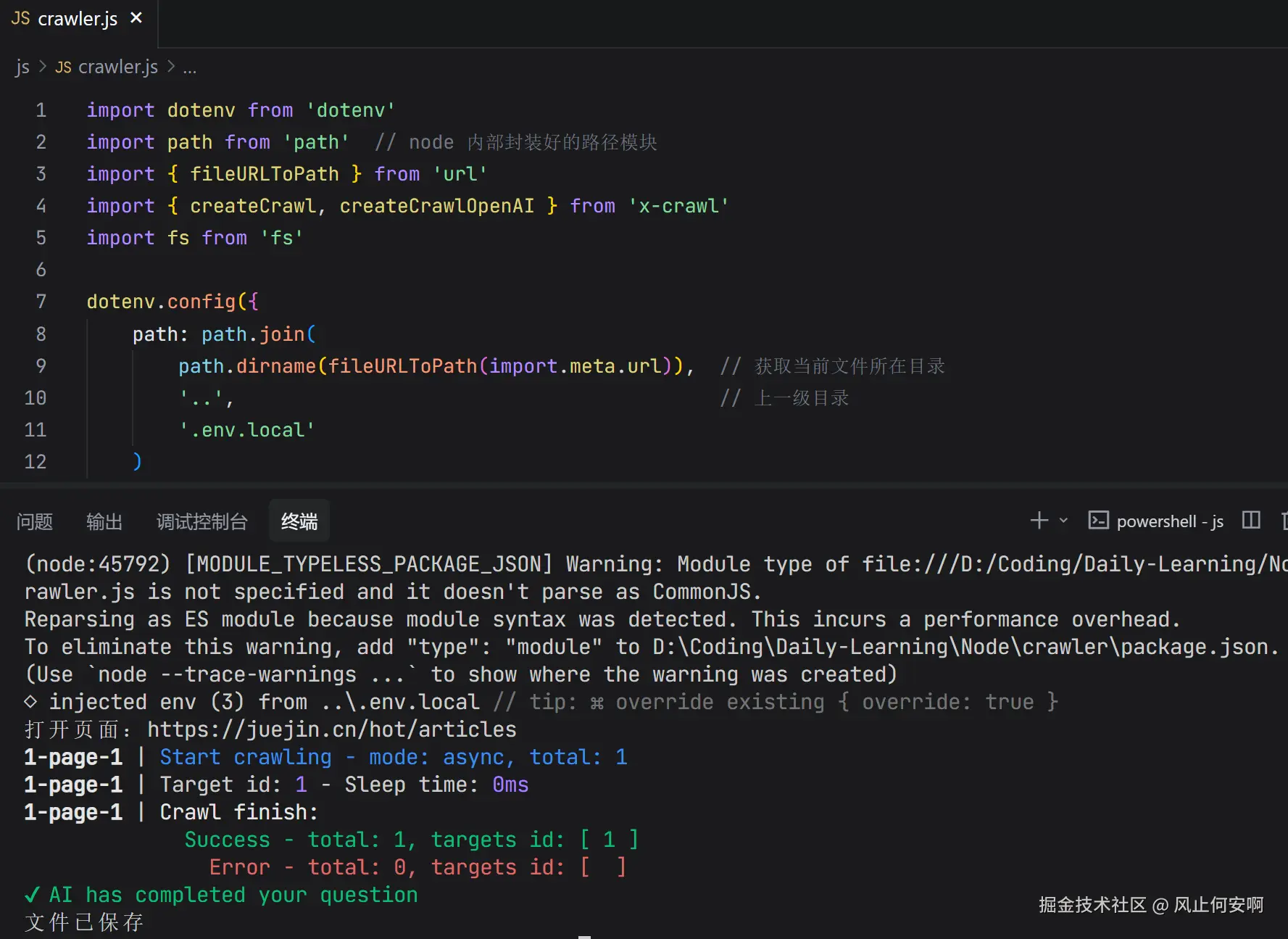
main();在终端运行这个文件就可以得到图片的效果:
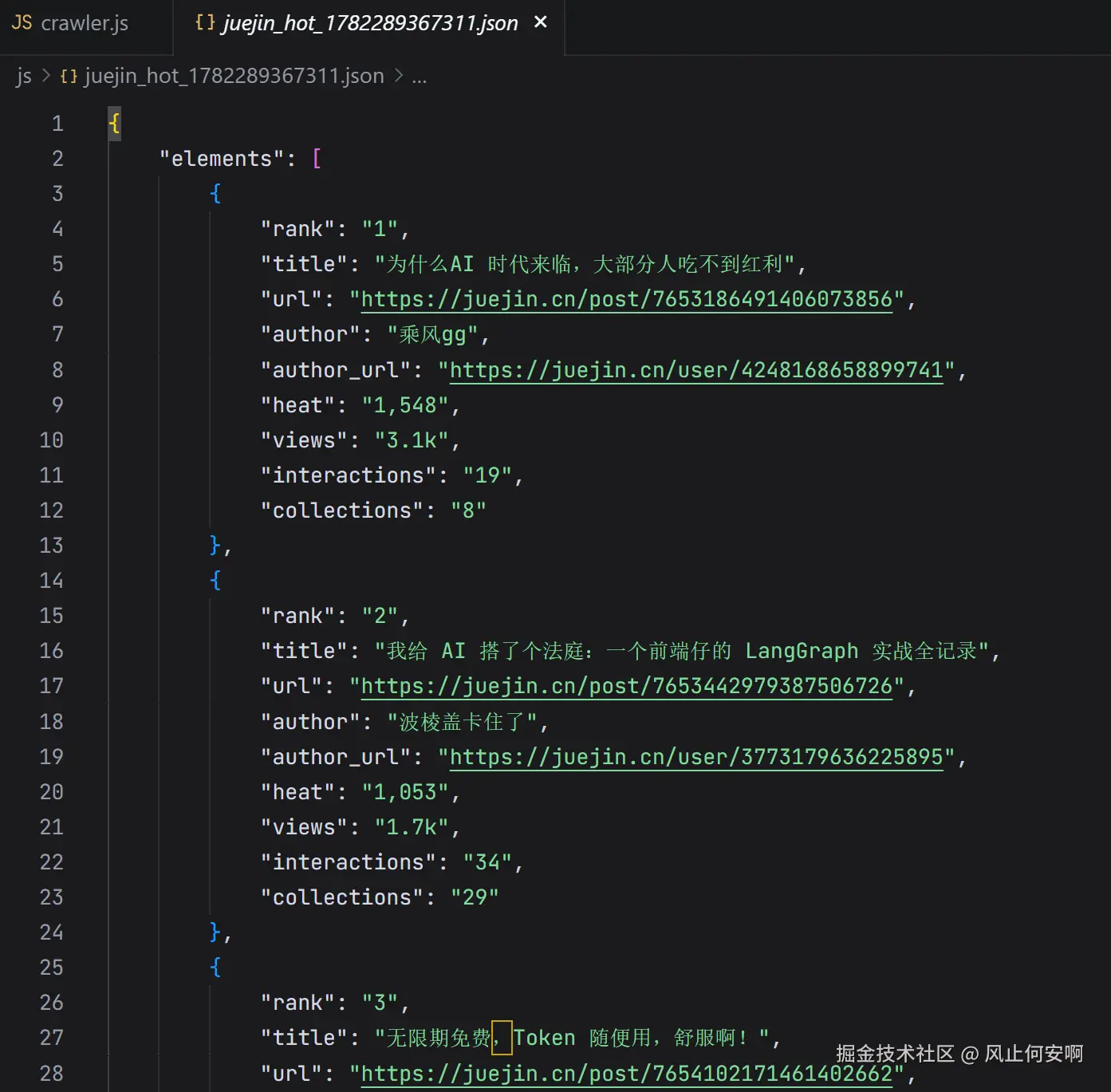
然后文件夹里多了一个json文件,完全对应文章榜的内容:
步骤 3:代码运行流程拆解,看懂每一步在干嘛
-
环境变量加载 :ES Module 中没有传统
__dirname,用fileURLToPath拿到当前文件真实路径,精准读取上级目录的.env.local,密钥不硬编码在代码里,安全规范 -
爬虫实例初始化 :
createCrawl封装 Puppeteer,自动安装浏览器内核,不用手动配置 Chromium -
模拟真人访问网页 :
crawlPage启动无头浏览器打开掘金,等待动态列表渲染完毕,避免拿到空白 HTML -
提取目标区块 HTML :精准截取热榜容器
.hot-list的完整源码,减少 AI 无效文本消耗 -
AI 智能解析 HTML:把整块 HTML + 我们自定义的字段需求丢给大模型,AI 自动识别每条文章对应数据,输出标准 JSON 数组
-
本地持久化存储 :Node 内置
fs模块直接写入本地文件,时间戳命名,每次抓取生成独立文件,不会覆盖历史数据
结语
可能有些前端朋友觉得爬虫是后端专属技能,其实依托 Node.js,我们写 JS 就能搞定网页数据抓取,再搭配大模型 AI,直接解决传统爬虫最头疼的页面适配、数据清洗问题。