1. 主控层
主控层 (Controller Driver):"即控制器驱动注册"。
"作为内核 SPI 子系统的核心执行引擎,主控层驱动负责将上层抽象出的标准化数据请求(spi_message)转化为底层硬件可解析的指令序列;它既是通信协议的'配置者',也是数据流的'调度指挥官',通过对物理寄存器、DMA 通道及中断系统的实时操控,确保数据在内存缓冲区与物理总线之间实现稳定、高效、有序的闭环传输。"
职责逻辑拆解(从抽象到具体)
为了清晰展示这种结合,我们可以将其分为三个层级:
-
承接层:标准化转译
输入:
从 SPI Core 接收标准化的 spi_message。
动作:
驱动需要根据特定 SoC 的特性,将这些通用的数据包进行拆解。它不仅是简单的参数配置(时钟、模式、位宽),更是将这些逻辑要求映射为物理链路的初始化设定。
-
执行层:物理世界的控制
通道掌控:
主控层是唯一直接接触"物理引脚"的层级。它负责激活片选信号(CS)、配置时钟(SCK)频率,并确保 MOSI/MISO 引脚的电平跳变严格遵循 SPI 时序。
物理搬运:
这是核心职责------它通过 spi_imx_push(PIO 模式)或配置 DMA Engine,亲手将内存中数据从"虚拟的内核缓冲区"推送到"硬件物理 FIFO"中,完成数据从逻辑到电流的转换。
-
监控层:闭环反馈
动态响应:
利用硬件中断(如 MXC_INT_TE 和 MXC_INT_RR)建立反馈闭环。它不是一次性发送完毕,而是实时监测硬件状态,一旦 FIFO 出现空间(空闲或就绪),立即调度执行下一次搬运。
异常防御:
实时监控传输时序,一旦出现总线超时、FIFO 溢出或 DMA 传输故障,驱动需立即执行硬件复位,确保通信链路的健壮性。
读者在阅读完后续的代码研究之后再回过头来看就能看懂了
主控层驱动所承担的'翻译、搬运与监控'职责,在 Linux 内核中是通过 struct spi_controller 结构体中的函数指针(如 transfer_one)这一契约机制,被强制要求落地的。
-
契约的定义(SPI Core 的立场)
SPI Core 作为抽象层,它定义了"主控层必须做什么"(即你整理的职责):
它不知道 i.MX6ULL 是怎么操作 FIFO 的。
但它定义了一个通用模板 struct spi_controller,并要求任何一个 SPI 主机驱动(如 spi-imx.c)在注册时,必须填入这个模板里的函数指针(如 transfer_one)。
-
实现的落地(主控层的具体职责)
当 spi-imx.c 填入函数指针的那一刻,它就正式承接了你整理出的那三大职责:
承接层(翻译):Core 调用 transfer_one,将 spi_message 传给 spi_imx_transfer。此时,"职责"开始了,驱动开始将标准数据包转化为特定的寄存器配置。
执行层(搬运):驱动内部通过填充 txfifo 和控制物理引脚,具体实现了"搬运数据到硬件 FIFO"的物理操作。
监控层(反馈):通过注册中断服务程序 spi_imx_isr,驱动利用中断机制回应 Core 的调用要求。
在 drivers/spi/spi.c(抽象层/SPI Core)中,它无法直接调用一个叫 transfer_one 的函数,因为 spi.c 根本不知道将来会有哪些具体的硬件驱动。
SPI Core 的立场 :它只知道 struct spi_master(在旧内核中)或 struct spi_controller(在新内核中)这个结构体里一定有一个叫 transfer_one 的成员变量。
接口的本质:这是一个函数指针。SPI Core 调用的是这个指针指向的地址,而不是硬编码的函数名。
综上,我们要研究的应该是开发板自身的具体函数,由于我们所用来研究的开发板是 imx6ull ,所以进入 spi-imx.c 查看:
c
static int spi_imx_transfer(struct spi_device *spi,
struct spi_transfer *transfer)
{
struct spi_imx_data *spi_imx = spi_master_get_devdata(spi->master);
if (spi_imx->usedma)
return spi_imx_dma_transfer(spi_imx, transfer);
else
return spi_imx_pio_transfer(spi, transfer);
}在这个函数里面添加日志信息,查看其调用链
8.552323 inv-mpu6000-spi spi2.0: spi_imx_transfer: transfer length=2
8.564071 CPU: 0 PID: 188 Comm: udevd Not tainted 4.9.88 #17
8.564081 Hardware name: Freescale i.MX6 UltraLite (Device Tree)
8.564121 \<80112a34\> (unwind_backtrace) from \<8010dc2c\> (show_stack+0x20/0x24)
8.564142 \<8010dc2c\> (show_stack) from \<80469964\> (dump_stack+0x80/0x94)
8.564163 \<80469964\> (dump_stack) from \<8066aa5c\> (spi_imx_transfer+0x3c/0x2a8)
8.564181 \<8066aa5c\> (spi_imx_transfer) from \<80667e98\> (spi_bitbang_transfer_one+0x60/0xb0)
8.564197 \<80667e98\> (spi_bitbang_transfer_one) from \<806668a4\> (spi_transfer_one_message+0x1d4/0x558)
8.564212 \<806668a4\> (spi_transfer_one_message) from \<80666ff4\> (__spi_pump_messages+0x3cc/0x73c)
8.564226 \<80666ff4\> (__spi_pump_messages) from \<80667530\> (__spi_sync+0x1a8/0x25c)
8.564239 \<80667530\> (__spi_sync) from \<80667638\> (spi_sync+0x54/0x6c)
8.564257 \<80667638\> (spi_sync) from \<805c9024\> (regmap_spi_write+0x80/0x88)
8.564274 \<805c9024\> (regmap_spi_write) from \<805c3ad8\> (_regmap_raw_write+0x39c/0x934)
8.564289 \<805c3ad8\> (_regmap_raw_write) from \<805c40ec\> (_regmap_bus_raw_write+0x7c/0xa4)
8.564303 \<805c40ec\> (_regmap_bus_raw_write) from \<805c2a78\> (_regmap_write+0x70/0x164)
8.564316 \<805c2a78\> (_regmap_write) from \<805c4400\> (regmap_write+0x4c/0x6c)
8.564347 \<805c4400\> (regmap_write) from \<7f04230c\> (inv_mpu6050_set_power_itg+0x6c/0x98 inv_mpu6050)
8.564379 \<7f04230c\> (inv_mpu6050_set_power_itg inv_mpu6050) from \<7f042e8c\> (inv_mpu_core_probe+0x28c/0x3d4 inv_mpu6050)
8.564410 \<7f042e8c\> (inv_mpu_core_probe inv_mpu6050) from \<7f049100\> (inv_mpu_probe+0x68/0x98 inv_mpu6050_spi)
8.564432 \<7f049100\> (inv_mpu_probe inv_mpu6050_spi) from \<80664210\> (spi_drv_probe+0x8c/0xb8)
8.564448 \<80664210\> (spi_drv_probe) from \<805a1f38\> (driver_probe_device+0x214/0x450)
8.564463 \<805a1f38\> (driver_probe_device) from \<805a2284\> (__driver_attach+0x110/0x12c)
8.564482 \<805a2284\> (__driver_attach) from \<8059fce8\> (bus_for_each_dev+0x5c/0xac)
8.564498 \<8059fce8\> (bus_for_each_dev) from \<805a17a4\> (driver_attach+0x2c/0x30)
8.564512 \<805a17a4\> (driver_attach) from \<805a123c\> (bus_add_driver+0x1d0/0x274)
8.564527 \<805a123c\> (bus_add_driver) from \<805a3038\> (driver_register+0x88/0x104)
8.564542 \<805a3038\> (driver_register) from \<8066413c\> (__spi_register_driver+0x84/0x88)
8.564562 \<8066413c\> (__spi_register_driver) from \<7f04b020\> (inv_mpu_driver_init+0x20/0x24 inv_mpu6050_spi)
8.564585 \<7f04b020\> (inv_mpu_driver_init inv_mpu6050_spi) from \<80101cc4\> (do_one_initcall+0x54/0x180)
8.564604 \<80101cc4\> (do_one_initcall) from \<801ffc58\> (do_init_module+0x74/0x1f4)
8.564624 \<801ffc58\> (do_init_module) from \<801b84c4\> (load_module+0x1f98/0x2620)
8.564641 \<801b84c4\> (load_module) from \<801b8dc0\> (SyS_finit_module+0xc4/0xfc)
8.564657 \<801b8dc0\> (SyS_finit_module) from \<80109280\> (ret_fast_syscall+0x0/0x48)
| 执行阶段 | 函数名 | 职责细节 |
|---|---|---|
| 1. 业务意图层 | inv_mpu6050_set_power_itg |
策略决策 :决定"我要给传感器上电"。它不关心 SPI,只关心寄存器 0x6B(电源管理)的值。 |
| 2. 协议抽象层 | regmap_write |
协议封装 :将简单的"写"操作格式化。它负责判断:这次操作是走 I2C 还是 SPI?如果是 SPI,就打包成 spi_message。 |
| 3. 通讯桥接层 | spi_sync |
接口入口 :这是 SPI 子系统的标准入口。它将异步的写入请求转化为同步等待,通过 wait_for_completion 阻塞当前进程。 |
| 4. 队列调度层 | spi_transfer_one_message |
排队与拆解:如果总线上同时有多个设备请求,它负责公平调度。并将一个完整消息(message)拆解为一个个具体的传输单元(transfer)。 |
| 5. 位处理适配层 | spi_bitbang_transfer_one |
模式适配:这是一个中间件,负责处理复杂的位宽转换、相位极性,并判断底层驱动是否已准备就绪。 |
| 6. 物理执行层 | spi_imx_transfer |
最终执行者 :调用 spi_imx_pio_transfer 或 DMA,直接操作 i.MX6ULL 物理寄存器(如 ECSPI_TXDATA)。 |
调用栈中的 spi_imx_transfer 就是对上述"职位描述"的响应。当你看到 spi_transfer_one_message 调用 spi_imx_transfer 时,这正是内核通过函数指针在调用主控层接口。
根据是否启用 dma 使用两种不同的函数进行数据传输
1.1 spi_imx_pio_transfer
c
static int spi_imx_pio_transfer(struct spi_device *spi,
struct spi_transfer *transfer)
{
/* 获取私有数据结构体,其中包含了寄存器基地址、状态机等信息 */
struct spi_imx_data *spi_imx = spi_master_get_devdata(spi->master);
unsigned long transfer_timeout;
unsigned long timeout;
/* 1. 初始化传输状态:记录待发送和待接收的缓冲区指针及剩余长度 */
spi_imx->tx_buf = transfer->tx_buf;
spi_imx->rx_buf = transfer->rx_buf;
spi_imx->count = transfer->len;
spi_imx->txfifo = 0; // 记录当前已经推入 FIFO 的数据量
/* 2. 重置完成量 (completion):这是核心机制,用于实现传输同步 */
reinit_completion(&spi_imx->xfer_done);
/* 3. 推入首批数据到硬件 FIFO:触发第一次数据传输 */
spi_imx_push(spi_imx);
/* 4. 配置中断控制:开启发送完成中断 (MXC_INT_TE - Transmit Empty) */
/* 当硬件 FIFO 变空时,会触发中断,进而唤醒下面的等待 */
spi_imx->devtype_data->intctrl(spi_imx, MXC_INT_TE);
/* 5. 计算超时时间:根据传输字节数计算一个合理的等待时长 */
transfer_timeout = spi_imx_calculate_timeout(spi_imx, transfer->len);
/* 6. 等待传输完成:
* 该函数会让当前进程进入睡眠状态,直到 ISR 中断处理函数调用
* complete(&spi_imx->xfer_done) 将其唤醒,或者超时退出。
*/
timeout = wait_for_completion_timeout(&spi_imx->xfer_done,
transfer_timeout);
/* 7. 错误检查:如果超时则说明硬件无响应 */
if (!timeout) {
dev_err(&spi->dev, "I/O Error in PIO\n");
spi_imx->devtype_data->reset(spi_imx); // 重置 SPI 控制器状态
return -ETIMEDOUT;
}
/* 8. 返回成功:返回本次实际传输的字节数 */
return transfer->len;
}
- spi_imx->tx_buf = transfer->tx_buf;
含义:保存"源数据"的起始地址。
为什么要保存?
transfer 结构体是由上层临时创建的,传输完成后可能会被销毁。
驱动需要保存这个指针,这样当后续发生中断时,驱动才能知道从内存的哪个位置开始读取数据来填充 FIFO。- spi_imx->rx_buf = transfer->rx_buf;
含义:保存"接收缓冲区"的起始地址。
为什么要保存?
当 SPI 硬件从外部接收数据时,它会把数据送到 FIFO。驱动程序必须知道这些数据应该存放在内存的哪个位置(rx_buf)才不会出错。- spi_imx->count = transfer->len;
含义:保存"剩余传输字节数"。
为什么要保存?
这是最关键的指针/计数器。在 SPI 传输过程中,硬件 FIFO 容量有限(比如只有 64 字节),但 transfer->len 可能是 1024 字节。
驱动无法一次性把所有数据发完。因此,count 作为剩余数据量的计数器,每次中断触发时,驱动都会从这里减去已经发出去的字节数。当 count 减为 0 时,说明传输结束。- spi_imx->txfifo = 0;
含义:重置当前推入 FIFO 的计数器。
为什么要重置?
这是一个"本次传输的局部计数器"。
在某些实现中,驱动用它来记录"当前已经推入硬件 FIFO,但还没被硬件真正发送出去"的数据量,用来防止 FIFO 溢出。每次启动一个新传输,都要清零,从头开始算。
c
static void spi_imx_push(struct spi_imx_data *spi_imx)
{
/* 1. FIFO 填充循环:判断当前 FIFO 没满(spi_imx->txfifo < 最大容量) */
while (spi_imx->txfifo < spi_imx_get_fifosize(spi_imx)) {
/* 2. 数据总量判断:如果剩余要发送的 count 已经归零,说明任务完成,跳出循环 */
if (!spi_imx->count)
break;
/* 3. 调用发送函数:这里调用了函数指针 spi_imx->tx() */
/* 这个 tx() 指针指向的是具体负责转换数据位宽(8位/16位/32位)的函数 */
spi_imx->tx(spi_imx);
/* 4. 更新计数器:增加 txfifo 计数,表示又往硬件 FIFO 里塞入了一个单位的数据 */
spi_imx->txfifo++;
}
/* 5. 硬件触发:执行具体的"启动传输"操作 */
/* 这里的 trigger 指向的是具体 SoC 的控制寄存器,用来正式开启传输电平脉冲 */
spi_imx->devtype_data->trigger(spi_imx);
}要找到 tx 函数指针具体指向的实现函数,最好的方法不是搜索 tx(因为 tx 是一个成员变量名,到处都是),而是去寻找 "赋值" 的代码。
在 C 语言的驱动开发中,函数指针的赋值通常发生在驱动的初始化阶段。对于 spi-imx.c,你可以查找:
tx =
c
static int spi_imx_setupxfer(struct spi_device *spi,
struct spi_transfer *t)
{
struct spi_imx_data *spi_imx = spi_master_get_devdata(spi->master);
struct spi_imx_config config;
int ret;
/* 1. 确定传输参数:优先使用本次传输请求(t)中的参数,若为空则使用设备(spi)的默认配置 */
config.bpw = t ? t->bits_per_word : spi->bits_per_word;
config.speed_hz = t ? t->speed_hz : spi->max_speed_hz;
/* 2. 参数兜底:确保 bpw(位宽)和 speed_hz(频率)不为零,防止配置错误 */
if (!config.speed_hz)
config.speed_hz = spi->max_speed_hz;
if (!config.bpw)
config.bpw = spi->bits_per_word;
/* 3. 核心:函数指针绑定(适配器模式) */
/* 根据位宽(bpw)动态选择发送(tx)和接收(rx)数据的底层函数 */
/* 这样做是为了在传输时能够根据位宽高效地读写寄存器 */
if (config.bpw <= 8) {
spi_imx->rx = spi_imx_buf_rx_u8;
spi_imx->tx = spi_imx_buf_tx_u8;
} else if (config.bpw <= 16) {
spi_imx->rx = spi_imx_buf_rx_u16;
spi_imx->tx = spi_imx_buf_tx_u16;
} else {
spi_imx->rx = spi_imx_buf_rx_u32;
spi_imx->tx = spi_imx_buf_tx_u32;
}
/* 4. DMA 模式判断:判断当前传输是否满足 DMA 使用条件 */
if (spi_imx_can_dma(spi_imx->bitbang.master, spi, t))
spi_imx->usedma = 1;
else
spi_imx->usedma = 0;
/* 5. 若使用 DMA,配置 DMA 通道及传输字节数 */
if (spi_imx->usedma) {
ret = spi_imx_dma_configure(spi->master,
spi_imx_bytes_per_word(config.bpw));
if (ret)
return ret;
}
/* 6. 最终生效:调用硬件相关的配置函数,将速率、模式等信息写入具体 SoC 的物理寄存器 */
spi_imx->devtype_data->config(spi, &config);
return 0;
}然而直接搜索 spi_imx_buf_rx_u8,spi_imx_buf_rx_u16,spi_imx_buf_rx_u32会发现搜索不到函数的定义,这个时候我们可以考虑是否因为函数逻辑几乎相同,而使用了宏进行定义。
c
#define MXC_SPI_BUF_TX(type) \
static void spi_imx_buf_tx_##type(struct spi_imx_data *spi_imx) \
{ \
type val = 0; \
\
/* 1. 如果内存中有待发送数据,则读取并更新指针 */ \
if (spi_imx->tx_buf) { \
val = *(type *)spi_imx->tx_buf; /* 读取内存数据 */ \
spi_imx->tx_buf += sizeof(type); /* 指针按数据类型大小偏移 */ \
} \
\
/* 2. 更新剩余计数器,记录还剩多少字节没发完 */ \
spi_imx->count -= sizeof(type); \
\
/* 3. 将数据写入硬件发送寄存器 (writel 是写入 32 位寄存器的标准函数) */ \
writel(val, spi_imx->base + MXC_CSPITXDATA); \
}在 spi_imx_buf_rx_##type 这种宏定义中,type 并不是 C 语言的关键字,而是 宏定义的参数。
这行代码 static void spi_imx_buf_rx_##type(struct spi_imx_data *spi_imx) 是在定义一个C 语言函数。
我们分两部分拆解它的含义:
1.## 是什么?
是 C 语言预处理器的 "连接符"
它的作用是将两个符号在编译预处理阶段"粘"在一起,形成一个新的名字
当你调用 MXC_SPI_BUF_RX(u8) 时:
预处理器会将 spi_imx_buf_rx_ 和 u8 连接起来。
最终生成的函数名就是:spi_imx_buf_rx_u8。
2.type 在这里代表什么?
在这个宏里,type 是一个占位符。当你调用宏时,type 会被你传入的参数(如 u8, u16, u32)替换。
| 宏调用 | 展开后的函数定义 |
|---|---|
MXC_SPI_BUF_RX(u8) |
static void spi_imx_buf_rx_u8(struct spi_imx_data *spi_imx) { ... } |
MXC_SPI_BUF_RX(u16) |
static void spi_imx_buf_rx_u16(struct spi_imx_data *spi_imx) { ... } |
MXC_SPI_BUF_RX(u32) |
static void spi_imx_buf_rx_u32(struct spi_imx_data *spi_imx) { ... } |
总结
这行代码本质上是:"定义一个函数,函数名由 spi_imx_buf_rx_ 加上传入的类型名(如 u8)组成,函数的参数是一个指向 spi_imx_data 结构体的指针。"
这是一种利用 C 语言预处理器来批量生成相似函数的高级技巧,目的是为了:
- 减少重复代码:不用手动写三个逻辑几乎一样的函数。
- 保证类型安全:确保了对 u8、u16、u32 数据的内存操作都是标准的类型强转。
在 C 语言的宏定义(Macro Definition)中,反斜杠 \ 的作用是 "续行符"。
简单来说,它的意思是:告诉编译器,下一行的代码依然属于当前的宏定义,不要在这里结束。
writel 的功能:将一个 32 位的数值写入到指定的内存映射地址(即硬件寄存器的地址)中
c
void writel(u32 value, volatile void __iomem *addr);value: 你要写入的 32 位数据。
addr: 你要写入的寄存器地址(这个地址必须是经过 ioremap 映射过的虚拟地址,也就是你在结构体中看到的 spi_imx->base + 偏移量)。
至此,我们可以对主控层的功能进行更进一步的理解:
上层传来的 spi_transfer 是通用的(比如"我要以 1MHz 发送这 100 字节"),主控层通过 spi_imx_setupxfer 进行环境适配。它确认了当前硬件(i.MX6ULL)的能力,并选定了最高效的"搬运工"(即你找到的那些 tx/rx 函数指针),并决策是采用 PIO (轮询/中断) 还是 DMA (直接内存访问) 模式完成 SPI 总线上"内存"与"物理设备寄存器"之间的数据交换。
好,我们现在再回到 spi_imx_pio_transfer,提出一个问题:
当一次传输无法把所有数据都处理完成时,应该如何解决?
我们注意到 spi_imx_push 执行后紧接着
spi_imx->devtype_data->intctrl(spi_imx, MXC_INT_TE);
我们必须层层分析,首先先看 devtype_data,既然它后续还有 intctrl,说明它是一个结构体,查找 "devtype_data {"
c
/**
* struct spi_imx_devtype_data - SPI 控制器硬件类型抽象表
* * 此结构体定义了一套标准的"接口协议"。不同 i.MX 芯片的底层寄存器控制方式
* 虽然不同,但它们必须通过这套协议向驱动核心提供服务。
*/
struct spi_imx_devtype_data {
/* 1. 中断控制器:负责开关特定的硬件中断 (如发送空、接收满等) */
void (*intctrl)(struct spi_imx_data *, int);
/* 2. 硬件配置:将 SPI 参数(位宽、时钟频率等)写入具体芯片的寄存器 */
int (*config)(struct spi_device *, struct spi_imx_config *);
/* 3. 启动触发器:拉动物理触发开关,开启一次 SPI 数据搬运/传输 */
void (*trigger)(struct spi_imx_data *);
/* 4. 状态查询:检查接收 FIFO 中是否有新数据可读 */
int (*rx_available)(struct spi_imx_data *);
/* 5. 错误恢复:当传输超时或发生异常时,强制复位 SPI 硬件控制器 */
void (*reset)(struct spi_imx_data *);
/* 6. 型号枚举:标识当前驱动正在处理的硬件芯片类型 (便于驱动内部微调逻辑) */
enum spi_imx_devtype devtype;
};所以 intctrl 是一个中断控制器,我们需要找到它到底关联了什么中断,从搜索到的信息可以知道构建的结构体类型名字 是 spi_imx_devtype_data ,所以我们直接对这个结构体类型进行查找:
可以看到多个该类型的结构体,但由于我们使用的是 imx6ull 芯片,所以我们关注 imx6ul_ecspi_devtype_data
c
static struct spi_imx_devtype_data imx6ul_ecspi_devtype_data = {
.intctrl = mx51_ecspi_intctrl,
.config = mx51_ecspi_config,
.trigger = mx51_ecspi_trigger,
.rx_available = mx51_ecspi_rx_available,
.reset = mx51_ecspi_reset,
.devtype = IMX6UL_ECSPI,
};可以知道对应的具体函数是 mx51_ecspi_intctrl
c
/**
* mx51_ecspi_intctrl - ECSPI 控制器的中断使能配置函数
* @spi_imx: 包含 SPI 控制器硬件基地址等私有数据的结构体
* @enable: 上层传入的中断使能标志位(如 MXC_INT_TE, MXC_INT_RR)
*
* 逻辑:
* 本函数通过位运算,将通用的中断标志位转换为芯片特定的物理寄存器控制位,
* 并通过 writel 操作将其一次性写入硬件的中断控制寄存器中。
*/
static void mx51_ecspi_intctrl(struct spi_imx_data *spi_imx, int enable)
{
/* 1. 初始化临时变量,清空所有位 */
unsigned val = 0;
/* 2. 翻译"发送空中断":
* 如果上层请求开启 TE (Transmit Empty) 中断,
* 则将 ECSPI 特有的 TEEN (Transmit Empty Interrupt Enable) 位设为 1
*/
if (enable & MXC_INT_TE)
val |= MX51_ECSPI_INT_TEEN;
/* 3. 翻译"接收就绪中断":
* 如果上层请求开启 RR (Receive Ready) 中断,
* 则将 ECSPI 特有的 RREN (Receive Ready Interrupt Enable) 位设为 1
*/
if (enable & MXC_INT_RR)
val |= MX51_ECSPI_INT_RREN;
/* 4. 更新物理硬件:
* 将构造好的 val 写入 ECSPI_INT 寄存器。
* writel 会确保数据按 32 位格式写入指定的内存映射地址(spi_imx->base + 偏移)。
* 此操作将立即更新硬件的实际中断响应状态。
*/
writel(val, spi_imx->base + MX51_ECSPI_INT);
}-
MX51_ECSPI_INT_TEEN (Transmit Empty Enable)
目的:解决"发送饥渴"问题
原理:告诉硬件,当发送 FIFO 里的数据被送往总线导致 FIFO 变空(或低于阈值)时,请务必打断 CPU 当前的工作。
如果没有它:你发完第一批数据(比如 16 字节)后,硬件 FIFO 就空了,它会停止发送,且不会提醒 CPU,导致剩余的几百字节数据永远留在内存里发不出去。
一句话总结:这是"续杯"开关,保证发送缓冲区永远有数据可供硬件发送。
-
MX51_ECSPI_INT_RREN (Receive Ready Enable)
目的:解决"接收溢出"问题
原理:SPI 是同步通信,你每发送一个时钟周期,总线上必定会同时回来一个数据位。这个数据位会存入接收 FIFO。如果这个数据不及时取走,FIFO 满了之后,后续的数据就会丢失(溢出)。
如果没有它:硬件默默地接收数据,直到 FIFO 满,然后硬件报错(Overrun),但 CPU 根本不知道,导致你收到的数据全都是错的或断断续续的。
一句话总结:这是"清理"开关,保证接收缓冲区永远有空间接纳新数据,防止数据丢失。
MX51_ECSPI_INT_TEEN 和 MX51_ECSPI_INT_RREN 都是用来"开启"中断功能的开关,触发它们会导致 CPU 跳转去执行 SPI 的处理函数。
既然我们已经明确了 TEEN 和 RREN 这两个'传感器开关'的作用,以及它们如何将硬件状态映射为 CPU 的中断请求,那么接下来的核心就是分析中断处理的'大脑'------即当 CPU 响应中断并跳转进入 spi_imx_isr 函数(无论是因为 MX51_ECSPI_INT_TEEN(发送空)被触发,还是因为 MX51_ECSPI_INT_RREN(接收就绪)被触发,CPU 最终进入的函数永远是 spi_imx_isr)
要想找到中断相关内容,我们需要搜索 "isr"
c
/**
* spi_imx_isr - SPI 中断服务函数
* @irq: 中断号
* @dev_id: 传递进来的私有数据 (指向 spi_imx_data 结构体)
*
* 逻辑概要:
* 每当硬件状态变化(FIFO 可读/可写)触发中断,CPU 就会执行此函数。
* 它采用"激进处理"策略,在一次中断中尽可能完成所有待读写的数据。
*/
static irqreturn_t spi_imx_isr(int irq, void *dev_id)
{
struct spi_imx_data *spi_imx = dev_id;
/* 1. 循环读取:清理接收 FIFO
* 只要硬件 FIFO 中有数据,就立即读走,防止 FIFO 溢出 (Overrun)。
* 并相应减少 txfifo 计数器(记录当前已发送但未收到的数据量)。
*/
while (spi_imx->devtype_data->rx_available(spi_imx)) {
spi_imx->rx(spi_imx);
spi_imx->txfifo--;
}
/* 2. 持续填充:发送逻辑
* 如果内存缓冲区中还有剩余数据待发送 (spi_imx->count > 0),
* 则调用 spi_imx_push 压入 FIFO,继续驱动硬件发送。
*/
if (spi_imx->count) {
spi_imx_push(spi_imx);
return IRQ_HANDLED;
}
/* 3. 等待收尾:处理最后剩余数据
* 如果发送缓冲区已空,但 FIFO 中仍有数据正在传输 (txfifo > 0),
* 此时无需发送新数据,但必须开启 RR (接收就绪) 中断,
* 等待硬件把最后的数据收回来。
*/
if (spi_imx->txfifo) {
spi_imx->devtype_data->intctrl(spi_imx, MXC_INT_RR);
return IRQ_HANDLED;
}
/* 4. 传输完成:关断与通知
* 数据收发均已完成,关闭所有硬件中断,
* 并唤醒正在等待此次传输结束的进程 (complete)。
*/
spi_imx->devtype_data->intctrl(spi_imx, 0);
complete(&spi_imx->xfer_done);
return IRQ_HANDLED; // 告诉内核:中断已处理,无需再调其他函数
}判断内存缓冲区是否还有数据没有发完:
- 未发完,则继续调用 spi_imx_push 压入FIFO,驱动硬件发送
- 发完,则说明 CPU 的数据都已经发送给TX FIFO 了,不再有软件层面的数据要发;但硬件层面,移位寄存器可能还在转移刚刚 TX FIFO 的数据到MOSI引脚,所以要开启 MXC_INT_RR 中断,当硬件把所有的数据都推入RX FIFO之后,触发中断,再次进入 spi_imx_isr 清理接收到的FIFO数据,存入内存缓冲区
CPU / DMA <-----> 【TX FIFO】 -----> 【TX 移位寄存器】 -----> MOSI 引脚
CPU / DMA <-----> 【RX FIFO】 <----- 【RX 移位寄存器】 <----- MISO 引脚
什么是 IRQ_HANDLED?
在 Linux 中,ISR(中断服务程序)必须返回一个类型为 irqreturn_t 的值,它是给内核看的"状态报告"。
IRQ_HANDLED (处理成功):
告诉内核:"我已经识别出这是我的设备发出的中断,并且我已经妥善处理了它。请继续正常工作。"
IRQ_NONE (未处理):
告诉内核:"这不是我的设备发出的,或者是误报。请去问问同一条中断线上的其他驱动程序。"
为什么会有 IRQ_NONE?
因为硬件引脚资源有限,有时多个外设会共享同一个物理中断线(IRQ Line)。如果内核收到中断,它会遍历该中断线上注册的所有驱动。如果你的驱动返回 IRQ_HANDLED,内核就知道任务完成;如果所有驱动都返回 IRQ_NONE,内核就会认为发生了"未处理中断(spurious interrupt)"从而发出警告。
SPI 中断驱动数据传输链路
第一阶段:传输点火(主线程发起)
当上层应用发起一次 SPI 数据传输(例如 spi_sync)时:
1.准备数据:驱动程序将数据准备在内存缓冲区中。
2.首批填充:调用 spi_imx_push
关键点:push 会根据 FIFO 的剩余空间,将内存中尽可能多的一块数据(通常是填满 FIFO 容量)压入硬件 FIFO。
3.使能中断:调用 intctrl(spi_imx, MXC_INT_TE)。开启"发送空中断"。这相当于告诉硬件:"只要这批数据发完了(只要FIFO有数据,移位寄存器就会自行启动,直到 FIFO 数据发送完成),立刻通过 IRQ 引脚打断 CPU。"
4.进入等待:主线程调用 wait_for_completion 进入睡眠,进入"等待 CPU 调度"状态,此时 CPU 可以去处理其他进程,直到中断到来。
第二阶段:中断接力(ISR 循环触发)
当硬件执行完第一批发送,FIFO 变空,硬件触发中断,CPU 跳转到spi_imx_isr:
1.清理旧账 (while 循环):
- 逻辑:调用 rx_available 和 rx。
- 目的:接收 FIFO 里的数据必须优先取走。因为 SPI 全双工,你每发一个字节,从机必然回一个字节。如果不及时清理,一旦 FIFO 溢出,传输就会报错。
2.补货续航 (if (spi_imx->count) ):
- 逻辑:调用 spi_imx_push。
- 目的:如果内存里还有剩余数据没发完,再次填满 FIFO。硬件接到新数据后,会自动开始新一轮的物理传输,整个传输链条保持运动。
3.循环往复:由于此时的 MXC_INT_TE 始终处于开启的状态,所以只要FIFO发送完数据就会再次进入 isr,直到内存缓冲区为空,才会跳出这个循环。否则 spi_imx_isr 函数永远无法执行到 "3. 等待收尾:处理最后剩余数据" 这一步
第三阶段:收尾归档(完成通知)
当 spi_imx->count 为 0 时,意味着内存数据已全部推向硬件:
1.最后清算 (if (spi_imx->txfifo)):
- 逻辑:虽然数据发完了,但 FIFO 里可能还剩下最后几笔数据正在通过电线传输,且对应有从机的数据尚未回传。
- 手段:开启 MXC_INT_RR(接收就绪中断)。
- 目的:这是最后一次收网,确保把硬件内残留的最后数据读取完毕。
2.停机与唤醒:
- 逻辑:调用 intctrl(spi_imx, 0)(关闭所有中断,报警器关掉)和 complete(&spi_imx->xfer_done)。
- 目的:告知内核传输圆满结束,唤醒之前睡眠的主线程,将处理结果(成功或失败)返回给应用层。
1.2 spi_imx_dma_transfer
c
static int spi_imx_dma_transfer(struct spi_imx_data *spi_imx,
struct spi_transfer *transfer)
{
/* 声明用于描述 DMA 异步传输任务的描述符指针 (TX 为发送, RX 为接收) */
struct dma_async_tx_descriptor *desc_tx, *desc_rx;
/* 定义用于超时监控的变量 */
unsigned long transfer_timeout;
unsigned long timeout;
/* 通过 SPI 私有数据获取 SPI 主机控制器对象 */
struct spi_master *master = spi_imx->bitbang.master;
/* 获取发送和接收的分散聚合表(SG Table),DMA 必须依靠 SG 表来处理物理内存碎片 */
struct sg_table *tx = &transfer->tx_sg, *rx = &transfer->rx_sg;
/*
* 关键逻辑:RX 必须先于 TX 配置。
* 因为 TX DMA 启动后会立即触发硬件开始发送,如果此时 RX 没准备好,
* 从机返回的数据就会导致接收 FIFO 溢出 (Overrun)。
*/
/* 1. 配置 RX DMA 通道 */
/* 准备 RX DMA 描述符:指定 RX 通道、物理内存地址、块数、方向(设备到内存)、中断标志等 */
desc_rx = dmaengine_prep_slave_sg(master->dma_rx,
rx->sgl, rx->nents, DMA_DEV_TO_MEM,
DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
/* 若描述符申请失败,则立即返回错误 */
if (!desc_rx)
return -EINVAL;
/* 将 DMA 接收完成后的回调函数注册到描述符中 */
desc_rx->callback = spi_imx_dma_rx_callback;
/*
将 SPI 私有数据结构体作为参数传递给回调函数,
* spi_imx 是你的私有数据结构体 (struct spi_imx_data *)。
* 通过强制类型转换将其转化为通用指针 void *,存入描述符中
*/
desc_rx->callback_param = (void *)spi_imx;
/* 将 RX 描述符提交到 DMA 引擎的等待队列中 */
dmaengine_submit(desc_rx);
/* 重置 RX 完成量 (completion),用于后续在中断中唤醒进程 */
reinit_completion(&spi_imx->dma_rx_completion);
/* 正式向硬件下达启动指令,此时 RX 通道已准备好在有数据到来时搬运至内存 */
dma_async_issue_pending(master->dma_rx);
/* 2. 配置 TX DMA 通道 */
/* 准备 TX DMA 描述符:配置方式与 RX 类似,区别在于方向为 DMA_MEM_TO_DEV (内存到设备) */
desc_tx = dmaengine_prep_slave_sg(master->dma_tx,
tx->sgl, tx->nents, DMA_MEM_TO_DEV,
DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
/* 若 TX 描述符申请失败,需回滚并终止已启动的 RX DMA */
if (!desc_tx) {
dmaengine_terminate_all(master->dma_tx);
return -EINVAL;
}
/* 注册发送完成回调 */
desc_tx->callback = spi_imx_dma_tx_callback;
/* 同样传递私有数据用于中断处理 */
desc_tx->callback_param = (void *)spi_imx;
/* 将 TX 描述符加入 DMA 调度队列 */
dmaengine_submit(desc_tx);
/* 重置 TX 完成量 */
reinit_completion(&spi_imx->dma_tx_completion);
/* 启动 TX 通道,此时数据开始流向 SPI 硬件发送 FIFO */
dma_async_issue_pending(master->dma_tx);
/* 3. 等待与执行 */
/* 根据传输长度计算预期的超时时长,防止硬件死锁导致进程永久挂起 */
transfer_timeout = spi_imx_calculate_timeout(spi_imx, transfer->len);
/* 真正触发 SPI 硬件控制器的使能开关,开始物理总线时钟与数据传输 */
spi_imx->devtype_data->trigger(spi_imx);
/* 4. 同步等待:CPU 进入睡眠,直到 DMA 完成中断调用回调函数唤醒它 */
/* 等待 TX 完成:若 TX 通道在超时时间内未通过中断调用回调唤醒当前进程,则报错 */
timeout = wait_for_completion_timeout(&spi_imx->dma_tx_completion,
transfer_timeout);
if (!timeout) {
dev_err(spi_imx->dev, "I/O Error in DMA TX\n");
/* 超时则强制终止所有 DMA 传输,释放占用的硬件资源 */
dmaengine_terminate_all(master->dma_tx);
dmaengine_terminate_all(master->dma_rx);
return -ETIMEDOUT;
}
/* 等待 RX 完成:等待接收数据搬运完毕 */
timeout = wait_for_completion_timeout(&spi_imx->dma_rx_completion,
transfer_timeout);
if (!timeout) {
dev_err(&master->dev, "I/O Error in DMA RX\n");
/* 超时则执行硬件重置逻辑,并清理 RX 通道 */
spi_imx->devtype_data->reset(spi_imx);
dmaengine_terminate_all(master->dma_rx);
return -ETIMEDOUT;
}
/* 所有 DMA 传输任务按序完成,返回本次传输的实际数据长度 */
return transfer->len;
}在嵌入式开发和 DMA 子系统中,"描述符" 可以被理解为"硬件执行任务的说明书"或"任务清单"。
-
为什么需要描述符?(问题的本质)
DMA 是一个独立的硬件单元,它不知道你的软件想干什么,也不懂什么叫"数组"、"结构体"或"链表"。
如果 CPU 直接去指挥 DMA:"去把 0x80000000 地址的 1024 字节搬运到 0x02000000",这在简单场景可行。
但在复杂的 Linux 系统中,数据往往是散落在内存各处的(通过 scatterlist 管理),且数据传输量巨大。如果 CPU 每搬运一小块内存就要打断 DMA 一次,那 DMA 就失去了存在的意义。
描述符的作用: 软件把一次复杂、分散的传输任务,预先整理成一份"硬件能读懂的格式",放入内存,然后把这份说明书的起始地址交给 DMA 硬件。DMA 硬件启动后,会自动读取这份清单,逐条执行,直到完成。
-
描述符里写了什么?(结构)
在 imx-sdma.c 驱动中,描述符对应 struct sdma_buffer_descriptor。它通常包含以下核心信息:
源地址 (Source Address):数据从哪里搬?
目的地址 (Destination Address):数据搬到哪里去?
传输长度 (Count):一次搬运多少字节?
控制信息 (Control/Status Bits):这是灵魂所在,例如:
DONE:硬件写回位,告诉 CPU 这一条搬完了。
WRAP:是否循环传输(常用于音频)。
INTR:做完这一条后,是否给 CPU 发个中断信号?
CONT:是否还有下一条?(实现链表结构)。
在 Linux 内核中,completion 机制是一种轻量级、专门用于任务间同步的机制。它比互斥锁(mutex)或信号量(semaphore)更简单,专门用于"等待某个任务完成"的场景。
你可以把 completion 想象成一个"信号灯",它只有两种状态:没亮(没完成) 和 亮了(完成了)。
三个核心操作
completion 的使用逻辑非常直观,只有三个关键函数:
-
reinit_completion(&x):重置/初始化。把信号灯的状态设为"没亮"(计数器归零)。在调用之前,必须确保状态是干净的。
为什么需要"计数"能力?
如果 completion 只是一个简单的二进制开关(开/关),那么在多核环境下,你可能会面临一个严峻的逻辑冲突:
场景:假设你的驱动代码调用 wait_for_completion 的瞬间,刚好硬件中断触发了 complete()。
如果不带计数器:如果中断先到,它把开关拨到了"完成",但此时你还没有进入等待状态。当你稍后进入 wait_for_completion 时,你可能会因为错过了信号而永久睡眠,永远醒不过来。
计数器的逻辑是:
complete() 操作会将计数器 +1。
wait_for_completion() 操作会检查计数器。如果计数器 > 0,它直接将计数器 -1 然后直接返回,根本不进入睡眠状态。
这相当于在说:"任务已经完成了(计数器是 1),我不需要睡眠等待了,继续往下执行吧。"
-
wait_for_completion_timeout(&x, timeout):等待。如果灯没亮,调用此函数的进程会进入睡眠状态(Blocked),把 CPU 让出来给别的任务。如果超时了灯还没亮,就自动唤醒并返回错误。
-
complete(&x):亮灯。当任务完成时(例如 DMA 传输完毕),中断服务程序调用此函数。它会把灯点亮,并直接唤醒那个正在睡眠等待的进程。
1.2.1 cscope 工具介绍
由于函数定义用 grep 定位比较低效,这里介绍一个工具 "cscope"
cscope 的强大之处在于它将你的代码库转化为了一个关联数据库,不仅仅是简单的字符串匹配。
安装后在源码目录执行
cscope -Rbq
-R: 递归遍历子目录。
-b: 构建索引数据库 (cscope.out),而不启动交互界面。
-q: 生成倒排索引,极大提升大型项目(如内核)的检索速度。
开始搜索:
方式 A(交互模式):输入 cscope -d 进入交互界面,在对应的查找框输入函数名即可。
方式 B(Vim 高效模式):在 Vim 中使用 :cs find 命令(最推荐)。
方式A
执行:
cscope -d
在 cscope 界面中,你主要会用到以下几个功能:
-
Find this C symbol (编号 0):最常用。搜索变量、宏定义、函数名。如果你不确定该找哪一个,选这个通常没错。
-
Find this function definition (编号 1):精准搜索函数定义(即 static int ... { 这一行)。这是你查找 dmaengine_prep_slave_sg 定义的最佳选择。
-
Find functions called by this function (编号 2):查找该函数内部调用了哪些其他函数。
-
Find functions calling this function (编号 3):查找哪些地方调用了该函数。这在分析驱动调用链时最有用。
方式B
在 Vim 中使用 cscope 是内核开发者的"必杀技"。它的核心在于将代码库作为数据库,让你在编写代码的同时实现秒级跳转。
要让 Vim 能够使用 cscope,必须遵循 "挂载数据库 -> 执行查询 -> 查看跳转" 的三步工作流。
第一步:在 Vim 中挂载数据库
Vim 不会自动加载你生成的 cscope.out,每次进入 Vim(或者在 Vim 内)都需要手动挂载。
打开文件:
在源码根目录下执行:vim drivers/spi/spi-imx.c
挂载数据库(在 Vim 的命令模式下输入):
:cs add cscope.out
如果提示 cscope.out: No such file or directory,说明你不在根目录,请输入绝对路径:
:cs add /home/book/100ask_imx6ull-sdk/Linux-4.9.88/cscope.out
第二步:掌握 :cs find 指令
这是你最高频使用的命令。格式为::cs find <类型> <符号名>。
常用类型列表:
s:查找这个符号(变量、宏、函数名)的所有出现位置。
g:查找定义(Definition)。跳转到函数体最快的方式。
c:查找调用者(Callers)。分析调用链的核心,查找谁调用了该函数。
d:查找该函数调用的其他函数。
实战操作:
查找定义::cs find g dmaengine_prep_slave_sg
查找谁调用了它::cs find c dmaengine_prep_slave_sg
第三步:极速跳转与回退(进阶技巧)
当你执行 :cs find 后,Vim 会列出所有匹配项:
跳转:系统会自动列出序号。直接输入序号 + 回车即可跳转到对应代码。
回退(非常重要):跳转到目标函数看代码后,想立刻跳回刚才的位置?
按下 Ctrl + t。
你可以连续按,它会记录你的跳转历史,像浏览器的"后退"键一样好用。
1.2.2 dmaengine_prep_slave_sg (rx的)
现在我们使用 cscope -d 搜索 spi_imx_dma_transfer 中的 dmaengine_prep_slave_sg
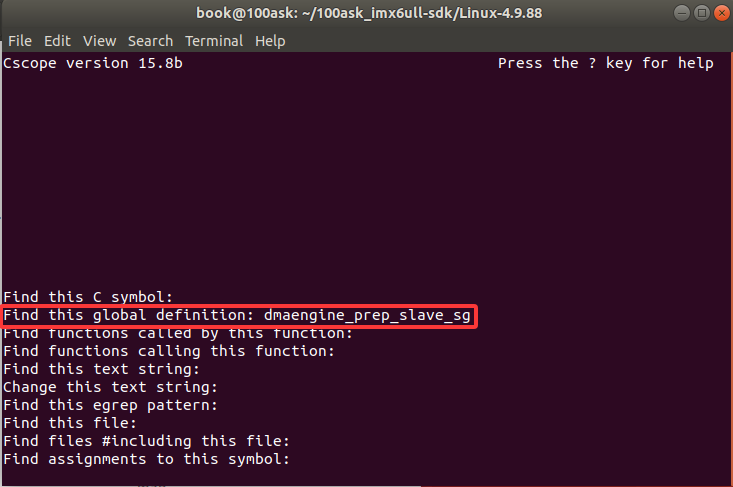
c
static inline struct dma_async_tx_descriptor *dmaengine_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl, unsigned int sg_len,
enum dma_transfer_direction dir, unsigned long flags)
{
if (!chan || !chan->device || !chan->device->device_prep_slave_sg)
return NULL;
return chan->device->device_prep_slave_sg(chan, sgl, sg_len,
dir, flags, NULL);
}即可快速定位函数定义!
该函数本身只是一个"分发员"。
-
输入判断:if (!chan || !chan->device || !chan->device->device_prep_slave_sg)
这是一套严谨的空指针检查,防止因为硬件 DMA 通道没初始化好而导致内核崩溃(Panic)。
-
真正的执行者:chan->device->device_prep_slave_sg(...)
这行代码展示了多态:chan->device 是一个指向硬件控制器驱动的结构体。
具体的 DMA 实现(比如 sdma.c 对于 i.MX6ULL 的实现)会预先把自己的一组函数指针填充到 chan->device 中。
当调用此接口时,它实际上调用的是底层驱动编写的具体函数。
| 参数 | 含义 | 研究重点 |
|---|---|---|
struct dma_chan *chan |
DMA 通道实例 | 它是连接内存与外设的"管道"。 |
struct scatterlist *sgl |
分散聚合表指针 | 物理内存不连续时,DMA 怎么找数据?靠的就是这个链表。 |
unsigned int sg_len |
内存块数量 | sgl 链表里有多少个节点。 |
enum dma_transfer_direction dir |
传输方向 | 必须关注是 DMA_MEM_TO_DEV 还是 DMA_DEV_TO_MEM。 |
unsigned long flags |
标志位 | 如 DMA_PREP_INTERRUPT(完成后是否触发中断)。 |
这个 static inline 函数跳转到的是一个函数指针 (device_prep_slave_sg)。这意味着简单的 cscope 查找可能只能找到定义,无法直接跳转到具体代码。
既然我们已经确认了 chan->device 的类型是 struct dma_device(函数参数),并且接口名是 device_prep_slave_sg,接下来的步骤如下:
-
确认结构体成员名(确定目标)
我们已经明确了目标:找到所有给 dma_device 结构体中的 device_prep_slave_sg 指针赋值的地方。
-
执行定位赋值的精准搜索
方法1:
在内核源码根目录下,使用 grep 搜索整个内核目录中,imx 芯片 的对应实例:
grep -rn "device_prep_slave_sg =" . | grep "imx"
book@100ask:~/100ask_imx6ull-sdk/Linux-4.9.88$ grep -rn "device_prep_slave_sg =" . | grep "imx"
./drivers/dma/imx-sdma.c:2352: sdma->dma_device.device_prep_slave_sg = sdma_prep_slave_sg;
./drivers/dma/imx-dma.c:1186: imxdma->dma_device.device_prep_slave_sg = imxdma_prep_slave_sg;
方法2:
或者也可以通过 cscope 进行查找:
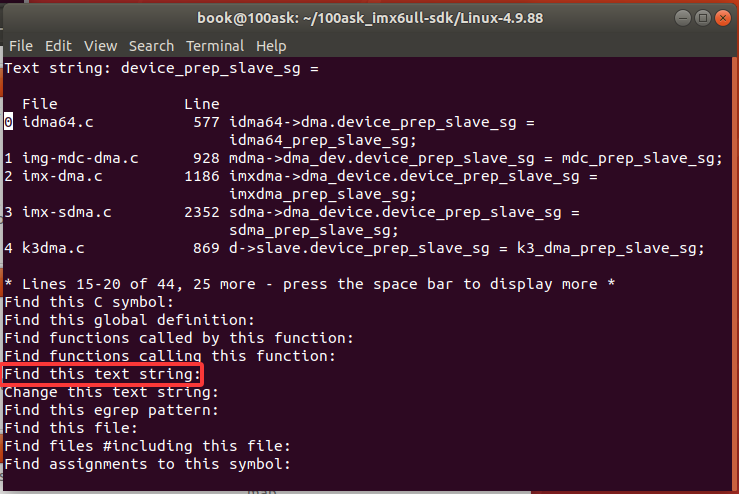
在 "Find this text string:" 后输入 "device_prep_slave_sg =",通过空格翻页,查看上方搜索结果区域的内容也能找到。
为什么有两个?
imx-sdma.c:这是 i.MX6/7 系列最核心、最复杂的智能 DMA 驱动,功能强大,支持多种固件脚本,i.MX6ULL 的各类外设(SPI, UART, I2C 等)高性能传输都靠它。
imx-dma.c:这是早期 i.MX 芯片使用的较简单的 DMA 驱动。
[root@100ask:~]# dmesg | grep -i "dma"
[ 0.000000] OF: reserved mem: initialized node linux,cma, compatible id shared-dma-pool
[ 0.305428] DMA: preallocated 256 KiB pool for atomic coherent allocations
[ 0.545550] mxs-dma 1804000.dma-apbh: initialized
[ 0.567652] i2c i2c-0: can't use DMA, using PIO instead.
[ 0.570155] i2c i2c-1: can't use DMA, using PIO instead.
[ 1.208217] imx-sdma 20ec000.sdma: loaded firmware 3.3
[ 3.375108] mmc0: SDHCI controller on 2190000.usdhc [2190000.usdhc] using ADMA
[ 3.464559] mmc1: SDHCI controller on 2194000.usdhc [2194000.usdhc] using ADMA1.208217 imx-sdma 20ec000.sdma: loaded firmware 3.3
这行日志明确说明了你的 i.MX6ULL 正在使用 imx-sdma.c 驱动,并且已经成功加载了固件。所以,你刚才在 grep 中看到的 sdma_prep_slave_sg 就是后续要研究的函数。
后续我们就使用 cscpoe 来定位目标了,先进入 vim 模式,执行
:cs add cscope.out
挂载数据库
再执行
:cs find g sdma_prep_slave_sg
查看函数定义
c
static struct dma_async_tx_descriptor *sdma_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_transfer_direction direction,
unsigned long flags, void *context)
{
return sdma_prep_sg(chan, NULL, 0, sgl, sg_len, direction, flags);
} 在 Linux 内核 DMA 框架中,sdma_prep_slave_sg 的返回值类型为 struct dma_async_tx_descriptor *,这里的 async 并不是指该函数本身是"异步函数",而是指它返回的这个结构体描述的是一个"异步传输任务"。
-
它是任务的"定义",而非"执行"
在内核设计中,prep 系列函数(如 device_prep_slave_sg)的主要工作是同步地构建一个传输任务的描述符。
这个描述符包含了一次 DMA 传输所需的所有信息:源地址、目的地址、长度、传输方向等。
之所以叫 dma_async_tx_descriptor,是因为它描述的这个任务,在提交给硬件之后,执行过程是完全异步的。
-
异步传输的生命周期
名字里的 async 反映了整个 DMA 传输的生命周期:
准备阶段(同步):调用 sdma_prep_slave_sg 时,CPU 是在同步执行代码,申请内存、填充 BD 链表。
提交阶段(异步起点):当驱动调用 dmaengine_submit() 将此描述符交给 DMA 引擎时,真正的异步过程就开始了。此时 CPU 可以立即去做其他事情,而不需要等待数据传输完成。
硬件执行(异步):SDMA 硬件异步读取内存中的 BD 链表,执行搬运。
回调通知(异步结果):当硬件搬运完成后,触发中断,DMA 核心层通过这个描述符中预设的 callback 函数,异步地通知上层驱动任务完成。
-
为了支持"多任务链式排队"
内核使用 dma_async_tx_descriptor 结构体,是为了让上层驱动(如 SPI)能够管理多个任务序列。
这个结构体允许你通过链表(tx_list 等字段)将多个异步任务链接在一起,从而实现 DMA 传输的自动接续。
如果不是"异步"设计的,上层驱动就必须在每次传输完成后阻塞 CPU 等待下一次,这会极大降低系统性能。
c
static struct dma_async_tx_descriptor *sdma_prep_sg(
struct dma_chan *chan,
struct scatterlist *dst_sg, unsigned int dst_nents,
struct scatterlist *src_sg, unsigned int src_nents,
enum dma_transfer_direction direction, unsigned long flags)
{
/* 将通用的 dma_chan 强制转换为 SDMA 私有的通道结构 sdma_channel */
struct sdma_channel *sdmac = to_sdma_chan(chan);
/* 获取通道所属的 SDMA 引擎控制器实例 */
struct sdma_engine *sdma = sdmac->sdma;
int ret, i, count;
int channel = sdmac->channel;
/* 初始化源和目的 scatterlist 的迭代指针 */
struct scatterlist *sg_src = src_sg, *sg_dst = dst_sg;
struct sdma_desc *desc;
/* 基本的安全性检查,确保通道有效 */
if (!chan)
return NULL;
dev_dbg(sdma->dev, "setting up %d entries for channel %d.\n",
src_nents, channel);
/*
* 1. 初始化传输描述符:
* 分配一个 sdma_desc 对象,并为其内部的 BD 数组分配相应的内存空间,
* 用于存放本次传输的所有片段信息。
*/
desc = sdma_transfer_init(sdmac, direction, src_nents);
if (!desc)
goto err_out;
/* 2. 遍历每一个 Scatterlist 碎片 (Fragment) */
/* for_each_sg 是内核提供的宏,用于安全地迭代遍历 scatterlist 链表 */
for_each_sg(src_sg, sg_src, src_nents, i) {
/* 定位当前碎片对应的 BD 指针 */
struct sdma_buffer_descriptor *bd = &desc->bd[i];
int param;
/* 将该碎片的物理地址赋值给 BD 中的 buffer_addr,硬件通过此地址访问内存 */
bd->buffer_addr = sg_src->dma_address;
/* 如果是内存到内存传输,必须同时配置目的内存的物理地址 */
if (direction == DMA_MEM_TO_MEM) {
BUG_ON(!sg_dst); // 若目的 SG 为空,触发内核致命错误
bd->ext_buffer_addr = sg_dst->dma_address;
}
/* 获取当前碎片的数据长度 */
count = sg_dma_len(sg_src);
/* 检查传输长度是否超过了硬件描述符支持的最大值 (SDMA_BD_MAX_CNT) */
if (count > SDMA_BD_MAX_CNT) {
dev_err(sdma->dev, "SDMA channel %d: maximum bytes for sg entry exceeded: %d > %d\n",
channel, count, SDMA_BD_MAX_CNT);
ret = -EINVAL;
goto err_bd_out;
}
/* 将长度写入 BD 的 mode.count 字段,告诉 DMA 硬件本次搬运多少数据 */
bd->mode.count = count;
sdmac->chn_count += count;
/*
* 检查并配置总线宽度:
* 根据源和目的地址的对齐情况,配置 BD 中的控制位以确定总线访问位宽 (8/16/32 bit)。
*/
if (direction == DMA_MEM_TO_MEM)
ret = check_bd_buswidth(bd, sdmac, count,
sg_dst->dma_address,
sg_src->dma_address);
else
ret = check_bd_buswidth(bd, sdmac, count, 0,
sg_src->dma_address);
if (ret)
goto err_bd_out;
/* 3. 设置 BD 控制状态位 (最为关键的硬件指令) */
/* BD_DONE: 硬件处理完后会清除此位以通知软件;BD_EXTD: 使用扩展地址;BD_CONT: 表示链表未结束 */
param = BD_DONE | BD_EXTD | BD_CONT;
/* 如果是列表的最后一个碎片: */
if (i + 1 == src_nents) {
param |= BD_INTR; // 传输完成后触发中断通知 CPU
param |= BD_LAST; // 标记这是传输链表的最后一个 BD
param &= ~BD_CONT; // 显式清除连续传输位,告知硬件链表终止
}
dev_dbg(sdma->dev, "entry %d: count: %d dma: 0x%pad %s%s\n",
i, count, &sg_src->dma_address,
param & BD_WRAP ? "wrap" : "",
param & BD_INTR ? " intr" : "");
/* 将最终构建的 param 参数写入 BD 的 status 字段,硬件读取后按此执行 */
bd->mode.status = param;
/* 如果是 Mem-to-Mem,移动到下一个目的内存碎片指针 */
if (direction == DMA_MEM_TO_MEM)
sg_dst = sg_next(sg_dst);
}
/* 4. 将准备好的描述符加入虚拟通道队列 (准备进入异步执行) */
/* vchan_tx_prep 将 desc 转化为 dma_async_tx_descriptor,静候 dmaengine_submit 调用 */
return vchan_tx_prep(&sdmac->vc, &desc->vd, flags);
err_bd_out:
sdma_free_bd(desc); // 清理已分配的 BD 内存资源
kfree(desc); // 释放描述符内存
err_out:
dev_dbg(sdma->dev, "Can't get desc.\n");
return NULL;
}在 SDMA(Smart DMA)架构中,BD 是 Buffer Descriptor(缓冲区描述符)的缩写。
它是 软件(驱动程序) 与 硬件(SDMA 处理器) 之间沟通的唯一语言。如果你把 DMA 传输比作一次"货物运输",那么 BD 就是那张详细的"物流单"。
关键点逻辑总结:
-
物理映射:DMA 只认识物理地址,sg_src->dma_address 是由 dma_map_sg 函数预先映射好的物理地址,确保了 DMA 能够直接访问。
-
链表构建:通过循环遍历 scatterlist 并设置 BD_CONT 与 BD_LAST,成功在内存中构建了一个硬件可识别的"任务清单"。
-
状态反馈:设置 BD_INTR 是实现异步的关键,硬件在搬运完最后一个数据块后,会产生中断,驱动的中断服务程序随后会执行回调函数,完成整个异步通信过程。
1.2.3 spi_imx_dma_rx_callback
c
static void spi_imx_dma_rx_callback(void *cookie)
{
/*
* 1. 获取私有数据指针:
* 'cookie' 是在 dmaengine_prep_slave_sg 时传入的 (void *)spi_imx。
* 这里通过强制类型转换将其还原为 spi_imx_data 结构体,
* 从而能够访问到该通道的完成量 (completion)。
*/
struct spi_imx_data *spi_imx = (struct spi_imx_data *)cookie;
/*
* 2. 触发完成量 (Complete):
* 这行代码是异步与同步的"桥梁"。
* 它会将 dma_rx_completion 标记为"已完成",并唤醒此前在
* spi_imx_dma_transfer 中调用 wait_for_completion_timeout()
* 而进入睡眠状态的内核进程。
*/
complete(&spi_imx->dma_rx_completion);
}回调函数 spi_imx_dma_rx_callback 不是由你的 SPI 驱动直接调用的,而是在 DMA 控制器的底层驱动:
执行者:是由内核的 DMA 子系统框架 (virt-dma) 调用的。
触发者:是由 SDMA 硬件中断 驱动的。
时机:当中断处理函数确认任务完成后,从描述符中取出你之前预存的 callback 指针,通过函数指针直接调用。
1.2.4 dma_async_issue_pending (rx的)
c
static inline void dma_async_issue_pending(struct dma_chan *chan)
{
chan->device->device_issue_pending(chan);
}同样的,这个函数并不是某个具体的函数,我们仍然通过 "赋值" 的方法来查找,在 cscpoe -d 中搜索 "device_issue_pending ="
c
File Line
1 imx-dma.c 1192 imxdma->dma_device.device_issue_pending =
imxdma_issue_pending;
2 imx-sdma.c 2364 sdma->dma_device.device_issue_pending = sdma_issue_pending;根据之前的分析,我们要研究的是 imx - sdma.c
c
static void sdma_issue_pending(struct dma_chan *chan)
{
/* 1. 将通用 DMA 通道强制转换为 SDMA 私有通道结构体 */
struct sdma_channel *sdmac = to_sdma_chan(chan);
unsigned long flags;
/*
* 2. 获取自旋锁:
* 由于虚拟通道 (vchan) 可能会被多个线程(如任务提交者、中断处理程序等)同时操作,
* 因此必须使用自旋锁来保护内部的链表状态,防止竞态条件。
* spin_lock_irqsave 会同时关闭本地 CPU 中断,防止死锁。
*/
spin_lock_irqsave(&sdmac->vc.lock, flags);
/*
* 3. 核心调度判断逻辑:
* vchan_issue_pending(&sdmac->vc) 会做两件事:
* a. 将该通道中"挂起 (pending)"状态的描述符移到"已提交 (submitted)"队列。
* b. 如果有新任务从挂起队列被移入已提交队列,返回 true。
*
* !sdmac->desc: 这是一个关键检查,确保当前硬件通道是空闲的 (没有正在进行的传输)。
*
* 逻辑含义:如果调度器成功提取了新任务,且此时硬件没有任务在跑,就立即启动新任务。
*/
if (vchan_issue_pending(&sdmac->vc) && !sdmac->desc)
/* 4. 真正触发硬件启动:将描述符交给 SDMA 引擎去执行 */
sdma_start_desc(sdmac);
/* 5. 释放锁并恢复中断 */
spin_unlock_irqrestore(&sdmac->vc.lock, flags);
}
c
static void sdma_start_desc(struct sdma_channel *sdmac)
{
/* 从虚拟通道的队列中取出一个待处理的任务节点 (virt_dma_desc) */
struct virt_dma_desc *vd = vchan_next_desc(&sdmac->vc);
struct sdma_desc *desc;
struct sdma_engine *sdma = sdmac->sdma;
int channel = sdmac->channel;
/*
* 如果队列中没有待处理任务,清空当前描述符指针并返回
* (防止硬件继续调度旧任务)
*/
if (!vd) {
sdmac->desc = NULL;
return;
}
/* 将通用的 virt_dma_desc 转换为 SDMA 特有的 sdma_desc 结构体 */
sdmac->desc = desc = to_sdma_desc(&vd->tx);
/*
* 任务管理策略:
* 如果不是循环模式 (IMX_DMA_SG_LOOP),说明是一个普通的单次传输任务。
* 1. 将该任务从待处理队列移入执行中的列表 (sdmac->pending)。
* 2. 从虚拟通道的发布队列 (issued list) 中将其删除。
*/
if (!(sdmac->flags & IMX_DMA_SG_LOOP)) {
list_add_tail(&sdmac->desc->node, &sdmac->pending);
list_del(&vd->node);
}
/*
* 核心:硬件寄存器赋值 (核心驱动逻辑)
* SDMA 硬件内部维护着通道控制寄存器 (channel_control)。
* 将 BD 的物理地址 (desc->bd_phys) 告知 SDMA 硬件:
* 1. base_bd_ptr: 告知硬件 BD 链表的起始地址。
* 2. current_bd_ptr: 告知硬件当前从哪个 BD 开始搬运。
*/
sdma->channel_control[channel].base_bd_ptr = desc->bd_phys;
sdma->channel_control[channel].current_bd_ptr = desc->bd_phys;
/*
* 点火启动:
* 调用底层函数开启该 DMA 通道,此时硬件 SDMA 处理器会自动根据上述
* 寄存器中设置的 BD 物理地址,开始异步搬运数据。
*/
sdma_enable_channel(sdma, sdmac->channel);
}一、 核心任务交接:base_bd_ptr 与 current_bd_ptr
在 imx-sdma.c 驱动中,以下两行代码是硬件与驱动进行"任务交接"的仪式:
c
sdma->channel_control[channel].base_bd_ptr = desc->bd_phys;
sdma->channel_control[channel].current_bd_ptr = desc->bd_phys;- 寄存器的功能定义
base_bd_ptr (基地址指针):定义了"物流清单"(BD 链表)的物理起点。当硬件需要重置任务或从头开始时,它会回到此地址。
current_bd_ptr (当前指针):定义了 SDMA 处理器此刻正在执行的 BD 地址。硬件每搬运完一个数据块,就会自动根据链表逻辑更新此指针,直至传输完成。 - 为什么初始化要赋值相同?
在调用 sdma_enable_channel 触发传输的瞬间,清单的第一行就是任务的起点,因此起始地址与当前指针必须一致。 - 驱动的责任与风险
驱动必须将 物理地址 (绝对不能是虚拟地址) 准确无误地写入这两个寄存器。如果赋值错误,SDMA 会去访问内存中的"垃圾数据",轻则导致数据传输异常,重则引发总线错误(Bus Error)导致系统崩溃。你可以将此过程理解为"给硬件装填弹药":驱动不仅提供了弹药库的位置(base),还指明了第一发子弹的发射点(current)。
二、 深入理解:为什么寄存器能写入"内存地址"?
很多人误以为寄存器只能存"0"或"1",这其实是一个误区。在嵌入式系统架构中,寄存器的功能远比开关丰富。
-
寄存器的分类与本质
控制/状态寄存器:用于存储 0/1 开关信号(如中断使能、启动位)。
地址/数据寄存器:用于存储数值。在 32 位系统下,一个内存地址本质上就是一个 32 位的数字。硬件的寄存器本质上就是一组 32 位的触发器(Flip-Flops),它们完全能够存储并锁定这个 32 位的数字。
-
内存映射机制 (MMIO)
在 Linux 中,SDMA 的控制台被映射到了系统的地址空间。当你向 base_bd_ptr 赋值时,内核实际上是通过内存映射方式,将 32 位的地址值写入了硬件控制器对应的存储单元。
c
static void sdma_enable_channel(struct sdma_engine *sdma, int channel)
{
/*
* writel: Linux 内核提供的写入 IO 内存的原子操作函数。
* sdma->regs + SDMA_H_START:
* SDMA_H_START 是 SDMA 硬件的"通道启动寄存器"偏移地址。
* sdma->regs 是该控制器在 SoC 物理地址空间中的基地址映射。
*
* 作用:
* 该寄存器是一个"门铃(Doorbell)"寄存器。向对应的位写入 1,
* 就会告诉 SDMA 硬件引擎:"你的第 N 号通道已经准备好了描述符(BD)清单,
* 现在可以立刻开始执行了。"
*/
writel(BIT(channel), sdma->regs + SDMA_H_START);
}在 C 语言和 Linux 内核中,BIT(n) 是一个非常经典的宏,它的定义通常是:
#define BIT(n) (1 << (n))
-
什么是 << (左移操作)?
<< 是位运算符,意思是把二进制数字"向左移动若干位"。
数字 1 的二进制形式是:...00000001
如果你让它左移 2 位 (1 << 2),就会变成:...00000100
-
为什么结果是 0x04?
我们来对比一下二进制和十六进制的换算:
1 << 0 (移动 0 位):...00000001 -> 十六进制是 0x01
1 << 1 (移动 1 位):...00000010 -> 十六进制是 0x02
1 << 2 (移动 2 位):...00000100 -> 十六进制是 0x04
1 << 3 (移动 3 位):...00001000 -> 十六进制是 0x08
-
在 DMA 硬件里为什么要这么做?
硬件芯片里的寄存器通常是 32 位的(就像一行 32 个开关)。
如果这个芯片支持 32 个 DMA 通道(通道 0 到 通道 31),芯片工程师通常不会给每个通道分配一个单独的寄存器,而是设计一个寄存器,其中的每一个位(bit)对应一个通道:
第 0 位(Bit 0)如果被写为 1,代表"启动 0 号通道"
第 1 位(Bit 1)如果被写为 1,代表"启动 1 号通道"
第 2 位(Bit 2)如果被写为 1,代表"启动 2 号通道"
1.2.5 配置 RX DMA 通道 总结
c
/* 1. 配置 RX DMA 通道 */
/* 准备 RX DMA 描述符:指定 RX 通道、物理内存地址、块数、方向(设备到内存)、中断标志等 */
desc_rx = dmaengine_prep_slave_sg(master->dma_rx,
rx->sgl, rx->nents, DMA_DEV_TO_MEM,
DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
/* 若描述符申请失败,则立即返回错误 */
if (!desc_rx)
return -EINVAL;
/* 将 DMA 接收完成后的回调函数注册到描述符中 */
desc_rx->callback = spi_imx_dma_rx_callback;
/*
将 SPI 私有数据结构体作为参数传递给回调函数,
* spi_imx 是你的私有数据结构体 (struct spi_imx_data *)。
* 通过强制类型转换将其转化为通用指针 void *,存入描述符中
*/
desc_rx->callback_param = (void *)spi_imx;
/* 将 RX 描述符提交到 DMA 引擎的等待队列中 */
dmaengine_submit(desc_rx);
/* 重置 RX 完成量 (completion),用于后续在中断中唤醒进程 */
reinit_completion(&spi_imx->dma_rx_completion);
/* 正式向硬件下达启动指令,此时 RX 通道已准备好在有数据到来时搬运至内存 */
dma_async_issue_pending(master->dma_rx);-
任务准备 (dmaengine_prep_slave_sg):
这是驱动与 DMA 框架的"契约签订"阶段。你将分散的物理内存碎片(scatterlist)、传输方向(DEV_TO_MEM)以及控制参数(如 INTERRUPT)提交给 DMA 控制器。此时,驱动只是构建好了任务清单(描述符 Descriptor),硬件尚未真正开始工作。
-
上下文绑定与提交 (callback & dmaengine_submit):
上下文绑定:
desc_rx->callback_param = (void *)spi_imx; 这步极其关键。它将"现场数据"打包进任务描述符。因为 DMA 完成时处于中断上下文,它不知道你是谁,只有通过这个"标签"才能在回调中找回 spi_imx 实例。
放入队列:
dmaengine_submit(desc_rx); 将任务放入该 DMA 通道的调度队列中。此时任务处于"待命"状态,等待控制器执行。
-
同步机制初始化 (reinit_completion):
这一步是同步流程的"清零"。通过重置 completion,确保了之前传输留下的"已完成"状态被清除,使得当前进程能够进入受控的睡眠状态,并等待未来那个唯一的回调来将其唤醒。
-
硬件点火 (dma_async_issue_pending):
这是真正的"点火"动作。在此之前,DMA 硬件就像是在沉睡,它虽然知道队列里有任务,但还没开始处理。调用此函数后,驱动直接操作硬件寄存器,通知 DMA 引擎:"立刻从队列里取任务并开始物理搬运"。
1.2.6 配置 TX DMA 通道 总结
-
任务准备 (dmaengine_prep_slave_sg):
与 RX 类似,这是驱动向 DMA 框架提交传输意图的阶段。不同的是,传输方向设定为 DMA_MEM_TO_DEV,即数据从主存(缓冲区)流向 SPI 总线设备。此时驱动仅完成了发送任务清单(描述符)的创建,数据仍静止在内存中。
-
错误防御与上下文绑定 (rollback & callback):
防御性回滚:由于 TX 配置晚于 RX,为了防止 SPI 全双工模式下出现"一端忙、一端空"的逻辑死锁,若 TX 配置失败,驱动会立即调用 dmaengine_terminate_all(master->dma_rx) 强行撤销已经就绪的 RX 任务。
上下文绑定:将 spi_imx 私有数据实例通过 callback_param 挂载到描述符上,确保发送完成后,中断回调能够精准识别是哪个 SPI 通道完成了发报任务。
-
队列提交与同步准备 (dmaengine_submit & reinit_completion):
入队:dmaengine_submit(desc_tx) 将配置好的 TX 任务推入 DMA 引擎的虚拟执行队列。
同步清零:reinit_completion 将 TX 的完成量重置,清除了历史传输留下的状态痕迹,为即将进入的"等待发送完成"状态做好逻辑清场。
-
硬件点火 (dma_async_issue_pending):
这是 TX 的启动时刻。驱动通过写入硬件寄存器(SDMA_H_START),将之前入队的 TX 任务提交给 SDMA 硬件引擎。一旦执行此操作,DMA 引擎开始从内存地址搬运数据流向 SPI 发送 FIFO,开启了真正的物理总线传输。
1.2.7 SPI 全双工执行
虽然驱动代码中 RX 和 TX 的 dma_async_issue_pending 是先后执行的(有微秒级的时序差),但硬件却能完美实现全双工传输。
这背后的秘密在于:DMA 只是"数据搬运工",而 SPI 控制器才是"总线指挥官"。
以下是其背后的核心机制:
-
真正的"同步"是由 SPI 控制器硬件完成的
SPI 协议的物理特性决定了:有时钟(SCK)才有数据交换。
在 SPI 主机模式下,一旦你启动了 SPI 控制器并开始发送数据,SCK 时钟线就会不断产生脉冲。
只要 SCK 在跳动,MOSI(发送)和 MISO(接收)线上的数据就会同时发生位移(Shift)。
硬件机制:SPI 控制器的内部逻辑会自动把从 MISO 进来的位(Bit)推入 RX FIFO,同时从 TX FIFO 取出一个位推到 MOSI。这是一个硬件层面的"原子动作"。
-
为什么 DMA 的启动有时差没关系?
虽然你先调了 RX 的 issue_pending,后调了 TX 的 issue_pending,但在纳秒级的时间尺度上,它们产生的影响分别是:
RX 启动后:DMA 引擎处于"饥饿"状态。它盯着 RX FIFO,发现里面是空的(因为还没开始传),所以它静静地在等待,不占用总线。
TX 启动后:DMA 引擎开始从内存搬数据进入 TX FIFO。一旦 TX FIFO 满了,硬件逻辑会自动开始通过 SPI 发送数据,产生 SCK 时钟。
关键点在于:
SPI 控制器只有在检测到 TX FIFO 有数据且使能了发送时,才会产生 SCK。而只要 SCK 一产生,接收(RX)也就自动开始了。所以,即便 RX 比 TX 早启动几十个微秒,它仅仅是多等了那几十微秒而已,完全不影响全双工的同步性。
-
为什么"先启动 RX,后启动 TX"是工业标准?
在 Linux 的 SPI 驱动中,你几乎总能看到:
先点火 RX DMA
再点火 TX DMA
这不是为了同步,而是为了防溢出 (Overrun Prevention):
如果先启动 TX,数据瞬间爆发式进入 FIFO,可能在 RX DMA 还没来得及响应、还没准备好搬运之前,数据就已经溢出了(RX FIFO Full)。
先启动 RX,意味着让"搬运工"先就位。一旦数据开始流动,DMA 已经准备好即时清空 FIFO,从而确保系统在高吞吐量下不会丢失任何一个字节。
总结
SPI 的全双工不是靠"两个 DMA 的启动指令"同步的,而是靠 SPI 总线的物理特性(SCK 时钟) 来强制同步的。
DMA 的作用:仅仅是保证 FIFO 不空(TX)或不满(RX)。
SPI 控制器硬件的作用:通过 SCK 产生时钟,强制保证发送和接收的动作步调一致。
所以,你不需要担心这两行代码的时序差。只要确保它们都配置正确,物理层面的"时钟"会自动把它们拉到同一水平线上。