我的网站原文地址:www.javayong.cn/md/ocr/01-R...
我在学习使用 PaddleOCR 时,在本地 Mac M1 上进行了测试,发现 PaddleOCR 的性能表现并不理想------处理每张图片大约需要 5 秒。于是我开始寻找替代方案,意外发现社区中有大量开发者推荐 RapidOCR。
这不禁让我思考:为什么 RapidOCR 能够如此快速?
今天这篇文章,我们将深入探讨 RapidOCR 的核心优势,剖析其高性能背后的技术秘密------ONNX,最后还会介绍具体的使用方法。
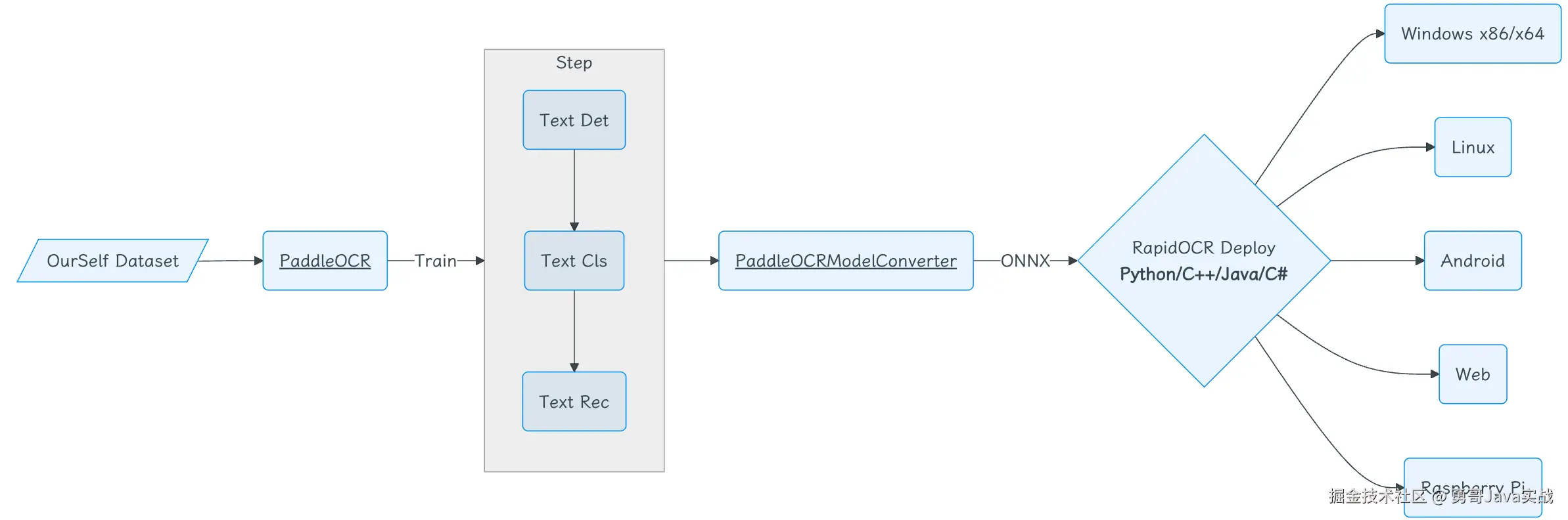
RapidOCR 简介
RapidOCR 是一款完全开源免费、支持离线快速部署的多平台多语言 OCR 工具,以极致的速度与广泛的兼容性为核心优势。
鉴于 PaddleOCR 在工程化方面仍有优化空间,RapidOCR 致力于简化并加速 OCR 模型在各类终端设备上的推理部署。项目创新性地将 PaddleOCR 模型转换为高度兼容的 ONNX 格式,并基于 Python、C++、Java、C# 等多种编程语言实现了跨平台的无缝移植,让开发者能够轻松上手、高效集成。
看到这里,你可能会产生疑问:什么是 ONNX?
什么是 ONNX
ONNX(Open Neural Network Exchange,开放神经网络交换)是一种用于表示深度学习模型的开放格式。它定义了模型的数据结构和计算图,使得不同深度学习框架训练的模型可以互相转换和使用。
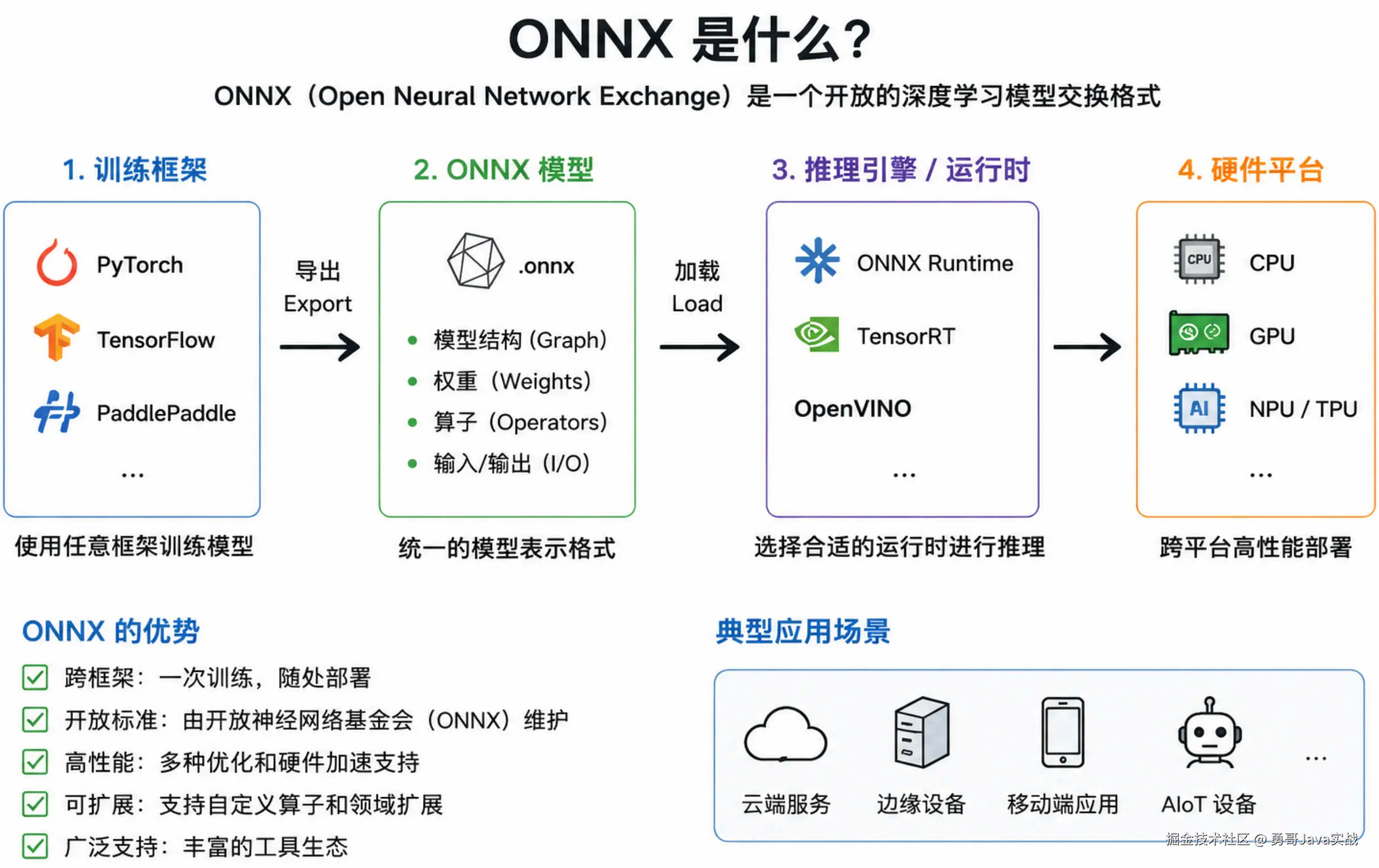
它的主要特点是:
- 跨框架兼容:支持 PyTorch、TensorFlow、MXNet 等主流框架的模型导出
- 跨平台部署:可在不同硬件平台和操作系统上无缝运行
- 高性能推理:支持多种推理优化技术,显著提升模型运行效率
- 可扩展架构:支持自定义算子,便于功能扩展
开发者可以使用任何支持的框架训练模型,然后导出为 ONNX 格式,再使用任何支持 ONNX 的推理引擎进行部署。
以机器视觉领域为例,C# 作为应用开发的主流语言,ONNX 格式因此备受青睐。开发者无需安装庞大的 PaddlePaddle 框架,也不必使用 Python 编写识别算法,直接使用 ONNX Runtime 库即可完成所有工作,极大提升了开发效率。
简而言之,ONNX 就像是深度学习模型的"通用语言",让模型能够在不同的环境和平台之间自由迁移。
快速开始
首先创建一个 Python 工程,在依赖文件中添加依赖:
ini
# OCR
rapidocr==3.9.0接下来封装一个 RapidOCR 示例:
python
def example_3_chinese_english_mixed():
# 创建 RapidOCR 实例(使用默认参数,自动检测多语言)
ocr = RapidOCR()
# 读取图片
img = Image.open(TEST_IMAGE_1)
img_array = np.array(img)
print(f"图片信息: {img.size} {img.mode}")
# 执行 OCR
result = ocr(img_array)
# 转换结果格式(RapidOCR 3.8+ 返回 RapidOCROutput 对象)
result = convert_result(result)
# result 格式: [[[x1,y1],[x2,y1],[x2,y2],[x1,y2]], (文本, 置信度)]
print(f"\n检测到 {len(result)} 个文本框\n")
for i, (box, (text, score)) in enumerate(result, 1):
print(f"{i}. 文本: {text}")
print(f" 置信度: {score:.4f}")
print(f" 坐标: {box}\n")
def convert_result(result):
"""
将 RapidOCR 3.8+ 的 RapidOCROutput 对象转换为旧格式
Args: result: RapidOCR 返回的结果(可能是 RapidOCROutput 对象或列表)
Returns: 旧格式列表: [([[x1,y1],[x2,y1],[x2,y2],[x1,y2]], (text, confidence)), ...]
""" if hasattr(result, 'boxes') and result.boxes is not None:
# RapidOCROutput 对象
boxes = result.boxes
txts = result.txts
scores = result.scores
return [[box.tolist(), (txt, float(score))]
for box, txt, score in zip(boxes, txts, scores)]
return result # 已经是旧格式
打印结果:
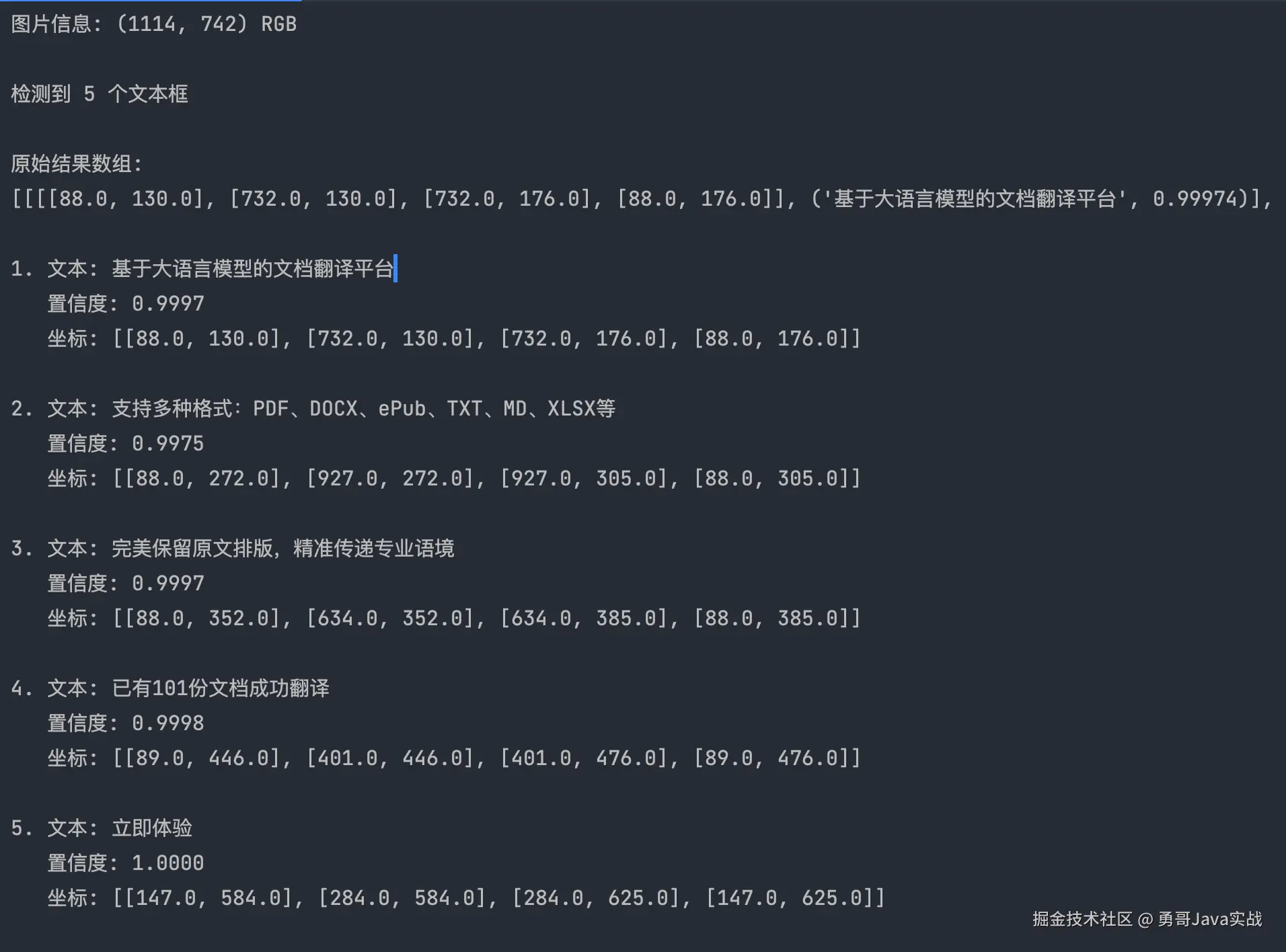
RapidOCR 的识别结果采用以下格式:
arduino
[
[box_points, text, score],
[box_points, text, score],
...
]字段说明:
box_points:文本框的四个顶点坐标text:识别出的文本内容score:置信度分数(0-1 之间,越接近 1 表示识别结果越可靠)
图片 OCR 样式示例:

总结
RapidOCR 通过采用 ONNX 格式和多种推理引擎优化,成功实现了高性能、高精度的 OCR 识别能力,其开源、跨平台的特性使其成为 OCR 领域的优秀选择。
如果你也遇到了 PaddleOCR 的性能瓶颈 (没有 GPU 资源),不妨尝试一下 RapidOCR,相信会给你带来惊喜。