先给大家看看我当前的使用情况,按照tokscale的统计,我总共花了$1.8K美金(¥12.2K)的token
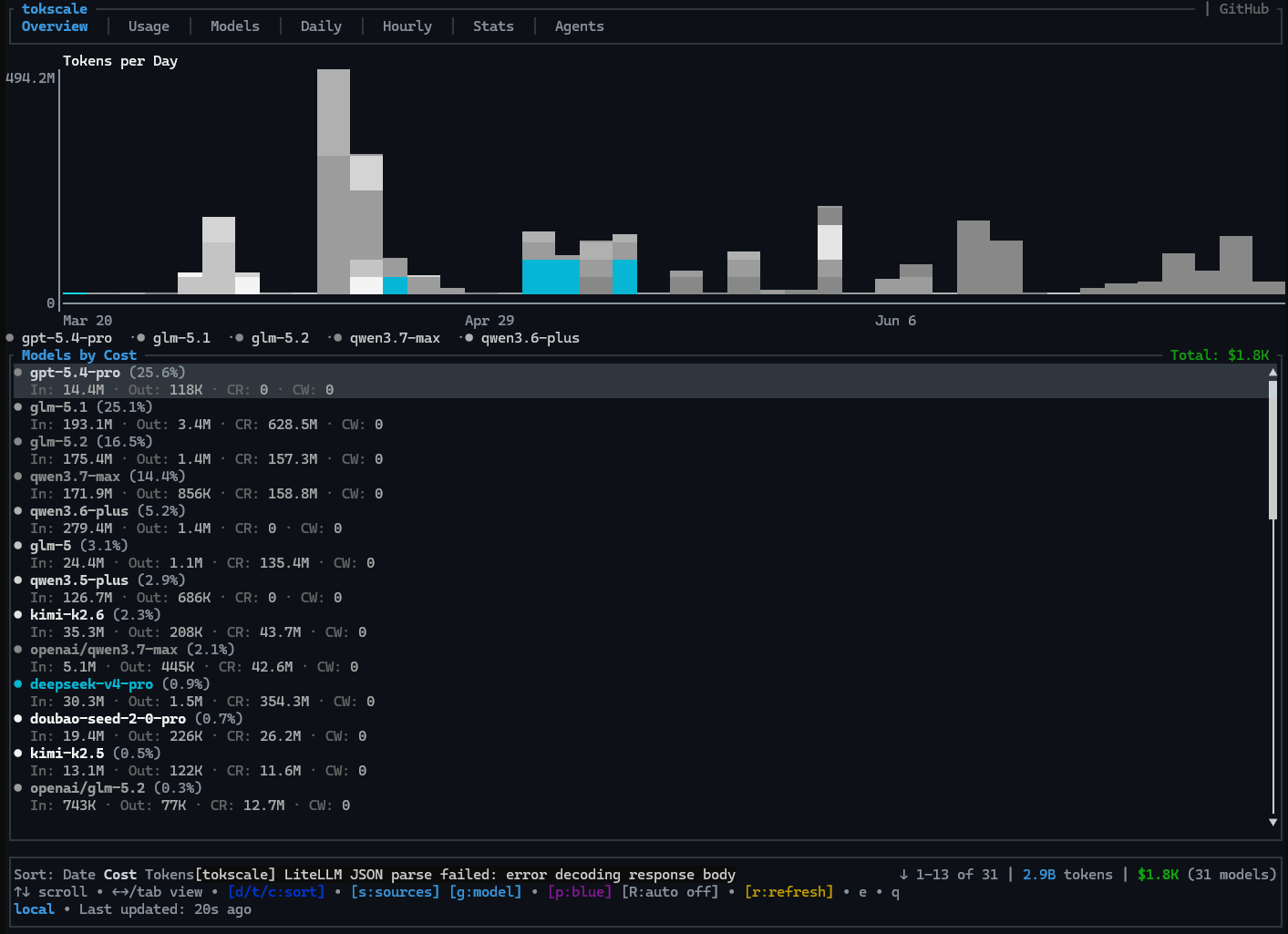
我主要是周末在家休息的时候用,可以从我的日使用情况看出,基本都是周六周日使用
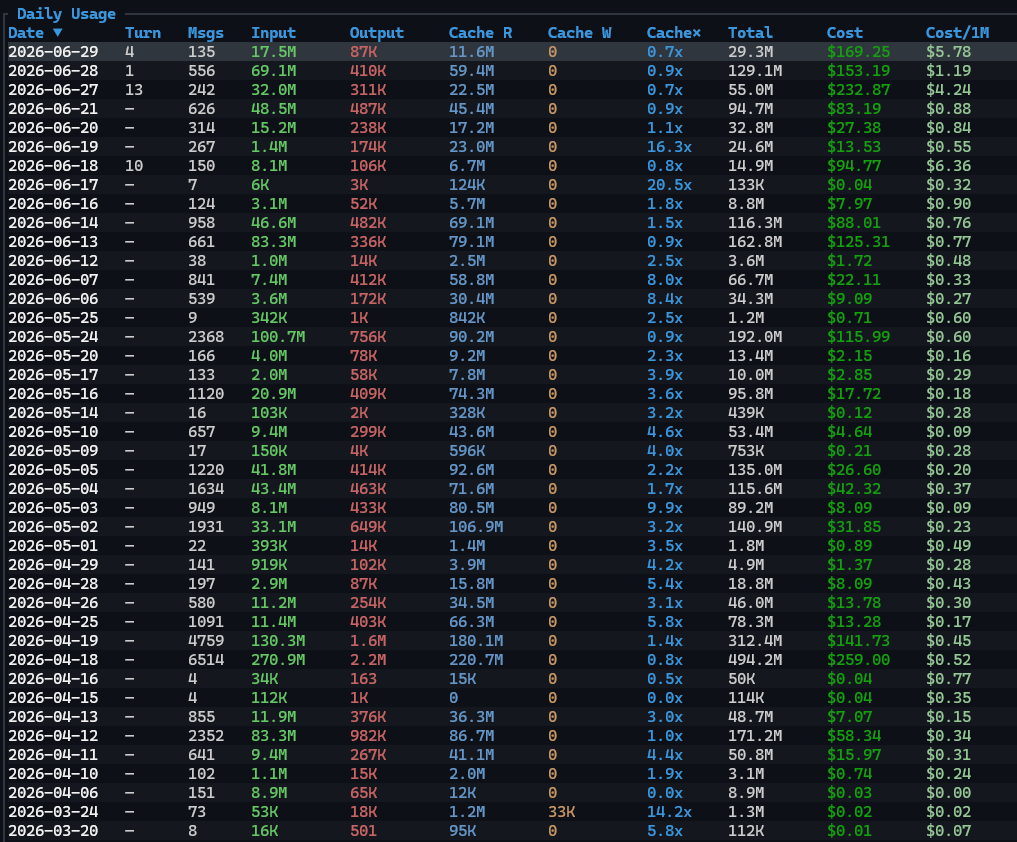
我目前消耗token的最多的模型是glm-5.1,花了8个亿token,排第二的是deepseek-v4-pro,花了3.86亿,glm-5.2、qwen3.7-max目前都花了3个多亿,这还只是我周末在家闲的时间用的情况,我在单位使用量是这里的5倍左右
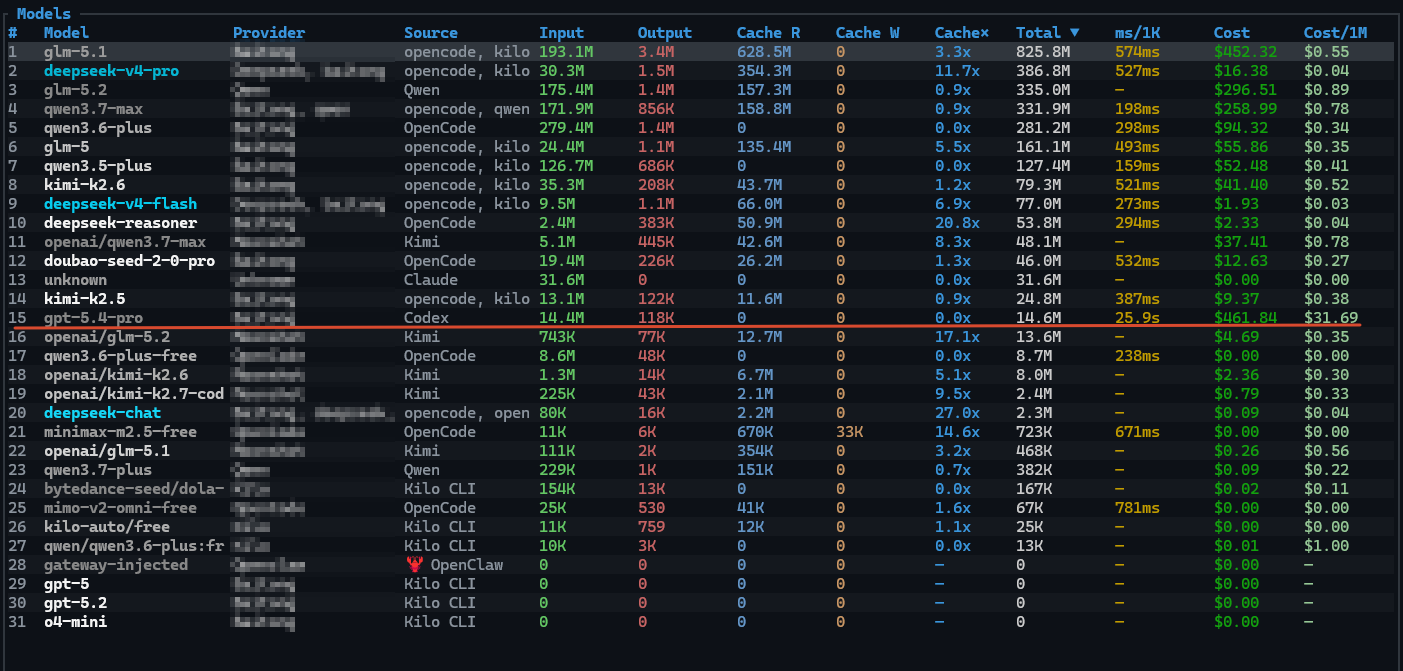
上面这张图也可以看出国产模型在价格上的优势,gpt-5.4-pro我只用了1400万token,就花了$461,是我所有模型支出最高的,比花了8亿token的glm-5.1还高,目前体验也没有明显的差距,有些问题glm解决不了,切换到gpt-5.4-pro也还是解决不了
上面这张图也可以看出我用的工具,opencode、claude、codex、qwen code、kilo code、kimi code我都用过,在公司我还安装了cline、ZCode、continue等等工具,对当前不同模型不同agent工具我的使用感受分享一下
我最近也vibe coding了一个开源项目:Vibe Coding------Qt高性能绘图库QIm,大家有兴趣可以去了解
模型
和广大感受一样,国内编程最强 glm-5.2,这点毋庸置疑;之前的 glm-5.1 也很强,这是我的主力编程模型。qwen 系列除了 3.7 外表现都一般,但 qwen3.7-max 在编程领域有很大突破,至少我体验比 kimi-k2.7-code 要好。kimi 在 qwen3.7 以前一直是我编程的第二选择,qwen3.7 出来后 kimi 暂时排第三。deepseek-v4-pro 强项不在编程,基本编程我都不用 deepseek,但规划和探索我经常用到。截至 2026 年 7 月初,编程领域国内模型我的排名如下:
glm-5.2 > qwen3.7-max > kimi-k2.7-code > glm-5.1 >= kimi-k2.6 >= deepseek-v4-pro有些工具(如 opencode + oh-my-openagent)可以为不同角色配置不同模型。例如 omo 我搭配的主力写代码是 glm 系列,审查规划用 deepseek,探索用 deepseek flash,视觉相关用 qwen 的 plus 多模态系列,这是我之前的搭配。oh-my-openagent 的作者认为 kimi 比 glm 好,但我的体验感觉还是 glm 比 kimi 好。
agent 工具
目前 AI 编程的主流工具,第一类是以 claude code、codex、opencode 为代表的 CLI 工具及其对应的插件和桌面端。国内类似的工具有 qwen code、kimi code、mimo code,还有智谱的 ZCode------ZCode 相对特殊,只提供 GUI 没有 CLI。这些 CLI 端加持插件后能力提升会很大,例如 oh-my-xx 系列插件,但有时也会过度设计,这个后面会讲到。
第二类是基于 VSCode 魔改的,如 Cursor、Trae、Qoder、CodeBuddy 等。
第三类是提供 VSCode 插件、完全依赖 VSCode 生态的,最经典的有 cline、kilo code、roo code(已停止维护)、continue。
上面提到的工具,除了 CodeBuddy 和 mimo code 我都使用过。
由于公司提供了 coding plan 且额度无限(但只有国产模型),基本所有新模型我都体验过,且在不同工具上都有体验(主要是 CLI 端),因此可以横向比较不同工具和不同模型的能力。
我体验较深的是第一类------claude code、codex、opencode 这些工具,可以自由配置 coding plan,不需要登录,内网可用。第二类 VSCode 魔改的都需要登录,在我公司内网无法使用。第三类基于 VSCode 插件的目前能力相对较弱,且 claude code、codex、opencode 自己也都提供了 VSCode 插件,第三类目前基本没什么生存空间,kilo code也开始发行了cli端。
下面是我对这些工具的能力排名:
claude code ≈ codex > qwen code > kimi code > opencodeVSCode 魔改类我冲过 Qoder 的会员,效果挺好,但也非常贵,说实话,我个人感觉效果和 Cursor 不相上下甚至是比 Cursor 好用的,前提是你充了会员,Trae 唯一优点只有免费,Agent能力非常一般
cursor ≈ qoder > traeCodeBuddy没用过不做评价
VSCode 插件版本如 cline、kilo code、continue,总体能力和没装插件的 opencode 差不多。
opencode 安装了 oh-my-openagent 插件后能力接近 qwen code,但达不到 codex,而且效率会低很多,token 花费也大很多。
以上工具迭代速度非常快,不要以一个月前的印象来评价,大家可以关注它们的 GitHub 主页,看看 issues。
AI 编程的一些经验
AGENTS.md 和 文档构建
基本所有工具都带 /init 命令,但很多人不清楚这一点,我看我团队AI Agent是否用的好,就先看项目根目录下是否存在AGENTS.md文档,如果连这个文档都没有,那说明连Agent工具都不会用,目前我项目里Claude.md,Qwen.md都只有一句话:read AGENTS.md,统一到一个文件中
AGENTS.md 是解决 AI 编程工具没有记忆的共同痛点,一份好的 AGENTS.md 应该包含:
- 项目概述:项目是什么、用什么技术栈、解决什么问题
- 目录结构:关键目录和文件的职责说明
- 编码规范:命名约定、格式化规则、注释风格
- 构建与测试:怎么编译、怎么跑测试、有什么前置条件
- 文档地图:指引涉及某个模块应该阅读哪些文档
- 踩过的坑:已知的陷阱和注意事项,比如某个依赖有版本兼容问题、某个路径不能改
实际效果非常明显,且你要时刻想着更新它或补充它,我经常一个事情如果Agent千难万难终于搞定,我会让Agent总结,并把必要的内容添加进 AGENTS.md 中,同时一段时间后我也会让Agent主动更新一下AGENTS.md文件
在ai流行前,除非你的项目是开源项目,否则一般很少会花大精力维护文档,但 ai 流行后,文档会变得非常关键,我项目里必定存在docs文件夹,这里面存放项目的架构、构建测试、开发规范、开发说明、业务描述、使用教程等内容。尤其是开发规范,你应该把项目的开发规范订好,并在AGENTS.md中指引过去
开发规范包括:
- 命名约定
- 注释规范
- 文档撰写规范·
- 代码风格及特殊约定
开发规范你要不断完善,当你发现某次任务有偏差,你就要思考的是如何完善你的"制度",而不是放任不管,这个文档的开发规范就是你的"制度",就像每个公司都有自己的规章制度一样,规章制度的建立都是在每次惨痛教训后凝炼出来的内容,ai编程也一样,你这个项目就好比一个公司,你要有你的制度,每次ai做错了做的不好了,你首先要思考你的制度是否有问题,是否有遗漏,这是后续让agent健康工作的基础。
两个提升效果的关键 Skill:superpowers 与 grilling
不同的 skill 会让 AI 用不同的方法论来解决问题。skill千千万,我体验下来,有两个 skill 对编程效果的提升特别显著。
第一个是 superpowers。
superpowers 的核心思路是"先思考再动手",有一套较好的工作流,对于一些预设编排弱的 agent 工具尤其需要,例如没有安装omo插件的opencode,但claude code,codex这些实际没有必要安装,因为superpowers的思路都已经集成进他们的编排里面。
superpowers的spec和plan机制我觉得设计的挺好,比oh-my-openagent的计划做的更好,opencode后期我觉得不开omo,直接用superpowers体验效果更佳
第二个是 grilling (以及它的变体 grill-with-docs)。
grilling 是一种对抗式审查的思路。当你有一个方案或设计时,不要急着让 AI 去实现,而是让 grilling skill 对方案进行无情地质疑和挑战。它会从各个角度提问,从而暴露出你自己都没想到的问题。
我经常在方案设计阶段使用 grill me。流程是这样的:先让 AI 出一个初步方案,然后启动 grilling,让它对自己的方案进行多轮拷问,每轮都会发现新问题,然后迭代修正方案。几轮下来,方案的成熟度远高于初版。当然,有时候是真的在拷问你,不要无脑什么事情都启用grill me,有时候问题多到让你烦,其实现在agent工具强大后,大部分agent的plan模式能替代grill me的功能,且提问的度把握的还可以。
superpowers 自身有 brainstorm 也可以做类似grill me的活,但当前codex, qwen code这些工具的编排已经挺好,不需要superpowers加持,反而有时候grill me用的更多,但如果活比较大,涉及面比较广,我还是会启用superpowers
命令范围要精准:大任务能完成,但细节会丢失
AI 编程的一个重要经验是:你让 AI 做的事情越大,它丢的细节就越多。
有很多人吐槽vibe coding像下图一样

如果你没有什么编程基础,让ai生成一个大项目,的确有可能会像上图一样,但我经历过几个公司的经验来看,普通人开发的软件也好不到哪里去,反而有时候开源的项目更有水平。在一个小任务里,ai写的代码比的过90%的普通程序员,但大任务就不行。
当前(2026-06月)AI 的上下文窗口虽然达100万,大任务也都能完成,但我实际体验下来经验是,任务越大,细节丢失越多。上下文窗口大不代表注意力分配得好,当你给 AI 一个笼统的大任务,比如"帮我重构这个模块"或"帮我实现这个功能",它确实能产出一个看起来完整的结果,但如果你仔细审查,会发现大量细节被悄悄忽略了,有些情况甚至会偷懒。因为很多大任务都是基于子agent来完成,在任务派发过程中的agent间沟通有时候会丢失细节
AI 在处理大任务时,会本能地优先保证主干逻辑跑通,而把那些"看起来不重要"的细节牺牲掉。问题是,这些一个项目的成功及稳定性,这些细节往往是代码质量的关键。
我的做法是把大任务拆成精准的中小任务。举个例子,与其说"帮我实现用户管理模块",不如让AI先根据你的代码库制定一个"用户管理模块"的任务规划,提示词模板大概如下:
markdown
我需要构建xxx模块,{xxxxx一堆需求描述}
---
在构建前深度探索此项目,提出一个任务规划,把任务拆解为若干个可以独立实施和验证的中小任务。并生成一个实施计划,每个任务只描述具体要做什么、涉及的模块,以及简要的验收标准,不要提供任何实现代码。任务之间尽量保持低耦合,每个任务完成后应能独立测试,不阻塞其他任务。按合理的实施顺序输出任务清单,方便我逐步执行。在一些能自定义agent的工具,我会设计一个任务拆解师的agent角色,让他把我需求拆解为若干个任务,在逐个执行
后续你每次可以基于拆解的任务逐个执行和调试,这样效果明显会比一次性完成一个大任务更好,也更可控,否则审核ai代码都会无比吃力。那些鼓吹Agent编程24小时的的确是可以编,但代码质量会飞速下降,我也不建议ai跑太久没有人为介入查看。
Vibe Coding 时代程序员的价值
AI 编程能力越来越强,很多人开始讨论"程序员会不会被淘汰"。我的观点是:普通程序员需求变少,但也无法淘汰,普通程序员就像大楼的监工,监督和审核事情免不了,沟通查bug这些都需要;而高级程序员不仅不会淘汰,反而会更关键。
原因很简单:AI 擅长的是"执行"------给它明确的指令,它能快速产出代码。但"做什么"和"按什么路线做最符合公司利益"这两个问题,AI 自己是回答不了的。这两个问题恰恰是架构师的职责,ai替代的是纯粹的码农。
在 vibe coding 时代,程序员的角色会从"写代码的人"转变为"指挥 AI 写代码的人"。这个角色更接近架构师:
- 你决定技术选型:用什么框架、什么架构模式、什么数据结构。AI 可以给你建议,但最终决策权在你。一个错误的选型,AI 会忠实地帮你实现得很漂亮,但方向就是错的。
- 你设计模块边界:哪些功能放在一起、哪些要解耦、接口怎么定义。好的模块边界让 AI 在每个模块内的编程都简单清晰;差的边界会让 AI 的代码充满跨模块的隐式依赖,越写越乱。
- 你制定规范 :命名约定、错误处理策略、日志规范、测试标准。这些规范写进
AGENTS.md,AI 就能稳定遵循;没有规范,AI 每次的输出风格都不一样,代码库会越来越混乱。 - 你审查质量:AI 产出的代码,你需要判断是否正确、是否安全、是否可维护。AI 不会主动告诉你"这段代码有安全风险"或"这个设计在数据量大了之后会有性能问题",这些需要人来把关。
一个好的架构能让 AI 的编程效果成倍提升。我自己的体会是:当项目结构清晰、模块职责明确、规范文档完善时,AI 几乎可以独立完成大部分开发任务,我只需要做审查和微调。反之,当项目结构混乱、规范缺失时,AI 产出的代码质量也随之下滑,需要大量人工修正。
所以未来的竞争力不在于"能不能写代码"------这已经是 AI 的基本能力了------而在于"能不能设计出让 AI 高效工作的架构"。这要求你对系统设计、领域建模、工程规范有深入的理解,这些恰恰是高级程序员和架构师的核心能力。
低端程序员的工作(CRUD、模板代码、简单 bug 修复)确实会被 AI 大量替代,这不是危言耸听。但能做架构决策、能把控系统质量、能让 AI 更好地工作的人,价值只会越来越高。