目录
1.摘要
本文面向危险品仓库巡检中的异构多 UAV,研究任务分配与无冲突路径规划联合优化。现有启发式方法难以兼顾求解时间与解质量,本文提出强化学习辅助框架:先用带任务约束mTSP 转换完成任务分配,再用 MAPPO 多智能体策略生成无冲突路径,该路径策略可从少量 UAV 训练场景扩展到更多 UAV。仿真表明,该框架在求解时间、路径质量和可扩展性上优于现有算法。
2.问题描述
考虑 n n n 架异构 UAV { u 1 , u 2 , ... , u n } \{u_1,u_2,\ldots,u_n\} {u1,u2,...,un} 在仓库内执行检测任务。起点集合为 V s = { v s 1 , ... , v s n } V_s=\{v_s^1,\ldots,v_s^n\} Vs={vs1,...,vsn},终点集合为 V d = { v d 1 , ... , v d n } V_d=\{v_d^1,\ldots,v_d^n\} Vd={vd1,...,vdn},任务目标集合为 V t = { v t 1 , ... , v t m } V_t=\{v_t^1,\ldots,v_t^m\} Vt={vt1,...,vtm}。对每个目标 v t i v_t^i vti,函数 c i = f A ( v t i ) c_i=f_A(v_t^i) ci=fA(vti) 给出可执行该任务的 UAV 子集。工作空间用有限无向图 G = ( V , E ) G=(V,E) G=(V,E) 表示,其中 V = V s ∪ V d ∪ V t V=V_s\cup V_d\cup V_t V=Vs∪Vd∪Vt, E = V × V E=V\times V E=V×V。为简化建模,假设 UAV 高度恒定,地图为 x × y x\times y x×y 的二维平面。
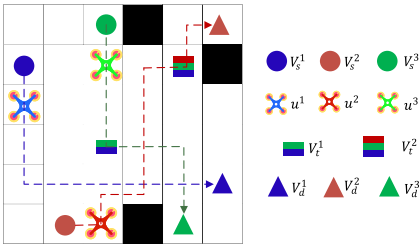
UAV 配备传感器,可探测静态和动态障碍。若 UAV 与任一障碍欧氏距离不小于安全距离 ϵ \epsilon ϵ,则状态安全:
s ( p u i ( t ) ) = { 1 , ∀ o ∈ I , δ u i > ϵ , 0 , otherwise , s(p_u^i(t))= \begin{cases} 1,&\forall o\in I,\ \delta_u^i>\epsilon,\\ 0,&\text{otherwise}, \end{cases} s(pui(t))={1,0,∀o∈I, δui>ϵ,otherwise,
δ u i = ( x u i ( t ) − x o i ( t ) ) 2 + ( y u i ( t ) − y o i ( t ) ) 2 . \delta_u^i=\sqrt{(x_u^i(t)-x_o^i(t))^2+(y_u^i(t)-y_o^i(t))^2}. δui=(xui(t)−xoi(t))2+(yui(t)−yoi(t))2 .
所有 UAV 轨迹为:
τ = { τ i ∣ τ i = ( p u i ( 0 ) , ... , p u i ( T i ) ) } . \tau=\{\tau_i\mid \tau_i=(p_u^i(0),\ldots,p_u^i(T_i))\}. τ={τi∣τi=(pui(0),...,pui(Ti))}.
总体完成时间取最晚到达时间:
T ( τ ) = max ( t i ) , i = 1 , 2 , ... , n . T(\tau)=\max(t_i),\quad i=1,2,\ldots,n. T(τ)=max(ti),i=1,2,...,n.
每个目标点必须出现在具备能力 UAV 轨迹:
P ( v t i ) = { τ j ∣ ∀ u j ∈ c i } . P(v_t^i)=\{\tau_j\mid \forall u_j\in c_i\}. P(vti)={τj∣∀uj∈ci}.
UAV 在任务点需悬停完成检测,悬停时间不小于任务执行时间:
h ( P ( v t i ) ) ≥ g ( v t i ) . h(P(v_t^i))\ge g(v_t^i). h(P(vti))≥g(vti).
联合优化目标为最小化最大完成时间,并满足起点、终点、安全、悬停和任务能力约束:
arg min τ T ( τ ) s.t. p u i ( 0 ) = v s i , i = 1 , 2 , ... , n , p u i ( T i ) = v d i , i = 1 , 2 , ... , n , s ( p u i ( t ) ) = 1 , ∀ t < T i , h ( P ( v t i ) ) ≥ g ( v t i ) , P ( v t i ) = { τ j ∣ ∀ u j ∈ c i } . \begin{aligned} \arg \min_{\tau} \quad & T(\tau) \\ \text{s.t.} \quad & p_u^i(0) = v_s^i, \quad i = 1, 2, \dots, n, \\ & p_u^i(T_i) = v_d^i, \quad i = 1, 2, \dots, n, \\ & s(p_u^i(t)) = 1, \quad \forall t < T_i, \\ & h(P(v_t^i)) \ge g(v_t^i), \\ & P(v_t^i) = \{\tau_j \mid \forall u_j \in c_i\}. \end{aligned} argτmins.t.T(τ)pui(0)=vsi,i=1,2,...,n,pui(Ti)=vdi,i=1,2,...,n,s(pui(t))=1,∀t<Ti,h(P(vti))≥g(vti),P(vti)={τj∣∀uj∈ci}.
3.预备知识
多 UAV 路径规划可表述为 POMDP,记为 ⟨ A , S , O , R , T , γ , ρ 0 ⟩ \langle A,S,O,R,T,\gamma,\rho_0\rangle ⟨A,S,O,R,T,γ,ρ0⟩。每个智能体按策略 π i ( a i ∣ s t ) \pi_i(a_i|s_t) πi(ai∣st) 选择动作并获得奖励。最大折扣回报策略:
π i ∗ = arg max π i E s 0 , a 0 , o 0 , ... ∑ t = 0 ∞ γ t R i ( s t i , a t i ) . \pi_i^*=\arg\max_{\pi_i}\mathbb{E}{s_0,a_0,o_0,\ldots}\sum{t=0}^{\infty}\gamma^t R_i(s_t^i,a_t^i). πi∗=argπimaxEs0,a0,o0,...t=0∑∞γtRi(sti,ati).
策略优化把策略表示为参数函数 π ( θ ) \pi(\theta) π(θ),目标为:
θ ∗ = arg max θ J ( π ( θ ) ) . \theta^*=\arg\max_{\theta}J(\pi(\theta)). θ∗=argθmaxJ(π(θ)).
普通梯度上升为:
θ k + 1 = θ k + α ∇ θ J ( π θ ) ∣ θ k . \theta_{k+1}=\theta_k+\alpha\nabla_{\theta}J(\pi_{\theta})|_{\theta_k}. θk+1=θk+α∇θJ(πθ)∣θk.
为避免策略更新过大,TRPO 用 KL 约束限制新旧策略距离:
π k + 1 = arg max π ∈ Π θ J ( π ) s.t. D K L ( π , π k ) ≤ δ . \pi_{k+1}=\arg\max_{\pi\in\Pi_{\theta}}J(\pi) \quad \text{s.t.}\quad D_{KL}(\pi,\pi_k)\le\delta. πk+1=argπ∈ΠθmaxJ(π)s.t.DKL(π,πk)≤δ.
4.基于多智能体强化学习辅助算法设计
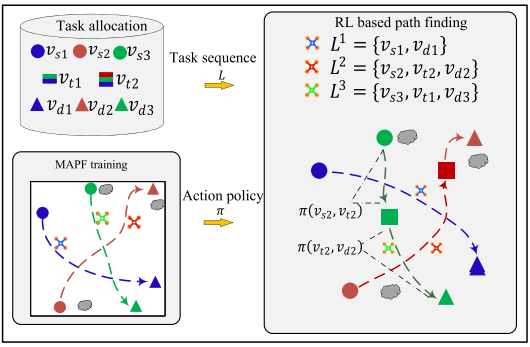
框架包含任务分配、MAPF 离线训练和 MAPF 在线执行三部分。任务分配模块输入起点、终点、任务点和能力约束,输出每架 UAV 的任务序列 L i = { v s i , v t i 1 , v t i 2 , ... , v d i } L_i=\{v_s^i,v_t^{i1},v_t^{i2},\ldots,v_d^i\} Li={vsi,vti1,vti2,...,vdi}。在线执行时,UAV 依序访问任务点,并在相邻任务点之间调用已训练的 MARL 策略完成快速避碰飞行。
任务分配采用带任务约束的 mTSP 转换方法,用现有 TSP 求解器求解,再将单 TSP 回路拆分为各 UAV 的任务序列。
每架 UAV 只需在当前序列段内从起点飞到目标点。状态空间由自身状态 s e g o s_{ego} sego、目标状态 s d e s s_{des} sdes、周围动态障碍 s d y n s_{dyn} sdyn 和静态障碍 s s t a s_{sta} ssta 组成。UAV 与动态障碍状态含位置、速度和航向 x , y , v x , v y , cos θ , sin θ x,y,v_x,v_y,\\cos\\theta,\\sin\\theta x,y,vx,vy,cosθ,sinθ,静态实体只含位置 x , y x,y x,y。
考轨迹用于加速训练,其奖励由当前位置到参考轨迹点集的最近距离给出:
R d _ r e f = min { d i ∣ d i = d i s ( P , P τ ) , P τ ∈ τ r e f } . R_{d\ref}=\min\{d_i\mid d_i=dis(P,P{\tau}),\ P_{\tau}\in\tau_{ref}\}. Rd_ref=min{di∣di=dis(P,Pτ), Pτ∈τref}.
最终奖励为:
R = λ 1 R c _ d + λ 2 R c _ s + λ 3 R d _ d e s + λ 4 R d _ r e f , λ 1 > λ 2 ≫ λ 3 > λ 4 . R=\lambda_1R_{c\d}+\lambda_2R{c\s}+\lambda_3R{d\des}+\lambda_4R{d\_ref}, \quad \lambda_1>\lambda_2\gg\lambda_3>\lambda_4. R=λ1Rc_d+λ2Rc_s+λ3Rd_des+λ4Rd_ref,λ1>λ2≫λ3>λ4.
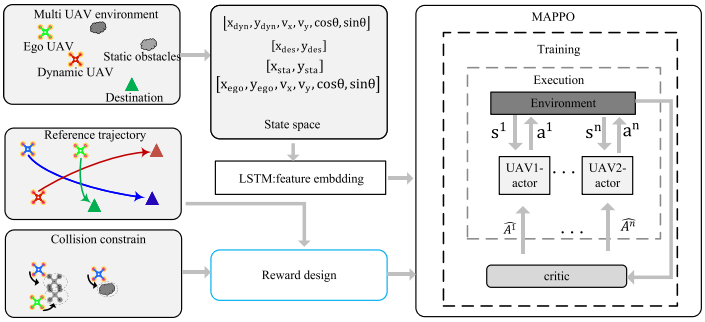
MAPPO 由多个 actor 和一个集中式 critic 组成。训练时 critic 使用全局状态和所有 UAV 动作评估价值;执行时只保留 actor,每架 UAV 根据局部观测独立决策。集中式 critic 的损失为:
L M A P P O V ( ϕ ) = E v ϕ ( s t , a t 1 , a t 2 , ... , a t n ) − y ( t ) 2 , L_{MAPPO}^V(\phi)=\mathbb{E}\leftv_{\\phi}(s_t,a_t\^1,a_t\^2,\\ldots,a_t\^n)-y(t)\\right^2, LMAPPOV(ϕ)=Evϕ(st,at1,at2,...,atn)−y(t)2,
y ( t ) = R t + γ v ϕ ( s t + 1 , a t + 1 1 , a t + 1 2 , ... , a t + 1 n ) . y(t)=R_t+\gamma v_{\phi}(s_{t+1},a_{t+1}^1,a_{t+1}^2,\ldots,a_{t+1}^n). y(t)=Rt+γvϕ(st+1,at+11,at+12,...,at+1n).
所有 UAV 共享 actor 参数,按局部观测更新:
θ k + 1 = arg max θ E L C L I P ( s i , a i , θ ) . \theta_{k+1}=\arg\max_{\theta}\mathbb{E}\leftL\^{CLIP}(s\^i,a\^i,\\theta)\\right. θk+1=argθmaxELCLIP(si,ai,θ).
为捕获周围环境的时间变化,用 LSTM 编码过去若干时刻的障碍状态。经 LSTM 预处理后 MAPPO 状态:
S t = { s e g o t , s d e s t } + f l s t m ( s o b s t − p , s o b s t − p + 1 , ... , s o b s t ) . S_t=\{s_{ego}^t,s_{des}^t\}+f_{lstm}(s_{obs}^{t-p},s_{obs}^{t-p+1},\ldots,s_{obs}^{t}). St={segot,sdest}+flstm(sobst−p,sobst−p+1,...,sobst).
5.结果展示
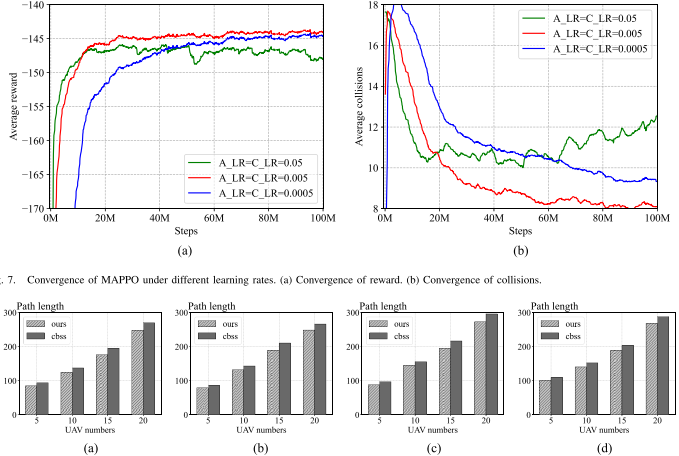
仿真用 Python 和 OpenAI Gym 环境实现,路径规划模块只学习从起点到终点的无冲突飞行,不涉及任务分配。在随机起终点的 5 UAV 环境中训练 MAPPO。不同学习率对收敛影响明显:学习率 0.05 收敛快但最终奖励低、碰撞多;0.0005 太小,模型难收敛;0.005 获得最高奖励和最低平均碰撞次数,因此后续实验采用该学习率。
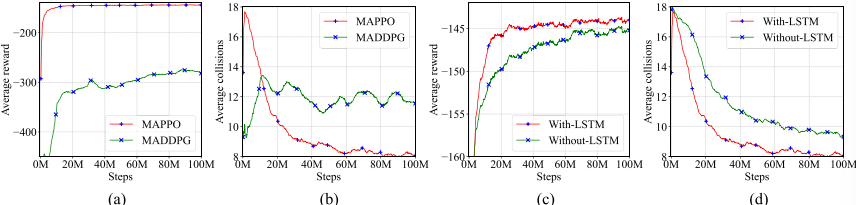
消融实验比较带 LSTM 与不带 LSTM 的 MAPPO。LSTM 能编码周围障碍过去一段时间的运动状态,使 UAV 更好判断动态障碍趋势,因此收敛更快,最终奖励更高、碰撞更少。
本文提出强化学习辅助的多异构 UAV 任务分配与无冲突路径规划框架,用于仓库货物检测类 IIoT 场景。集中式任务分配模块基于 mTSP 转换,按 UAV 功能和任务约束生成最小路径任务序列;分布式路径规划模块基于 POMDP 和 MAPPO,可部署到任意数量 UAV。
6.参考文献
Zhao G, Wang Y, Mu T, et al. Reinforcement-learning-assisted multi-UAV task allocation and path planning for IIoTJ. IEEE Internet of Things Journal, 2024, 11(16): 26766-26777.
7.算法辅导·应用定制·读者交流
xx