原创不易,转载请注明出处。本文基于真实项目实战,完整代码可直接复用。
前言
面试官问:"缓存击穿怎么解决?"
大多数人答:"用 SETNX 互斥锁,只放一个请求去查数据库。"
面试官追问:"还有更好的方案吗?阻塞等待的那些请求,能不能连 Redis 都不用再读一遍?"
答不上来了。
本文介绍一个更优雅的方案------SingleFlight 请求合并 ,并从零手写实现。核心就两个类:ConcurrentHashMap + CompletableFuture,二十行代码搞定。实际用在我自己的 O2O 生活服务平台中,配合 Caffeine + Redis 两级缓存架构,保护了秒杀商品、热门商户等热点数据的访问。
一、缓存击穿是什么
先搞清楚问题出在哪里。
正常情况:
请求 → 查 Redis 缓存 → 命中 → 直接返回(毫秒级,不查 DB)
缓存击穿:
一个热点 Key(比如双 11 秒杀券的库存详情)过期了
→ 请求 1:缓存没命中 → 准备查 DB
→ 请求 2:缓存没命中 → 准备查 DB
→ 请求 3:缓存没命中 → 准备查 DB
→ ...
→ 请求 100:缓存没命中 → 准备查 DB
100 个请求同时打到数据库 → 连接池被打满 → 整个系统不可用
关键词:一个热点 Key 过期 + 高并发 = 缓存击穿。
这三个概念经常被一起问,别搞混了:
| 问题 | 根因 | 典型场景 |
|---|---|---|
| 缓存穿透 | 查的是根本不存在的数据 | 恶意用不存在的 ID 刷接口 |
| 缓存击穿 | 一个热点 Key 过期 | 热门商品详情页、秒杀券库存 |
| 缓存雪崩 | 大量 Key 同时过期 | 批量缓存设了相同的 TTL |
二、SETNX 互斥锁方案(能用,但不够好)
最常见的方案:同一时刻只放一个请求去查 DB,其余排队等着。
java
public String getData(String key) {
// 1. 先查缓存
String data = redis.get(key);
if (data != null) return data;
// 2. 拿锁
RLock lock = redisson.getLock("lock:" + key);
lock.lock();
try {
// 3. Double Check(拿到锁再查一次,可能别人已经重建好了)
data = redis.get(key);
if (data != null) return data;
// 4. 查 DB → 写缓存
data = db.query(key);
redis.set(key, data, 30, TimeUnit.MINUTES);
} finally {
lock.unlock();
}
return data;
}流程如下:
请求 1:拿锁成功 → 查 DB → 写缓存 → 释放锁 → 返回数据
请求 2:等锁... → 拿到锁 → Double Check 读 Redis → 缓存有了 → 返回数据
请求 3:等锁... → 拿到锁 → Double Check 读 Redis → 缓存有了 → 返回数据
...
请求 100:等锁... → 拿到锁 → Double Check 读 Redis → 缓存有了 → 返回数据DB 只查了 1 次,看起来问题解决了。但有一个容易被忽略的瑕疵:
每个等待的请求都要走一遍:
等锁 → 拿锁 → 读 Redis(Double Check)→ 释放锁
虽然 DB 只查了 1 次,Redis 却被读了 100 次,
而且每次抢锁、释放锁都有 CPU 开销。并发越高,这个开销越明显。能不能更省?能不能连 Redis 的 Double Check 都不用做了?
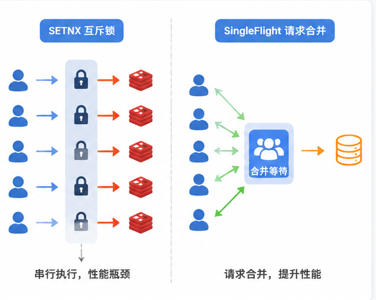
三、SingleFlight 请求合并方案
核心思路:第 1 个请求查 DB 拿到结果,直接把结果共享给所有等待的请求。
请求 1:查 DB → 拿到结果 → 存到"共享盒子"里 → 返回
请求 2:发现有人在查了 → 直接等"共享盒子"的结果 → 拿到同一份数据 → 返回
请求 3:发现有人在查了 → 直接等"共享盒子"的结果 → 拿到同一份数据 → 返回
...
请求 100:同上
DB 只查了 1 次,Redis 的 Double Check 一次都没读,
所有等待的请求直接共享第 1 个请求的查询结果。和 SETNX 的本质区别:
SETNX(排队执行):
请求 1 查 DB → 请求 2 拿锁 → 读缓存 → 释放锁
→ 每个等待的请求最后都要"亲手"读一次缓存
SingleFlight(结果共享):
请求 1 查 DB → 请求 2、3、100 直接拿第 1 个人的结果
→ 只有第 1 个人"动手",其他人"伸手拿"四、手写实现(完整代码)
核心就两个东西:
- ConcurrentHashMap:登记本,记录"哪个 Key 正在被查询"
- CompletableFuture:共享盒子,让等待的请求拿到同一个结果
java
@Component
public class SingleFlightCache {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 正在执行中的请求
* key = 缓存 Key
* value = 该 Key 对应的异步查询任务
*/
private final ConcurrentHashMap<String, CompletableFuture<String>> flyMap =
new ConcurrentHashMap<>();
/**
* 查询缓存,缓存未命中时走 SingleFlight 逻辑
*
* @param key 缓存 Key
* @param dbFallback 查 DB 的回调函数
* @param ttl 缓存过期时间
* @param unit 时间单位
* @return 缓存数据
*/
public String get(String key, Function<String, String> dbFallback,
long ttl, TimeUnit unit) {
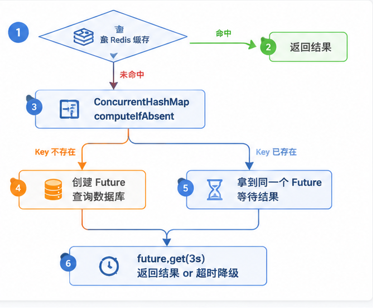
// ====== 第 1 步:先查缓存 ======
String cached = redisTemplate.opsForValue().get(key);
if (cached != null) {
return cached;
}
// ====== 第 2 步:缓存未命中,尝试加入已有的"飞行中"请求 ======
CompletableFuture<String> future = flyMap.computeIfAbsent(key, k ->
CompletableFuture.supplyAsync(() -> {
try {
// 只有第一个请求能进来这里
String dbData = dbFallback.apply(key);
redisTemplate.opsForValue().set(key, dbData, ttl, unit);
return dbData;
} finally {
// 无论成功失败,都要清理,防止内存泄漏
flyMap.remove(key);
}
})
);
// ====== 第 3 步:阻塞等待结果 ======
try {
return future.get(3, TimeUnit.SECONDS); // 3 秒超时
} catch (TimeoutException e) {
// 超时了,清理掉这个 Future,防止后续请求一直等一个永远不会完成的结果
flyMap.remove(key);
return null; // 降级返回 null
} catch (Exception e) {
flyMap.remove(key);
return null;
}
}
}使用方式非常简洁:
java
@Service
public class ShopService {
@Autowired
private SingleFlightCache singleFlightCache;
public Shop getById(Long id) {
String key = "cache:shop:" + id;
// 一行调用,传入查 DB 的回调
String json = singleFlightCache.get(
key,
k -> { // 查 DB 的回调
Shop shop = shopMapper.selectById(id);
return shop == null ? "" : JSON.toJSONString(shop);
},
30, TimeUnit.MINUTES // 缓存 30 分钟
);
return json == null ? null : JSON.parseObject(json, Shop.class);
}
}五、逐行拆解------为什么这么写
5.1 为什么用 ConcurrentHashMap
java
ConcurrentHashMap<String, CompletableFuture<String>> flyMap100 个线程同时读写这个 Map。普通 HashMap 在多线程下会丢数据甚至形成死循环(JDK 1.7 头插法扩容时链表反转导致环形引用)。ConcurrentHashMap 内部用 CAS + synchronized(JDK 8)锁住单个桶,不同桶之间互不影响,读写安全且并发度高。
5.2 为什么用 computeIfAbsent
java
CompletableFuture<String> future = flyMap.computeIfAbsent(key, k ->
CompletableFuture.supplyAsync(() -> { ... })
);computeIfAbsent 是 ConcurrentHashMap 提供的原子方法,将"判断 Key 是否存在"和"不存在则放入"两步合并为一步:
key 不存在 → 执行 lambda 创建 Future → 放入 Map → 返回这个 Future
key 已存在 → 不执行 lambda → 直接返回已有的 Future
三步一气呵成,不会被其他线程插队
→ 保证只有第一个请求能创建 Future,后续请求拿到的是同一个实例如果自己用 if (map.get(key) == null) + map.put(key, value) 分两步写,A 线程和 B 线程可能同时判断 Key 不存在,然后各自创建了一个 Future------合并就失败了。
5.3 为什么用 CompletableFuture
java
return future.get(3, TimeUnit.SECONDS);后续请求调用 future.get() 会阻塞等待 ------线程挂起,不占用 CPU,直到第一个请求查完 DB 返回结果后才被唤醒。相比于 while (result == null) 忙轮询,这种等待方式不消耗 CPU,而且天然支持超时机制。
5.4 为什么 finally 里要 remove
java
.finally {
flyMap.remove(key);
}第一个请求查完了,Future 已经有结果。如果不从 Map 里移除,这个 Entry 会一直留在里面。下一次缓存又过期时,computeIfAbsent 发现 Key 还存在,直接返回一个早已完成的旧 Future------里面装着过期的数据,请求合并不但没生效,还拿到了脏数据。
注意 remove 写在 supplyAsync 的 lambda 的 finally 里,不是写在 get() 的外面:不管查询成功还是抛出异常,finally 都会执行清理。
5.5 为什么设 3 秒超时
java
future.get(3, TimeUnit.SECONDS);如果第一个请求查 DB 非常慢------比如慢 SQL 要跑 10 秒------后续 99 个请求不能全卡住干等 10 秒。超时后降级返回 null,配合空值缓存(短 TTL)兜底,至少不会把请求全憋死。
六、两种方案对比
| 维度 | SETNX 互斥锁 | SingleFlight 请求合并 |
|---|---|---|
| DB 查询次数 | 1 次 | 1 次 |
| Redis 调用次数 | 每人 1 次 GET(Double Check) | 0 次 |
| 等待者做了什么 | 等锁 → 拿锁 → 自己读 Redis → 释放锁 | 直接等第 1 个人的 Future 结果 |
| 实现复杂度 | 简单(Redisson 一行 lock()) |
稍复杂(手写 ConcurrentHashMap + CompletableFuture) |
| 适用场景 | 有副作用操作(下单扣库存,必须排队) | 纯读场景(查缓存,不要副作用) |
一句话总结区别:
SETNX 是"排队后各自重建",请求合并是"一人查完全员共享"。
更重要的是:知道什么时候该用什么方案,比知道方案本身更重要。 秒杀下单扣库存这种有副作用的场景,必须用 SETNX 排队保证安全;纯读缓存这种无副作用的场景,用请求合并更省 Redis 调用。
七、进阶:和 Go 语言 SingleFlight 的对比
Go 标准库里有现成的 golang.org/x/sync/singleflight 包:
go
// Go 版本:一行调用
g := singleflight.Group{}
v, err, _ := g.Do("key", func() (interface{}, error) {
return db.Query("SELECT ...")
})Java 标准库没有这个能力,需要手写。但思路完全一致------都是用一个并发安全的 Map 记录"谁正在查",用共享结果的方式让等待者直接拿到同一个返回值。Go 语言的 singleflight.Group 内部也是 sync.Map + sync.WaitGroup,和我们的 ConcurrentHashMap + CompletableFuture 一一对应。
八、踩坑总结
坑 1:忘记清理 Map
java
// ❌ 没有 finally 清理
CompletableFuture<String> future = flyMap.computeIfAbsent(key, k ->
CompletableFuture.supplyAsync(() -> db.query(key))
);查询抛异常时 Future 虽然完成了,但 Map 里的 Entry 没被删。下一次缓存过期时,computeIfAbsent 看到 Key 还在,返回的是一个已失败的旧 Future------缓存永远重建不了。
坑 2:没有设置超时
java
// ❌ 无限等待,不设超时
return future.get();第一个请求的 DB 慢 SQL 跑了 10 秒,后续所有请求全卡 10 秒。加上超时机制,至少能降级返回旧数据或空值。
坑 3:异常没有捕获处理
java
// ❌ 异常直接抛出去
return future.get(3, TimeUnit.SECONDS);get() 抛出的异常如果不 catch,会导致外层没有清理 Map 的机会。supplyAsync 的 lambda 里面 finally 只能保证创建 Future 的那个线程最终会 remove,但如果有后续请求在 get 这里抛了 InterruptedException,它自己也要做清理。
九、面试怎么答
面试官:"缓存击穿怎么解决?"
"我项目里用手写 SingleFlight 请求合并,不是用 SETNX 互斥锁。核心是 ConcurrentHashMap 存正在执行的请求,CompletableFuture 让后面的人等同一个结果。第一个请求通过 computeIfAbsent 创建 Future 去查 DB,后续请求拿到同一个 Future 直接
get(3秒)阻塞等。DB 只查一次,后面的请求连 Redis 的 Double Check 都不用读,直接共享结果。3 秒超时降级防止死等,finally 里 remove 防止内存泄漏。"
面试官:"和 SETNX 互斥锁有什么区别?"
"SETNX 是排队执行------后面的请求等锁释放后,自己再读一次 Redis Double Check。请求合并是结果共享------后面的请求直接拿第一个请求查 DB 的返回值,连 Redis 都不用再读一次。区别在于'排队等的人要不要自己再动手'。另外场景不同:SETNX 适合有副作用的操作(如下单扣库存,必须严格排队),请求合并适合纯读场景(查缓存,无副作用)。"
总结
| 方案 | 核心思路 | 代码量 |
|---|---|---|
| SETNX 互斥锁 | 排队,每人拿锁后自己读一次 Redis | 5 行(Redisson lock) |
| SingleFlight 请求合并 | 共享,只有第 1 个人查 DB | 20 行(手写) |
请求合并不是银弹------纯读场景用它最省 Redis 调用,有副作用操作(如库存扣减)还是用 SETNX 排队更安全。知道什么场景用什么方案,比知道方案本身更重要。