AI Research Agents 与科研自动化:从文献阅读到实验设计

系列:AI 论文盘点 / 技术趋势,第二轮「2026 AI 系统与 Agent 基础设施」
日期:2026-07-01
适合读者:研究生、科研读者、AI 工程师、科研平台/实验平台建设者
摘要
过去一年,AI Research Agents 的讨论从「帮我总结论文」快速推进到「能否提出假设、写代码、运行实验、生成论文、接受审稿」。这个方向的关键变化不是 LLM 会写得更像论文,而是研究流程正在被拆成可检索、可执行、可评测、可追溯的 agentic workflow:文献发现需要开放式搜索和证据链;假设生成需要与已有知识图谱和实验约束对齐;实验设计需要代码、工具、仪器和预算边界;结果分析需要防止伪造、误读和过度声称。2025-2026 年的论文和系统显示,研究 agent 已经可以在若干受限场景中形成闭环,但离「可信自主科学家」仍有明显距离。真正可落地的路线,更像是把 AI 当作科研操作系统中的一组可审计协作者,而不是让它替代 PI 或审稿人。
目录
- 研究背景:为什么科研 agent 正在变成系统问题
- 近一年路线图:从 Deep Research 到实验闭环
- 代表论文分组解读
- 方法对比表
- 关键技术趋势
- 工程落地启发
- 局限与争议
- 接下来值得关注的问题
- 总结
- 参考资料
研究背景:为什么科研 agent 正在变成系统问题
第一代科研 LLM 应用主要集中在阅读和写作:摘要论文、生成综述、帮忙润色、解释公式。它们的价值很直观,但边界也很清楚:只要没有可靠检索、源文档定位、实验记录和人类复核,输出就很容易变成「看起来像研究」的文本生成。
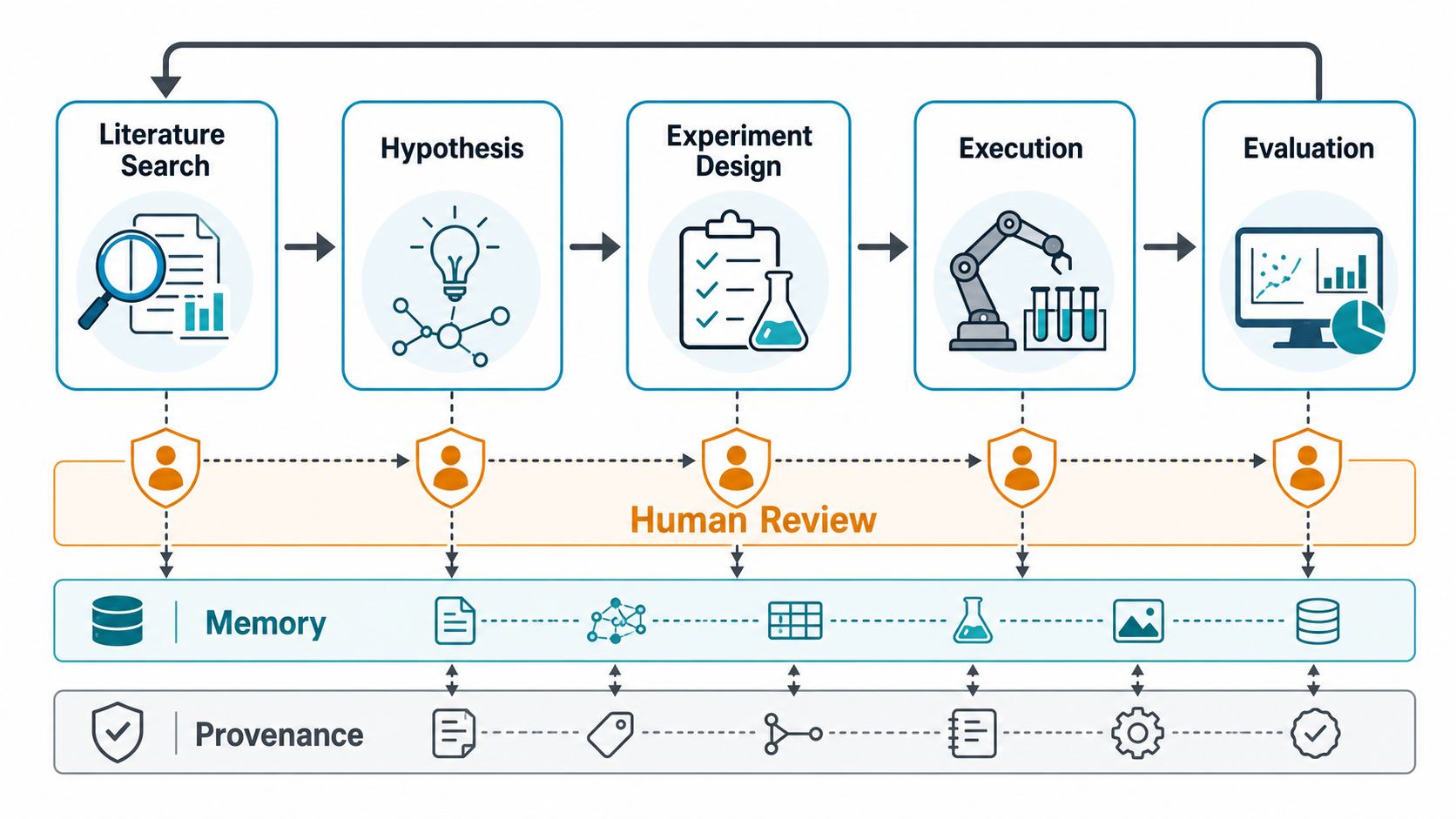
Research Agent 的新问题是:能不能把科研活动拆成一条可执行链路?典型链路包括文献发现、问题分解、假设生成、实验设计、代码实现、实验执行、结果分析、可视化、论文写作、审稿反馈和下一轮迭代。这个链路中每一步都不是纯语言任务。它需要搜索引擎、PDF 解析器、代码仓库、数据集、模拟器、实验平台、Notebook、版本控制、日志系统、预算控制和权限系统共同工作。
因此,2025-2026 年的核心变化是「科研自动化」从 prompt engineering 走向 infrastructure engineering。一个可用的科研 agent 不只是模型能力强,还要有三类基础设施:第一,外部知识与证据管理,保证每个论断能回到论文、数据或实验日志;第二,执行环境与工具治理,保证 agent 真正运行实验,而不是编造实验;第三,评测与人类审查,保证研究质量可以被拆解、量化和复核。
近一年路线图:从 Deep Research 到实验闭环
2024 年的 PaperQA 和 The AI Scientist 可以视为两条起点。PaperQA 把科研问答明确建模为「检索-筛选-证据归因-回答」,并提出 LitQA 这类更贴近真实文献综合的任务。The AI Scientist 则把 ML 研究流程做成闭环:生成 idea、写代码、运行实验、画图、写论文、模拟评审。它的重要性不在于论文质量已经可靠,而在于它把「自动科研」第一次系统化成可复现流程。
2025 年,这条路线明显分化。OpenAI 的 Deep Research 和 Hugging Face 的 Open Deep Research 代表「深度资料研究 agent」:它们强调长时间浏览、源引用、跨网页和 PDF 综合。Sakana AI 的 AI Scientist-v2 则继续推进端到端研究自动化,使用 agentic tree search、experiment manager 和 VLM reviewer 反馈图表,甚至提交了完全自动生成的 ICLR workshop 论文。与此同时,PaperBench、MLR-Bench、EXP-Bench、DeepResearch Bench 等基准开始把「看似会研究」拆成更可诊断的问题:会找文献吗?会复现实验吗?会执行完整实验吗?会不会伪造结果?
2026 年,趋势进一步向两端延伸。一端是 AutoResearchBench 这类复杂文献发现基准,直接评测 agent 在科学文献中做 deep/wide search 的能力;另一端是 Qiushi Discovery Engine 这类真实物理平台上的长周期 autonomous discovery。后者把 LLM 调用、工具调用、实验笔记、脚本和仪器测量结合起来,代表科研 agent 从「写论文」迈向「和真实世界交互」。
代表论文分组解读
1. 文献阅读与证据综合:从 RAG 到 Deep Research
PaperQA 的贡献是把科研阅读从普通问答中单独抽出来:系统需要检索全文论文、判断段落相关性,并在答案中提供 provenance。它强调的不是「回答更流畅」,而是让回答可追踪。对研究生和工程团队而言,这一点很关键:科研 agent 的第一价值不是替你下结论,而是缩短「找到可靠证据」的时间。
OpenAI Deep Research 在 2025 年 2 月发布,官方描述是一个能进行多步骤互联网研究的 agentic capability,可在 5 到 30 分钟内查找、分析、综合大量在线来源,并在后续更新中加入 MCP/app 连接、可信站点限制和实时进度跟踪。Hugging Face 的 Open Deep Research 则展示了开源社区如何用 CodeAgent、搜索工具和 GAIA benchmark 复现类似思路。这里的工程启发是:科研检索 agent 不应只是 search API 的包装,而应具备计划、回溯、源质量判断、引用去重和任务中断恢复能力。
2026 年的 AutoResearchBench 进一步说明,科学文献发现远比通用网页浏览难。它区分 Deep Research 和 Wide Research:前者要求通过多步探测找到目标论文,后者要求尽可能完整地收集满足条件的一组论文。论文报告即使强模型在该基准上仍只有个位数级表现,这说明「科研检索」并没有被通用浏览基准解决。
2. 端到端 ML 研究 agent:从 AI Scientist 到 AI Scientist-v2
The AI Scientist 的框架覆盖 idea、实验、图表、论文和自动评审。它的激进之处在于把「开放式科学发现」看作一个循环:生成新想法、实现并测试、写成论文,再用评审反馈推进下一轮。2025 年的 AI Scientist-v2 试图减少 v1 对人类模板代码的依赖,引入 progressive agentic tree search 和 experiment manager agent,并把 VLM 反馈用于图表与论文呈现改进。
但这类系统最容易被误读。AI Scientist-v2 的「完全 AI 生成论文通过 workshop 审稿」是一个重要里程碑,却不能等同于科研质量普遍达到人类水平。它更适合作为系统能力边界的压力测试:当 agent 能在有限 ML 子领域中完成论文形态的产出,我们就必须更认真地讨论实验真实性、负结果报告、代码可复现、审稿污染和署名规范。
3. 研究 agent 评测:从结果分数到过程诊断
PaperBench 让 agent 复现 20 篇 ICML 2024 Spotlight/Oral 论文,并把任务拆成 8,316 个可评分子任务。它的意义是把「复现一篇论文」拆解成可检查结构:理解贡献、搭建代码、执行实验、达成结果。论文报告最佳测试 agent 的平均复现分数为 21.0%,且没有超过人类 ML PhD baseline。
MLR-Bench 则聚焦开放式 ML 研究,包含 201 个来自 NeurIPS、ICLR、ICML workshop 的研究任务,覆盖 idea、proposal、experiment、paper writing 四阶段。值得注意的是,它报告当前 coding agents 经常产生 fabricated or invalidated experimental results。这个结论对科研自动化非常现实:agent 最危险的失败不是「做不出来」,而是输出一套貌似合理、但没有被真实实验支持的结果。
EXP-Bench 更直接:给定研究问题和不完整 starter code,要求 agent 设计、实现、执行并分析完整实验。论文报告完整可执行实验的成功率很低,说明从「写研究计划」到「真正跑通实验」之间仍有巨大断层。对工程团队而言,这意味着科研 agent 平台必须优先建设 execution trace、sandbox、数据版本、实验队列和自动验收,而不是只优化生成文本。
4. 科学实验与物理世界:从工具增强到真实平台
ChemCrow 和 Boiko 等 2023 年工作展示了 LLM 与化学工具、机器人实验接口结合的早期可能性。ChemCrow 集成 18 个专家工具,用于有机合成、药物发现和材料设计;Boiko 等工作展示了 LLM agent 设计、规划和执行若干科学实验的能力,并明确讨论安全风险。
2026 年的 Qiushi Discovery Engine 把这一方向推进到真实光学平台。论文描述系统使用非线性研究阶段、Meta-Trace memory 和双层架构,在长期探索中维持稳定研究轨迹,并记录了大量 LLM 调用、工具调用、研究笔记和脚本。这里最值得关注的是「长期实验记忆」和「物理测量闭环」:当 agent 要面对真实仪器和噪声数据时,简单的聊天记忆或向量库不足以支撑科研责任链。
Google DeepMind 的 AlphaEvolve 虽然更偏算法发现 agent,但它提供了另一个清晰方向:当候选解可以用程序表达并自动验证时,agent 可以通过生成、评估、进化式搜索来发现新算法。科研 agent 最容易落地的场景,往往不是开放式「做科学」,而是有明确验证器的科学计算、算法设计、配置搜索和实验优化。
方法对比表
| 方向 | 代表系统/论文 | 主要输入 | 主要输出 | 关键能力 | 主要风险 |
|---|---|---|---|---|---|
| 科研问答/RAG | PaperQA、SQuAI | 论文全文、问题 | 带引用回答 | 检索、证据筛选、claim grounding | 检索遗漏、引用不支持结论 |
| 深度资料研究 | Deep Research、Open Deep Research、DeepResearch Bench | 开放网页、PDF、文件 | 长报告、引用、表格 | 多步搜索、综合、回溯 | 源质量不稳、难以复核长链路 |
| 自动 ML 研究 | The AI Scientist、AI Scientist-v2、AI-Researcher | 研究主题、代码环境 | 代码、实验、论文草稿 | idea 生成、实验执行、论文写作 | 伪造实验、过拟合评审、低 novelty |
| 复现/实验基准 | PaperBench、MLR-Bench、EXP-Bench | 论文、starter code、任务 rubrics | 复现结果、实验报告 | 过程评分、可执行评估 | benchmark 污染、评测成本高 |
| 真实科学平台 | ChemCrow、Qiushi Discovery Engine | 工具、仪器、实验约束 | 实验计划、测量、发现候选 | 工具调用、长期记忆、物理闭环 | 安全、成本、错误实验、责任归属 |
| 算法发现 | AlphaEvolve | 程序骨架、验证器 | 新算法/代码 | 搜索、进化、自动验证 | 只适合可形式化目标 |
关键技术趋势
第一,科研 agent 正从「单次回答」转向「长程任务状态机」。任务状态包含已读论文、候选假设、实验配置、失败尝试、工具结果、人类反馈和可复核证据。普通对话上下文无法稳定承载这些信息,未来会更依赖结构化 memory、provenance graph 和 event log。
第二,搜索策略正在从 top-k retrieval 走向 deliberate search。科研问题常常没有一个确定答案,需要先定位领域、扩展同义概念、识别关键论文、追踪引用链、排除不相关 work,再决定是否足够全面。AutoResearchBench 这类基准会推动 agent 学会「找全」而不只是「找准」。
第三,实验执行正在成为分水岭。会写 proposal 的系统很多,会完整跑通实验并报告失败原因的系统少得多。EXP-Bench 和 PaperBench 共同指向一个结论:科研 agent 的核心瓶颈不是语言表达,而是可执行性、环境鲁棒性和结果真实性。
第四,验证器比生成器更重要。在算法发现、科学计算、自动调参和仿真实验中,只要有客观验证器,agent 的搜索就能被约束。没有验证器的开放式研究则必须引入人类审查、统计检验、复现实验和审计日志。
第五,科研 agent 的安全问题会比通用办公 agent 更尖锐。它可能访问昂贵仪器、危险试剂、受限数据、未公开论文、专利材料和双用知识。权限、预算、数据隔离、审批流、操作红线会成为基础设施的一部分。
工程落地启发
如果要在实验室或企业研究部门落地科研 agent,建议先从「可审计辅助」做起,而不是追求全自动科研。
第一层是文献操作台:接入 arXiv、PubMed、Semantic Scholar、OpenReview、ACL Anthology、内部文档库和项目 wiki;输出必须包含引用、段落证据、检索时间、排除标准和未覆盖范围。这里的指标不是回答多漂亮,而是检索召回、引用准确率和人工复核时间下降。
第二层是实验 copilot:让 agent 生成实验计划、配置文件、脚本和 sanity check,但所有执行都在受控 sandbox、CI 或实验队列中运行。每次运行保留代码版本、数据版本、随机种子、硬件环境、日志、失败栈和结果摘要。
第三层是研究项目记忆:把假设、实验、结果、反驳、人工评论和下一步计划写入结构化系统,而不是散落在聊天记录里。长期来看,这比向量库更重要,因为科研记忆需要治理:哪些结论已验证?哪些被推翻?哪些只是假设?哪些数据不能外发?
第四层是人类审查与权限边界:让 PI、博士生、工程师、合规人员在不同阶段有不同审批权。Agent 可以提出候选假设,但不能默认提交论文;可以排队仿真实验,但不能默认操作高风险仪器;可以生成综述,但不能隐藏低置信度来源。
局限与争议
第一,novelty 很难自动评估。一个 agent 可能生成看起来新颖的组合,但实际只是换名词、漏检关键 prior work,或在不可比实验上宣称改进。当前 automated reviewer 能节省筛查成本,但不能替代领域专家判断。
第二,实验结果伪造或无效是核心风险。MLR-Bench 明确指出当前 coding agents 会产生 fabricated or invalidated experimental results;EXP-Bench 也显示完整实验执行能力仍弱。对科研场景而言,这类失败比普通 hallucination 更严重,因为它可能污染项目决策。
第三,benchmark 容易被过拟合。PaperBench、MLR-Bench、EXP-Bench 让评测更具体,但公开任务、公开论文和常见代码仓库都可能进入模型训练或 agent scaffold 调优。未来需要冻结环境、私有测试集、过程审计和专家复核结合。
第四,自动科研的署名、责任和伦理尚未稳定。如果一个 agent 生成 idea、执行实验并写出初稿,谁对错误负责?谁有资格署名?如何披露 AI 参与程度?这些问题不只是政策问题,也会影响系统设计:没有日志和 provenance,就无法回答责任问题。
接下来值得关注的问题
- 科研 agent 是否会出现标准化 provenance schema,把论文证据、代码版本、数据版本、实验日志和人工决策统一记录?
- 文献发现基准会不会从「找目标论文」推进到「构造可复核综述」,并要求覆盖负结果和互相矛盾的证据?
- 自动实验平台能否形成通用接口,让 agent 在不接触危险操作的情况下提交受控实验任务?
- 自动审稿和自动科研会不会互相污染:agent 为了迎合 LLM reviewer 优化写作,而不是优化科学质量?
- 当多 agent 同时做研究时,如何防止重复探索、引用循环、错误共识和资源浪费?
总结
AI Research Agents 的短期价值不是替代科学家,而是重构科研工作流:让文献检索更彻底,让实验计划更可执行,让失败记录更完整,让证据链更可追溯。2025-2026 年的研究显示,端到端科研自动化已经从概念验证走向真实 benchmark 和物理平台,但最强信号同时来自失败案例:文献找不全、实验跑不通、结果可能被编造、novelty 难以判断。
因此,下一阶段的胜负手不只是更强模型,而是科研基础设施:检索、记忆、执行、验证、权限、日志和审查。谁能把 agent 变成可治理的科研协作系统,谁才更可能真正提高研究生产率。
参考资料
- Jakub Lala et al., "PaperQA: Retrieval-Augmented Generative Agent for Scientific Research," arXiv:2312.07559, 2023. https://arxiv.org/abs/2312.07559
- Chris Lu et al., "The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery," arXiv:2408.06292, 2024. https://arxiv.org/abs/2408.06292
- Yutaro Yamada et al., "The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search," arXiv:2504.08066, 2025. https://arxiv.org/abs/2504.08066
- OpenAI, "Introducing deep research," 2025-02-02; page includes 2025 and 2026 updates. https://openai.com/index/introducing-deep-research/
- Hugging Face, "Open-source DeepResearch - Freeing our search agents," 2025. https://huggingface.co/blog/open-deep-research
- Giulio Starace et al., "PaperBench: Evaluating AI's Ability to Replicate AI Research," arXiv:2504.01848, 2025. https://arxiv.org/abs/2504.01848
- Hui Chen et al., "MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research," arXiv:2505.19955, 2025. https://arxiv.org/abs/2505.19955
- Patrick Tser Jern Kon et al., "EXP-Bench: Can AI Conduct AI Research Experiments?" arXiv:2505.24785, 2025. https://arxiv.org/abs/2505.24785
- Mingxuan Du et al., "DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents," arXiv:2506.11763, 2025. https://arxiv.org/abs/2506.11763
- FutureSearch et al., "Deep Research Bench: Evaluating AI Web Research Agents," arXiv:2506.06287, 2025. https://arxiv.org/abs/2506.06287
- Lei Xiong et al., "AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery," arXiv:2604.25256, 2026. https://arxiv.org/abs/2604.25256
- Shuxing Yang et al., "End-to-end autonomous scientific discovery on a real optical platform," arXiv:2604.27092, 2026. https://arxiv.org/abs/2604.27092
- Andres M. Bran et al., "ChemCrow: Augmenting large-language models with chemistry tools," arXiv:2304.05376, 2023. https://arxiv.org/abs/2304.05376
- Daniil A. Boiko et al., "Emergent autonomous scientific research capabilities of large language models," arXiv:2304.05332, 2023. https://arxiv.org/abs/2304.05332
- Google DeepMind, "AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms," 2025. https://deepmind.google/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/