PointNet:让神经网络直接"看"点云,3D深度学习的开山之作
作者:小探
首发:探物 AI
序列:3D感知网络的第4篇文章
转载请注明出处
上一篇我们学习了CenterPoint,理解了无锚框BEV检测方法。但回到最根本的问题------如何让神经网络直接处理3D点云?这一篇我们来看PointNet------第一个直接在原始点云上工作的深度学习模型,它用极其简洁的设计解决了点云的无序性问题,开创了整个3D深度学习领域!
一、从2D图像到3D点云:为什么需要PointNet?
1.1 2D图像处理的成功
2D图像处理(CNN):
✅ 像素排列在规则网格上
✅ 可以直接用卷积操作
✅ 平移不变性天然具备
✅ 成熟的网络架构(ResNet, VGG等)
结果:
图像分类、目标检测、语义分割...
各种任务都取得了巨大成功1.2 3D点云的挑战
3D点云:
❌ 点散布在三维空间中,没有固定排列
❌ 不能直接用卷积(卷积需要规则网格)
❌ 点的顺序可以任意变化
❌ 点的数量不固定
问题:
如何让神经网络理解这种"混乱"的数据?1.3 传统解决方案
方法1:体素化(Voxelization)
点云 → 3D网格 → 3D卷积
问题:
- 3D卷积计算量大(O(N³))
- 体素化丢失细节
- 内存消耗大
方法2:多视图投影(Multi-view)
点云 → 2D图像 → 2D CNN
问题:
- 丢失3D几何信息
- 视角选择困难
- 遮挡问题
方法3:手工特征(Hand-crafted Features)
点云 → 几何特征 → 传统分类器
问题:
- 特征设计需要专业知识
- 泛化能力差
- 无法端到端训练1.4 PointNet的突破
PointNet的核心思想:
不转换数据,直接在原始点云上工作!
输入:N个点的点云 [N, 3]
输出:分类结果 / 逐点分割
关键创新:
1. 用MLP提取逐点特征
2. 用对称函数(最大池化)解决无序性
3. 用T-Net对齐输入
结果:
✅ 端到端训练
✅ 直接处理点云
✅ 计算效率高
✅ 精度超越传统方法二、PointNet的核心思想
2.1 一句话概括
用MLP提取逐点特征,用最大池化解决无序性问题,让神经网络直接在原始点云上工作。
2.2 核心问题:无序性
问题描述:
同一辆车的点云,点的顺序可以任意变化:
点云A: [点1, 点2, 点3, ..., 点1024]
点云B: [点3, 点1, 点1024, ..., 点2]
这两个点云描述的是同一辆车!
但输入向量完全不同
网络必须识别出它们是同一个物体
类比:
一袋弹珠:
- 你把弹珠倒出来,重新放进去
- 弹珠的顺序变了
- 但袋子里还是同样的弹珠
点云就像一袋弹珠:
- 点的顺序不重要
- 重要的是有哪些点,它们在哪里2.3 解决方案:对称函数
什么是对称函数?
输入的顺序不影响输出
例子:
- 最大值:max(3, 1, 2) = max(1, 2, 3) = 3
- 求和:sum(3, 1, 2) = sum(1, 2, 3) = 6
- 平均值:mean(3, 1, 2) = mean(1, 2, 3) = 2
无论输入顺序如何,输出都一样!
PointNet的选择:
用最大池化作为对称函数
输入:N个点的特征 [N, 1024]
输出:全局特征 [1, 1024]
无论点的顺序如何,输出都一样!2.4 PointNet的三步走
步骤1:逐点特征提取
对每个点独立地用MLP提取特征
输入:每个点 [x, y, z]
输出:每个点的高维特征 [x, y, z, f1, f2, ..., fk]
步骤2:全局特征聚合
用最大池化聚合所有点的特征
输入:N个点的特征 [N, 1024]
输出:全局特征 [1, 1024]
步骤3:任务头
分类:全局特征 → FC → 类别
分割:全局特征 + 逐点特征 → FC → 逐点类别三、PointNet的网络结构详解
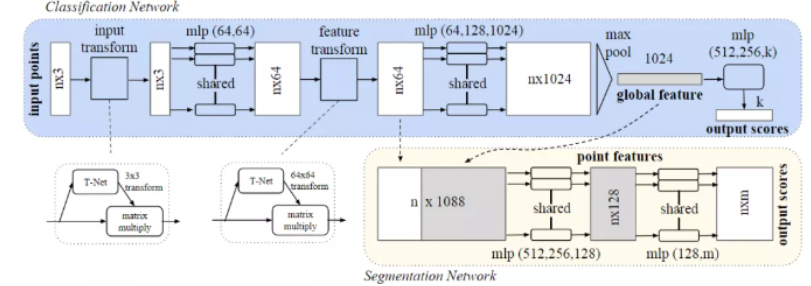
3.1 整体架构(分类网络)
输入点云 [N, 3]
│
↓
┌─────────────────────────────────────────────┐
│ 步骤1:输入对齐(T-Net) │
│ │
│ - 学习3x3变换矩阵 │
│ - 对齐输入点云 │
│ - 解决点云的旋转不变性 │
└─────────────────────────────────────────────┘
│
↓
对齐后的点云 [N, 3]
│
↓
┌─────────────────────────────────────────────┐
│ 步骤2:逐点特征提取(MLP) │
│ │
│ - 共享MLP:[64, 64, 128, 1024] │
│ - 每个点独立处理 │
│ - 输出:每个点1024维特征 │
└─────────────────────────────────────────────┘
│
↓
逐点特征 [N, 1024]
│
↓
┌─────────────────────────────────────────────┐
│ 步骤3:全局特征聚合(Max Pooling) │
│ │
│ - 对N个点的特征取最大值 │
│ - 输出:全局特征 [1, 1024] │
│ - 无序性问题解决! │
└─────────────────────────────────────────────┘
│
↓
全局特征 [1, 1024]
│
↓
┌─────────────────────────────────────────────┐
│ 步骤4:分类头 │
│ │
│ - FC: 1024 → 512 → 256 → num_classes │
│ - Dropout + BatchNorm │
│ - 输出:类别概率 │
└─────────────────────────────────────────────┘
│
↓
分类结果3.2 T-Net:输入对齐网络
问题:
同一辆车,不同的旋转角度,点云坐标不同
网络应该识别出它们是同一辆车
车头朝东:[(1,0,0), (2,0,0), ...]
车头朝北:[(0,1,0), (0,2,0), ...]
这两个点云描述的是同一辆车!
但坐标完全不同
解决方案:T-Net
学习一个3x3变换矩阵,将输入点云对齐到标准坐标系
输入:点云 [N, 3]
输出:变换矩阵 [3, 3]
对齐后的点云 = 原始点云 × 变换矩阵
类比:
你拍一张桌子的照片:
- 从左边拍:桌子是斜的
- 从正面拍:桌子是正的
T-Net的作用:
- 无论从哪个角度拍
- 都把桌子"摆正"
- 让网络更容易识别3.3 共享MLP:逐点特征提取
python
# 共享MLP的实现
class SharedMLP(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Conv1d(in_channels, out_channels, 1)
self.bn = nn.BatchNorm1d(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
# x: [B, C, N] - batch, channels, points
return self.relu(self.bn(self.conv(x)))共享MLP的含义:
所有点使用相同的MLP权重
输入:点云 [B, 3, N]
↓
Conv1d(3, 64) + BN + ReLU
↓
Conv1d(64, 64) + BN + ReLU
↓
Conv1d(64, 128) + BN + ReLU
↓
Conv1d(128, 1024) + BN + ReLU
↓
输出:逐点特征 [B, 1024, N]
关键点:
- Conv1d的kernel_size=1,相当于对每个点独立做FC
- 所有点共享相同的权重
- 每个点独立处理,不依赖其他点3.4 Max Pooling:全局特征聚合
最大池化的作用:
将N个点的特征聚合成一个全局特征
输入:逐点特征 [B, 1024, N]
输出:全局特征 [B, 1024, 1]
伪代码:
global_feat = max(point_features, dim=N)
为什么用最大池化?
1. 对称函数:输出不依赖输入顺序
2. 保留最显著特征:每个维度取最大值
3. 计算简单:O(N)复杂度
图解:
点云:
点1: [0.5, 0.8, 0.2, ...]
点2: [0.3, 0.9, 0.1, ...]
点3: [0.7, 0.6, 0.4, ...]
↓ 最大池化
全局: [0.7, 0.9, 0.4, ...]
每个维度取所有点的最大值四、PointNet的实验结果
4.1 3D物体分类(ModelNet40)
ModelNet40数据集:
- 40个类别
- 12,311个3D模型
- 训练集:9,843
- 测试集:2,468
结果对比:
┌─────────────────────┬───────────────┐
│ 方法 │ 整体准确率 │
├─────────────────────┼───────────────┤
│ 3DShapeNets │ 77.3% │
│ VoxNet │ 83.0% │
│ Subvolume │ 86.0% │
│ MVCNN │ 90.1% │
│ PointNet │ 89.2% │
│ PointNet++ │ 90.7% │
└─────────────────────┴───────────────┘
PointNet的优势:
✅ 直接处理点云,不需要体素化
✅ 计算效率高
✅ 精度接近多视图方法4.2 3D场景语义分割(S3DIS)
S3DIS数据集:
- 6个大型室内场景
- 13个语义类别
- 超过6亿个点
结果对比:
┌─────────────────────┬───────────────┐
│ 方法 │ mIoU │
├─────────────────────┼───────────────┤
│ PointNet │ 47.6% │
│ PointNet++ │ 54.5% │
│ SPGraph │ 62.1% │
│ RSNet │ 56.4% │
└─────────────────────┴───────────────┘
PointNet的局限:
❌ 缺乏局部特征提取
❌ 对复杂场景分割效果一般
→ 这是PointNet++要解决的问题4.3 推理速度
推理速度对比(单个点云):
┌─────────────────────┬───────────────┐
│ 方法 │ 时间 (ms) │
├─────────────────────┼───────────────┤
│ 3D卷积(体素) │ 500+ │
│ 多视图CNN │ 200+ │
│ PointNet │ 10-20 │
│ PointNet++ │ 20-30 │
└─────────────────────┴───────────────┘
PointNet的速度优势:
✅ 不需要体素化预处理
✅ 共享MLP计算高效
✅ 适合实时应用五、常见问题解答(FAQ)
Q1: PointNet为什么不用卷积?
答:
传统卷积的要求:
- 输入必须是规则网格
- 图像:2D网格
- 体素:3D网格
点云的特点:
- 点散布在空间中
- 没有固定排列
- 不能直接用卷积
PointNet的解决方案:
- 用MLP(多层感知机)处理每个点
- 用共享MLP(Conv1d, kernel=1)实现
- 每个点独立处理,不需要规则网格Q2: 最大池化会不会丢失信息?
答:
确实会丢失信息:
- 最大池化只保留每个维度的最大值
- 其他点的信息被忽略
但在实践中:
- 全局特征已经足够用于分类
- 分割任务会结合逐点特征
- 全局特征 + 逐点特征 = 完整信息
类比:
你看到一张照片:
- 一眼就能认出是"猫"
- 但不需要记住每个像素
最大池化就像"一眼看出是什么"
而逐点特征就像"仔细看每个细节"Q3: PointNet能处理多大的点云?
答:
理论上:
- 可以处理任意大小的点云
- 每个点独立处理
实际上:
- 受GPU内存限制
- 常用:1024-8192个点
- 更多点需要下采样
优化方法:
1. 随机下采样
2. 最远点采样(FPS)
3. 体素化下采样Q4: PointNet的旋转不变性如何?
答:
T-Net的作用:
- 学习变换矩阵对齐输入
- 提供一定的旋转不变性
但T-Net的局限:
- 只学习了3x3变换
- 对大角度旋转效果一般
- 对反射变换不鲁棒
改进方法:
1. 数据增强:随机旋转训练
2. 手工特征:加入法向量等
3. 后续工作:更好的对齐方法九、总结:PointNet的精髓
9.1 核心思想
- 直接处理点云:不需要转换为体素或多视图
- 共享MLP:对每个点独立提取特征
- 最大池化:用对称函数解决无序性
- T-Net:学习输入对齐,提供旋转不变性
9.2 一句话总结
PointNet用MLP提取逐点特征,用最大池化聚合全局特征,用T-Net对齐输入,首次实现了直接在原始点云上工作的深度学习模型,开创了整个3D深度学习领域。
9.3 关键创新
| 创新 | 作用 |
|---|---|
| 共享MLP | 逐点特征提取 |
| 最大池化 | 解决无序性问题 |
| T-Net | 输入对齐,旋转不变性 |
| 端到端训练 | 不需要手工特征 |
9.4 下一步学习
- PointNet++:层次化点云学习,解决局部特征问题
- SECOND:稀疏卷积加速体素方法
- CenterPoint:无锚框BEV检测
附录:关键术语表
| 术语 | 英文 | 含义 |
|---|---|---|
| 点云 | Point Cloud | 3D空间中点的集合 |
| 无序性 | Unordered | 点的顺序可以任意变化 |
| 对称函数 | Symmetric Function | 输出不依赖输入顺序的函数 |
| T-Net | Transformation Network | 学习输入对齐的网络 |
| 共享MLP | Shared MLP | 所有点使用相同权重的MLP |
| 最大池化 | Max Pooling | 取每个维度的最大值 |
下期预告:《PointNet++------如何让网络"看懂"局部结构?层次化点云学习的突破》