作者 : Yishuo Chen1^11, Boran Wang1∗^{1*}1∗, Xinyu Guo1^11, Wenbin Zhu1^11, Jiasheng He1^11, Xiaobin Liu1,2^{1,2}1,2, Jing Yuan1,2^{1,2}1,2
单位:
- 南开大学人工智能学院,中国天津 300350
- 教育部可信行为智能工程研究中心,南开大学,中国天津 300350
邮箱 : wangbr1025@gmail.com
https://arxiv.org/pdf/2412.04931
摘要
弱光环境下的目标检测是一项具有挑战性的任务,因为物体在 RGB 图像中通常无法清晰可见。由于红外图像提供了补充 RGB 图像的清晰边缘信息,融合 RGB 和红外图像有望增强在弱光环境下的检测能力。然而,现有涉及可见光和红外图像的工作仅关注图像融合,而非目标检测。此外,它们直接融合这两种图像模态,忽略了它们之间的相互干扰。为了融合这两种模态以最大化跨模态的优势,我们设计了一种基于双重增强的跨模态目标检测网络 DEYOLO,其中设计了语义-空间跨模态模块和新型双向解耦聚焦(bi-directional decoupled focus)模块,以实现以检测为中心的 RGB-红外(RGB-IR)相互增强。具体而言,首先提出了双重语义增强通道权重分配模块(DECA)和双重空间增强像素权重分配模块(DEPA),以在特征空间中聚合跨模态信息,从而提高特征表示能力,使得特征融合能够面向目标检测任务。同时,在 DECA 和 DEPA 中设计了一种双重增强机制,包括对双模态融合和单模态的增强,以减少两种图像模态之间的干扰。然后,开发了一种新型的双向解耦聚焦模块,以在不同方向上扩大骨干网络的感受野,从而提高 DEYOLO 的表示质量。在 M3FD 和 LLVIP 数据集上的大量实验表明,我们的方法以明显的优势优于最先进的(SOTA)目标检测算法。我们的代码已开源:https://github.com/chips96/DEYOLO。
关键词: 目标检测 · 可见光-红外 · 双重增强
1. 引言
作为计算机视觉的一项基础任务,复杂场景下的目标检测仍面临各种挑战。由于可见光波长范围有限,在光照条件较差的复杂环境(如浓烟)中很难获取物体信息。为了解决这个问题,红外信息被广泛引入。然而,由于红外图像质量较低,通用检测器很难从中提取有用的纹理和颜色信息。因此,它们很难单独支持检测任务。
相比之下,利用可见光-红外图像跨模态中的互补信息可以提高目标检测的性能。常用的方法采用"融合-检测"(fusion-and-detection)策略,这意味着图像融合网络使用目标检测结果作为验证指标。然而,融合-检测方法存在几个缺陷。首先,双模态图像的融合并不专注于目标检测任务。其次,它们冗余的模型结构(例如,分别用于融合和检测的两个独立模型)导致了训练成本的增加。第三,尽管红外(IR)图像具有丰富的结构信息,但其缺点是缺乏纹理。因此,融合模型通常专注于丰富纹理信息,同时消除物体复杂的亮度信息。相反,它们很少考虑两种模态图像之间的相互干扰。例如,在融合过程中,红外图像可能会抵消可见光成像的质量。仅进行直接的图像对融合而不进行跨模态增强,不足以提高目标检测性能。
大多数现有的 RGB-IR 检测模型要么构建四通道输入,要么在两个独立的分支中保持 RGB 和红外图像,并在下游合并它们的特征。这些多模态信息融合策略在一定程度上提高了检测性能。然而,我们认为在这些方法中,两种模态之间的交互是不充分的。单模态图像处理与特征融合之间存在明显的界限,导致跨模态信息利用不足。此外,它们缺乏在通道和空间维度上的复合交互,忽视了语义和结构信息之间的潜在关系。
为此,我们提出了一种跨模态特征融合方法,以双重增强视觉和红外图像的特征图用于检测任务。这种增强策略能够引导两个模态特征从不同尺度的融合过程,以确保特征信息的完整性和最优的信息提取。针对目标检测,设计了 DECA 和 DEPA,分别用于丰富特征图中包含的语义和结构信息。此外,为了突出模态特定的特征,我们在骨干网络中插入了一种新型的双向解耦聚焦。它在 DEYOLO 的特征提取阶段多方向地改善了感受野,从而产生了更好的结果。图 1 展示了 DEYOLO 与 DetFusion、IRFS、PIAFusion、SeAFusion、U2Fusion 的检测结果。可以观察到,提出的 DEYOLO 取得了更好的检测结果。

本文的贡献有三方面:
- 我们提出了基于 YOLOv8 的 DEYOLO,它在骨干网络和检测头之间执行跨模态特征融合。与直接融合双模态图像的其他融合方法不同,我们在特征空间中融合双模态信息,并专注于目标检测任务。
- 我们提出了两个利用双重增强机制的模块 DECA 和 DEPA。它们通过重新分配通道和像素的权重,减少了两种模态之间的干扰,并实现了语义和空间信息的增强。
- 为了使骨干网络提取的特征更好地适应我们的双重增强机制,我们设计了双向解耦聚焦。它在不同方向上对浅层特征图进行下采样,在不丢失周围信息的情况下增加了感受野。
2. 相关工作
在本节中,我们首先回顾常用的单模态目标检测算法。然后,介绍一些最近的可见光和红外图像融合方法。
2.1 单模态目标检测
最近,深度神经网络被提出以提高目标检测任务的准确性,包括 CNN 及其变体(如 Sparse R-CNN, CenterNet2 和 YOLO 系列),以及基于 Transformer 的模型(如 DETR 和 Swin Transformer)。尽管这些模型可以实现出色的性能,但它们都仅利用来自单模态图像的信息。此外,这些模型严重依赖图像的纹理,这阻碍了它们对红外图像的检测能力。
为了处理红外目标检测问题,研究人员不断引入不同的网络结构和机制。ALCNet 使用骨干网络提取图像的高级语义特征,并使用模型驱动的编码器学习局部对比度特征。ISTDU-Net 有效地整合了编码和解码阶段,并通过跳跃连接促进信息传递。这种结构能够在保持高分辨率的同时增加感受野。IRSTD-GAN 将红外目标视为一种特殊的噪声。它可以根据 GAN 学习到的数据分布和层次特征,从输入图像中预测红外小目标。这些模型仅考虑红外图像,而没有从可见光图像中提取信息。
上述单模态方法不太适合复杂光照条件下的目标检测。相比之下,双模态融合可以从可见光和红外图像中提取互补信息,从而减少了对纹理信息的过度依赖。
2.2 融合与检测方法
考虑到红外图像不易受不良光照条件的影响,已经提出了各种可见光和红外图像融合方法。U2Fusion 是一个无监督的端到端图像融合网络,可以解决不同的融合问题。它使用特征提取和信息测量来自动估计相应源图像的重要性,并提出自适应的信息保留度。PIAFusion 使用光照感知损失将光照因素考虑在内。SwinFusion 涉及基于自注意力和交叉注意力的融合单元,以挖掘同一域内和跨域的长距离依赖关系。CDDFuse 引入了 Transformer-CNN 提取器,并成功分解了理想的模态特定特征和模态共享特征。在融合过程之后,获得的图像被馈送到单独的模型以检测物体。
尽管这些模型可以产生令人信服的结果,保留融合结果与源图像之间的自适应相似性,但它们并不直接针对目标检测任务。另一个缺点是融合结果中可能存在冲突(例如,红外图像的无纹理斑块破坏了可见光图像原本丰富的纹理),这对检测精度有害。相比之下,DEYOLO 仅专注于目标检测,并且新设计的双重增强机制可以解决冲突问题。
3. 方法
如图 2 所示,为了处理从双模态图像中提取的多尺度特征,我们在 YOLOv8 模型的骨干网络和颈部(necks)之间添加了新设计的模块 DECA 和 DEPA(图 3)。通过特定的双重增强机制,语义和空间信息的融合使得双模态特征更加和谐。同时,对于骨干网络,为了更好地提取和保留两种模态图像的有用特征,我们提出了一种新型的双向解耦聚焦策略。它增加了骨干网络在不同方向上的感受野,并确保原始信息不泄露。
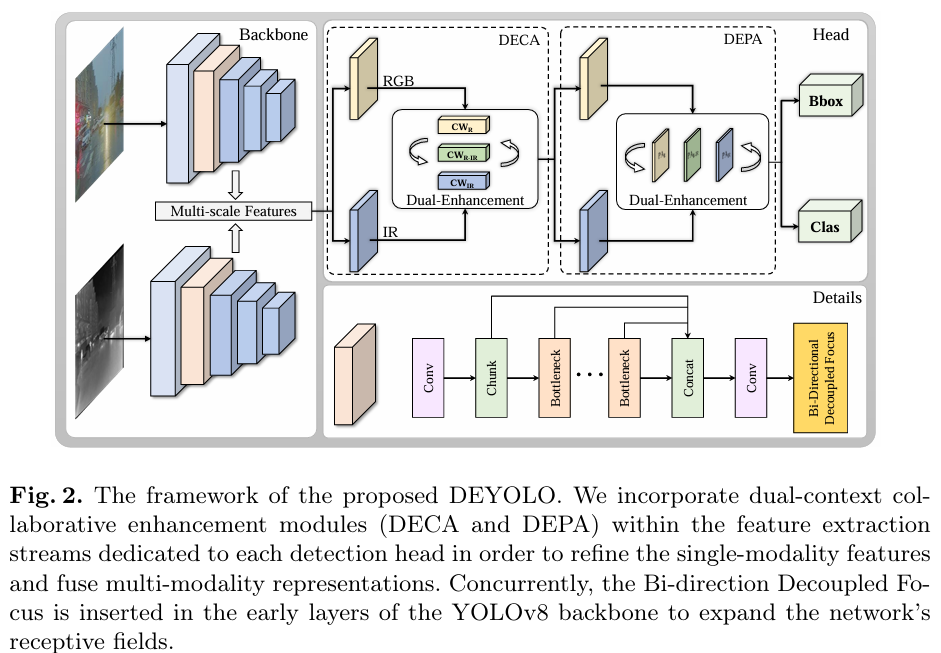
3.1 DECA:双重语义增强通道权重分配模块
这里的双重增强机制是指:利用单模态信息对通道间的双模态融合结果进行增强,并进一步利用双模态融合的互补信息对单模态进行增强。因此,DECA 能够通过根据每个通道的重要性分配权重来强调语义信息。
第一次增强旨在利用单模态特征来改善 RGB 和 IR 特征的双模态融合结果,这些结果可能包含冲突。设 FV0∈Rb×c×h×wF_{V0} \in \mathbb{R}^{b \times c \times h \times w}FV0∈Rb×c×h×w 和 FIR0∈Rb×c×h×wF_{IR0} \in \mathbb{R}^{b \times c \times h \times w}FIR0∈Rb×c×h×w 分别为骨干网络计算出的可见光和红外图像的特征图。首先,为了获取 RGB 和 IR 图像的综合信息,我们沿通道维度拼接这两个特征。然后,卷积操作将使组合后的特征图恢复到之前的尺寸,过滤掉冗余信息。结果,获得了混合特征图 FMix0∈Rb×c×h×wF_{Mix0} \in \mathbb{R}^{b \times c \times h \times w}FMix0∈Rb×c×h×w:
FMix0=conv(concat(FV0,FIR0))(1) F_{Mix0} = conv(concat(F_{V0}, F_{IR0})) \tag{1} FMix0=conv(concat(FV0,FIR0))(1)
接下来,我们通过卷积提出了一种新颖的权重编码方法。设计了一个编码器,在空间维度上逐步将 FMix0F_{Mix0}FMix0 压缩到 Rb×c×1×1\mathbb{R}^{b \times c \times 1 \times 1}Rb×c×1×1 的大小:
WMix0=CMWE(FMix0)∈Rb×c×1×1(2) W_{Mix0} = CMWE(F_{Mix0}) \in \mathbb{R}^{b \times c \times 1 \times 1} \tag{2} WMix0=CMWE(FMix0)∈Rb×c×1×1(2)
其中 CMWE(⋅)CMWE(\cdot)CMWE(⋅) 指的是图 3 中的跨模态权重提取操作。
另一方面,我们需要获取每种模态的特定特征。SE 块显式地对其卷积特征的通道之间的相互依赖性进行建模,以提高特征图表示的质量。受此启发,我们将此结构输入可见光和红外图像,以获得大小为 Rb×c×1×1\mathbb{R}^{b \times c \times 1 \times 1}Rb×c×1×1 的特征块,这代表了不同通道的权重值:
{WV0=CWE(FV0)∈Rb×c×1×1WIR0=CWE(FIR0)∈Rb×c×1×1(3) \begin{cases} W_{V0} = CWE(F_{V0}) \in \mathbb{R}^{b \times c \times 1 \times 1} \\ W_{IR0} = CWE(F_{IR0}) \in \mathbb{R}^{b \times c \times 1 \times 1} \end{cases} \tag{3} {WV0=CWE(FV0)∈Rb×c×1×1WIR0=CWE(FIR0)∈Rb×c×1×1(3)
其中 CWE(⋅)CWE(\cdot)CWE(⋅) 指的是图 3 中的通道权重提取块。WV0W_{V0}WV0 和 WIR0W_{IR0}WIR0 可以通过逐元素乘法来增强两种模态的混合特征以重新分配权重,这能够突出重要的通道:
{WenV0=WV0⊗softmax(WMix0)WenIR0=WIR0⊗softmax(WMix0)(4) \begin{cases} W_{enV0} = W_{V0} \otimes softmax(W_{Mix0}) \\ W_{enIR0} = W_{IR0} \otimes softmax(W_{Mix0}) \end{cases} \tag{4} {WenV0=WV0⊗softmax(WMix0)WenIR0=WIR0⊗softmax(WMix0)(4)
对于第二次增强,我们试图使 RGB 和 IR 的每个特征图充分利用另一种模态的各自优势。为此,FV0F_{V0}FV0 和 FIR0F_{IR0}FIR0 将乘以在第一次增强中获得的相应特征权重,以从另一种模态获取语义和纹理信息:
{FIR1=FIR0⊙WenV0FV1=FV0⊙WenIR0(5) \begin{cases} F_{IR1} = F_{IR0} \odot W_{enV0} \\ F_{V1} = F_{V0} \odot W_{enIR0} \end{cases} \tag{5} {FIR1=FIR0⊙WenV0FV1=FV0⊙WenIR0(5)
其中 ⊙\odot⊙ 是通道维度上的乘法。增强结果 FV1∈Rb×c×w×hF_{V1} \in \mathbb{R}^{b \times c \times w \times h}FV1∈Rb×c×w×h 和 FIR1∈Rb×c×w×hF_{IR1} \in \mathbb{R}^{b \times c \times w \times h}FIR1∈Rb×c×w×h 将传递到下面描述的 DEPA。
3.2 DEPA:双重空间增强像素权重分配模块
与 DECA 类似,DEPA 也采用了双重增强机制。DEPA 在空间维度上重新编码,强调重要的像素位置,同时最小化不相关的像素位置。
具体而言,为了获得包含全局信息的混合特征,我们使用卷积对两个特征图 FV1F_{V1}FV1 和 FIR1F_{IR1}FIR1 执行形状变换。然后,对彼此的结果应用逐元素乘法:
WMix1=conv(FV1)⊗conv(FIR1)(6) W_{Mix1} = conv(F_{V1}) \otimes conv(F_{IR1}) \tag{6} WMix1=conv(FV1)⊗conv(FIR1)(6)
之后,对 WMix1W_{Mix1}WMix1 执行 softmax 操作。为了在空间维度上充分获取每种模态特定的特征,我们保留了不同卷积核大小学习到的空间信息的差异。
{WIR1temp=concat(conv1(FIR1),conv2(FIR1))WV1temp=concat(conv1(FV1),conv2(FV1))(7) \begin{cases} W_{IR1temp} = concat(conv_1(F_{IR1}), conv_2(F_{IR1})) \\ W_{V1temp} = concat(conv_1(F_{V1}), conv_2(F_{V1})) \end{cases} \tag{7} {WIR1temp=concat(conv1(FIR1),conv2(FIR1))WV1temp=concat(conv1(FV1),conv2(FV1))(7)
在公式 (7) 中,使用两个卷积操作从不同的尺度提取像素权重。通过在通道维度上拼接它们,我们可以获得 WIR1∈Rb×2×w×hW_{IR1} \in \mathbb{R}^{b \times 2 \times w \times h}WIR1∈Rb×2×w×h 和 WV1∈Rb×2×w×hW_{V1} \in \mathbb{R}^{b \times 2 \times w \times h}WV1∈Rb×2×w×h。然后,我们通过将通道数减半来压缩特征,并获得 WIR1∈Rb×1×w×hW_{IR1} \in \mathbb{R}^{b \times 1 \times w \times h}WIR1∈Rb×1×w×h 和 WV1∈Rb×1×w×hW_{V1} \in \mathbb{R}^{b \times 1 \times w \times h}WV1∈Rb×1×w×h。对 WIR1W_{IR1}WIR1 和 WV1W_{V1}WV1 应用由 softmax 处理后的 FMix1F_{Mix1}FMix1 的逐元素乘法:
{WenIR1=WIR1⊗softmax(FMix1)WenV1=WV1⊗softmax(FMix1)(8) \begin{cases} W_{enIR1} = W_{IR1} \otimes softmax(F_{Mix1}) \\ W_{enV1} = W_{V1} \otimes softmax(F_{Mix1}) \end{cases} \tag{8} {WenIR1=WIR1⊗softmax(FMix1)WenV1=WV1⊗softmax(FMix1)(8)
第二次增强是通过输入特征图与第一次增强结果之间的逐元素乘法操作来实现的:
{FIR=FIR1⊙WenV1FV=FV1⊙WenIR1(9) \begin{cases} F_{IR} = F_{IR1} \odot W_{enV1} \\ F_{V} = F_{V1} \odot W_{enIR1} \end{cases} \tag{9} {FIR=FIR1⊙WenV1FV=FV1⊙WenIR1(9)
公式 (9) 旨在从空间维度上的另一种模态中提取结构特征。最后,我们对 FIRF_{IR}FIR 和 FVF_{V}FV 进行逐元素相加,以用于目标检测。
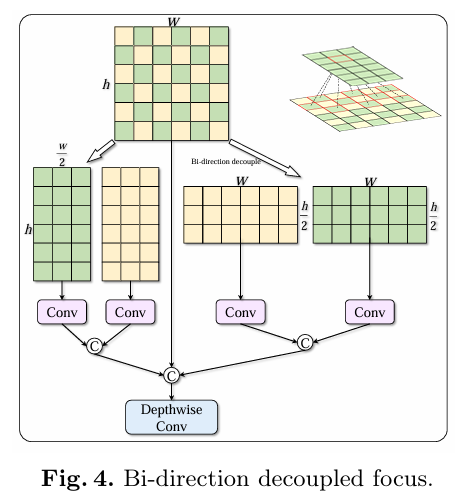
3.3 双向解耦聚焦 (Bi-direction Decoupled Focus)
在本小节中,我们倾向于从单模态的角度提高目标检测的性能。为了增强提取目标的能力,设计了双向解耦聚焦以扩大 DEYOLO 骨干网络的感受野,同时最小化周围像素的损失。
YOLOv5 中的 focus 块是一种切片操作,它是对 YOLOv2 中 passthrough 层的改进。这种特定操作以间隔一个像素的方式获取图像中的像素,从而可以在不丢失信息的情况下提供两倍下采样的特征图。
受这种下采样方法的启发,我们设计了双向解耦聚焦,以在多方向上充分保留信息。具体而言,我们采用了水平和垂直实现的两种特定采样和编码规则。如图 4 所示,我们将像素分为两组进行卷积。每组同时关注相邻和远处的像素。最后,我们在通道维度上拼接原始特征图,并使其通过深度可分离卷积(depth-wise convolution)层。
4. 实验
4.1 数据集
由于红外图像是通过测量物体发出的热辐射获得的,它们容易受到环境中噪声的影响。事实上,只有少量由红外和可见光图像组成的高质量数据集可用,例如 TNO 和 RoadScene。然而,这些数据集通常针对红外和可见光图像融合任务,而不是目标检测,因此缺乏目标检测的标签。FLIR 数据集提供了目标检测的注释,但缺乏像素级对齐。因此,我们选择了公共数据集 M3FD、LLVIP 和 KAIST,这些数据集在红外-可见光图像对上是像素级对齐的,并包含目标检测的注释。其中,M3FD 数据集包含 4,200 对图像,总计 8,400 张图像。LLVIP 数据集包含 16,836 对图像,总计 33,672 张图像。考虑到原始 KAIST 数据集包含有噪声的注释,我们使用了清理后的训练集(7,601 个样本)和测试集(2,252 个样本)。
4.2 实现细节
在本小节中,进行了两组实验以验证 DEYOLO 的有效性。一组是与 SOTA 单模态目标检测算法的比较,另一组是与融合-检测算法的比较。在训练单模态检测算法时,我们分别使用红外和可见光图像训练模型。为了实验的公平性,我们还将数据集中的可见光和红外图像组合起来,作为这些检测器的训练集。对于融合-检测算法,在比较算法中采用了用于跨模态融合的预训练图像融合模型,然后将融合后的图像进一步用于训练 YOLOv8。训练在八张 NVIDIA RTX 4090 GPU 上进行。训练的 epoch 数为 800,批量大小(batch size)为 64,初始和最终学习率分别为 1×10−21 \times 10^{-2}1×10−2 和 1×10−41 \times 10^{-4}1×10−4。我们在验证集上评估我们的方法,并使用 IoU 阈值为 0.5 的平均精度均值(mAP)和平均对数漏检率(LAMR)作为评估指标。
4.3 消融实验
为了验证 DEYOLO 中关键组件的影响,我们在 M3FD 数据集上进行了大量实验,以研究它们如何影响我们的最终性能。
表 1. M3FD 数据集上的消融实验。 Bi-direction 表示在骨干网络上使用双向解耦聚焦。DECA 表示使用 DECA 模块。DEPA 表示使用 DEPA 模块。
| Bi-direction | DECA | DEPA | mAP50 | mAP50-95 |
|---|---|---|---|---|
| 80.8 | 54.3 | |||
| ✓\checkmark✓ | 85.0 | 58.7 | ||
| ✓\checkmark✓ | 84.4 | 57.8 | ||
| ✓\checkmark✓ | 85.2 | 58.9 | ||
| ✓\checkmark✓ | ✓\checkmark✓ | ✓\checkmark✓ | 86.6 | 59.6 |
首先,我们分别验证了使用双向解耦聚焦、DECA 和 DEPA 模块对模型的影响。实验结果如表 1 所示。可以看出,DECA 和 DEPA 更明显地提高了模型的检测精度。与仅使用可见光图像训练的基线网络相比,单独使用 DECA 和 DEPA 模块可将 mAP50 分别提高 4.2% 和 3.6%,将 mAP50-95 分别提高 4.4% 和 3.5%。而 DECA 的改进比 DEPA 更明显。联合使用它们可将 mAP50 提高 4.4%,将 mAP50-95 提高 4.6%。此外,同时使用所有三个模块可进一步提高目标检测精度,这两个指标分别提高了 5.8% 和 5.3%。
在 DECA 和 DEPA 模块中,结合了来自两种模态的语义和空间信息的通道权重和空间像素权重,分别用于增强单模态通道权重和空间像素权重内的语义和结构信息。然后将增强的权重应用于单模态特征图,以实现双重增强。通过充分利用每种模态的优势及其在特征空间内的互补信息,使用 DECA 和 DEPA 可以提高跨模态目标检测的性能。由于我们使用的是深度特征,与空间信息相比,每个特征图包含更强的语义信息。因此,DECA 对模型的增强效果比 DEPA 更显著。
此外,为了研究如何使 DECA 和 DEPA 中的双重增强机制缓解双模态图像之间的干扰并更好地获得跨模态通道权重和像素权重,我们分别在 DEPA 的特征混合部分和 DECA 的跨模态权重提取部分选择了不同的超参数。
表 2. DEPA 中用于获取混合特征的不同卷积核大小的性能。
| Layer | Kernel Size | mAP50 | mAP50-95 |
|---|---|---|---|
| Conv | 3×33 \times 33×3 | 85.3 | 58.9 |
| 5×55 \times 55×5 | 85.1 | 58.4 | |
| 7×77 \times 77×7 | 85.1 | 58.1 |
对于 DEPA,我们使用不同的卷积核大小来获取两种模态的空间像素权重。结果如表 2 所示。我们认为,随着卷积核大小的增加,每种单模态内越来越多的冗余信息也被整合进来,从而增加了两种模态之间的相互干扰,阻碍了特征增强。我们发现,对于不同尺度的特征图,当卷积层数相同时,3×33 \times 33×3 的核大小能更好地对空间像素信息进行建模。
表 3. DECA 中通过跨模态权重提取生成 WMix0W_{Mix0}WMix0 的不同方式的性能。
| Layer | Number of Layers | mAP50 | mAP50-95 |
|---|---|---|---|
| Conv | 1 | ×\times× | ×\times× |
| 2 | 84.5 | 58.1 | |
| 3 | 84.9 | 57.8 | |
| Depth-wise Conv | 2 | 84.5 | 58.3 |
| 3 | 85.2 | 58.9 |
对于 DECA,我们尝试使用具有不同层数的不同类型的卷积来进行跨模态通道权重提取。实验结果如表 3 所示。我们首先尝试通过一层与原始特征图大小相同的卷积直接提取每个通道的权重。然而,我们发现如果层数设置为 1,模型无法收敛(表中用 ×\times× 表示)。然后,我们连续将卷积层数设置为 2 和 3,发现当层数为 3 时,可以更好地提取每个通道的权重。对于通道权重提取,我们发现深度可分离卷积(depth-wise convolution)由于其快速的收敛速度,更适合引导训练过程,这证明了它的优势。
4.4 与最先进 (SOTA) 模型的比较
最后,我们在 M3FD 和 LLVIP 数据集上将 DEYOLO 与最近的 SOTA 融合模型和目标检测模型进行了比较。这里我们选择 YOLOv8-n 和 YOLOv8-l 作为我们的基线。
表 4. 与其他检测器的性能比较。 Visible 表示使用可见光图像训练模型,infrared 表示使用红外图像训练模型。Cross-modality 表示使用双模态图像进行训练。
| Method | Modality | mAP50 | mAP50-95 |
|---|---|---|---|
| Swin Transformer | visible | 76.4 | 44.9 |
| infrared | 72.6 | 41.9 | |
| cross-modality | 73.8 | 42.6 | |
| CenterNet2 | visible | 78.5 | 52.4 |
| infrared | 65.3 | 42.4 | |
| cross-modality | 70.2 | 46.5 | |
| Sparse RCNN | visible | 82.4 | 49.6 |
| infrared | 76.4 | 44.8 | |
| cross-modality | 78.2 | 47.3 | |
| YOLOv7-tiny | visible | 82.1 | 51.6 |
| infrared | 78.1 | 48.4 | |
| cross-modality | 80.1 | 49.8 | |
| YOLOv7 | visible | 90.4 | 61.3 |
| infrared | 87.9 | 58.3 | |
| cross-modality | 88.3 | 59.6 | |
| YOLOv8n | visible | 80.8 | 54.3 |
| infrared | 78.3 | 52.3 | |
| cross-modality | 79.2 | 52.8 | |
| YOLOv8l | visible | 88.3 | 61.8 |
| infrared | 86.5 | 59.6 | |
| DEYOLO-n (ours) | Cross-modality | 86.6 | 58.9 |
| DEYOLO-l (ours) | Cross-modality | 91.2 | 66.3 |
如表 4 所示,由于利用了来自两种模态的不同信息,DEYOLO 优于所有单模态目标检测模型。此外,使用可见光图像训练的检测器的 mAP 高于使用红外图像训练的检测器。但没有任何单模态检测器能超越使用双重特征增强机制的 DEYOLO。特别是,DEYOLO 优于基于 ViT 的模型,如 Swin Transformer 和 Sparse RCNN。基于 ViT 的模型仅考虑单模态全局相关性,而 DEYOLO 额外使用了由 DECA 和 DEPA 提取的两种模态之间的互补信息,且没有冲突。
可以观察到,一些融合-检测方法(如 DetFusion 和 U2Fusion)产生的融合图像看起来更像红外图像,缺乏检测任务所需的部分纹理和颜色信息。另一方面,其他方法(包括 SeAFusion 和 Tardal)获得的融合图像未能有效捕获红外图像中丰富的结构信息。比较方法未能平衡两种模态的纹理和结构信息以提高检测精度。相比之下,DEYOLO 首先通过双向解耦聚焦利用两种模态的优势,然后基于双重增强机制利用 DECA 和 DEPA 模块减少两种模态之间的相互干扰,从而提高检测精度。
表 5. 与融合-检测工作的性能比较。
| Dataset | Method | Modality | mAP50 | mAP50-95 |
|---|---|---|---|---|
| M3FD | IRFS | cross-modality | 81.2 | 55.8 |
| Tardal | cross-modality | 81.0 | 54.9 | |
| CDDFuse | cross-modality | 80.3 | 54.9 | |
| PIAFusion | cross-modality | 80.6 | 54.9 | |
| Swin Fusion | cross-modality | 80.2 | 54.7 | |
| DetFusion | cross-modality | 80.6 | 55.0 | |
| SeAFusion | cross-modality | 80.7 | 55.4 | |
| U2Fusion | cross-modality | 79.2 | 53.8 | |
| DEYOLO-n (ours) | cross-modality | 86.6 | 58.9 | |
| DEYOLO-l (ours) | cross-modality | 91.2 | 66.3 | |
| LLVIP | IRFS | cross-modality | 94.0 | 60.7 |
| Tardal | cross-modality | 94.5 | 63.3 | |
| CDDFuse | cross-modality | 92.1 | 57.5 | |
| PIAFusion | cross-modality | 96.1 | 62.4 | |
| Swin Fusion | cross-modality | 93.3 | 59.4 | |
| MFEIF | cross-modality | 95.8 | 64.0 | |
| SeAFusion | cross-modality | 96.2 | 64.0 | |
| U2Fusion | cross-modality | 92.2 | 58.3 | |
| DEYOLO-n (ours) | cross-modality | 96.8 | 65.4 |
如表 5 所示,我们的方法在两个数据集上的性能均优于最先进的融合-检测方法。具体而言,在 M3FD 数据集中,DEYOLO-n 的 mAP50 和 mAP50-95 至少比其他模型高出 5.4% 和 3.1%。而 DEYOLO-l 的 mAP50 和 mAP50-95 的提升可分别达到 10.0% 和 10.5% 以上。同时,在 LLVIP 数据集中,我们观察到 DEYOLO-n 的 mAP50 和 mAP50-95 分别至少有 0.6% 和 1.4% 的提升。此外,在图 5 和图 6 中,M3FD 数据集中每个类别的检测结果也显示了我们方法的优越性。
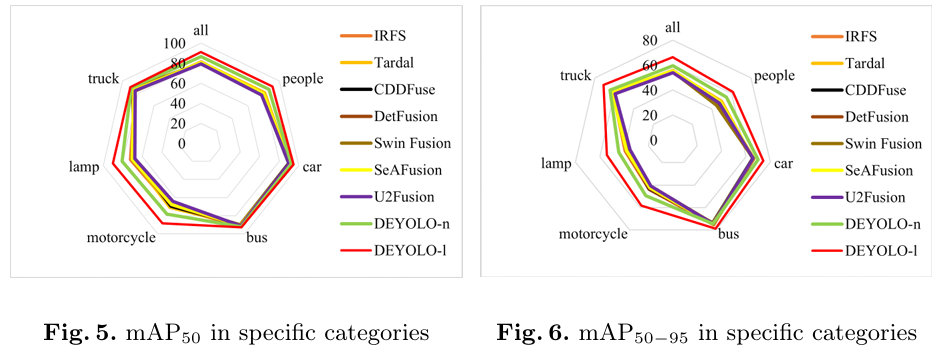
表 6. KAIST 数据集上与其他 RGB-T 检测器的比较。
| Methods | ALL | Day | NIGHT |
|---|---|---|---|
| RPN+BDT | 29.83 | 30.51 | 27.62 |
| TC-DET | 27.11 | 34.81 | 10.31 |
| Halfway Fusion | 25.75 | 24.88 | 26.59 |
| IATDNN | 26.37 | 27.29 | 24.41 |
| IAF R-CNN | 20.59 | 21.85 | 18.96 |
| CIAN | 14.12 | 14.77 | 11.13 |
| DEYOLO (ours) | 15.45 | 17.23 | 12.23 |
为了验证我们模型的泛化能力,我们在 KAIST 数据集上进行了实验,如表 6 所示。与 M3FD 和 LLVIP 数据集不同,KAIST 由 RGB 和热成像图像对组成。热成像图像与我们研究中研究的红外图像不同,其成像质量较低且差异显著。因此,这些实验作为对我们模型的扩展验证。从表 6 中可以明显看出,我们的方法虽然没有达到 SOTA 性能,但优于大多数现有方法。
5. 结论
在本文中,我们提出了 DEYOLO,使用双重增强机制用于复杂光照环境下的跨模态目标检测。设计了 DECA 和 DEPA,以在骨干网络和检测头之间融合两种模态的特征图。并在骨干网络中提出了双向解耦聚焦,以提高特征提取能力。该方法在两个数据集上的优越性得到了验证。值得指出的是,本文提出的 DECA 和 DEPA 都可以作为即插即用模块,在其他模型中更广泛地应用,以解决复杂环境下的目标检测问题。这将是我们未来工作的主题。
6. 致谢
本工作部分受中国国家自然科学基金(批准号:U21A20486, 62473208 和 62401294)、天津市杰出青年科学基金(批准号:20JCJQJC00140)、山东省自然科学基金重大基础研究项目(批准号:ZR2019ZD07)、中国博士后科学基金资助项目(批准号:GZC20240753)以及中央高校基本科研业务费专项资金(批准号:078-63243158)的资助。
参考文献
(注:为保持学术引用的准确性与规范性,参考文献列表保留英文原文。)
- FLIR: Flir thermal dataset for algorithm training. https://www.flir.in/oem/adas/adas-dataset-form (2018)
- Bochkovskiy, A., Wang, C.Y., Liao, H.Y.M.: Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020)
- Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European conference on computer vision. pp. 213--229. Springer (2020)
- Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1251--1258 (2017)
- Dai, Y., Wu, Y., Zhou, F., Barnard, K.: Attentional local contrast networks for infrared small target detection. IEEE Transactions on Geoscience and Remote Sensing 59(11), 9813--9824 (2021)
- Guan, D., Cao, Y., Yang, J., Cao, Y., Yang, M.Y.: Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection. Information Fusion 50, 148--157 (2019)
- Hou, Q., Zhang, L., Tan, F., Xi, Y., Zheng, H., Li, N.: Istdu-net: Infrared small-target detection u-net. IEEE Geoscience and Remote Sensing Letters 19, 1--5 (2022)
- Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132--7141 (2018)
- Hwang, S., Park, J., Kim, N., Choi, Y., So Kweon, I.: Multispectral pedestrian detection: Benchmark dataset and baseline. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1037--1045 (2015)
- Jia, X., Zhu, C., Li, M., Tang, W., Zhou, W.: LLVIP: A visible-infrared paired dataset for low-light vision. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3496--3504 (2021)
- Jocher, G.: YOLOv5 by Ultralytics (May 2020). https://github.com/ultralytics/yolov5
- Jocher, G.: ultralytics/yolov8: v8.1.0- yolov8 oriented bounding boxes (obb). https://github.com/ultralytics/ultralytics (2024)
- Kieu, M., Bagdanov, A.D., Bertini, M., Del Bimbo, A.: Task-conditioned domain adaptation for pedestrian detection in thermal imagery. In: European conference on computer vision. pp. 546--562. Springer (2020)
- Li, C., Song, D., Tong, R., Tang, M.: Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognition 85, 161--171 (2019)
- Liu, J., Zhang, S., Wang, S., Metaxas, D.N.: Multispectral deep neural networks for pedestrian detection. arXiv preprint arXiv:1611.02644 (2016)
- Liu, J., Fan, X., Huang, Z., Wu, G., Liu, R., Zhong, W., Luo, Z.: Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In: CVPR. pp. 5802--5811 (2022)
- Liu, J., Fan, X., Jiang, J., Liu, R., Luo, Z.: Learning a deep multi-scale feature ensemble and an edge-attention guidance for image fusion. IEEE TCSVT 32(1), 105--119 (2021)
- Liu, Z., Lin, Y., Cao, Y., et al.: Swin transformer: Hierarchical vision transformer using shifted windows. In: ICCV. pp. 10012--10022 (2021)
- Ma, J., Tang, L., Fan, F., et al.: SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA Journal of Automatica Sinica 9(7), 1200--1217 (2022)
- Park, K., Kim, S., Sohn, K.: Unified multi-spectral pedestrian detection based on probabilistic fusion networks. Pattern Recognition 80, 143--155 (2018)
- Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: CVPR. pp. 779--788 (2016)
- Redmon, J., Farhadi, A.: YOLO9000: better, faster, stronger. In: CVPR. pp. 7263--7271 (2017)
- Sun, P., Zhang, R., Jiang, Y., et al.: Sparse r-cnn: End-to-end object detection with learnable proposals. In: CVPR. pp. 14454--14463 (2021)
- Sun, Y., Cao, B., Zhu, P., Hu, Q.: Detfusion: A detection-driven infrared and visible image fusion network. In: ACM MM. pp. 4003--4011 (2022)
- Tang, L., Yuan, J., Ma, J.: Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Information Fusion 82, 28--42 (2022)
- Tang, L., Yuan, J., Zhang, H., Jiang, X., Ma, J.: PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Information Fusion 83, 79--92 (2022)
- Toet, A.: The TNO multiband image data collection. Data in brief 15, 249--251 (2017)
- Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. NeurIPS 30 (2017)
- Wang, C.Y., Bochkovskiy, A., Liao, H.Y.M.: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: CVPR. pp. 7464--7475 (2023)
- Wang, D., Liu, J., Liu, R., Fan, X.: An interactively reinforced paradigm for joint infrared-visible image fusion and saliency object detection. Information Fusion 98, 101828 (2023)
- Xu, H., Ma, J., Jiang, J., Guo, X., Ling, H.: U2fusion: A unified unsupervised image fusion network. IEEE TPAMI 44(1), 502--518 (2020)
- Xu, H., Ma, J., Le, Z., Jiang, J., Guo, X.: FusionDN: A Unified Densely Connected Network for Image Fusion. In: AAAI (2020)
- Zhang, L., Liu, Z., Zhang, S., et al.: Cross-modality interactive attention network for multispectral pedestrian detection. Information Fusion 50, 20--29 (2019)
- Zhao, B., Wang, C., Fu, Q., Han, Z.: A novel pattern for infrared small target detection with generative adversarial network. IEEE TGRS 59(5), 4481--4492 (2020)
- Zhao, Z., Bai, H., Zhang, J., et al.: CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion. In: CVPR. pp. 5906--5916 (2023)
- Zhou, X., Koltun, V., Krähenbühl, P.: Probabilistic two-stage detection. arXiv preprint arXiv:2103.07461 (2021)