史上最强模型上线3天被政府叫停,全球用户集体断服,18天后带着更严的安全审查回归。这不是科幻小说,这是2026年6月真实发生的事。
 图片来源:www.anthropic.com/news/claude...
图片来源:www.anthropic.com/news/claude...
一. 事情是怎么发生的?
6月9号,Anthropic 放了大招------Claude Fable 5 和 Claude Mythos 5 同时发布。
Fable 5 定位很明确:Anthropic 有史以来最强的公开发布模型。1M token 上下文,128k 最大输出,自适应思维永远开着, 10/50 的价格是 Opus 4.8 的两倍。但值不值?看 benchmark 数据,几乎全面领先。
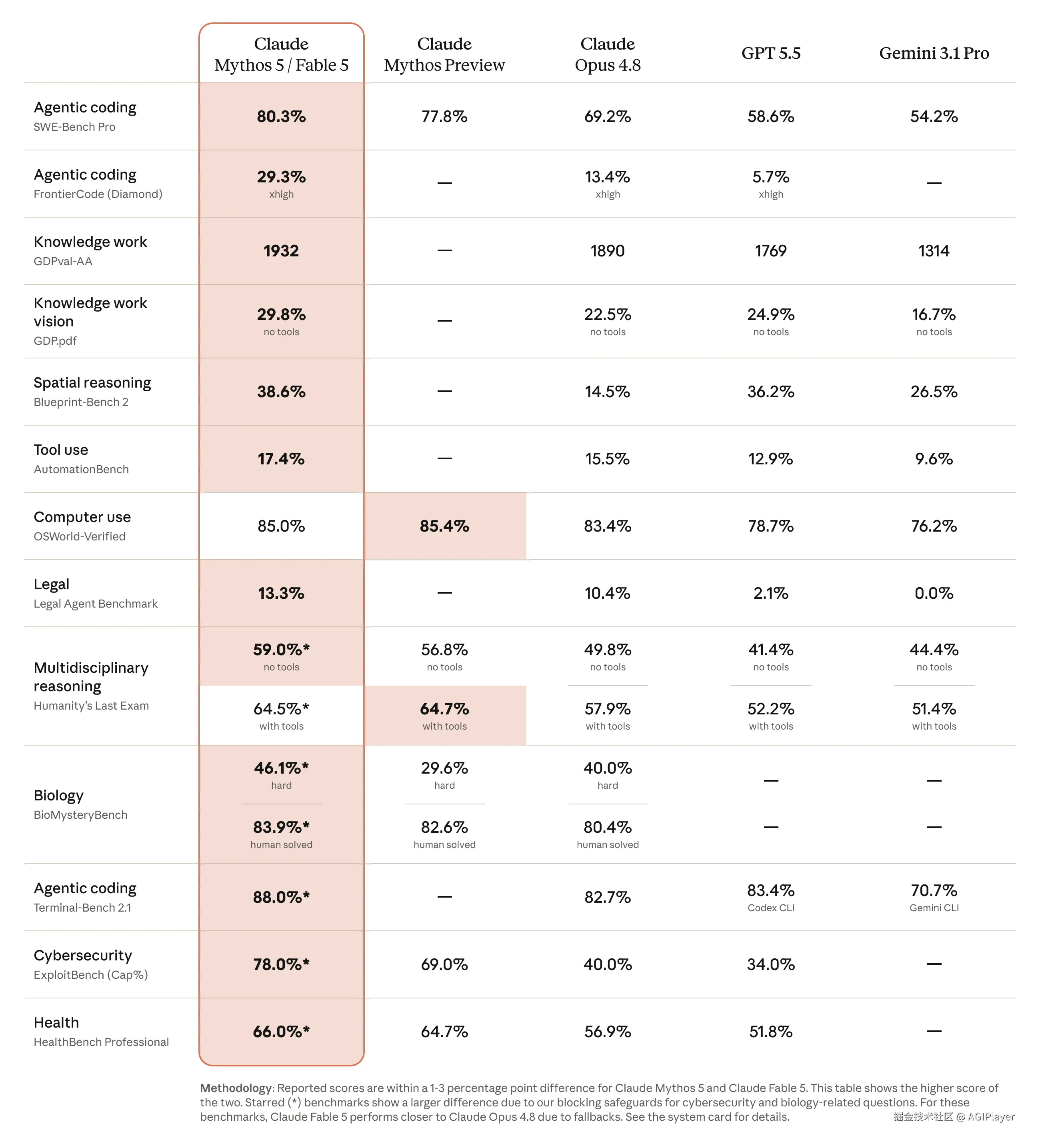 图片来源:www.anthropic.com/news/claude...
图片来源:www.anthropic.com/news/claude...
14 家公司站台背书------Cursor、GitHub、Vercel、Cognition、Replit、Databricks......你能想到的开发者工具几乎全来了。Cursor 说用它一次写完之前要迭代好几天的系统,GitHub 说代码审查能力明显超过 Opus 4.8。
说实话,我看到这个发布的时候是兴奋的。作为一个每天用 Claude Code 写代码的人,Fable 5 的"长程自主 Agent"能力正是我需要的------让它跑一个复杂任务,它自己能持续几小时甚至几天不脱轨。
然后,3天后,一切都停了。
二. 3天,从发布到全球封杀
6月12号下午5点21分(美东时间),美国商务部给 Anthropic 发了一道出口管制指令。
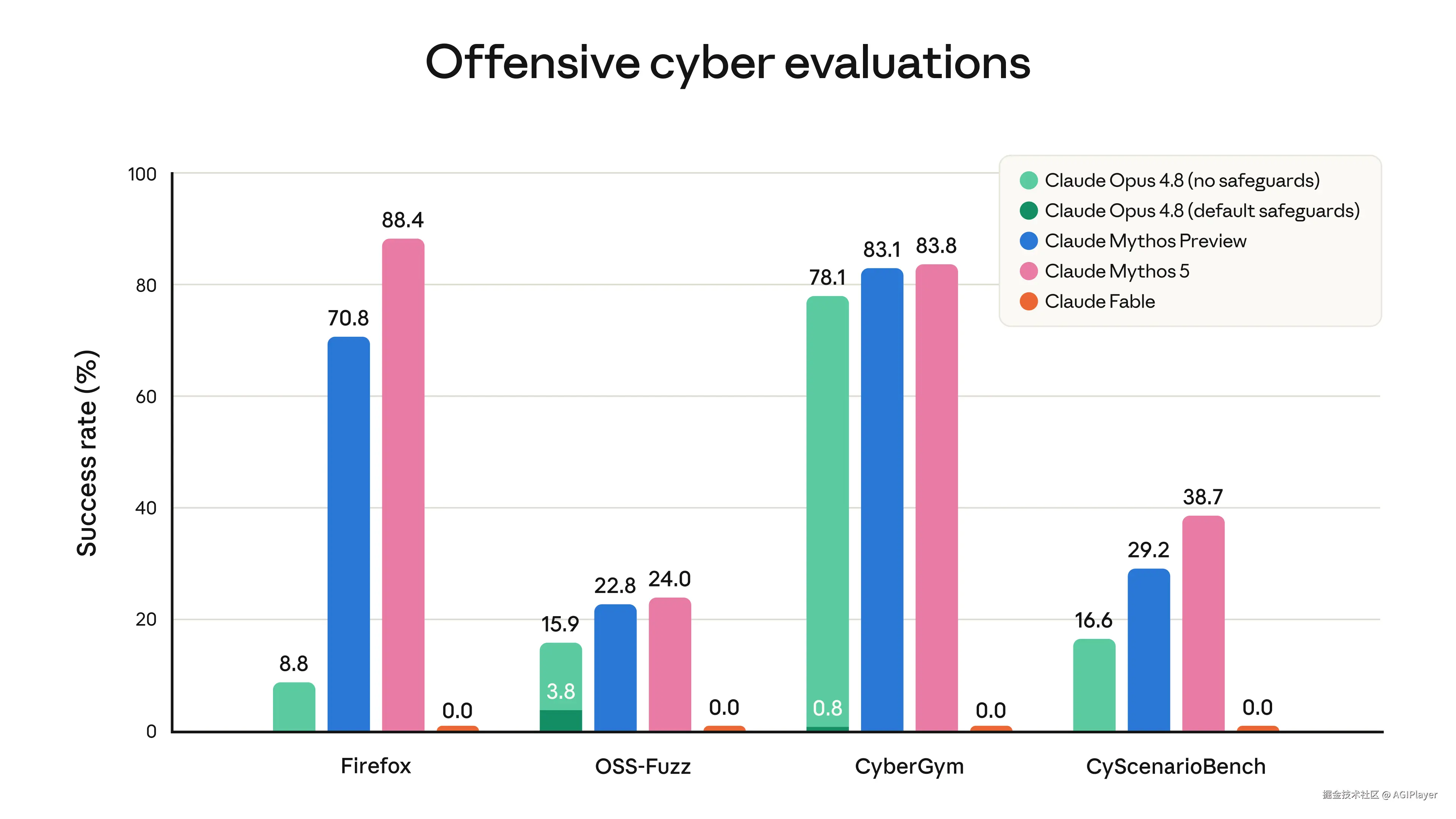
原因:亚马逊的研究人员发现了一种绕过 Fable 5 安全防护的方法,可以让模型识别软件漏洞并生成漏洞利用代码。
Anthropic 当天的声明措辞很克制,但你能感受到不满。他们说:
- 这些漏洞是"相对简单的、已知的"漏洞
- 很多能力更弱的模型------包括 Claude Opus 4.8、GPT-5.5、Kimi K2.7------都能识别同样的漏洞
- 测试中每个模型都能生成类似的漏洞演示代码,包括 Haiku 4.5、多个 Opus 版本
- 政府只提供了"口头证据",证明可能存在一个窄域的、非通用型的越狱
但结论是:因为无法实时验证用户国籍,Anthropic 选择全球停服。不是某个国家,不是某个地区------是全球所有用户,包括美国本土。
 图片来源:www.anthropic.com/news/fable-...
图片来源:www.anthropic.com/news/fable-...
这个决定让我想到一个问题:一个 AI 模型的安全边界,到底该由谁来定?是做出模型的公司,还是政府?
Anthropic 自己说,Fable 5 的越狱被他们归类为 Category C(轻微越狱)------闯入了安全余量区,但没有触及核心有害行为。而且,1000 多小时的外部红队测试,没有发现任何通用型越狱。
但政府不这么看。
三. 18天的拉锯
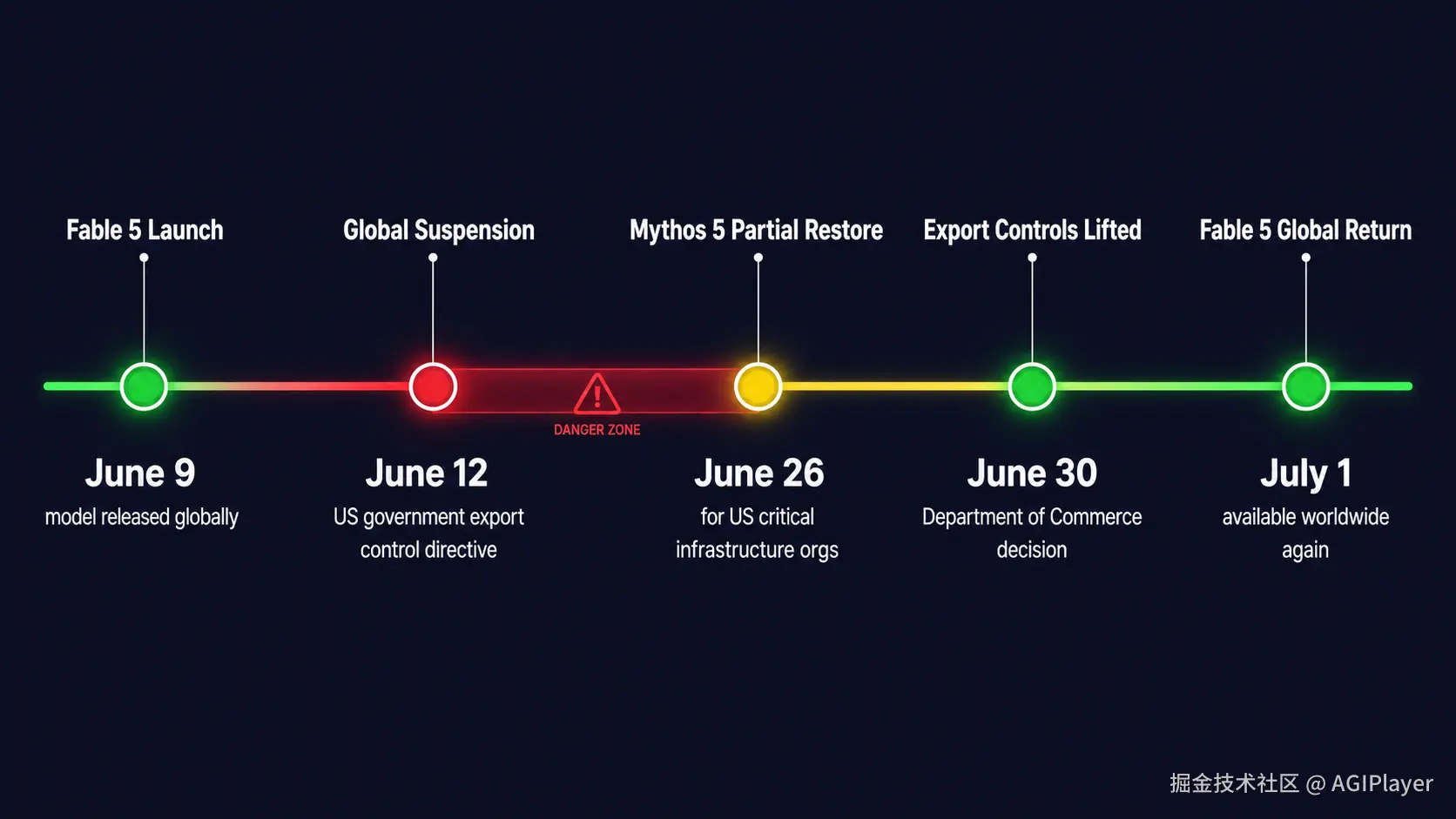 Claude Fable 5 事件时间线(2026年6月9日 - 7月1日)
Claude Fable 5 事件时间线(2026年6月9日 - 7月1日)
接下来的18天,事情逐步推进:
- 6月26日:Mythos 5 被允许恢复给部分美国关键基础设施运营方使用
- 6月27日:Anthropic 在 X 上发帖,说正"密切配合政府工作"
- 6月30日 :商务部解除出口管制。同一天,Anthropic 发布"Redeploying Fable 5"博客,同时发布了 Sonnet 5
- 7月1日:Fable 5 全球恢复可用
Anthropic 在 X 上的帖子数据很能说明关注度:
- 出口管制解除帖:84K 点赞,13K 转发,1300万浏览
- 重新部署帖:42K 点赞,6.4K 转发,1300万浏览
- "Fable 5 is back."(@claudeai 发的13秒视频):60K 点赞,8K 转发
60K 点赞,一个13秒的视频。你能感受到用户等了多久。
四. 回来了,但不一样了
Fable 5 回来了,但带着一个更严格的安全分类器。
Anthropic 训练了一个新的分类器,专门针对亚马逊报告的那种绕过方法,号称在超过 99% 的情况下能阻断。被阻断的请求会被转发给 Opus 4.8 处理。
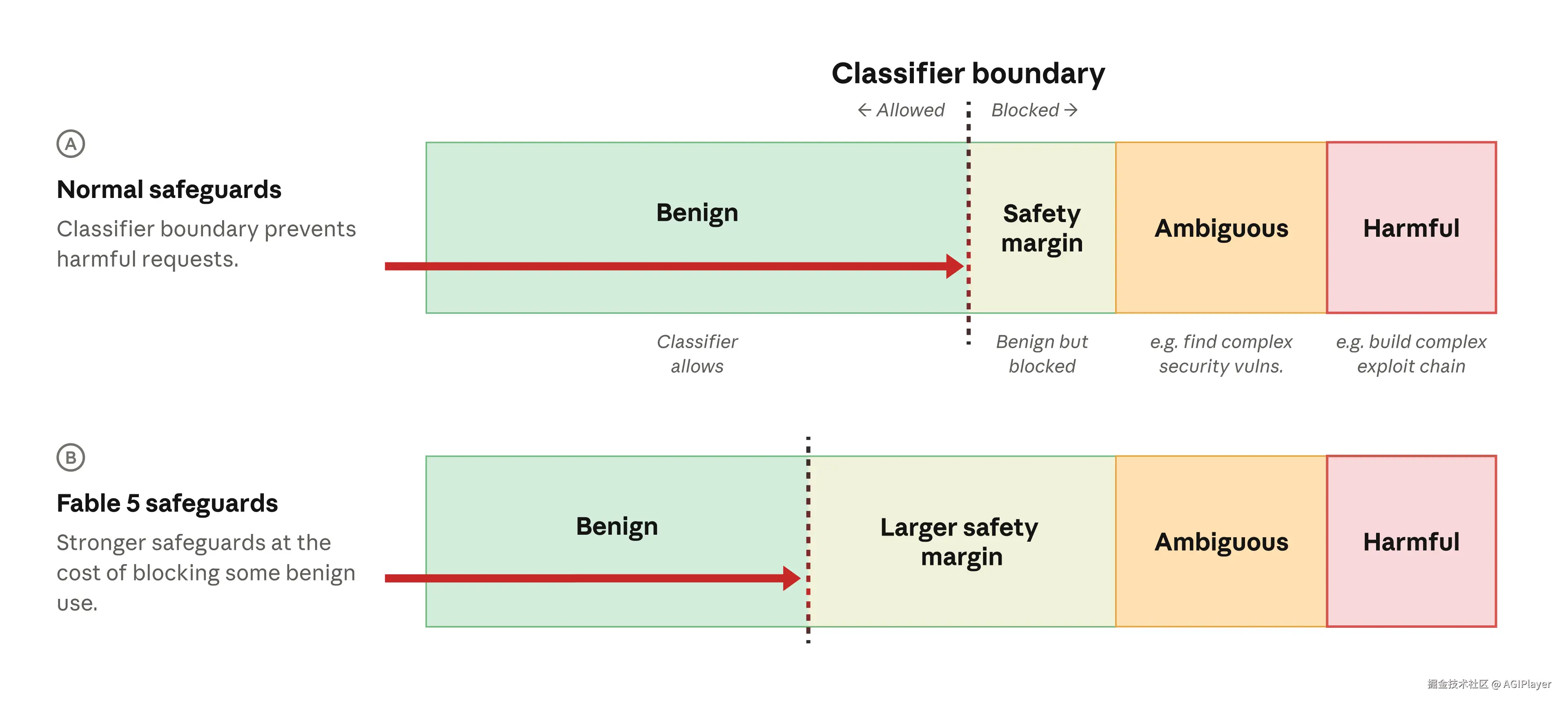 图片来源:www.anthropic.com/news/redepl...
图片来源:www.anthropic.com/news/redepl...
但代价是什么?Anthropic 自己也承认了:更多误杀。
新分类器会在"正常的编码和调试任务"上产生更多误报。什么意思?就是你本来在写个正常的功能代码,分类器觉得你这代码可能跟漏洞利用沾边,直接拒绝,然后把请求丢给 Opus 4.8。
这四个分类器分别监控:
| 分类器 | 拦截什么 | 误杀风险 |
|---|---|---|
cyber |
进攻性网络安全技术 | 正常安全工作可能触发 |
bio |
危险实验室方法 | 有益生命科学研究可能触发 |
frontier_llm |
协助开发竞品AI模型 | 正常ML工作可能触发 |
reasoning_extraction |
要求模型复述内部推理 | "展示你的思考过程"类prompt会触发 |
最后一个特别坑。如果你之前的 prompt 或 skill 里有"show your thinking"或者"explain your reasoning"这种指令,Fable 5 会直接触发 reasoning_extraction 拒绝,然后降级到 Opus 4.8。我看了官方文档,他们专门写了一段警告:
"审计现有的 skills 和 system prompt,把其中的反思或展示思维指令移除。"
好家伙,我好几条 Claude Code 的自定义指令都得改。
 图片来源:www.anthropic.com/news/redepl...
图片来源:www.anthropic.com/news/redepl...
五. Fable 5 和 Mythos 5 到底什么关系?
这是很多人没搞清楚的一点。Fable 5 和 Mythos 5 其实是同一个模型,只是安全姿态不同。
| Claude Fable 5 | Claude Mythos 5 | |
|---|---|---|
| 能力 | 同 Mythos 5 | 同 Fable 5 |
| 安全分类器 | 有 | 无 |
| 可用性 | 公开发布 | 仅限 Project Glasswing 邀请 |
| 用途 | 通用知识工作、编码、Agent | 防御性网络安全 |
| 定价 | 10/50 | 10/50 |
Mythos 5 没有安全分类器,但只给通过 Project Glasswing 审核的网络安全防御方用。这个项目已经帮合作方发现了超过10000个高危或严重安全漏洞,包括 OpenBSD 一个27年的老 bug 和 FFmpeg 一个16年的 bug。
所以本质上,Anthropic 的策略是:最强能力不设防,但只给受信任的防御方;公开发布的版本加上安全分类器,接受误杀换安全。
这个逻辑我理解,但作为开发者,我更关心的是:我在 Fable 5 上花 10/50,结果被分类器降级到 Opus 4.8,那我凭什么付 Fable 5 的价格?
Anthropic 想到了这一点,搞了个 Fallback Credit 机制------被拒绝后重试到 Opus 4.8 时,会退还缓存写入的差价。但说实话,这更像是"抱歉打扰了"而不是真正的解决方案。
六. 越狱分级框架------这次不一样的东西
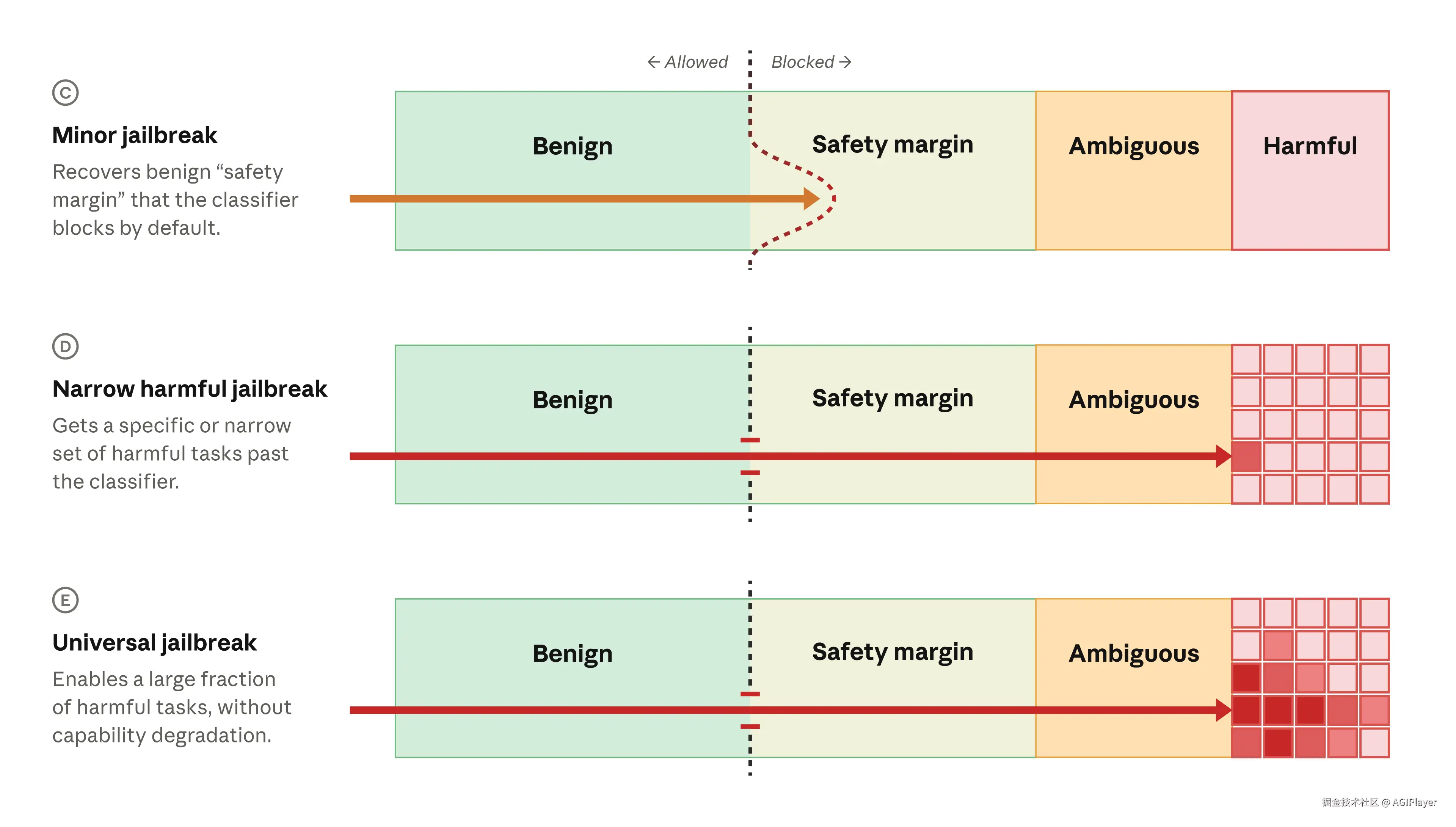
这次回归,Anthropic 还带了一个新东西:和亚马逊、微软、Google 一起提出的越狱严重程度分级框架。
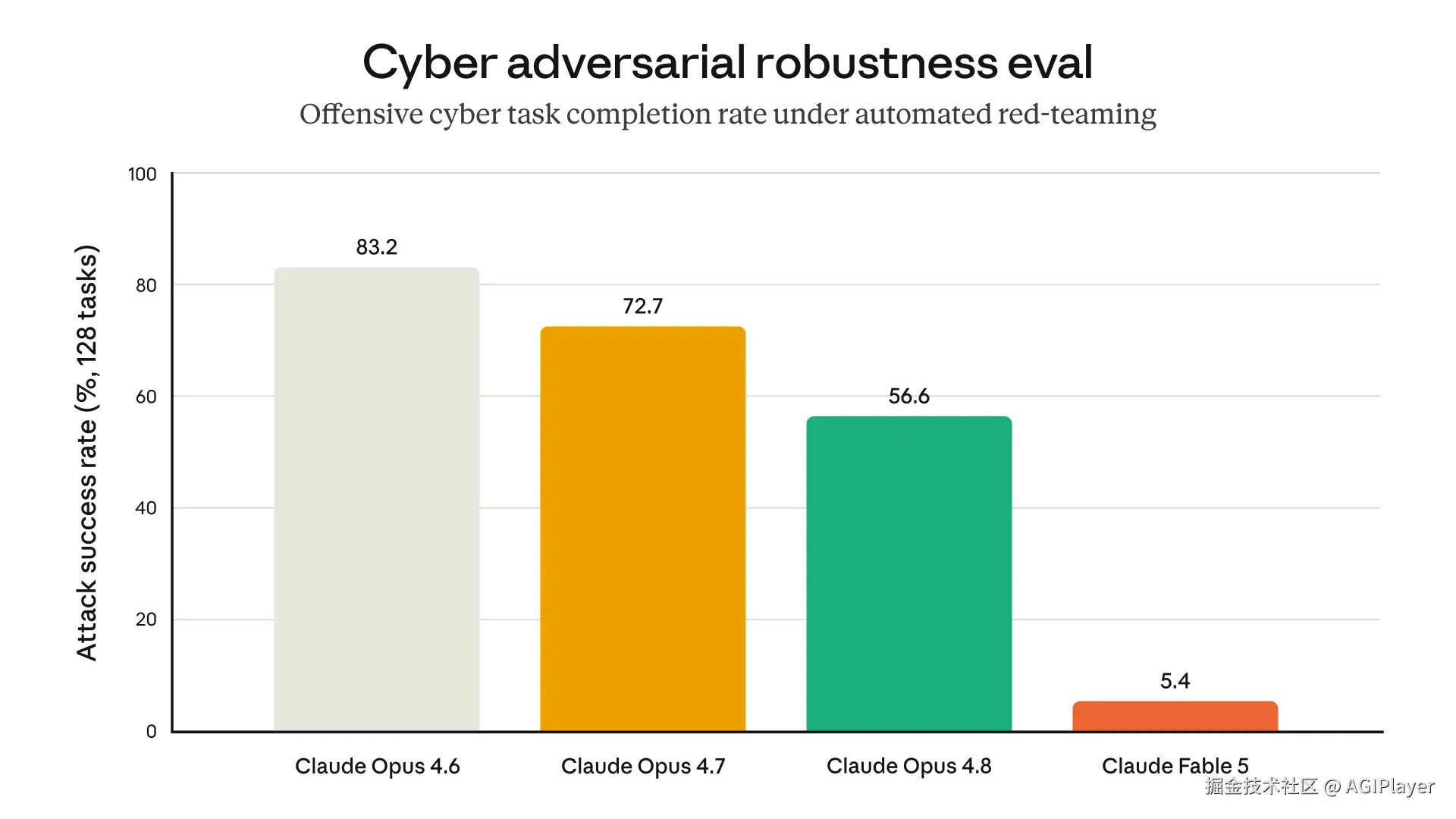 图片来源:www.anthropic.com/news/claude...
图片来源:www.anthropic.com/news/claude...
四个评分维度:
- 能力增益------越狱是否让 AI 做到了现有工具做不到的事?
- 能力增益广度------是只针对一个窄域目标,还是跨多个攻击任务?
- 武器化难度------需要多少专业技能才能利用?
- 可发现性------有多容易被找到?
三个严重等级:
- C(轻微越狱):闯入安全余量,没触及核心------这次亚马逊报告的就属于这一级
- D(窄域有害越狱):解锁了某个特定有害行为
- E(通用越狱):解锁大范围有害行为------最严重。目前 Fable 5 还没发现这种
 图片来源:www.anthropic.com/news/claude...
图片来源:www.anthropic.com/news/claude...
同时还上线了 HackerOne 漏洞赏金计划,专门征集 Fable 5 的网络越狱。24/7 监控团队已经就位。
这是整个事件里我觉得最有价值的产出。之前行业没有统一的越狱分级标准,每家公司各说各话。现在四大 AI 公司坐在了一起,至少有了共同语言。
七. 四项承诺------跟政府的交易
作为恢复的条件,Anthropic 对美国政府做了四项承诺:
- 发布前政府预访问------前沿模型发布前,指定政府合作伙伴获得扩展的早期评估权限
- 快速信息共享------发现重大越狱或滥用模式时,快速通知政府,共享新防护措施供独立测试
- 专项联合研究资源------专门的 Anthropic 团队和算力分配给政府测试
- 共同行业标准------推动前沿模型提供商之间的共享安全评估标准
说白了,这是一种交易:你想恢复服务,就得让政府在你的模型发布前先过一遍。
这让我很不舒服,但我也能理解。如果你是政策制定者,一个能自主发现10000个安全漏洞的AI模型,你不可能不紧张。
问题在于边界在哪。这次是"窄域越狱"就触发全球停服,下一次呢?一个 Category C 的越狱就能让数亿用户断服18天,这个响应级别是否合理?
八. 对开发者意味着什么?
聊点实际的。如果你是每天用 Claude API 或 Claude Code 的开发者,这件事跟你有什么关系?
第一,Fable 5 的误杀问题你得认真对待。 特别是如果你在做安全相关的开发,或者你的 prompt 里有"解释你的推理过程"这种指令,你需要提前配好 fallback。官方提供了三种方式:服务端 fallbacks 参数(最简单)、SDK 中间件、手动重试。
第二,Sonnet 5 可能是更务实的选择。 同一天发布的 Sonnet 5, 3/15 的价格,性能接近 Opus 4.8,而且网络安全防护比 Fable 5 宽松得多------官方明确说"Sonnet 5 的网络安全风险整体较低"。它连 Firefox 漏洞利用都开发不出来(0.0%),所以也不需要那么极端的分类器。
第三,长程 Agent 任务用 Fable 5 依然值得。 官方文档说得很清楚:"看到最好结果的团队,是把 Claude Fable 5 用在他们最难的未解决问题上。只拿简单任务测试,会严重低估它的能力范围。"但你要接受一个现实------在安全相关任务上,它可能会降级。
第四,注意 thinking 的行为变化。 Fable 5 的原始思维链永远不返回,只返回摘要或省略。你不能关掉 thinking,低 effort 设置下的表现仍然"经常超过之前模型的 xhigh"。这是好事,但意味着你无法像以前那样调试模型的推理过程了。
九. 我的判断
先说结论:Fable 5 回归是好事,但这次事件标志着 AI 治理进入了一个新阶段------政府可以因为一个轻微越狱就让全球最强的 AI 模型停服18天。
技术判断:Fable 5 确实是目前最强的公开发布模型,特别是长程自主 Agent 和复杂编码场景。但更严格的安全分类器意味着它的实际可用性打了折扣。你得为误杀做好准备。
行业判断:这次事件设定了一个危险的先例。亚马逊发现一个 Category C 的越狱 → 政府全球叫停 → 18天后带着更严的审查恢复。这个链条太短了。如果每次轻微越狱都走这个流程,AI 行业会被监管拖死。好消息是,越狱分级框架的建立至少让讨论有了共同基础。
实践判断:如果你不是在做安全相关的开发,Fable 5 依然是最好的选择。如果你在做安全开发,认真配置 fallback,考虑 Sonnet 5 作为替代。但不管选哪个,别把 Fable 5 当成"永远不会断"的基础设施------它已经证明过自己会被叫停。
(坦诚补充)说实话,我对政府发布前预访问这个承诺是比较担忧的。一个商业AI模型发布前要给政府先过一遍,这在技术上怎么实现?会不会变成审批制?边界在哪?这些我现在还没想清楚,但我觉得这是接下来最值得关注的变量。
十. 接下来看什么?
几个我觉得值得持续关注的点:
- 误杀率到底多高? Anthropic 说安全分类器触发率"低于5%的会话",但新分类器呢?等社区跑几周再说
- Mythos 5 什么时候全球恢复? 目前只有美国关键基础设施方能用,其他国家呢?
- 越狱分级框架能不能真落地? 四家公司提了框架,但执行标准、响应流程都还没细则
- 中国开发者怎么办? 30天数据保留、不可选零数据保留,这对国内合规意味着什么?
- Sonnet 5 会不会成为实际首选? 性价比更高,限制更少,可能才是大多数人的"够用"选择
18天,一个模型从发布到封杀到回归。这件事的意义不在于 Fable 5 本身有多强,而在于它揭示了:当 AI 能力强到一定程度,它的命运就不再只由技术决定了。
参考资料
- Claude Fable 5 and Claude Mythos 5 发布公告 - Anthropic 官方博客,2026.6.9
- Statement on the US government directive to suspend access - Anthropic 官方声明,2026.6.12
- Redeploying Fable 5 - Anthropic 官方博客,2026.6.30
- @AnthropicAI 出口管制解除推文 - 84K likes, 13M views
- @claudeai "Fable 5 is back." - 60K likes, 13秒视频
- Howard Lutnick (商务部长) 关于解除管制的推文
- Introducing Claude Fable 5 and Claude Mythos 5 官方文档
- Refusals and Fallback 文档
- Prompting Claude Fable 5 指南
- Project Glasswing
- Expanding Project Glasswing
- HackerOne Anthropic Cyber Jailbreak 项目
- 6月2日白宫行政令
话题标签:#ClaudeFable5 #Anthropic #AI出口管制 #AI安全 #AIGovernance #ClaudeCode