Unlimited-OCR,2026年6月百度最新开源 OCR 模型,是一个基于 DeepSeek OCR 改进的端到端文档解析模型,实现了长文档从第一页到最后一页的连贯高效输出,在 OmniDocBench v1.6 基准上达到 93.92% 综合指标,位列端到端模型第一。这次我在云服务器上配置了 SGLang 来加速模型,推理速度极快,仅需12GB 显存即可运行,还给 Unlimited OCR 添加了自定义 WebUI 前端,可以调用单图识别、多图识别、PDF长文档识别三种模式,并可视化输出结果。
以下链接可以免实名注册并送算力点试用 GPU 服务器:
注册链接:https://growthdata.virtaicloud.com/t/xK
登陆后进入项目链接:
https://open.virtaicloud.com/web/project/detail/727536358747230208
点击右上角运行一下,确定克隆项目和数据到自己工作空间,点击立即运行,启动后点右上角进入开发环境。
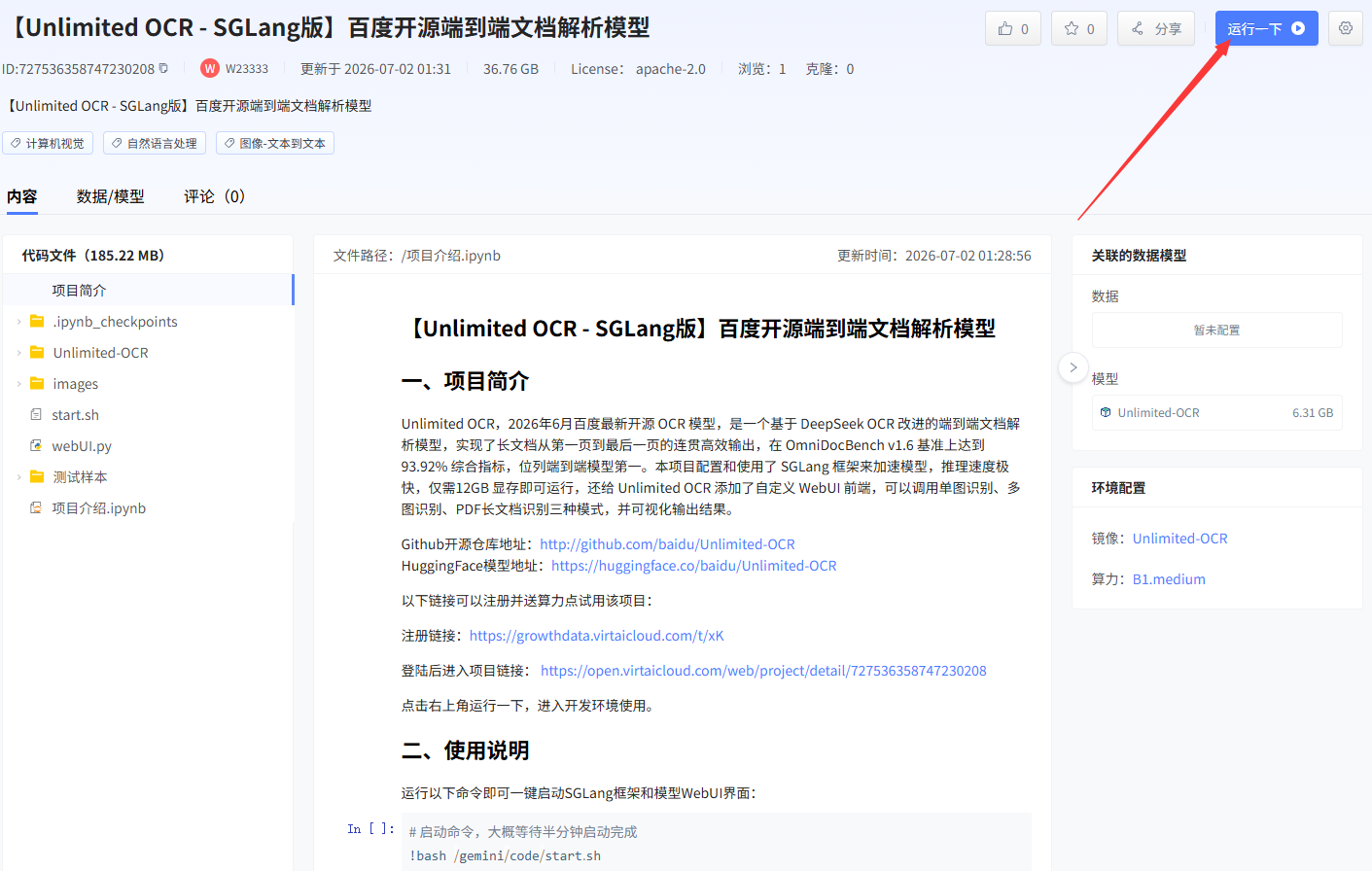
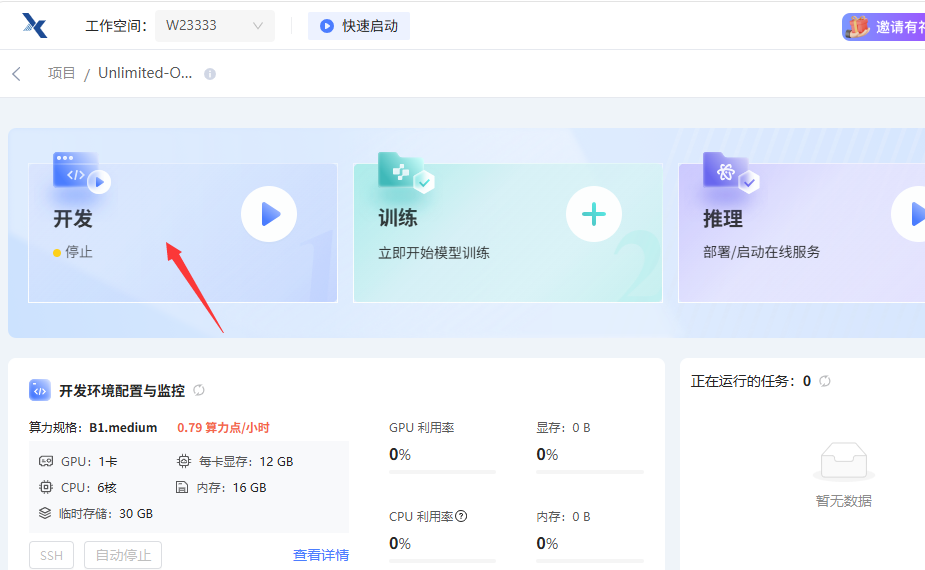
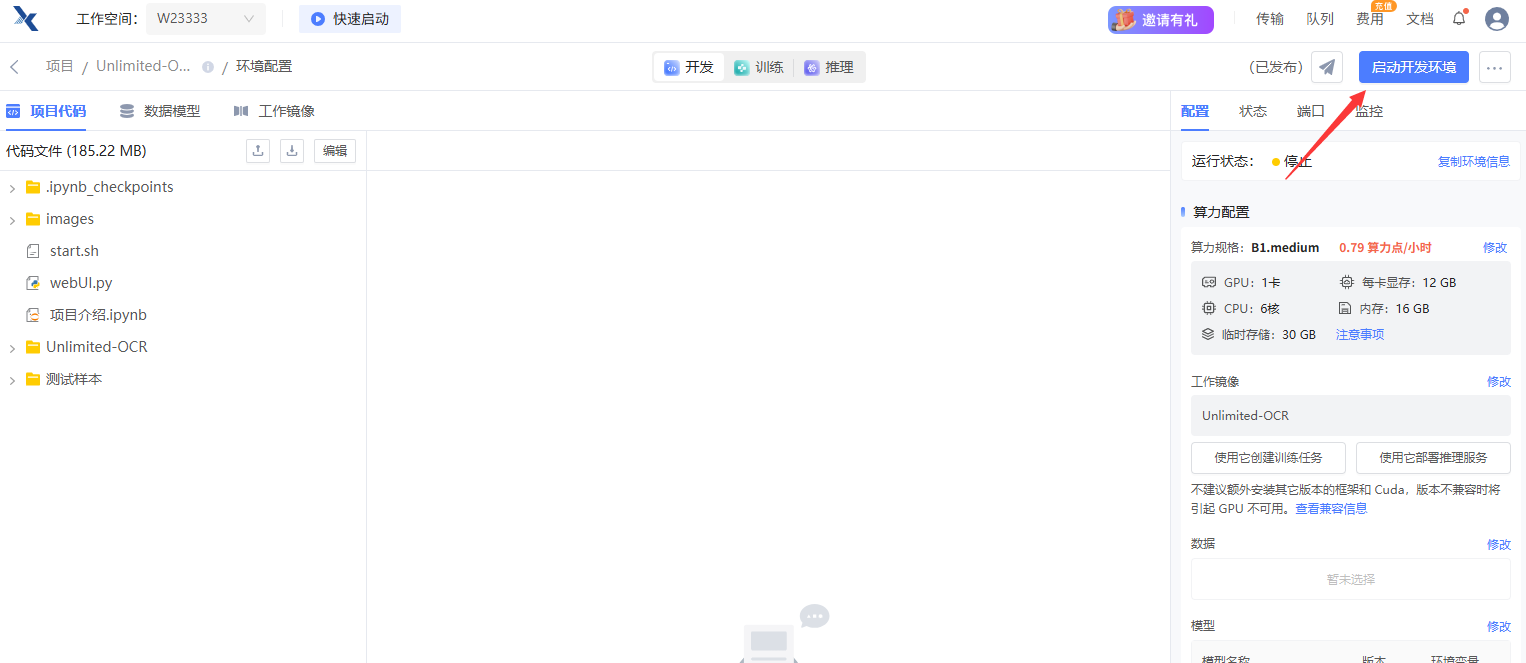
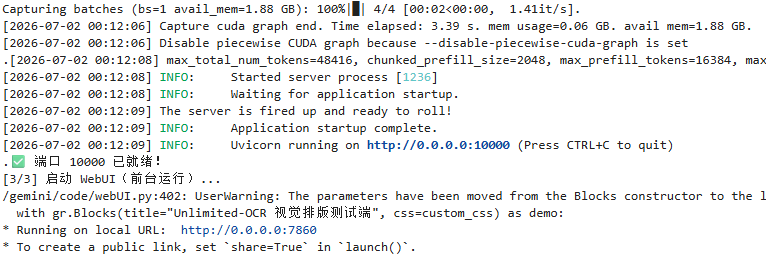
双击打开左侧的 项目说明.ipynb 文件,找到 "二、使用说明:" 下方的 !bash start.sh 这一行命令,点击选中后再点击上面的运行图标运行该命令行,即可启动服务界面:
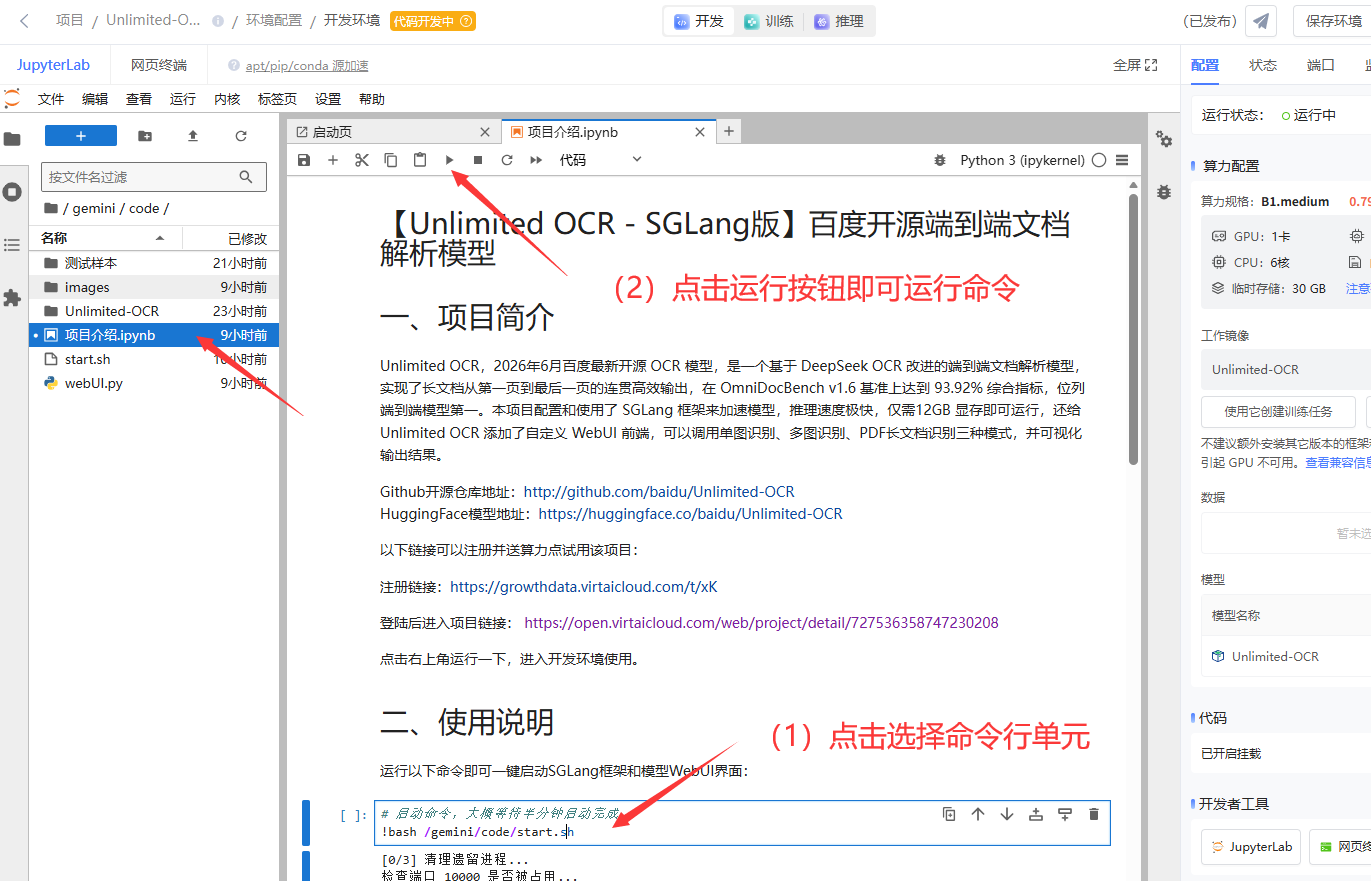
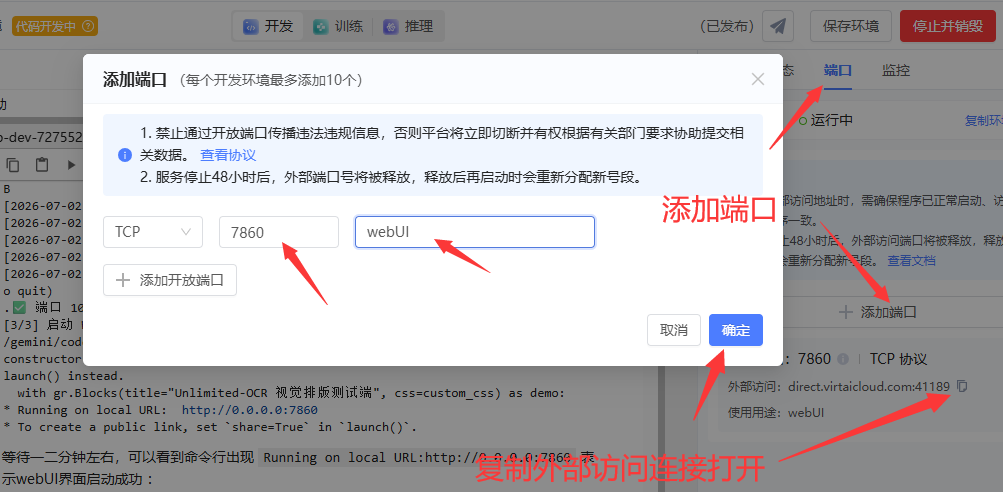
启动大概半分钟,出现`Running on local URL:http://0.0.0.0:7860 和 Uvicorn running on http://0.0.0.0:10000` ,表示启动完成,按下图在右侧添加端口 7860 并将外部链接复制到浏览器新窗口打开,就可以打开 WebUI 界面。
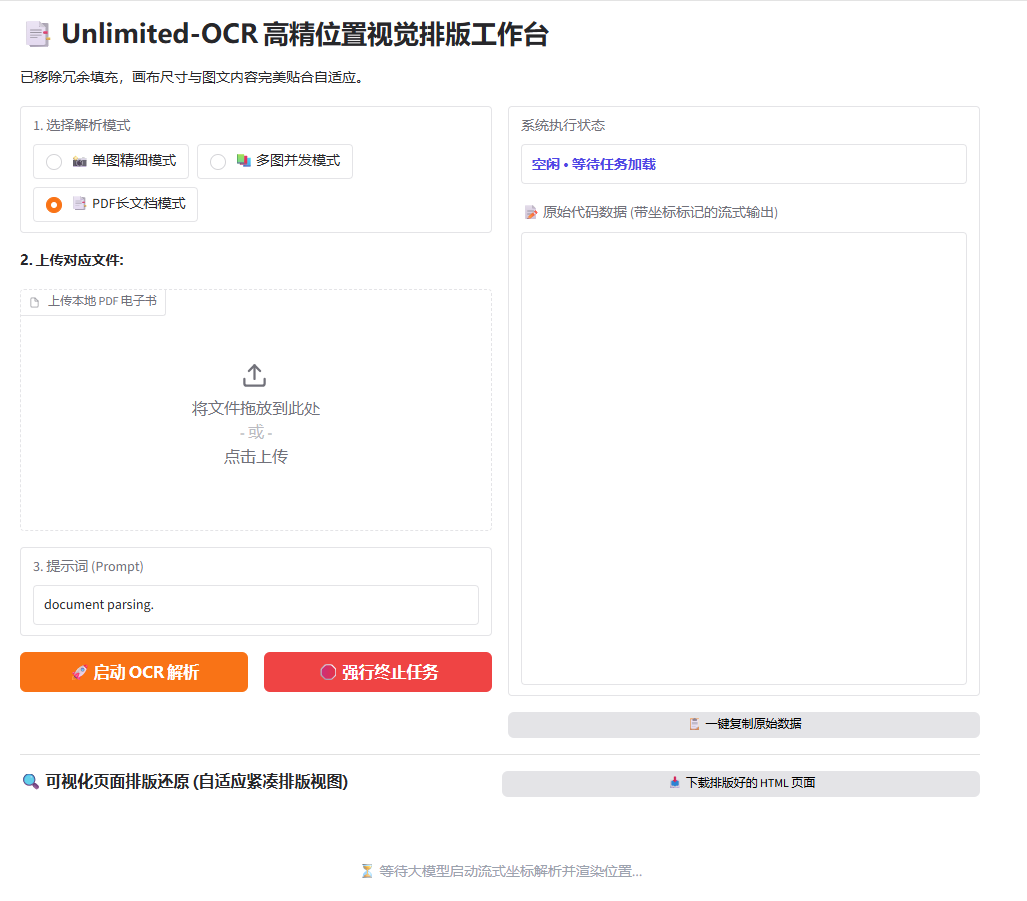
然后是OCR识别单图多图和PDF文档的演示,我在左侧 /gemini/code/测试样本文件夹里 放了两张图片和一个 影印PDF 文档可以下载下来做测试。首先单图点击上传:
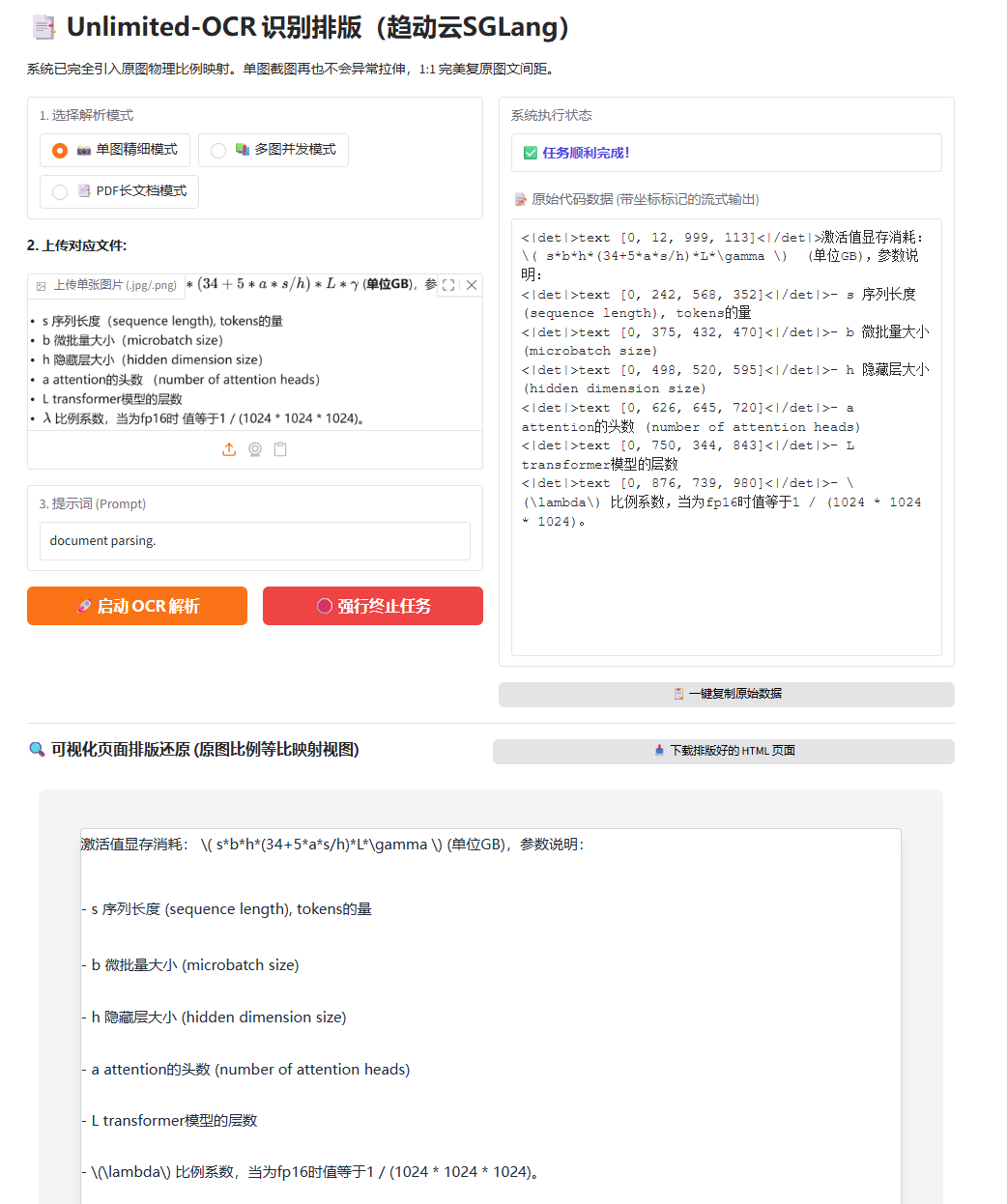
然后是多图测试:
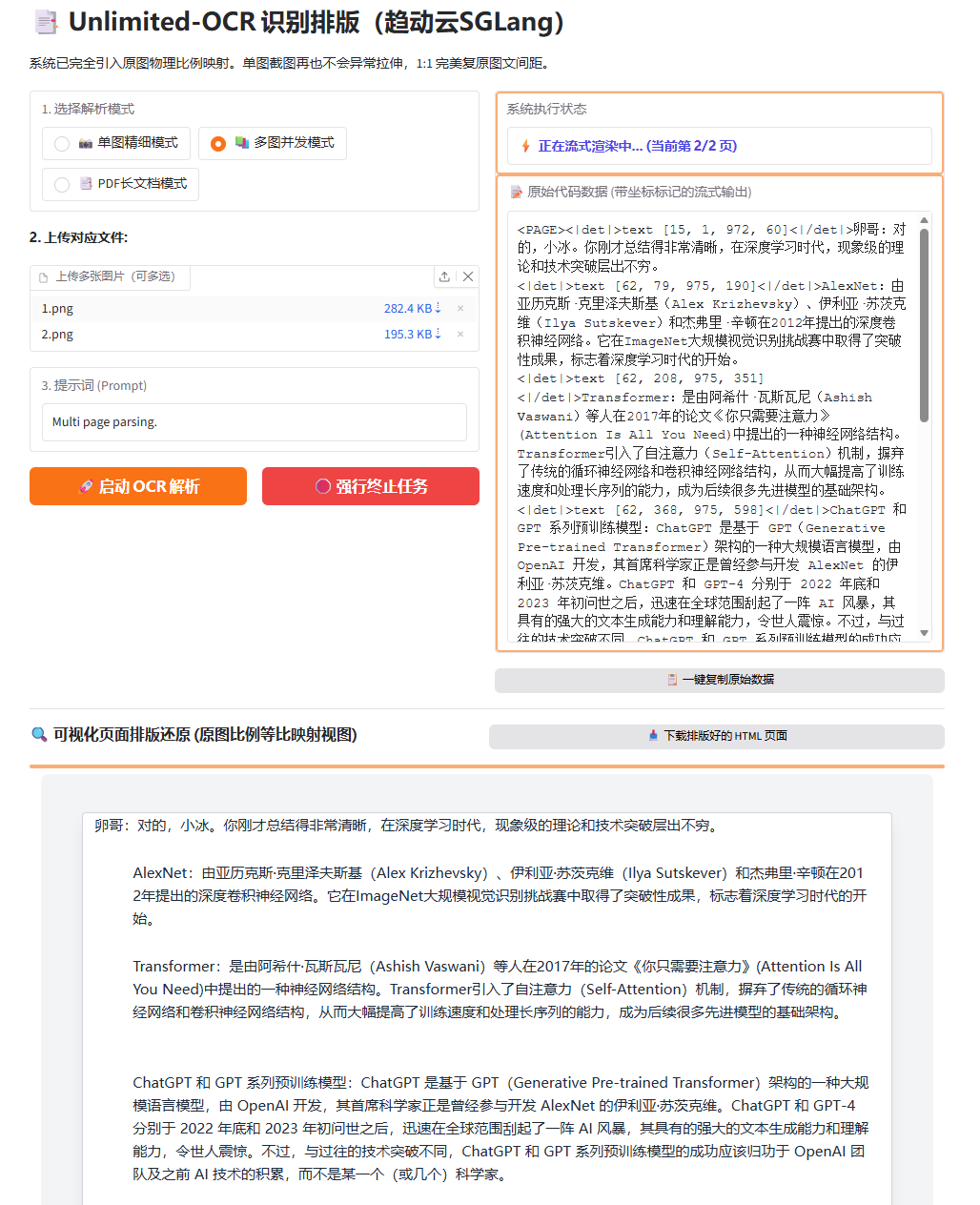
最后是PDF 整个文档测试:
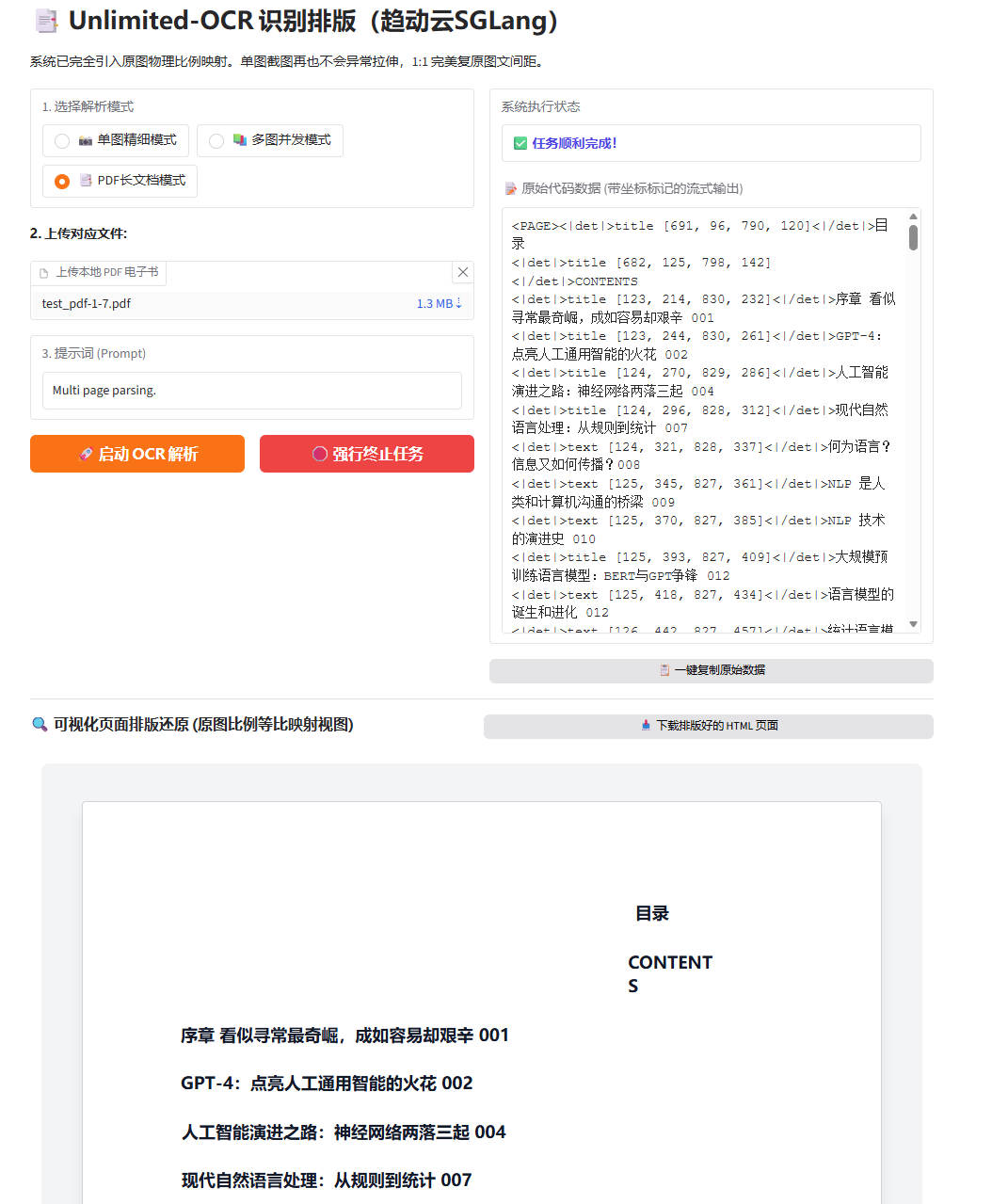
总的来看识别能力不比PPOCR差了,文档处理速度很快,再对输出做一些截断和处理才能达到好的排版展示效果,排版代码已上传服务器欢迎试用。最后用完记得点项目右上角停止和销毁来关闭服务器,以节省算力,也可以多注册几个号试用。如果遇到 bug 或者对 AIGC 创作感兴趣的话,欢迎在项目说明.ipynb后面的群里反馈讨论。