一、它到底是什么?一句话说清楚
这是一个能在标准 GGUF 格式下直接运行 LLaMA/Qwen 模型的微型推理引擎 ,核心代码只有约 780 行 C(或 900 行 C++),没有任何外部依赖 。你不需要装 Python、不需要装 PyTorch、不需要转换模型格式,直接把 .gguf 文件丢给它就能跑。
它同时提供了两个版本:
- 单文件教学版:C 和 C++ 各一个文件,打印出来刚好一张 A4 纸,适合逐行阅读理解 Transformer 的完整推理流程。
- FAST 实战版:拆成几个模块,支持更多量化格式、CPU 加速、聊天模式、RAG 检索、甚至分布式推理,但依然保持"一眼能看完"的代码量。
二、为什么需要这么个东西?------ 先理解痛点
现在跑一个大模型,通常的路径是:
- 下载 PyTorch 格式的模型(几十 GB)
- 用
transformers库加载 - 或者用
llama.cpp转换格式后再推理 - 依赖一大堆:Python、CUDA、CMake、各种库......
这个引擎想解决的问题很简单:如果我只想在嵌入式设备上跑一个 7B 模型,能不能不要那么多包袱?
答案是:能。而且只需要 512MB 内存(7B 模型 + 4K 上下文,Q8_0 量化),这在很多开发板上都能跑。
三、核心设计思路:做减法,而不是做加法
3.1 哲学:"简单不是缺少复杂度,而是控制复杂度"
这个项目的核心设计理念可以总结为几点:
| 设计原则 | 具体做法 |
|---|---|
| 零依赖 | 纯 C/C++,只用标准库,make 一下就能编译 |
| 直接加载 | 通过 mmap 直接映射 GGUF 文件,不转换、不预处理 |
| 可读性优先 | 代码量控制在能"一口气读完"的范围内 |
| 按需扩展 | 新增功能走模块化,不破坏原有简洁性 |
| 嵌入式友好 | 能在裸机、开发板、机器人等边缘设备上运行 |
3.2 整体架构流程
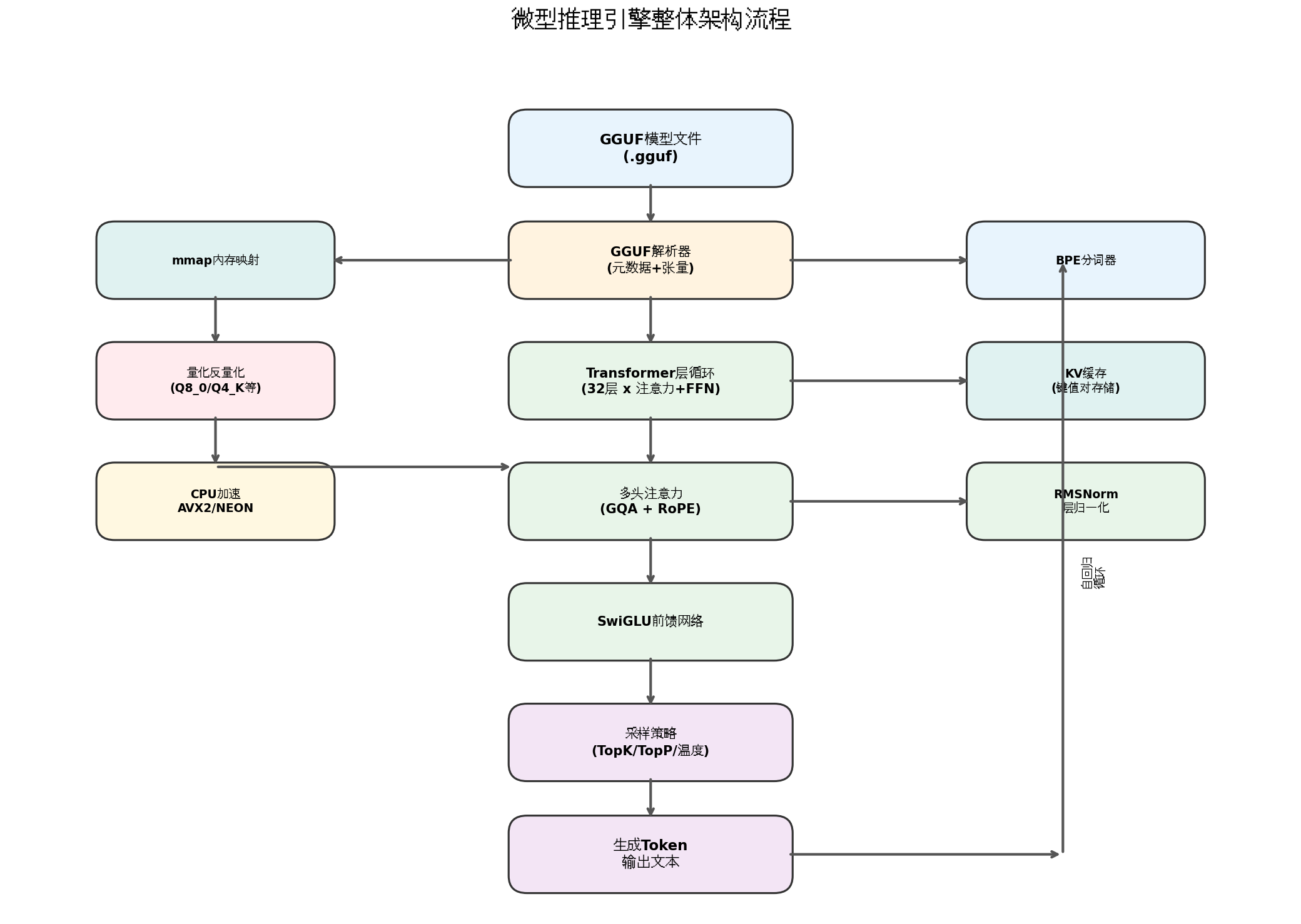
下面是引擎的完整推理流程:
If you need the complete source code, please add the WeChat number (c17865354792)
流程解读:
- GGUF 文件 → 解析器 :直接读取
.gguf文件,解析元数据(模型配置、词汇表等)和张量数据(权重矩阵)。 - mmap 内存映射 :用操作系统提供的
mmap把文件映射到内存,零拷贝加载,启动极快,多个进程还能共享同一份内存。 - BPE 分词:把输入文本拆成 Token ID,用的是标准的 Byte Pair Encoding 算法。
- 量化反量化:权重以 Q8_0、Q4_K、甚至 Q1_0 等格式存储,计算时按需反量化成 FP32。
- Transformer 层循环:32 层(以 7B 模型为例),每层做注意力 + 前馈网络计算。
- KV 缓存:把之前生成的 Token 的 K、V 向量存起来,避免重复计算,这是自回归生成的关键优化。
- 采样输出:用 Top-K、Top-P、温度等策略从 logits 中采样下一个 Token。
- 自回归循环:把生成的 Token 再喂回输入,继续生成,直到满足停止条件。
四、Transformer 单层内部是怎么算的?
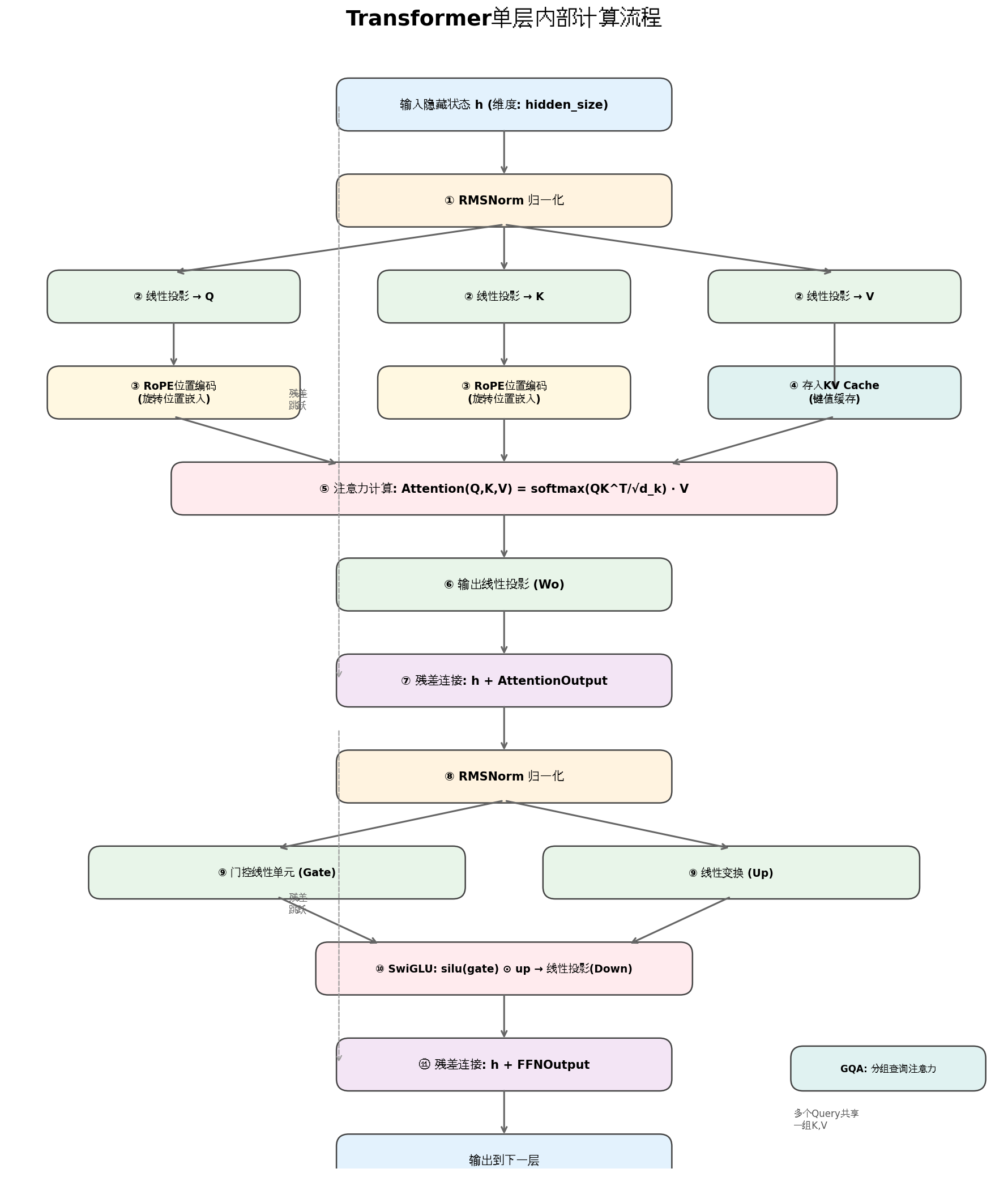
这是整个引擎最核心的部分。以 LLaMA 架构为例,每一层内部要走 11 个步骤:
逐层拆解(大白话版):
步骤 ①:RMSNorm 归一化
输入是一个向量(维度比如 4096),先做个归一化。RMSNorm 比 LayerNorm 更简单,只算均方根,不用减均值。公式大概是:
output = input / sqrt(mean(input²)) * weight步骤 ②:线性投影出 Q、K、V
归一化后的向量分别乘以三个权重矩阵,得到:
- Q(Query):我要查什么
- K(Key):我有什么信息
- V(Value):信息的具体内容
步骤 ③:RoPE 位置编码
Q 和 K 需要知道"这个词在句子第几个位置"。RoPE(旋转位置编码)的做法很巧妙:把 Q、K 向量当成复数,按位置角度旋转一下。这样模型就能理解词的先后顺序,而且旋转操作可以用简单的三角函数完成,计算量很小。
步骤 ④:存入 KV Cache
K 和 V 被存进缓存。下次生成新 Token 时,只需要计算新 Token 的 Q,然后和之前所有 Token 的 K、V 做注意力,不用重新算旧的。
步骤 ⑤:注意力计算
核心公式:
Attention(Q,K,V) = softmax(Q × K^T / √d_k) × VQ × K^T:算每个词和其他词的"相关性分数"/ √d_k:缩放,防止分数太大导致 softmax 梯度消失softmax:转成概率分布× V:按概率加权求和,得到注意力输出
这里用了 GQA(分组查询注意力):多个 Query 头共享同一组 K、V 头,减少内存和计算量。
步骤 ⑥:输出线性投影
注意力结果再乘一个权重矩阵,映射回原始维度。
步骤 ⑦:残差连接
把输入直接加到输出上。这是 Transformer 的精髓:如果这层学不到东西,至少保证信息能无损传递下去,训练深层网络时才不容易梯度消失。
步骤 ⑧:再次 RMSNorm
进入前馈网络前再归一化一次。
步骤 ⑨~⑩:SwiGLU 前馈网络
这是 LLaMA 用的激活方式,比传统 ReLU 更平滑:
gate = silu(input × W_gate)
up = input × W_up
output = (gate ⊙ up) × W_downsilu 是 Sigmoid 加权的线性单元,⊙ 是逐元素乘法。门控机制让网络能选择性传递信息。
步骤 ⑪:第二次残差连接
再把 FFN 前的输入加到 FFN 输出上,完成一层。
五、量化与内存优化:怎么把 28GB 压到 1GB?
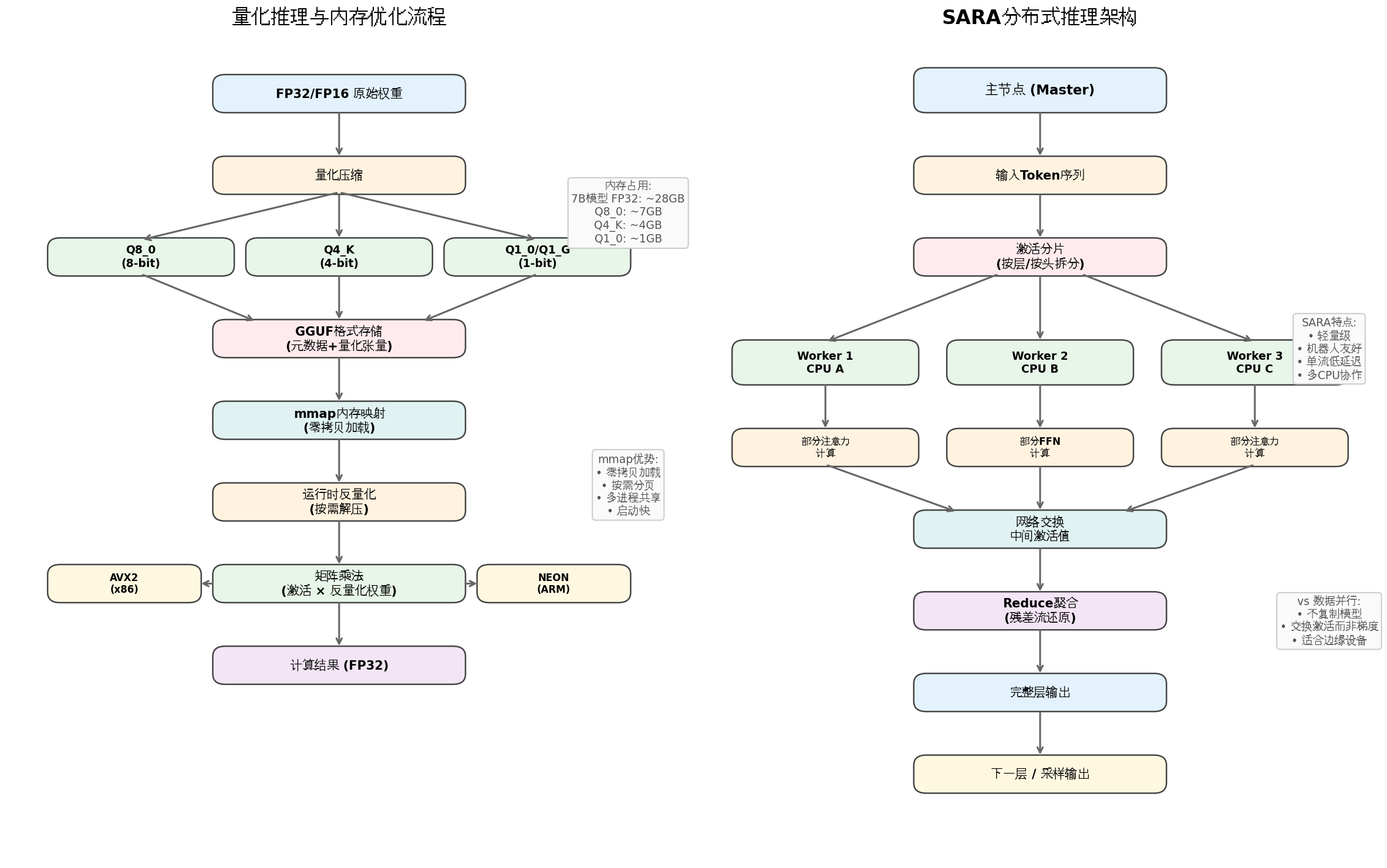
5.1 量化格式一览
| 格式 | 位宽 | 7B 模型大小 | 适用场景 |
|---|---|---|---|
| FP32 | 32-bit | ~28 GB | 训练用,推理太慢 |
| Q8_0 | 8-bit | ~7 GB | 精度损失小,通用推理 |
| Q4_K | 4-bit | ~4 GB | 平衡精度和速度 |
| Q1_0 / Q1_G | 1-bit | ~1 GB | 极致压缩,新兴方向 |
1-bit 量化 是最近的热点。以前 BitNet 是 3 值(-1, 0, +1),现在真正的 1-bit 模型(如 Bonsai-8B)已经出现,每个权重只有 1 个 bit,配合分组缩放因子,精度 surprisingly 还能用。
5.2 运行时反量化
引擎不是一次性把所有权重反量化成 FP32(那内存就爆炸了),而是计算到某一层时,临时把该层的量化权重反量化,算完就扔 。配合 mmap 的按需分页,内存占用压到最低。
5.3 CPU 加速:AVX2 和 NEON
- x86 平台:用 AVX2/FMA 指令集,一条指令能同时算 8 个 FP32 或 16 个 FP16。
- ARM 平台:用 NEON 指令集,类似的功能。
这些 SIMD(单指令多数据)优化是"热路径"------只加速最频繁的矩阵乘法,代码其他部分保持简洁。
六、RAG 检索:给模型装个"记忆"
这个引擎支持加载一个 BERT GGUF 模型 做嵌入(Embedding),实现轻量级 RAG:
- 解析历史聊天记录
- 用 BERT 把每句话转成向量
- 存到内存中的向量数据库
- 新对话时,把用户问题也转成向量,找最相似的历史记录
- 把相关记录注入到当前 prompt 前面,让模型"记得"之前的对话
没有外部向量数据库,没有网络请求,纯本地完成。 这在嵌入式设备上非常实用。
七、SARA 分布式推理:多 CPU 协作
SARA(Sharded Activation Reduction Architecture)是一种轻量级分布式推理方案,特别适合机器人场景:
- 机器人通常有多个 CPU,但只有一个"思路流"需要加速
- 把 Transformer 的某些层或注意力头拆分到不同 CPU 上计算
- 各 CPU 算完后,通过网络交换中间激活值(比交换梯度小得多)
- 主节点把部分结果聚合回残差流
与数据并行的区别 :数据并行是每个 GPU 复制一份完整模型,处理不同 batch;SARA 是模型分片,每个 CPU 只存部分权重,适合内存受限的边缘设备。
八、聊天模式与状态管理
FAST 引擎支持完整的终端聊天体验:
- 保存/加载对话状态(整个 KV Cache + 生成位置)
- 预填系统提示后保存状态,下次直接加载,省去重复计算
- 可配置 AI/用户名称、结束标记、聊天记录持久化
这在嵌入式交互场景中很实用------比如机器人开机时加载一个"系统提示状态",之后每次对话都从热状态开始。
九、涉及的关键技术领域总结
这个项目虽然代码量少,但横跨了多个 AI 系统领域:
| 领域 | 涉及知识点 |
|---|---|
| 模型格式 | GGUF v3 规范、张量存储、元数据解析 |
| 量化压缩 | 8-bit/4-bit/1-bit 量化、反量化、分组缩放 |
| Transformer 架构 | 多头注意力、GQA、RoPE、RMSNorm、SwiGLU、残差连接 |
| 内存优化 | mmap 零拷贝、KV Cache、按需加载 |
| CPU 优化 | SIMD 指令(AVX2/NEON)、矩阵乘法优化 |
| 分词 | BPE 算法、合并规则、词汇表管理 |
| 采样策略 | Greedy、Top-K、Top-P、温度调节 |
| 检索增强 | Embedding、向量相似度、RAG 流程 |
| 分布式系统 | 模型分片、激活交换、Reduce 聚合 |
| 嵌入式系统 | 裸机适配、内存受限环境下的推理 |
十、运行方式与效果
准备模型:去 Hugging Face 下载 GGUF
你需要一个 GGUF 格式的模型文件。推荐从 Hugging Face 下载,比如:
- LLaMA/Mistral 系列 :
Mistral-7B-Instruct-v0.3-Q8_0.gguf - Qwen3 系列 :
Qwen3-8B-Q8_0.gguf - BERT 嵌入模型:用于 RAG 检索(可选)
下载地址示例:
https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.3-GGUF教学版:单文件极简推理
运行命令:
bash
./gguf-c model.gguf 64 "Hello there"参数说明:
model.gguf:模型文件路径64:生成 64 个 token"Hello there":输入提示词
效果:终端会直接打印生成的 token,一行一个,类似这样:
Hello
there
!
How
can
I
assist
you
today
?特点:
-
代码只有 780 行 C,可以打印出来逐行阅读
-
支持 原始 token ID 输入 (适合调试):
bash./gguf-cpp model.gguf 32 tokens 1 15043 29871 -
没有花哨的输出格式,纯文本打印,适合理解推理流程的每一步
FAST 版:功能完整的实战引擎
这是日常使用的版本,支持各种参数和模式。
单轮生成
bash
./gguf-fast -m model.gguf -n 64 -p "Explain rotary embeddings in one paragraph."效果示例(假设输出):
Rotary Position Embedding (RoPE) is a method to encode positional information into transformer models by rotating the query and key vectors in a high-dimensional space. Unlike traditional absolute position embeddings that add fixed vectors to input embeddings, RoPE applies rotation matrices based on token positions, allowing the model to naturally understand relative distances between tokens through the properties of rotation. This approach is particularly effective in long-context scenarios because the relative position information is preserved in the attention scores through the dot product of rotated vectors.从文件加载提示词
bash
./gguf-fast -m model.gguf -f prompt.txt -n 128 -K 40 -T 0.9 -M 0.7参数说明:
-K 40:Top-K 采样,只从概率最高的 40 个 token 中选-T 0.9:Top-P 采样,累积概率达到 90% 就截断-M 0.7:温度 0.7,输出更稳定
聊天模式
bash
./gguf-fast -m model.gguf -C -A Assistant -U User -E "User:" -n 256效果:进入交互式终端聊天,类似:
User: 你好
Assistant: 你好!很高兴见到你。有什么我可以帮你的吗?
User: 解释一下量子计算
Assistant: 量子计算是一种利用量子力学原理(如叠加和纠缠)进行信息处理的计算范式...带记忆检索的聊天(RAG)
bash
./gguf-fast -m model.gguf -C -l chat.log -B bert.gguf -A Assistant -U User -E $'\n' -n 256效果 :它会自动读取 chat.log 里的历史对话,用 BERT 模型把历史内容转成向量,当你问新问题时,自动找到最相关的历史记录注入到 prompt 前面,让模型"记得"之前的上下文。
状态保存与加载
bash
# 第一次:加载系统提示,预计算后保存状态
./gguf-fast -m model.gguf -f system_prompt.txt -S state.bin
# 之后每次:直接加载状态,跳过预计算
./gguf-fast -m model.gguf -L state.bin -n 128效果 :系统提示很长时(比如几百字),第一次预计算可能要几秒。保存状态后,后续加载只需 毫秒级,直接进入生成阶段。
可视化版本:看神经网络"思考"
bash
./gguf-fast-sdl -m model.gguf -p "Trace this token stream." -n 64 -V效果:会弹出一个 SDL2 窗口,实时显示:
- 嵌入层(Embedding)的激活分布
- 注意力输出的热路径
- 前馈网络的信号流
- 最终 logits 的 token 概率分布
每一帧对应一个生成 token ,你可以 literally 看到神经网络是怎么"想"出下一个词的。这不是花架子,而是理解注意力机制内部行为的绝佳工具。
分布式 SARA 版本
Worker 端(在另一台机器或另一个 CPU 上跑):
bash
./gguf-cpp-distrib -m Mistral-7B-Instruct-v0.3-Q8_0.gguf -W 1/2 -M 19095Master 端(主控节点):
bash
./gguf-cpp-distrib -m Mistral-7B-Instruct-v0.3-Q8_0.gguf -w 10.0.0.2:19095 -n 64 Hi效果:多个 CPU 协作完成同一批推理,适合机器人场景------比如树莓派集群、多核 ARM 开发板。每个 worker 只负责部分层的计算,通过网络交换中间激活值,最后聚合结果。
快速上手清单
bash
# 1. 下载模型
wget https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.3-GGUF/resolve/main/mistral-7b-instruct-v0.3.Q8_0.gguf
# 2. 跑教学版
./gguf-c mistral-7b-instruct-v0.3.Q8_0.gguf 64 "Hello, how are you?"
# 3. 跑 FAST 版
./gguf-fast -m mistral-7b-instruct-v0.3.Q8_0.gguf -n 128 -p "Write a haiku about coding."
# 4. 聊天模式
./gguf-fast -m mistral-7b-instruct-v0.3.Q8_0.gguf -C -A AI -U Human -E "Human:" -n 256总结
如果你有以下需求,这个项目是绝佳的起点:
- 想从零理解 Transformer 推理:单文件版 780 行 C 代码,比任何论文都直观。
- 想在嵌入式设备上跑大模型:512MB 内存就能跑 7B 模型,无依赖,直接编译。
- 想构建自己的推理框架:FAST 版提供了模块化参考,量化、加速、聊天、RAG、分布式都有现成实现。
- 讨厌"为了复杂而复杂":没有 CMake 迷宫、没有 42 层抽象、没有遥测,只有能看懂的代码。
"简单不是缺少复杂度,而是控制复杂度。"
当你能在一张 A4 纸上读完一个能跑 7B 模型的推理引擎时,你会对"大模型"这件事有完全不同的理解。
Welcome to follow WeChat official account【程序猿编码】