GPU Instancing(GPU 实例化)是一种通过一次 Draw Call 绘制大量相同网格 的渲染优化技术。
本文从原理、数据流、Unity 实现、限制和进阶对比等维度系统讲解。
目录
- [一、核心问题:为什么需要 GPU Instancing](#一、核心问题:为什么需要 GPU Instancing)
- 二、底层原理
- 三、数据流详解
- [四、Unity 中的完整工作流](#四、Unity 中的完整工作流)
- 五、关键限制
- [六、进阶:GPU Instancing、动态合批、静态合批 三者对比](#六、进阶:GPU Instancing、动态合批、静态合批 三者对比)
- 七、典型应用场景
- 八、小结
- 九、实践
一、核心问题:为什么需要 GPU Instancing
1.1 传统渲染的瓶颈
假设场景中有 1000 棵相同的树:
CPU → 提交 DrawCall_1(树1,位置A) → GPU 绘制
CPU → 提交 DrawCall_2(树2,位置B) → GPU 绘制
...
CPU → 提交 DrawCall_1000 → GPU 绘制瓶颈在 CPU→GPU 的通信开销,而非 GPU 算力:
- 每次 DrawCall 都要绑定资源、设置状态、切换 Shader 常量
- CPU 和 GPU 之间的驱动开销(driver overhead)非常大
- GPU 大部分时间在等待指令
1.2 GPU Instancing 的思路
CPU → 提交 1 次 DrawCall("画 1000 个树,实例数据在这里") → GPU 循环绘制 1000 次一次提交,GPU 内部循环执行,几乎消除了 CPU 提交开销。
二、底层原理
2.1 图形 API 层面
GPU Instancing 依赖底层 API 提供的实例化绘制指令:
| API | 指令 |
|---|---|
| OpenGL | glDrawElementsInstanced |
| DirectX 11 | DrawIndexedInstanced |
| Vulkan | vkCmdDrawIndexed(..., instanceCount, ...) |
| Metal | drawIndexedPrimitives(..., instanceCount:) |
这些 API 相比普通 Draw 多一个参数 instanceCount,告诉 GPU:用同一份顶点/索引缓冲,绘制 N 遍。
2.2 GPU 硬件层面
GPU 在执行时会为每个实例生成一个内置的 SV_InstanceID(HLSL)/ gl_InstanceID(GLSL):
for (instanceID = 0; instanceID < instanceCount; instanceID++) {
for (vertex in mesh.vertices) {
vertexShader(vertex, instanceID); // 顶点着色器可访问 instanceID
}
}Shader 就能根据 instanceID 从"实例数据数组"中索引出该实例专属的数据(位置、颜色、缩放等)。
三、数据流详解
3.1 共享数据 vs 每实例数据
| 数据类型 | 说明 | 存储位置 |
|---|---|---|
| 共享数据 | 顶点、UV、法线、索引 | 顶点缓冲(只上传一份) |
| 每实例数据 | Model 矩阵、颜色、参数等 | 实例 Buffer / Constant Buffer 数组 |
3.2 数据结构示意
hlsl
// 共享顶点缓冲(Vertex Buffer)
struct Vertex {
float3 position;
float3 normal;
float2 uv;
};
Vertex vertices[N]; // 只上传一次
// 每实例数据(Per-Instance Buffer)
struct InstanceData {
float4x4 objectToWorld;
float4 color;
};
InstanceData instances[1000]; // 1000 个实例的数据3.3 Unity 中的实现(CBUFFER)
Unity 使用 Constant Buffer 数组 存储每实例数据:
hlsl
UNITY_INSTANCING_BUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_DEFINE_INSTANCED_PROP(float, _Metallic)
UNITY_INSTANCING_BUFFER_END(Props)宏展开后大致是:
hlsl
CBUFFER_START(UnityInstancing_Props)
float4 _Color_Array[500];
float _Metallic_Array[500];
CBUFFER_END在顶点/片元着色器中通过 unity_InstanceID 索引:
hlsl
float4 color = _Color_Array[unity_InstanceID];四、Unity 中的完整工作流
4.1 Shader 侧改造
hlsl
Shader "Custom/InstancedShader"
{
Properties
{
_Color ("Color", Color) = (1,1,1,1)
}
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing // 开启实例化变体
#include "UnityCG.cginc"
struct appdata {
float4 vertex : POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID // 声明接收 instanceID
};
struct v2f {
float4 pos : SV_POSITION;
UNITY_VERTEX_INPUT_INSTANCE_ID // 传给片元着色器
};
UNITY_INSTANCING_BUFFER_START(Props)
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_INSTANCING_BUFFER_END(Props)
v2f vert(appdata v) {
v2f o;
UNITY_SETUP_INSTANCE_ID(v); // 从输入中提取 instanceID
UNITY_TRANSFER_INSTANCE_ID(v, o); // 传递到片元
o.pos = UnityObjectToClipPos(v.vertex);
return o;
}
fixed4 frag(v2f i) : SV_Target {
UNITY_SETUP_INSTANCE_ID(i);
return UNITY_ACCESS_INSTANCED_PROP(Props, _Color);
}
ENDCG
}
}
}4.2 CPU 侧的合批条件
Unity 自动合批 GPU Instancing 需满足:
- 相同 Mesh
- 相同 Material(Shader 勾选 Enable GPU Instancing)
- 不同的 MaterialPropertyBlock 也可 (用
MaterialPropertyBlock设置每实例属性) - 光照模式一致(前向渲染中受同一光源影响)
- 无 Light Probe 冲突(或使用 LPPV)
4.3 手动 API:Graphics.DrawMeshInstanced
csharp
Matrix4x4[] matrices = new Matrix4x4[1000];
MaterialPropertyBlock props = new MaterialPropertyBlock();
Vector4[] colors = new Vector4[1000];
// 填充 matrices 和 colors ...
props.SetVectorArray("_Color", colors);
Graphics.DrawMeshInstanced(mesh, 0, material, matrices, 1000, props);一帧一次调用,Unity 会打包成 1 个(或几个,受 batch 上限限制)DrawCall。
4.4 大规模场景:Graphics.DrawMeshInstancedIndirect
当实例数超过几千甚至上百万(如草地系统),可用 Indirect 版本,参数存于 ComputeBuffer,配合 Compute Shader 做剔除:
csharp
ComputeBuffer argsBuffer; // 实例数量参数
ComputeBuffer instanceBuffer; // 每实例数据
Graphics.DrawMeshInstancedIndirect(mesh, 0, material, bounds, argsBuffer);五、关键限制
5.1 Batch 大小上限
一个 DrawCall 的实例数量受 Constant Buffer 大小限制:
- PC / 主机:通常 1023 个(Unity 默认)
- 移动端:500 左右
- 超过会自动拆分成多个 DrawCall
5.2 不支持的情况
- SkinnedMeshRenderer(蒙皮网格)通常不能直接实例化
- 使用 Lightmap 的静态物体(会被静态合批优先接管)
- Shader 未开启
#pragma multi_compile_instancing
5.3 与其他合批的优先级
Unity 合批优先级(视版本和渲染管线不同):
静态合批 > 动态合批 > GPU Instancing > SRP Batcher
六、进阶:GPU Instancing、动态合批、静态合批 三者对比
三者都是为了减少 DrawCall,但机制、限制和适用场景各不相同。下表从多个维度直接对比:
6.1 综合对比表
| 对比维度 | 静态合批(Static Batching) | 动态合批(Dynamic Batching) | GPU Instancing |
|---|---|---|---|
| 合并时机 | 构建/加载时(一次) | 每帧运行时 | 不合并,GPU 内部循环 |
| 网格是否合并 | ✅ 合并为大 Mesh | ✅ 每帧合并为临时 Mesh | ❌ 共享同一份 Mesh |
| 顶点变换位置 | 预先烘焙到世界空间 | 每帧 CPU 变换 | GPU 顶点着色器完成 |
| 物体是否可动 | ❌ 必须静止 | ✅ 可任意变换 | ✅ 可任意变换 |
| 是否要求同 Mesh | ❌ 不需要 | ❌ 不需要 | ✅ 必须相同 Mesh |
| 是否要求同材质 | ✅ 是 | ✅ 是 | ✅ 是(需勾选 Enable Instancing) |
| 网格大小限制 | 无 | 严格:顶点属性 ≤ 900(默认) | 无 |
| 单批数量上限 | 无(合并后视为一个 Mesh) | 由属性数上限决定 | PC 约 1023,移动端约 500 |
| CPU 开销 | 极低 | 高(每帧做顶点变换) | 极低 |
| 内存开销 | 高(保留合并后大顶点缓冲) | 低(临时缓冲,帧末释放) | 低(Mesh 共享 + 每实例数据数组) |
| GPU 开销 | 低 | 低 | 低(有轻微 InstanceID 索引开销) |
| 每实例数据支持 | ❌ 不支持(顶点已烘焙) | ❌ 不支持 | ✅ 支持(颜色、参数等可不同) |
| 蒙皮网格支持 | ❌ 不支持 | ❌ 不支持 | ❌ 不直接支持 |
| Lightmap 支持 | ✅ 支持 | ⚠️ 有限 | ⚠️ 有限 |
| 启用方式 | 勾选 Static → Batching Static |
Project Settings → Player 勾选开关 | Shader 勾选 Enable GPU Instancing |
| 典型场景 | 场景静态建筑、地形、装饰 | 大量小型可动物体(掉落物、UI) | 草、树、粒子、子弹、NPC 群体 |
6.2 优先级顺序
Unity 在同时满足多个条件时,合批优先级为:
静态合批 > 动态合批 > GPU Instancing > SRP Batcher
即:静态物体优先走静态合批;如果 Shader 支持 Instancing 且未被前两者接管,才走 GPU Instancing。
6.3 一句话记忆
| 方式 | 核心思想 |
|---|---|
| 静态合批 | 空间换时间:预烘焙,物体不能动 |
| 动态合批 | 时间换空间:每帧变换,可动但 CPU 累 |
| GPU Instancing | 让 GPU 循环:最优雅,但要求同 Mesh |
七、典型应用场景
- 植被系统:草、树、灌木
- 粒子替代:用 Mesh 实例代替 Billboard
- 建筑装饰:栏杆、砖块、窗户
- 敌人/NPC 群体:相同模型不同位置
- 弹幕/子弹:大量相同弹体
八、小结
GPU Instancing 的本质:把"CPU 提交 N 次 DrawCall"变成"CPU 提交 1 次 + GPU 内部循环 N 次",通过:
- 共享网格数据(Vertex Buffer 只上传一份)
- 每实例常量缓冲数组(Per-Instance CBuffer)
- InstanceID 索引(
SV_InstanceID/unity_InstanceID)
这三件套实现,是现代渲染中处理"大量相同物体"的标准方案。
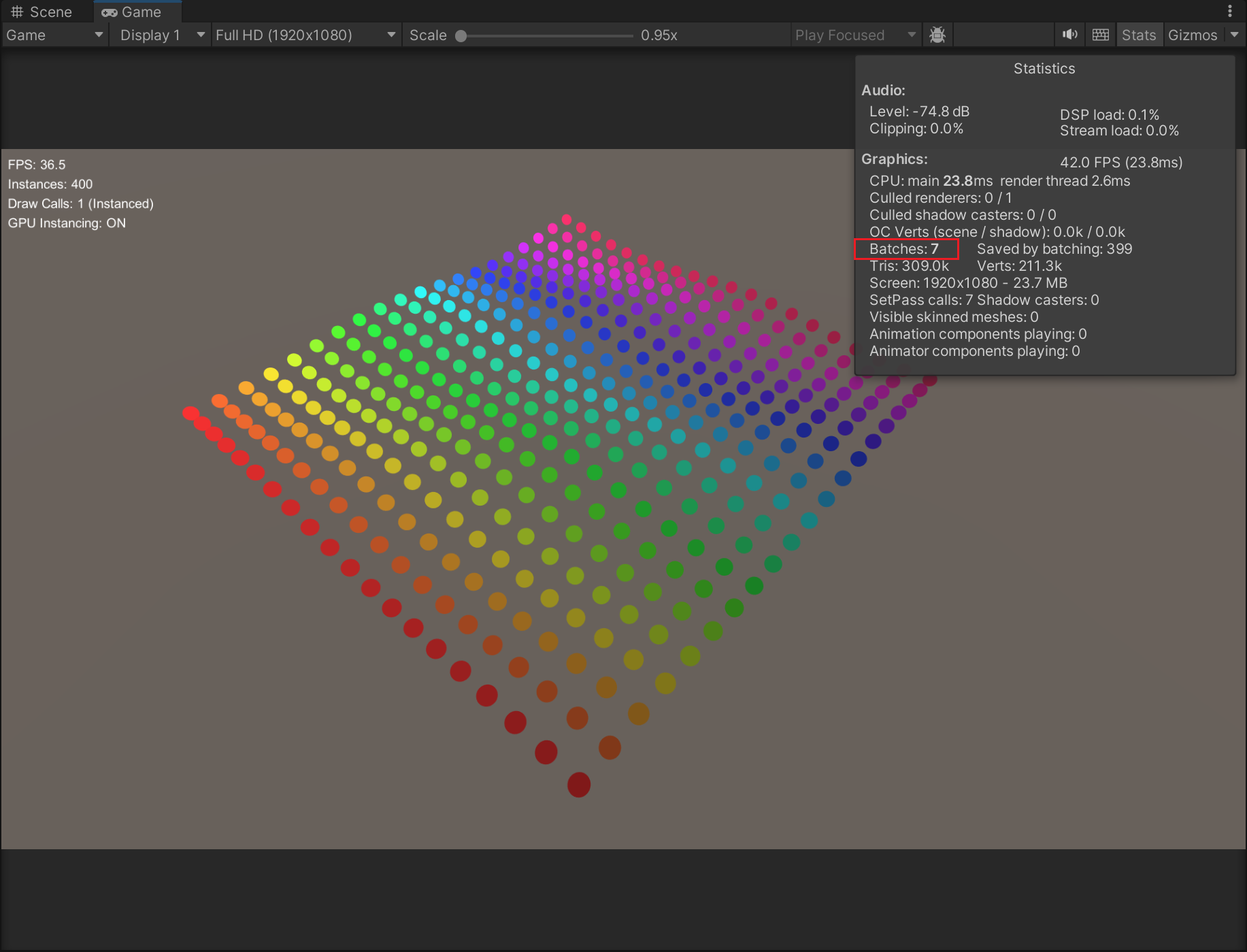
九、实践
开启GPU Instancing :
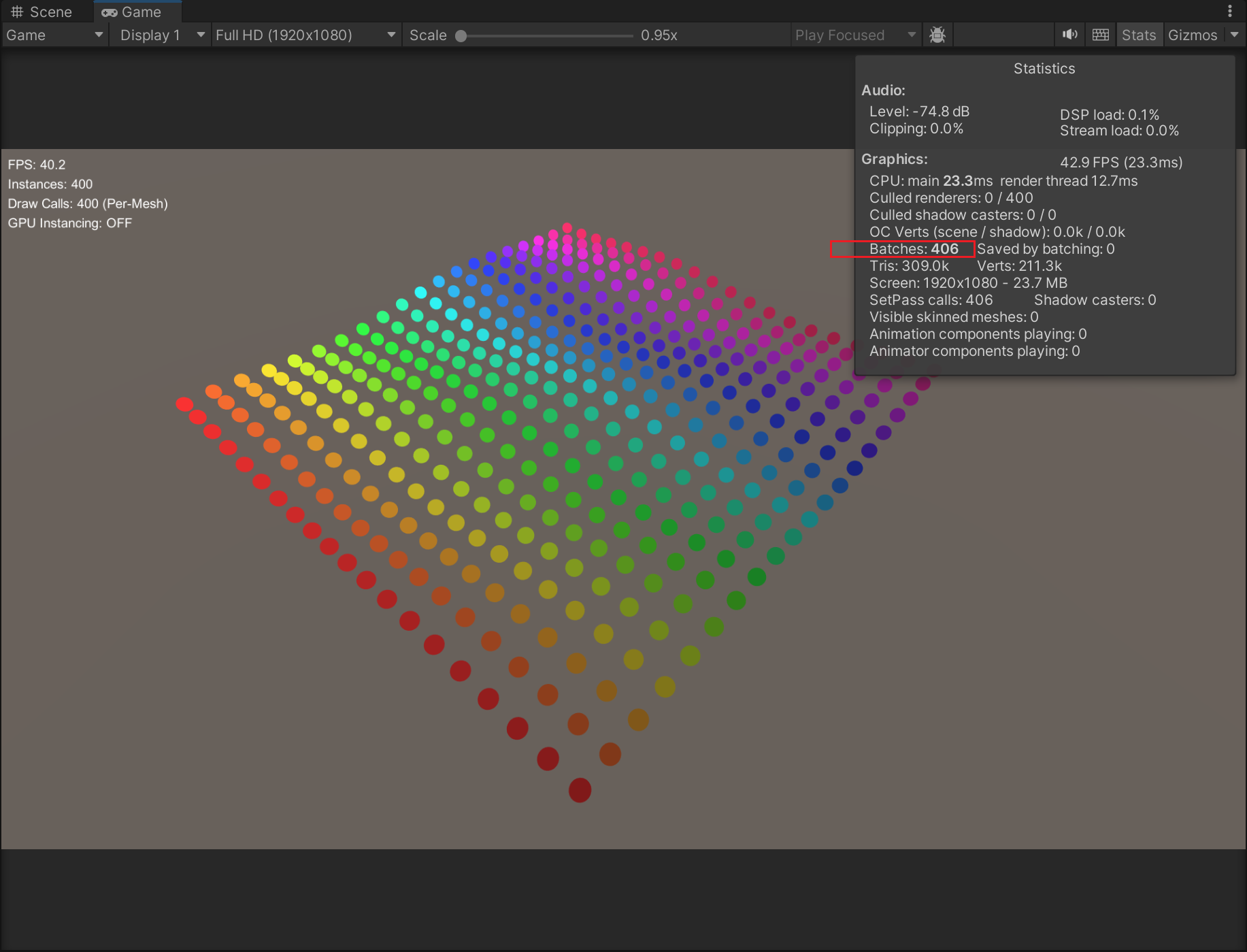
关闭GPU Instancing :
一句话记忆
共享几何 + 每实例数据数组 + InstanceID 索引 = GPU 内部循环渲染