Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第七章 Classes and Interfaces(类与接口)
作为一种面向对象编程语言,Python 支持各种特性,如继承、多态和封装。在 Python 中完成任务通常需要编写新的类,并定义它们如何通过接口和关系进行交互。
类与继承机制使得用对象来表述 Python 程序的预期行为变得十分简便。它们使您能够随着时间的推移不断完善和扩展功能。在需求不断变化的环境中,这些机制提供了灵活性。熟练掌握类与继承的使用方法,有助于您编写易于维护的代码。
Python 也是一种多范式语言 ,它鼓励采用函数式编程 风格。函数对象属于第一类,这意味着它们可以像普通变量一样被传递。Python 还允许你在同一程序中使用混合的面向对象风格与函数式风格特性,这种方式可能比各自独立使用任何一种风格都更为强大。
Item 56:倾向于使用数据类来创建不可变对象
在 Python 中,几乎一切内容都可在运行时进行修改,这是该语言理念中的一个基本要素(参见 Item 55 和 Item 3)。然而,这种灵活性往往会导致一些难以调试的问题。
减少可能出现问题的范围的一种方法是,在对象创建后不允许对其进行修改。这一要求迫使代码的编写采用功能式风格,其中函数和方法的主要目的便是始终如一地将输入映射为输出,类似于数学方程式的处理方式。
以这种风格编写的函数很容易测试。您只需考虑参数和返回值的等效性,而不必担心对象引用和身份。推理和修改不会进行可变状态转换或导致外部副作用的函数是很简单的。通过返回以后无法修改的值,函数可以避免下游意外。
通过创建不可变的对象,你便能够利用这些优势来使用你自己的数据类型。内置的 dataclasses 模块(详见 Item 51)提供了一种定义此类对象的方法,这种方法远胜于使用 Python 的标准面向对象特性。dataclasses 还内置了其他功能,例如能够将值对象用作字典中的键以及集合中的成员。
防止对象被修改
在 Python 中,函数的所有参数都是通过引用传递的。遗憾的是,这会导致调用者的数据可以被任何被调用者修改(详情见 Item 30)。这种行为可能会引发各种令人困惑的 bug。例如,这里我定义了一个标准类,用于表示二维空间中一个标记点的位置:
class Point:
def __init__(self, name, x, y):
self.name = name
self.x = x
self.y = y我可以定义一个行为规范的辅助函数,用于计算两点间的距离,且不会修改输入参数:
def distance(left, right):
return ((left.x -right.x) ** 2+
(left.y -right.y) ** 2) ** 0.5
origin1 = Point("source", 0, 0)
point1 = Point("destination", 3, 4)
print(distance(origin1, point1))
>>>
5.0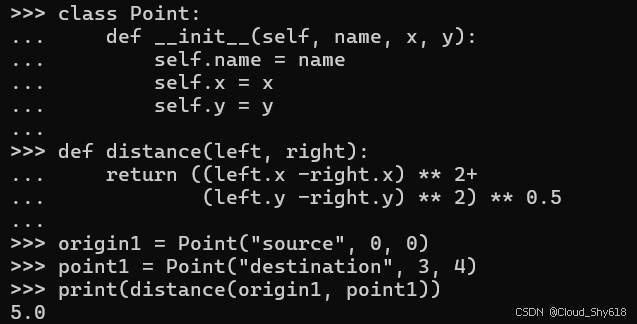
我还可以定义一个行为欠佳的函数,该函数会覆盖第一个参数中 x 的值:
def bad_distance(left, right):
left.x = -3
return distance(left, right)这种修改会导致错误的计算结果产生,并且会永久性地改变原对象的状态,从而使后续的运算结果也变得不准确:
print(bad_distance(origin1, point1))
print(origin1.x)
>>>
7.211102550927978
-3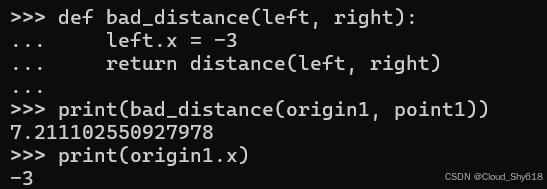
我可以通过实现 __setattr__ 和 __delattr__ 特殊方法,并让它们抛出 AttributeError 异常,来防止在标准类中发生此类修改行为(有关信息,请参阅 Item 61:"使用 __getattr__、__getattribute__ 和 __setattr__ 实现惰性属性")。为了设置初始属性值,我直接在 __dict__ 对象字典中赋值键值对:
class ImmutablePoint:
def __init__(self, name, x, y):
self.__dict__.update(name=name, x=x, y=y)
def __setattr__(self, key, value):
raise AttributeError("Immutable object: set not allowed")
def __delattr__(self, key):
raise AttributeError("Immutable object: del not allowed")现在我可以像以前一样进行同样的距离计算,并得出正确的答案:
origin2 = ImmutablePoint("source", 0, 0)
assert distance(origin2, point1) == 5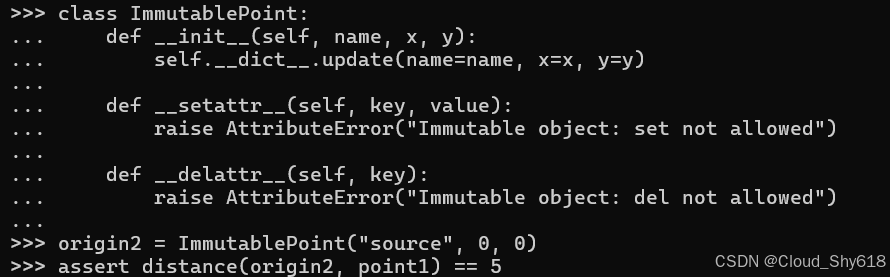
但使用这个行为欠佳、会修改自身输入的函数时,会引发异常:
bad_distance(origin2, point1)
>>>
Traceback ...
AttributeError: Immutable object: set not allowed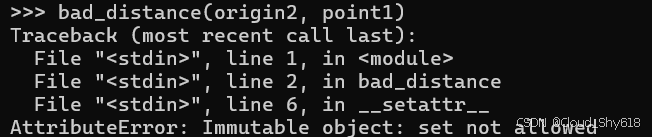
若想使用内置的 dataclasses 模块实现相同的功能,我所需要做的仅仅是将 frozen 标志传递给 dataclass 装饰器即可:
from dataclasses import dataclass
@dataclass(frozen=True)
class DataclassImmutablePoint:
name: str
x: float
y: float
origin3 = DataclassImmutablePoint("origin", 0, 0)
assert distance(origin3, point1) == 5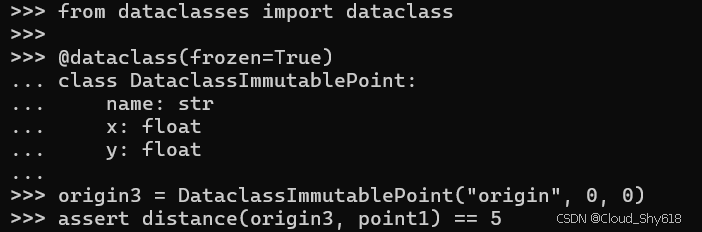
尝试修改此新数据类的属性时,运行时将会引发类似的 AttributeError 错误:
bad_distance(origin3, point1)
>>>
Traceback ...
FrozenInstanceError: cannot assign to field 'x'
此外,这种数据类方法还能使静态分析工具在程序执行前便能够检测到此类问题(详情请见 Item 124:"考虑通过类型分析进行静态分析以规避错误"):
from dataclasses import dataclass
@dataclass(frozen=True)
class DataclassImmutablePoint:
name: str
x: float
y: float
origin = DataclassImmutablePoint("origin", 0, 0)
origin.x = -3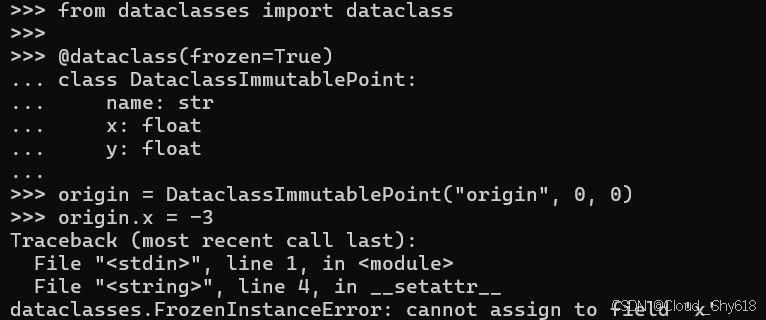
你还可以利用内置模块中的 Final 和 Never 功能,使标准类同样无法通过静态分析,但所需的代码量要大得多:
from typing import Any, Final, Never
class ImmutablePoint:
name: Final[str]
x: Final[int]
y: Final[int]
def __init__(self, name: str, x: int, y: int) -> None:
self.name = name
self.x = x
self.y = y
def __setattr__(self, key: str, value: Any) -> None:
if key in self.__annotations__ and key not in dir(self):
# Allow the very first assignment to happen
super().__setattr__(key, value)
else:
raise AttributeError("Immutable object: set not allowed")
def __delattr__(self, key: str) -> Never:
raise AttributeError("Immutable object: del not allowed")创建被替换属性的对象副本
当对象是不可变时,一个自然而然的问题便会浮现:如果对数据结构进行修改已不可能,那么该如何编写能够实现任何功能的代码呢?例如,这里有一个辅助函数,用于将一个 Point 对象相对移动一段距离:
def translate(point, delta_x, delta_y):
point.x += delta_x
point.y += delta_y正如预期的那样,当输入对象为不可变时,该方法会失败:
point1 = ImmutablePoint("destination", 5, 3)
translate(point1, 10, 20)
>>>
Traceback ...
AttributeError: Immutable object: set not allowed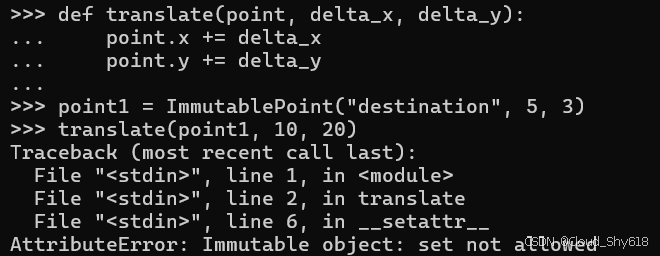
解决这一局限性的方法之一,是返回给定参数的副本,同时更新其中的属性值:
def translate_copy(point, delta_x, delta_y):
return ImmutablePoint(
name=point.name,
x=point.x +delta_x,
y=point.y +delta_y,
)但是,这很容易出错,因为你需要复制未修改的所有属性,例如本例中的 name。 随着时间的推移,随着类添加、删除或更改属性,这种复制代码可能会不同步,并导致程序中出现神秘的错误。
为了降低标准类中出现此类错误的风险,我在这里添加了一个方法,该方法能够使用给定的一组属性覆盖创建对象的副本:
class ImmutablePoint:
def __init__(self, name, x, y):
self.__dict__.update(name=name, x=x, y=y)
def __setattr__(self, key, value):
raise AttributeError("Immutable object: set not allowed")
def __delattr__(self, key):
raise AttributeError("Immutable object: del not allowed")
def _replace(self, **overrides):
fields = dict(
name=self.name,
x=self.x,
y=self.y,
)
fields.update(overrides)
cls = type(self)
return cls(**fields)现在,代码可以依靠 _replace 方法来确保正确考虑所有属性。这里定义了使用该方法的 translate 函数的另一个版本:
def translate_replace(point, delta_x, delta_y):
return point._replace( # Changed
x=point.x + delta_x,
y=point.y + delta_y,
)请注意 name 属性不再被提及。但这种方法仍然不理想。尽管已将字段复制代码集中到类内的一个位置,但 _replace 方法仍然有可能不同步,因为它需要手动维护。此外,每个需要此功能的类都必须定义自己的 _replace 方法,这会导致需要管理更多样板代码。
要使用 dataclass 完成相同的行为,我可以简单地使用 dataclasses 模块中的 replace 辅助函数;不需要更改类定义,不需要定义自定义 _replace 方法,并且该方法不可能不同步:
import dataclasses
def translate_dataclass(point, delta_x, delta_y):
return dataclasses.replace( # Changed
point,
x=point.x +delta_x,
y=point.y +delta_y,
)在字典和集合中使用不可变对象
当你将相同的键分配给字典中的不同值时,你期望只保留最终的映射:
my_dict = {}
my_dict["a"] = 123
my_dict["a"] = 456
print(my_dict)
>>>
{'a': 456}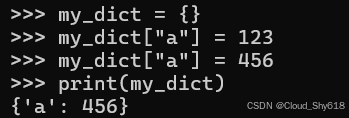
类似地,当您向集合中添加一个值时,您预计同一值的所有后续添加都不会导致集合发生任何更改,因为该值已经存在:
my_set = set()
my_set.add("b")
my_set.add("b")
print(my_set)
>>>
{'b'}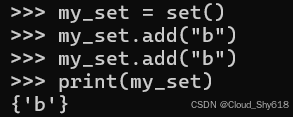
这些稳定的映射和重复数据删除行为是对这些数据结构如何工作的关键期望。令人意外的是,默认情况下,用户定义的对象不能像上面代码中的简单值 "a" 和 "b" 一样用作字典键或设置值。
例如,假设我想编写一个程序来模拟电的物理特性。在此处,我创建了一个字典,它将点对象映射到该位置上的电荷量(可能还存在其他字典,将相同的点对象映射到其他量值,如磁通量等)。:
point1 = Point("A", 5, 10)
point2 = Point("B", -7, 4)
charges = {
point1: 1.5,
point2: 3.5,
}从字典中检索给定点的值似乎可行:
print(charges[point1])
>>>
1.5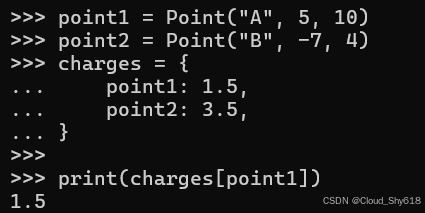
然而,如果我创建另一个看似与第一个 Point object 相同的对象------具有相同的坐标和名称------那么在通过字典进行查找时,会引发 KeyError 异常:
point3 = Point("A", 5, 10)
charges[point3]
>>>
Traceback ...
KeyError: <__main__.Point object at 0x100e85eb0>
经过进一步检查后发现,这些 Point objects 并不被视为等同对象,原因在于我尚未为该类实现 __eq__ 特殊方法:
assert point1 != point3对于对象来说 == 运算符的默认实现与仅比较其标识的 is 运算符相同。在此处,我实现了 __eq__ 特殊方法,以便它能比较对象属性值的差异:
class Point:
def __init__(self, name, x, y):
self.name = name
self.x = x
self.y = y
def __eq__(self, other):
return (
type(self) == type(other)
and self.name == other.name
and self.x == other.x
and self.y == other.y
)现在,两个看似等同的点对象也将被 == 运算符视为等同:
point4 = Point("A", 5, 10)
point5 = Point("A", 5, 10)
assert point4 == point5然而,即便有了这些新的等价对象,从较早时期开始的字典查找操作依然无法完成:
other_charges = {
point4: 1.5,
}
other_charges[point5]
>>>
Traceback ...
TypeError: unhashable type: 'Point'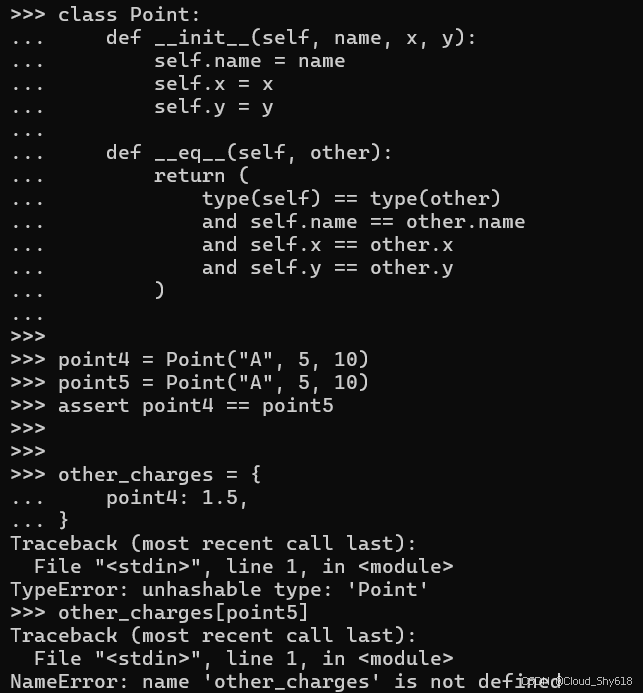
问题是 Point 类没有实现 __hash__ 特殊方法。Python 的字典类型实现依赖于 __hash__ 方法返回的整数值来维护其内部查找表。为了使字典正常工作,这个哈希值对于单个对象必须是稳定且不变的,并且对于等效对象来说它必须是相同的。这里,我通过将对象的属性放入元组中并将其传递给 hash 内置函数来实现 __hash__ 方法:
class Point:
def __init__(self, name, x, y):
self.name = name
self.x = x
self.y = y
def __eq__(self, other):
return (
type(self) == type(other)
and self.name == other.name
and self.x == other.x
and self.y == other.y
)
def __hash__(self):
return hash((self.name, self.x, self.y))现在字典查询功能已按预期运行:
point6 = Point("A", 5, 10)
point7 = Point("A", 5, 10)
more_charges = {
point6: 1.5,
}
value = more_charges[point7]
assert value == 1.5借助数据类,要使用一个不可变对象作为字典中的键,完全无需进行上述任何操作。当你向数据类装饰器传入 frozenflag 参数时,便可自动获得所有这些行为(例如 __eq__、__hash__ 等):
point8 = DataclassImmutablePoint("A", 5, 10)
point9 = DataclassImmutablePoint("A", 5, 10)
easy_charges = {
point8: 1.5,
}
assert easy_charges[point9] == 1.5这些不可变的对象还可被用作集合中的值,并且能够有效地消除重复:
my_set = {point8, point9}
assert my_set == {point8}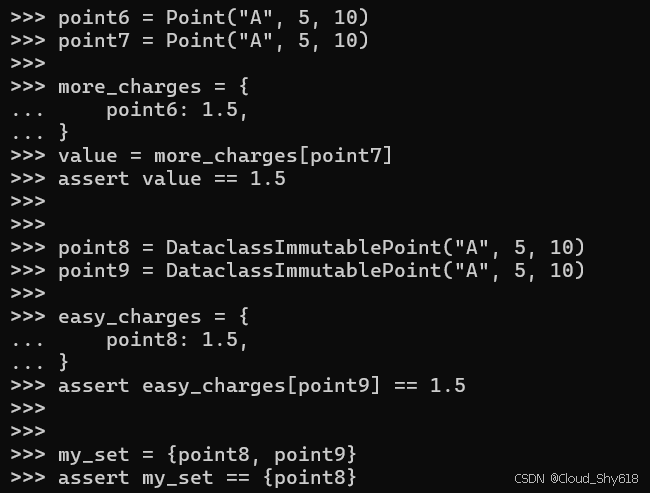
那命名元组呢?
在数据类被添加至 Python 标准库(版本 3.7)之前,用于创建不可变对象的一个良好选择是内置模块 collections 中的 namedtuple 函数。namedtuple 提供了与使用 frozen 标志的数据类装饰器相似的诸多优势,包括:
- 构造对象时可使用位置参数或关键字参数,当属性未指定时系统会自动提供默认值。
- 对象导向的特殊方法的自动定义(例如
__init__、__repr__、__eq__、__hash__、__lt__等)。 - 内置辅助方法
_replace和_dict,以及借助_fields和_field_defaults类属性进行运行时探查功能。 - 在使用内置模块 typing 中的 NamedTuple 类时,支持静态类型检查功能。
- 通过避免使用
__dict__实例字典(即类似于使用带有 slots=True 参数的 dataclasses)来降低内存占用量。
此外,命名元组的各个字段均可通过位置索引进行访问,这非常适用于封装诸如 CSV(逗号分隔值)文件中的行或数据库查询结果中的列等序列化数据结构------使用数据类时,必须调用 _astuple 方法。
然而,namedtuple 的顺序性质可能会导致无意的使用(即数字索引和迭代),从而导致错误并使以后难以迁移到标准类,特别是对于外部 APIs(请参阅 Item 119:"使用包来组织模块并提供稳定的 APIs")。 如果你的数据结构是顺序的,那么 namedtuple 可能是一个不错的选择,但否则最好使用数据类或标准类(参见 Item 65:"考虑类体定义顺序来建立属性之间的关系")。
注意:
- 使用不可变对象的函数式风格代码通常比修改状态并引发副作用的过程式风格代码更加稳健。
- 创建你自己的不可变对象最简单的方法是使用内置的 dataclasses 模块;只需在定义类时应用 dataclass 装饰器,并传入 frozen=True 参数即可。
- 使用 dataclasses 模块的 replace 辅助函数可使您创建带有某些属性已更改的不可变对象的副本,从而便于编写函数式风格的代码。
- 使用 dataclass 创建的不可变对象在值相等性方面具有可比性,且拥有稳定的哈希值,这使得它们能够被用作字典中的键以及集合中的值。
Item 57:从 collections.abc 类中继承自定义容器类型
在 Python 编程中,很大一部分内容都涉及定义包含数据的类,并描述这些对象之间如何相互关联。每个 Python 类都是一种容器,同时封装了属性与功能。Python 还提供了内置的容器类型来管理数据:列表、元组、集合和字典。
当你为诸如序列等简单用例设计类时,自然而然地会想要直接继承 Python 内置的 list 类。例如,假设我想要创建自己的一套自定义 list 类,该类应具备用于统计其成员出现频率的额外方法:
class FrequencyList(list):
def __init__(self, members):
super().__init__(members)
def frequency(self):
counts = {}
for item in self:
counts[item] = counts.get(item, 0) + 1
return counts通过对列表进行子类化,我获得了列表的所有标准功能,并保留了所有 Python 程序员都熟悉的语义。我可以定义其他方法来提供我需要的任何自定义行为:
foo = FrequencyList(["a", "b", "a", "c", "b", "a", "d"])
print("Length is", len(foo))
foo.pop() # Removes "d"
print("After pop:", repr(foo))
print("Frequency:", foo.frequency())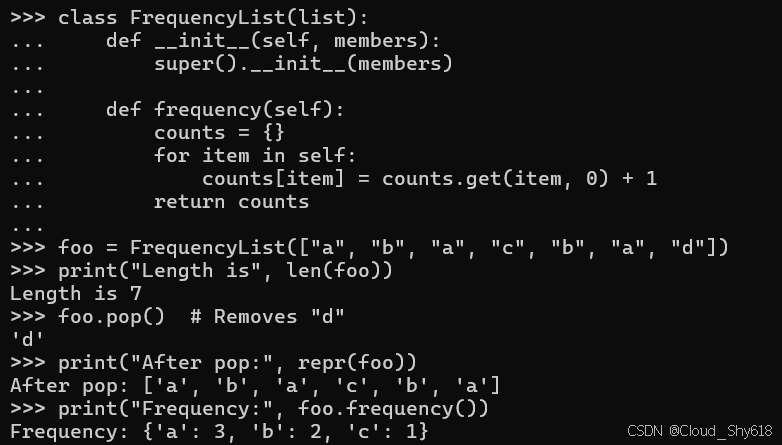
现在,假设我需要定义一个类似于列表并允许索引但不是列表子类的对象。例如,假设我想为二叉树类提供序列语义(如列表或元组;请参阅 Item 14:"了解如何对序列进行切片" 了解背景):
class BinaryNode:
def __init__(self, value, left=None, right=None):
self.value = value
self.left = left
self.right = right如何使这个类表现得像序列类型?Python 使用具有特殊名称的实例方法来实现其容器行为。当您通过索引访问序列项时:
bar = [1, 2, 3]
bar[0]它将被解释为:
bar.__getitem__(0)为了使 BinaryNode 类表现得像一个序列,您可以提供 __getitem__ 的自定义实现(通常发音为 "dunder getitem",是 "双下划线 getitem" 的缩写),它深度优先遍历对象树:
class IndexableNode(BinaryNode):
def _traverse(self):
if self.left is not None:
yield from self.left._traverse()
yield self
if self.right is not None:
yield from self.right._traverse()
def __getitem__(self, index):
for i, item in enumerate(self._traverse()):
if i == index:
return item.value
raise IndexError(f"Index {index} is out of range")这里我用普通的对象初始化构造了一个二叉树:
tree = IndexableNode(
10,
left=IndexableNode(
5,
left=IndexableNode(2),
right=IndexableNode(6, right=IndexableNode(7)),
),
right=IndexableNode(15, left=IndexableNode(11)),
)但除了能够使用 left 和 right 属性遍历树之外,我还可以像列表一样访问它:
print("Example 8")
print("LRR is", tree.left.right.right.value)
print("Index 0 is", tree[0])
print("Index 1 is", tree[1])
print("11 in the tree?", 11 in tree)
print("17 in the tree?", 17 in tree)
print("Tree is", list(tree))
>>>
LRR is 7
Index 0 is 2
Index 1 is 5
11 in the tree? True
17 in the tree? False
Tree is [2, 5, 6, 7, 10, 11, 15]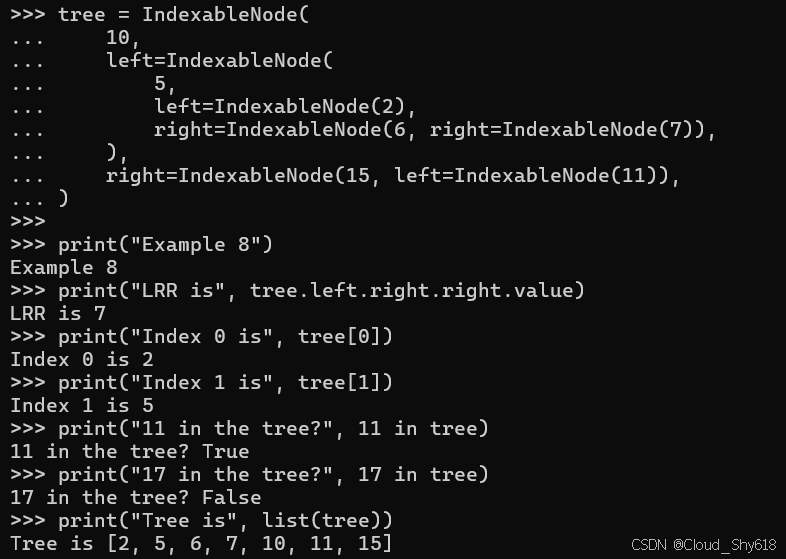
问题是实现 __getitem__ 不足以提供 Python 期望从列表实例中获得的所有序列语义:
len(tree)
>>>
Traceback ...
TypeError: object of type 'IndexableNode' has no len()len 内置函数需要另一个特殊方法 __len__,它必须具有自定义序列类型的实现:
class SequenceNode(IndexableNode):
def __len__(self):
count = 0
for _ in self._traverse():
count += 1
return count
tree = SequenceNode(
10,
left=SequenceNode(
5,
left=SequenceNode(2),
right=SequenceNode(6, right=SequenceNode(7)),
),
right=SequenceNode(15, left=SequenceNode(11)),
)
print("Tree length is", len(tree))
>>>
Tree length is 7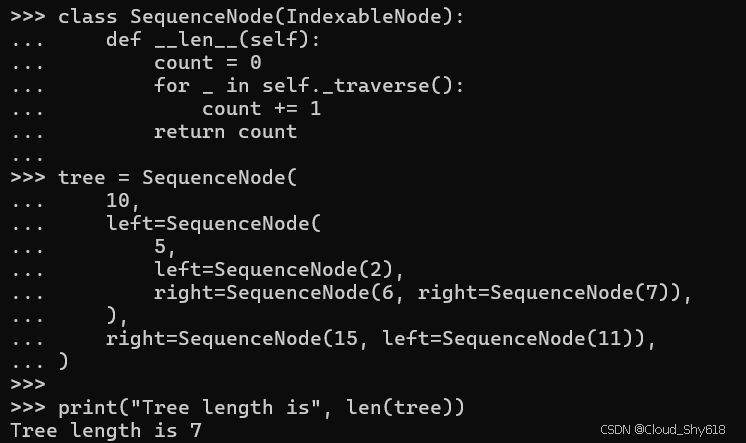
不幸的是,这仍然不足以让类完全充当有效的序列。还缺少 Python 程序员期望在列表或元组等序列上看到的计数和索引方法。事实证明,定义自己的容器类型比看起来要困难得多。
为了在整个 Python 世界中避免这种困难,collections.abc 内置模块定义了一组抽象基类,为每种容器类型提供所有典型方法。当您从这些抽象基类派生子类并忘记实现所需的方法时,该模块会告诉您出现了问题:
from collections.abc import Sequence
class BadType(Sequence):
pass
foo = BadType()
>>>
Traceback ...
TypeError: Can't instantiate abstract class BadType without an
➥implementation for abstract methods '__getitem__', '__len__'
当您实现 collections.abc 中的抽象基类所需的所有方法时,就像我上面使用 SequenceNode 所做的那样,它免费提供所有附加方法,例如 index 和 count :
class BetterNode(SequenceNode, Sequence):
pass
tree = BetterNode(
10,
left=BetterNode(
5,
left=BetterNode(2),
right=BetterNode(6, right=BetterNode(7)),
),
right=BetterNode(15, left=BetterNode(11)),
)
print("Index of 7 is", tree.index(7))
print("Count of 10 is", tree.count(10))
>>>
Index of 7 is 3
Count of 10 is 1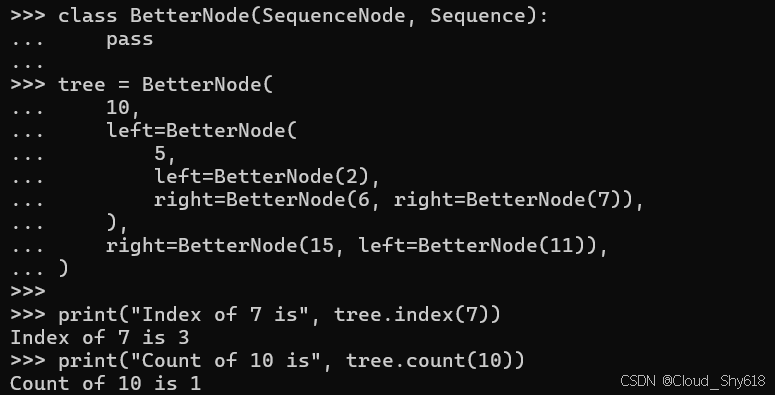
对于更复杂的容器类型(例如 Set 和 Mutable Mapping),使用这些抽象基类的好处甚至更大,它们需要实现大量特殊方法来匹配 Python 约定。
除了 collections.abc 模块之外,Python 还使用各种特殊方法进行对象比较和排序,这些方法可能由容器类和非容器类提供(例如,请参阅 Item 104:"了解如何使用 heapq 作为优先级队列" 和 Item 51:"首选数据类来定义轻量级类")。
注意:
- 对于简单的用例,可以直接从 Python 容器类型(如 list 或 dict)继承来利用它们的基本行为。
- 当不从内置类型继承时,请注意正确实现自定义容器类型所需的大量方法。
- 为了确保您的自定义容器类符合所需的行为,请让它们继承 collections.abc 中定义的接口。