
docker 命令没了,不代表节点不能查
生产节点上最常见的卡点不是"不会 Kubernetes",而是值班时习惯性敲:
docker ps结果返回:
bash: docker: command not found或者 Docker 服务根本不存在。此时很多人会转去看 kubectl get pod,但 kubectl 只能告诉你集群对象状态,不一定能回答节点上的容器运行时到底发生了什么。比如 Pod 一直 ContainerCreating、节点日志里出现 CRI 错误、镜像已经拉下来了但容器没有起来,这些问题最终都要落到 kubelet 和容器运行时之间的 CRI 层。
在 containerd 节点上,crictl 就是这个入口。它不是 Docker 的完整替代品,也不是 containerd 的万能管理工具。更准确地说,crictl 是直接面向 CRI 的排障工具:看 Pod Sandbox、容器、镜像、日志、运行时信息,验证 kubelet 看到的运行时状态是否正常。
本文按生产排障顺序写:先讲工具边界,再配置 endpoint,然后给出从 docker 迁移到 crictl 的命令表,最后给出常见错误和节点排障最小命令集。
概念边界:kubectl、crictl、ctr 分别看什么
先把边界划清楚,后面的命令才不会乱用。
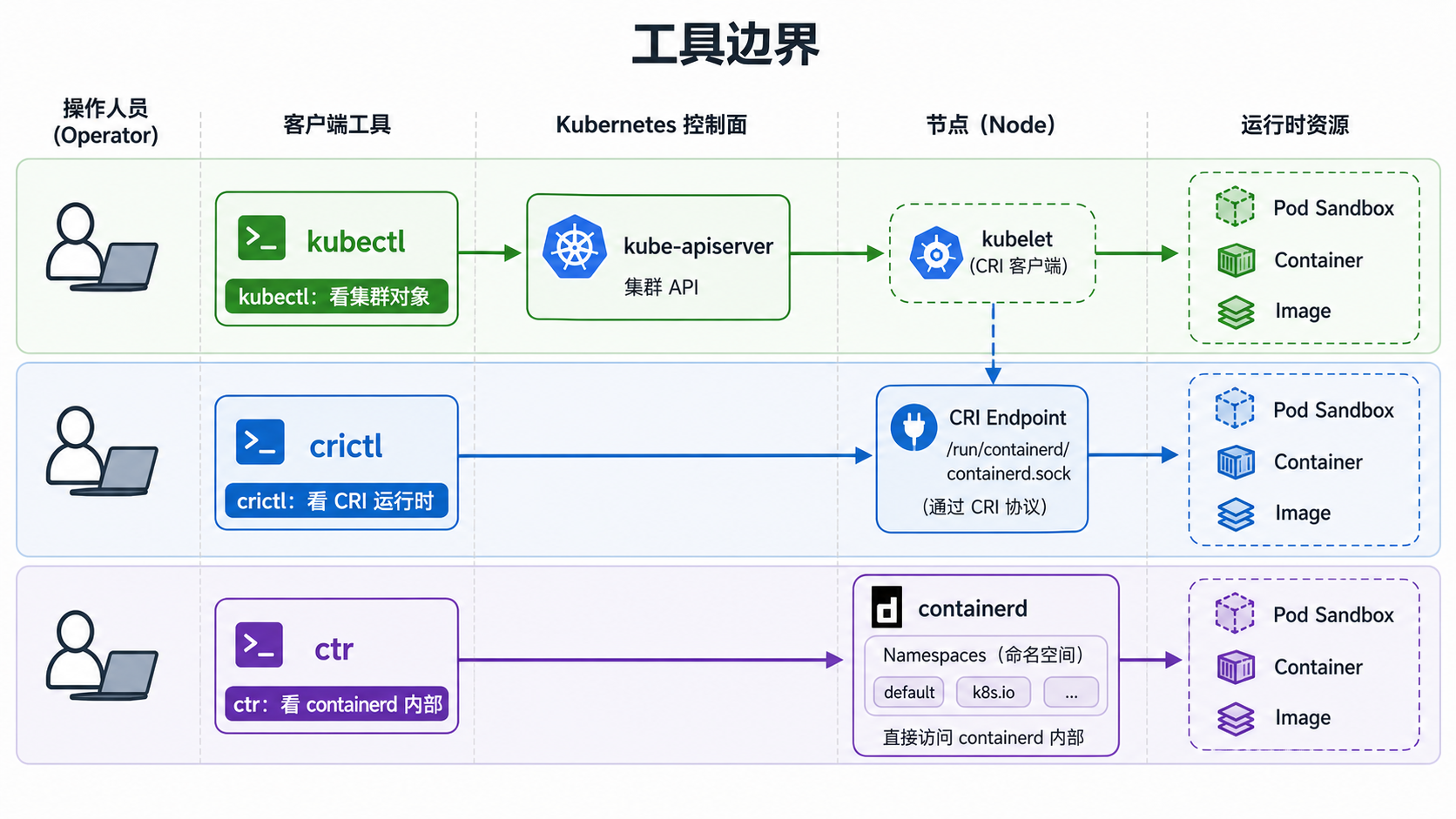
| 工具 | 主要连接对象 | 适合查看什么 | 不适合做什么 |
|---|---|---|---|
kubectl |
kube-apiserver | Pod、Node、Event、Deployment 等集群对象 | 直接判断节点本地 CRI socket 是否可用 |
crictl |
kubelet 使用的 CRI endpoint | Pod Sandbox、容器、镜像、容器日志、运行时信息 | 管理非 CRI 视角下的 containerd 内部对象 |
ctr |
containerd daemon | namespace、content、snapshot、底层镜像对象 | 替代 kubelet/CRI 做日常 Kubernetes 排障 |
journalctl |
systemd 日志 | kubelet、containerd 服务错误 | 直接列出 Pod 和容器对象 |
一个实用判断:
-
先用
kubectl判断"集群认为它是什么状态"。 -
再用
crictl判断"节点运行时实际有什么"。 -
只有当
crictl看不到、但你怀疑 containerd 内部状态异常时,再用ctr深挖。
不要一上来就用 ctr 替代 crictl。Kubernetes 通过 CRI 管理 Pod 和容器,crictl 的视角更接近 kubelet。
第一步:确认 crictl 连接的是 kubelet 使用的 runtime endpoint
crictl 好不好用,第一步看 /etc/crictl.yaml。如果 endpoint 指错了,后面所有命令都会误导你。
推荐配置如下:
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
pull-image-on-create: false
disable-pull-on-run: false写入或修正配置:
sudo tee /etc/crictl.yaml >/dev/null <<'EOF'
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
pull-image-on-create: false
disable-pull-on-run: false
EOF用途:固定 crictl 使用 containerd 的 CRI socket,避免它逐个尝试默认 endpoint 造成误判。 判断标准:后续 sudo crictl info 能返回 runtimeType、runtimeName、lastCNILoadStatus 等字段。
确认配置内容:
sudo cat /etc/crictl.yaml用途:检查 runtime-endpoint 和 image-endpoint 是否都是 unix:///run/containerd/containerd.sock。 判断标准:不要混入旧 Docker shim 路径,也不要写成不存在的 socket。
确认 socket 文件存在:
sudo ls -l /run/containerd/containerd.sock用途:判断 containerd CRI socket 是否真实存在。 判断标准:能看到 socket 文件,且权限允许 root 访问;如果显示 No such file or directory,先查 containerd 是否启动和配置是否加载 CRI 插件。
确认 containerd 服务状态:
sudo systemctl status containerd --no-pager用途:判断 containerd 是否正在运行。 判断标准:Active: active (running) 是基本前提;如果是 failed、activating、inactive,先看服务日志。
查看 containerd 最近日志:
sudo journalctl -u containerd -n 200 --no-pager用途:定位 CRI 插件、镜像仓库、snapshotter、shim 启动错误。 判断标准:重点看 failed、error、CRI、snapshotter、failed to start shim、failed to pull 等关键词。
第二步:用 crictl info 判断 CRI 是否可用
先不要急着查容器。最小入口是:
sudo crictl info用途:确认 crictl 可以通过 CRI 连接 containerd,并读取运行时状态。 判断标准:输出 JSON 中应出现运行时信息和 CNI 状态。重点看:
"runtimeName": "containerd"
"runtimeType": "io.containerd.runc.v2"
"lastCNILoadStatus": "OK"
"networkReady": true如果 crictl info 失败,先不要继续执行 crictl ps。按这个顺序查:
| 报错现象 | 常见原因 | 检查命令 | 下一步 |
|---|---|---|---|
connection refused |
containerd 未运行或 socket 不可用 | sudo systemctl status containerd --no-pager |
修复服务启动错误 |
no such file or directory |
endpoint 路径写错或 socket 不存在 | sudo ls -l /run/containerd/containerd.sock |
修正 /etc/crictl.yaml 或检查 containerd |
context deadline exceeded |
runtime 卡死、IO 卡住或服务响应慢 | sudo journalctl -u containerd -n 200 --no-pager |
查 shim、snapshotter、磁盘、镜像拉取错误 |
permission denied |
非 root 用户无权访问 socket | ls -l /run/containerd/containerd.sock |
用 sudo 执行或调整受控运维权限 |
第三步:把 docker 命令习惯迁移到 crictl/kubectl
下面这张表可以直接收藏。生产排障时不要只找"等价命令",要同时看对象层级:Kubernetes 里先有 Pod Sandbox,再有容器。
| Docker 习惯 | crictl 命令 | kubectl 命令 | 适用场景 |
|---|---|---|---|
docker ps |
sudo crictl ps |
kubectl get pod -A -o wide |
看正在运行的容器和 Pod 分布 |
docker ps -a |
sudo crictl ps -a |
kubectl describe pod -n <ns> <pod> |
看退出、创建中、异常容器 |
docker logs <id> |
sudo crictl logs <container_id> |
kubectl logs -n <ns> <pod> -c <container> |
看容器 stdout/stderr |
docker inspect <id> |
sudo crictl inspect <container_id> |
kubectl get pod -n <ns> <pod> -o yaml |
看容器运行时详情 |
| 无直接常用习惯 | sudo crictl pods |
kubectl get pod -A |
看 Pod Sandbox |
| 无直接常用习惯 | sudo crictl inspectp <pod_id> |
kubectl describe pod -n <ns> <pod> |
看 Sandbox 网络和元数据 |
docker images |
sudo crictl images |
不适用 | 看节点本地 CRI 镜像列表 |
docker pull nginx:1.25 |
sudo crictl pull nginx:1.25 |
kubectl create deployment 触发拉取 |
验证节点能否拉镜像 |
docker exec -it <id> sh |
sudo crictl exec -it <container_id> sh |
kubectl exec -n <ns> -it <pod> -c <container> -- sh |
进入容器,优先用 kubectl exec |
docker rm / docker rmi |
sudo crictl rm / sudo crictl rmi |
通常不建议直接删 | 清理异常对象,生产需谨慎 |
注意:生产集群里不要随手 crictl rm、crictl rmi。如果 kubelet 仍在管理对应 Pod,手工删除会被重新拉起或造成状态跳变。清理前至少确认 Pod 归属、业务窗口和回滚路径。
第四步:查看 Pod Sandbox
Kubernetes 里每个 Pod 通常会先创建 Pod Sandbox。Pod 网络、命名空间和 pause 容器相关问题,经常先体现在 Sandbox 层。
sudo crictl pods用途:列出节点上的 Pod Sandbox。 判断标准:目标 Pod 应该能在列表中看到,STATE 通常应为 Ready。如果 Pod 在 apiserver 里存在,但节点上没有对应 Sandbox,要继续看 kubelet 和 containerd 日志。
按命名空间或 Pod 名过滤:
sudo crictl pods --name <pod_name>用途:快速找到目标 Pod 的 Sandbox ID。 判断标准:输出里 NAMESPACE、NAME、STATE 与目标 Pod 对得上。
查看 Sandbox 详情:
sudo crictl inspectp <pod_sandbox_id>用途:查看 Pod Sandbox 的元数据、网络状态、标签和创建信息。 判断标准:重点看 metadata.name、metadata.namespace、state、network、labels,确认它是不是你要查的 Pod。
如果 crictl pods 看不到目标 Pod,按顺序查:
-
kubectl get pod -n <ns> <pod> -o wide,确认 Pod 是否已调度到当前节点。 -
kubectl describe pod -n <ns> <pod>,看 Events 是否卡在调度、拉镜像、创建 Sandbox。 -
sudo journalctl -u kubelet -n 200 --no-pager,看 kubelet 是否向 runtime 发起创建。 -
sudo journalctl -u containerd -n 200 --no-pager,看 containerd 是否创建 Sandbox 失败。
第五步:查看容器状态
查看正在运行的容器:
sudo crictl ps用途:列出当前运行中的容器。 判断标准:目标业务容器应为 Running;如果 Pod Ready 但这里没有容器,要检查是否查错节点或查错 namespace。
查看所有容器,包括退出和创建失败的:
sudo crictl ps -a用途:排查 CrashLoopBackOff、创建失败、退出过快的容器。 判断标准:重点看 STATE、ATTEMPT、POD ID。同一个容器多次 attempt 增长,说明 kubelet 一直重启它。
按 Pod Sandbox ID 过滤容器:
sudo crictl ps -a --pod <pod_sandbox_id>用途:只看某个 Pod 下的容器,避免节点上容器太多。 判断标准:能看到 init container、业务 container 的状态差异;如果 init container 失败,主容器通常不会启动。
查看容器详情:
sudo crictl inspect <container_id>用途:查看容器配置、状态、退出码、挂载、标签和运行时信息。 判断标准:重点看 status.state、status.exitCode、status.reason、info.runtimeSpec.mounts、labels。
第六步:查看日志与进入容器
查看容器日志:
sudo crictl logs <container_id>用途:直接读取容器 stdout/stderr。 判断标准:适合查应用启动失败、参数错误、依赖连接失败;如果没有输出,要确认容器是否已经启动过,以及日志是否写到了文件而不是 stdout。
查看最近 100 行:
sudo crictl logs --tail=100 <container_id>用途:避免日志过大影响排障效率。 判断标准:先看最近错误,再决定是否扩大范围。
进入容器:
sudo crictl exec -it <container_id> sh用途:在节点本地进入容器。 判断标准:容器必须处于运行状态,镜像里也必须有 sh 或对应 shell。生产优先使用 kubectl exec,只有控制面访问受限或需要节点本地验证时再用 crictl exec。
优先推荐的 Kubernetes 入口:
kubectl exec -n <namespace> -it <pod_name> -c <container_name> -- sh用途:从集群 API 视角进入容器,审计和权限边界更清楚。 判断标准:适合常规业务排障;如果 apiserver 不通,再考虑节点侧 crictl exec。
第七步:查看镜像与拉取问题
查看节点本地 CRI 镜像:
sudo crictl images用途:确认镜像是否已经被 runtime 拉到节点。 判断标准:目标镜像 tag 或 digest 应出现在列表中;如果没有,继续查 Pod Events 和 containerd 拉取日志。
拉取镜像验证仓库链路:
sudo crictl pull nginx:1.25用途:验证当前节点能否通过 CRI 拉取镜像。 判断标准:成功会显示镜像拉取完成;失败时根据错误判断 DNS、TLS、认证、镜像不存在还是仓库不可达。
查看镜像详情:
sudo crictl inspecti nginx:1.25用途:确认镜像 ID、repoTags、repoDigests、size、uid/gid 等信息。 判断标准:如果业务要求固定 digest,重点看 repoDigests 是否符合发布记录。
删除确认无用镜像:
sudo crictl rmi <image_id_or_ref>用途:释放节点磁盘或清理错误镜像。 判断标准:生产执行前先确认没有运行中 Pod 依赖该镜像;建议先用 crictl ps -a 和 crictl inspect 交叉确认。
第八步:常见故障与判断路径

| 现象 | 先看哪里 | 命令 | 判断标准 |
|---|---|---|---|
Pod 一直 ContainerCreating |
Events 与 Sandbox | kubectl describe pod -n <ns> <pod>、sudo crictl pods |
Events 里是否有 Sandbox、CNI、镜像拉取错误 |
crictl info 失败 |
endpoint 和 socket | sudo cat /etc/crictl.yaml、sudo ls -l /run/containerd/containerd.sock |
endpoint 存在且指向 containerd socket |
| 容器反复重启 | 容器 attempt 和日志 | sudo crictl ps -a --pod <pod_id>、sudo crictl logs <container_id> |
attempt 增长,日志中有启动失败原因 |
| 镜像拉不下来 | 镜像列表和 containerd 日志 | sudo crictl pull <image>、sudo journalctl -u containerd -n 200 --no-pager |
判断是 DNS、TLS、认证、仓库地址还是镜像不存在 |
| kubectl 看到 Pod,crictl 看不到 | 调度节点和 kubelet | kubectl get pod -n <ns> <pod> -o wide、sudo journalctl -u kubelet -n 200 --no-pager |
确认 Pod 是否真的调度到当前节点 |
| crictl 能看见容器,业务仍不通 | Pod 网络和应用日志 | sudo crictl inspectp <pod_id>、sudo crictl logs <container_id> |
先区分容器启动失败、网络失败、应用健康检查失败 |
生产排障时最容易犯的错是只看一个层面。kubectl get pod 显示 Pending、ContainerCreating、CrashLoopBackOff,只是入口;真正原因往往需要结合 kubelet 日志、containerd 日志、CRI 对象状态和镜像拉取错误。
节点排障最小命令集
下面这组命令适合直接做成值班手册。执行前先确认你在目标节点上,且具备对应运维权限。
kubectl get pod -A -o wide | grep <node_name>用途:确认哪些 Pod 调度到目标节点。 判断标准:目标 Pod 的 NODE 字段必须是当前要排查的节点。
kubectl describe pod -n <namespace> <pod_name>用途:查看 Pod Events、容器状态和调度信息。 判断标准:先定位是调度、镜像、Sandbox、探针还是应用退出。
sudo crictl info用途:确认 CRI runtime 可访问。 判断标准:能返回 containerd 运行时信息和 CNI 状态。
sudo crictl pods --name <pod_name>用途:定位 Pod Sandbox ID。 判断标准:能看到目标 Pod 的 Sandbox,且 namespace 匹配。
sudo crictl ps -a --pod <pod_sandbox_id>用途:查看该 Pod 下所有容器状态。 判断标准:区分 init container、业务容器、退出容器和重启次数。
sudo crictl logs --tail=100 <container_id>用途:查看容器最近日志。 判断标准:重点找启动失败、配置缺失、依赖不可达、权限拒绝等明确错误。
sudo crictl inspect <container_id>用途:查看容器 runtime 详情。 判断标准:看退出码、挂载、标签、Pod 归属和 runtimeSpec。
sudo crictl inspectp <pod_sandbox_id>用途:查看 Pod Sandbox 详情。 判断标准:看网络、namespace、metadata、labels 是否符合预期。
sudo crictl images用途:查看节点本地镜像列表。 判断标准:目标镜像 tag/digest 是否存在。
sudo journalctl -u kubelet -n 200 --no-pager用途:查看 kubelet 与 CRI 交互错误。 判断标准:重点看 FailedCreatePodSandBox、CreateContainer、ImagePull、PLEG、runtime。
sudo journalctl -u containerd -n 200 --no-pager用途:查看 containerd 服务层错误。 判断标准:重点看 failed to pull、failed to start shim、snapshotter、permission denied、certificate。
一页式 checklist
| 检查项 | 命令 | 正常结果 | 异常时下一步 |
|---|---|---|---|
| Pod 是否在本节点 | kubectl get pod -A -o wide |
NODE 是当前节点 |
查调度、污点、资源 |
| CRI 是否可连接 | sudo crictl info |
返回 containerd 信息 | 查 /etc/crictl.yaml 和 socket |
| Sandbox 是否存在 | sudo crictl pods --name <pod> |
有目标 Sandbox | 查 kubelet 创建 Sandbox 日志 |
| 容器是否启动 | sudo crictl ps -a --pod <pod_id> |
业务容器 Running |
查退出码和日志 |
| 日志是否有明确错误 | sudo crictl logs <container_id> |
无启动异常 | 查应用配置、依赖、探针 |
| 镜像是否存在 | sudo crictl images |
目标镜像存在 | 查仓库、TLS、认证、DNS |
| kubelet 是否报 CRI 错 | sudo journalctl -u kubelet -n 200 --no-pager |
无 runtime 错误 | 对照 Events 修复 |
| containerd 是否报底层错 | sudo journalctl -u containerd -n 200 --no-pager |
无 shim/pull/snapshotter 错误 | 查运行时、磁盘、仓库 |
生产注意事项
-
不要把
crictl当成业务发布工具。它适合排障,不适合绕过 Kubernetes 控制面管理生产容器。 -
不要在未确认归属的情况下执行
crictl rm、crictl rmi。先确认 Pod、namespace、业务窗口和是否会被 kubelet 重建。 -
涉及 containerd 配置变更时,先备份:
sudo cp /etc/containerd/config.toml /etc/containerd/config.toml.$(date +%F-%H%M%S).bak用途:修改 containerd 配置前保留回滚点。 判断标准:备份文件存在,且可读。
- 重启 containerd 前先评估节点上的工作负载。生产建议先 cordon 节点,再按业务窗口灰度处理:
kubectl cordon <node_name>用途:阻止新的 Pod 调度到该节点。 判断标准:kubectl get node <node_name> 显示 SchedulingDisabled。
- 需要重启服务时,先在测试节点验证,再灰度到生产:
sudo systemctl restart containerd用途:让 containerd 重新加载配置或恢复异常服务。 判断标准:执行后 sudo systemctl status containerd --no-pager 为 running,且关键 Pod 状态恢复。生产执行前必须确认回滚方案。
总结
没有 Docker 命令后,节点排障入口不是消失了,而是从 Docker daemon 视角切换到了 Kubernetes + CRI 视角。
一条可靠路径是:
-
用
kubectl确认集群对象和 Pod 调度节点。 -
用
crictl info确认 CRI endpoint 可用。 -
用
crictl pods看 Pod Sandbox。 -
用
crictl ps -a看容器状态。 -
用
crictl logs、inspect、inspectp定位容器和 Sandbox 细节。 -
用
journalctl -u kubelet、journalctl -u containerd收敛到服务层错误。
把这条链路跑熟后,docker ps 不存在不会影响你排障,反而会逼你更接近 Kubernetes 真实的运行时边界。
参考资料
-
Kubernetes 官方文档:Debugging Kubernetes nodes with crictl Debugging Kubernetes nodes with crictl | Kubernetes
-
Kubernetes 官方文档:Container Runtimes Container Runtimes | Kubernetes
-
cri-tools / crictl GitHub 仓库 https://github.com/kubernetes-sigs/cri-tools
-
containerd 官方文档 containerd docs -- containerd Overview